
Few-Shot Learning for Fault Diagnosis: Semi-Supervised Prototypical Network with Pseudo-Labels


Abstract
:1. Introduction
- (1)
- We used kernel principal component analysis to reduce the dimension of the feature space, which avoid redundant information embedded in the feature space reducing the generalization ability of the model;
- (2)
- We used apseudo-label-prediction algorithm to generate labeled samples, aiming to increase the labeled samples, which fully uses the unlabeled samples for training the prototype networks to avoid overfitting;
- (3)
- We adopted predicted pseudo-label data to fine tune the prototype network parameters, which can reduce the time required for adjusting the model parameters and improves diagnostic accuracy.
2. Theoretical Background
2.1. Few-Shot Learning
2.2. Prototypical Network
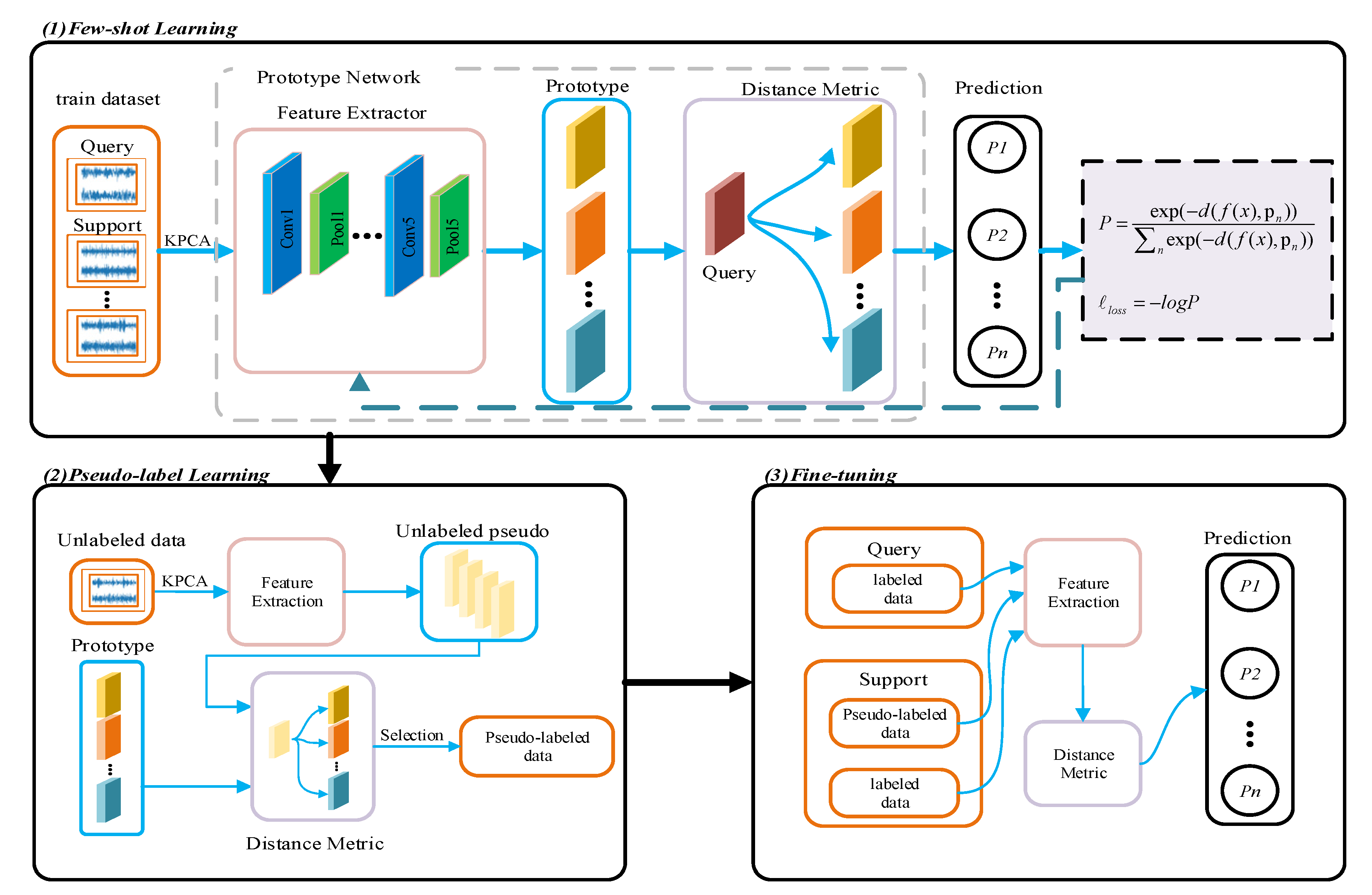
3. Proposed Method
3.1. KPAC
3.2. Metric and Query
3.3. Description of Proposed Method
| Algorithm 1: PSSPNlearning strategy |
| Input: Labeled dataset , unlabeled dataset , number of fault classes , support set with samples query set with Q samples, feature extractor episode, and epoch. |
Output: learnable parameter
|
4. Results and Discussion
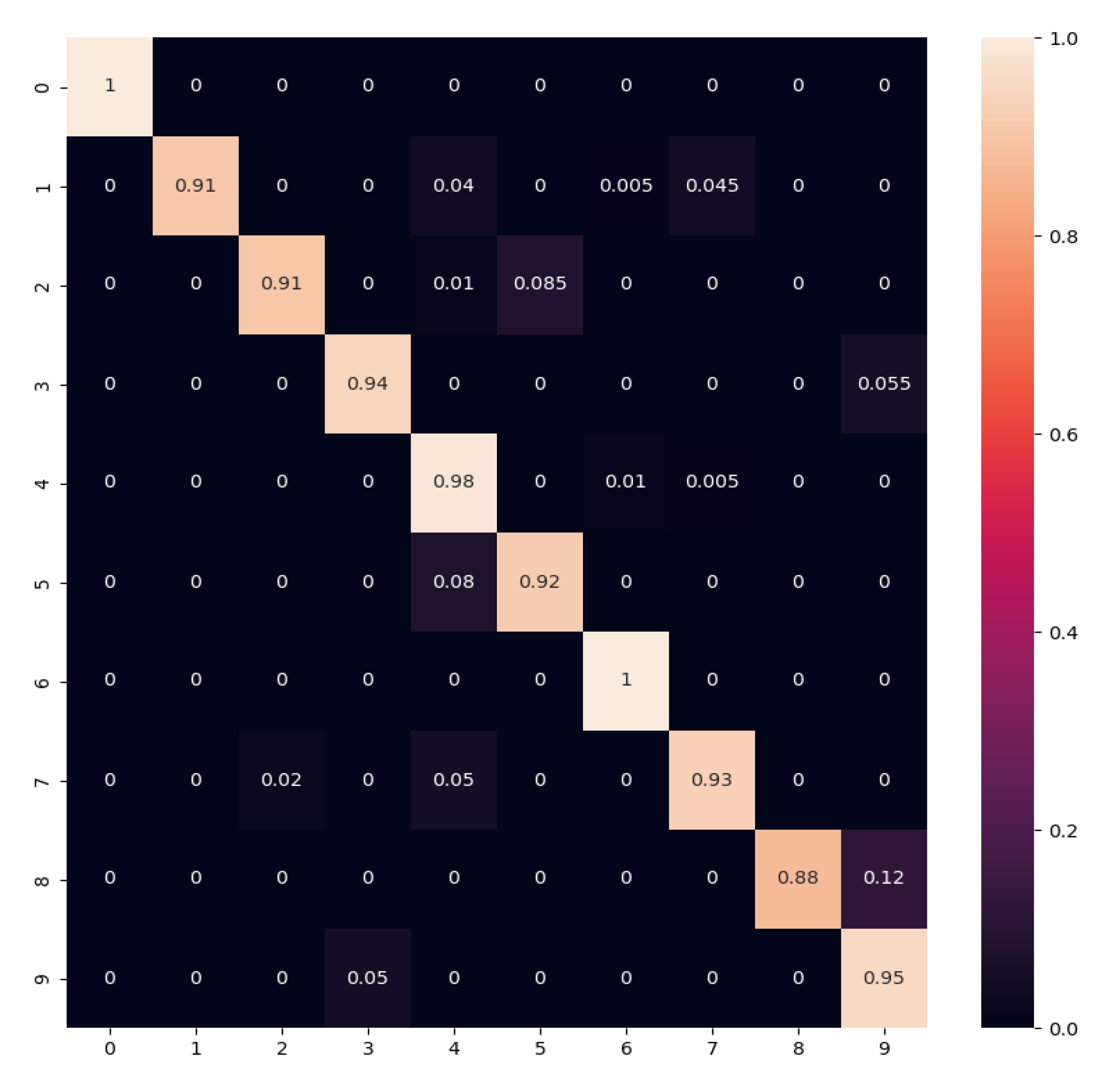
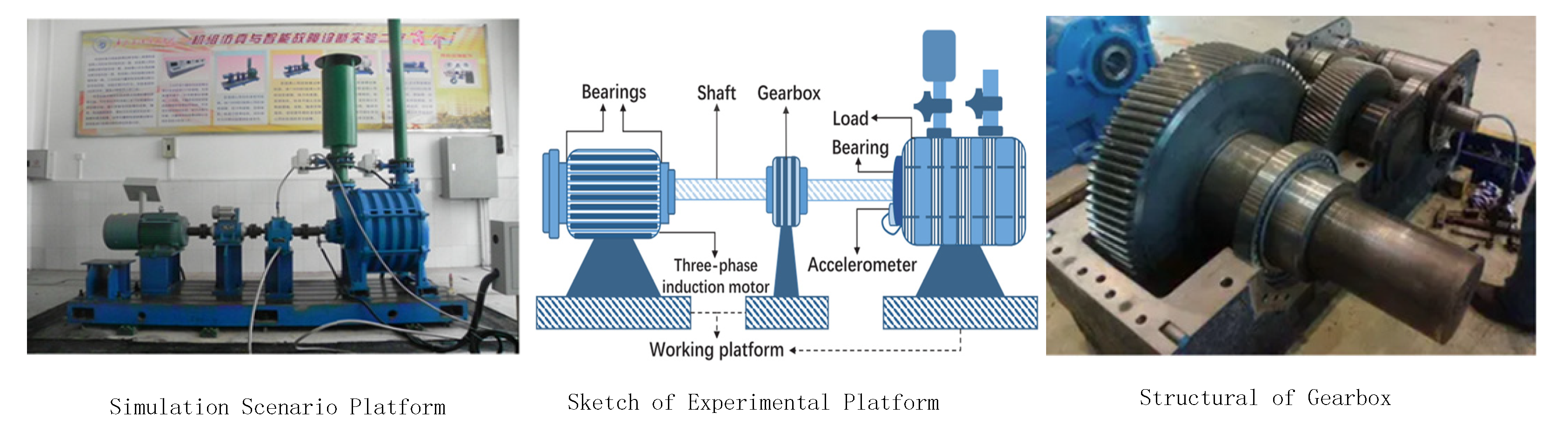
4.1. Case Study on CWRU
4.1.1. Description of CWRU
4.1.2. Results Analysis
4.2. Case Study on Petrochemical Dataset
4.2.1. Petrochemical Dataset Introduction
4.2.2. Six-Way Fault Classification
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Zhou, D.H.; Zhao, Y.H.; Wang, Z.D.; He, X.; Gao, M. Review on Diagnosis Techniques for Intermittent Faults in Dynamic Systems. IEEE Trans. Ind. Electron. 2020, 67, 2337–2347. [Google Scholar] [CrossRef]
