1. Introduction
With the continual development of the Internet and computer technology, network security issues are becoming increasingly important. Phishing attacks, which involve using fake websites to deceive users into obtaining their private information, cause significant losses to Internet users, financial institutions, and e-commerce companies [
1]. The adversaries involved usually obtain domain names and build fake webpages that are replicas of legitimate websites [
2]. Users access phishing websites via links sent by attackers and are often fooled into giving out such private information as their account passwords. According to the Anti-Phishing Working Group’s (APWG) report for the second quarter of 2022, the number of phishing attacks more than quadrupled compared with early 2020 and reached 1,097,811 in June 2022. This was the highest monthly total in the history of the APWG’S reporting [
3]. Thus, it is important to investigate methods to identify phishing websites.
Most Internet browsers currently in use have a function for blocking phishing websites. Filtering based on black-and-white lists of websites is one of the most widely used ones [
4]. However, blacklist filtering methods are becoming increasingly ineffective due to the growth in the types and numbers of phishing websites as well as improvements in technology. Phishing websites usually imitate the structure of legitimate webpages to deceive users. To make the deceit even more confusing, phishing websites also use domain- name-generation algorithms, using dates, popular search terms, and other specific transformations to generate fake domain names for registration [
5]. The methods of counterfeiting commonly used in the domains of phishing websites include character deletion, character duplication, sequence exchange, and character substitution [
6,
7].
Most methods to identify phishing websites use rich and easily recognizable features of webpages [
8]. However, these features are too complex for the real-time detection of a large number of domain names. Although domain-name-generation algorithms are different, the overall idea of domain-name generation is similar, and the features extracted by the neural network model for different kinds of DGA domain names have certain symmetry and generality, which can effectively identify counterfeit domain names [
9]. To cope with the increasing number of phishing activities, adapt to their current technological methods, and thus improve the efficiency of detection of phishing websites, this paper proposes a model based on LightGBM and domain names. The key contributions of this work are as follows:
(1) By considering the task of identifying phishing websites using a two-category processing model, we detail a framework to detect them.
(2) We explain the process of identifying phishing websites by using features of the domain name of the target website, and provide a method to optimize the model to ensure high detection accuracy.
The remainder of this article is structured as follows:
Section 2 describes the current research on identifying phishing websites, and
Section 3 details the proposed method. The results of experiments and an analysis of the proposed approach are given in
Section 4, and the conclusions of this study are presented in
Section 5.
2. Related Work
To confuse users, phishers generally imitate the URL of the target website to produce a phishing URL; stable features of the legitimate website, such as the URL’s statistical feature, the webpage code feature, and the webpage text feature, will inevitably be disrupted [
10,
11]. Therefore, the current solution for the identification of most phishing websites is to first use a feature-extraction algorithm to extract the features of legitimate websites (the extracted features are usually symmetrical and universal) and then apply these features symmetrically to accurately identify phishing websites [
12,
13,
14].
Based on the context and the density of the keywords, Altay et al. used three machine-learning-based methods to extract and analyze the features of words on pages to improve the accuracy of the detection of counterfeit pages [
15]. Fang et al. extracted the images and characters from phishing websites and used the Monte Carlo algorithm to train a classification model to precisely identify phishing websites [
16]. Chen et al. divided phishing websites into three categories based on similarity, used the wHash and SIFT mechanisms to evaluate website similarity, and used the Microsoft website dataset to test performance in terms of detection accuracy [
17]. Cersosimo et al. used the Splunk Machine Learning Toolkit to detect malicious domains [
18]. Phishing websites can be accurately identified by using the features of webpages, but this is not suitable for real-time detection and the identification of many domain names. To be more confusing to users, phishing websites often use strings similar to those of the corresponding legitimate websites as domain names.
