
WES-BTM: A Short Text-Based Topic Clustering Model

Abstract
:1. Introduction
2. Literature Review
3. Research Design
3.1. Data Collection
3.2. WES-BTM
3.2.1. Biterms Screening
3.2.2. Model Building
3.3. Contrast Experiment
4. Result and Discussion
4.1. Data Collection and Preprocessing
4.2. Biterm Similarity Calculation
4.3. Parameter Setting
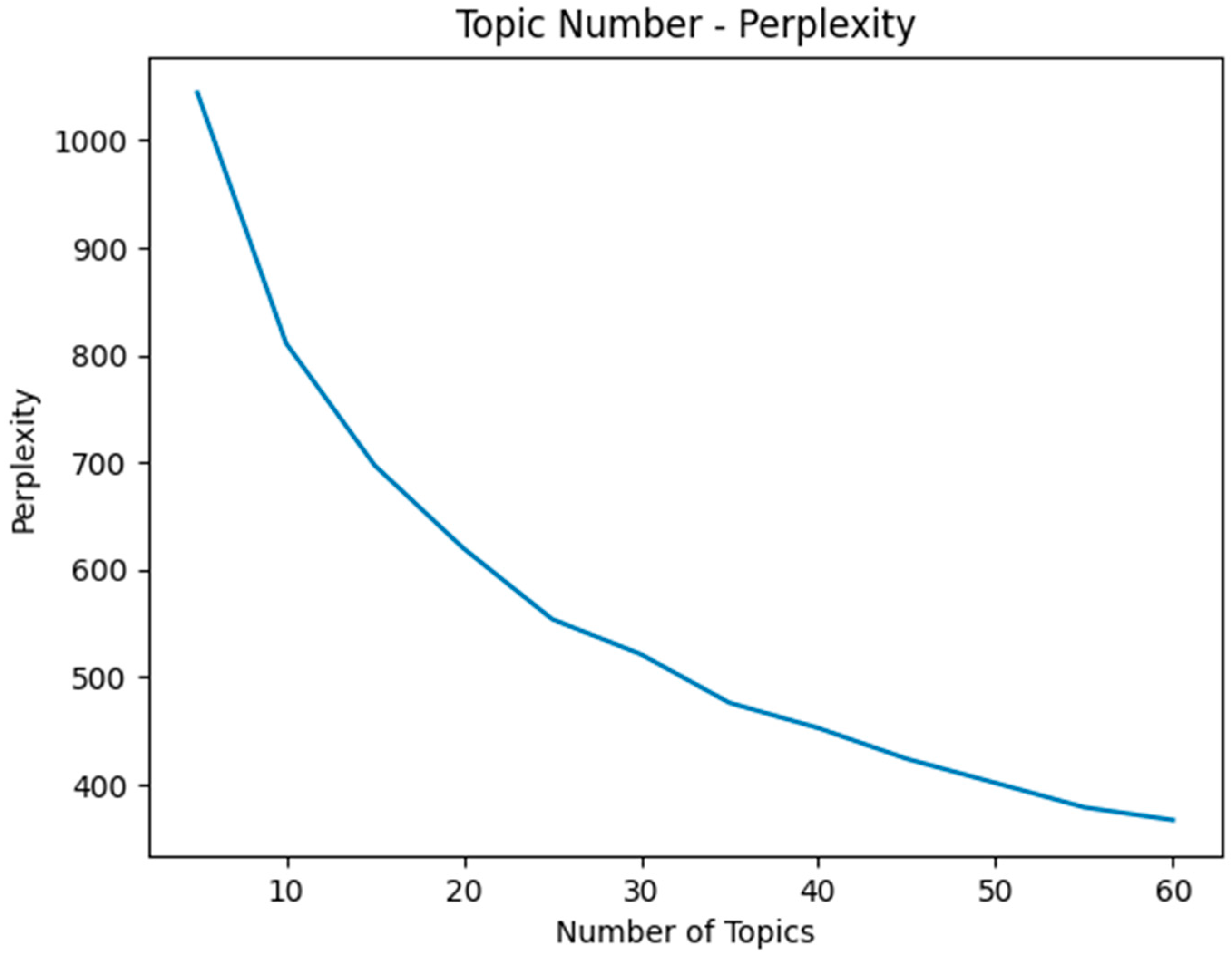
4.4. Optimal Number of Topics
4.5. Topic Model Training
4.6. Results Analysis
4.6.1. Compared algorithms
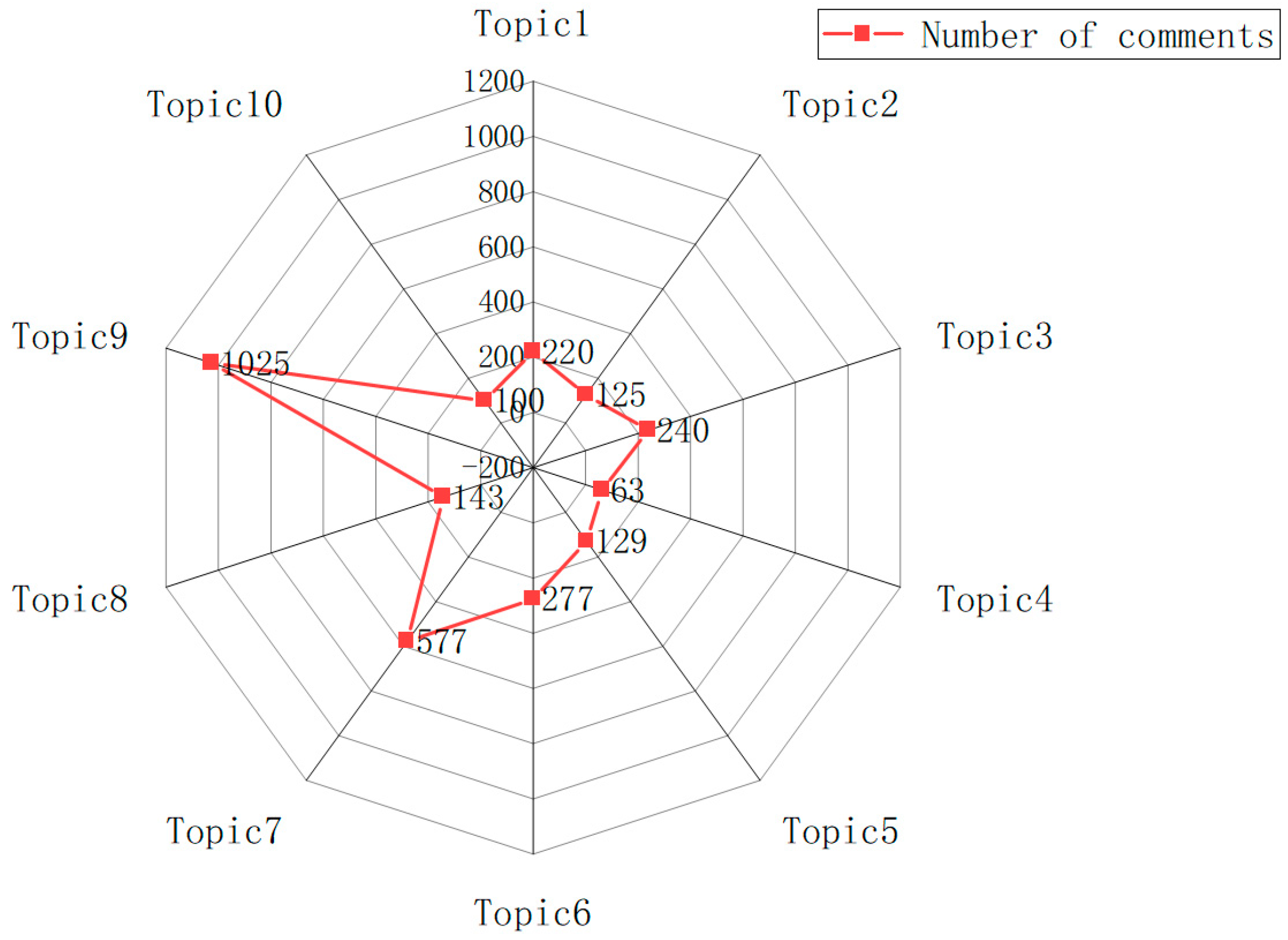