- Rai, A.; Upadhyay, S.H. A review on signal processing techniques utilized in the fault diagnosis of rolling element bearings. Tribol. Int. 2016, 96, 289–306. [Google Scholar] [CrossRef]
- He, J.; Ouyang, M.; Chen, Z.; Chen, D.; Liu, S. A Deep Transfer Learning Fault Diagnosis Method Based on WGAN and Minimum Singular Value for Non-Homologous Bearing. IEEE Trans. Instrum. Meas. 2022, 71, 1–9. [Google Scholar] [CrossRef]
- Qin, S.; Jiang, T. Improved Wasserstein conditional generative adversarial network speech enhancement. EURASIP J. Wirel. Commun. Netw. 2018, 2018, 181. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative Adversarial Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar] [CrossRef]
- Yin, H.; Li, Z.; Zuo, J.; Liu, H.; Yang, K.; Li, F. Wasserstein Generative Adversarial Network and Convolutional Neural Network (WG-CNN) for Bearing Fault Diagnosis. Math. Probl. Eng. 2020, 2020, 2604191. [Google Scholar] [CrossRef]
- Gong, W.; Chen, H.; Zhang, Z.; Zhang, M.; Wang, R.; Guan, C.; Wang, Q. A novel deep learning method for intelligent fault diagnosis of rotating machinery based on improved CNN-SVM and multichannel data fusion. Sensors 2019, 19, 1693. [Google Scholar] [CrossRef] [Green Version]
- Jiang, H.; Li, X.; Shao, H.; Zhao, K. Intelligent fault diagnosis of rolling bearings using an improved deep recurrent neural network. Meas. Sci. Technol. 2018, 29, 065107. [Google Scholar] [CrossRef]
- Cui, M.; Wang, Y.; Lin, X.; Zhong, M. Fault diagnosis of rolling bearings based on an improved stack autoencoder and support vector machine. IEEE Sens. J. 2020, 21, 4927–4937. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, Y.; Hu, C.; Liu, Z.; Cheng, L.; Zhou, Y. A novel intelligent fault diagnosis method based on variational mode decomposition and ensemble deep belief network. IEEE Access 2020, 8, 36293–36312. [Google Scholar] [CrossRef]
