1. Introduction
The advent of quantum computing has resulted in a deeper theoretical re-examination of all existing cryptographic mechanisms and their practical implementations. The result of these reviews is a return to symmetric cryptographic systems and information-theoretical security measures. The central principle of this approach is simple to formulate: a cryptographic system provides absolute secrecy of messages if, and only if, the uncertainty (entropy) of its secret key is not less than the uncertainty of messages [
1]. Systems designed in this way are known to be resistant to the unlimited computing resources of adversaries and thus to cryptanalysis based on quantum computers [
2]. The price to be paid is the production and distribution of an enormous quantity of secret cryptographic keys, which must meet the highest criteria of true randomness. Nowadays, solutions for the problem of generating and distributing secret keys at the same time are mainly based on the fundamental results of Ahlsvede and Csiszar [
3], Maurer [
4], and Csiszar and Narayan [
5]. The basic idea of this approach is the extraction of keys in a distributed communication scenario based on a random source whose correlated components are available to participants. Depending on the location of the source of uncertainty, there are two different approaches: (i) source is independent of communication channels (the source model), and (ii) source is the communication channel itself (the channel model) [
4].
In this paper, we will deal only with the source model and corresponding sequential key distillation strategy by public discussions (SKD) since it has many advantages for professional applications, primarily in the domain of military and special operations [
6]:
Secret keys cannot be established through physical distribution during special operations;
If there are no pre-generated and distributed secret keys, it makes them impossible to compromise before the start of critical operations;
The principle of risk minimization dictates that compromising one subsystem does not compromise the entire system. Accordingly, the SKA system should be independent of cryptographic and telecommunication modules. This fact excludes the use of the SKA channel model, favoring the SKA source model.
The critical block in SKD is the privacy amplification (PA), which minimizes the amount of information available to an eavesdropper. If the PA is based on hash functions, the eavesdropper conditional Renyi entropy of order 2 (ECRE2) of sequence shared by legitimate parties determines the maximum length of the secret keys so that no information is leaked to the eavesdropper, see Corollary 4 [
7]. However, two key things are difficult to quantify in practice:
The first category of common practice is based on adopting a single global lower bound for ECRE2 for a given source. This constant is then used to determine the output dimension of a universal class of hash functions for all individual realizations of the protocol [
4,
7,
8,
9]. It is clear that in this way, the optimal strategy based on the local lower bound of ECRE2 is replaced by a far suboptimal one. We will call this strategy the global lower bound (GLB) strategy. The consequences of the GLB strategy are as follows:
The second category of common practice is based on the (usually wrong) assumption that the input sequence in the PA block is uncorrelated with the corresponding eavesdropper sequence. In that case, relying on the well-known hash leftover lemma (HLL) [
11], the PA block is designed to eliminate only that information that is leaked through the public discussion channel [
12,
13,
14]. We will call this strategy the HLL strategy. The consequences of the HLL strategy are as follows:
In this paper, we propose a new PA design methodology based on a machine learning system that estimates ECRE2 and its lower bound. The system is based on a predicting intervals regression deep neural network (PIDNN), trained for a given source of common randomness. Inputs to the system are features locally measured on the side of legitimate participants. The basic properties of this system are as follows:
A precise estimate of the lower bound for ECRE2;
Quantification of the security margin of the generated keys;
Quantification of the amount of leaked information;
Quantification of the unused randomness of a given source;
Quantification of the gain of the chosen strategy in relation to any other PA strategy.
In this way, we address the key issues of PA design, mentioned in points 1 and 2. Quantifications of the unused randomness of a given source and quantification of the gain of the chosen strategy in relation to any other PA strategy are introduced for the first time in this field. The quantification of the unused randomness of a given source can also be seen as a contribution to the general field of Information and Communications Technologies for Sustainable Development Goals [
16] and encourages the development of services for privacy preserving [
17].
The price to be paid for all the advantages of the proposed system is the formation of training sets and the training of PIDNN for a given source. Since this part of the work is performed only once in the offline mode, the complexity of the PA block in the working mode increases only for the computing resources necessary for ECRE2 prediction based on the already trained PIDNN.
The theoretical basis of the proposed method is formulated in Theorems 2 and 3,
Section 3. In this way, we remain within the framework of information-theoretic security, which guarantees, in advance, the appropriate performance and security margins of the generated secret keys.
Experimental evaluation was conducted for two different sources, i.e., 6-dimensional and 14-dimensional EEG signals from 50 participants, varying the different advantage distillation (AD) and information reconciliation (IR) SKD strategies. The results show a significant increase in the quantity of generated secret keys without compromising their cryptographic quality. For a 14-dimensional and 6-dimensional EEG source, amplification is from 3.6 to 4.6 times and from 1.35 to 1.85 times, respectively, depending on the IR strategy and the lossless compression block before PA. On average, across all proposed systems and analyzed sources, the best machine learning strategy, called the hybrid strategy, increases the quantity of generated keys by 2.77 times compared to the classical strategy. By introducing the Huffman lossless coder before the PA block, the loss of potential source randomness was reduced from 68.48% to a negligible 0.75%, while the leakage rate per one bit remains in the order of magnitude .
The rest of the paper is organized as follows.
Section 2 provides the basics of the SKD strategy for the source model.
In
Section 3, the classic PA block design strategy is presented. The importance of local decision making based on ECRE2 and the fundamental role of its lower bound was indicated. Theorem 2 can be considered a reformulation of Corollary 4 from [
7] under conditions of knowing ECRE2. Theorem 3 gives the conditions under which the PA block provides maximum uncertainty about established secret keys on the Eve side if the lower bound for ECRE2 is known with a given probability.
In
Section 4, the ML system for predicting the lower bound of ECRE2 is presented. It consists of an interval prediction deep neural network with 11 or 13 inputs and three outputs, which provide a prediction for ECRE2, as well as the lower and upper bounds of the range in which its true value lies with a predefined probability. Having a reliable lower bound enables a more efficient design of the PA block. Global indicators of gains are introduced, both in terms of the efficiency of using the randomness of a given source, as well as in terms of the quantity of generated keys in comparison with classical PA systems.
In
Section 5, the synthesis of the proposed system in the case of two sources of EEG signals of different dimensions is presented in detail. The training set was obtained by recording EEG signals for 50 participants, resulting in an ensemble of 2 × 50 × (2 × 50 − 1)/2 = 4950 different triplets (Alice, Bob, Eve). After appropriate quantization and serialization, binary sequences of 36,000 bits in length were obtained for each participant. Experimental metrics include estimation of key generation rate (KR), the amount of information leaked to Eve, NIST’s tests of the cryptographic quality of keys, as well as the gains compared to classical systems.
In the sixth concluding section, the complexity of system implementation and its practical usability are discussed, as well as some open issues concerning the efficient estimate of ECRE2.
2. Sequential Key Distillation Strategy
Figure 1 shows a source model for SKA within a scenario in which three parties, Alice, Bob, and Eve, observe realizations of a DMS. Each of them receives their own set of observations. Let X, Y, and Z, be Alice’s, Bob’s, and Eve’s observations, respectively. Alice’s and Bob’s goals are to agree on a secret key K, based on their observations X and Y, so that Eve has no information about it. A public authenticated noiseless communication channel is fully available to all parties, including Eve.
SKD strategy is four stage protocol consisting of [
4]:
Randomness sharing. Alice, Bob, and Eve observe n realizations of DMS (XYZ, PXYZ), where PXYZ denotes the joint probability measure of the random variables X, Y, and Z.
Advantage distillation. If necessary, Alice and Bob exchange messages over a public channel to “distill” the observation parts on which they have an advantage over Eve.
Information reconciliation. Alice and Bob exchange messages over the public channel in order to eliminate mutual differences and agree on a common binary string.
Privacy amplification. Alice and Bob publicly agree on a deterministic function that they would apply to their common sequence to generate the final secret key.
The secrecy capacity of a public channel is the maximum rate at which information can be reliably exchanged between legitimate parties such that the rate at which an eavesdropper obtains this information is arbitrarily small.
The secret key capacity is, at the same time, the maximum length of a secret key that can be sent in the presence of an eavesdropper and can be defined by
where
denotes the mutual information between
and
, while
denotes this mutual information conditioned by
. The advantage of the SKD strategy is the proven achievement of all secret key rates lower than the secrecy capacity
, as well as its explicit practical implementation [
4].
