1. Introduction
Many problems in number theory and computer arithmetic play important roles in cryptography. Examples of such problems are the generation of prime numbers [
1,
2,
3], primality testing [
4,
5], modular exponentiation [
6], addition chains and sequences [
7,
8] and integer factorization [
9,
10,
11,
12]. Developing fast algorithms that address these problems is one of the main challenges of algorithm complexity and leads to significant improvements in various applications.
The research in this paper focuses on generating primes. Given an integer number m, the objective is to find all prime numbers p such that 1 <
p ≤
m, where a number
p is prime if and only if it has only two divisors, 1 and
p. There are many crucial applications [
13,
14,
15,
16,
17] for generating a prime number or all prime numbers up to an integer m, for example:
Creating one or more large primes is a step in the key generation algorithms of some asymmetric key cryptosystems, such as the Rivest, Shamir and Adleman (RSA) cryptosystem [
13]; protocols, such as the Diffie–Hellman exchange protocol [
14]; and digital signature algorithms, such as ElGamal [
15].
Error-correcting codes are defined over the Galois field of prime power order [
17], where Galois’ theory originated in the study of symmetric functions, i.e., the coefficients of a monic polynomial are the elementary symmetric polynomials in the roots.
The security of many asymmetric key cryptosystems, such as RSA, is based on factoring a large composite (nonprime) integer into its prime factors. One efficient method to find a small prime factor for any composite integer is by using prime sieving.
Several algorithms have been proposed to generate prime numbers up to an integer m using different techniques and platforms. The sieve of Eratosthenes, set theory, and wheel factorization are all examples of different ways to generate prime numbers up to the integer m. On the other hand, different platforms are used to design the solution, such as sequential and parallel computers.
The oldest and simplest algorithm to generate prime numbers up to an integer
m is the sieve of Eratosthenes [
1]. The algorithm works by repeatedly marking the multiples of each prime as a composite number, beginning with the first prime number, 2. There are two main disadvantages of the Eratosthenes sieve algorithm. First, the run time of the algorithm is not linear,
O(
m log log
m). Second, the algorithm uses a large storage size,
O(
m).
Based on the two disadvantages of the Eratosthenes sieve algorithm, different algorithms have been proposed. Some of these algorithms [
18,
19,
20,
21,
22] reduced the running time to a linear time by testing each composite number exactly once. Marison [
18], theoretically, reduced the time complexity of prime sieving using a double linked list. In [
19], the authors achieved linear time complexity based on assuming that the multiplication of integers that are less than or equal to
m can be performed in a constant time. The Pritchard sieve [
20] avoided considering near-composite numbers by generating gradually larger wheels that represent the sequence of numbers that are not divisible by any of the primes already processed. In [
21], the author introduced a practical improvement on the Eratosthenes sieve algorithm. In [
22], the author reduced the time of the sieving algorithm to a sublinear time using the wheel method.
Another technique for improving the prime sieve is the segmented sieve [
23,
24,
25,
26], which aims to reduce the memory consumption of the sieve method. The technique is based on dividing the range, 2 to
m, into
m/∆ subintervals, each of size ∆. Then, the method sieves one subinterval at a time by marking the multiples of each prime in the subinterval. Experimentally, the value of ∆ is equal to
In [
26], the author reduced the memory consumption to
O(
m1/3 (
log m)
2/3) as a theoretical study.
Recently, in 2021, the authors of [
1] proposed an algorithm based on set theory to generate a set of all prime numbers less than or equal to an integer
. The proposed algorithm outperforms the Eratosthenes and Sundaram algorithms in their run time, where the Sundaram sieve algorithm has a weaker performance than the Eratosthenes sieve algorithm [
1].
On the other hand, there are several parallel implementations for prime sieve algorithms. In [
27], two different distributed sieves of Eratosthenes algorithms on a hypercube computer, NCUBE/10, were introduced. Sorenson and Parberry [
28] presented and analyzed two theoretical parallel sieve algorithms on an exclusive read exclusive write parallel random-access machine. The authors of [
29] presented a parallel version of the Eratosthenes sieve algorithm on a cluster machine consisting of eight nodes. The proposed algorithm uses static and dynamic strategies to achieve load balancing between the processors. Two distributed algorithms were theoretically proposed in [
2,
30]. They are based on scheduling by a multiple edge reversal (SMER) graph and the wheel technique.