- Zhang, A.; Li, S.; Cui, Y.; Yang, W.; Dong, R.; Hu, J. Limited data rolling bearing fault diagnosis with few-shot learning. IEEE Access 2019, 7, 110895–110904. [Google Scholar] [CrossRef]
- Jiang, C.; Chen, H.; Xu, Q.; Wang, X. Few-shot fault diagnosis of rotating machinery with two-branch prototypical networks. J. Intell. Manuf. 2022. [Google Scholar] [CrossRef]
- Xu, J.; Xu, P.; Wei, Z.; Ding, X.; Shi, L. DC-NNMN: Across Components Fault Diagnosis Based on Deep Few-Shot Learning. Shock. Vib. 2020, 2020, 3152174. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, M.; Xu, Y.; Lu, W.; Yang, J.; Zhang, T. Metric-based meta-learning model for few-shot fault diagnosis under multiple limited data conditions. Mech. Syst. Signal Process. 2021, 155, 107510. [Google Scholar] [CrossRef]
- Xu, Y.; Li, Y.; Wang, Y.; Zhong, D.; Zhang, G. Improved few-shot learning method for transformer fault diagnosis based on approximation space and belief functions. Expert Syst. Appl. 2021, 167, 114105. [Google Scholar] [CrossRef]
- Tao, X.; Ren, C.; Li, Q.; Guo, W.; Liu, R.; He, Q.; Zou, J. Bearing defect diagnosis based on semi-supervised kernel Local Fisher Discriminant Analysis using pseudo labels. ISA Trans. 2021, 110, 394–412. [Google Scholar] [CrossRef]
- Zhang, X.; Su, Z.; Hu, X.; Han, Y.; Wang, S. Semi-supervised momentum prototype network for gearbox fault diagnosis under limited labeled samples. IEEE Trans. Ind. Inform. 2022, 18, 6203–6213. [Google Scholar] [CrossRef]
- Feng, Y.; Chen, J.; Zhang, T.; He, S.; Xu, E.; Zhou, Z. Semi-supervised meta-learning networks with squeeze-and-excitation attention for few-shot fault diagnosis. ISA Trans. 2021, 120, 383–401. [Google Scholar] [CrossRef]