3. PA Strategy
PA is the last stage of SKD in which all the information that was leaked to Eve in the PA and IR protocol execution phase is eliminated from the common sequence of Alice and Bob. As a rule, it is achieved by applying a suitable hash function from the class of universal hash functions or by applying a class of functions called extractors [
18]. In the theoretical sense, both procedures are equivalent. Recent studies show that the use of extractors is superior to the use of hash functions only with the very large key length of order greater than
bits [
19]. Keeping in mind the typical practice, we will limit ourselves to PA based on hash functions from the universal class of hash functions, defined as follows [
20]:
Definition 1. Given two finite setsand, a familyof functionsis 2-universal (universal for short) ifwhereis the random variable that represents the choice of a functionuniformly at random in.
In the analysis of this class of systems, collision entropy is shown to be the most suitable information measure, since it better measures the amount of uncertainty faced by Eve regarding the keys agreed upon by Alice and Bob using hash functions from the universal class. Therefore, we will list some important properties of this information measure.
Definition 2. The collision entropy of a discrete random variableiswhereis collision probability. For two discrete random variables,
and
, the conditional collision entropy of
given
is
For any discrete random variables , the collision entropy satisfies . If is uniformly distributed over , then , where is Shannon entropy.
The name collision entropy comes from the fact that it is a function of the collision probability (3) of obtaining the same realization of a random variable twice in two independent experiments. For a discrete random variable
X, the Renyi entropy of order α is
Therefore, collision entropy is identical to Renyi entropy of order 2, namely,
The connection between Renyi entropy and PA based on the universal family of hash functions is formulated in the following theorem [
7]:
Theorem 1 . Let be the random variable that represents the common sequence by Alice and Bob, and letbe the random variable that represents the total knowledge about S available to Eve. Let e be a particular realization of. If Alice and Bob know the ECRE2,to be at least some constant, and if they choose as their secret key, where G is a hash function chosen uniformly at random from a universal family of hash functions , then
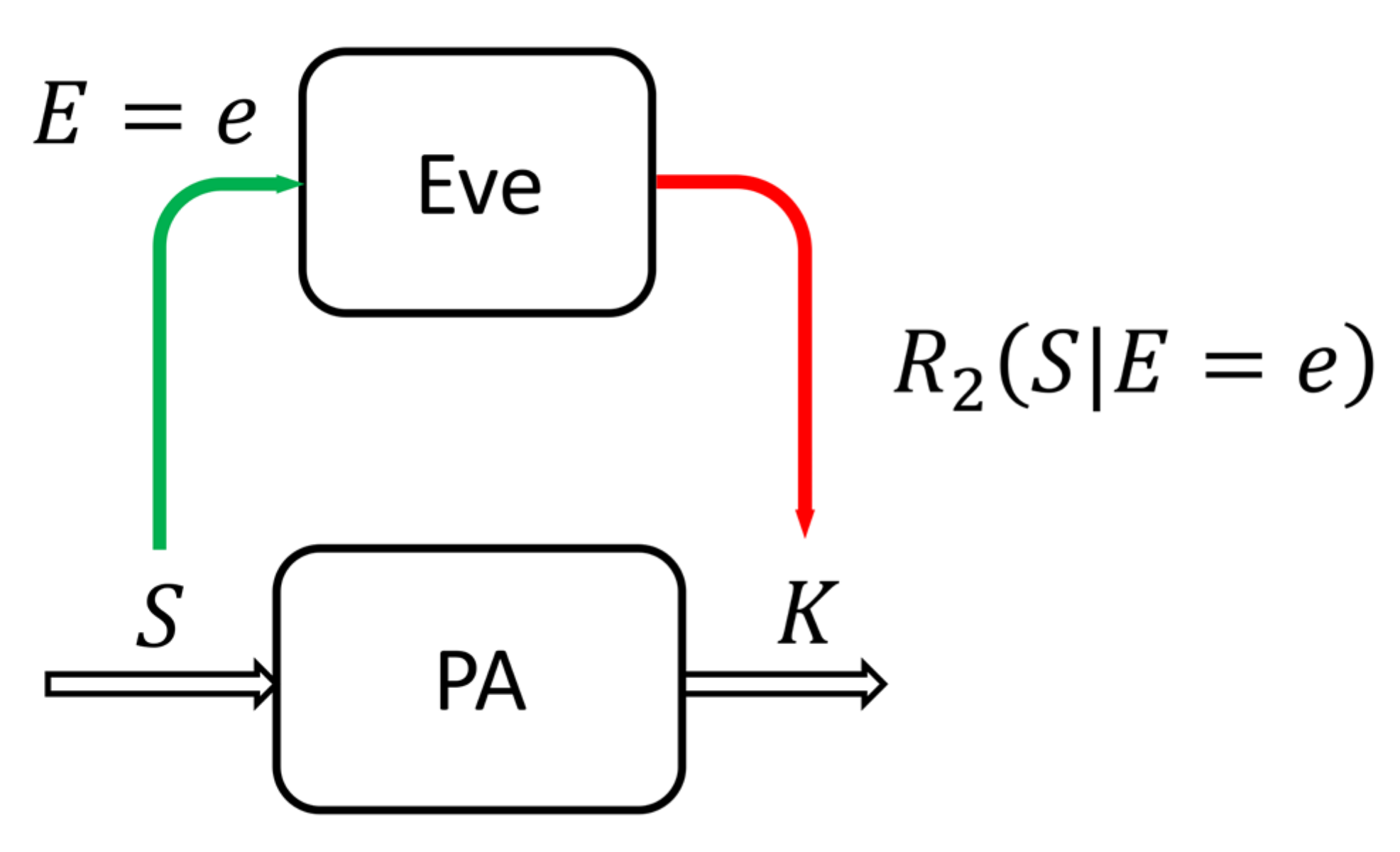
Remark 1. This result claims that Alice and Bob can generate a shared secret key of length, if they know the lower bound c of ECRE2, see Figure 2.Combining (7) and the fact that a binary sequence of length k cannot have a Shannon entropy greater than k, we obtain This further means that if Alice and Bob choose the length of the shared secret keywhere s is the security parameter, the generated keys will differ exponentially small infrom the maximum entropy sequences, while Eve’s total information about that secret key will be exponentially small in. We will call this PA strategy the global lower bound strategy. This result dominates today’s practice of applying PA in the SKD source model. Since the constant does not depend on Eve’s specific sequence it is clear that for each specific , there is a smaller or larger deviation from the established fixed lower bound , which leads to an unnecessary loss in the length of the generated keys, for the same operating conditions of SKD protocol and the same security parameter.
The following theorem provides the basis for strategy based on the local lower bound for ECRE2.
Theorem 2 .
Let be the random variable that represents the common sequence by Alice and Bob, and let E be the random variable that represents the total knowledge about available to Eve. Let e be a particular realization of E. If Alice and Bob choose as their secret key, where is a hash function chosen uniformly at random from a universal family of hash functions ,
then Proof of Theorem 2. The proof completely follows the steps of the proof of Theorem 3 from [
7], if all relevant probability measures are extended by the additional condition
. For complete proof see
Appendix A. □
In some practical fORapplications, the lower bound for ECRE2 is known to hold with some probability. Theorem 3 answers the question under which conditions in this situation the PA block will ensure the maximum equivocation of the established secret keys from Eve’s side.
Theorem 3. Letbe the random variable that represents the common sequence shared by Alice and Bob, and let E be the random variable that represents the total knowledge about S available to Eve. Let e be a particular realization of. Let the probability that let e be a particular realization oftakes on a valuesatisfyingis at least. Letbe an arbitrary security parameter. If Alice and Bob chooseas their secret key, whereis a hash function chosen uniformly at random from a universal family of hash functions, then key equivocation from the side of Eve is Proof of Theorem 3. By direct application of Theorem 2, we obtain
Let us divide the set of all sequences e into two sets
Then it is valid
which should have been proved. □
Remark 2. From Theorem 3, and the fact that the maximum value of Shannon entropy of a binary sequence of length k cannot be greater than k, for a small, K has almost maximal entropy for Eve: Remark 3. If, during the execution of the IR phase of the protocol,parity bits were exchanged over the public channel. According to Lemma 4 [7], it is necessary to perform additional compression for the same amount ofbits in the PA phase. Based on Theorem 2 and Remarks 1 and 3, we can claim that the
optimal PA strategy based on the ECRE2 is given by
The main obstacle to the application of this strategy is the fact that ECRE2 is unknown to Alice and Bob since it is conditioned by Eve’s sequence , which is generally unavailable to them. Is it possible to overcome this uncertainty? In this paper, we propose a solution based on machine learning.
