1. Introduction
Full-life testing is not feasible in life tests and engineering experiments due to the extensive amount of time and funds required. As a result, censored life tests that will be stopped when a portion of the products fail have been developed and widely used. One of the most common schemes is progressive Type-II censoring (PT-IIC), which has piqued the attention of statisticians and reliability experts. As described in the following, a progressively Type-II censored sample is noticed. Suppose for a sample of size
n units, the researcher determines beforehand that
m of these
n units fail with PT-IIC plan
. Once the first failure happens,
of the
surviving units will be arbitrarily eliminated from the test. Then, when the subsequent failure occurs,
of the
remaining units are arbitrarily removed, and so on. In the end, when the
mth failure takes place, all of the leftover
, denoted by
, living units are removed from the test. Many authors have considered this scheme; for example, Ng et al. [
1], Kundu [
2], Cramer and Schmiedt [
3], and Dey et al. [
4]. For additional details, see Balakrishnan and Cramer [
5].
With advancements in the field in both manufacturing design and technology, the lifespan of products is increasing more and more, resulting in a test duration that is relatively lengthy despite the fact that the PT-IIC is employed. Kundu and Joarder [
6] have offered the progressive Type-I hybrid censoring scheme to address this problem. The test time is ensured under this approach and will not exceed the scheduled duration
T. Conversely, the experiment is ended at a specific time, leading to a random number of failure units. When the amount of data is small or even zero, the statistical inference results using this scheme may be inappropriate or inefficient. In light of this, Ng et al. [
7] presented an adaptive PT-IIC to improve statistical analysis efficiency. In this plan, the number of failures
m is decided in advance, and the testing time is allowed to exceed the threshold
T. Many academics have studied this strategy due to its exceptional benefits; see, for example, Panahi and Moradi [
8], Kohansal and Shoaee [
9], Xiong and Gui [
10], and Du and Gui [
11], among others.
However, as Ng et al. [
7] indicated, when the total span of the test is not a major concern, the adaptive PT-IIC scheme functions effectively in statistical inference. However, if the test units are highly reliable products, the testing period will be extremely long, and the adaptive PT-IIC fails to ensure an appropriate total test length. Nonetheless, in numerous practical contexts, the duration of the test is necessarily assumed to be a critical consideration. Yan et al. [
12] suggested a novel censoring strategy known as an improved adaptive progressive Type-II censoring (IAPT-IIC) scheme to tackle this problem. The IAPT-IIC scheme has two appealing characteristics. The first is that it can effectively ensure that the experiment terminates within a defined time, and the second is that it is a generalization of many censoring plans. The detailed IAPT-IIC sample can be discussed as follows. Suppose
n units are placed in a test with a predetermined desired number of failures
m, progressive censoring plan
, and the two thresholds
and
, where
. Here,
is the first threshold, and it serves as an indicator of the test time, while
is the second threshold, reflecting the maximum time enabled by the test. At the time of the
ith failure, say
,
of the remaining units are removed at random. Following the IAPT-IIC sample, we have one of the following three cases:
Case I: If the mth failure occurs before the first threshold , i.e., , the test is finished at , which is the conventional progressive Type-II sample with progressive censoring plan , where .
Case II: If the mth failure occurs between the two thresholds and , i.e., , the test is terminated at , without any further withdrawals after , by putting , where is the number of observed failures before the threshold . Then, at the time of mth failure, all the remaining units are removed. This case represents the adaptive PT-IIC sample with progressive censoring plan , where .
