
A Software Reliability Model with Dependent Failure and Optimal Release Time

Abstract
:1. Introduction
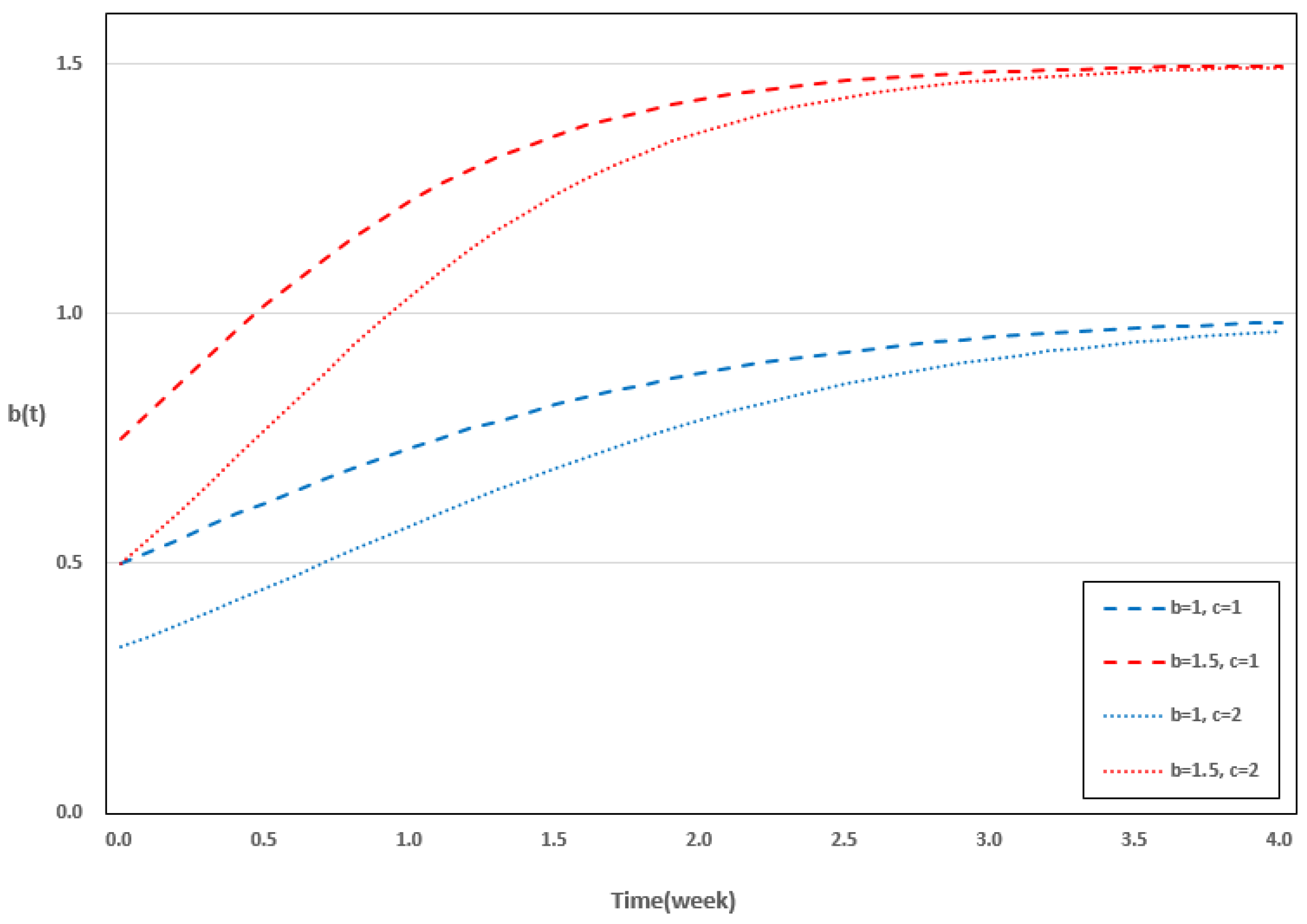
2. New Dependent Software Reliability Model
3. Numerical Examples
3.1. Data Information
3.2. Criteria
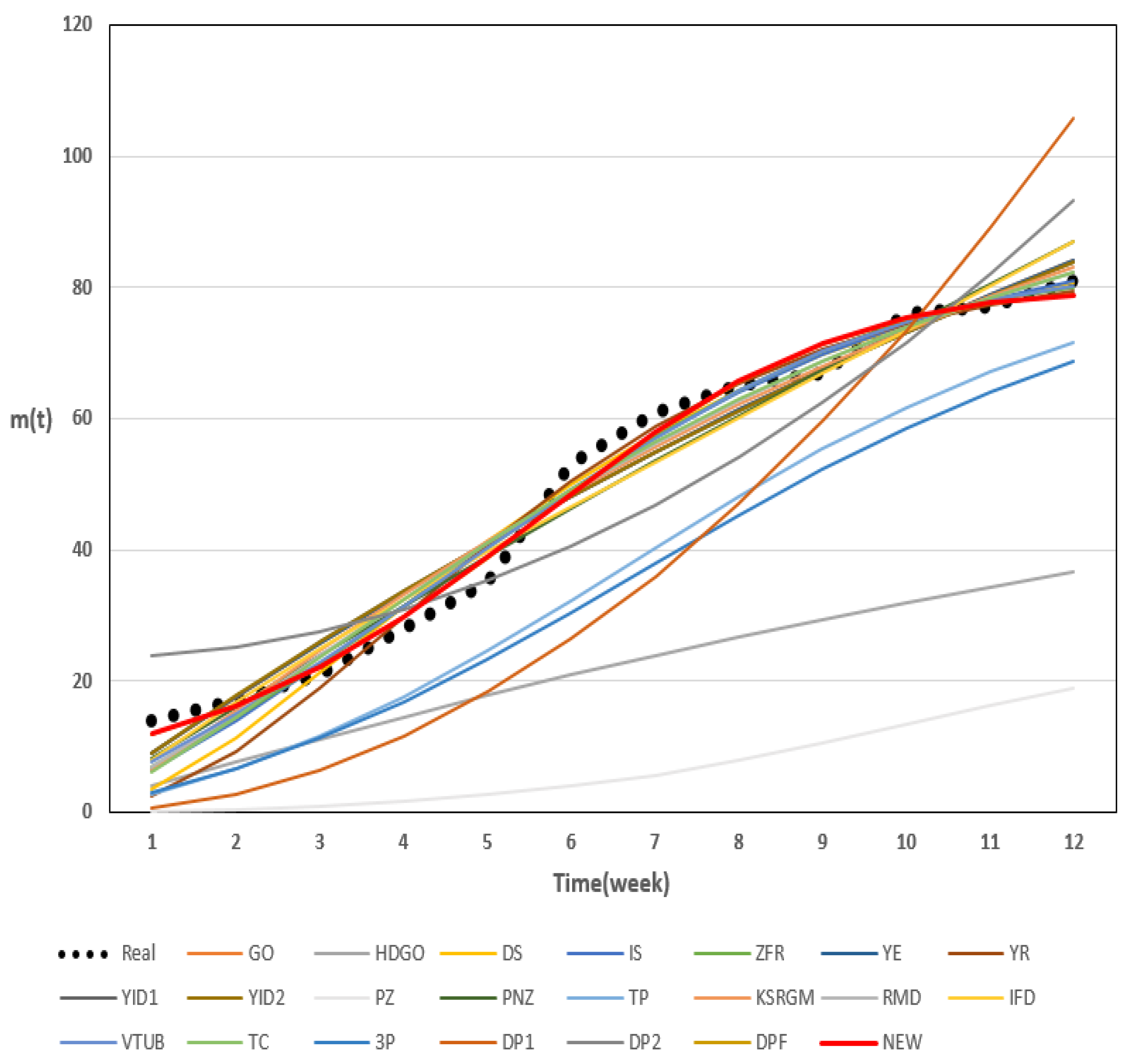
3.3. Results of Dataset 1
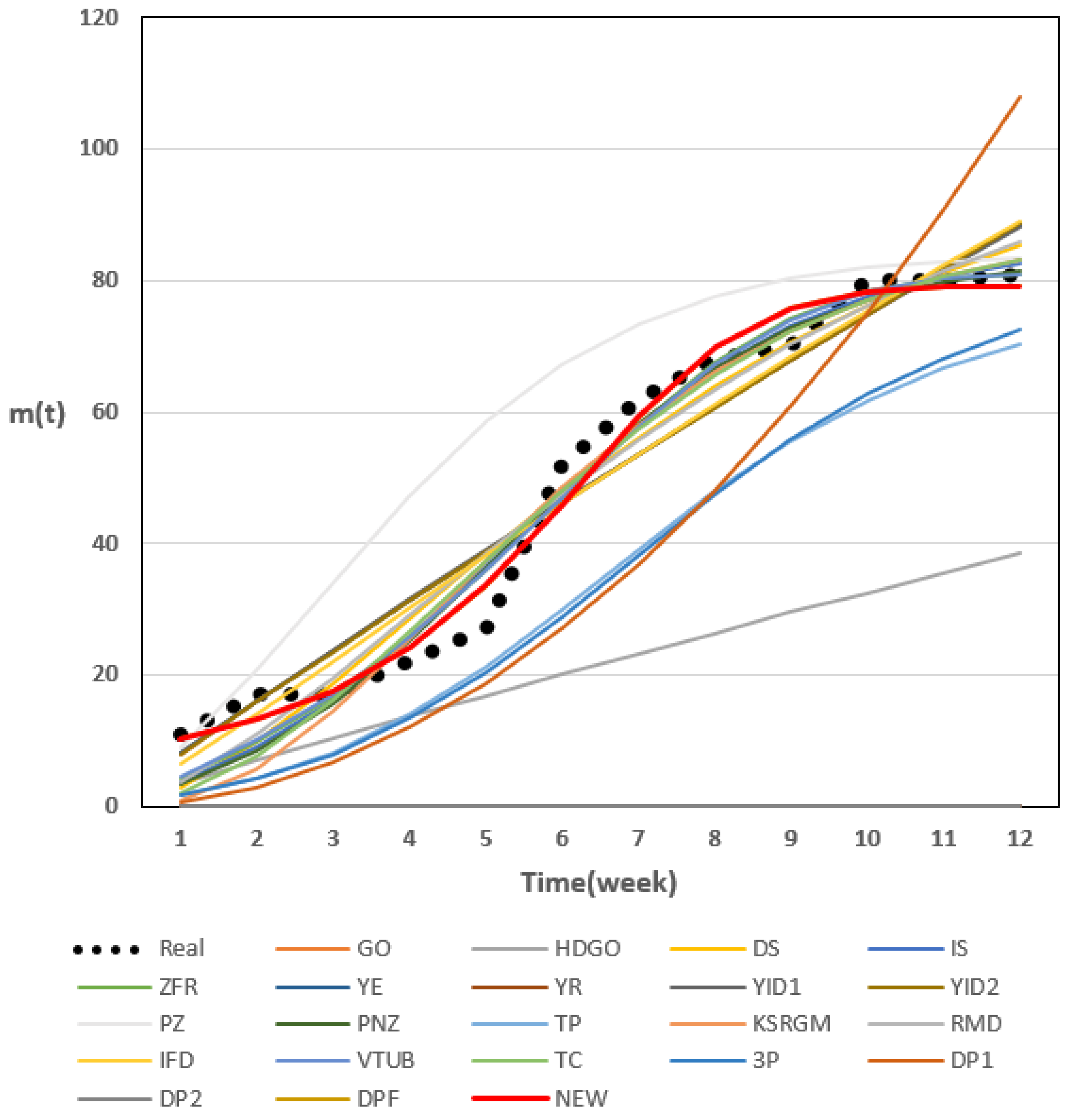
3.4. Results of Dataset 2
3.5. Results of Dataset 3
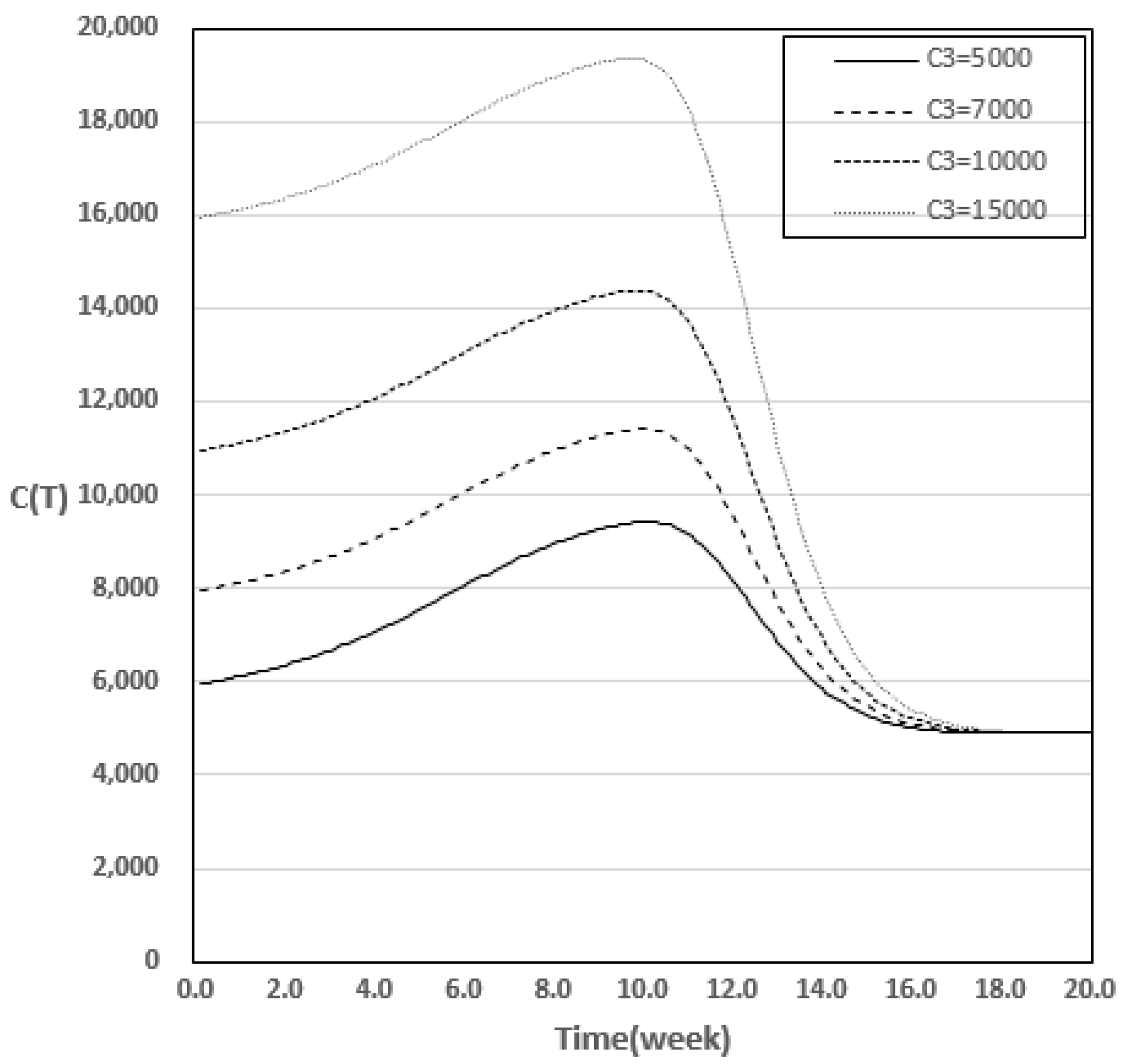
4. Optimal Release Time
4.1. Results of the Optimal Release Time
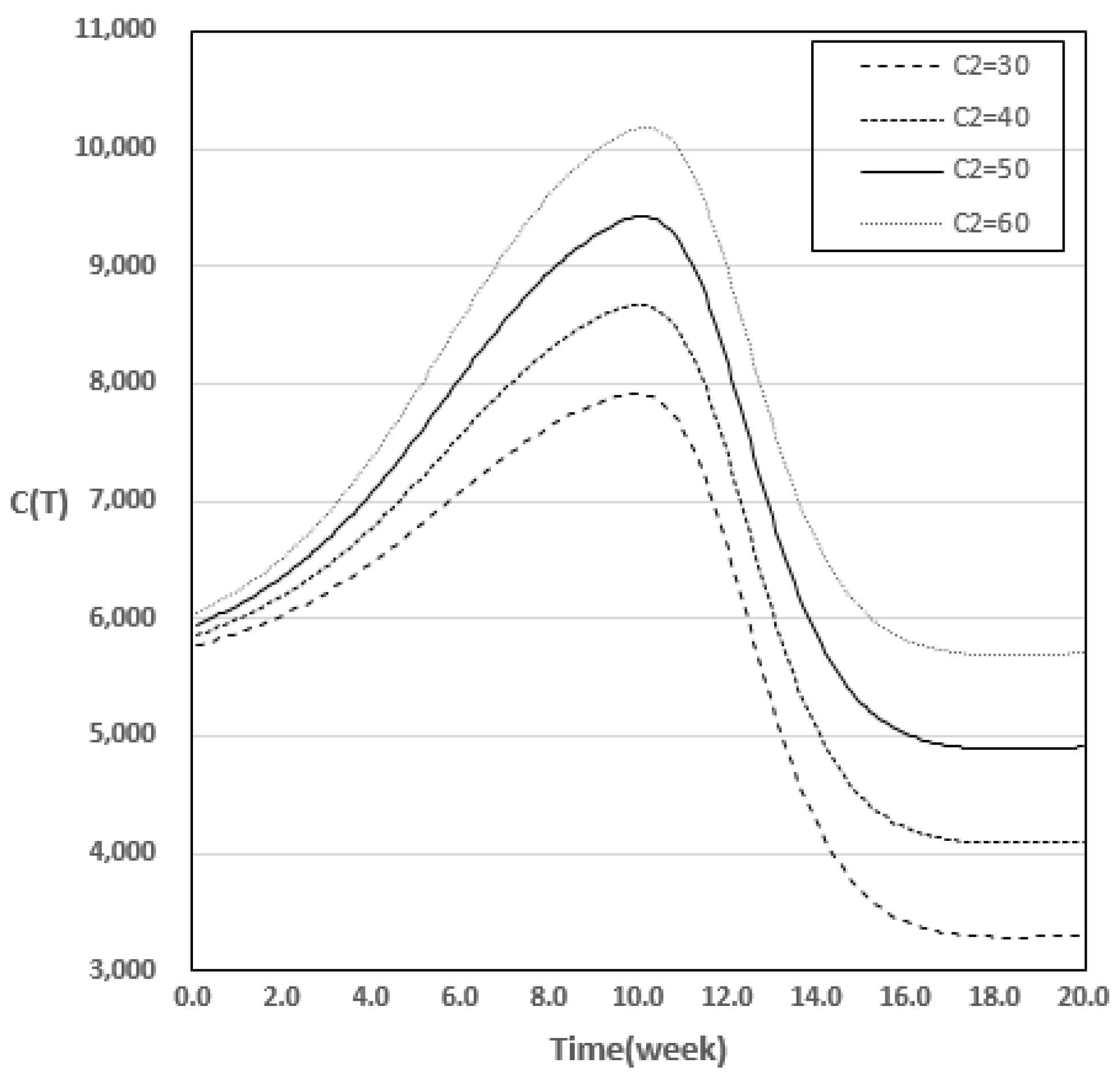
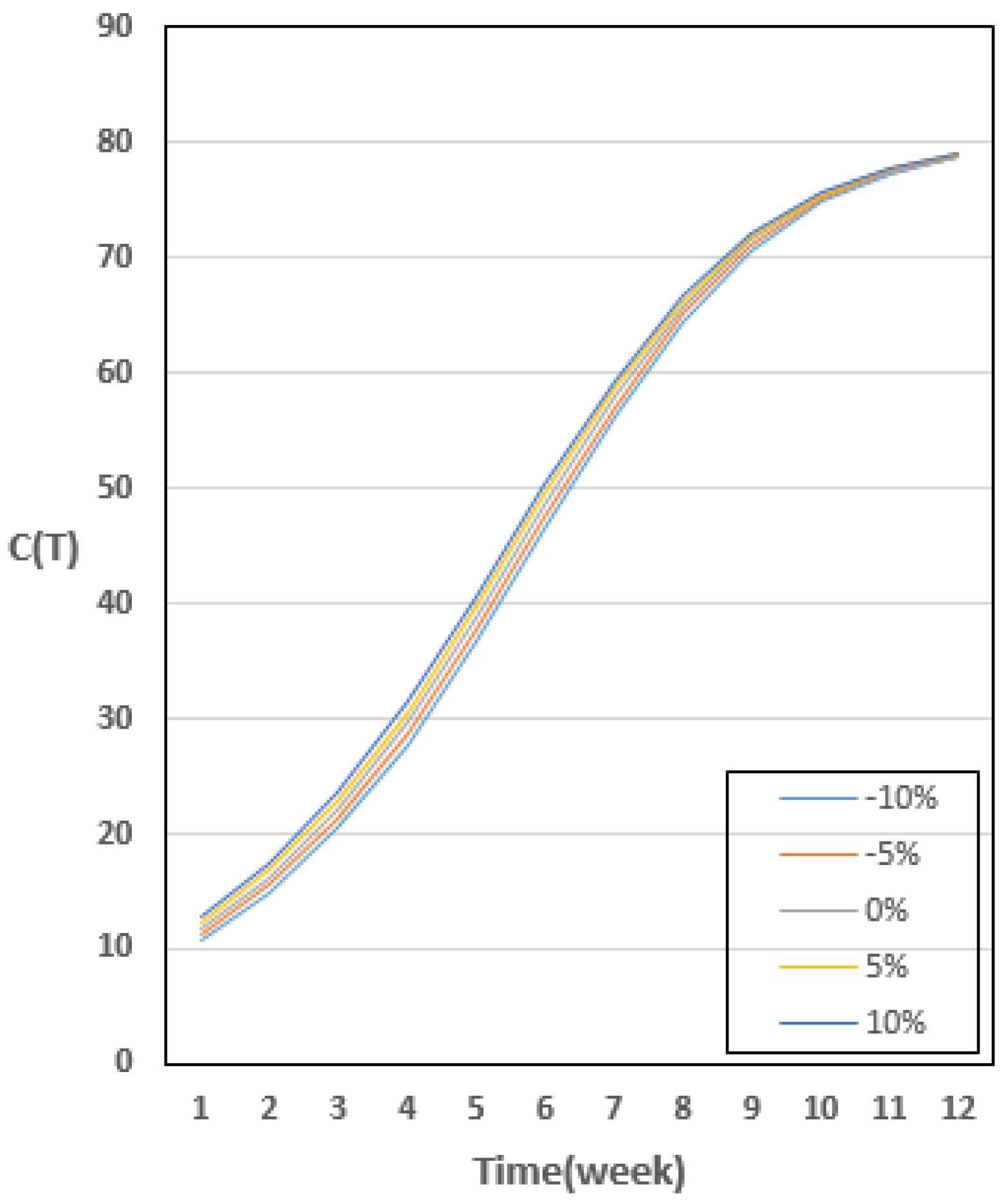
4.2. Results of Variation in Cost Model for Changes in Parameter
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, Y.C.; Wu, Y.J.; Wu, S.M. An outlook of a future smart city in Taiwan from post–internet of things to artificial intelligence internet of things. In Smart Cities: Issues and Challenges; Elsevier: Amsterdam, The Netherlands, 2019; pp. 263–282. [Google Scholar]
- Goel, A.L.; Okumoto, K. Time-dependent error-detection rate model for software reliability and other performance measures. IEEE Trans. Reliab. 1979, 28, 206–211. [Google Scholar] [CrossRef]
- Hossain, S.A.; Dahiya, R.C. Estimating the parameters of a non-homogeneous Poisson-process model for software reliability. IEEE Trans. Reliab. 1993, 42, 604–612. [Google Scholar] [CrossRef]
- Yamada, S.; Ohba, M.; Osaki, S. S-shaped reliability growth modeling for software fault detection. IEEE Trans. Reliab. 1983, 32, 475–484. [Google Scholar] [CrossRef]
- Ohba, M. Inflection S-shaped software reliability growth model. In Stochastic Models in Reliability Theory; Osaki, S., Hatoyama, Y., Eds.; Springer: Berlin, Germany, 1984; pp. 144–162. [Google Scholar]
- Zhang, X.M.; Teng, X.L.; Pham, H. Considering fault removal efficiency in software reliability assessment. IEEE Trans. Syst. Man Cybern. Part A-Syst. Hum. 2003, 33, 114–120. [Google Scholar] [CrossRef]
- Yamada, S.; Ohtera, H.; Narihisa, H. Software Reliability Growth Models with Testing-Effort. IEEE Trans. Reliab. 1986, 35, 19–23. [Google Scholar] [CrossRef]
- Yamada, S.; Tokuno, K.; Osaki, S. Imperfect debugging models with fault introduction rate for software reliability assessment. Int. J. Syst. Sci. 1992, 23, 2241–2252. [Google Scholar] [CrossRef]
- Pham, H.; Zhang, X. An NHPP software reliability models and its comparison. Int. J. Reliab. Qual. Saf. Eng. 1997, 4, 269–282. [Google Scholar] [CrossRef]
- Pham, H.; Nordmann, L.; Zhang, X. A general imperfect software debugging model with S-shaped fault detection rate. IEEE Trans. Reliab. 1999, 48, 169–175. [Google Scholar] [CrossRef]
- Teng, X.; Pham, H. A new methodology for predicting software reliability in the random field environments. IEEE Trans. Reliab. 2006, 55, 458–468. [Google Scholar] [CrossRef]
- Kapur, P.K.; Pham, H.; Anand, S.; Yadav, K. A unified approach for developing software reliability growth models in the presence of imperfect debugging and error generation. IEEE Trans. Reliab. 2011, 60, 331–340. [Google Scholar] [CrossRef]