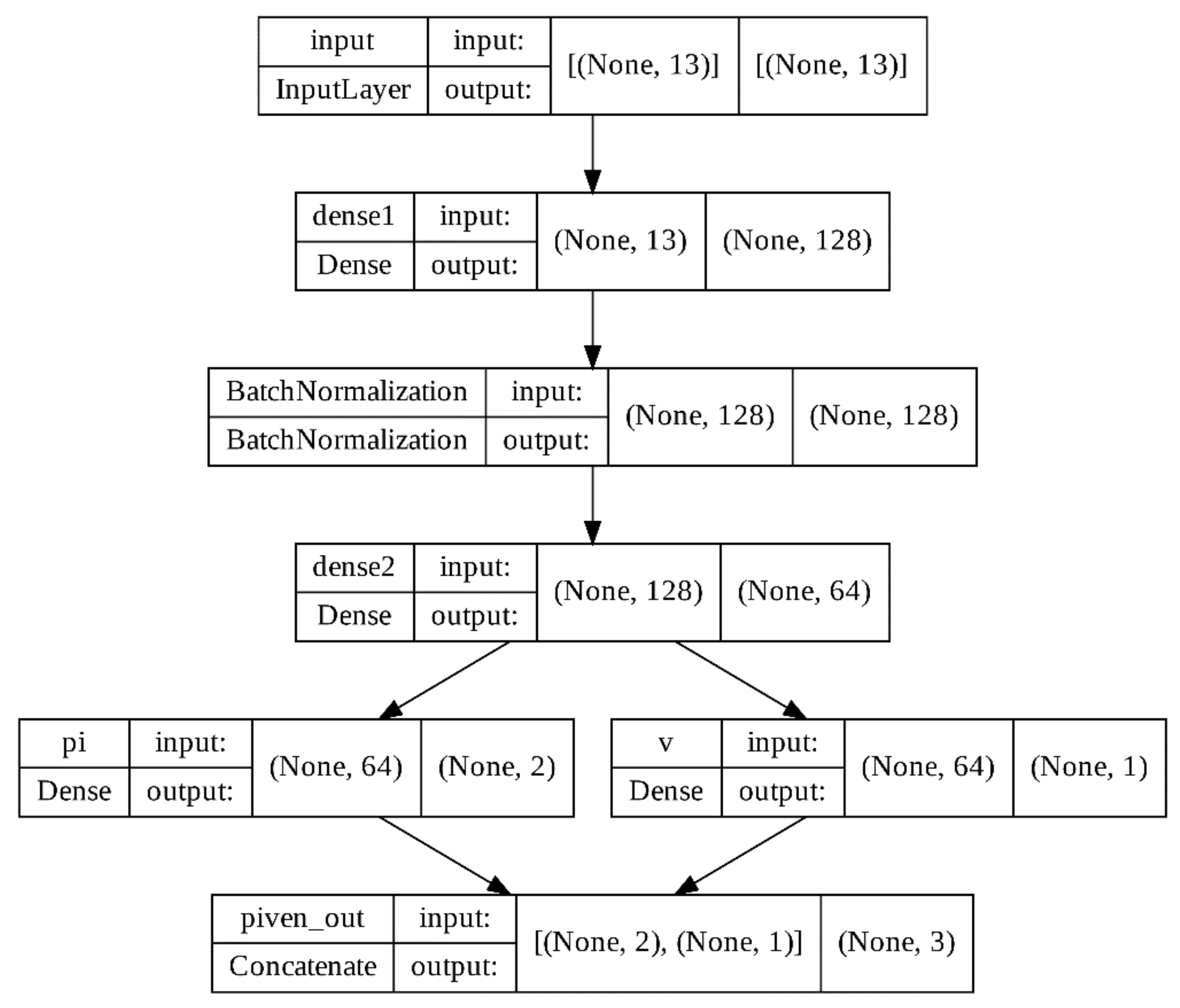
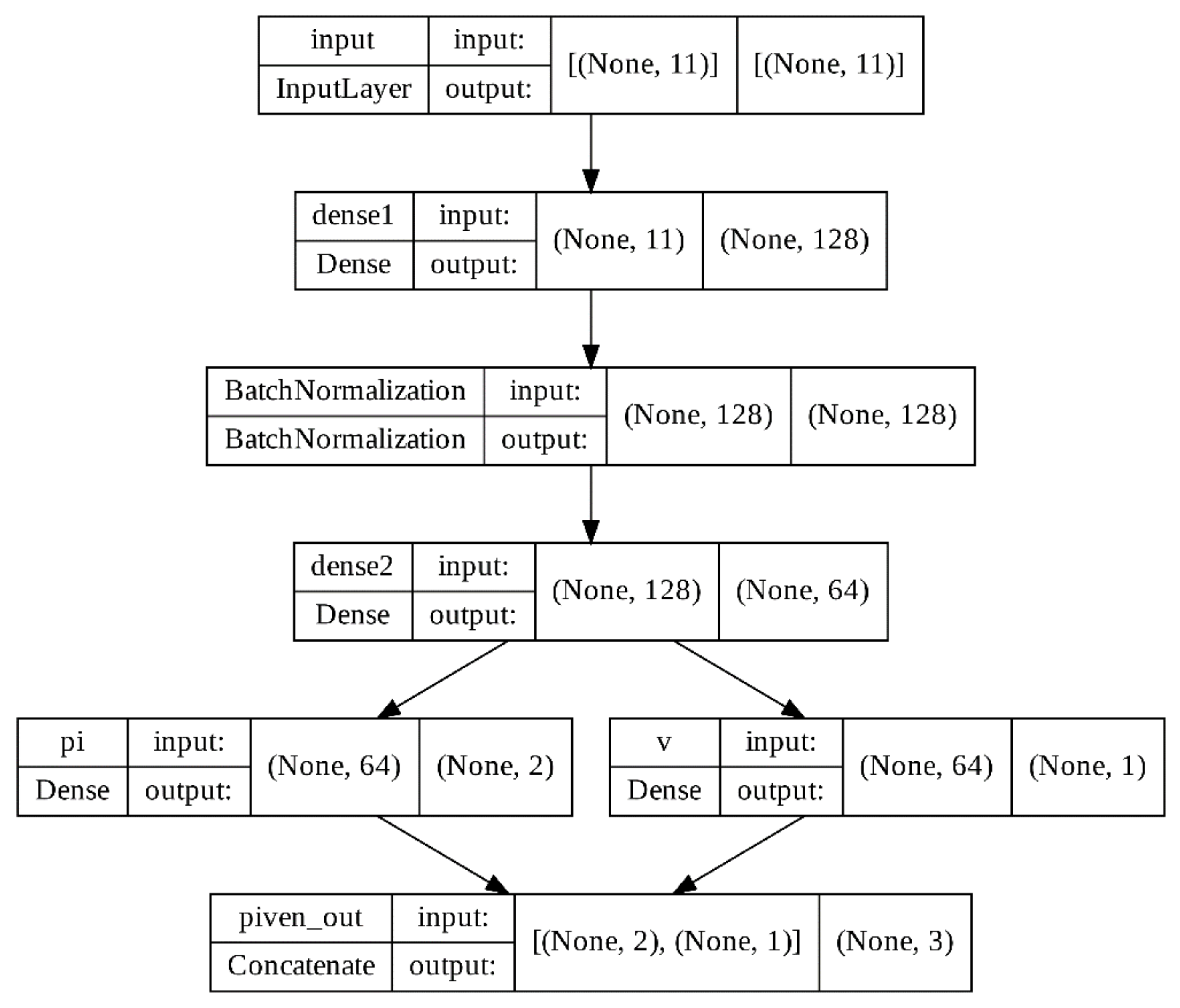
4. ML System for Predicting Lower Bound of ECRE2
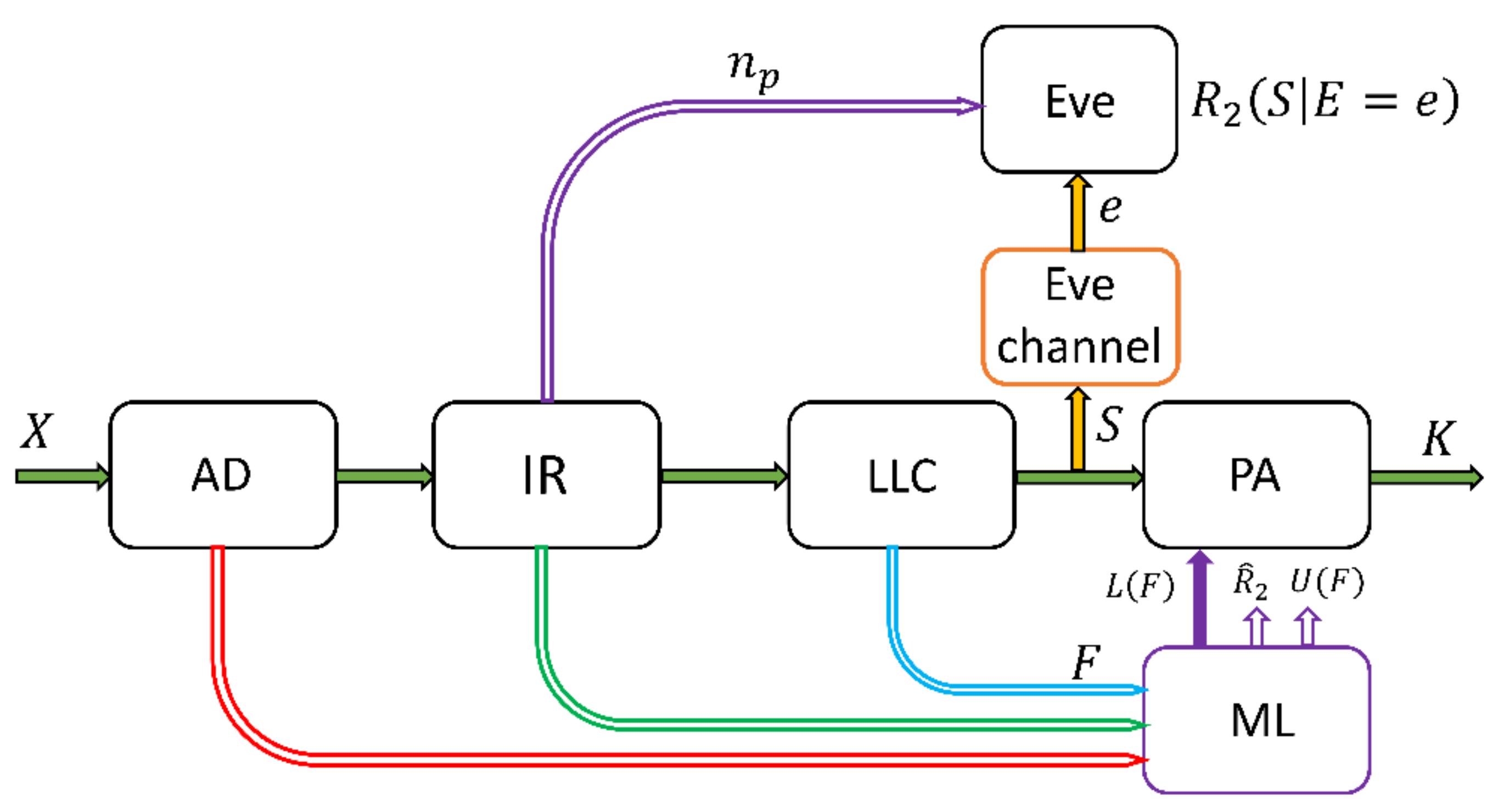
In the real operating conditions of a given SKD, since the selected DMS is known, it is possible to form training sets of the following structure, see
Figure 3:
where
N is the length of individual DMS sequences participating in the protocol, and
M is the number of these sequences in the training set. Since
determine
, we get the training set
and its final form
The feature vectors
are formed during the execution of SKD so that they are calculable entirely from the information possessed by Alice. As shown symbolically in
Figure 3, these features are usually formed based on information on Alice’s side after the execution of individual sub-blocks of SKD. Note that we limit ourselves to the direct SKD, in which Alice starts the protocol and determines the final key length [
21]. The same procedure applies to the inverse protocol, in which Alice and Bob switch roles.
