
Challenges and Open Problems of Legal Document Anonymization

 , and
, and 
Abstract
:1. Introduction
2. Privacy and Anonymization
2.1. Privacy Models
2.1.1. k-Anonymity
2.1.2. l-Diversity
2.1.3. t-Closeness
2.2. Available Tools, Solutions
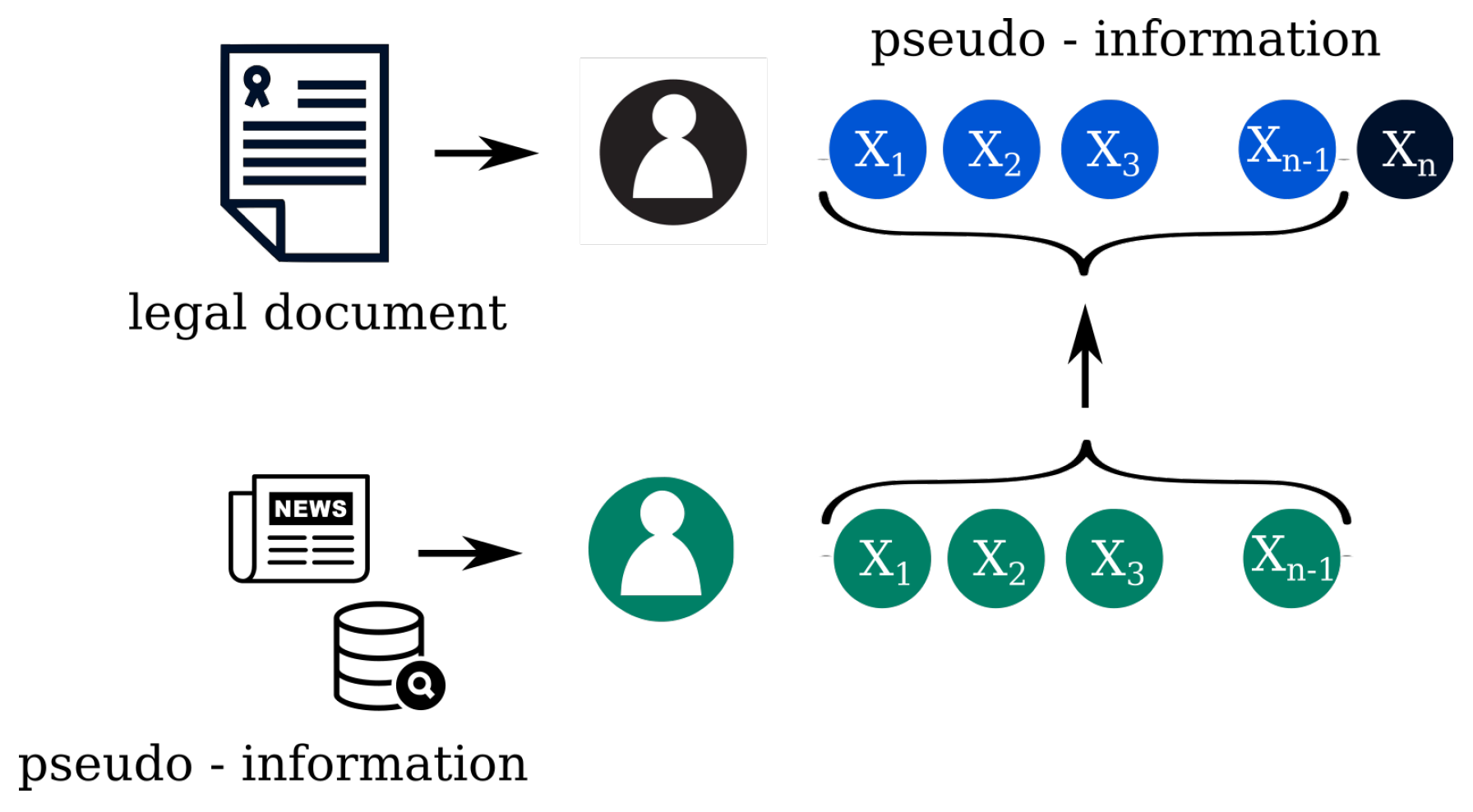