- Roy, P.; Mahapatra, G.S.; Dey, K.N. An NHPP software reliability growth model with imperfect debugging and error generation. Int. J. Reliab. Qual. Saf. Eng. 2014, 21, 1–3. [Google Scholar] [CrossRef]
- Pham, H. System Software Reliability; Springer: London, UK, 2006. [Google Scholar]
- Pham, H. A new software reliability model with Vtub-Shaped fault detection rate and the uncertainty of operating environments. Optimization 2014, 63, 1481–1490. [Google Scholar] [CrossRef]
- Chang, I.H.; Pham, H.; Lee, S.W.; Song, K.Y. A testing-coverage software reliability model with the uncertainty of operation environments. Int. J. Syst. Sci.-Oper. Logist. 2014, 1, 220–227. [Google Scholar]
- Song, K.Y.; Chang, I.H.; Pham, H. A Three-parameter fault-detection software reliability model with the uncertainty of operating environments. J. Syst. Sci. Syst. Eng. 2017, 26, 121–132. [Google Scholar] [CrossRef]
- Ramasamy, S.; Lakshmanan, I. Machine learning approach for software reliability growth modeling with infinite testing effort function. Math. Probl. Eng. 2017, 8040346. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y.S.; Chang, I.H.; Lee, D.H. Non-Parametric Software Reliability Model Using Deep Neural Network and NHPP Software Reliability Growth Model Comparison. J. Korean. Data Anal. Soc. 2020, 22, 2371–2382. [Google Scholar] [CrossRef]
- Begum, M.; Hafiz, S.B.; Islam, J.; Hossain, M.J. Long-term Software Fault Prediction with Robust Prediction Interval Analysis via Refined Artificial Neural Network (RANN) Approach. Eng. Lett. 2021, 29, 1158–1171. [Google Scholar]
- Zhu, J.; Gong, Z.; Sun, Y.; Dou, Z. Chaotic neural network model for SMISs reliability prediction based on interdependent network SMISs reliability prediction by chaotic neural network. Qual. Reliab. Eng. Int. 2021, 37, 717–742. [Google Scholar] [CrossRef]
- Sahu, K.; Alzahrani, F.A.; Srivastava, R.K.; Kumar, R. Evaluating the Impact of Prediction Techniques: Software Reliability Perspective. CMC-Comput. Mat. Contin. 2021, 67, 1471–1488. [Google Scholar] [CrossRef]
- Ogundoyin, S.O.; Kamil, I.A. A Fuzzy-AHP based prioritization of trust criteria in fog computing services. Appl. Soft. Comput. 2020, 97, 106789. [Google Scholar] [CrossRef]
- Rafi, S.; Akbar, M.A.; Yu, W.; Alsanad, A.; Gumaei, A.; Sarwar, M.U. Exploration of DevOps testing process capabilities: An ISM and fuzzy TOPSIS analysis. Appl. Soft Comput. 2021, 108377. [Google Scholar] [CrossRef]
- Li, Q.; Pham, H. Modeling Software Fault-Detection and Fault-Correction Processes by Considering the Dependencies between Fault Amounts. Appl. Sci. 2021, 11, 6998. [Google Scholar] [CrossRef]
- Son, H.I.; Kwon, K.R.; Kim, J.O. Reliability Analysis of Power System with Dependent Failure. J. Korean. Inst. Illum. Electr. Install. Eng. 2011, 25, 62–68. [Google Scholar]
- Pan, Z.; Nonaka, Y. Importance analysis for the systems with common cause failures. Reliab. Eng. Syst. Saf. 1995, 50, 297–300. [Google Scholar] [CrossRef]