Remark 4. The transition from the training set (13) to the final form (14) requires the calculation of ECRE2 for all pairs. It can be done based on the expressionwhereis the bit error probability of equivalent binary symmetric channel (BSC), whose input isand output[7]. A good estimate of, is normalized Hamming distancebetween. The normalized Hamming distance between two binary sequences X and Y of the same length is given by If the ML block at the output would only provide an estimate for ECRE2, which then be used in (12) to calculate the length of the distilled secret key, we have no guarantee that the value will be less than the true value of ECRE2. According to Theorem 2, the secret keys generated in this way would not have the desired cryptographic properties of uncertainty and negligible leakage of information to Eve.
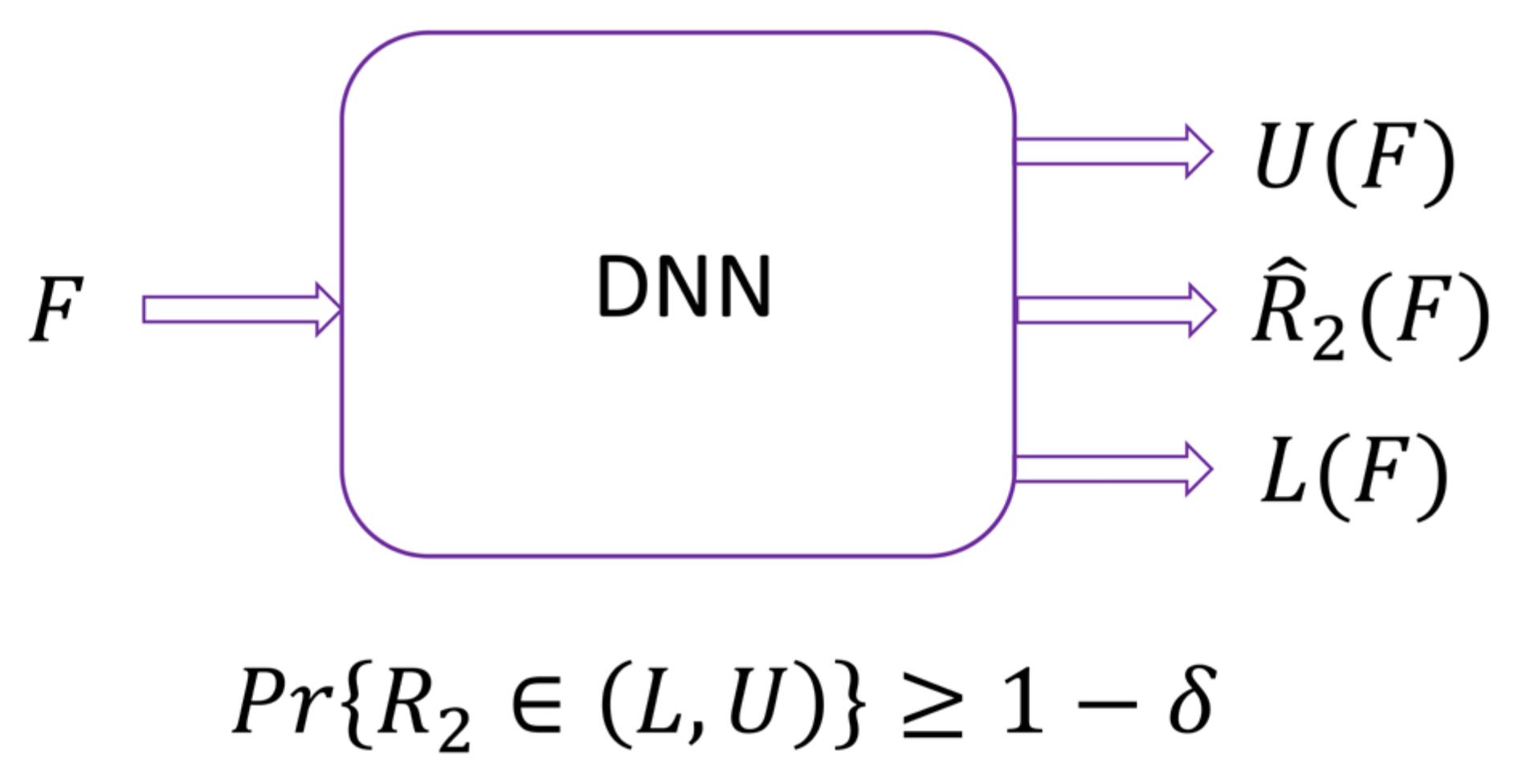
Therefore, the ML block should output an interval in which, with a given high probability of
, the true value of ECRE2 falls, see
Figure 4. Then we could use the lower bound
of that interval as an estimate for ECRE2 in (12). According to Theorem 3, we now have a guarantee of the desired cryptographic properties for the obtained keys.