Researchers have built models of detection according to the characteristics of characters used in phishing websites. Feroz et al. used the chi-square statistic and methods to assess the gain in information to extract 16 features of the vocabulary, including two-letter combinations and host-based features. They then used a machine-learning algorithm in Mahout to establish a reliable online learning framework to classify URLs. The results of K-fold cross-validation showed that the classifier is flexible [
19]. Chatterjee et al. introduced a phishing detection technique based on deep reinforcement learning to identify phishing URLs. They used their model on a balanced, labeled dataset of benign and phishing URLs, extracting 14 hand-crafted features from the given URLs to train the proposed model [
20]. Mvula et al. applied malicious domain name detection to COVID-19 and realized the classification of COVID-19 malicious domain names [
21]. Liu et al. proposed a method based on the generalized Levenshtein distance to measure the visual similarity between domain names and applied the minimum line-of-sight method of search based on triangle inequality and the locally sensitive hashing algorithm to improve its efficiency of searching [
22]. Zouina et al. proposed a lightweight method of detection that is based entirely on URLs and that extracts six URL features. It used the SVM algorithm and recorded an accuracy of 95.80%. This method can be integrated into smartphones and tablets because of its resource efficiency [
23]. Ozgur used a large amount of data from phishing and legitimate websites to propose a real-time anti-phishing system. The features used by the system included NLP features, word vectors, and hybrid features. The author compared seven NLP functions. The machine-learning classification algorithm found that the random forest algorithm based on NLP features delivered the best performance, with an accuracy of 97.98% [
24]. Wang et al. analyzed the differences between the URLs of phishing websites and legitimate websites, defined primitives and sensitivity to describe the characteristics of the language used, calculated the similarity among the primitives of domain names, and then used the random forest algorithm to learn features of the language of the sub-domains to classify URLs. The algorithm had an accuracy of 95.6% and an average recognition time shorter than 1 s [
25]. Yuan et al. proposed an improved BiGRU-Attention model that classified phishing websites based on the characteristics of the characters in their URLs. The model adequately learned the vector representing the domain name information and recorded an accuracy for classifying phishing websites at 99.55% [
26].
In addition to features of the characters of the domain name, features such as WHOIS information play an important role in the detection of phishing websites. Sun Dandan extracted three kinds of features of phishing websites: lexical features, WHOIS features, and page-related features. The author proposed a brand-name-anomaly algorithm based on the edit distance to improve the J48 algorithm, based on Weka as a model to classify the features of URLs [
27]. Aung et al. proposed a phishing-URL-detection model that used information-rich domain and path features [
28]. They split URLs into two parts, domain and path, and assume that URL patterns in the domain are less random than those in the path. The domain part consists of the URL components until the end of the domain name, whereas the path part includes the rest of the URLs until the non-alphanumeric character. To reduce the false-alarm rate in the model for the identification of phishing websites based on machine learning, Alsariera et al. proposed three meta-learner models based on the forest penalty attribute algorithm. A weight-adjustment strategy was included in the model to construct an efficient decision tree. The lowest accuracy of the three models was 96.26%, the FAR value was 0.004, and the ROC value was 0.994 [
29]. Mehanovic et al. used three K-nearest neighbor classifiers, a decision tree, and random forest to classify the features of websites obtained by the Weka feature selection method. This reduced the number of features used, thereby improving the model’s classification efficiency. The time needed for classification was reduced from 2.88 s to 0.02 s, and the model recorded an accuracy of classification of 100% [
30].
To avoid detection and blocking, phishing websites continually change their characteristics [
31]. Some phishing websites generated by using the GAN network can avoid detection [
32]. A model to identify such sites thus needs to be able to adapt to ensure the security of the network environment [
33]. Altyeb proposed an intelligent ensemble learning approach for phishing website detection based on weighted soft voting to enhance the detection of phishing websites [
34]. However, the time complexity of the detection method was not discussed.
Oram et al. proposed a LightGBM-based model for the identification of phishing websites [
35]. The proposed model showed high performance accuracy and proved to be a robust approach for phishing activity. Li et al. proposed a stacking model combining the Gradient Boosting Decision Tree, XGBoost, and LightGBM algorithms to detect phishing web pages [
36]. The authors extracted features from the URL and Hypertext Markup Language (HTML) of the suspicious website. The extracted features contained 8 URL- and 12 HTML-based features to generate a feature vector. The vector was fed to the stacked model for classification and achieved an accuracy of 97.30%. Chen et al. propose a graph-based cascade-feature-extraction method based on transaction records and a lightGBM-based Dual-sampling Ensemble algorithm to detect phishing accounts based on blockchain transactions [
37]. In the phishing website detection problem, we found that LightGBM was more efficient; thus, we selected it as our classification model.
3. Methodology
3.1. Framework of the Model
We extracted features of the domain name and used machine learning methods to implement our model to identify phishing websites.