For three reasons, the work in this paper is based on the algorithm proposed by Abd-Elnaby and El-Baz [
1], denoted as the AE algorithm. First, the AE algorithm is a recent algorithm that was published in 2021. Second, Abd-Elnaby and El-Baz showed that the AE algorithm is more efficient in its run time than the Eratosthenes and Sundaram algorithms by 81% and 97%, respectively [
1]. Third, there is no parallel algorithm for the AE algorithm. In addition, the main drawback of this algorithm is that its run time and storage are high when the size of
m is large.
In light of the above reasons, this paper introduces three algorithms for prime sieving based on two different platforms: sequential and multicore systems. The first algorithm is sequential. The other two algorithms are parallel. The experimental results of implementing the AE algorithm and the three proposed algorithms on different data sets show the following contributions.
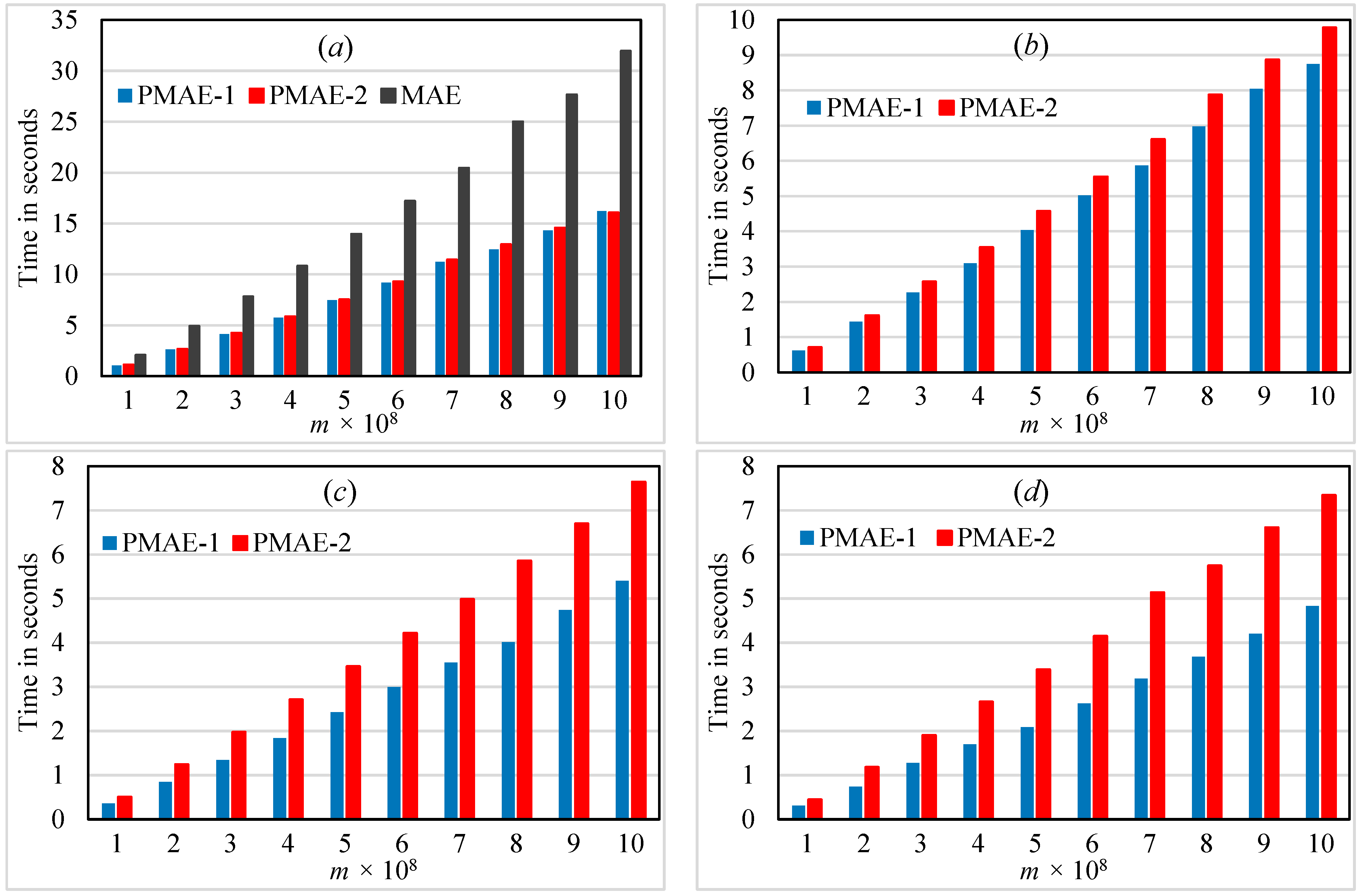
The proposed sequential algorithm (
Section 3) is more efficient than the AE algorithm by 98% on average.