4.6.2. Topic Strength Analysis
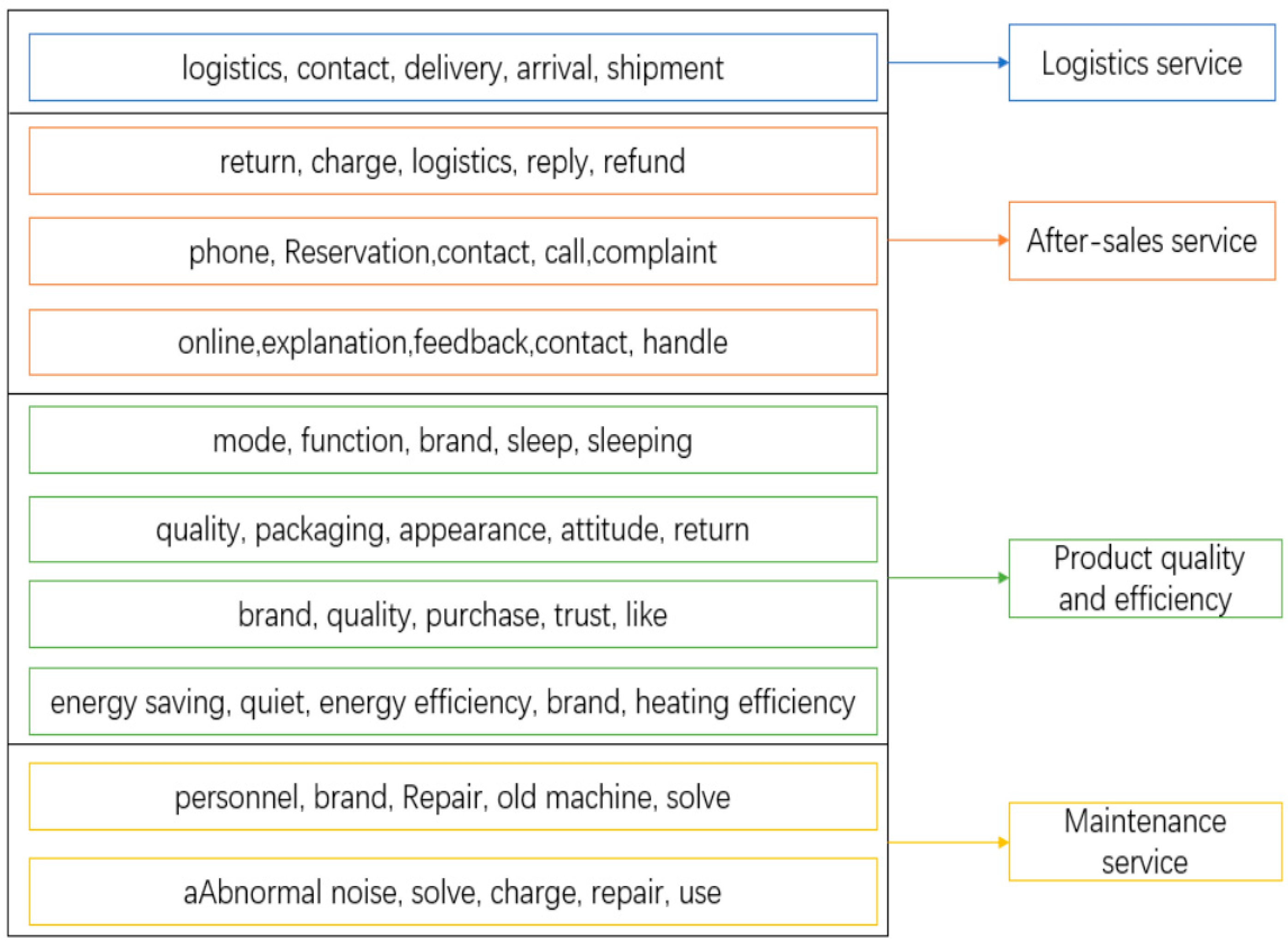
4.6.3. Topic Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lin, T.; Tian, W.; Mei, Q.; Cheng, H. The Dual-Sparse Topic Model: Mining Focused Topics and Focused Terms in Short Text. In Proceedings of the 23rd International Conference on World Wide Web, New York, NY, USA, 7 April 2014; pp. 539–550. [Google Scholar]
- Vulić, I.; De Smet, W.; Tang, J.; Moens, M.-F. Probabilistic Topic Modeling in Multilingual Settings: An Overview of Its Methodology and Applications. Inf. Process. Manag. 2015, 51, 111–147. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Yan, X.; Guo, J.; Lan, Y.; Cheng, X. A Biterm Topic Model for Short Texts. In Proceedings of the 22nd International Conference on World Wide Web, ACM, Rio de Janeiro, Brazil, 13 May 2013; pp. 1445–1456. [Google Scholar]
- Dehak, N.; Dehak, R.; Glass, J.; Reynolds, D.; Kenny, P. Cosine Similarity Scoring without Score Normalization Techniques. 2010. Available online: http://groups.csail.mit.edu/sls/publications/2010/Dehak_Odyssey.pdf (accessed on 1 December 2022).
