
Attention Optimized Deep Generative Adversarial Network for Removing Uneven Dense Haze




Abstract
:1. Introduction
- We propose a fully end-to-end network for single image dehazing. It can output a haze-free image directly from one hazy image without calculating intermediate parameters. Our method uses a generative adversarial network as the framework, which makes our network more robust, and even trained in a small-scale dataset.
- To better extract the semantic information degraded due to the dense haze, we employ a densely connected four-layer down-sampling. At the same time, the local learning mechanism is also introduced to allow the information of the thin haze region and low-frequency information to be passed through the down-sampling operation and be reserved.
- Spatial attention and channel attention module are introduced to our method. Considering the uneven distribution of haze in space and different feature channels have different sensitivity to haze concentration, it is not appropriate to use the same weights for them. Attention module allows for the assignment of different weights to different locations and channels, which helps the network to learn the uneven distribution haze and better deal with uneven dense haze.
2. Related Works
2.1. Traditional Algorithms
2.2. Learning-Based Algorithms
2.3. Generative Adversarial Network
3. Methods
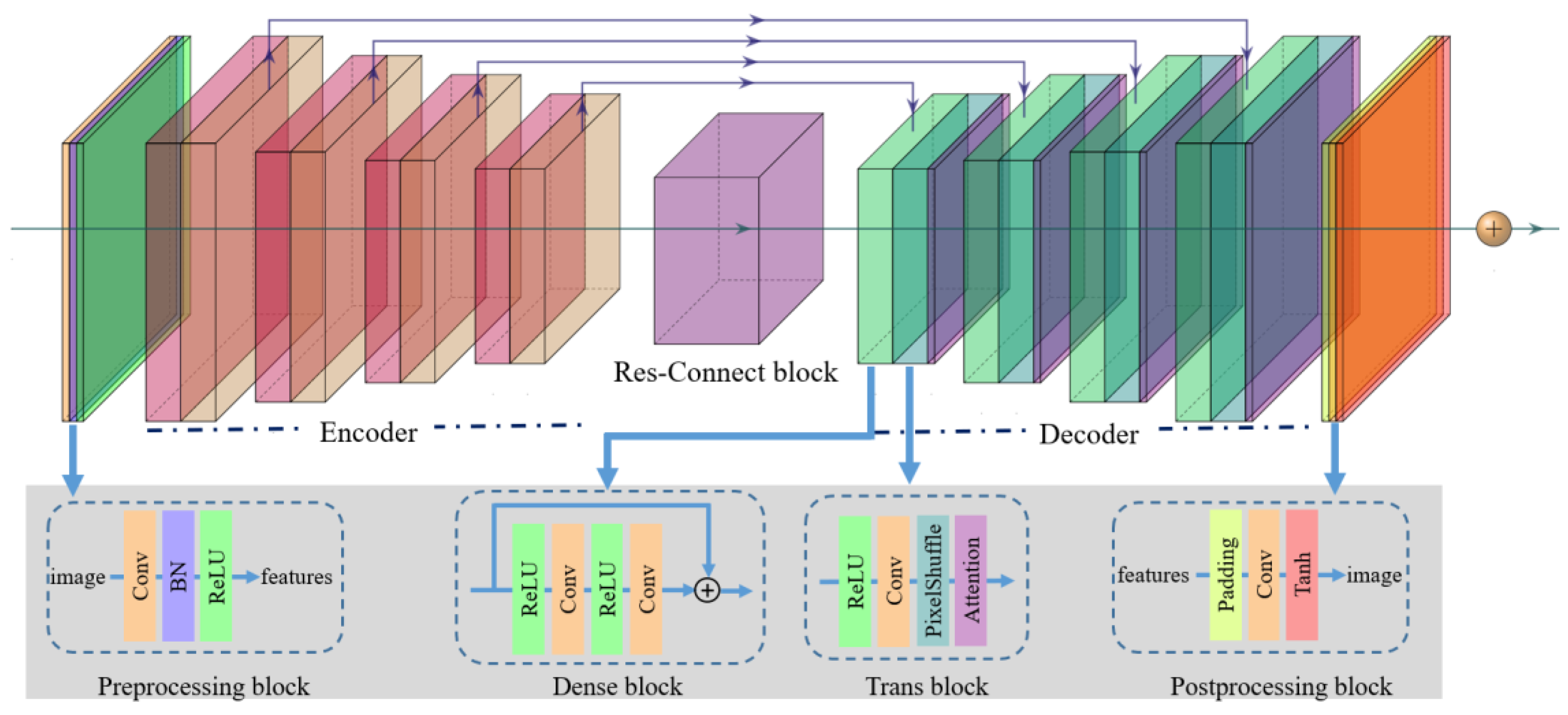
3.1. Overall Framework
3.2. Four-Layer Down-Sampling Encoder with Dense Residual Connection
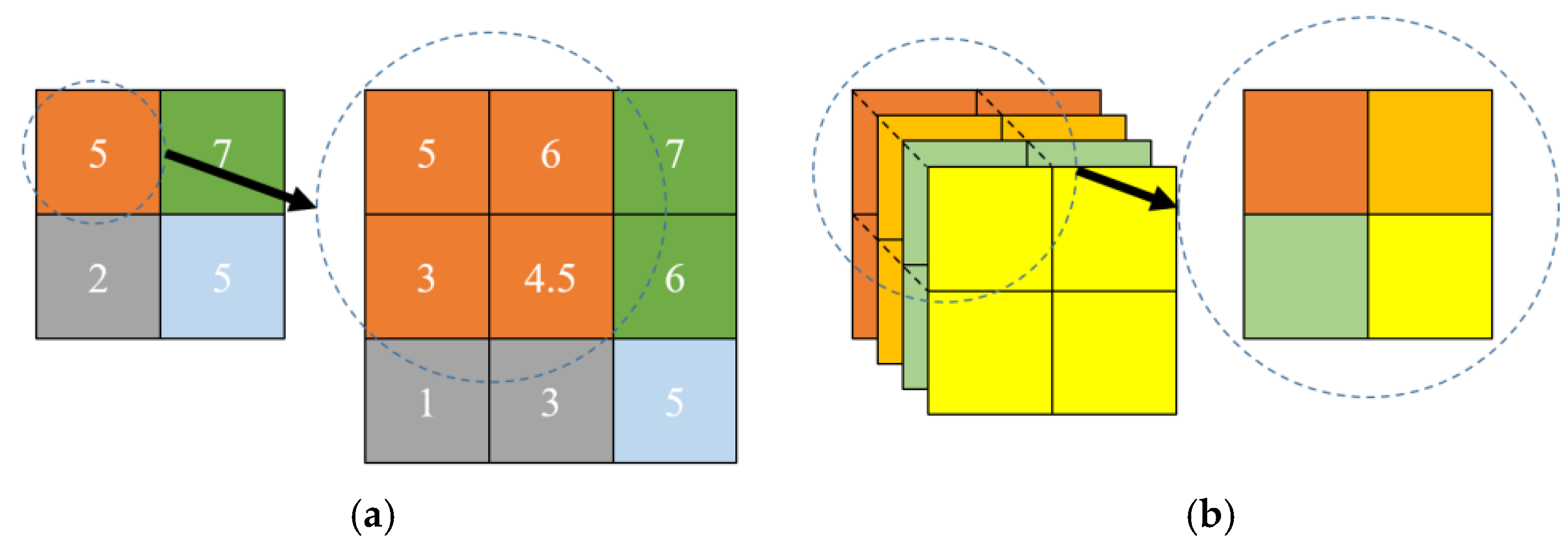
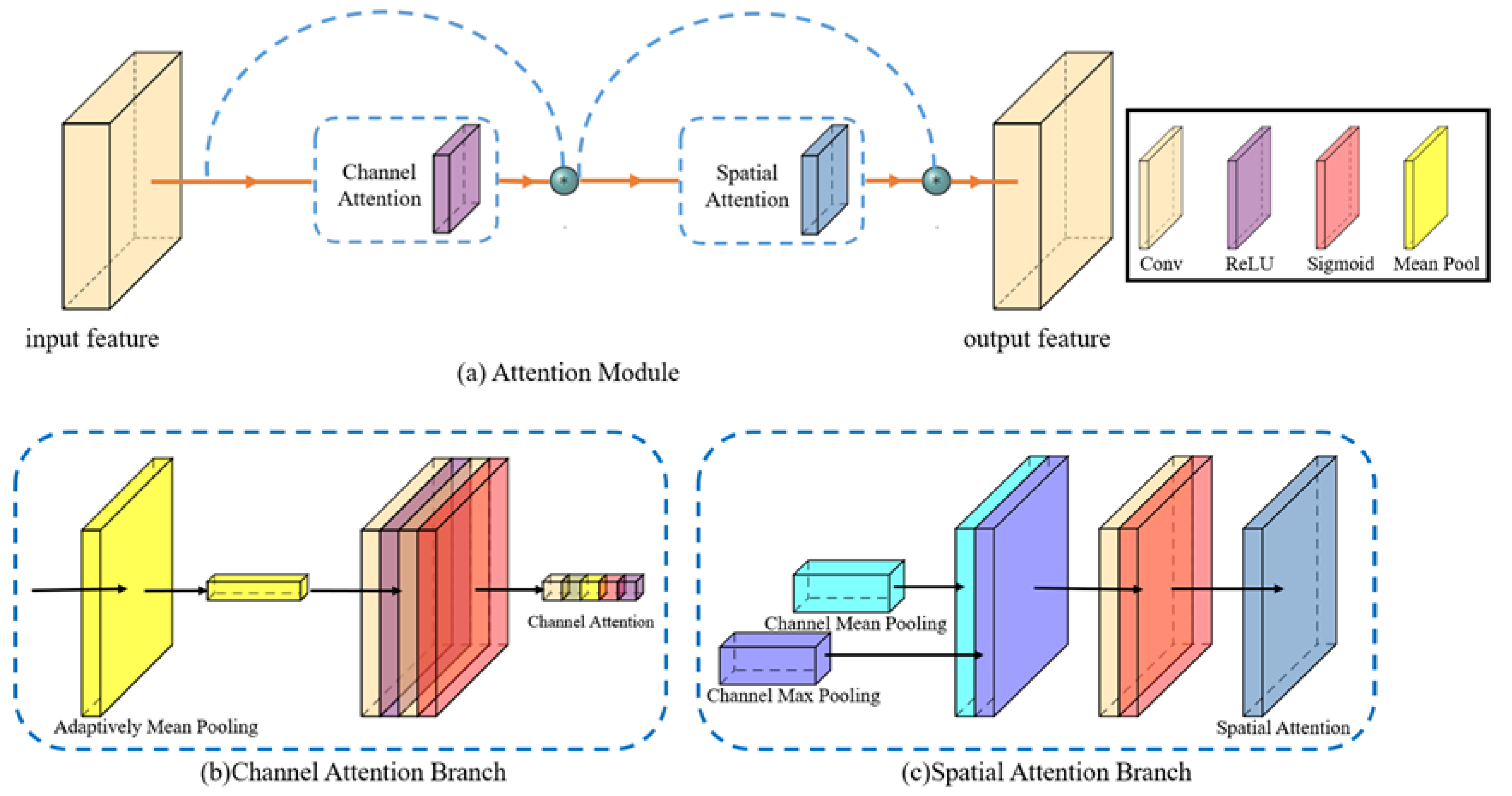
3.3. Attention Optimized Decoder
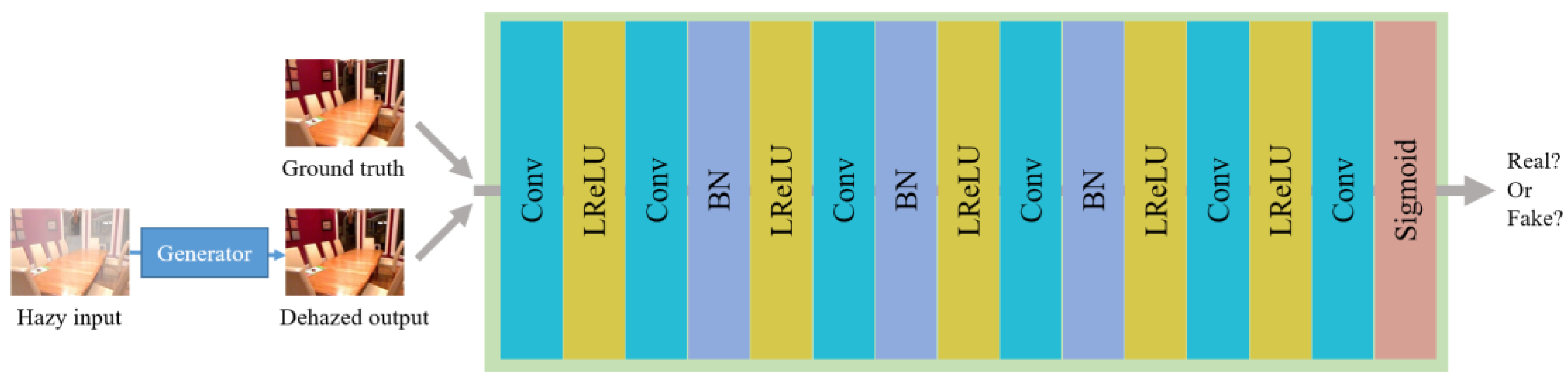