In the field of machine learning, the regression block shown in
Figure 4 is known as the prediction interval (PI) deep neural network (DNN) model, designed to produce PI for each sample [
22,
23,
24]. The usual approach to train PIDNN is based on two criterion functions: coverage and mean prediction interval width [
25].
Coverage is the ratio of dataset samples that fall within their respective PIs, measured using the prediction interval coverage probability (PICP) metric
where
n denotes the number of samples and
, otherwise
. It is obvious that
PICP tends to
Mean prediction interval width (MPIW) is a quality metric for the generated PIs whose goal is producing as tight a bound as possible:
The training of PIDNN is performed by the MPIW minimization optimization procedure while keeping the predefined PICP. By combining into a single criterion, we get an unconstrained loss function
where
Ψ is a quadratic penalty function and
λ is a hyperparameter controlling the relative importance of width vs. coverage. The algorithm used in this paper is based on the optimization described in [
24] and the software package provided on the corresponding GitHub repository [
26].
PA strategy based on PIDNN we will call machine learning strategy. It can be formulated by
In the PA system, based on the strategy (21), there may be a situation where
, where c is the global lower bound of ECRE2. Then the global lower bound strategy (9) is better, which justifies the introduction of the next strategy, which we will call the
hybrid PA strategy
where
while
is the value of ECRE2 satisfying the condition
been coverage value (17) of PIDNN trained on given DMS.
Figure 5 shows the global flow chart of the proposed PA design methodology based on machine learning.
5. Experimental Evaluation
In the previous section, we defined four different PA strategies:
The experimental evaluation of these strategies was carried out within a general methodological framework, which allows their fair comparison. This implies that different PA strategies are compared by fixing the source, AD and IR part of the SKD, and then varying the PA strategies. In order to get an idea of the dependence of the obtained results on the sources, two different sources were chosen, both in terms of their nature and probabilistic properties.
5.1. Sources of Common Randomness
All evaluation was performed on two sources of common randomness, both obtained from electroencephalography (EEG) signals recorded using the 14-channel EMOTIV EPOC+ wireless EEG headset [
27,
28]. A detailed argumentation regarding the practical application of this transducer as a source of common randomness in SKD protocols is given in [
6].
The first source, which we will call raw EEG, is formed by the serialization of all 14 EEG channel signals. The second source, which we will call EEG metrics, is formed by serialization of 6-dimensional performance metrics, denoted by interest (i.e., emotional valence, attractiveness, or averseness of the task at hand), engagement (or boredom, in negative valence, reflecting the mental workload), excitement (arousal, emotional intensity), stress (frustration), relaxation (meditation), and focus (attention) [
28].
Table 1 shows the basic parameters of these sources.
The signals were recorded from 50 participants aged 20–65 years selected randomly among the employees of Vlatacom Institute of High Technology, Belgrade, Serbia. The participants were aware of the research procedure, including the application of the sensors, and voluntarily agreed to take the test. The institutional ethics committee approved this research following the principles of the Declaration of Helsinki.
The EEG signal recording session lasted 20 min for each participant, who could do whatever they wanted during that time. As a rule, the participants read web content from the Internet, played games, worked on their projects, or meditated. For each participant, two samples of 2 s of recording for the raw EEG source, or two samples of 300 s for the source of EEG metrics, were then randomly selected. In this way, 100 samples were formed for each source.
