
An Efficient Deep Unsupervised Domain Adaptation for Unknown Malware Detection


Abstract
:1. Introduction
- A deep residual network with a self-attention module is used to extract features from multi-channels.
- We adopt the joint distribution alignment approach to reduce the distribution discrepancy. Firstly, inter-domain distribution discrepancy is reduced by adversarial learning. After that, class-level alignment can be achieved by optimizing the semantic alignment loss functions. Eventually, we can achieve intra-class sample compactness and inter-class sample separation.
- By the proposed model, massive experiments are done on two public malware datasets. Experimental findings show that the model can correctly classify unknown malware and has better accuracy than the existing detection models.
2. Related Work
2.1. Machine Learning-Based Malware Detection
2.2. Transfer Learning-Based Malware Detection
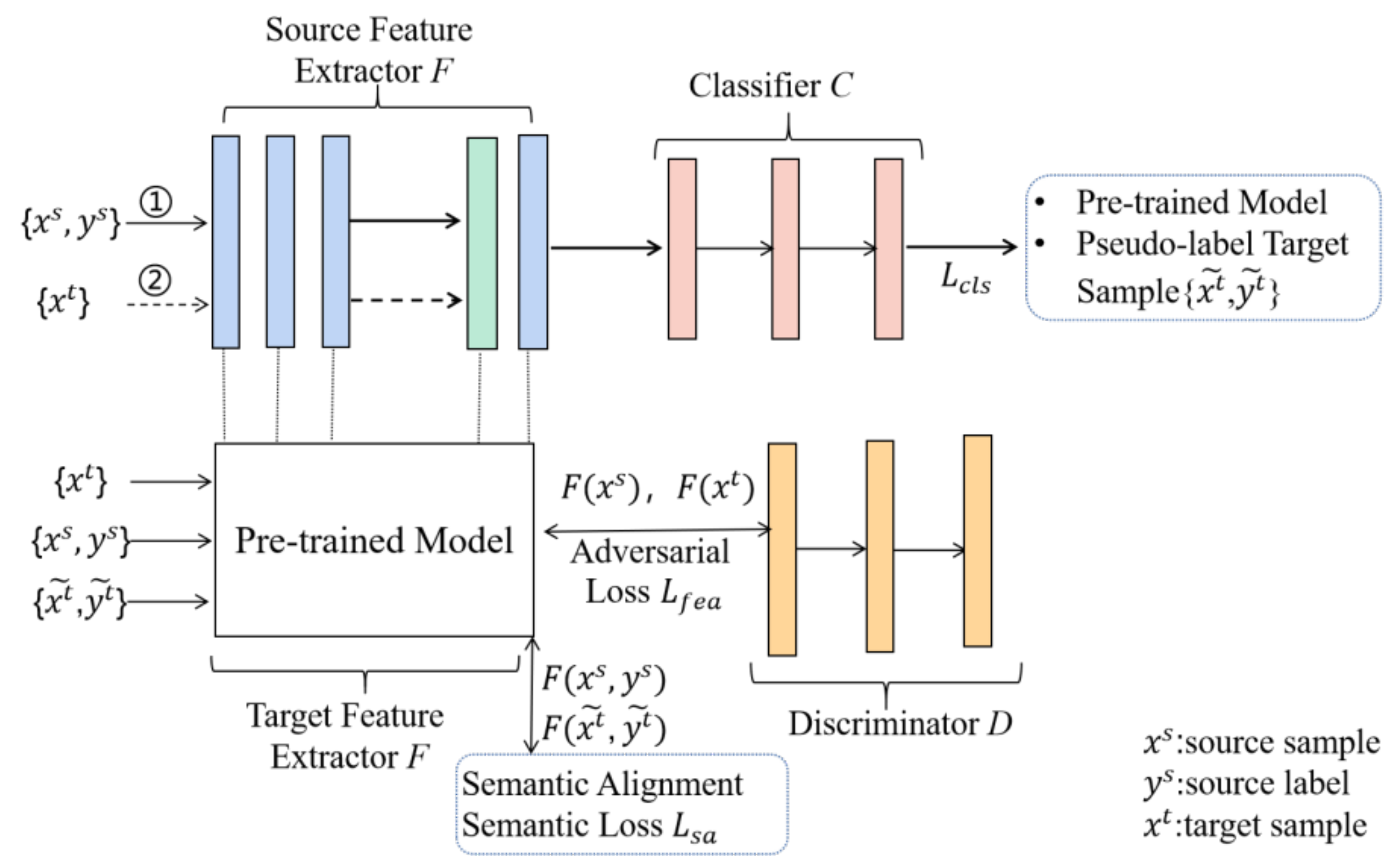
3. Method Description
3.1. Overview
3.2. Self-Attention Module
3.3. Global Domain Alignment
3.4. Semantic Alignment
3.5. Model Training
| Algorithm 1 Training of our model |
| Input: Source domain: , Target domain: , Pseudo-label: . Output,,. Initialize: 1: While do 2: Sample mini batch ds, dt and construct a batch in DS, Dt do 3: for t = 1 to batchsize do 4: Use ds to compute source domain class Center cs and ct←cs. 5: Compute Δcj by Equation (6) and update class 6: Compute semantic alignment loss by Equation (4). 7: Compute joint loss function 8: Back propagate to get the gradient value of each parameter 9: The parameter is updated by gradient descent with Adam optimizer 10: end for 11: Calculate mean loss and mean accuracy 12: end while |
4. Experiment and Result Analysis
4.1. Experimental Settings
4.1.1. Dataset
4.1.2. Implementation Details
4.1.3. Evaluation Metrics
4.2. Performance Comparison of Different Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Malware Statistics [EB/OL]. Available online: https://www.av-test.org/en/statistics/malware/ (accessed on 1 January 2022).
- Jung, B.H.; Bae, S.I.; Choi, C.; Im, E.G. Packer identification method based on byte sequences. Concurr. Comput. Pract. Exp. 2020, 32, e5082. [Google Scholar] [CrossRef]
- Yuan, Z.; Lu, Y.; Xue, Y. Droiddetector: Android malware characterization and detection using deep learning. Tsinghua Sci. Technol. 2016, 21, 114–123. [Google Scholar] [CrossRef]
- Shijo, P.V.; Salim, A. Integrated static and dynamic analysis for malware detection. Procedia Comput. Sci. 2015, 46, 804–881. [Google Scholar] [CrossRef] [Green Version]
- Imran, M.; Afzal, M.T.; Qadir, M.A. Using hidden markov model for dynamic malware analysis: First impressions. In Proceedings of the 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; pp. 816–821. [Google Scholar]
- Damodaran, A.; Di Troia, F.; Visaggio, C.A.; Austin, C.A.; Stamp, M. A comparison of static, dynamic, and hybrid analysis for malware detection. J. Comput. Virol. Hacking Tech. 2017, 13, 1–12. [Google Scholar] [CrossRef]
