

Overlapping Community Hiding Method Based on Multi-Level Neighborhood Information

Abstract
:1. Introduction
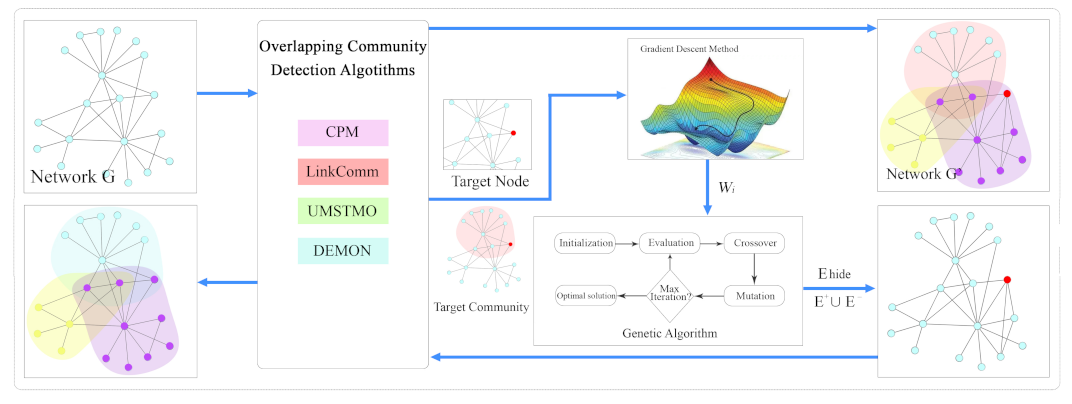
- We propose a new hiding algorithm that moves target nodes in overlapping areas out of a specific community.
- We introduce the probability of a node belonging to a community and change the probability by selecting appropriate links to operate.
- We conduct multiple experiments on five real social networks and compare the performance of the proposed hidden algorithm against four well-known overlapping community detection algorithms.
2. Related Work
2.1. Community Detection
2.2. Community Hiding
3. Methods
3.1. Problem Formulation
3.2. Overlapping Community Hiding Algorithm Based on Multi Level Neighborhood Information
| Algorithm 1 Overlapping community hiding method based on Multi-Level Neighborhood Information (MLNI). |
| Input: Network G, T, Target node n, , ; |
| Output: Updated Network ; |
| C← getCommunities(G); |
| ← getNodesInOverlappingArea(C); |
| if then |
| ← getCommunitiesOfNode(); |
| ← ChooseTargetCommunity(); |
| W← GetWeightOfCommunity() |
| ← GetProbability() |
| ParentPop ← Inatialization(); |
| while do |
| SelectedPop ← Selection(); |
| CrossoverPop ← Crossover(); |
| OffspringPop ← Elistism(); |
| ParentPop ← OffspringPop; |
| i←i + 1; |
| end |
| ← Update G; |
| end |
3.3. Probability (the Node Belongs to the Community)
3.4. Restrictions
3.5. Optimization Algorithm GA
4. Experiments
4.1. Datasets
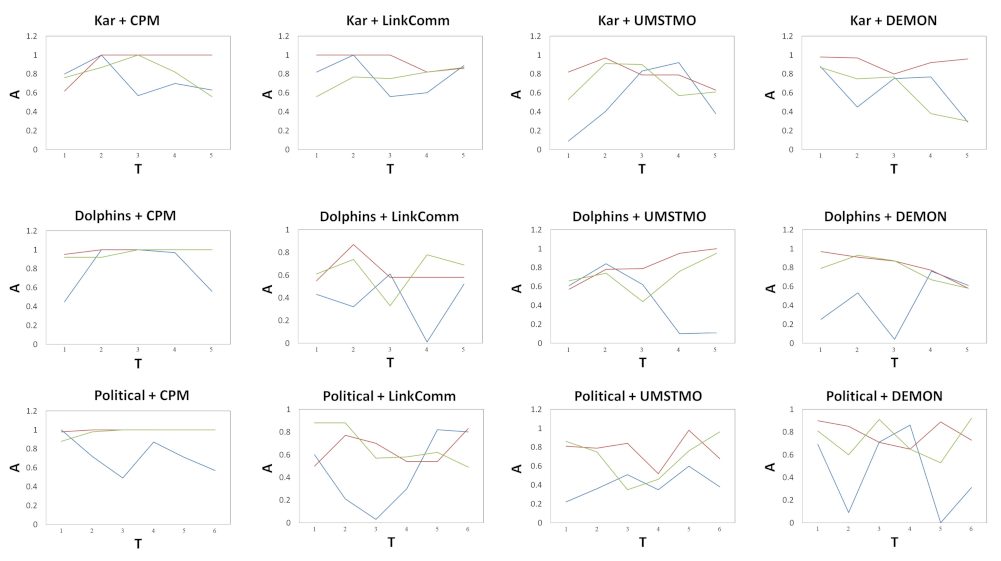
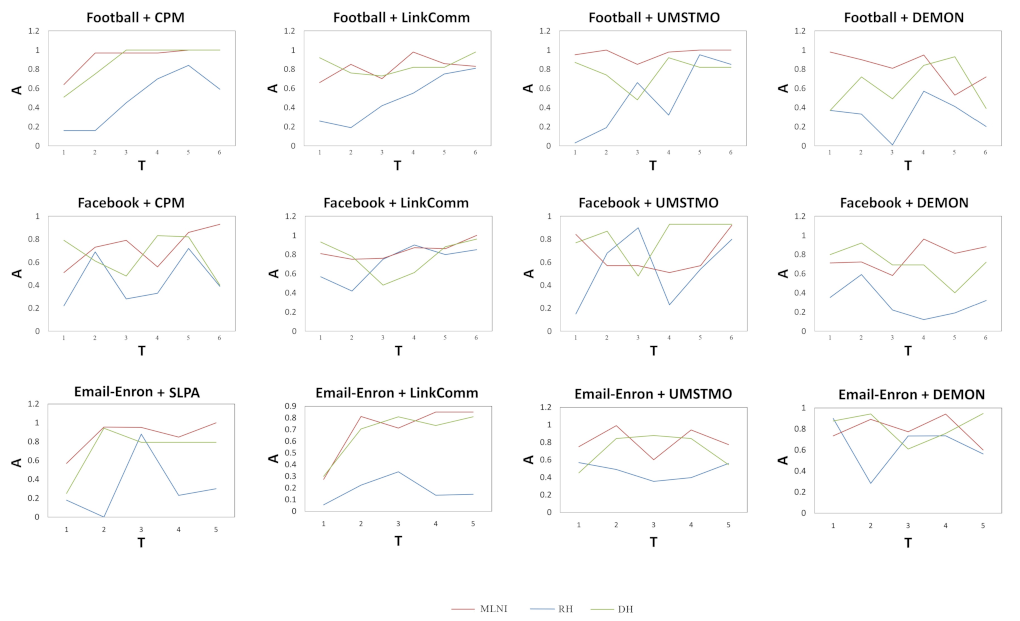
4.2. Evaluation Metric
4.3. Baseline Algorithms
| Algorithm 2 Random hiding strategy. |
| Input: Network G, T, Target node n; |
| Output: Updated Network ; |
| C← getCommunities(G); |
| ← getNodesInOverlappingArea(C); |
| if then |
| ← getCommunitiesOfNode(); |
| ← ChooseTargetCommunity(); |
| while do |
| ← getNonneighborSet(); |
| u← RandomChooseNode(); |
| add link to E; |
| ← getNeighborSet(); |
| v← RandomChooseNode(); |
| remove link from E; |
| end |
| ← Update G; |
| end |
| Algorithm 3 Base-degree hiding strategy. |
| Input: Network G, T, Target node n; |
| Output: Updated Network ; |
| C← getCommunities(G); |
| ← getNodesInOverlappingArea(C); |
| if then |
| ← getCommunitiesOfNode(); |
| ← ChooseTargetCommunity(); |
| while do |
| ← getNonneighborSet(); |
| u← ChooseNodeBaseDegree(); |
| add link to E; |
| ← getNeighborSet(); |
| v← ChooseNodeBaseDegree(); |
| remove link from E; |
| end |
| ← Update G; |
| end |