5.2. Architectures of Evaluated Systems
Based on the general architecture of the system from
Figure 3, three special variants, which we will denote as System A, B, and C, were selected for experimental evaluation.
System A consists of the sequence of BP ADD→CASCADE→Universal Hash blocks, where the BP ADD block denotes the bit parity advantage distillation/degeneration protocol [
29], and the CASCADE block denotes the one class of IR protocols, first proposed in [
30]. This protocol has found wide application in the domain of quantum key distribution and, as such, has been continuously improved and optimized. In this paper, we used an implementation described in [
31] and its associated GitHub repository [
32].
System B consists of the sequence of ADD→WINNOW→Universal Hash blocks, where the WINNOW block denotes a class of IR protocols based on error-correcting codes [
33].
System C consists of a sequence of blocks ADD→WINNOW→Huffman coding→Universal Hash, where the Huffman coding block performs lossless compression based on Huffman source codes [
34]. Huffman coders are synthesized based on local sequences at the output of the IR block. Since these sequences are the same for Alice and Bob, the resulting encoders will be the same for them and need not be exchanged over the public channel.
For all three systems, the BP ADD algorithm is executed in the AD block since it proved to be significantly more efficient than the standard bit parity advantage distillation (BP AD) algorithm [
35].
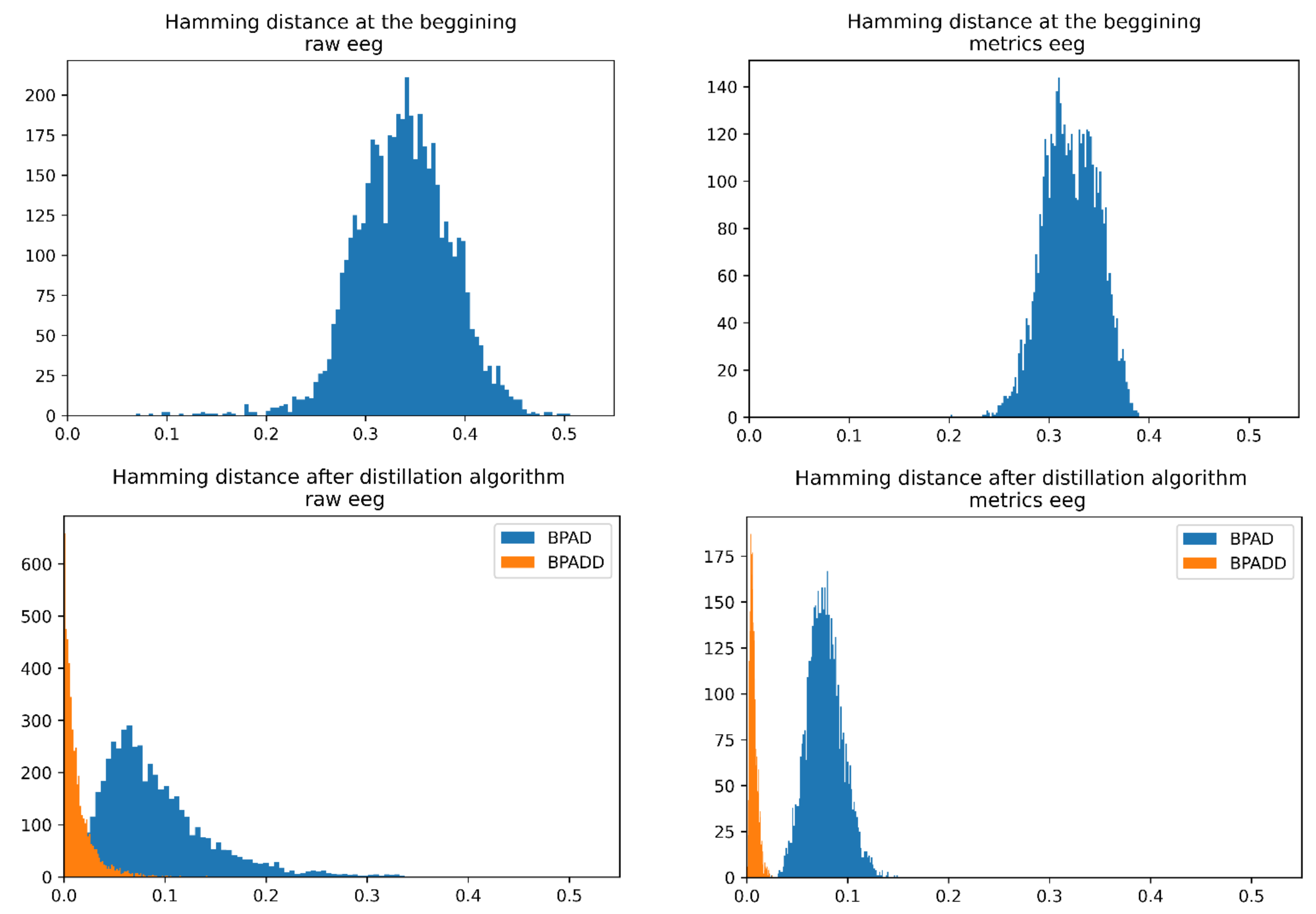
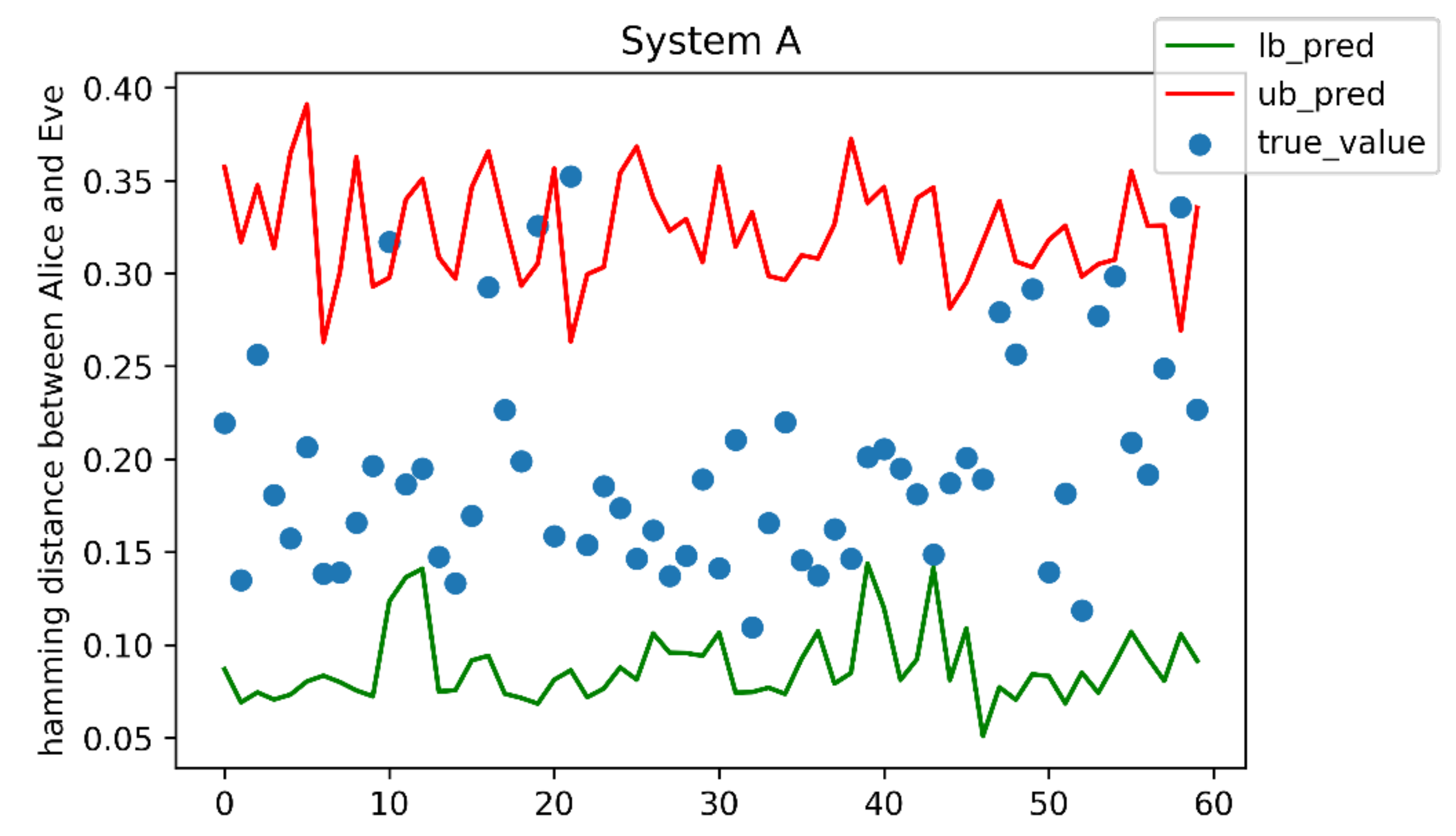
Figure 8 illustrates this fact. The top row shows the histograms of mutual normalized Hamming distances of all 100
99/2 = 4950 pairs (Alice, Bob) of sequences for the given initial set of 100 sequences. The bottom row shows a histogram of normalized Hamming distances for the same set of pairs after the end of the AD phase. It can be seen that the BP ADD algorithm more significantly increases the correlation between (Alice, Bob) sequences than the BP AD algorithm. Let us keep in mind that identical sequences have a normalized Hamming distance equal to zero, and uncorrelated sequences have a distance equal to 0.5.
The training set is formed for each of the analyzed systems in such a way that for each pair of sequences (Alice, Bob) the corresponding Eve sequence is randomly selected from the remaining sequences. This choice of the eavesdropper is close to the worst-case scenario for the efficiency of the SKD protocol since Eve is actually an insider. Namely, Eve belongs to the population that was selected to represent the future users of the system as representatively as possible.
Table 2 provides an overview of features F, which are measured during the execution of the SKD protocol for all 4950 pairs of legitimate users.
Having in mind Remark 4, the normalized Hamming distance between was taken for the desired output in the training set. This practically means that PIDNN is trained to predict ε, and then this output is translated into ECRE2 by functional transformation (15). Experimental results show that this approach is more efficient than direct ECRE2 prediction.
PIDNN training was performed by 10-fold cross-validation over all 4950 pairs of legitimate users. Lower bound predictions
were calculated on the corresponding test sets for each cross-validation iteration. In this way, after completing 10 rounds of cross-validation, predictions were obtained for all 4950 pairs of legitimate users while preserving the independence of the training and test sets. Parameters of learning algorithm are: a number of epochs = 400, batch size = 32, with Adam optimizer and learning rate 0.0005 [
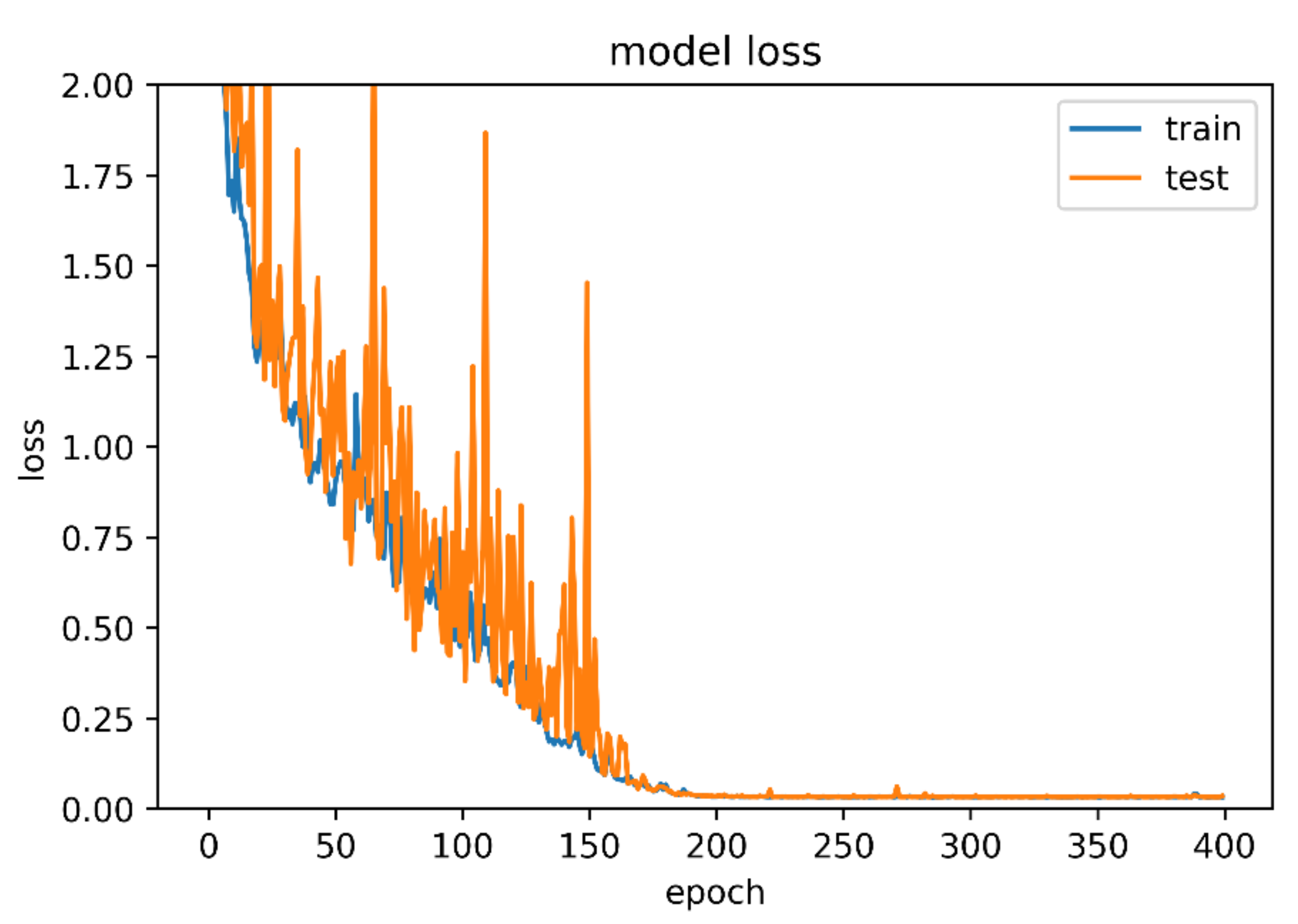
28]. For PI algorithm parameters are: λ = 15, and PICP = 0.95.
