
Hybrid Domain Attention Network for Efficient Super-Resolution

Abstract
:1. Introduction
2. Related Work
2.1. Traditional Methods
2.2. Methods Based on Deep Learning
3. Proposed Method
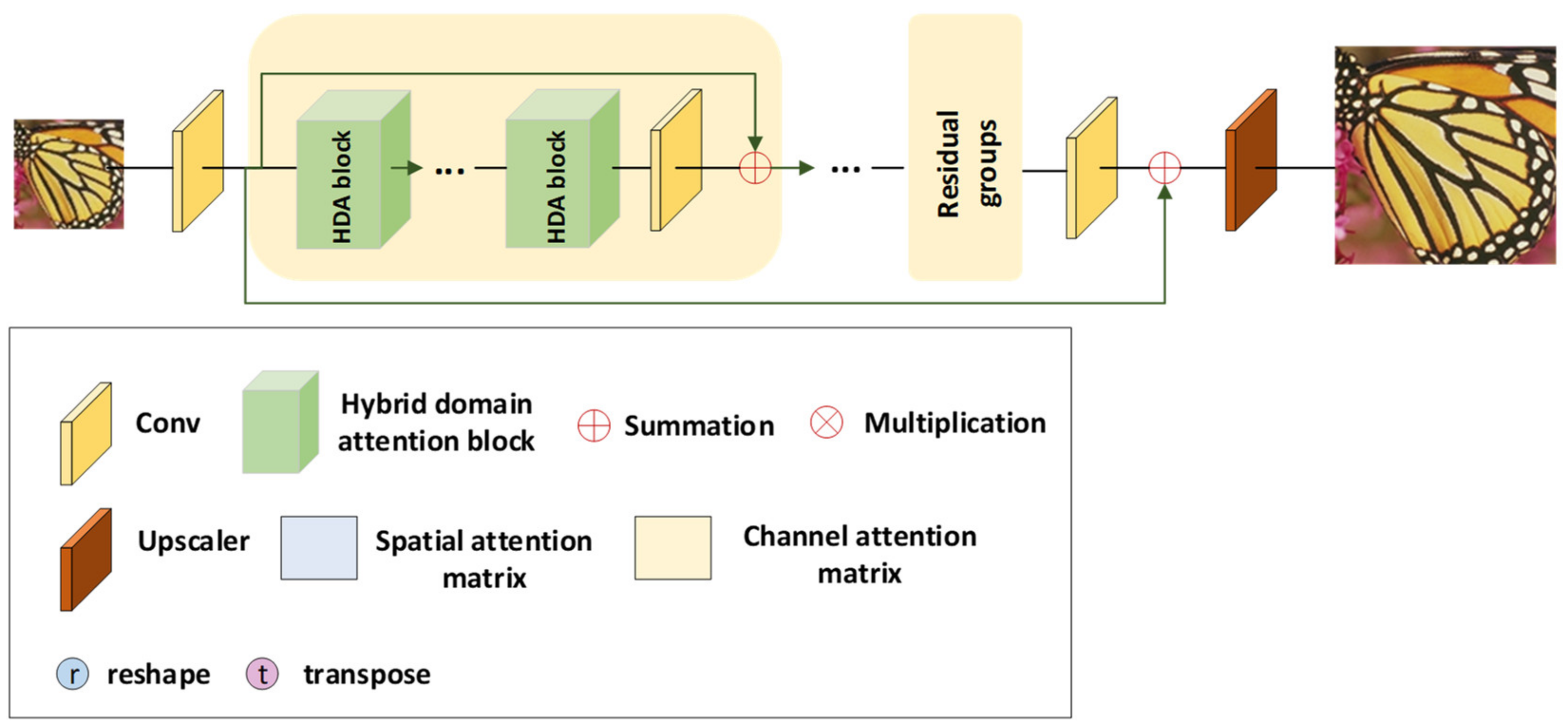
3.1. Overview
3.2. Hybrid Domain Attention Network
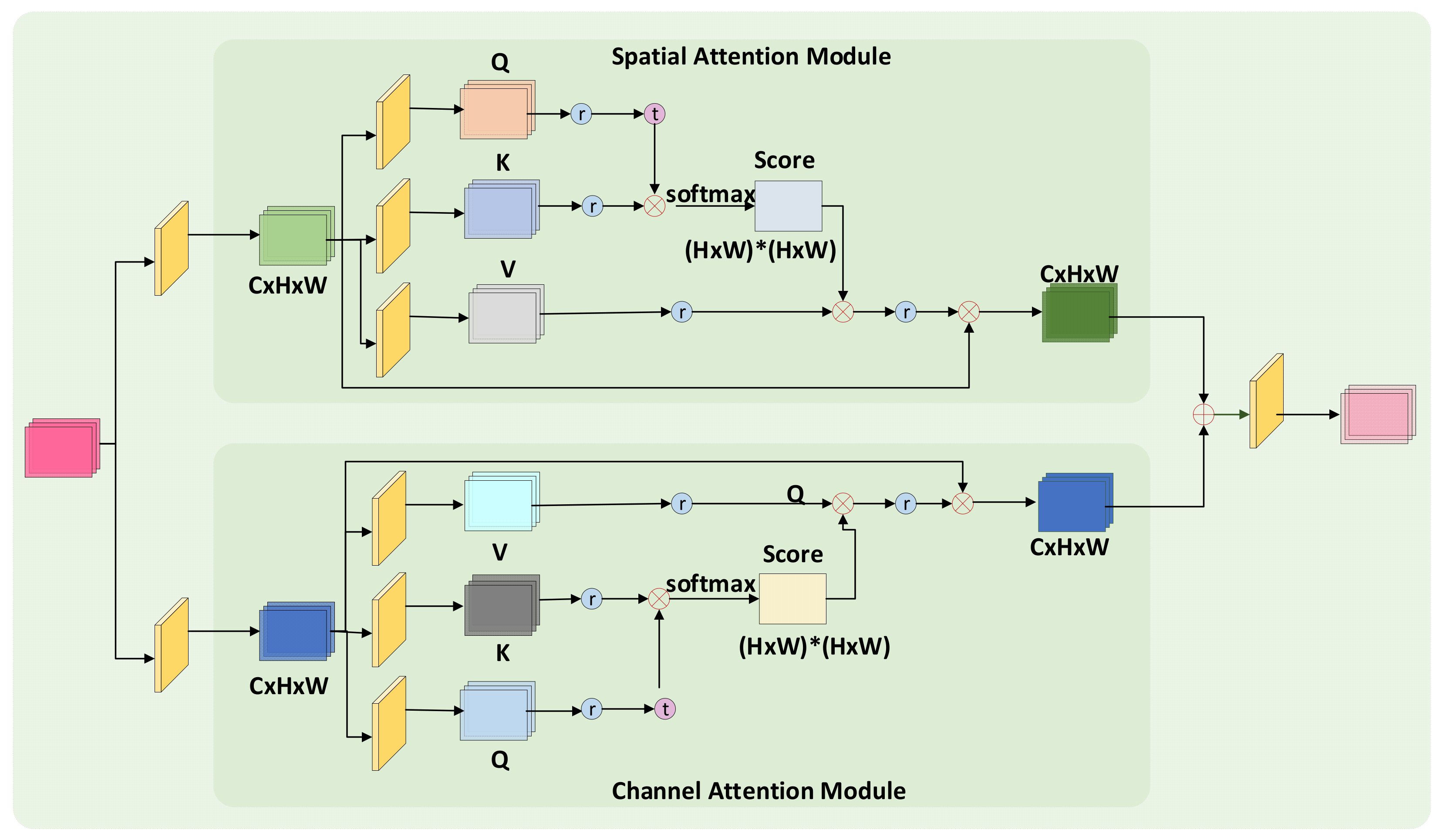
3.3. Spatial Self-Attention Module
3.4. Channel Self-Attention Module
3.5. Hybrid Domain Attention Module
4. Experiment
4.1. Datasets and Implementation Details
4.2. Effect of Data Preprocessing
4.3. Effect of SAM and CAM
4.4. Comparison with State-of-the-Arts
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, L.; Dong, X.; Wang, Y.; Ying, X.; Lin, Z.; An, W.; Guo, Y. Exploring sparsity in image super-resolution for efficient inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4917–4926. [Google Scholar]
- Liu, H.; Han, J.; Hou, S.; Shao, L.; Ruan, Y. Single image super-resolution using a deep encoder–decoder symmetrical network with iterative back projection. Neurocomputing 2018, 282, 52–59. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Wang, Y.; Dong, X.; Xu, Q.; Yang, J.; An, W.; Guo, Y. Unsupervised degradation representation learning for blind super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10581–10590. [Google Scholar]
- Zhang, K.; Liang, J.; Van Gool, L.; Timofte, R. Designing a practical degradation model for deep blind image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4791–4800. [Google Scholar]
- Kong, X.; Zhao, H.; Qiao, Y.; Dong, C. Classsr: A general framework to accelerate super-resolution networks by data characteristic. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12016–12025. [Google Scholar]