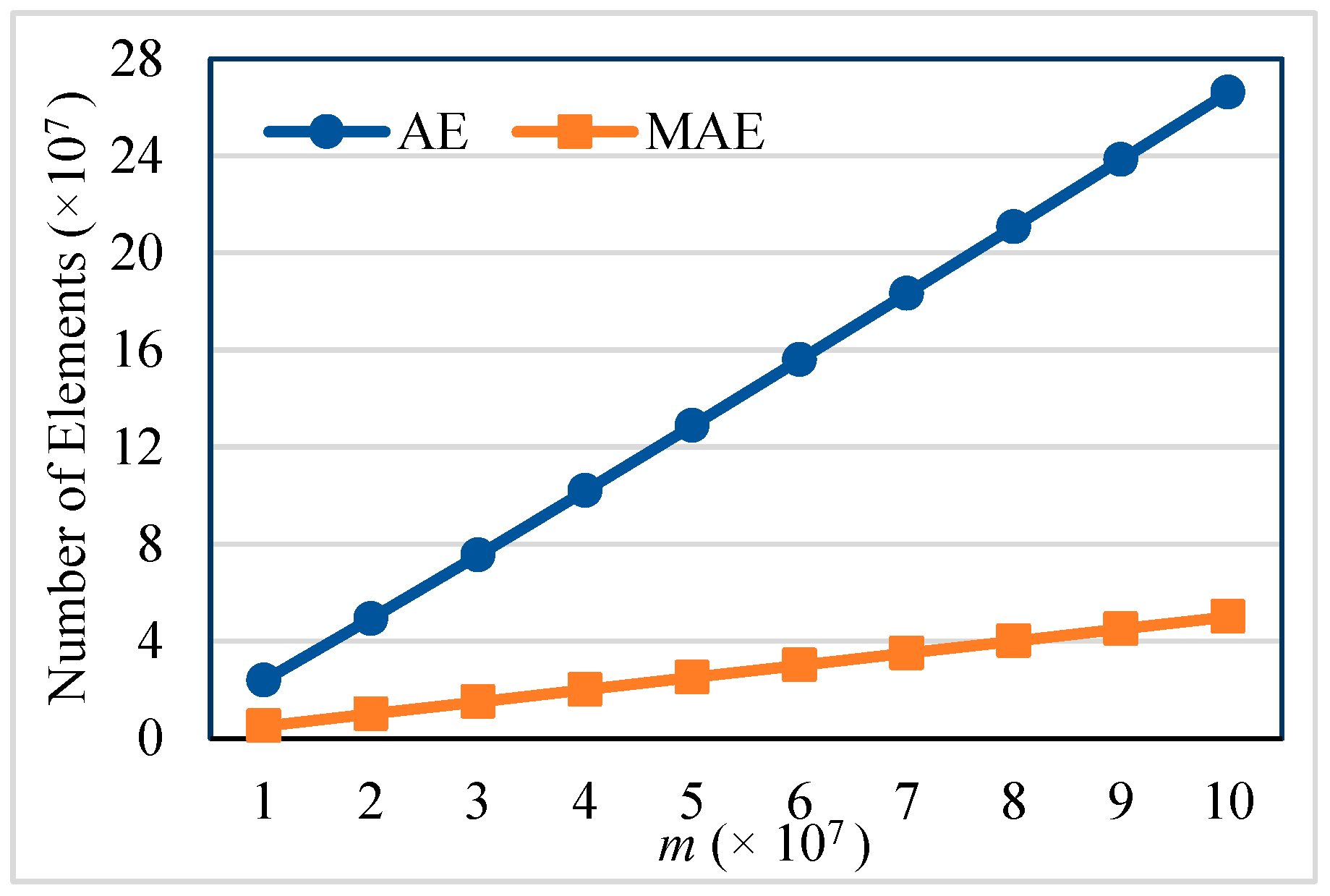
The proposed sequential algorithm reduces the memory consumption used by the AE algorithm by 80% on average.