Case III: If the second threshold
occurs before the
mth failure, i.e.,
, the test is stopped at
, without any further withdrawals after
, by replacing
, where
is the number of observed data before time
. Thereafter, at
, all the remaining units are discarded, namely
. This is the outcome of the IAPT-IIC sample, with the following observed data:
with the following progressive censoring plan:
Let
for simplicity. Then, with cumulative distribution function (CDF),
, and probability density function (PDF), say
, the likelihood function of the observed data in (
1), denoted by
can be expressed according to Yan et al. [
12] as follows:
where
C is a constant,
for Case I, II, and III, respectively, while
and
The exponential (Ex) distribution is probably the most extensively used statistical model among parametric models in a variety of applications. An explanation for its significance is that the exponential distribution has only one parameter, making it relatively easy to handle. Furthermore, this model was the first lifetime model for which extensive statistical methodologies were established in life-testing and reliability experiments. For the random variable
Y, the CDF of the Ex distribution is given by
, where
is a scale parameter. Numerous variants of the Ex distribution are offered in the literature to add extra flexibility in modeling real-world phenomena. The so-called alpha power Ex (APE) distribution proposed by Mahdavi and Kundu [
13] via introducing a new shape parameter represented by
is one of these extensions. If
Y is a random variable within the APE distribution, then its PDF and CDF are given as follows:
and
respectively. Mahdavi and Kundu [
13] investigated the APE distribution’s main features as well as the estimation of its parameters. In terms of exploring real datasets, they demonstrated that the APE distribution can be applied as an alternative for several standard distributions, including Weibull and gamma models. The reliability and hazard rate functions at a distinct time
t correspond to the APE distribution, denoted by
and
, respectively, and are given by:
and
The HRF of the APE distribution has three forms, namely, constant, increasing, and decreasing. Because of its importance and flexibility, numerous writers have attempted to study some of its estimation issues using various types of data. Nassar et al. [
14] studied various classical estimation approaches for the APE distribution. Salah [
15] addressed the APE distribution estimation with progressively Type-II censored data. Alotaibi et al. [
16] explored the APE distribution using classical and Bayesian approaches under adaptive progressively Type-II hybrid censored samples.
Owing to the flexibility of the APE distribution in modeling real datasets and the effectiveness of the IAPT-IIC strategy for completing the experiment within a specific time frame, this study focuses on the following points:
- 1.
Deriving the maximum likelihood estimates of the unknown parameters, as well as the RF and HRF. Based on the maximum likelihood estimates (MLEs), the asymptotic properties are employed to obtain the approximate confidence intervals (ACIs) of the unknown parameters.
- 2.
Considering the Bayesian estimation approach, the point and highest posterior density (HPD) credible intervals for the various parameters are investigated. The Bayesian estimates are acquired based on the squared error loss function via the Markov chain Monte Carlo (MCMC) procedure.
- 3.
Selecting the optimal progressively censored plan using four statistical criteria.
- 4.
Performing a simulation analysis to judge the performance of the various estimation techniques.
- 5.
Finally, analyzing three real datasets to evaluate the performance of the various estimations and demonstrate the significance of the proposed approaches.
To assure the applicability of the results acquired in this study, we assume the following:
- 1.
The selected IAPT-IIC sample comes from a population that is known to follow the APE distribution.
- 2.
The lifetime of the experiment under consideration is very long, so employing any censoring scheme rather than the IAPT-IIC scheme will be impractical.
The remainder of this work is structured as follows. The MLEs and ACIs of the APE parameters, RF, and HRF are reported in
Section 2. The Bayesian estimates are derived in
Section 3.
Section 4 offers the simulation outcomes to point out and assess the functioning of the estimators based on the IAPT-IIC.
Section 5 then discusses the determination of optimal censoring strategies based on various optimality criteria. In
Section 6, three practical cases are given in order to show the usefulness of the IAT-II PCS.
Section 7 brings the paper to a close.
