1. Introduction
Extreme Learning Machine (ELM) was first proposed as a novel single hidden layer feed-forward network (SLFN) training algorithm by Huang et al. [
1,
2]. Because ELM randomly generates the input weight and deviation of the hidden layer, ELM has the advantages of simple structure, low computational cost and good universality compared with traditional neural network algorithms [
3]. ELM has been used in many fields in recent years thanks to its fast learning and good generalization and general approximation capabilities [
4,
5,
6,
7,
8,
9,
10], such as bioinformatics [
4,
5], computer vision [
6], data mining [
7], robotics [
8], and engineering applications [
10].
Recently, ELM has been intensively studied by many researchers, and many variants have been proposed. For example, optimization extreme learning machine (OELM) was presented by Huang et al. [
11]. In [
12], Yang and Zhang proposed smooth extreme learning machine (SMELM) by applying smoothing techniques. Simultaneously, in [
13], Yang and Zhang suggested a new sparse extreme learning machine (SPELM). In addition, a unified learning framework for different applications was introduced by Huang et al. [
14]. Although the above improved versions of ELM have achieved good results, they are all supervised learning algorithms. In order to overcome the shortcomings of ELM, a novel semi-supervised extreme learning machine(SSELM) was suggested in [
15]. Subsequently, a robust SS-ELM (RSS-ELM) was proposed by Pei et al. 42 to overcome the effect of outliers on the SS-ELM, while a Lagrangian semi-supervised extreme learning machine (LELM) for pattern recognition was proposed by Ma et al. [
16].
In recent years, Jayadeva et al. [
17] have proposed an excellent machine learning tool called the twin support vector machine (TSVM) for classification tasks. Due to the superior performance of TSVM, many variants of TSVM have been proposed in recent years [
18,
19,
20,
21,
22]. It is well known that a significant advantage of Support Vector Machines (SVMs) is the implementation of the Structural Risk Minimisation principle (SRM). However, only the empirical risk minimisation (ERM) principle is considered in the standard TSVM learning framework. To improve the performance of TSVM, Shao et al. proposed a twin bounded support vector machine (TBSVM). In the TBSVM, the SRM principle is implemented by introducing regularization terms. Inspired by TSVM, Wan et al. proposed Twin Extreme Learning Machine (TELM). Similar to TSVM, TELM only considers the ERM principle.
Although the above SVM-based algorithms achieve good results, they can carry a heavy computational burden during training because they need to solve the quadratic programming problem (QPP). To overcome this challenge, Mangasarian et al. [
23] proposed a computationally powerful machine learning algorithm called a Lagrangian Support Vector Machine (LSVM). It minimises an unconstrained differentiable convex function in a space where the dimension is equal to the number of classification points. Recently, researchers have developed the idea of extending LSSVM to TSVM and its variants, achieving excellent results [
15,
23,
24,
25,
26,
27,
28,
29,
30]. Several representative works can be briefly reviewed as follows, such as the Lagrangian twin support vector machine (LTSVM) proposed by Balasundaram et al. [
24]. Shao et al. [
25] have proposed an efficient weighted Lagrangian dual support vector machine (WLTSVM) for imbalanced classification. It is well known that the performance of supervised learning algorithms tends to deteriorate when there is insufficient supervised information. An effective approach to deal with this problem is semi-supervised learning (SSL), which makes use of geometric information embedded in unlabelled samples [
31,
32,
33,
34,
35,
36,
37]. Over the past decades, researchers have presented various SSL methods from different perspectives and have achieved promising results such as Laplacian support vector machine (Lap-SVM) [
31], Laplacian twin support vector machine (Lap-TSVM) [
20], semi-supervised extreme learning machine(SS-ELM) [
36], and more.