3. Types of Privacy Attacks
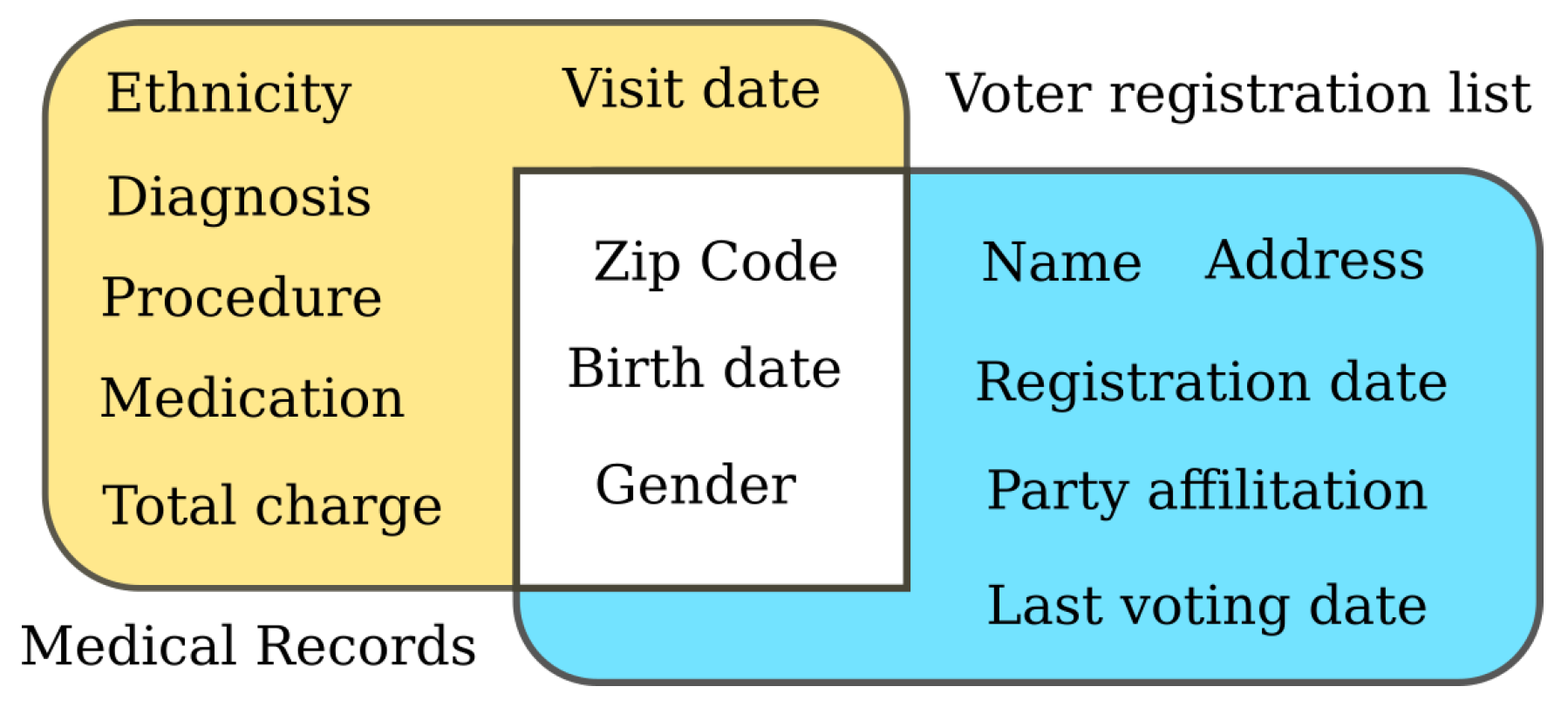
4. Does Document Domain Matter? Differences between Medical and Legal Anonymization Tasks
5. Structure and Privacy Risks in Hungarian Legal Documents
5.1. Judicial System, Regulations
5.2. Criticism of Current Regulation