3.4. Discriminator Network
3.5. Loss Function
4. Experiments
4.1. Datasets and Metrics
4.2. Implement Details
4.3. Experiment Results
4.4. Experiment on Large-Scale Dataset
4.5. Experiment on Real-World Images
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mccartney, E.J. Scattering phenomena. (book reviews: Optics of the atmosphere. scattering by molecules and particles). Science 1977, 196, 1084–1085. [Google Scholar]
- Cartney, E.J. Optics of the Atmosphere: Scattering by Molecules and Particles; John Wiley and Sons, Inc.: New York, NY, USA, 1976; 421p. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Chromatic framework for vision in bad weather. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2000 (Cat. No.PR00662), Hilton Head, SC, USA, 15 June 2000; IEEE: San Diego, CA, USA; Volume 1, pp. 598–605. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Vision and the atmosphere. Int. J. Comput. Vis. 2002, 48, 233–254. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. Single image dehazing using color attenuation prior. In BMVC; Citeseer: Park, PA, USA, 2014. [Google Scholar]
- Berman, D.; Treibitz, T.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–14. [Google Scholar]
- Fattal, R. Dehazing using color-lines. ACM Trans. Graph. (TOG) 2014, 34, 13. [Google Scholar] [CrossRef]
- Jiang, Y.; Sun, C.; Zhao, Y.; Yang, L. Image dehazing using adaptive bi-channel priorson superpixels. Comput. Vis. Image Underst. 2017, 165, 17–32. [Google Scholar] [CrossRef]
- Ju, M.; Gu, Z.; Zhang, D. Single image haze removal based on the improved atmospheric scattering model. Neurocomputing 2017, 260, 180–191. [Google Scholar] [CrossRef]