2. Classical Estimation Approach
In this part, the maximum likelihood estimation method is used to provide point and interval estimations of
, RF, and HRF of the APE distribution based on an IAPT-IIC sample. Based on the acquired sample
with a progressive censoring plan
, the likelihood function of
can be formulated from (
2)–(
4), after ignoring the constant
C, as shown below:
Let
and
. Then, one can write the log-likelihood function, denoted by
, as follows:
We are simply able to determine the normal equations by equating the first partial derivatives of
in (
8) with respect to
and
, respectively, to zero, as follows:
and
The maximum likelihood estimators (MLEs) of
and
of
and
, respectively, are obviously not straightforward in the delivered system of equations. The Newton–Raphson algorithm or another optimization algorithm must be used to obtain the required estimates in such scenarios. Another strategy to obtain the MLEs is to maximize the objective function in (
8) with respect to
and
. This technique is widespread when operating in the R programming language.
Then, using the MLEs’ invariance property, one can determine the MLEs of RF and HRF as follows:
and
The normal approximation of
can be used to perform asymptotic inference for the parameter vector
. The asymptotic normality of the MLEs provides the basis for establishing the ACIs of the parameters and reliability measures. Under some standard regular conditions, it is known that
for large
n, where
is the asymptotic variance–covariance matrix, which is likely to be approximated by taking the inverse of the observed Fisher information matrix in the form
. This method allows for obtaining the estimated variances, which are subsequently used in calculating the needed ACIs. Next, we derive the components of
by finding the second-order derivatives of (
8) as:
and
where
,
,
,
. As a result, the approximated variance–covariance matrix
can be expressed as:
The ACIs of the unknown parameters
and
can be obtained, respectively, as
and
, where
is the percentile
of the standard normal distribution, and
and
are obtained from (
11).
Another essential aspect to investigate is the construction of the ACIs for RF and HR. The challenge now is obtaining the variances of
and
if we know the variances of
and
. The delta method is one method used for dealing with this concern. It can be used to approximate the large-sample variance of a function of an estimator with known large-sample traits. Suppose that
and
are two vectors consisting of the first partial derivatives for RF and HRF with respect to
and
, respectively, and evaluated at
and
, as defined below:
Then, the approximate variances of the MLEs of RF and HRF can be expressed as:
where
and
Consequently, the ACIs of RF and HRF are given by and , where and .
4. Numerical Evaluations
This section provides extensive Monte-Carlo simulations to test the efficiency of the derived point/interval estimators of , , , and provided in the preceding sections.
4.1. Simulation Scenarios
The estimates of , , , and are assessed using different choices of , n, m, and . To achieve this objective, for , we acquired 1000 IAPT-IIC samples. Using , the values of and are 0.81593 and 1.99168, respectively. In addition to , and and (0.8, 1.2), several selections of m are used as failure percentages (FPs) of each n, such as %.
For the individual set
, the following progressive censoring schemes (PCSs)
are used, where
means 0 repeats
m times, namely:
where A, B, and C represents the left, middle, and right progressive removals, respectively.
To implement the experiment based on the philosophy sampling of IAPT-IIC from the proposed model, for specific values of , n, m, and , do the following steps:
- Step 1.
Put the true values of and .
- Step 2.
Simulate a PT-IIC sample as:
- a.
Get a uniform sample of size m (say ).
- b.
Set .
- c.
Set for .
- d.
Produce an IAPT-IIC sample from by set .
- Step 3.
Obtain at and remove the remaining sample .
- Step 4.
Obtain the first order statistics (say ) from a truncated distribution with sample size .
- Step 5.
Determine the IAPT-IIC sample type as follows:
- a.
If , the test stops at ; that is, Case I.
- b.
If , the test stops at , that is, Case II.
- c.
If , the test stops at , that is, Case III.
Once 1000 IAPT-IIC samples are collected via 4.2.2 programming software, we install two recommended packages:
A ’
’ package in the ’
’ function (by Henningsen and Toomet [
17]) to evaluate the MLEs and ACIs of
,
,
, and
.
A ’
’ package (by Plummer et al. [
18]) to calculate the Bayes and HPD interval estimates.
Implementing the MH approach examined in this study, the first 2000 (of 12,000) MCMC iterations are used as burn-in for each unknown quantity. Following that, the Bayes–MCMC estimates and associated 95% HPD intervals of , , , or are produced using the ’’ package. In regard to two criteria, namely, prior mean and prior variance, two sets labeled Prior 1 and 2 of the hyperparameters are taken as (2.5, 7.5, 5, 5) and (5, 15, 10, 10), respectively.