Inspired by the above excellent works, this paper proposes a new TELM learning framework, namely, a Lagrangian regularized twin extreme learning machine (LRTELM). LRTELM is based on optimization theory and structural risk minimization. In addition, we extend LRTELM to semi-supervised learning by introducing manifold regularization in order to improve the performance of LRTELM when the labeled samples are insufficient, as well as to obtain a Lagrangian semi-supervised regularized twin extreme learning machine (Lap-LRTELM).
LRTELM is based on optimization theory and structural risk minimization. Then, LRTELM is extended to semi-supervised learning by introducing manifold regularization to improve the performance of LRTELM when insufficient labeled samples are available, as well as to obtain a Lagrangian semi-supervised regularized twin extreme learning machine (Lap-LRTELM). Lap-LRTELM can effectively exploit the geometric information embedded in the distribution of unlabelled samples of margins in order to improve the generalisation performance of LRTELM. Experimental results on various datasets show that the proposed algorithms, LRTELM and Lap-LRTELM, are competitive in terms of accuracy and efficiency when compared with state-of-the-art learning algorithms.
In particular, the major contributions of this paper are as follows:
- (1)
Two effective and reliable learning frameworks based on TELM are proposed, namely, Lagrangian regularized twin extreme learning machine (LRTELM) and Laplacian Lagrangian regularized twin extreme learning machine (Lap-LRTELM).
- (2)
LRTELM and Lap-LRTELM implement the principle of structural risk minimization by introducing regularization terms in the objective function. We consider the square of the -norm of the vector of slack variables instead of the usual -norm, as in TELM, to make the objective functions strongly convex.
- (3)
Two fast, simple, and efficient algorithms are designed to solve the LRTELM and Lap-LRTELM, respectively. These two algorithms only need to solve two linear equations separately, avoiding the need to solve a pair of QPPs, as in TELM. The resulting iterative algorithms globally converge and have a lower computational burden.
- (4)
Experimental results on variety of datasets show that our algorithms, LRTELM and Lap-LRTELM, are competitive with other algorithms in terms of accuracy and efficiency.
The remainder of this paper is organised as follows. We briefly review ELM, TELM, and the framework of manifold regularization in
Section 2. In
Section 3 we describe LRTELM in detail, while
Section 4 describes the details Lap-LRTELM. Experimental results are presented in
Section 5; finally, concluding remarks are provided in
Section 6.
5. Experiment
In order to evaluate the performance of our proposed LRTELM and Lap-LRTELM, we compare our methods with related algorithms, including TELM [
40], LSVM [
23], LTSVM [
24], LELM [
16], Lap-LELM [
16], SS-ELM [
35], and Lap-TELM [
37]. The experimental settings are provided in
Section 5.1. In
Section 5.2, we provide supervised learning results and analysis. In
Section 5.3, we provide semi-supervised learning results and analysis.
5.1. Experimental Setup
Here, the accuracy of all experiments is calculated using the standard ten-fold cross-validation method and all parameters are selected using the grid search method. For convenience, we set the regularization parameters as . All parameter selection ranges are described as follows:
- (1)
Regularization parameters C and and the RBF kernel parameter are all selected from the set ;
- (2)
For the K-nearest neighbors parameter, N is selected from ;
- (3)
The hidden layer node L is selected from .
The activation function
(in which
,
b are randomly generated) was used for LRTELM, Lap-LRTELM, LELM, Lap-LELM, TELM, Lap-TELM, and SS-ELM. Classification accuracy (ACC) is used as an evaluation indicator to evaluate the performance of the algorithms involved. The ACC value is defined as
where
denotes true positives,
denotes true negatives,
denotes false negatives, and
denotes false positives. In order to better compare the computation times of all the algorithms employed, we recorded their running times, mainly including training and testing on all the datasets involved.