- Meng, G.; Wang, Y.; Duan, J.; Xiang, S.; Pan, C. Efficient image dehazing with boundary constraint and contextual regularization. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 617–624. [Google Scholar]
- Rahman, Z.; Aamir, M.; Pu, Y.-F.; Ullah, F.; Dai, Q. A smart system for low-light image enhancement with color constancy and detail manipulation in complex light environments. Symmetry 2018, 10, 718. [Google Scholar] [CrossRef] [Green Version]
- Ngo, D.; Lee, S.; Lee, G.-D.; Kang, B. Automating a Dehazing System by Self-Calibrating on Haze Conditions. Sensors 2021, 21, 6373. [Google Scholar] [CrossRef] [PubMed]
- Hajjami, J.; Napoléon, T.; Alfalou, A. Efficient Sky Dehazing by Atmospheric Light Fusion. Sensors 2020, 20, 4893. [Google Scholar] [CrossRef] [PubMed]
- He, T.; Liu, Y.; Yu, Y.; Zhao, Q.; Hu, Z. Application of deep convolutional neural network on feature extraction and detection of wood defects. Measurement 2020, 152, 107357. [Google Scholar] [CrossRef]
- Hu, Y.; Lu, M.; Xie, C.; Lu, X. Video-based driver action recognition via hybrid spatial-temporal deep learning framework. Multimed. Syst. 2021, 27, 483–501. [Google Scholar] [CrossRef]
- Feng, X.; Gao, X.; Luo, L. HLNet: A Unified Framework for Real-Time Segmentation and Facial Skin Tones Evaluation. Symmetry 2020, 12, 1812. [Google Scholar] [CrossRef]
- He, Y.; Cao, W.; Du, X.; Chen, C. Internal Learning for Image Super-Resolution by Adaptive Feature Transform. Symmetry 2020, 12, 1686. [Google Scholar] [CrossRef]