Figure 11 shows loss during training of PINDD.
5.3. Performance Measures
In order to compare individual PA strategies, we will introduce two indicators, gain and loss. Gain of PA strategy A over PA strategy B is defined as follows
where
and
denote the total length of generated keys using strategies A and B for the same input sequences
. Loss of PA strategy A is defined by
where
is the total length of generated keys using optimal PA strategy (12) for the same input sequences
.
The quantities appearing in
Table 3 and
Table 4 are defined as follows. PICP is given by (17), MPIW is defined by (18), R2 denotes the mean value, while
is the minimum value of ECRE2 over the entire population of size L of the given DMS
The mean value of the ECRE2 lower bound
obtained from PIDNN is denoted by
while the mean value of the corresponding lower bound
from the hybrid PA strategy is denoted by
which represents the potential gain in the length of the generated keys when applying the optimal PA strategy over the strategy based on the global lower bound
. Similarly,
is the gain in the length of the generated keys when applying the PA strategy based on machine learning compared to the standard procedure based on the global lower bound
for ECRE2. Corresponding losses
express percentage of the unused of a given DMS when applying global lower bound and machine learning PA strategy, respectively.
The key rate is given by
while the key acceptance rate is given by
The leakage rate measures the amount of information per bit contained in Eve’s keys about Alice and Bob’s common keys:
where
is the binary entropy function.
Quantities (25)–(31) characterize the performance of the system in terms of the length of the generated keys, provided that
and
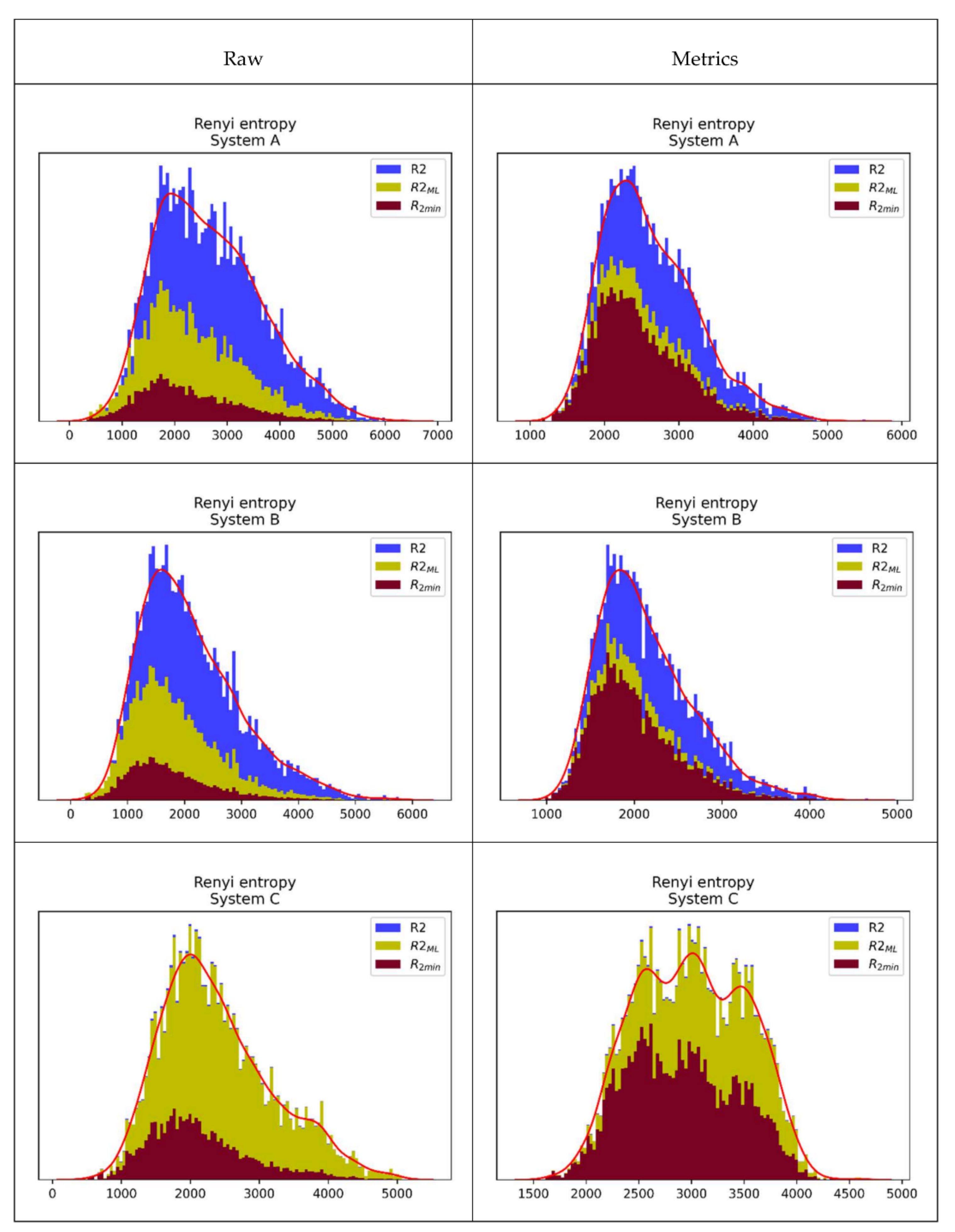
. In this way, ECRE2 was highlighted as the dominant factor affecting the lengths of the generated keys. In order to get a clear visual representation of the effects of different strategies on the degree of unused of a given source, specific histograms (see
Figure 13) were formed for each of the analyzed systems and sources. First, the ECRE2 histogram of the given source is calculated (blue color). It is also the theoretical limit of the possible length of generated keys, according to (12). Then we keep the bin structure of this basic histogram and calculate over them the histogram of key lengths generated by ML PA strategies (21) (yellow) and global lower bound PA strategy (9) (brown). The areas of these histograms are proportional to the total length of the generated keys of the corresponding PA strategies. Therefore,
(27) is proportional to the blue area,
(28) to the brown area, and
(29) to the yellow area. Gain indicators (31) and (32) are the ratios of blue and brown as well as yellow and brown areas, respectively. Loss indicators (33) and (34) can be interpreted similarly.
Table 3 summarizes all indicators for all three systems and both DMS.
Table 4 shows the results of the randomness tests of all generated key sequences. The randomness tests are based on the Statistical Test Suite developed by the U.S. National Institute of Standards and Technology NIST [
15]. The outcome of each experiment is represented by the
p-value. An individual test is considered to be passed successfully if the obtained
p-value is higher than the threshold of 0.01. Following the obtained results, it can be seen that all generated key sequences meet the defined randomness criteria in all presented tests.
The results of testing the hybrid strategy are given in
Table 5. The value of
is defined by (24), while the other indicators are given by
Table 6 shows the results of the randomness tests of all generated key sequences.