To validate the effectiveness of the proposed LRTELM and Lap-LRTELM, numerical simulations were carried out on various datasets, including nine benchmark datasets from the UCI repository, four image datasets, two artificial datasets, and five sets of infrared spectral datasets. We performed ten-fold cross-validation on all but four of the image datasets considered. (Due to the relatively small sample size of image datasets, which are generally high-dimensional and low-sample data, 0-fold cross validation was not used on image datasets.) Intuitively, the dataset was randomly partitioned into ten subsets, one of which was retained as the test set. This process was repeated ten times and the average of the ten test results was used as a performance measure. To obtain objective experimental results, we normalised all the data sets involved in the experiment to stay within the interval . For a fair comparison, we used Matlab’s Quadratic Programming (QP) toolbox to solve all QP problems in the algorithms of interest. All methods were implemented in MATLAB 2014a running on a PC with an Intel(R) Core(TM) i7-7200u processor (3.40 GHz) and 8 GB of RAM in system configuration.
5.2. Supervised Learning Results
5.2.1. Experiment on Near-Infrared Spectral Datasets
Today, information plays an increasingly important role in agricultural production as a new factor of production. For agricultural information, because of its strong locality and timeliness, determining the hidden information behind the data, improving the quality of information, and providing timely and practical information with prediction, seasonality, and guidance is an urgent problem to be studied and solved. Data mining techniques are now being used in various areas of agriculture [
41,
42]. It is well known that maize yield, a major grain crop in China, is significantly correlated with seed purity. The ’Nongda 108’ maize hybrid seed and the ’parent 178’ seed used in our experiment were obtained from the 2008 harvest in Beijing, China. A total of 240 seed samples were used in our experiment, 120 from the hybrid seeds and 120 from the parent seeds. We obtained near-infrared (NIR) spectral datasets of maize seeds using an MPA spectrometer, where the corresponding sample regions are denoted as A, B, C, D, and E regions. The information in these datasets is summarized in
Table 2.
To demonstrate the generalisation performance of the proposed LRTELM method in practical applications, the following numerical experiments were carried out on five near-infrared spectral datasets. Based on the optimal parameters, all experimental results are listed in
Table 3 and
Figure 1. Our analysis of the experimental results reveals the following:
- (1)
It is clear from
Table 3 that LRTELM achieves the best average ACC, the highest average score, and the best overall performance compared to other related algorithms.
- (2)
The experimental results + on the five datasets with LRTELM are better than with TELM or LELM.
- (3)
As the table shows, LRTELM outperforms the other four algorithms in terms of learning time.
Through the above analysis of the near-infrared spectral dataset, we can draw a safe conclusion that the proposed LRTELM is effective and reliable.
5.2.2. Experimental Results on UCI Datasets
To further test the classification performance of the proposed LRTELM and other related algorithms, we conducted numerical experiments on several publicly available UCI datasets (
http://archive.ics.uci.edu/ml/datasets.html (accessed on 22 March 2021)). All experimental results are presented in
Table 4. The analysis of all experimental results is as follows.
From
Table 4, it can be seen that in terms of classification performance, the proposed method outperforms other learning algorithms in most cases. Furthermore, in terms of learning efficiency, the proposed method outperforms other algorithms on most datasets. The main reason fpr this is that our LRTELM combines the advantages of TELM and LSVM while solving the problem of two smaller linear equations through an efficient iterative algorithm.