- Wu, Y.; Ma, S.; Zhang, D.; Sun, J. 3D Capsule Hand Pose Estimation Network Based on Structural Relationship Information. Symmetry 2020, 12, 1636. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Patel, V.M. Densely connected pyramid dehazing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.-H. Single image dehazing via multi-scale convolutional neural networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao, X.; Liu, W.; Yang, M.-H. Gated fusion network for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Qu, Y.; Chen, Y.; Huang, J.; Xie, Y. Enhanced pix2pix dehazing network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Shao, Y.; Li, L.; Ren, W.; Gao, C.; Sang, N. Domain adaptation for image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.-H. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking Single-Image Dehazing and Beyond. IEEE Trans. Image Process. 2019, 28, 492–505. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ronneberger, O.; Philipp, F.; Thomas, B. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, pp. 105–114. [Google Scholar]
- Wu, B.; Duan, H.; Liu, Z.; Sun, G. SRPGAN: Perceptual generative adversarial network for single image super resolution. arXiv Preprint 2017, arXiv:1712.05927. [Google Scholar]
- Yi, X.; Babyn, P. Sharpness-aware low-dose CT denoising using conditional generative adversarial network. Digit. Imaging 2018, 31, 655–669. [Google Scholar] [CrossRef]
- Liu, J.; Sun, W.; Li, M. Recurrent conditional generative adversarial network for image deblurring. IEEE Access 2018, 7, 6186–6193. [Google Scholar] [CrossRef]
- Song, H.; Wang, R. Underwater Image Enhancement Based on Multi-Scale Fusion and Global Stretching of Dual-Model. Mathematics 2021, 9, 595. [Google Scholar] [CrossRef]