- Huang, K.; Geng, J.; Jiang, W.; Deng, X.; Xu, Z. Pseudo-loss Confidence Metric for Semi-supervised Few-shot Learning. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 8651–8660. [Google Scholar]
- Wang, D.; Han, S.; Wang, Q.; He, L.; Tian, Y.; Gao, X. Pseudo-Label Guided Collective Matrix Factorization for Multiview Clustering. IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.S.; Hospedales, T.M. Learning to Compare: Relation Network for Few-Shot Learning. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Pan, Y.; Yao, T.; Li, Y.; Wang, Y.; Ngo, C.-W.; Mei, T.; Soc, I.C. Transferrable Prototypical Networks for Unsupervised Domain Adaptation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2234–2242. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical Networks for Few-shot Learning. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Varon, C.; Alzate, C.; Suykens, J.A.K. Noise Level Estimation for Model Selection in Kernel PCA Denoising. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2650–2663. [Google Scholar] [CrossRef] [PubMed]
- Ji, Z.; Chai, X.; Yu, Y.; Pang, Y.; Zhang, Z. Improved prototypical networks for few-Shot learninge. Pattern Recognit. Lett. 2020, 140, 81–87. [Google Scholar] [CrossRef]
- Smith, W.A.; Randall, R.B. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]
- Tian, X.; Chen, L.; Zhang, X.; Chen, E. Improved prototypical network model for forest species classification in complex stand. Remote Sens. 2020, 12, 3839. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Q.; He, X.; Sun, G.; Zhou, D. Compound-Fault Diagnosis of Rotating Machinery: A Fused Imbalance Learning Method. IEEE Trans. Control Syst. Technol. 2021, 29, 1462–1474. [Google Scholar] [CrossRef]