- Vasan, D.; Alazab, M.; Wassan, S.; Naeem, H.; Safaei, B.; Zheng, Q. IMCFN: Image-based malware classification using fine-tuned convolutional neural network architecture. Comput. Netw. 2020, 171, 107–138. [Google Scholar] [CrossRef]
- Rafique, M.F.; Ali, M.; Qureshi, A.S.; Khan, A.; Mirza, A.M. Malware Classification using Deep Learning based Feature Extraction and Wrapper based Feature Selection Technique. arXiv 2019, arXiv:1910.10958. [Google Scholar]
- Vasan, D.; Alazab, M.; Wassan, S.; Naeem, H.; Safaei, B.; Zheng, Q. Image-based malware classification using ensemble of CNN architectures (IMCEC). Comput. Secur. 2020, 92, 101748. [Google Scholar] [CrossRef]
- Catak, F.O.; Ahmed, J.; Sahinbas, K.; Khand, Z.H. Data augmentation-based malware detection using convolutional neural networks. PeerJ Comput. Sci. 2021, 7, e346. [Google Scholar] [CrossRef]
- Arora, A.; Peddoju, S.K.; Chouhan, V.; Chaudhary, A. Hybrid Android malware detection by combining supervised and unsupervised learning. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, New York, NY, USA, 15 October 2018; pp. 798–800. [Google Scholar]
- Wilson, G.; Cook, D.J. A survey of unsupervised deep domain adaptation. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–46. [Google Scholar] [CrossRef] [PubMed]
- Nataraj, L.; Yegneswaran, V.; Porras, P. A comparative assessment of malware classification using binary texture analysis and dynamic analysis. In Proceedings of the ACM Conference on Computer and Communications Security, New York, NY, USA, 21 October 2011; pp. 21–30. [Google Scholar]
- Naeem, H.; Guo, B.; Naeem, R.M. A light-weight malware static visual analysis for IoT infrastructure. In Proceedings of the 2018 International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu China, 26–28 May 2018; pp. 240–244. [Google Scholar]
- Yan, J.; Qi, Y.; Rao, Q. Detecting malware with an ensemble method based on deep neural network. Secur. Commun. Netw. 2018, 2018, 7247095. [Google Scholar] [CrossRef] [Green Version]
- Alom, M.Z.; Taha, T.M. Network intrusion detection for cyber security using unsupervised deep learning approaches. In Proceedings of the 2017 IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 27–30 June 2017; pp. 63–69. [Google Scholar]
- Pitolli, G.; Laurenza, G.; Aniello, L.; Querzoni, L.; Baldoni, R. MalFamAware: Automatic family identification and malware classification through online clustering. Int. J. Inf. Secur. 2021, 20, 371–386. [Google Scholar] [CrossRef]
- Moti, Z.; Hashemi, S.; Namavar, A. Discovering future malware variants by generating new malware samples using generative adversarial network. In Proceedings of the 9th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 24–25 October 2019; pp. 319–324. [Google Scholar]
- Sun, Q.; Liu, Y.; Chua, T.S.; Schiele, B. Meta-transfer learning for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 403–412. [Google Scholar]