- Song, D.; Wang, Y.; Chen, H.; Xu, C.; Xu, C.; Tao, D. Addersr: Towards energy efficient image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15648–15657. [Google Scholar]
- Xie, W.; Song, D.; Xu, C.; Xu, C.; Zhang, H.; Wang, Y. Learning Frequency-aware Dynamic Network for Efficient Super-Resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4308–4317. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–20 June 2016; pp. 1646–1654. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Lemaire, C.; Achkar, A.; Jodoin, P.M. Structured pruning of neural networks with budget-aware regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9108–9116. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 184–199. [Google Scholar]
- Hou, H.; Andrews, H. Cubic splines for image interpolation and digital filtering. IEEE Trans. Acoust. Speech Signal Process. 1978, 26, 508–517. [Google Scholar]
- Zhong, M.; Lin, J. A Review of Super-Resolution Image Reconstruction Algorithms. J. Front. Comput. Sci. Technol. 2022, 1–24. [Google Scholar] [CrossRef]
- Chang, H.; Yeung, D.Y.; Xiong, Y. Super-resolution through neighbor embedding. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2004), Washington, DC, USA, 27 June–2 July 2004; Volume 1, p. I. [Google Scholar]
- Wang, Z.; Liu, D.; Yang, J.; Han, W.; Huang, T. Deep networks for image super-resolution with sparse prior. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 370–378. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4799–4807. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the 23rd British Machine Vision Conference (BMVC), Surrey, UK, 3–7 September 2012. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the NIPS 2017 Workshop Autodiff, Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Da, K. A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Hong, C.; Kim, H.; Baik, S.; Oh, J.; Lee, K.M. DAQ: Channel-Wise Distribution-Aware Quantization for Deep Image Super-Resolution Networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2675–2684. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Data Preprocessing | FLOPs | PSNR | SSIM |
|---|---|---|---|---|
| G1 | × | 112.3 G | 33.51 | 0.9169 |
| G2 | √ | 130.4 G | 33.59 | 0.9175 |
| Model | SAM | CAM | Params | FLOPs | PSNR | SSIM |
|---|---|---|---|---|---|---|
| model 1 | × | × | 1.00 M | 213.8 G | 37.86 | 0.9582 |
| model 2 | × | √ | 0.67 M | 128.3 G | 37.83 | 0.9583 |
| model 3 | √ | × | 1.25 M | 139.1 G | 37.90 | 0.9591 |
| model 4 | √ | √ | 1.06 M | 130.4 G | 37.94 | 0.9598 |
| Model | Scale | FLOPs | Params | Set5 PSNR/SSIM | Set14 PSNR/SSIM | B100 PSNR/SSIM | Urban100 PSNR/SSIM |
|---|---|---|---|---|---|---|---|
| Bicubic | ×2 | 33.66/0.9299 | 30.24/0.8688 | 29.56/0.8431 | 26.88/0.8403 | ||
| SRCNN [7] | 52.7 G | 1.55 M | 36.66/0.9545 | 32.42/0.9063 | 31.36/0.8879 | 29.50/0.8946 | |
| VDSR [9] | 612.6 G | 0.67 M | 37.53/0.9587 | 33.03/0.9124 | 31.90/0.8960 | 30.76/0.9140 | |
| LapSRN [27] | 29.9 G | 0.81 M | 37.52/0.9591 | 33.08/0.9130 | 31.08/0.8950 | 30.41/0.9101 | |
| CARN [28] | 222.8 G | 1.59 M | 37.76/0.9590 | 33.52/0.9166 | 32.09/0.8978 | 31.92/0.9256 | |
| HDANet | 130.4 G | 1.06 M | 37.94/0.9598 | 33.59/0.9175 | 32.13/0.8988 | 32.17/0.9283 | |
| Bicubic | ×3 | 30.39/0.8682 | 27.55/0.7742 | 27.21/0.7385 | 24.46/0.7349 | ||