- Dong, Y.; Liu, Y.; Zhang, H.; Chen, S.; Qiao, Y. FD-GAN: Generative adversarial networks with fusion-discriminator for single image dehazing. Proc. Conf. AAAI Artif. Intell. 2020, 34, 10729–10736. [Google Scholar] [CrossRef]
- Deng, Q.; Huang, Z.; Tsai, C.-C.; Lin, C.-W. Hardgan: A haze-aware representation distillation gan for single image dehazing. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Suárez, P.L.; Sappa, A.D.; Vintimilla, B.X.; Hammoud, R.I. Deep learning based single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhu, H.; Peng, X.; Chandrasekhar, V.; Li, L.; Lim, J.-H. DehazeGAN: When Image Dehazing Meets Differential Programming. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; pp. 1234–1240. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Berstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Shi, W.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video su-per-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhang, X.; Wang, T.; Wang, J.; Tang, G.; Zhao, L. Pyramid channel-based feature attention network for image dehazing. Comput. Vis. Image Underst. 2020, 197, 103003. [Google Scholar] [CrossRef]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. Proc. Conf. AAAI Artif. Intell. 2020, 34, 11908–11915. [Google Scholar] [CrossRef]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. Griddehazenet: Attention-based multi-scale network for image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Simonyan, K.; Andrew, Z. Very deep convolu-tional networks for large-scale image recognition. arXiv Preprint 2014, arXiv:1409.1556. [Google Scholar]