- Pathak, Y.; Shukla, P.K.; Tiwari, A.; Stalin, S.; Singh, S. Deep transfer learning-based classification model for COVID-19 disease. IRBM, 2020; online ahead of print. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Feng, W.; Yu, H.; Huang, M.; Yang, Q. Transfer learning with dynamic distribution adaptation. ACM Trans. Intell. Syst. Technol. (TIST) 2020, 11, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Neyshabur, B.; Sedghi, H.; Zhang, C. What is being transferred in transfer learning? arXiv 2020, arXiv:2008.11687. [Google Scholar]
- Celik, Y.; Talo, M.; Yildirim, O.; Karabatak, M.; Acharya, U.R. Automated invasive ductal carcinoma detection based using deep transfer learning with whole-slide images. Pattern Recognit. Lett. 2020, 33, 232–239. [Google Scholar] [CrossRef]
- Rezende, E.; Ruppert, G.; Carvalho, T.; Theophilo, A.; Ramos, F.; Geus, P. Malicious software classification using VGG16 deep neural network’s bottleneck features. Adv. Intell. Syst. Comput. 2018, 738, 51–59. [Google Scholar]
- Cui, B.; Chen, X.; Lu, Y. Semantic segmentation of remote sensing images using transfer learning and deep convolutional neural network with dense connection. IEEE Access 2020, 8, 116744–116755. [Google Scholar] [CrossRef]
- Sorocky, M.J.; Zhou, S.; Schoellig, A.P. Experience selection using dynamics similarity for efficient multi-source transfer learning between robots. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 2739–2745. [Google Scholar]
- Bartos, K.; Sofka, M.; Franc, V. Optimized invariant representation of network traffic for detecting unseen malware variants. In Proceedings of the 25th USENIX Security Symposium, USENIX, Austin, TX, USA, 10–12 August 2016; pp. 807–822. [Google Scholar]
- Li, H.; Chen, Z.; Spolaor, R. Dart: Detecting unseen malware variants using adaptation regularization transfer learning. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 1 May 2019; pp. 1–6. [Google Scholar]
- Rong, C.; Gou, G.; Cui, M.; Xiong, G.; Li, Z.; Guo, L. TransNet: Unseen malware variants detection using deep transfer learning. Lect. Notes Inst. Comput. Sci. 2020, 336, 84–101. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. arXiv 2019, arXiv:1805.08318v2. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, J.; Chen, J.; Shi, Z.; Wu, W.; He, Q. Multi-representation adaptation network for cross-domain image classification. Neural Netw. 2019, 119, 214–221. [Google Scholar] [CrossRef]
- Zhuang, F.; Cheng, X.; Luo, P.; Pan, S.J.; He, Q. Supervised representation learning: Transfer learning with deep autoencoders. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Palo Alto, CA, USA, 27 June 2015; pp. 4119–4125. [Google Scholar]
- Sun, B.; Feng, J.; Saenko, K. Return of frustratingly easy domain adaptation. In Proceedings of the Thirtieth Conference on Artificial Intelligence, Phoenix, AZ, USA, 2 March 2016; pp. 2058–2065. [Google Scholar]
- Courty, N.; Flamary, R.; Tuia, D.; Rakotomamonjy, A. Optimal transport for domain adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1853–1865. [Google Scholar] [CrossRef] [PubMed]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial discriminative domain adaptation. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2962–2971. [Google Scholar]