5.3. Current Practice and Potential Risks
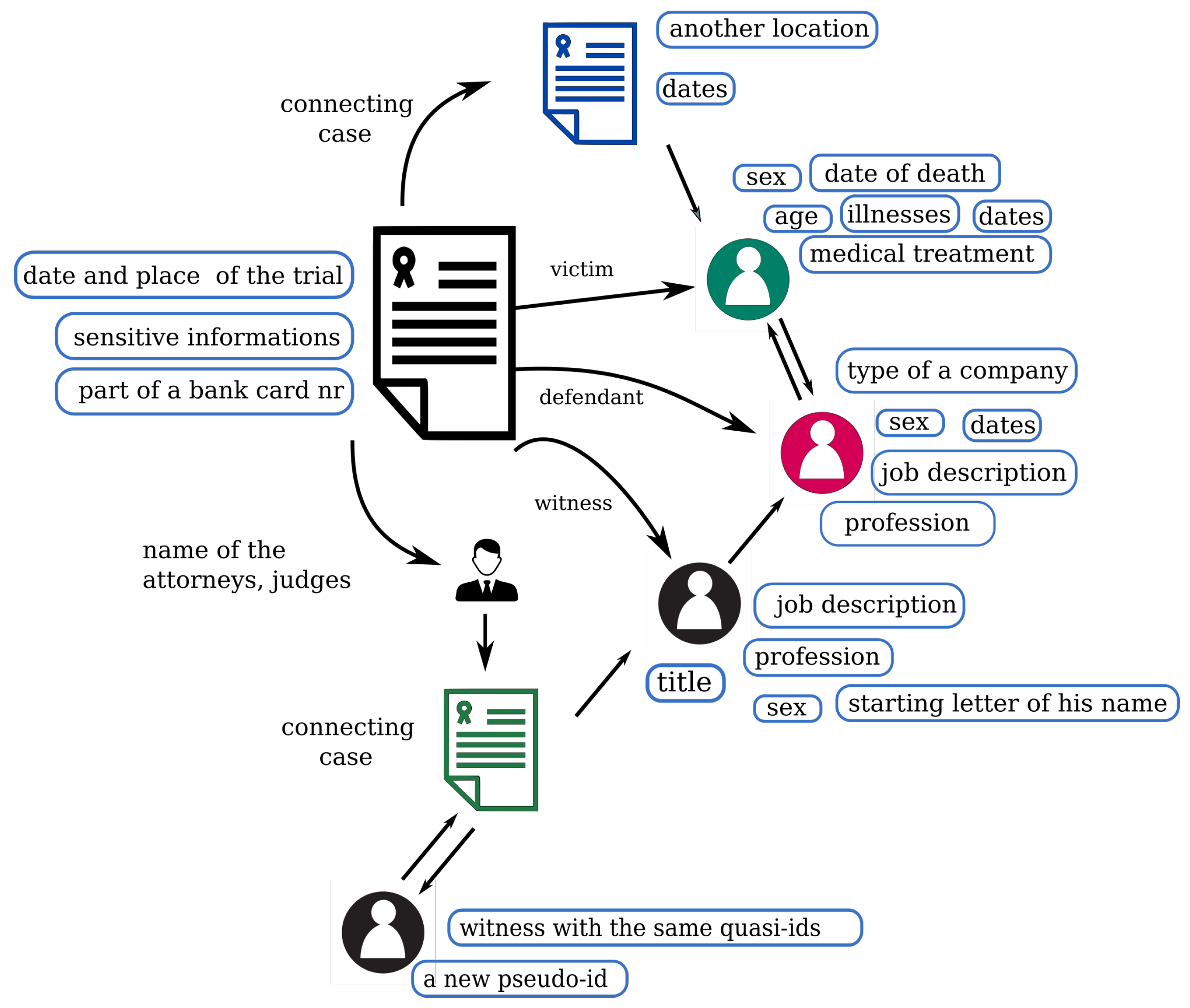
5.4. Case Studies
5.4.1. Datasets and Search Framework
- Case-law of the Constitutional Court: decisions and procedural decisions of the Constitutional Court of Hungary, currently approximately 9800 documents.