| SRCNN [7] | 52.7 G | 1.55 M | 32.75/0.9090 | 29.28/0.8209 | 28.41/0.7863 | 26.24/0.7989 | |
| VDSR [9] | 612.6 G | 0.67 M | 33.66/0.9213 | 29.77/0.8314 | 28.82/0.7976 | 27.14/0.8279 | |
| LapSRN [27] | 29.9 G | 0.81 M | 33.82/0.9227 | 29.87/0.8320 | 28.82/0.7980 | 27.07/0.8280 | |
| CARN [28] | 118.8 G | 1.59 M | 34.29/0.9255 | 30.29/0.8407 | 29.06/0.8034 | 28.06/0.8493 | |
| HDANet | 66.7 G | 1.06 M | 34.35/0.9210 | 30.28/0.8405 | 29.11/0.8053 | 28.23/0.8531 | |
| Bicubic | ×4 | 28.42/0.8104 | 26.00/0.7027 | 25.96/0.6675 | 23.14/0.6577 | ||
| SRCNN [7] | 52.7 G | 1.55 M | 30.48/0.8628 | 27.49/0.7503 | 26.90/0.7101 | 24.52/0.7221 | |
| VDSR [9] | 612.6 G | 0.67 M | 31.35/0.8838 | 28.01/0.7674 | 27.29/0.7251 | 25.18/0.7524 | |
| LapSRN [27] | 149.4 G | 0.81 M | 31.54/0.8850 | 28.19/0.7720 | 27.32/0.7270 | 25.21/0.7560 | |
| CARN [28] | 90.9 G | 1.59 M | 32.13/0.8937 | 28.60/0.7806 | 27.58/0.7349 | 26.07/0.7837 | |
| RDN-DAQ [29] | 6.9 M | 31.61/. | 28.21/. | 27.31/. | 25.52/. | ||
| HDANet | 40.5 G | 1.08 M | 32.15/0.8941 | 28.61/0.7810 | 27.56/0.7338 | 26.12/0.7871 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Feng, L.; Liang, H.; Yang, Y. Hybrid Domain Attention Network for Efficient Super-Resolution. Symmetry 2022, 14, 697. https://doi.org/10.3390/sym14040697
Zhang Q, Feng L, Liang H, Yang Y. Hybrid Domain Attention Network for Efficient Super-Resolution. Symmetry. 2022; 14(4):697. https://doi.org/10.3390/sym14040697
Chicago/Turabian StyleZhang, Qian, Linxia Feng, Hong Liang, and Ying Yang. 2022. "Hybrid Domain Attention Network for Efficient Super-Resolution" Symmetry 14, no. 4: 697. https://doi.org/10.3390/sym14040697