4.4. Result Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xuan, Q.; Zhang, Z.; Fu, C.; Hu, H.; Filkov, V. Social Synchrony on Complex Networks. IEEE Trans. Cybern. 2018, 48, 1420–1431. [Google Scholar] [CrossRef]
- Xuan, Q.; Fang, H.; Fu, C.; Filkov, V. Temporal motifs reveal collaboration patterns in online task-oriented networks. Phys. Rev. E 2015, 91, 052813. [Google Scholar] [CrossRef] [Green Version]
- Abbasi, A.A.; Younis, M.F. A survey on clustering algorithms for wireless sensor networks. Comput. Commun. 2007, 30, 2826–2841. [Google Scholar] [CrossRef]
- Vieira, V.d.F.; Xavier, C.R.; Evsukoff, A.G. A comparative study of overlapping community detection methods from the perspective of the structural properties. Appl. Netw. Sci. 2020, 5, 51. [Google Scholar] [CrossRef]
- Garcia, J.O.; Ashourvan, A.; Muldoon, S.; Vettel, J.M.; Bassett, D.S. Applications of Community Detection Techniques to Brain Graphs: Algorithmic Considerations and Implications for Neural Function. Proc. IEEE 2018, 106, 846–867. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, J.; Xia, Y.; Zhang, X. Robustness of Interdependent Power Grids and Communication Networks: A Complex Network Perspective. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 115–119. [Google Scholar] [CrossRef]
- Schiavo, S.; Reyes, J.; Fagiolo, G. International trade and financial integration: A weighted network analysis. Quant. Financ. 2010, 10, 389–399. [Google Scholar] [CrossRef]
- Gross, R.; Acquisti, A. Information Revelation and Privacy in Online Social Networks. In Proceedings of the 2005 ACM Workshop on Privacy in the Electronic Society (WPES’05), Alexandria, VA, USA, 7 November 2015; Association for Computing Machinery: New York, NY, USA, 2005; pp. 71–80. [Google Scholar]
- Zhang, C.; Sun, J.; Zhu, X.; Fang, Y. Privacy and security for online social networks: Challenges and opportunities. IEEE Netw. 2010, 24, 13–18. [Google Scholar] [CrossRef]
- Zhou, B.; Pei, J.; Luk, W. A brief survey on anonymization techniques for privacy preserving publishing of social network data. ACM Sigkdd Explor. Newsl. 2008, 10, 12–22. [Google Scholar] [CrossRef]
- Kearns, M.; Roth, A.; Wu, Z.S.; Yaroslavtsev, G. Private algorithms for the protected in social network search. Proc. Natl. Acad. Sci. USA 2016, 113, 913–918. [Google Scholar] [CrossRef]
- Waniek, M.; Michalak, T.P.; Rahwan, T.; Wooldridge, M.J. Hiding Individuals and Communities in a Social Network. Nat. Hum. Behav. 2018, 2, 139–147. [Google Scholar] [CrossRef] [Green Version]
- Fionda, V.; Pirrò, G. Community Deception or: How to Stop Fearing Community Detection Algorithms. IEEE Trans. Knowl. Data Eng. 2018, 30, 660–673. [Google Scholar] [CrossRef]