- Ancuti, C.; Ancuti, C.O.; Timofte, R.; Vleeschouwer, C.D. I-HAZE: A dehazing benchmark with real hazy and haze-free indoor images. In International Conference on Advanced Concepts for Intelligent Vision Systems; Springer: Cham, Switzerland, 2018; pp. 620–631. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; Timofte, R.; Vleeschouwer, C.D. O-haze: A dehazing benchmark with real hazy and haze-free outdoor images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 754–762. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv Preprint 2014, arXiv:1412.6980. [Google Scholar]
- dehazeGAN. Available online: https://github.com/kirqwer6666/dehazeGAN (accessed on 1 December 2021).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
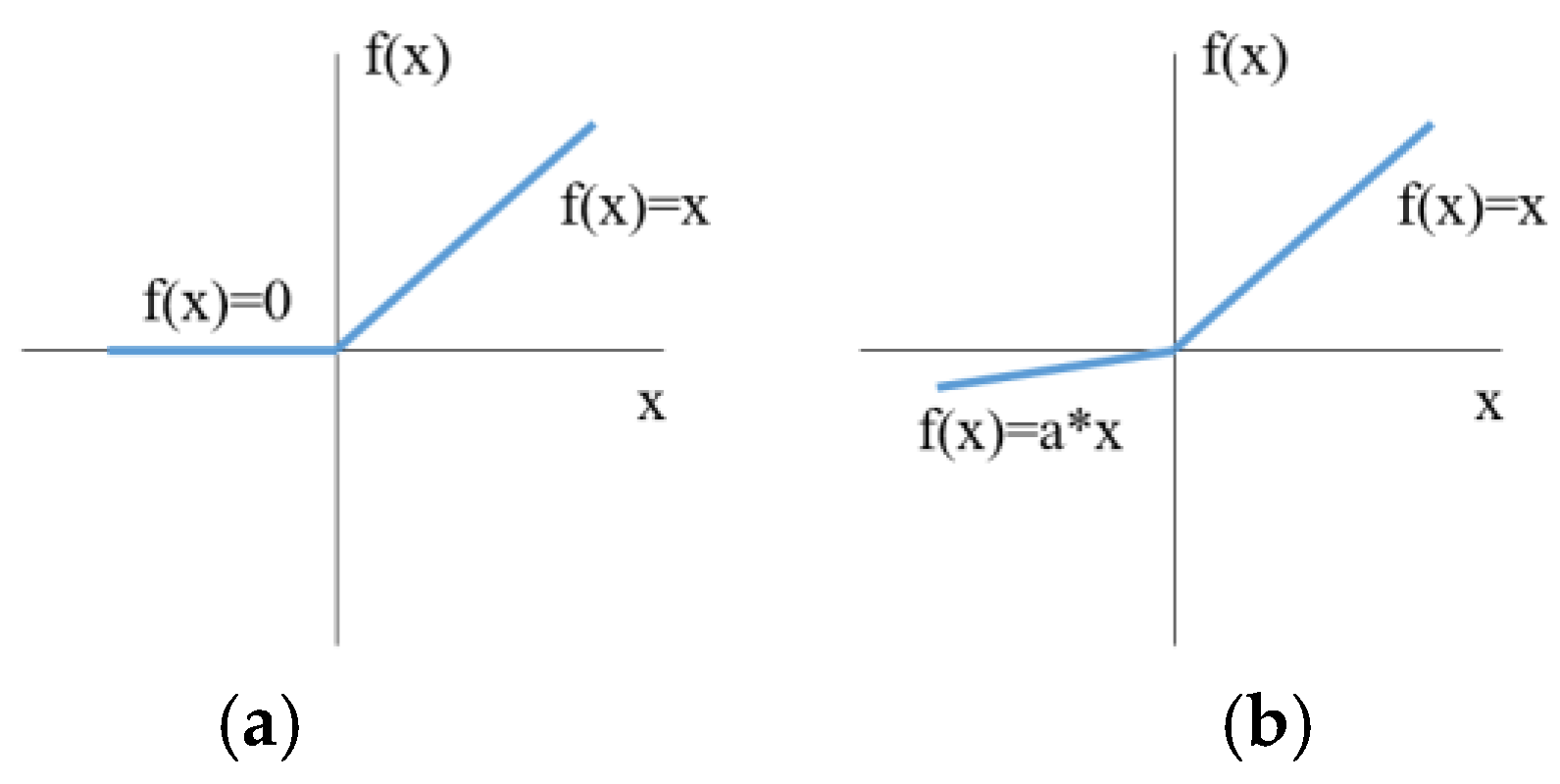{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DCP [5] | CAP [6] | DehazeNet [21] | DCPDN [22] | AOD-Net [24] | Ours | ||
|---|---|---|---|---|---|---|---|
| I-HAZY | PSNR | 14.43 | 14.62 | 15.72 | 16.21 | 13.98 | 22.17 |
| SSIM | 0.752 | 0.767 | 0.734 | 0.755 | 0.732 | 0.793 | |
| O-HAZY | PSNR | 16.78 | 16.01 | 16.12 | 15.16 | 15.03 | 22.72 |
| SSIM | 0.653 | 0.681 | 0.612 | 0.673 | 0.539 | 0.784 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, W.; Zhao, Y.; Feng, L.; Tang, J. Attention Optimized Deep Generative Adversarial Network for Removing Uneven Dense Haze. Symmetry 2022, 14, 1. https://doi.org/10.3390/sym14010001
Zhao W, Zhao Y, Feng L, Tang J. Attention Optimized Deep Generative Adversarial Network for Removing Uneven Dense Haze. Symmetry. 2022; 14(1):1. https://doi.org/10.3390/sym14010001
Chicago/Turabian StyleZhao, Wenxuan, Yaqin Zhao, Liqi Feng, and Jiaxi Tang. 2022. "Attention Optimized Deep Generative Adversarial Network for Removing Uneven Dense Haze" Symmetry 14, no. 1: 1. https://doi.org/10.3390/sym14010001