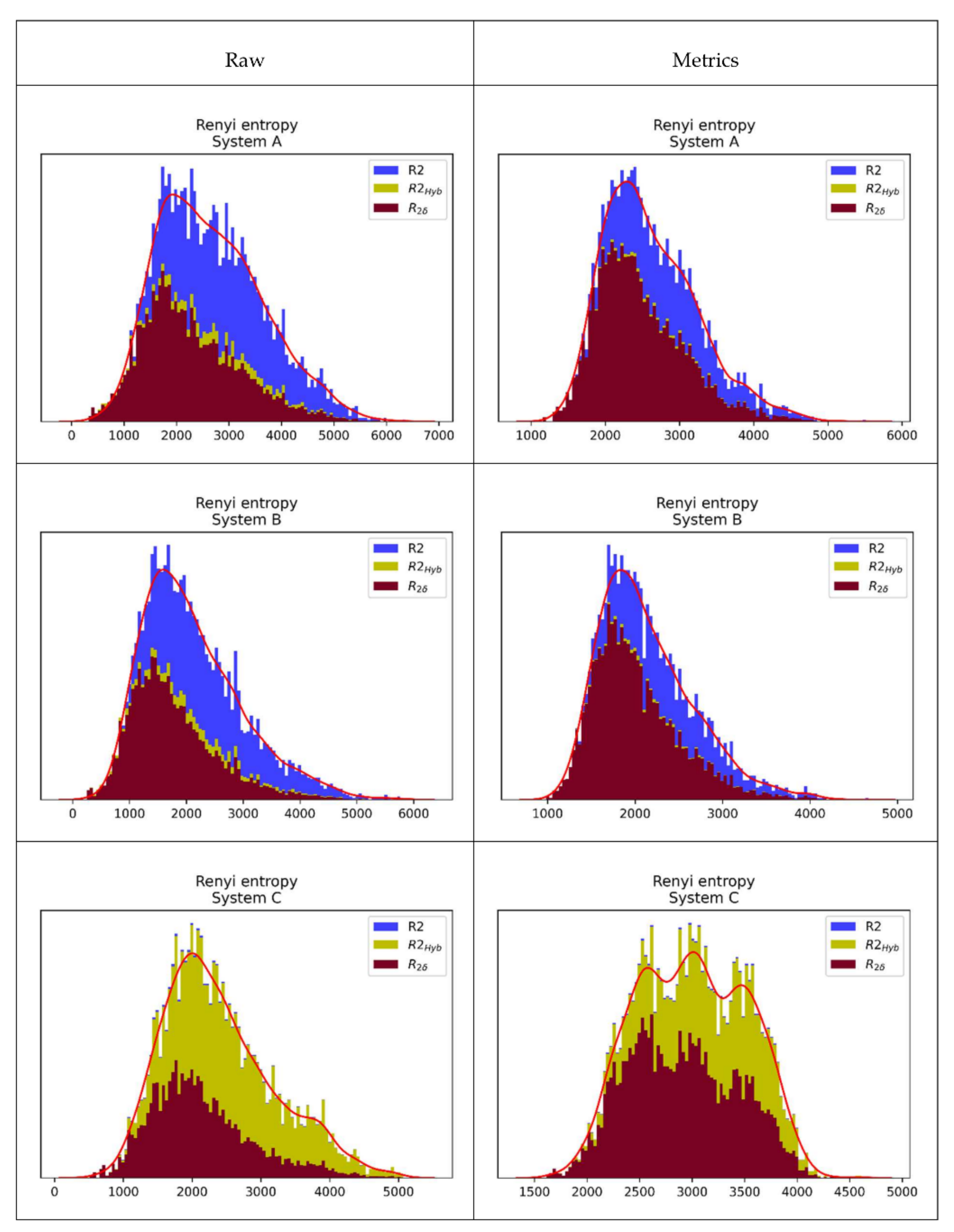
Histograms of generated key lengths for optimal, hybrid, and global lower bound
PA strategies are presented in
Figure 14.
- (a)
For all systems and all sources, the generated keys passed NIST randomness tests with a high margin of confidence;
- (b)
On average, across all systems and sources, the GLB strategy leaves almost 68% of ECRE2 potential unused. By introducing the ML strategy, the unused is reduced to 35%, and the hybrid strategy would further reduce this indicator to 32%;
- (c)
On average, across all systems and sources, the ML strategy increases the quantity of generated keys by 2.61 times compared to the GLB strategy. The hybrid strategy further increases this indicator to 2.77 times;
- (d)
The average value for the parameter across all systems and sources is , see (24). Since it is a very small value, according to Remark 2, generated keys have almost maximal entropy for Eve. The further consequence of this fact is the very small average leakage rate that is per one key bit;
- (e)
Note the dramatic difference of two orders of magnitude in the leakage rate between the classic HLL strategy and the proposed ML hybrid strategy (
, last two rows of
Table 5);
- (f)
On average, across all systems and sources in terms of KR indicators, hybrid strategies give better results than non-hybrid ones (4.41 vs. 3.91). The same is valid for the KAR indicator (98.84% vs. 97.29%);
- (g)
Averaged by sources, the performance of systems A, B, and C are ranked as A < B < C for all important indicators, such as KR, KAR, LR, and . The same relationships are observed for hybrid strategies;
- (h)
System C has a loss close to 0, unlike systems A and B, where this parameter is 52.6%;
- (i)
Averaged across sources, ML gain with respect to the GLB strategy amounts to (2.28, 2.32, 3.23) for systems A, B, and C, respectively;
- (j)
In systems A and B, the hybrid strategy provides improvements of 10–12%, while for system C they do not provide a significant improvement compared to the basic ML strategy;
- (k)
In terms of all performances, system C significantly exceeds systems A and B by giving = 3.23, = 0.76%, = 0.295 , and .
5.4. Security Analysis
The presented PA strategies based on machine learning introduce an additional ML block compared to standard PA strategies. From the point of view of security, this does not reduce the uncertainty of the generated keys since the output of this block is the output dimension of the applied hash function, which is also sent to all parties via the public channel as a public parameter in the original version of the protocol.
In the training phase, the system designer can incorporate additional a priori information about the expected Eve strategy. This strategy can be different from the worst-case scenario, which we adopted in this research, taking Eve as a de facto insider from the set of expected users of the system.
The introduction of a block for lossless compression based on Huffman’s optimal coding also does not impair the security performance of the system. Namely, the Huffman coder is uniquely determined by the common sequence that Alice and Bob have before the PA block. Therefore, Alice and Bob generate their own Huffman codes locally without requiring any additional communication over the public channel. Eve’s strategy, in this case, can be two-fold. The first possibility is to generate a local Huffman coder on its sequence. In that case, any mismatch of its sequence with the Alice, Bob sequence has an effect very similar to applying some equivalent hash function with the same degree of compression. Another possibility is that Eve owns a local Huffman encoder formed by Alice and Bob. Due to the mismatch of the coder with the local Eve sequence, the output sequence will be very similar to the result of the equivalent hash function, as in the first strategy. The experimental evaluation shows that the Huffman coder not only does not compromise the security performance of the system but improves it to a significant extent, which is best seen by the significantly lower value of the LR indicator of system C compared to systems A and B, regardless of the type of source and type of strategy (hybrid or not hybrid).
6. Conclusions
In this paper, a new methodology for the synthesis of the PA block of the SKD system based on machine learning was introduced. In offline mode, before the execution of the protocol itself, the PIDNN was trained on the training set drawn from the given DMS. In protocol execution mode, trained PIDNN gives a local lower bound for ECRE2 with high precision and confidence.
The proposed theoretical-empirical methodology of PA block analysis and design allows us to give new answers to two difficult questions posed in the introductory part of the paper,
How much of the total available pure randomness is allocated to secret keys?
Is there any leakage toward eavesdroppers, and what is the real security margin of the generated secret keys?
The proposed PA block design methodology allows us to quantify both phenomena mentioned in these questions. In addition, it allows us to precisely quantify the advantage of the proposed hybrid ML strategy over previously known GLB and HLL strategies. The proposed ML and hybrid strategies far surpass GLB and HLL classic PA design in all aspects.
In particular, System C, which consists of the sequence of blocks ADD→WINNOW→Huffman coding→Universal Hash, in terms of efficient utilization of the given DMS, gives almost ideal results (percentage of unused is 0.75%). This property is of particular importance in today’s time of “hunger” for efficient sources and methods of generation and distribution of absolutely secret cryptographic keys.
A particularly interesting and unexpected result is the large leakage of information toward Eve in the classical HLL strategy, which today dominates the practical application of SKD. This result shows that although these systems pass NIST randomness tests, such as in [
14], they are susceptible to an efficient dictionary-based attack that allows Eve to reconstruct the Alice and Bob strings before entering the hash block.
Our next research efforts will be focused on trying to replace the entire AD—IR—LLC—PA processing chain with a unique machine learning structure.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}