- Pham, L.; Pham, H. Software Reliability Models with Time Dependent Hazard Rate Based on Bayesian Approach. IEEE Trans. Syst. Man Cybern. Part A-Syst. Hum. 2000, 30, 25–35. [Google Scholar] [CrossRef]
- Lee, D.H.; Chang, I.H.; Pham, H. Software reliability model with dependent failures and SPRT. Mathematics 2020, 8, 1366. [Google Scholar] [CrossRef]
- Kim, H.C. The Property of Learning effect based on Delayed Software S-Shaped Reliability Model using Finite NHPP Software Cost Model. Indian J. Sci. Technol. 2015, 8, 1–7. [Google Scholar] [CrossRef]
- Yang, B.; Xie, M. A study of operational and testing reliability in software reliability analysis. Reliab. Eng. Syst. Saf. 2000, 70, 323–329. [Google Scholar] [CrossRef]
- Yamada, S.; Osaki, S. Cost-reliability optimal release policies for software systems. IEEE Trans. Reliab. 1985, 34, 422–424. [Google Scholar] [CrossRef]
- Singpurwalla, N.D. Determining an optimal time interval for testing and debugging software. IEEE Trans. Softw. Eng. 1991, 17, 313–319. [Google Scholar] [CrossRef]
- Song, K.Y.; Chang, I.H. A Sensitivity Analysis of a New NHPP Software Reliability Model with the Generalized Exponential Fault Detection Rate Function Considering the Uncertainty of Operating Environments. J. Korean. Data Anal. Soc. 2020, 22, 473–482. [Google Scholar]
- Li, X.; Xie, M.; Ng, S.H. Sensitivity analysis of release time of software reliability models incorporating testing effort with multiple change-points. Appl. Math. Model. 2010, 34, 3560–3570. [Google Scholar] [CrossRef]
- Stringfellow, C.; Andrews, A.A. An empirical method for selecting software reliability growth models. Empir. Softw. Eng. 2002, 7, 319–343. [Google Scholar] [CrossRef]
- Inoue, S.; Yamada, S. Discrete software reliability assessment with discretized NHPP models. Comput. Math. Appl. 2006, 51, 161–170. [Google Scholar] [CrossRef] [Green Version]
- Anjum, M.; Haque, M.A.; Ahmad, N. Analysis and ranking of software reliability models based on weighted criteria value. Int. J. Inf. Technol. Comput. Sci. 2013, 2, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Jeske, D.R.; Zhang, X. Some successful approaches to software reliability modeling in industry. J. Syst. Softw. 2005, 74, 85–99. [Google Scholar] [CrossRef]
- Iqbal, J. Software reliability growth models: A comparison of linear and exponential fault content functions for study of imperfect debugging situations. Cogent Eng. 2017, 4, 1286739. [Google Scholar] [CrossRef]
- Zhao, J.; Liu, H.W.; Cui, G.; Yang, X.Z. Software reliability growth model with change-point and environmental function. J. Syst. Softw. 2006, 79, 1578–1587. [Google Scholar] [CrossRef]
- Akaike, H. A new look at statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–719. [Google Scholar] [CrossRef]
- Pillai, K.; Nair, V.S. A model for software development effort and cost estimation. IEEE Trans. Softw. Eng. 1997, 23, 485–497. [Google Scholar] [CrossRef]