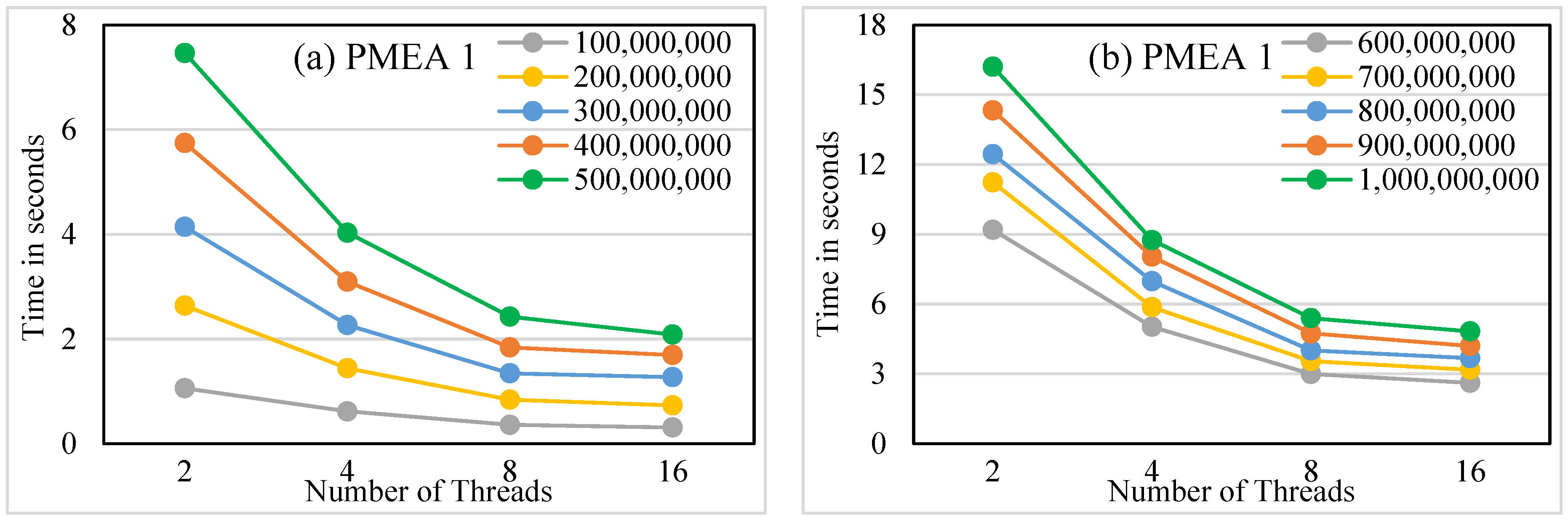
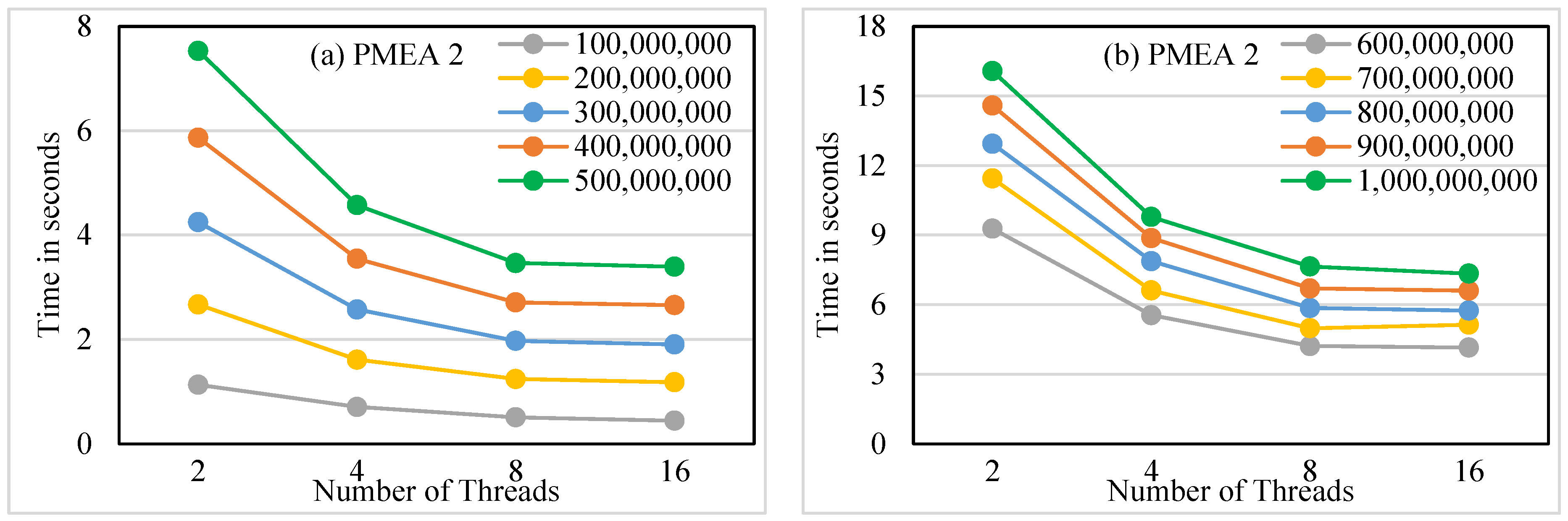
The two proposed parallel algorithms are more efficient than the proposed sequential algorithm by 72% and 67%, respectively, on average. The proposed parallel algorithms are scalable.
The structure of the paper consists of an introduction and five sections. In
Section 2, the AE algorithm is described. The first proposed algorithm for a single processor is presented in
Section 3. In
Section 4, two parallel algorithms for prime sieving are introduced. The experimental studies for the three proposed algorithms are presented in
Section 5. Finally,
Section 6 contains the conclusion and open research questions.
3. The Proposed Sequential Algorithm
This section describes the main idea behind the new prime sieve sequential algorithm. This section also presents the pseudocode of the proposed algorithm that aims to reduce the amount of time and storage for the AE algorithm.
3.1. Main Idea
The AE algorithm consists of four main steps, and the proposed algorithm focuses on modifying these steps.
For Step 1, there is no need to store the odd numbers 2i + 1 into array B. Initially, all odd numbers can be marked as a prime number by setting the value 1 at position i in array B, where position number i represents an odd number 2i + 1.
For Step 2, the value of
k, which is used for Step 3, can be computed in a single statement without making a loop as follows. The while loop of Step 2 terminates when
Therefore, the question now is as follows: what is the value of
k that satisfies inequality (3)? The value of
k can be computed by solving inequality (3), as follows:
Therefore, instead of computing k by executing a number of iterations, the value of k is computed directly by inequality (4). The main advantage of this modification is reducing the computation time from = to O(1).
For Step 3, the AE algorithm collects all multiples of the prime numbers and assigns them to the auxiliary array X. This step can be modified by ignoring the collection of these numbers, multiples of primes, in array X, so there is no need to use array X. Thus, array B can be modified directly as follows.
Since the integer is odd but not prime, and since the location of this integer in array B is , the algorithm marks the integer as a composite number by modifying array B directly, as follows: .
The main advantages of this modification are as follows.
Reducing the auxiliary storage by a factor = in the worst case. The worst case occurs when . Therefore, the storage of the modified AE algorithm is reduced by a factor O(|A|+|X|).
Reducing the run time of assigning array X to the auxiliary array A (see Line 12 in Algorithm 1).
There is no need to compute the difference between the two arrays as in Step 4 (see Line 14 in Algorithm 1).