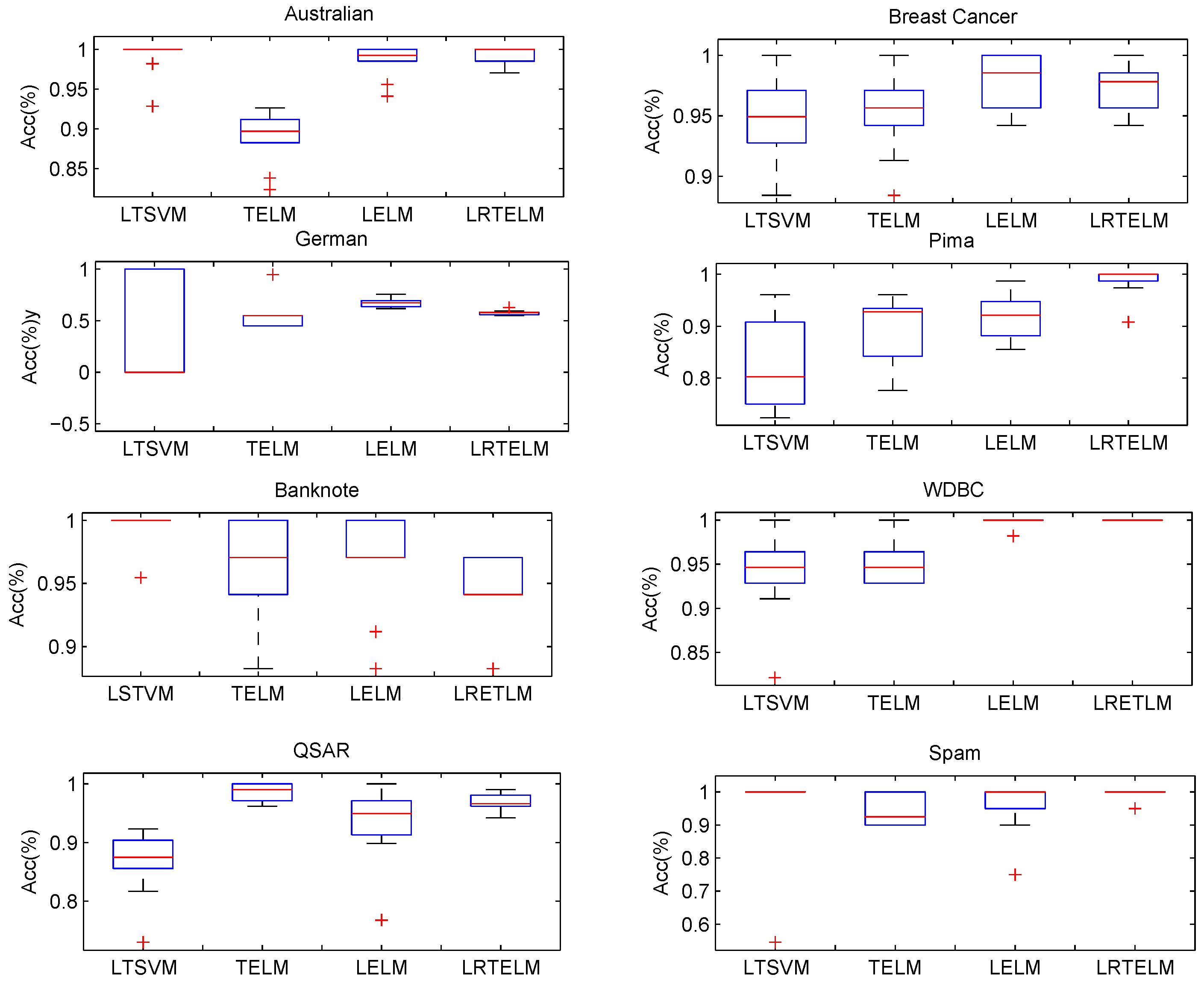
In order to statistically validate the performance of the proposed LRTELM, eight UCI datasets were selected and a series of experiments were conducted. The results of all experiments based on the optimal parameters are presented as box plots in
Figure 2.
Figure 2 shows the ACC box plots for LSVM, LTSVM, LELM, TELM, and LRTELM on the eight UCI datasets. The
x-axis shows the different classifiers, including LSVM, LTSVM, LELM, TELM, and LRTELM, while the
y-axis shows the ACC for all UCI datasets. From
Figure 2, it can be seen that LRTELM has better classification accuracy than the other algorithms on most of the datasets.
5.2.3. Statistical Analysis
In this section, in order to analyse the significant differences between the seven algorithms on the ten UCI datasets, we employed the well-known Friedman test [
43]. This test is known to be a simple, safe, and robust non-parametric test where the null hypothesis of the test is that all algorithms have the same performance. If the null hypothesis is rejected, a post hoc Nemeny test can be performed [
43]. The average ranks of the five algorithms on all used datasets are shown in
Table 3 and
Table 4, respectively.