- Peng, R.; Li, Y.F.; Zhang, W.J.; Hu, Q.P. Testing effort dependent software reliability model for imperfect debugging process considering both detection and correction. Reliab. Eng. Syst. Saf. 2014, 126, 37–43. [Google Scholar] [CrossRef] [Green Version]
- Sharma, K.; Garg, R.; Nagpal, C.K.; Garg, R.K. Selection of optimal software reliability growth models using a distance based approach. IEEE Trans. Reliab. 2010, 59, 266–276. [Google Scholar] [CrossRef]
- Pham, H. On estimating the number of deaths related to Covid-19. Mathematics 2020, 8, 655. [Google Scholar] [CrossRef]
- Wang, L.; Hu, Q.; Liu, J. Software reliability growth modeling and analysis with dual fault detection and correction processes. IIE Trans. 2016, 48, 359–370. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Model | Mean Value Function | Note |
|---|---|---|---|
| 1 | Goel-Okumoto (GO) [2] | Concave | |
| 2 | Hossain-Dahiya (HDGO) [3] | Concave | |
| 3 | Yamada et al. (DS) [4] | S-Shape | |
| 4 | Ohba (IS) [5] | S-Shape | |
| 5 | Zhang et al. (ZFR) [6] | S-Shape | |
| 6 | Yamada et al. (YE) [7] | Concave | |
| 7 | Yamada et al. (YR) [7] | S-Shape | |
| 8 | Yamada et al. (YID 1) [8] | Concave | |
| 9 | Yamada et al. (YID 2) [8] | Concave | |
| 10 | Pham-Zhang (PZ) [9] | Both | |
| 11 | Pham et al. (PNZ) [10] | Both | |
| 12 | Teng-Pham (TP) [11] | S-Shape | |
| 13 | Kapur et al. (KSRGM) [12] | S-Shape | |
| 14 | Roy et al. (RMD) [13] | Concave | |
| 15 | Pham (IFD) [14] | Concave | |
| 16 | Pham (Vtub) [15] | S-Shape | |
| 17 | Chang et al. (TC) [16] | Both | |
| 18 | Song et al. (3P) [17] | S-Shape | |
| 19 | Pham (DP1) [28] | Concave, Dependent | |
| 20 | Pham (DP2) [28] | Concave, Dependent | |
| 21 | Lee et al. (DPF) [29] | S-Shape, Dependent | |
| 22 | Proposed Model | S-Shape, Dependent |
| Index | Dataset 1 | Dataset 2 | Dataset 3 | |||
|---|---|---|---|---|---|---|
| Failures | Cumulative Failures | Failures | Cumulative Failures | Failures | Cumulative Failures | |
| 1 | 14 | 14 | 11 | 11 | 90 | 90 |
| 2 | 3 | 17 | 6 | 17 | 17 | 107 |
| 3 | 4 | 21 | 0 | 17 | 19 | 126 |
| 4 | 7 | 28 | 5 | 22 | 19 | 145 |
| 5 | 7 | 35 | 5 | 27 | 26 | 171 |
| 6 | 18 | 53 | 25 | 52 | 17 | 188 |
| 7 | 8 | 61 | 10 | 62 | 1 | 189 |
| 8 | 4 | 65 | 6 | 68 | 1 | 190 |
| 9 | 2 | 67 | 2 | 70 | 0 | 190 |
| 10 | 9 | 76 | 10 | 80 | 0 | 190 |
| 11 | 1 | 77 | 0 | 80 | 2 | 192 |
| 12 | 4 | 81 | 1 | 81 | 0 | 192 |
| 13 | 0 | 192 | ||||
| 14 | 0 | 192 | ||||
| 15 | 11 | 203 | ||||
| 16 | 0 | 203 | ||||
| 17 | 1 | 204 | ||||
| No. | Model | Estimation |
|---|---|---|
| 1 | GO | , |
| 2 | HDOG | , , |
| 3 | DS | , |
| 4 | IS | , , |
| 5 | ZFR | , , , , |
| 6 | YE | , , |
| 7 | YR | , , |
| 8 | YID1 | , , |
| 9 | YID2 | , , |
| 10 | PZ | , , , |
| 11 | PNZ | , , |
| 12 | TP | , , , , , |
| 13 | KSRGM | , , |
| 14 | RMD | , , |
| 15 | IFD | , , |
| 16 | Vtub | , , , |
| 17 | TC | , , , |
| 18 | 3P | , , , |
| 19 | DP1 | , |
| 20 | DP2 | , , |