- Hu, Q.; Qin, A.; Zhang, Q.; He, J.; Sun, G. Fault Diagnosis Based on Weighted Extreme Learning Machine with Wavelet Packet Decomposition and KPCA. IEEE Sens. J. 2018, 18, 8472–8483. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Layer Type | Kernel Size/Stride | Kernel Number | Output Size (Width × Depth) | Padding |
|---|---|---|---|---|---|
| 1 | Conv1 | 3 × 1/1 × 1 | 16 | 256 × 16 | same |
| 2 | Pool1 | 2 × 1/1 × 1 | 16 | 128 × 16 | valid |
| 3 | Conv2 | 3 × 1/1 × 1 | 32 | 128 × 32 | same |
| 4 | Pool2 | 2 × 1/1 × 1 | 32 | 64 × 64 | valid |
| 5 | Conv3 | 3 × 1/1 × 1 | 64 | 32 × 64 | same |
| 6 | Pool3 | 2 × 1/1 × 1 | 64 | 16 × 64 | valid |
| 7 | Conv4 | 3 × 1/1 × 1 | 64 | 16 × 64 | same |
| 8 | Pool4 | 2 × 1/1 × 1 | 64 | 6 × 64 | valid |
| 9 | Conv5 | 3 × 1/1 × 1 | 64 | 6 × 64 | same |
| 10 | Pool5 | 2 × 1/1 × 1 | 64 | 3 × 64 | valid |
| State | Description | Fault Size (Inches) |
|---|---|---|
| N | Normal condition | |
| RF | Fault on roller | 0.007, 0.014, 0.021 |
| IF | Fault on inner race | 0.007, 0.014, 0.021 |
| OF | Fault on te out race | 0.007, 0.014, 0.021 |
| Fault Location | None | Ball | Inner Race | Outer Race | Load | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fault Diameter (Inches) Fault Labels | 0 | 0.007 | 0.014 | 0.021 | 0.007 | 0.014 | 0.021 | 0.007 | 0.014 | 0.024 | ||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| Dataset | Pretrain | 500 | 500 | 500 | 500 | 500 | 500 | 500 | 500 | 500 | 500 | 1 |
| Unlabeled | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | ||
| Test | 200 | 200 | 200 | 200 | 200 | 200 | 200 | 200 | 200 | 200 | ||
| Methods | CWRU | ||||
|---|---|---|---|---|---|
| 1-Shot | 5-Shot | 10-Shot | 15-Shot | 30-Shot | |
| CNN | 18.88 ± 0.23 | 80.58 ± 0.38 | 80.36 ± 0.54 | 80.09 ± 0.07 | 80.32 ± 0.17 |
| ProtoNet [24] | 83.06 ± 0.77 | 89.80 ± 0.32 | 92.27 ± 0.23 | 99.81 ± 0.02 | 99.85 ± 0.01 |