For Step 4, the AE algorithm computes the difference between two arrays. The first array B contains all odd numbers, and the other array X represents all nonprime odd numbers.
Based on the improvement in Step 3, all prime numbers are found by the following simple test: if the value of B[i] does not change to 0, i.e., B[i] = 1, then the integer 2i + 1 is prime, and thus the algorithm stores the integer 2i + 1 to the output set P. Otherwise, the algorithm ignores the integer 2i + 1. The pseudocode for this step is as follows: if B[i] = 1, then P[j++] = 2i + 1, where j represents the location of the prime number 2i + 1 at the array P and starts with 1.
The main advantage of this step is reducing the time from to if A is a sorted array in the best case; otherwise, the time is reduced from to .
3.2. The Algorithm
From the previous comments on the AE algorithm and the suggested improvements, the pseudocode of the modified AE algorithm, denoted as MAE, is given in Algorithm 2. Steps 1, 2, 3 and 4 represent Lines 1–2, 3, 4–9 and 10–14, respectively.
| Algorithm 2: MAE. |
| Input: A positive integer m. |
| 1. | for i = 1 to do |
| 2. | B[i] = 1 |
| 3. | |
| 4. | for i = 1 to k do |
| 5. |
|
| 6. | n = 0 |
| 7. | while (d ≠ 0) and (n ≤ d) do |
| 8. | 0 |
| 9. | n = n + 1 |
| 10. | P[0] = 2; j = 1 |
| 11. | for i = 1 to do |
| 12. | if B[i] = 1 then |
| 13. | P[j] = |
| 14. | j = j + 1 |
| Output: A set P of all prime numbers less than or equal to m. |
4. The Proposed Parallel Algorithms
This section presents two new parallel algorithms for prime sieving by parallelizing the MAE algorithm on a shared memory parallel model. In this model, all processors communicate via shared memory and assume that the model can run t threads at the same time.
The parallelization of the MAE algorithm can be performed by parallelizing each step in the MAE algorithm, except for the second step, since it is a simple statement. Two versions of parallelization, PMAE-1 and PMAE-2, are introduced. Both versions are similar except for the parallelization of the third step of the MAE algorithm. The steps of the PMAE-1 algorithm, Algorithm 3, are as follows.
For the first step, the sequential loop can be parallelized easily by dividing it into t subranges of equal size, and each thread works independently on one subrange (see Lines 1–8 in the PMAE-1 algorithm). In this step, there is no need to read the same element by many threads and to write in the same cell concurrently by more than one thread.
For the second step, there is no need to parallelize it because it consists of one simple step (see Line 9 of the PMAE-1 algorithm).
For the third step, the parallelization of this step is performed dynamically because the number of iterations for the inner loop is based on the value of d, and this value varies for each new iteration of the outer loop, i.e., it depends on the value of i. For example, when i = 1, the value of , whereas the value of when i = 2. It is clear that the value of the numerator of d decreases and that the value of the denominator increases. Since each iteration of the outer loop in Step 3 of the MAE algorithm is done individually, we parallelize the outer loop while keeping the inner loop sequential (see Lines 10–14 in the PMAE-1 algorithm).