In Bayes MCMC computations, the convergence evaluation entails ensuring that the pattern, or chain, is the major concern in order to obtain a representative sample from the objective posterior distribution. For this objective, three convergence techniques are used: (i) the auto-correlation function (ACF), (ii) the Brooks–Gelman–Rubin (BGR) diagnostic, and (iii) the trace thinning-based (for example, we took the 5th point). Taking
,
,
n[FP%] = 100[40%],
, and
,
Figure 1 and
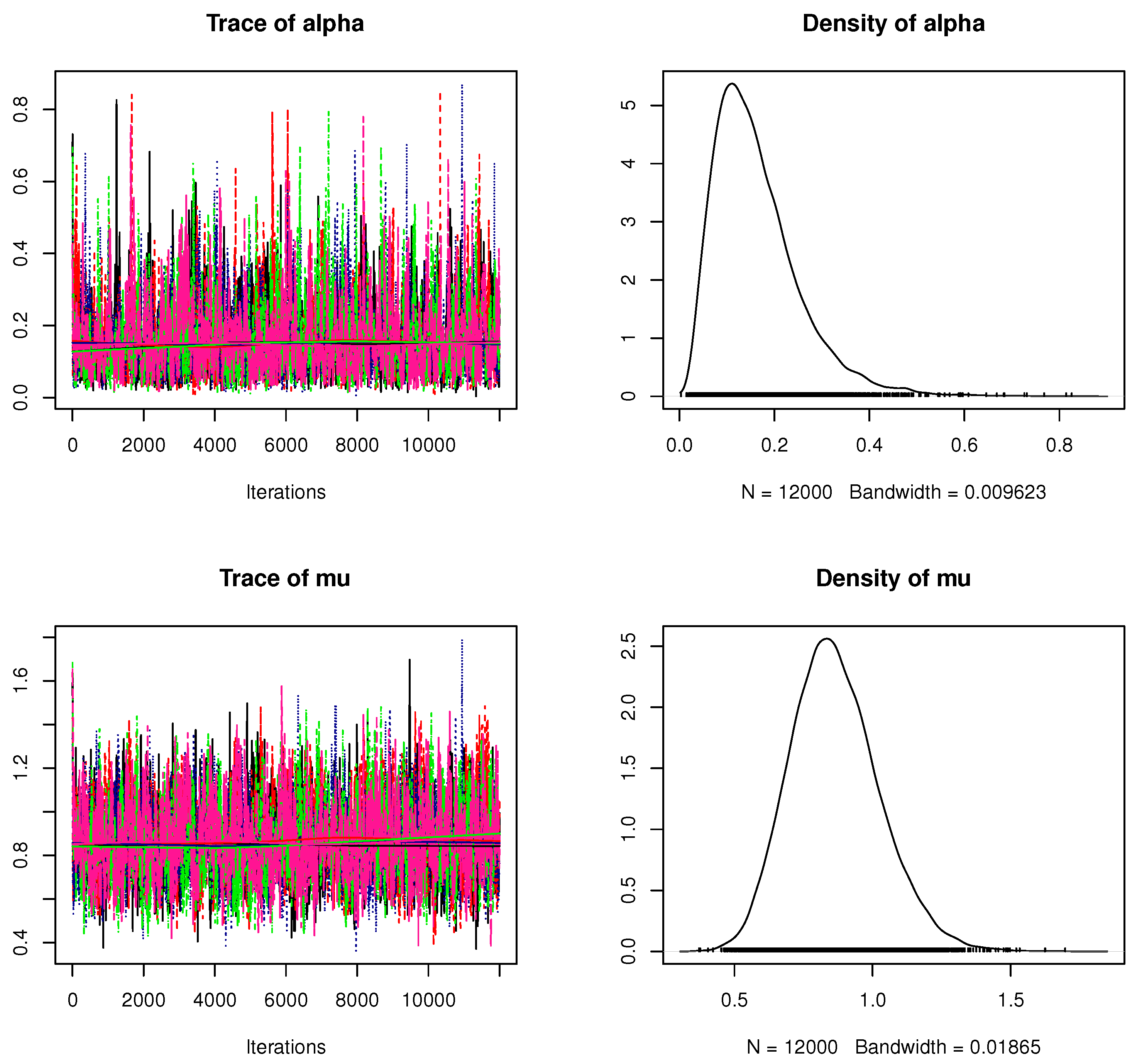
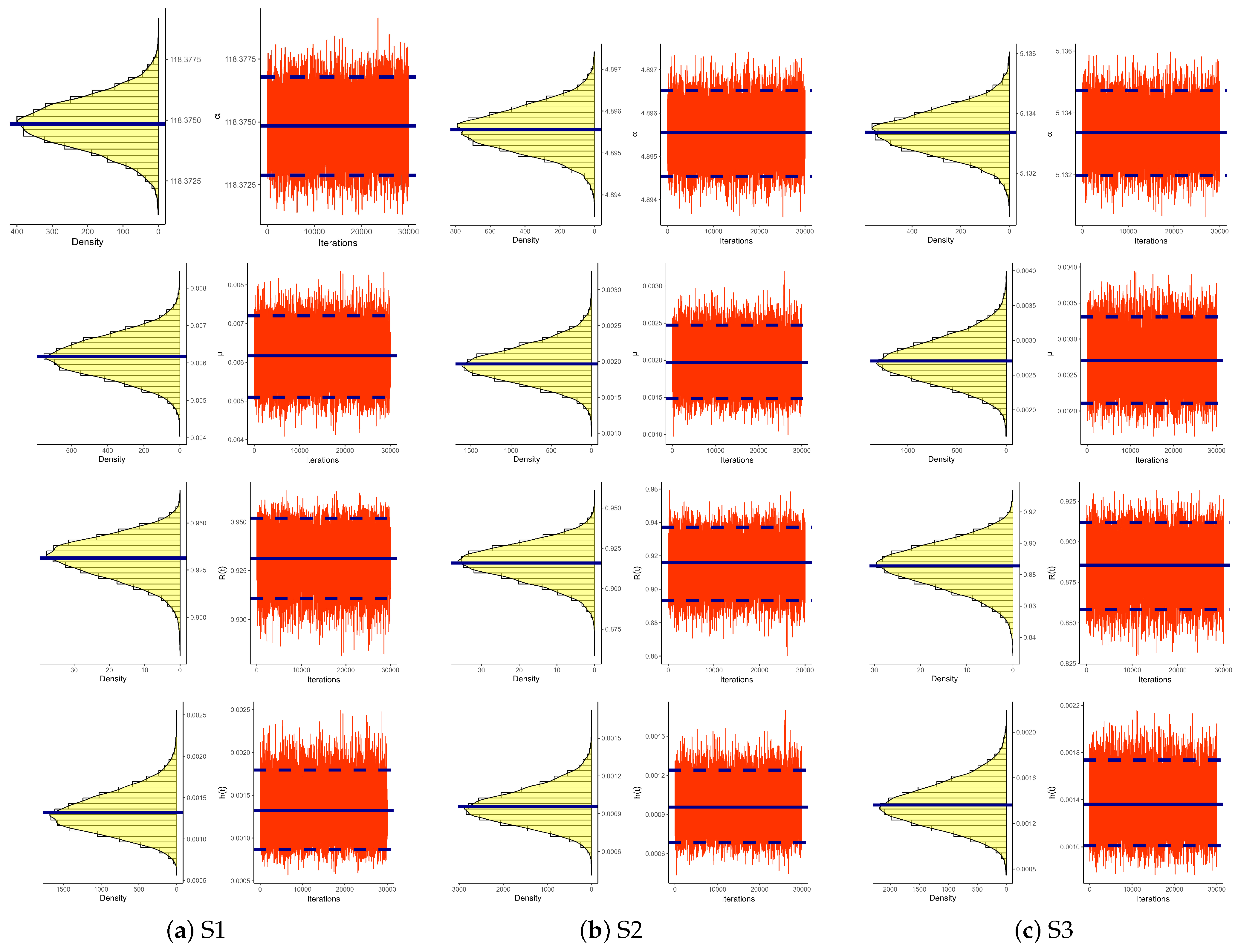
Figure 2 show the suggested convergence (i)–(iii) operators.