| IPN [28] | 85.97 ± 0.43 | 89.97 ± 0.23 | 93.36 ± 0.31 | 99.59 ± 0.03 | 99.28 ± 0.05 |
| ProtoNet+KPCA | 85.12 ± 0.58 | 92.03 ± 0.23 | 95.88 ± 0.10 | 96.30 ± 0.13 | 96.26 ± 0.09 |
| PSSPN (ours) | 89.72 ± 0.38 | 94.65 ± 0.16 | 97.05 ± 0.07 | 95.92 ± 0.10 | 96.59 ± 0.07 |
| Fault Location | F0 | F1 | F2 | F3 | F4 | ||
|---|---|---|---|---|---|---|---|
| Fault Label | 0 | 1 | 2 | 3 | 4 | 5 | |
| Dataset | Pretrain | 500 | 500 | 500 | 500 | 500 | 500 |
| Unlabeled | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | |
| Test | 200 | 200 | 200 | 200 | 200 | 200 | |
| Method | Petrochemical Dataset | ||||
|---|---|---|---|---|---|
| 1-Shot | 5-Shot | 10-Shot | 15-Shot | 30-Shot | |
| CNN | 41.46 ± 0.16 | 76.63 ± 0.41 | 92.84 ± 0.01 | 82.79 ± 0.14 | 91.78 ± 0.24 |
| ProtoNet [24] | 86.79 ± 0.53 | 94.07 ± 0.18 | 97.04 ± 0.06 | 97.56 ± 0.14 | 97.71 ± 0.29 |
| IPN [28] | 88.86 ± 2.20 | 89.12 ± 1.91 | 100 | 100 | 100 |
| ProtoNet+KPCA | 88.70 ± 0.38 | 95.35 ± 0.07 | 98.38 ± 0.07 | 98.30 ± 0.04 | 99.17 ± 0.20 |
| PSSPN | 89.61 ± 0.30 | 96.23 ± 0.06 | 97.77 ± 0.08 | 98.57 ± 0.04 | 97.30 ± 0.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, J.; Zhu, Z.; Fan, X.; Chen, Y.; Liu, S.; Chen, D. Few-Shot Learning for Fault Diagnosis: Semi-Supervised Prototypical Network with Pseudo-Labels. Symmetry 2022, 14, 1489. https://doi.org/10.3390/sym14071489
He J, Zhu Z, Fan X, Chen Y, Liu S, Chen D. Few-Shot Learning for Fault Diagnosis: Semi-Supervised Prototypical Network with Pseudo-Labels. Symmetry. 2022; 14(7):1489. https://doi.org/10.3390/sym14071489
Chicago/Turabian StyleHe, Jun, Zheshuai Zhu, Xinyu Fan, Yong Chen, Shiya Liu, and Danfeng Chen. 2022. "Few-Shot Learning for Fault Diagnosis: Semi-Supervised Prototypical Network with Pseudo-Labels" Symmetry 14, no. 7: 1489. https://doi.org/10.3390/sym14071489