- Li, K.; Yan, D.; Liu, Y.; Zhu, Q. A Network-Based Feature Extraction Model for Imbalanced Text Data. Expert Syst. Appl. 2022, 195, 116600. [Google Scholar] [CrossRef]
- Gnanavel, S.; Mani, V.; Sreekrishna, M.; Amshavalli, R.S.; Reta Gashu, Y.; Duraimurugan, N.; Srinivasa Rao, N. Rapid Text Retrieval and Analysis Supporting Latent Dirichlet Allocation Based on Probabilistic Models. Mob. Inf. Syst. 2022, 2022, e6028739. [Google Scholar] [CrossRef]
- Qiu, L.; Yu, J. CLDA: An Effective Topic Model for Mining User Interest Preference under Big Data Background. Complexity 2018, 2018, 2503816. [Google Scholar] [CrossRef]
- Deerwester, S.; Dumais, S.; Furnas, G.; Landauer, T.; Harshman, R. Indexing by Latent Semantic Analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Hofmann, T. Probabilistic Latent Semantic Analysis. arXiv 2013, arXiv:1301.6705. [Google Scholar]
- Anwar, W.; Bajwa, I.S.; Choudhary, M.A.; Ramzan, S. An Empirical Study on Forensic Analysis of Urdu Text Using LDA-Based Authorship Attribution. IEEE Access 2019, 7, 3224–3234. [Google Scholar] [CrossRef]
- Tommasel, A.; Godoy, D. Short-Text Feature Construction and Selection in Social Media Data: A Survey. Artif. Intell. Rev. 2018, 49, 301–338. [Google Scholar] [CrossRef]
- Hong, L.; Davison, B. Empirical Study of Topic Modeling in Twitter. In Proceedings of the SOMA 2010—Proceedings of the 1st Workshop on Social Media Analytics, New York, NY, USA, 25–28 July 2010. [Google Scholar] [CrossRef]
- Zhao, W.X.; Jiang, J.; Weng, J.; He, J.; Lim, E.-P.; Yan, H.; Li, X. Comparing Twitter and Traditional Media Using Topic Models. In Proceedings of the Advances in Information Retrieval, Dublin, Ireland, 18–21 April 2011; Clough, P., Foley, C., Gurrin, C., Jones, G.J.F., Kraaij, W., Lee, H., Mudoch, V., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 338–349. [Google Scholar]
- Balikas, G.; Amini, M.-R.; Clausel, M. On a Topic Model for Sentences. ACM Sigir. Forum. 2016, 921–924. [Google Scholar]
- Angelov, D. Top2Vec: Distributed Representations of Topics. arXiv 2020, arXiv:2008.09470. [Google Scholar]
- Grootendorst, M. BERTopic: Neural Topic Modeling with a Class-Based TF-IDF Procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Wu, D.; Zhang, M.; Shen, C.; Huang, Z.; Gu, M. BTM and GloVe Similarity Linear Fusion-Based Short Text Clustering Algorithm for Microblog Hot Topic Discovery. IEEE Access 2020, 8, 32215–32225. [Google Scholar] [CrossRef]
- Park, S.-H.; Song, A.-R.; Park, Y.-H.; Ihm, S.-Y. A Study on Bestseller Short Text Semantics Analysis Using Topic Model. J. Image Cult. Contents 2018, 15, 101–112. [Google Scholar] [CrossRef]
- Niu, W.; Tan, W.; Jia, W. CS-BTM: A Semantics-Based Hot Topic Detection Method for Social Network. Appl. Intell. 2022, 52, 18187–18200. [Google Scholar] [CrossRef]
- Hu, R.; Liu, J.; Wen, Y. SP-BTM: A Specific Part-of-Speech BTM for Service Clustering. In Proceedings of the 2020 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), Exeter, UK, 17–19 December 2020; pp. 1050–1057. [Google Scholar]
- Huang, J.; Peng, M.; Li, P.; Hu, Z.; Xu, C. Improving Biterm Topic Model with Word Embeddings. World Wide Web 2020, 23, 3099–3124. [Google Scholar] [CrossRef]
- Zhou, X.; Ouyang, J.; Li, X. Two Time-Efficient Gibbs Sampling Inference Algorithms for Biterm Topic Model. Appl. Intell. 2018, 48, 730–754. [Google Scholar] [CrossRef]
- Zheng, X.; He, W.; Li, L. Distributed Representations Based Collaborative Filtering with Reviews. Appl. Intell. 2019, 49, 2623–2640. [Google Scholar] [CrossRef]
- Fxsjy/Jieba: Jieba Chinese Word Segmentation. Available online: https://github.com/fxsjy/jieba (accessed on 18 September 2023).