- Chen, J.; Chen, L.; Chen, Y.; Zhao, M.; Yu, S.; Xuan, Q.; Yang, X. GA-Based Q-Attack on Community Detection. IEEE Trans. Comput. Soc. Syst. 2019, 6, 491–503. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Liu, J.; Zhang, Z.; Zhu, L.; Li, A. Rem: From structural entropy to community structure deception. Adv. Neural Inf. Process. Syst. 2019, 32, 12938–12948. [Google Scholar]
- Chen, J.; Chen, Y.; Chen, L.; Zhao, M.; Xuan, Q. Multiscale Evolutionary Perturbation Attack on Community Detection. IEEE Trans. Comput. Soc. Syst. 2021, 8, 62–75. [Google Scholar] [CrossRef]
- Gregory, S. An Algorithm to Find Overlapping Community Structure in Networks. In Proceedings of the Knowledge Discovery in Databases: PKDD 2007, Warsaw, Poland, 17–21 September 2007; Kok, J.N., Koronacki, J., Lopez de Mantaras, R., Matwin, S., Mladenič, D., Skowron, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 91–102. [Google Scholar]
- Xie, J.; Kelley, S.; Szymanski, B.K. Overlapping community detection in networks: The state-of-the-art and comparative study. ACM Comput. Surv. 2013, 45, 43:1–43:35. [Google Scholar] [CrossRef] [Green Version]
- Liu, D.; Yang, G.; Wang, Y.; Jin, H.; Chen, E. How to Protect Ourselves From Overlapping Community Detection in Social Networks. IEEE Trans. Big Data 2022, 8, 894–904. [Google Scholar] [CrossRef]
- Lehnerer, S. Community Detection in Complex Networks using Genetic Algorithms. In Proceedings of the SKILL 2018—Studierendenkonferenz Informatik, Berlin, Germany, 26–27 September 2018; Becker, M., Ed.; Gesellschaft für Informatik e.V.: Bonn, Germany, 2018; pp. 35–46. [Google Scholar]
- Liu, H.; Hu, X.B.; Yang, S.; Zhang, K.; Di Paolo, E. Application of complex network theory and genetic algorithm in airline route networks. Transp. Res. Rec. 2011, 2214, 50–58. [Google Scholar] [CrossRef]
- Wang, S.; Zou, H.; Sun, Q.; Zhu, X.; Yang, F. Community detection via improved genetic algorithm in complex network. Inf. Technol. J. 2012, 11, 384. [Google Scholar] [CrossRef] [Green Version]
- Liu, D.; Duan, D.; Shikai, S.; Song, G. Effective Semisupervised Community Detection Using Negative Information. Math. Probl. Eng. 2015, 2015, 109671. [Google Scholar] [CrossRef]
- Liu, D.; Liu, X.; Wang, W.; Bai, H. Semi-supervised community detection based on discrete potential theory. Phys. A Stat. Mech. Its Appl. 2014, 416, 173–182. [Google Scholar] [CrossRef]
- Liu, D.; Bai, H.Y.; Li, H.J.; Wang, W.J. Semi-supervised community detection using label propagation. Int. J. Mod. Phys. B 2014, 28, 1450208. [Google Scholar] [CrossRef]