| 21 | DPF | , , |
| 22 | Proposed model | , , |
| No. | Model | MSE | MAE | Adj_R2 | PRR | PP | AIC | PRV | RMSPE | MEOP | TS | PC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | GO | 21.1918 | 4.4966 | 0.9627 | 0.4187 | 0.2758 | 80.5308 | 4.3889 | 4.3892 | 4.0878 | 7.6254 | 16.5565 |
| 2 | HDOG | 23.5465 | 4.9962 | 0.9581 | 0.4187 | 0.2758 | 82.5308 | 4.3889 | 4.3892 | 4.4966 | 7.6254 | 16.5875 |
| 3 | DS | 22.4994 | 3.8718 | 0.9604 | 9.4838 | 0.7292 | 92.7861 | 4.4119 | 4.5135 | 3.5198 | 7.8572 | 16.8558 |
| 4 | IS | 16.8528 | 3.8882 | 0.9700 | 1.4452 | 0.3769 | 80.9153 | 3.6786 | 3.7104 | 3.4994 | 6.4512 | 15.0824 |
| 5 | ZFR | 24.2415 | 5.8035 | 0.9540 | 1.2042 | 0.3441 | 86.8823 | 3.6068 | 3.6338 | 4.9744 | 6.3174 | 18.4848 |
| 6 | YE | 26.5773 | 5.6309 | 0.9519 | 0.4182 | 0.2753 | 84.5796 | 4.3963 | 4.3965 | 5.0052 | 7.6380 | 16.9984 |
| 7 | YR | 33.2210 | 5.1600 | 0.9398 | 23.6437 | 0.9460 | 103.5558 | 4.6865 | 4.8967 | 4.5867 | 8.5395 | 17.8909 |
| 8 | YID1 | 23.6037 | 4.9679 | 0.9579 | 0.4140 | 0.2764 | 82.4537 | 4.3944 | 4.3946 | 4.4711 | 7.6347 | 16.5984 |
| 9 | YID2 | 23.8374 | 5.0079 | 0.9575 | 0.4070 | 0.2771 | 82.5743 | 4.4162 | 4.4163 | 4.5071 | 7.6724 | 16.6427 |
| 10 | PZ | 217.3085 | 17.6277 | 0.5983 | 0.5816 | 1.2389 | 84.1256 | 4.7893 | 11.3435 | 15.4243 | 20.4300 | 24.8053 |
| 11 | PNZ | 4000.777 | 68.0533 | −6.2441 | 2.6223 | 10.4504 | 142.6741 | 25.7721 | 52.1779 | 60.4918 | 93.7126 | 37.0551 |
| 12 | TP | 31.0301 | 7.0496 | 0.9387 | 1.6004 | 0.3946 | 89.3412 | 3.7102 | 3.7518 | 5.8747 | 6.5247 | 21.7987 |
| 13 | KSRGM | 26.0975 | 5.4865 | 0.9527 | 1.5345 | 0.4198 | 88.8357 | 4.3440 | 4.3556 | 4.8769 | 7.5688 | 16.9255 |
| 14 | RMD | 21.9129 | 5.0225 | 0.9604 | 1.1967 | 0.3659 | 84.6918 | 3.9784 | 3.9909 | 4.4644 | 6.9355 | 16.2264 |
| 15 | IFD | 29.9616 | 5.5723 | 0.9467 | 0.653 | 0.3059 | 87.6572 | 4.9344 | 4.9498 | 5.0151 | 8.6017 | 17.6717 |
| 16 | Vtub | 18.9012 | 4.8111 | 0.9650 | 0.7591 | 0.2784 | 82.2273 | 3.4511 | 3.4667 | 4.2097 | 6.0252 | 16.2579 |
| 17 | TC | 26.6474 | 5.8343 | 0.9507 | 1.8283 | 0.4312 | 89.1447 | 4.0938 | 4.1159 | 5.1050 | 7.1541 | 17.4601 |
| 18 | 3P | 21.7357 | 5.0238 | 0.9599 | 1.4395 | 0.3767 | 84.9059 | 3.6859 | 3.7164 | 4.3958 | 6.4613 | 16.7470 |
| 19 | DP1 | 361.825 | 19.1467 | 0.3631 | 448.095 | 3.2745 | 174.8811 | 14.9748 | 17.8944 | 17.4061 | 31.5087 | 30.7442 |
| 20 | DP2 | 113.5394 | 11.4623 | 0.7945 | 0.5996 | 1.0133 | 109.7792 | 9.0867 | 9.0870 | 10.1888 | 15.7870 | 22.8067 |
| 21 | DPF | 9.9490 | 3.2278 | 0.9819 | 0.0689 | 0.0606 | 73.2850 | 2.6894 | 2.6899 | 2.8692 | 4.6732 | 13.0680 |
| 22 | Proposed model | 9.9274 | 3.2140 | 0.9821 | 0.0647 | 0.0577 | 73.4605 | 2.6866 | 2.6870 | 2.8569 | 4.6682 | 13.0594 |
| No. | Model | Estimation |
|---|---|---|
| 1 | GO | , |
| 2 | HDOG | , |
| 3 | DS | , |
| 4 | IS | , , |
| 5 | ZFR | , , , , |
| 6 | YE | , , |
| 7 | YR | , , |
| 8 | YID1 | , , |
| 9 | YID2 | , , |
| 10 | PZ | , , , |
| 11 | PNZ | , , |