For the fourth step, the parallelization of this step can be performed by using three substeps. In the first substep, each thread
ti counts the number of primes in the subrange
and stores this value, i.e., the number of primes, in the variable
count[
i], where
| Algorithm 3: PMAE-1. |
| Input: A positive integer m and t threads. |
| 1. | |
| 2. | for i = 0 to t − 1 do parallel |
| 3. | if (i ≠ t − 1) then |
| 4. | for j = (i × m1)/t +1 to ((i + 1) × m1)/t do |
| 5. | B[j] = 0 |
| 6. | else |
| 7. | for j = (i × m1)/t + 1 to m1 do |
| 8. | B[j] = 0 |
| 9. | |
| 10. | for i = 1 to k do parallel (Dynamically) |
| 11. |
|
| 12. | if (d ≠ 0) then |
| 13. | for n = 0 to d do |
| 14. | 0 |
| 15. | for i = 0 to t − 1 do parallel |
| 16. | count[i] = 0 |
| 17. | if (i ≠ t − 1) then |
| 18. | for j = (i × m1)/t + 1 to ((i + 1) × m1)/t do |
| 19. | if B[j] ≠ 0 then |
| 20. | TmpP[i,count[i]] = 2 × j + 1 |
| 21. | count[i] = count[i] + 1 |
| 22. | Else |
| 23. | for j = (i × m1)/t + 1 to m1 do |
| 24. | if B[j] ≠ 0 then |
| 25. | TmpP[i,count[i]] = 2 × j + 1 |
| 26. | count[i] = count[i] + 1 |
| 27. | ps[0] = 0 |
| 28. | for i = 1 to t − 1 do |
| 29. | ps[i] = ps[i − 1] + count[i − 1] |
| 30. | for i = 0 to t do parallel |
| 31. | for j = 0 to count[i] − 1 do |
| 32. | P[ps[i] + j] = TmpP[i,j] |
| Output: A set P of all prime numbers less than or equal to m. |
The thread ti stores the j-th prime number in the range ri at position j − 1 in the auxiliary array TmpP[i,j]. This means that all prime numbers in the subrange ri exist in TmpP[i,-]. This substep represents Lines 15–26 of the PMAE-1 algorithm.
In the second substep of Step 4, the algorithm computes the prefix sums
ps for the integers 0,
count[0],
count[1], …,
count[
t − 2]. The objective of this step is to compute and store the start positions of all prime numbers that exist in the subrange
ri in the output array
P. The start position of each subrange is given by
where
.
If the value of
t is small, as in the experimental study, array
ps is computed sequentially (see lines 27–29). Otherwise, the algorithm uses the binary tree strategy [
31,
32] to compute
ps.
In the third substep, each thread ti starts to copy the prime numbers from the auxiliary array TmpP[i,-] to the output array P starting from position ps[i] (see Lines 30–32).
The run time for the PMAE-1 algorithm can be computed as follows. Step 1 requires O(m1/t), whereas Step 2 requires O(1). Step 4 requires O(m1/t + t) when ps is computed sequentially and O(m1/t + log t) when ps is computed in parallel. Step 3 is based on the number of elements in each set Ai, and its run time is approximately equal to O(m1/t) in the average case. Therefore, the overall time complexity of the PMAE-1 algorithm is O(m1/t + t) = O(m1/t) or O(m1/t + log t) = O(m1/t), since m1 >> t.
The steps of the PMAE-2 algorithm, Algorithm 4, are similar to those of the PMAE-1 algorithm except for the third step. Step 3 of the PMAE-2 algorithm is based on parallelizing the inner loop, whereas the outer loop is sequential. The inner loop consists of
d + 1 concurrent iterations that are distributed to
t threads. Therefore, Lines 10–14 of the PMAE-1 algorithm can be rewritten as follows.
| Algorithm 4: PMAE-2. |
| Input: A positive integer m and t threads. |
| | // Similar to Algorithm 3, Lines 1–9 |
| 10. | for i = 1 to k do |
| 11. |
|
| 12. | if (d ≠ 0) then |
| 13. | for n = 0 to d do parallel |
| 14. | 0 |
| | // Similar to Algorithm 3, Lines 15–32 |
The run time for Step 3 of the PMAE-2 algorithm is , where is the run time for the inner loop using t threads, and represents the value of d at iteration i from the outer loop. Therefore, the run time of the PMAE-2 algorithm is O(m1/t).
6. Conclusions and Future Work
Generating prime numbers is important in designing some cryptosystems, such as in [
13,
33]. In this paper, generating prime numbers up to an integer number
m on two platforms, sequential and parallel, is addressed. The developed works for prime sieving are based on set theory. The first proposed sequential algorithm improves the run time of the best known algorithm by 98%. Moreover, two proposed parallel algorithms based on two strategies, static and dynamic, are introduced. The two parallel algorithms surpass the sequential algorithm, with improvements of 72% and 67% on average. Additionally, the maximum speedup achieved by the best parallel algorithm using 16 threads is 7.