- Gao, J.; Zhang, W.; Guan, T.; Feng, Q. Evolutionary Game Study on Multi-Agent Collaboration of Digital Transformation in Service-Oriented Manufacturing Value Chain. Electron. Commer. Res. 2022, 1–22. [Google Scholar] [CrossRef]
- Li, R.; Jiang, Y.; Yang, W.; Tang, G.; Wang, S.; Ma, C.; He, W.; Xiong, X.; Xiao, Y.; Zhao, E.Y. From Semantic Retrieval to Pairwise Ranking: Applying Deep Learning in E-Commerce Search. In Proceedings of the Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, ACM, Paris, France, 18 July 2019; pp. 1383–1384. [Google Scholar]
- Xin, S.; Li, Z.; Zou, P.; Long, C.; Zhang, J.; Bu, J.; Zhou, J. ATNN: Adversarial Two-Tower Neural Network for New Item’s Popularity Prediction in E-Commerce. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 2499–2510. [Google Scholar]
- Chen, Y.; Visnjic, I.; Parida, V.; Zhang, Z. On the Road to Digital Servitization—The (Dis)Continuous Interplay between Business Model and Digital Technology. Int. J. Oper. Prod. Manag. 2021, 41, 694–722. [Google Scholar] [CrossRef]
- Li, S.; Zhao, Z.; Hu, R.; Li, W.; Liu, T.; Du, X. Analogical Reasoning on Chinese Morphological and Semantic Relations. arXiv 2018, arXiv:1805.06504. [Google Scholar]
- Zhang, D.; Xu, H.; Su, Z.; Xu, Y. Chinese Comments Sentiment Classification Based on Word2vec and SVMperf. Expert Syst. Appl. 2015, 42, 1857–1863. [Google Scholar] [CrossRef]
- Bayesian Networks: Regenerative Gibbs Samplings: Communications in Statistics—Simulation and Computation: Vol 51, No 12. Available online: https://www.tandfonline.com/doi/abs/10.1080/03610918.2020.1839770?journalCode=lssp20 (accessed on 30 March 2023).