| 12 | TP | , , , , , |
| 13 | KSRGM | , , |
| 14 | RMD | , , |
| 15 | IFD | , , |
| 16 | Vtub | , , , |
| 17 | TC | , , , |
| 18 | 3P | , , , |
| 19 | DP1 | , |
| 20 | DP2 | , , |
| 21 | DPF | , , |
| 22 | Proposed model | , , |
| No. | Model | MSE | MAE | Adj_R2 | PRR | PP | AIC | PRV | RMSPE | MEOP | TS | PC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | GO | 52.7922 | 6.9705 | 0.9252 | 0.4713 | 0.6631 | 113.9369 | 6.9157 | 6.9267 | 6.3369 | 11.8896 | 21.1202 |
| 2 | HDOG | 58.6580 | 7.7450 | 0.9159 | 0.4713 | 0.6631 | 115.9369 | 6.9157 | 6.9267 | 6.9705 | 11.8896 | 20.6949 |
| 3 | DS | 40.0324 | 5.9373 | 0.9433 | 8.5312 | 1.0273 | 116.8063 | 5.9998 | 6.0299 | 5.3975 | 10.3536 | 19.7368 |
| 4 | IS | 30.7961 | 5.1688 | 0.9559 | 5.1137 | 0.8444 | 102.4472 | 4.9413 | 5.0132 | 4.6519 | 8.6150 | 17.7954 |
| 5 | ZFR | 42.3215 | 7.0918 | 0.9353 | 3.2756 | 0.7195 | 104.7204 | 4.7496 | 4.8001 | 6.0787 | 8.2459 | 20.1564 |
| 6 | YE | 66.0197 | 8.6990 | 0.9038 | 0.4695 | 0.6677 | 117.922 | 6.9138 | 6.9280 | 7.7325 | 11.8923 | 20.6380 |
| 7 | YR | 4668.125 | 73.375 | −5.7994 | 4.00 × 1017 | 12.000 | 2807.273 | 28.0112 | 56.369 | 65.2222 | 100.000 | 37.6722 |
| 8 | YID1 | 58.7470 | 7.7242 | 0.91571 | 0.4677 | 0.6707 | 115.8113 | 6.9207 | 6.9319 | 6.9518 | 11.8987 | 20.7017 |
| 9 | YID2 | 58.9848 | 7.7955 | 0.91544 | 0.4730 | 0.6551 | 116.2140 | 6.9390 | 6.9463 | 7.0159 | 11.9227 | 20.7199 |
| 10 | PZ | 42.3248 | 6.7234 | 0.9371 | 11.0678 | 1.0170 | 110.5663 | 5.0554 | 5.1787 | 5.8830 | 8.9070 | 19.0795 |
| 11 | PNZ | 35.2459 | 5.7358 | 0.9486 | 6.5289 | 0.9046 | 104.9515 | 4.8955 | 5.0492 | 5.0985 | 8.6893 | 18.1275 |
| 12 | TP | 63.8102 | 10.1380 | 0.8983 | 4.8099 | 0.8346 | 112.9315 | 5.0230 | 5.3563 | 8.4484 | 9.2430 | 23.6011 |
| 13 | KSRGM | 50.5240 | 6.8779 | 0.9265 | 114.740 | 1.4819 | 135.0029 | 5.8715 | 6.0461 | 6.1137 | 10.4035 | 19.5679 |
| 14 | RMD | 49.4957 | 7.4822 | 0.9279 | 3.9839 | 0.8882 | 116.9778 | 5.9847 | 5.9985 | 6.6509 | 10.297 | 19.4857 |
| 15 | IFD | 54.1681 | 7.6923 | 0.9223 | 0.7680 | 0.6392 | 116.0510 | 6.6572 | 6.6573 | 6.9231 | 11.4255 | 20.3365 |
| 16 | Vtub | 35.2724 | 6.0531 | 0.9476 | 2.4728 | 0.6598 | 101.2283 | 4.6866 | 4.7335 | 5.2965 | 8.1311 | 18.4415 |
| 17 | TC | 50.7521 | 7.5092 | 0.9245 | 21.0460 | 1.1721 | 121.4836 | 5.5793 | 5.6745 | 6.5706 | 9.7535 | 19.7150 |
| 18 | 3P | 40.5560 | 6.8976 | 0.9397 | 4.5115 | 0.8180 | 107.3639 | 5.0151 | 5.0748 | 6.0354 | 8.7189 | 18.9300 |
| 19 | DP1 | 319.4078 | 17.5031 | 0.5477 | 219.278 | 2.8473 | 190.4276 | 14.6847 | 16.8565 | 15.9119 | 29.2453 | 30.1207 |
| 20 | DP2 | 4668.094 | 73.3747 | −5.7994 | 8.23 × 1011 | 11.9998 | 5,039.181 | 28.0112 | 56.3689 | 65.2219 | 99.9997 | 37.6722 |
| 21 | DPF | 19.0466 | 4.3652 | 0.9722 | 0.1630 | 0.1495 | 92.2767 | 3.7212 | 3.7218 | 3.8802 | 6.3876 | 15.6657 |
| 22 | Proposed model | 18.9722 | 4.3544 | 0.9723 | 0.1615 | 0.1482 | 92.2155 | 3.7139 | 3.7145 | 3.8706 | 6.3751 | 15.6500 |
| No. | Model | Estimation |