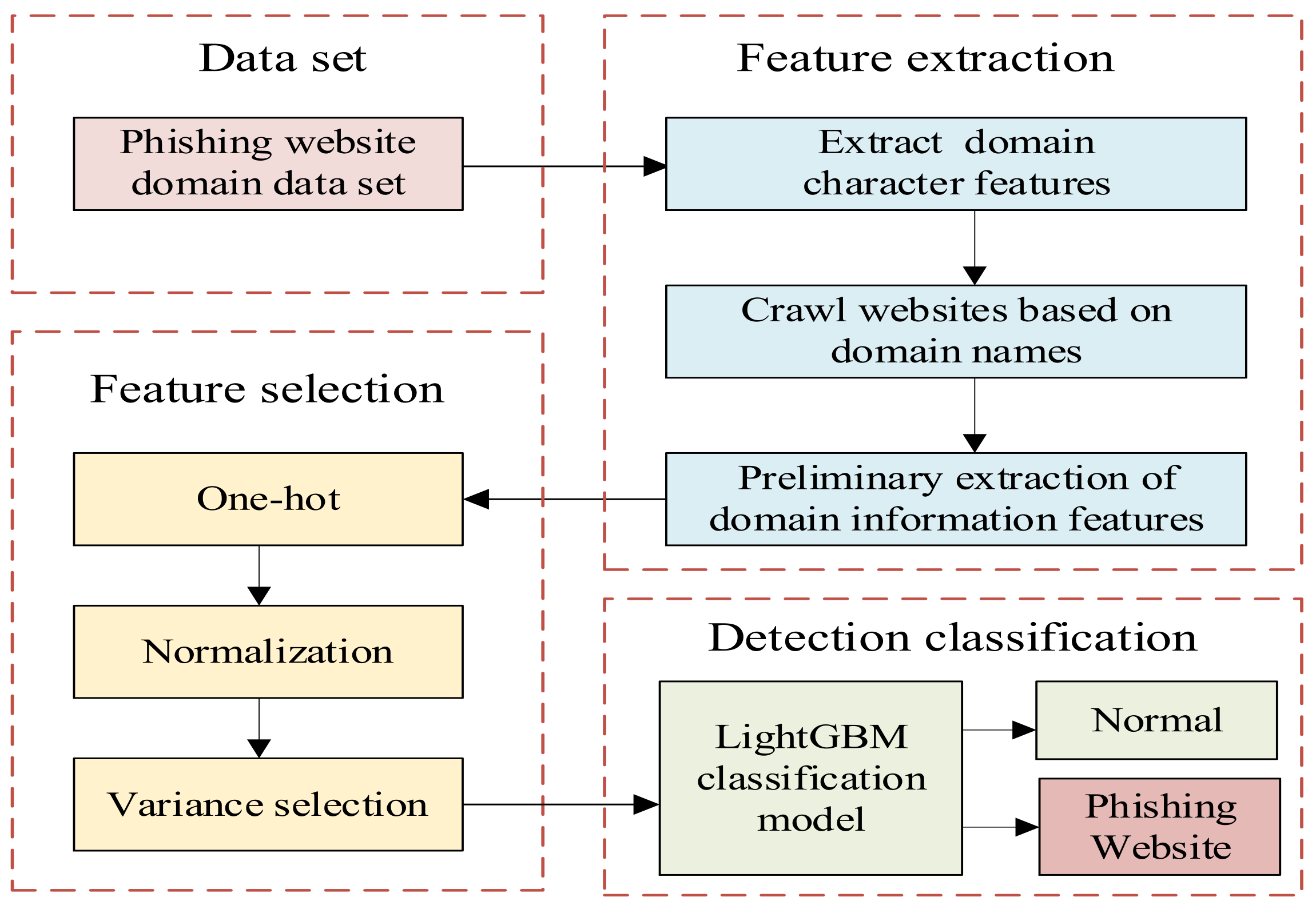
Figure 1 shows the overall framework.
The model is divided into four steps:
Step 1: Domain name dataset pre-processing. The domain name dataset that was used comes from the data published by the PhishTank website and the Alexa website. After obtaining the domain name data, clear the invalid data and check the duplicate of the two domain name datasets.
Step 2: Domain name feature extraction. Through the analysis of counterfeit domain names, two self-owned characteristics of domain names in the domain name dataset are extracted. The first feature is the domain name character feature. According to the character arrangement of domain names of phishing websites and normal websites, the model selects features that may improve the classification effect for extraction and preliminarily screens them according to the classification effect. In addition, in order to further improve the classification accuracy, this model adds domain name information features on the basis of domain-name character features. Domain name information features refer to the IP address and filing information of the domain name. Based on the domain name dataset, write a crawler program to crawl and query the domain name information published by the website, and further process the crawled data to obtain the domain name information characteristics. After that, the two types of features are integrated to obtain a feature dataset.
Step 3: Domain name feature selection. The features of different domains were relatively discrete, and there was no correlation between them. In addition, they cannot be inputted into the machine learning model LightGBM for training in the form of vectors. Thus, one-hot encoding was used to map the features into a computer-readable feature matrix and regularization was performed on them. One-hot encoding mainly used N-bit status registers to encode N states. Each state had an independent register bit, and only one bit was valid at any time. However, the existence of a large number of irrelevant, redundant or noisy features will not only bring about the problem of increasing the dimension but also directly affect the performance of the classifier. Therefore, in order to ensure the accuracy of the classification model and improve the classification efficiency, a variance selection method was used to filter the feature matrix. By changing the parameters and conducting experiments for many times to determine the variance filtering threshold, more representative and comprehensive features of domain can be obtained.
Step 4: LightGBM recognition classification. The obtained domain name features are passed to LightGBM classifier for training, and finally the phishing website classification model is obtained, and the website classification results are output.