- Weston, J.; Ratle, F.; Mobahi, H.; Collobert, R. Deep learning via semi-supervised embedding. In Neural Networks: Tricks of the Trade 2012; Montavon, G., Orr, G.B., Eds.; Springer Press: Berlin/Heidelberg, Germany, 2012; Volume 7700, pp. 639–655. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Eds.; Springer: Cham, Switzerland, 2016; Volume 9911, pp. 499–515. [Google Scholar]
- Ficco, M. Detecting IoT malware by Markov chain behavioral models. In Proceedings of the 2019 IEEE International Conference on Cloud Engineering (IC2E), Prague, Czech Republic, 24–27 June 2019; pp. 229–234. [Google Scholar]
- Moustafa, N.; Slay, J.; Creech, G. Novel geometric area analysis technique for anomaly detection using trapezoidal area estimation on large-scale networks. IEEE Trans. Big Data 2017, 5, 481–494. [Google Scholar] [CrossRef]
- Zhao, Y.; Cui, W.; Geng, S.; Bo, B.; Feng, Y.; Zhang, W. A malware detection method of code texture visualization based on an improved faster RCNN combining transfer learning. IEEE Access 2020, 8, 166630–166641. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Family | Class | Family |
|---|---|---|---|
| 1 | Virus | Ramnit | 1541 |
| 2 | Trojan | Vundo | 475 |
| 3 | Trojan | Lollipop | 2478 |
| 4 | Trojan | Gatak | 1013 |
| 5 | Botnet | Simda | 42 |
| 6 | Malware Attack | Traceur | 751 |
| 7 | Trojan | Kelihos_ver1 | 398 |
| 8 | Trojan | Kelihos_ver3 | 2942 |
| 9 | Trojan Downloader | Obfuscator.ACY | 1228 |
| No. | Family | Samples | No. | Family | Samples |
|---|---|---|---|---|---|
| 1 | Yuner.A | 800 | 14 | Instantaccess | 431 |
| 2 | Wintrim.BX | 97 | 15 | Fakerean | 381 |
| 3 | VB.AT | 408 | 16 | Dontovo.A | 162 |
| 4 | Swizzor.gen!I | 132 | 17 | Dialplatform.B | 177 |
| 5 | Swizzor.gen!E | 128 | 18 | C2LOP.P | 146 |
| 6 | Skintrim.N | 80 | 19 | C2LOP.gen!g | 200 |
| 7 | Rbot!gen | 158 | 20 | Autorun.K | 106 |
| 8 | Obfuscator.AD | 142 | 21 | Alueron.gen!J | 198 |
| 9 | Malex.gen!J | 136 | 22 | Allaple.L | 1591 |
| 10 | Lolyda.AT | 159 | 23 | Allaple.A | 2949 |
| 11 | Lolyda.AA3 | 123 | 24 | Agent.FYI | 116 |
| 12 | Lolyda.AA2 | 184 | 25 | Adialer.C | 122 |
| 13 | Lolyda.AA1 | 213 | 26 | Total | 9339 |
| Method | Accuracy | Recall | Precision | F1-Score |
|---|---|---|---|---|
| BIRCH [17] | 95.02% | 90.2% | 95.2% | 92.3% |
| DART [28] | 93.9% | 91.2% | 89.8% | 90.0% |
| GAA-ADS [39] | 92.8% | 91.3% | - | - |
| RCNN+Transfer Learning [40] | 92.8% | - | 95.6% | - |
| Proposed method (Malimg) | 95.63 | 95.30% | 95.34% | 94.98% |
| Proposed method (BIG-2015) | 95.04% | 94.25% | 95.10% | 94.65% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Chai, G.; Li, Q.; Wang, C. An Efficient Deep Unsupervised Domain Adaptation for Unknown Malware Detection. Symmetry 2022, 14, 296. https://doi.org/10.3390/sym14020296
Wang F, Chai G, Li Q, Wang C. An Efficient Deep Unsupervised Domain Adaptation for Unknown Malware Detection. Symmetry. 2022; 14(2):296. https://doi.org/10.3390/sym14020296
Chicago/Turabian StyleWang, Fangwei, Guofang Chai, Qingru Li, and Changguang Wang. 2022. "An Efficient Deep Unsupervised Domain Adaptation for Unknown Malware Detection" Symmetry 14, no. 2: 296. https://doi.org/10.3390/sym14020296