|---|---|---|
| 1 | GO | , |
| 2 | HDOG | , , |
| 3 | DS | , |
| 4 | IS | , , |
| 5 | ZFR | , , , , |
| 6 | YE | , , |
| 7 | YR | , , |
| 8 | YID1 | , , |
| 9 | YID2 | , , |
| 10 | PZ | , , , , |
| 11 | PNZ | , , |
| 12 | TP | , , , , , |
| 13 | KSRGM | , , |
| 14 | RMD | , , |
| 15 | IFD | , , |
| 16 | Vtub | , , , |
| 17 | TC | , , , |
| 18 | 3P | , , , |
| 19 | DP1 | , |
| 20 | DP2 | , , |
| 21 | DPF | , , |
| 22 | Proposed model | , , |
| No. | Model | MSE | MAE | Adj_R2 | PRR | PP | AIC | PRV | RMSPE | MEOP | TS | PC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | GO | 80.6779 | 6.9602 | 0.9301 | 0.1705 | 0.1013 | 184.3314 | 8.6734 | 8.6955 | 6.5252 | 4.7492 | 34.1231 |
| 2 | HDOG | 86.4370 | 7.4526 | 0.9247 | 0.1714 | 0.1015 | 186.2332 | 8.6705 | 8.6951 | 6.9558 | 4.7491 | 33.2854 |
| 3 | DS | 232.628 | 9.5029 | 0.7982 | 1.2915 | 0.3330 | 331.8567 | 14.6423 | 14.7605 | 8.9090 | 8.0644 | 42.0654 |
| 4 | IS | 86.4395 | 7.4550 | 0.9247 | 0.1706 | 0.1013 | 186.3337 | 8.6711 | 8.6953 | 6.9580 | 4.7492 | 33.2856 |
| 5 | ZFR | 111.138 | 9.4352 | 0.9010 | 0.1837 | 0.1047 | 193.0813 | 8.7023 | 8.7388 | 8.6489 | 4.7734 | 32.2423 |
| 6 | YE | 79.3698 | 8.1539 | 0.9304 | 0.0993 | 0.0738 | 167.3203 | 8.0202 | 8.0298 | 7.5715 | 4.3853 | 31.6111 |
| 7 | YR | 378.666 | 12.8708 | 0.6679 | 2.7655 | 0.4685 | 523.3189 | 17.3551 | 17.5296 | 11.9514 | 9.5785 | 41.7676 |
| 8 | YID1 | 78.8312 | 7.1635 | 0.9313 | 0.1282 | 0.0868 | 157.6388 | 8.2937 | 8.3046 | 6.6860 | 4.5353 | 32.6406 |
| 9 | YID2 | 78.8367 | 7.1869 | 0.9313 | 0.1276 | 0.0866 | 157.8252 | 8.2915 | 8.3047 | 6.7078 | 4.5355 | 32.6411 |
| 10 | PZ | 100.990 | 8.6962 | 0.9108 | 0.1719 | 0.1017 | 190.3321 | 8.6767 | 8.7014 | 8.0272 | 4.7525 | 32.2669 |
| 11 | PNZ | 84.9077 | 7.7388 | 0.9256 | 0.1281 | 0.0867 | 159.8744 | 8.2915 | 8.3049 | 7.1860 | 4.5356 | 32.0493 |
| 12 | TP | 98.6971 | 10.573 | 0.9113 | 0.0740 | 0.0626 | 166.0911 | 7.8528 | 7.8540 | 9.6118 | 4.2889 | 31.5071 |
| 13 | KSRGM | 111.132 | 8.1738 | 0.9025 | 0.2521 | 0.1297 | NA | 9.4631 | 9.5000 | 7.5900 | 5.1890 | 33.7990 |
| 14 | RMD | 93.1051 | 8.0261 | 0.9184 | 0.1714 | 0.1015 | 188.2567 | 8.6714 | 8.6960 | 7.4528 | 4.7496 | 32.6486 |
| 15 | IFD | 3691.538 | 60.2705 | −2.2183 | 24.7762 | 2.5036 | 466.1166 | 51.3584 | 56.5265 | 56.2524 | 31.0359 | 59.5661 |
| 16 | Vtub | 28.6529 | 5.2313 | 0.9747 | 0.0094 | 0.0090 | Inf | 4.6356 | 4.6357 | 4.8289 | 2.5315 | 24.7084 |
| 17 | TC | 72.2812 | 8.5966 | 0.9361 | 0.0521 | 0.0479 | 158.9319 | 7.3621 | 7.3628 | 7.9353 | 4.0207 | 30.2602 |
| 18 | 3P | 81.0554 | 8.8835 | 0.9284 | 0.0731 | 0.0614 | 164.5417 | 7.7935 | 7.7967 | 8.2001 | 4.2577 | 30.9476 |
| 19 | DP1 | 11,068.48 | 101.169 | −8.6006 | 9,218.87 | 6.8842 | 1224.361 | 78.7966 | 100.6555 | 94.8460 | 55.6271 | 71.0335 |
| 20 | DP2 | 12,760.68 | 116.690 | −10.191 | 11,546.76 | 6.8801 | 1248.593 | 78.7816 | 100.6144 | 108.3548 | 55.6039 | 64.6312 |
| 21 | DPF | 26.8104 | 4.9195 | 0.9765 | 0.0096 | 0.0092 | NA | 4.6673 | 4.6673 | 4.5682 | 2.5487 | 24.5565 |