3.2. Feature Analysis
The features of the domain name used here can be obtained only by using known strings of domain names without obtaining information related to user privacy, such as traffic in the network. Features of the domain name can be divided into two categories according to the acquisition method: features of the characters used in the domain name and features of information on the domain name. The features of information on the domain name can be obtained through the corresponding website or other query websites to this end, whereas the features of the characters used in the domain name can be obtained through a local feature-extraction algorithm without visiting the website.
3.2.1. Features of the Characters Used in the Domain Name
Table 1 lists the domain names used by typical phishing websites. An analysis of the differences between the domain names of the phishing websites and the corresponding legitimate websites led to a total of 10 features of the characters used in the domain name in four categories. The four types of features were N-gram features, quantitative and matching features, maximum segmentation-related features, and edit distance.
There are certain differences between the character sequence of the domain name of a phishing website and that of a legitimate site. The N-gram feature can reflect this difference well. N-gram is a method of coding that is commonly used in natural language processing [
38,
39]. If the length of the text is
l, the N-gram method can divide it into
l+1−N continuous N-tuples, thereby retaining information on the word order of the text. The domain names of phishing websites may lead to extracted sequences that have a low probability of appearing in the domain names of legitimate sites. However, as N continues to increase, the feature vector space continues to increase as well, such that the feature matrix becomes increasingly sparse. Principal component analysis is used to reduce the dimensionality of the N-gram feature matrix and improve the model’s classification efficiency.
The ratios of character composition, top-level domain names, and sensitive matching words of domain names of phishing websites are also different from those of the domain names of legitimate sites. The proposed model extracts vowels, numbers, single characters, and special characters from the domain name. Because domain names with shorter strings are easier to remember, they can be more easily registered early on given that the number of character combinations is small. A phishing website can usually register only a longer domain name. The hierarchical characteristics of the domain names are also extracted by the model because some domain names of phishing websites are disguised as those of legitimate websites by adding sub-domains to them. To steal users’ identity and account information, the domain names of phishing websites may contain sensitive words such as “login” or “verify.” The feature-extraction step involves extracting information on whether the domain name contains such sensitive words. Different top-level domain names have different costs of registration and requirements of registrants. Some domain names of phishing websites often use cheap top-level domain names for registration and insert such strings as “com” into the domain name to give the illusion of being a well-known domain name with which users are familiar. The model thus extracts the characteristics of well-known domain names, including their type and location.
The smallest meaningful linguistic unit in English is called a morpheme. Phishing websites can construct their own domain names through word patching or by exploiting users’ misspellings. The proposed model thus extracts the characteristics of morphemes used in the domain name as well. The steps of the extraction algorithm are shown in
Figure 2. The final extracted features include the minimum number of divisions of the domain name, the length of each part of the division, and the ratio of misspellings.
The smallest number refers to the number of letters in a word for the match to be as long as possible if the domain name is divided into readable parts; for example, in the case of a domain name for
www.southvalleypeacecenter.org” (accessed on 18 June 2022), after break up, this domain is broken up into “WWW”, “south”, “valley”, and “peace”. The minimum partition number of “center” and “org” is six. Here, the length of each segment is denoted as {3, 5, 6, 5, 6, 3}.
To masquerade as a legitimate website, phishing websites generate domain names by adding, deleting, and replacing characters based on the domain names of legitimate sites. The proposed model thus extracts the Levenshtein distance of the domain names. This refers to the minimum number of single-character editing operations required to convert domain name “a” into “b”. It reflects the likelihood of the test domain name being a counterfeit of the domain name of a legitimate website. The Levenshtein distance between domain names a and b can be described by Formula (1):
where
refers to the distance between the first
i characters of
a and the first
j characters of
b.
Counterfeit domain names usually maintain a small editing distance from normal domain names. When the length of domain names is short, such as “qq.com”, the editing distance between it and other short domain names is also small. If the similarity-related feature of domain name editing distance is only used for judgement, normal domain names with short domain names will be misjudged as counterfeit domain names. Therefore, this feature must be combined with domain name length characteristics.
By analyzing the difference between fake domain names and legitimate domain names, 10 characters of domain names in four categories are extracted. The four types of features are the N-gram feature, quantitative feature and matching feature, maximum segmentation correlation feature, and edit distance feature.
3.2.2. Features of Information on the Domain Name
The domain name of the website contains a large amount of information, such as WHOIS information and filing information. This can be used to determine the registration-related background of the domain name to infer the credibility of the website. WHOIS information is used to check whether a domain name is registered. If it is, detailed information on it, including the registrar, owner, registration date, and expiration date can be obtained.