- Cao, H.; Kang, J. Study on Improvement of Recommendation Algorithm Based on Emotional Polarity Classification. In Proceedings of the 2020 5th International Conference on Computer and Communication Systems (ICCCS), Shanghai, China, 15–18 May 2020; pp. 182–186. [Google Scholar]
- Wang, X.; Wang, H.; Zhao, G.; Liu, Z.; Wu, H. ALBERT over Match-LSTM Network for Intelligent Questions Classification in Chinese. Agronomy 2021, 11, 1530. [Google Scholar] [CrossRef]
- Mimno, D.; Wallach, H.M.; Talley, E.; Leenders, M.; McCallum, A. Optimizing Semantic Coherence in Topic Models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Scotland, UK, 27–31 July 2011; pp. 262–272. [Google Scholar]
- Ma, Y.; Xiang, Z.; Du, Q.; Fan, W. Effects of User-Provided Photos on Hotel Review Helpfulness: An Analytical Approach with Deep Leaning. Int. J. Hosp. Manag. 2018, 71, 120–131. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Meaning |
|---|---|
| Hyperparameter of Dirichlet distribution for θ | |
| Hyperparameter of Dirichlet distribution for | |
| Topic-specific word distribution | |
| Topic distribution of the whole corpus | |
| Biterms from the multinomial distribution of words | |
| All biterms in the short text corpus | |
| K | Dimensionality of topics |
| Topic selected from multinomial distribution of topics | |
| Similarity threshold |
| Word1 | Word2 | Similarity |
|---|---|---|
| Rest | Online shopping | 0.099184 |
| One-stop | Full process | 0.46240 |
| Door-to-door | Delivered to home | 0.44340 |
| Reliable | Cute | 0.29023 |
| Price Comparison | Cheap | 0.59638 |
| Impact | Repair | 0.20116 |
| Threshold γ | K = 5 | K = 10 | K = 15 | K = 20 | K = 25 |
|---|---|---|---|---|---|
| 0 | −19.2738 | −107.27 | −268.705 | −493.265 | −810.569 |
| 0.1 | −20.4315 | −109.156 | −261.272 | −479.804 | −797.129 |
| 0.2 | −19.1881 | −104.833 | −265.059 | −488.35 | −775.682 |
| 0.3 | −21.9134 | −110.502 | −275.766 | −490.324 | −779.5 |
| 0.4 | −22.2633 | −112.257 | −266.203 | −483.858 | −744.105 |
| Topic | Keywords | ||||
|---|---|---|---|---|---|
| Topic 1 | logistics | contact | delivery | arrival | shipment |
| Topic 2 | return | charge | logistics | reply | refund |
| Topic 3 | mode | function | brand | sleep | sleeping |
| Topic 4 | quality | packaging | appearance | attitude | return |
| Topic 5 | abnormal noise | solve | charge | repair | use |
| Topic 6 | phone | reservation | contact | call | complaint |
| Topic 7 | brand | quality | purchase | trust | like |
| Topic 8 | personnel | brand | repair | old machine | solve |
| Topic 9 | energy saving | quiet | energy efficiency | brand | heating efficiency |
| Topic 10 | online | explanation | feedback | contact | handle |
| Metric | Jensen–Shannon Divergence | Topic Coherence | Perplexity | |
|---|---|---|---|---|
| Model | ||||
| NMF | 0.732260575 | 69.29741217 | 1192.004004 | |
| LDA | 0.726564254 | 69.99972076 | 1225.850567 | |
| BTM | 0.679978854 | 72.62718216 | 816.7186215 | |
| WES-BTM | 0.679495459 | 72.6664798 | 810.5492609 | |
| Topic | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Number | |||||||||||
| 1 | 0.02224 | 0 | 0.00205 | 0.00403 | 0.00487 | 0.0105 | 0.17302 | 0.00519 | 0.03042 | 0.74766 | |
| 2 | 0.10231 | 0.00803 | 0.09877 | 0.01188 | 0.00761 | 0.06512 | 0.4701 | 0.00673 | 0.20856 | 0.02087 | |
| 3 | 0.06096 | 0.00648 | 0.01792 | 0.00541 | 0.01029 | 0.01544 | 0.72332 | 0.00081 | 0.15876 | 0.0006 | |
| … | |||||||||||
| 2898 | 0.11855 | 0.01644 | 0.03072 | 0.00149 | 0.02322 | 0.05286 | 0.10575 | 0.0031 | 0.64223 | 0.00565 | |
| 2899 | 0.04238 | 0.04128 | 0.03361 | 0.0012 | 0.00272 | 0.01534 | 0.02914 | 0.00877 | 0.75504 | 0.07053 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Gao, W.; Jia, Y. WES-BTM: A Short Text-Based Topic Clustering Model. Symmetry 2023, 15, 1889. https://doi.org/10.3390/sym15101889
Zhang J, Gao W, Jia Y. WES-BTM: A Short Text-Based Topic Clustering Model. Symmetry. 2023; 15(10):1889. https://doi.org/10.3390/sym15101889
Chicago/Turabian StyleZhang, Jian, Weichao Gao, and Yanhe Jia. 2023. "WES-BTM: A Short Text-Based Topic Clustering Model" Symmetry 15, no. 10: 1889. https://doi.org/10.3390/sym15101889