To begin with, we can calculate the Friedman statistic variable using the following formulation:
where
k is number of algorithms,
N is number of UCI datasets, and
is the average rank of the
jth algorithm on the employed datasets; note that
and
in this paper. Furthermore, according to the
-distribution with
degrees of freedom, we have:
where
obeys
F-distribution with
and
degrees of freedom. In addition, for
we can obtain
. Obviously, the value of
; thus, the null hypothesis can be rejected.
Next, we further compare the seven algorithms in pairs using the Nemenyi post hoc test. The difference in performance between the two algorithms is significant when the average rank difference between the two algorithms is larger than the critical value, otherwise the difference is not significant. By dividing the Studentized range statistic by
, we obtain
. Therefore, we can calculate the critical difference (CD) using the following formulation:
Thus, if the average rank of the two algorithms differs by at least
, their performance is significantly different. From
Table 3, we can conclude that the proposed LRTELM differs from the other four algorithms as follows:
where
denotes the difference between two algorithms,
A and
B. We can then conclude that the proposed LRTELM performs significantly better than LSVM and LTSVM on the NIR spectral dataset, while there is no significant difference between LRTELM, TELM, and LELM. Similarly, on the UCI dataset, it can be seen that the proposed LRTELM performs significantly better than LSVM, while there is no significant difference between LRTELM, LTSVM, TELM, and LELM according to the mean rank and correlation values reported in
Table 4.
5.3. Semi-Supervised Learning Results
5.3.1. Experimental Results on Artificial Datasets
To verify the effect of manifold regularization on model performance, in this section we use the two artificial datasets [
44,
45] shown in
Figure 3 to investigate the performance of our proposed Lap-LRTELM. Each dataset contains 200 samples with two randomly selected labeled samples and 98 unlabeled samples for every class.
Here, we analyze the effects of the
parameters on the performance of our proposed Lap-LRTELM;
is used to control the weight of
. For the parameter
, the optimal parameters are
,
, and
,
, and we select different
from the set
in order to observe the impact of
on the performance of the proposed Lap-LRTELM. It is easy to see from
Figure 4 that the shape of the curve grows in the beginning and then falls when
. This means that
can improve the performance of Lap-LRTELM with
.
Table 5 shows the classification accuracy of TELM, LRTELM, Lap-TELM, and Lap-LRTELM on the artificial datasets. According to the results shown in
Table 5, it is obvious that when the tagged data are relatively small, the learning efficiency of Lap-LRTELM is better than the other three algorithms.
From the above experimental analysis of two artificial datasets, we can conclude that the performance of the proposed Lap-TELM is indeed improved by incorporating manifold regularisation. Intuitively, manifold regularisation can help the algorithm to seek a more reasonable classifier.
5.3.2. Experimental Results on UCI Datasets
In this section, to evaluate the effectiveness of Lap-LRTELM, we conduct experiments with different fractions of labeled samples, i.e.,
and
. In our experiments, the SS-ELM, Lap-LELM, Lap-TELM, and Lap-LRTELM were used to construct data adjacency graphs using
K-nearest neighbors. All of experimental results are presented in
Table 6.
From
Table 6, it can be seen that the performance of all the algorithms improves as the number of labelled samples increases. Furthermore, we find that the proposed Lap-LRTELM outperforms the other algorithms in most cases, regardless of the size of the labelled samples. Furthermore, the generalisation performance of the proposed Lap-LRTELM outperforms the other relevant ELM-based algorithms on all datasets.
The analysis of the above experimental results shows that the proposed Lap-LRTELM improves the classification performance of the LRTELM by using flow regularisation. Intuitively, a reasonable classifier can be built using manifold regularisation.