Ip138.com (accessed on 18 June 2022) and
ip.tool.chinaz.com (accessed on 18 June 2022) provide a query service for information on domain names. We used Python to write a crawler to obtain information on domain names provided by these websites for the dataset of domain names. The steps of information extraction are shown in
Figure 3.
We set a cookie and visited the relevant website to obtain the source code of the query page. We analyzed the structure of the source code to find fields containing information on the domain name. According to the different formats of the fields, we used the Beautiful Soup HTML parser and regular expressions to separately match each field to crawl information on the domain name. The information initially obtained by the crawler contained 12 items: IP address, physical location, registrar, person to contact, contact email, contact number, update time, creation time, expiration time, company, Domain Name Server, and filing information.
Because the attacker may have registered multiple domain names simultaneously, the location-related information of these domain names may be similar. WHOIS information is often missing in the registration information of domain names of phishing websites. The completeness of such information as the names of human contacts and their telephone numbers can thus be used to verify the security of the relevant domain name to some extent. Similarly, the presence of registration information may reflect the security of the domain name. Because they are frequently blocked by security personnel, phishing websites often need to change their domain names or IP addresses. Many phishing websites have a short duration of registration, which has thus become a factor in identifying phishing websites. We also analyzed and sorted the information obtained by the crawler program.
The final features of information on the domain name include address-related information, complete WHOIS information, time-related information, and filing information.
3.3. LightGBM
LightGBM is an additive model composed of multiple trees [
40]. The model uses the negative gradient of the loss function to replace the residuals as the basis for generating a decision tree. While ensuring classification accuracy, it has a high training speed, takes up little memory, and can handle large-scale data. For a given dataset, the LightGBM model and its objective function are as follows:
where
is the decision tree,
is the predicted value,
is the loss function,
is the first derivative of the loss function,
is its second derivative, and
is a regular term used to express the complexity of the model.
To optimize the objective function, the regular term is expressed as:
where
is the number of leaf nodes of the tree and
is the output of each leaf node.
The objective function is then rewritten as an expression related to
and
. We take the partial derivative of the objective function with respect to
. If its derivative is zero, the objective function yields the minimum value. We define the sample set on each leaf node
as
and substitute the obtained value of
into the objective function. The result is as follows:
where
,
.
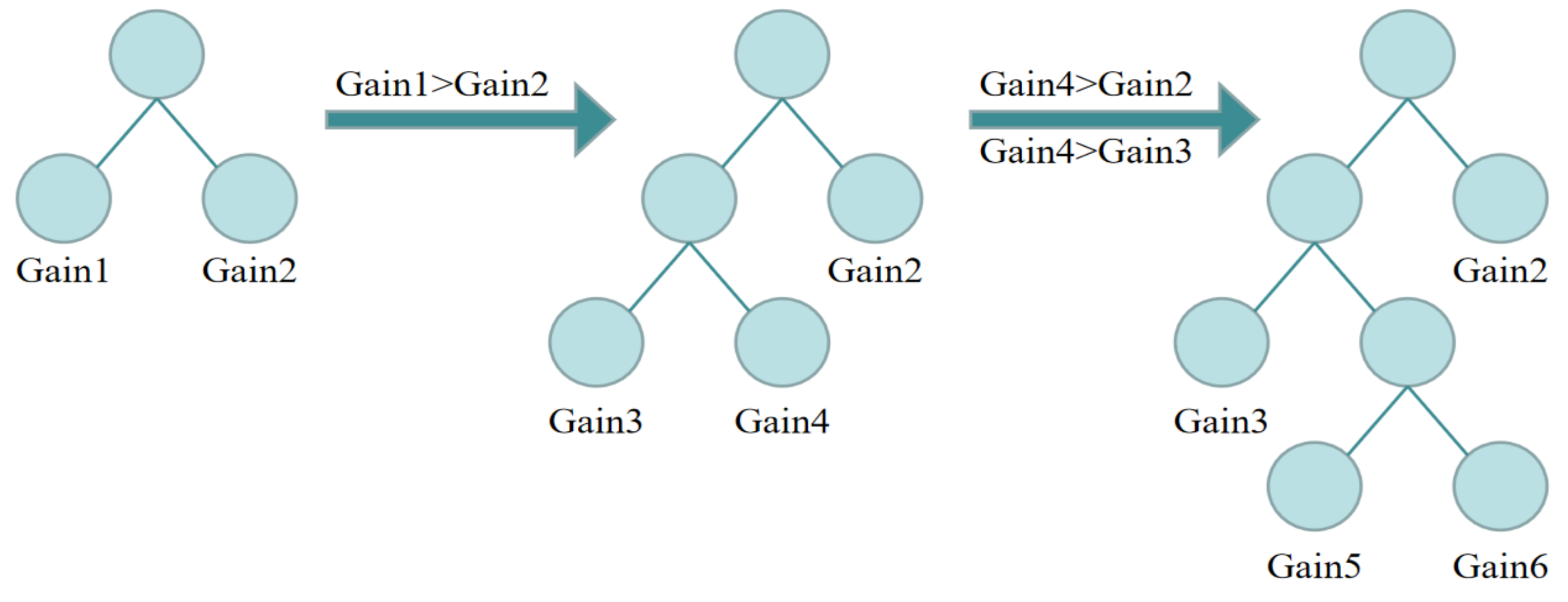
Compared with the level-wise method, the leaf-wise method adopted by LightGBM makes tree generation more efficient. As shown in
Figure 4, the node with the largest split gain among the leaf nodes is selected as the next split leaf node until the decision tree has grown appropriately. When splitting the tree the same number of times, the leaf-wise method can reduce errors and improve accuracy to a greater extent than the level-wise method. However, it can make the decision tree too deep, resulting in overfitting. Therefore, LightGBM adds a maximum depth limit to prevent overfitting while ensuring high efficiency.