- Fan, L.; Xu, S.; Liu, D.; Ru, Y. Semi-Supervised Community Detection Based on Distance Dynamics. IEEE Access 2018, 6, 37261–37271. [Google Scholar] [CrossRef]
- Liu, D.; Wang, C.; Jing, Y. Estimating the optimal number of communities by cluster analysis. Int. J. Mod. Phys. B 2016, 30, 1650037. [Google Scholar] [CrossRef]
- Liu, D.; Chang, Z.; Yang, G.; Chen, E. Community hiding using a graph autoencoder. Knowl.-Based Syst. 2022, 253, 109495. [Google Scholar] [CrossRef]
- Pons, P.; Latapy, M. Computing Communities in Large Networks Using Random Walks. In Proceedings of the Computer and Information Sciences—ISCIS 2005, Istanbul, Turkey, 26–28 October 2005; Yolum, P., Güngör, T., Gürgen, F., Özturan, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 284–293. [Google Scholar]
- Girvan, M.; Newman, M.E. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [Green Version]
- Rosvall, M.; Bergstrom, C.T. Maps of random walks on complex networks reveal community structure. Proc. Natl. Acad. Sci. USA 2008, 105, 1118–1123. [Google Scholar] [CrossRef] [Green Version]
- Clauset, A.; Newman, M.E.J.; Moore, C. Finding community structure in very large networks. Phys. Rev. E Stat. Nonliner Soft Matter Phys. 2004, 6, 66–111. [Google Scholar] [CrossRef] [Green Version]
- Reichardt, J.; Bornholdt, S. Statistical mechanics of community detection. Phys. Rev. E 2006, 74, 016110. [Google Scholar] [CrossRef] [Green Version]
- Gao, R.; Li, S.; Shi, X.; Liang, Y.; Xu, D. Overlapping Community Detection Based on Membership Degree Propagation. Entropy 2021, 23, 15. [Google Scholar] [CrossRef]
- Coscia, M.; Rossetti, G.; Giannotti, F.; Pedreschi, D. DEMON: A local-first discovery method for overlapping communities. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’12), Beijing, China, 12–16 August 2012; ACM: New York, NY, USA, 2012; pp. 615–623. [Google Scholar]
- Palla, G.; Derényi, I.; Farkas, I.; Vicsek, T. Uncovering the overlapping community structure of complex networks in nature and society. Nature 2005, 435, 814–818. [Google Scholar] [CrossRef] [PubMed]
- Ahn, Y.Y.; Bagrow, J.P.; Lehmann, S. Link communities reveal multiscale complexity in networks. Nature 2010, 466, 761. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Asmi, K.; Lotfi, D.; El Marraki, M. Overlapping community detection based on the union of all maximum spanning trees. Library Hi Tech 2020, 38, 276–292. [Google Scholar] [CrossRef]
- Nagaraja, S. The impact of unlinkability on adversarial community detection: Effects and countermeasures. In Proceedings of the 10th International Conference on Privacy Enhancing Technologies (PETS’10), Berlin, Germany, 21–23 July 2010; pp. 253–272. [Google Scholar]