Figure 1a demonstrates that the lag autocorrelation inside every chain for every parameter stands for a high mixture of the generated chains and notable convergence for the posterior distribution.
Figure 1b illustrates that there is a little variation in the variance within and variance between the resulting Markov chains. It additionally suggests that raising the quantity of the burn-in data is a successful strategy for reducing the impact of the starting values.
Figure 2 signifies that the developed Markov chains of
,
,
, or
are suitably composite. As an outcome, the furnished point and interval estimations of
,
,
, and
are dependable and acceptable.
Specifically, for the parameter
, the average estimate (Av.E) is expressed as:
where
is the estimate obtained from the
ith sample. The root mean squared errors (RMSEs) and mean absolute biases (MABs) for comparing the various point estimates of
were obtained, respectively, as:
and
The assessment of interval estimates of
is based on their average confidence lengths (ACLs) and coverage percentages (CPs), which are defined, respectively, as:
and
where
indicates the indicator operator and
represent the (lower, upper) boundaries of the
asymptotic (or credible) interval of
. The Av.E, RMSE, MAB, ACL, and CP values for the other parameters can be easily calculated in the same way.
4.2. Simulation Results
A heatmap is a usual approach to displaying information. Colors are used to indicate individual values in a matrix in this tool. Therefore,
Figure 3,
Figure 4,
Figure 5 and
Figure 6 depict the acquired RMSEs, MABs, ACLs, and CPs of the various quantities using the
4.2.2 programming language. Further descriptions of the methods on hand have been outlined on the ’
’ line in
Figure 3,
Figure 4,
Figure 5 and
Figure 6 for concentration, including (for Prior 1 (say P1) as an example) the Bayesian MCMC estimates termed ”MCMC-P1” and the HPD interval estimates mentioned as ”HPD-P1”. In the Supplementary File, the corresponding numerical outcomes of
,
,
, and
are reported.
Figure 3,
Figure 4,
Figure 5 and
Figure 6 show the following findings in regard to the lowest RMSE, MAB, and 95% ACL values, in addition to highest 95% CP values:
The most important part is that the offered estimates of , , , or function adequately.
As n (or FP%) increases, all estimates of , , , and behave satisfactorily. A similar comment is offered when decreases. Therefore, to obtain a better result, we advise increasing the level of n (or FP%) as much as possible.
As increase, the RMSEs, MABs, and ACLs of various quantities decrease, while their CPs increase.
Because of the gamma knowledge, the Bayesian estimates of various parameters outperform alternative estimates, as predicted. The same finding is drawn in the context of HPD intervals.
Because Prior 2’s variance is less than Prior 1’s variance, MCMC simulations using Prior 2 yield greater precision estimates than others for , , , or .
When the proposed schemes A, B, and C are compared, it is discovered that the proposed estimates of and behave better with scheme A and those of , and behave better with scheme C than others.
Therefore, to obtain high-quality estimates of any unknown life parameter in the presence of the proposed censored data, the experimenter must maximize the total test duration while taking into account the total cost of the test.
To sum up, in the context of data acquired through improved adaptive progressive Type-II censoring, implementing a Bayesian framework via Metropolis–Hastings sampling is recommended for estimating the APE parameters or their reliability features.



 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}