LightGBM uses histogram optimization to divide continuous values into a series of discrete domains to simplify the expression of the data and reduce the required memory. Histogram regularization also enables the model to avoid overfitting and yield better generalization results.
To reduce the size of the dataset and the feature set, LightGBM uses two algorithms: gradient-based one-sided sampling (GOSS) and exclusive feature bundling (EFB). GOSS uses samples with large and small gradients to calculate the information gain while remaining as consistent as possible with the overall data distribution and ensuring that samples with small gradient values are trained. EFB bundles mutually exclusive features to reduce the number of feature dimensions and improve computational efficiency. The conflict ratio can be used to measure the degree of non-exclusion of two features that are not completely mutually exclusive.
5. Conclusions
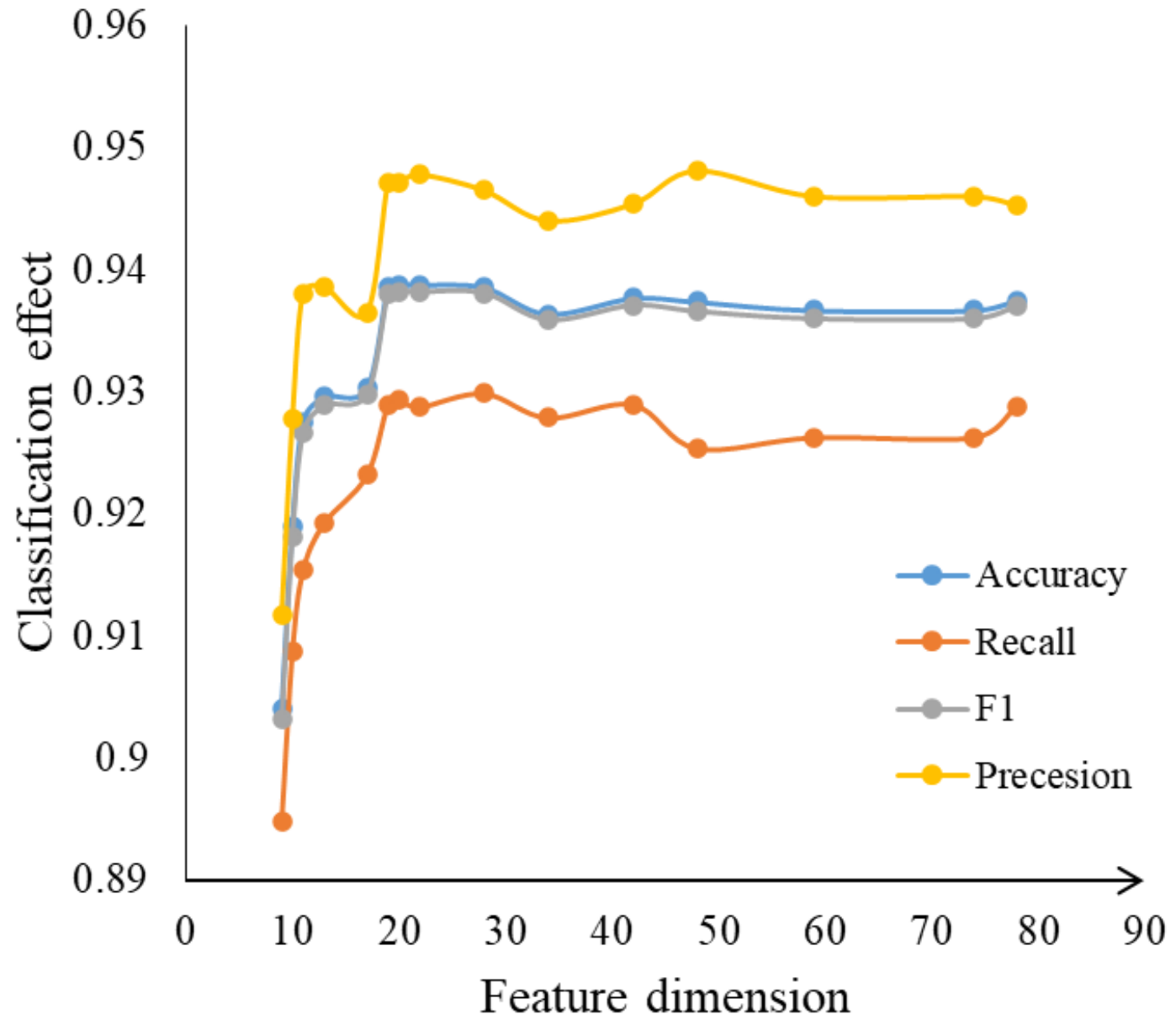
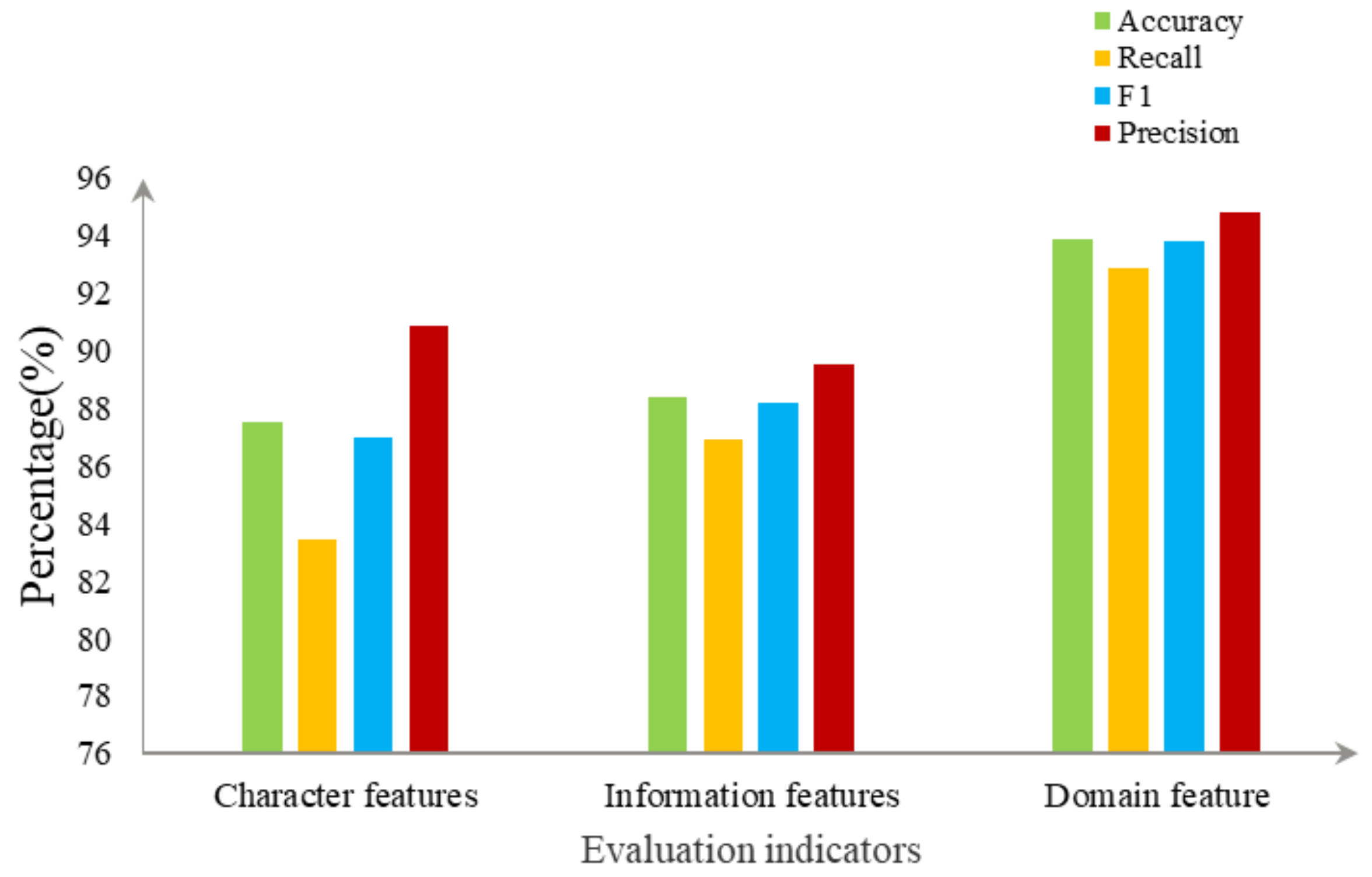
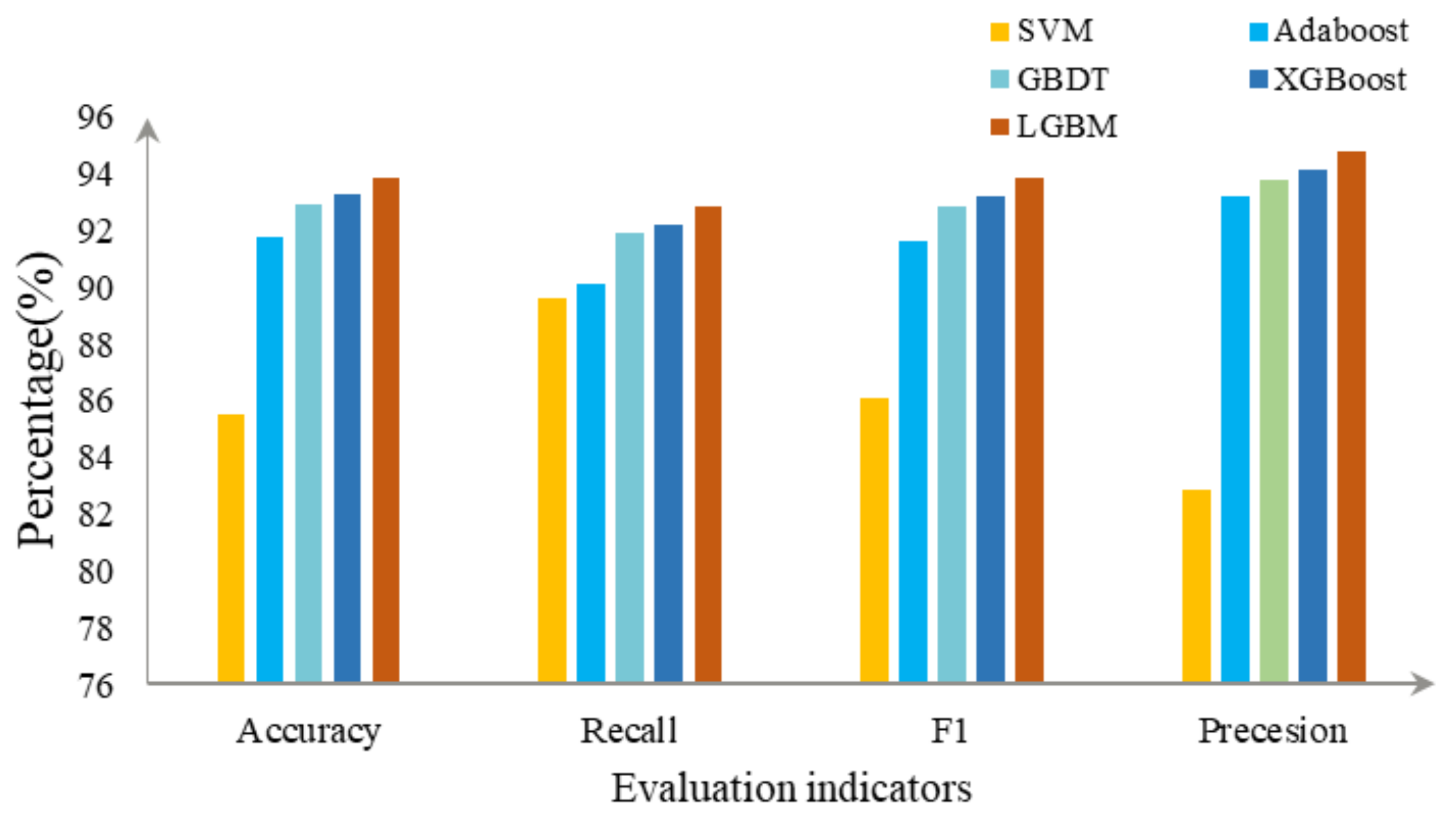
According to the symmetry of domain name features, this paper proposes a phishing website recognition model based on LightGBM. We tested the model on data from PhishTank for testing. The features of the domain names of phishing websites were divided into features of the characters used in the domain name and features of information on the domain name and were extracted separately. Once they had been filtered, 16 features of the domain name were finally selected for model training. The grid-search method was used during training to optimize the parameters of the LightGBM model. We compared the performance of different models with the proposed one. The results showed that the model that used features of the domain name for training was significantly superior to the model that used only a single feature for training, with increases of 5% in terms of accuracy, precision, recall, and the F value. The proposed LightGBM model also outperformed the GBDT, AdaBoost, XGBoost, and SVM models.
The proposed phishing website recognition method extracts features manually according to experience. In future work, neural networks and other methods can be used as alternatives to reduce the manual workload in the model construction process and improve the method’s automation.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}