- Chen, X.; Jiang, Z.; Li, H.; Ma, J.; Yu, P.S. Community Hiding by Link Perturbation in Social Networks. IEEE Trans. Comput. Soc. Syst. 2021, 8, 704–715. [Google Scholar] [CrossRef]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations. Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]
- Zachary, W.W. An information flow model for conflict and fission in small groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef] [Green Version]
- Newman, M. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef] [Green Version]
- Traud, A.L.; Mucha, P.J.; Porter, M.A. Social structure of facebook networks. Phys. A Stat. Mech. Its Appl. 2012, 391, 4165–4180. [Google Scholar] [CrossRef]
- Xie, J.; Szymanski, B.K.; Liu, X. SLPA: Uncovering Overlapping Communities in Social Networks via A Speaker-listener Interaction Dynamic Process. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops (ICDMW), Vancouver, BC, Canada, 11 December 2011. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| original network with nodes V , links E. | |
| C | the communities discovered by some community detection algorithms of G. |
| stands for adding and removal links in network. | |
| n | the target node |
| the target community | |
| the set of nodes in the overlapping area of community | |
| the propagation function | |
| the weight of each layer | |
| the aggregation function | |
| the probability of node n belonging to community | |
| the neighbors of node n | |
| the degree of node n | |
| the probability that node n belongs to other communities except the target community |
| Network | Nodes | Links | Description |
|---|---|---|---|
| Football | 115 | 613 | American football teams |
| Karate | 34 | 78 | Zachary Karate’s Club |
| Dolphins | 62 | 159 | Dolphins association |
| Political | 105 | 441 | Books about US politics |
| 4390 | 88,243 | Facebook social network | |
| Email-Enron | 36,693 | 183,831 | Email communication network from Enron |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, G.; Wang, Y.; Chang, Z.; Liu, D. Overlapping Community Hiding Method Based on Multi-Level Neighborhood Information. Symmetry 2022, 14, 2328. https://doi.org/10.3390/sym14112328
Yang G, Wang Y, Chang Z, Liu D. Overlapping Community Hiding Method Based on Multi-Level Neighborhood Information. Symmetry. 2022; 14(11):2328. https://doi.org/10.3390/sym14112328
Chicago/Turabian StyleYang, Guoliang, Yanwei Wang, Zhengchao Chang, and Dong Liu. 2022. "Overlapping Community Hiding Method Based on Multi-Level Neighborhood Information" Symmetry 14, no. 11: 2328. https://doi.org/10.3390/sym14112328