5.3.3. Experimental Results on Image Datasets
To rationally demonstrate the semi-supervised approach involved, we utilised the equivalent experimental setup reported by Melacci and Belkin [
24]. Concretely, we employed a four-fold cross-validation approach for each image dataset, with one fold as the test set (denoted by
) and the remaining folds as the training set. The training set was divided into labelled data (
), unlabelled data (
), and validation data (
). Here, this random folding was repeated three times, producing a total of twelve divisions. Detailed information on the datasets is summarized in
Table 7.
The performance of these algorithms on the USPST(B), COIL20(B), G50C, and MNIST(B) datasets was evaluated in our experiments using ACC ± S (classification accuracy ± standard deviation); the experimental results are shown in
Table 8.
As can be seen from
Table 8, Lap-LRTELM outperforms the other five algorithms in terms of classification accuracy on all the datasets involved. Compared with LRTELM, the proposed Lap-LRTELM can effectively utilise unlabelled samples to produce better performance. The experimental results show that by taking streamwise regularisation into account, the proposed Lap-LRTELM can achieve better performance compared to considering only one part.
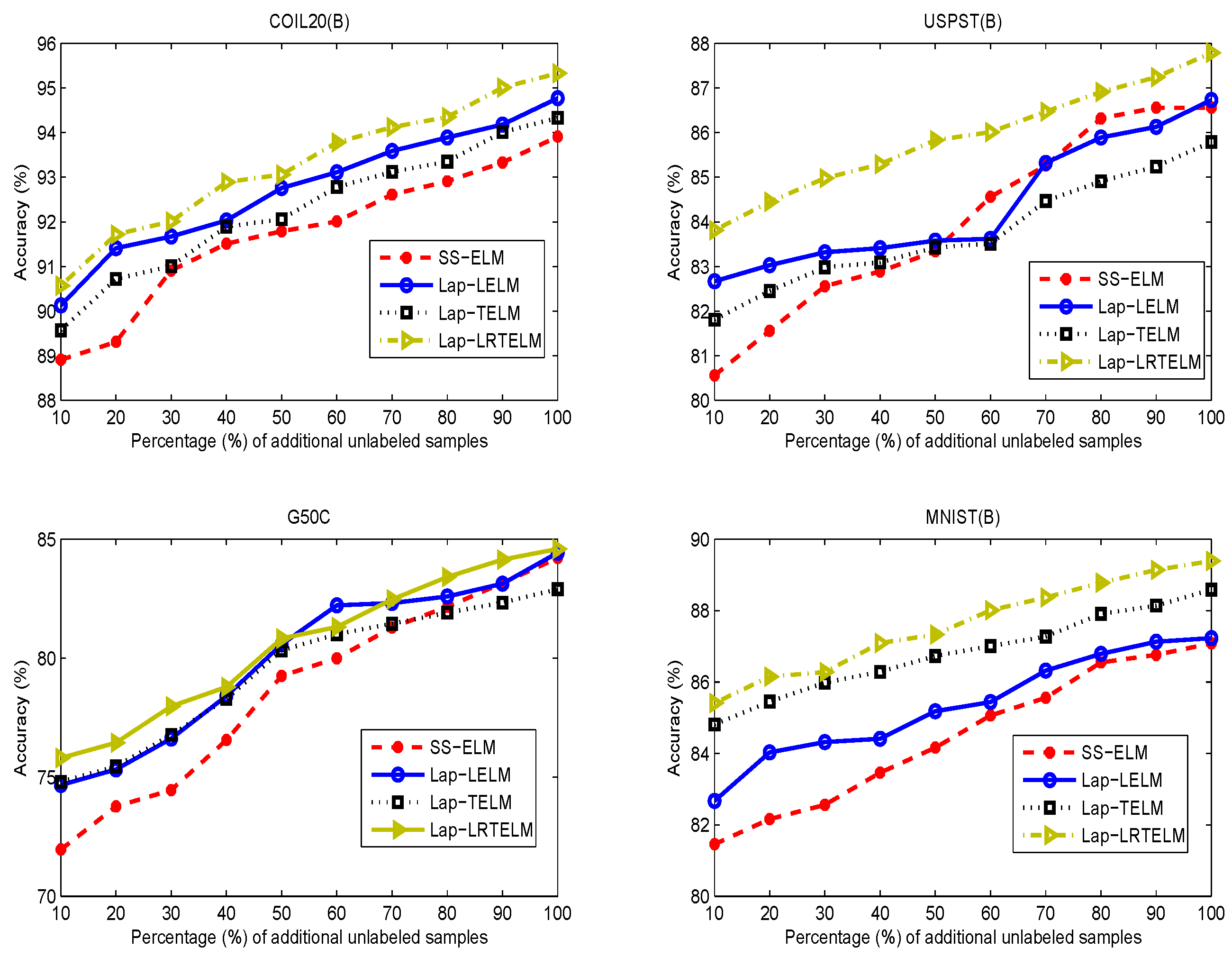
To analyse the influences of labelled and unlabelled samples on the performance of the relevant semi-supervised methods, we conducted a further series of experiments on COIL20(B), USPST(B), and G50C. The results of all experiments are shown in
Figure 5 and
Figure 6.
Figure 5 shows the classification accuracy of SS-ELM, Lap-TELM, Lap-LELM, and Lap-RTELM for different labelled samples on COIL20(B), USPST(B), G50C, and MNIST(B). As can be seen from the following
Figure 5, in most cases Lap-RTELM achieves the best results relative to the other three algorithms. The classification accuracy of all algorithms improves substantially as the number of labelled samples increases.
Figure 6 shows the performance of the four semi-supervised algorithms for different numbers of unlabelled samples. Using the same experimental scheme as in [
29], we add unlabelled samples to the unlabelled set (
) in 10% increments, while the labelled set (
), test set (
), and validation set (
) remain unchanged. From