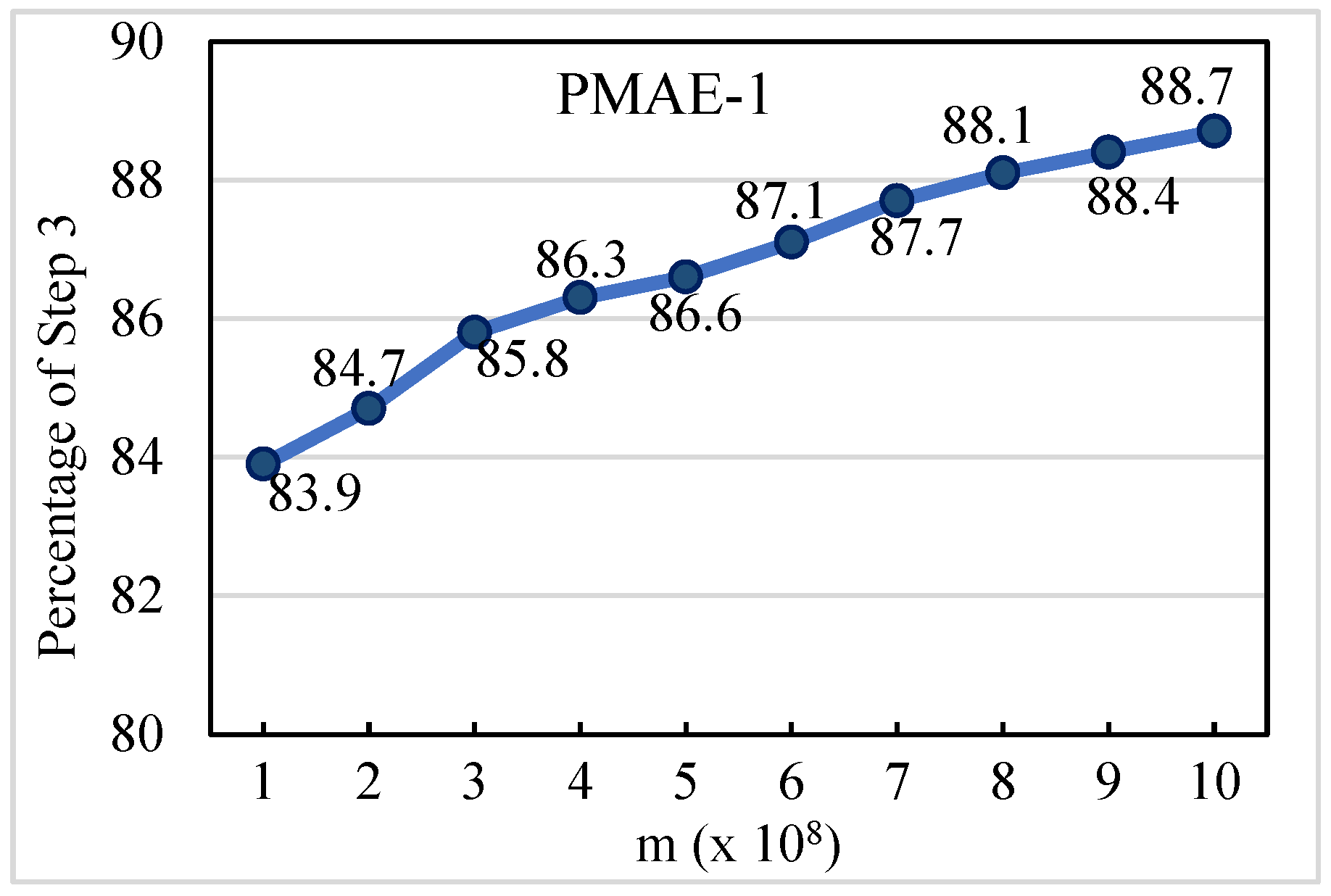
Based on the discussion of the results, there are some open questions regarding future works. First, how can a technique that is more efficient than Step 3 of the proposed parallel algorithms be developed? Second, what is the effect of increasing the number of threads and data size on the proposed parallel algorithms? Third, since the performance of PMAE-1 increases with increasing the number of threads, and since recent graphic processing units (GPUs) have thousands of threads, how can the PMAE-1 algorithm be implemented on a single GPU or multi-GPUs?


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}