| 22 | Proposed model | 26.8047 | 4.9209 | 0.9765 | 0.0096 | 0.0092 | NA | 4.6668 | 4.6668 | 4.5694 | 2.5484 | 24.5551 |
| Base | x = 2 | x = 4 | x = 6 | x = 8 | x = 10 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| T* | C(T) | T* | C(T) | T* | C(T) | T* | C(T) | T* | C(T) | |
| 18.2 | 4886.985 | 18.3 | 4888.735 | 18.3 | 4888.856 | 18.3 | 4888.863 | 18.3 | 4888.863 | |
| C0 | x = 2 | x = 4 | x = 6 | x = 8 | x = 10 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| T* | C(T) | T* | C(T) | T* | C(T) | T* | C(T) | T* | C(T) | |
| 300 | 18.2 | 4686.985 | 18.3 | 4688.735 | 18.3 | 4688.856 | 18.3 | 4688.863 | 18.3 | 4688.863 |
| 500 | 18.2 | 4886.985 | 18.3 | 4888.735 | 18.3 | 4888.856 | 18.3 | 4888.863 | 18.3 | 4888.863 |
| 700 | 18.2 | 5086.985 | 18.3 | 5088.735 | 18.3 | 5088.856 | 18.3 | 5088.863 | 18.3 | 5088.863 |
| 10 | 18.9 | 4702.044 | 19.0 | 4702.818 | 19.0 | 4702.864 | 19.0 | 4702.866 | 19.0 | 4702.866 |
| 20 | 18.2 | 4886.985 | 18.3 | 4888.735 | 18.3 | 4888.856 | 18.3 | 4888.863 | 18.3 | 4888.863 |
| 30 | 17.8 | 5066.820 | 17.9 | 5069.652 | 17.9 | 5069.861 | 17.9 | 5069.873 | 17.9 | 5069.874 |
| 30 | 18.2 | 3285.254 | 18.3 | 3286.995 | 18.3 | 3287.116 | 18.3 | 3287.123 | 18.3 | 3287.123 |
| 40 | 18.2 | 4086.120 | 18.3 | 4087.865 | 18.3 | 4087.986 | 18.3 | 4087.993 | 18.3 | 4087.993 |
| 50 | 18.2 | 4886.985 | 18.3 | 4888.735 | 18.3 | 4888.856 | 18.3 | 4888.863 | 18.3 | 4888.863 |
| 60 | 18.2 | 5687.851 | 18.3 | 5689.604 | 18.3 | 5689.726 | 18.3 | 5689.733 | 18.3 | 5689.733 |
| 5000 | 18.2 | 4886.985 | 18.3 | 4888.735 | 18.3 | 4888.856 | 18.3 | 4888.863 | 18.3 | 4888.863 |
| 7000 | 18.5 | 4893.210 | 18.6 | 4894.846 | 18.6 | 4894.958 | 18.6 | 4894.964 | 18.6 | 4894.964 |
| 10,000 | 18.9 | 4899.648 | 19.0 | 4901.186 | 19.0 | 4901.277 | 19.0 | 4901.281 | 19.0 | 4901.282 |
| 15,000 | 19.2 | 4906.802 | 19.3 | 4908.208 | 19.3 | 4908.297 | 19.3 | 4908.301 | 19.3 | 4908.301 |
| 20.4 | 4129.849 | 19.2 | 4507.887 | 18.3 | 4888.856 | 17.6 | 5272.215 | 16.8 | 5657.258 | |
| 22.6 | 4979.801 | 20.0 | 4929.426 | 18.3 | 4888.856 | 16.8 | 4855.545 | 15.4 | 4827.546 | |
| 16.4 | 4847.806 | 17.4 | 4869.089 | 18.3 | 4888.856 | 19.2 | 4907.319 | 20.0 | 4924.648 | |
| 18.6 | 4892.931 | 18.4 | 4890.757 | 18.3 | 4888.856 | 18.2 | 4887.130 | 18.2 | 4885.583 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.S.; Song, K.Y.; Pham, H.; Chang, I.H. A Software Reliability Model with Dependent Failure and Optimal Release Time. Symmetry 2022, 14, 343. https://doi.org/10.3390/sym14020343
Kim YS, Song KY, Pham H, Chang IH. A Software Reliability Model with Dependent Failure and Optimal Release Time. Symmetry. 2022; 14(2):343. https://doi.org/10.3390/sym14020343
Chicago/Turabian StyleKim, Youn Su, Kwang Yoon Song, Hoang Pham, and In Hong Chang. 2022. "A Software Reliability Model with Dependent Failure and Optimal Release Time" Symmetry 14, no. 2: 343. https://doi.org/10.3390/sym14020343