Figure 6, it is easy to observe that classification accuracy improves when unlabelled samples are added to the unlabelled set (
). Even without any labelled ones, Lap-LRTELM performs better than SS-ELM, Lap-TELM and Lap-LELM. This phenomenon is consistent with Belkin et al. [
24] in that stream regularization is effective for purely supervised learning.
5.3.4. Statistical Analysis
In this section, we use the famous Friedman test with the corresponding post hoc test [
43] to analyze and compare algorithms’ performance on UCI datasets. The average ranking of the five algorithms on all datasets used is shown in
Table 6. First, we compare the performance of the five algorithms on the UCI dataset, in which 10% of the sample was labelled.
To begin with, we can calculate the Friedman statistic variable using the following formulation:
where
k is number of algorithms,
N is the number of UCI datasets, and
is the average rank of the
jth algorithm on the employed datasets; note that
and
in this paper. Furthermore, according to the
-distribution with
degrees of freedom, we have:
where
obeys
F-distribution with
and
degrees of freedom. In addition, for
we can obtain
. Obviously, the value of
; thus, the null hypothesis can be rejected.
Furthermore, we compared the seven algorithms in pairs using the Nemenyi post hoc test. The difference in performance between the two algorithms is significant when the average rank difference between the two algorithms is larger than the critical value; otherwise, the difference is not significant. By dividing the Studentized range statistic by
, we obtain
. Therefore, we can calculate the critical difference (CD) using the following formulation:
Thus, if the average ranks of two algorithms differ by at least
, their performance is significantly different. From
Table 6, we can derive the differences between the proposed Lap-LRTELM and other four algorithms as follows:
In summary, the proposed Lap-LRTELM performs significantly better than LRTELM, SS-ELM, and Lap-TELM, and there is no significant difference between Lap-LRTELM and Lap-LELM on UCI datasets with 10% labeled samples. Similarly, on UCI datasets with 30% labeled samples, we can obtain the same conclusions based on the average ranks and relevant values reported in
Table 6.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}