- Court Decisions: consists of decisions from all tiers of the Hungarian judicial system from district courts up to the Supreme Court. This is the biggest dataset containing approximately 160,000 documents. This study was conducted using this dataset.
- Uniformity Decisions: binding decisions of the Supreme Court in uniformity cases to ensure the uniform application of law within the Hungarian judiciary, currently containing approximately 200 documents.
- Selected case-law: selection of the most important court decisions, currently containing approximately 2200.
- Division opinions and decisions: decisions of the divisions of the courts on abstract, theoretical legal questions. Contains approximately 400 documents.
5.4.2. Illustrative Examples
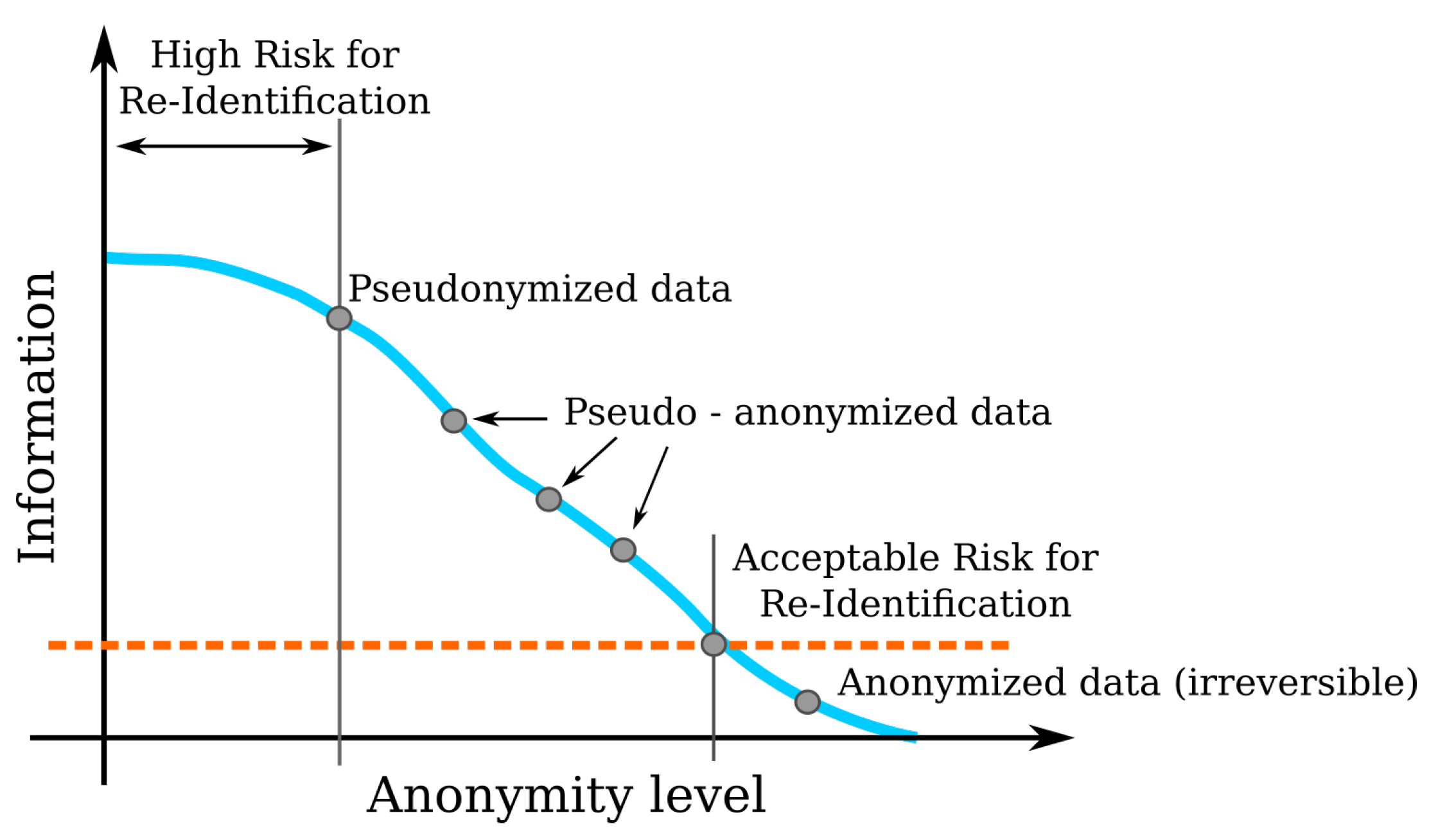
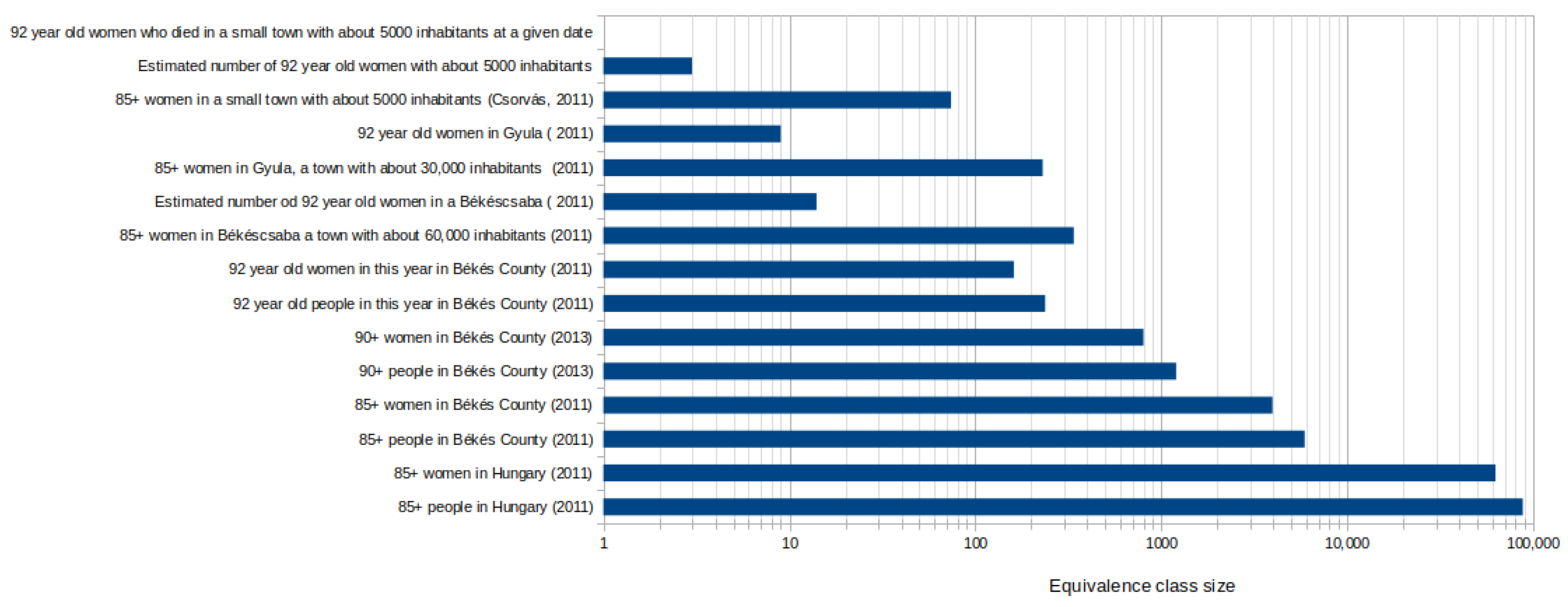
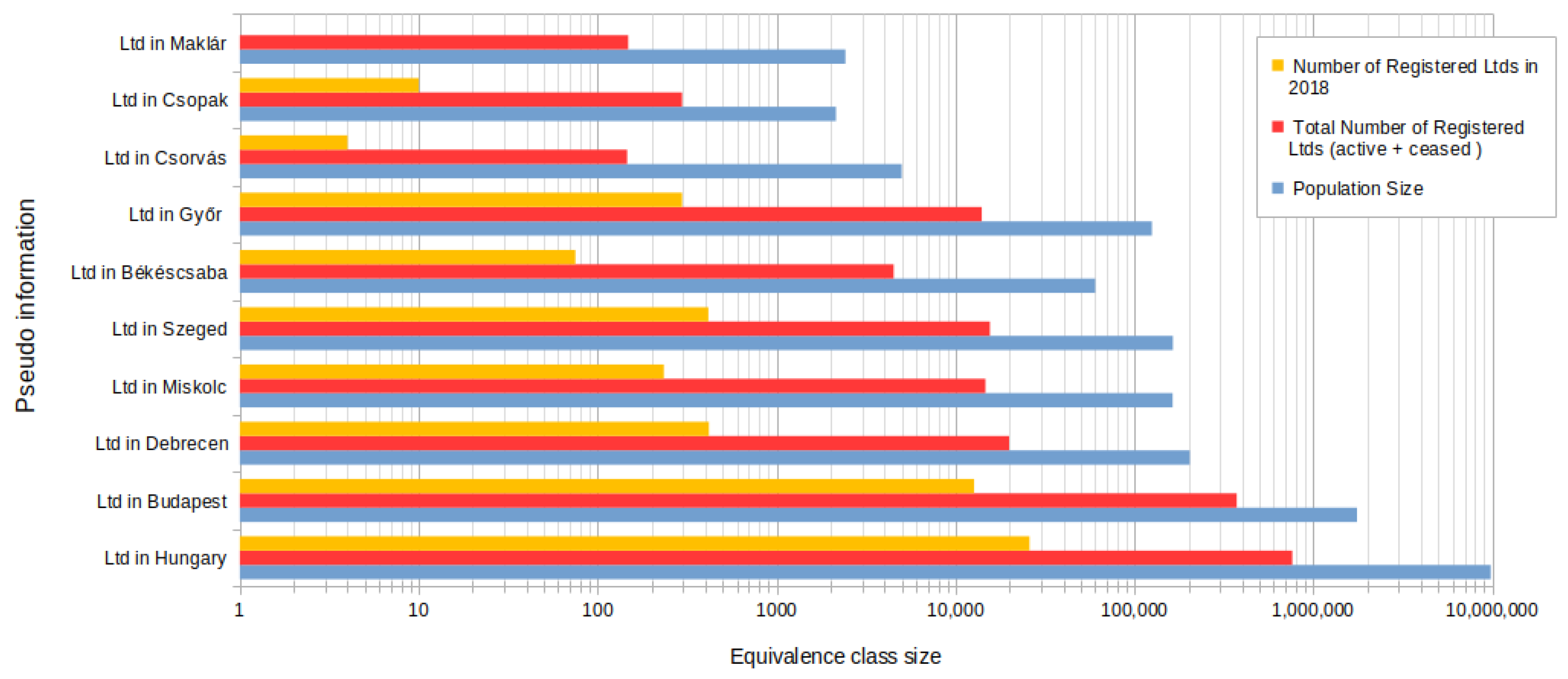
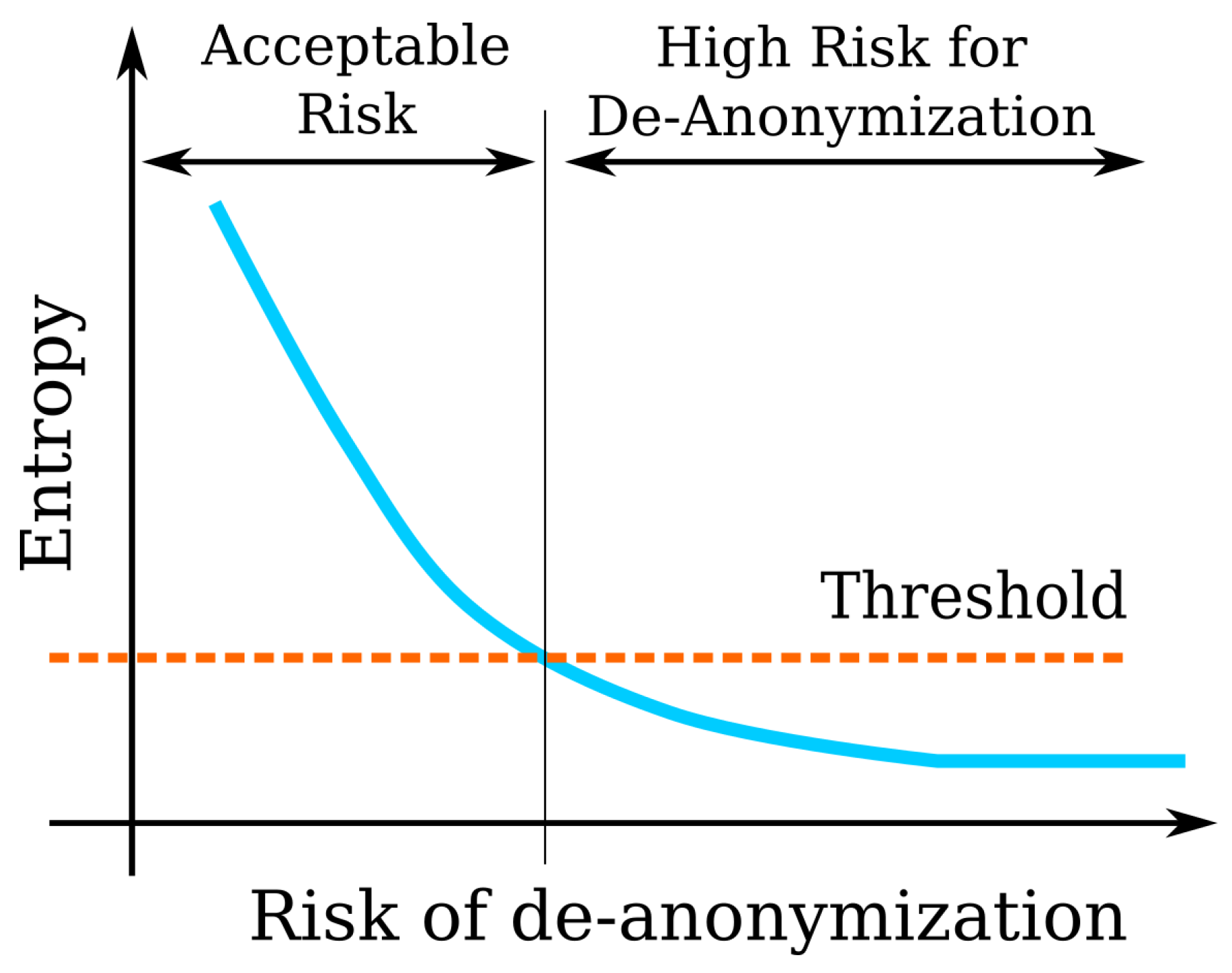
5.5. Quantifying Risk
5.6. The Threshold
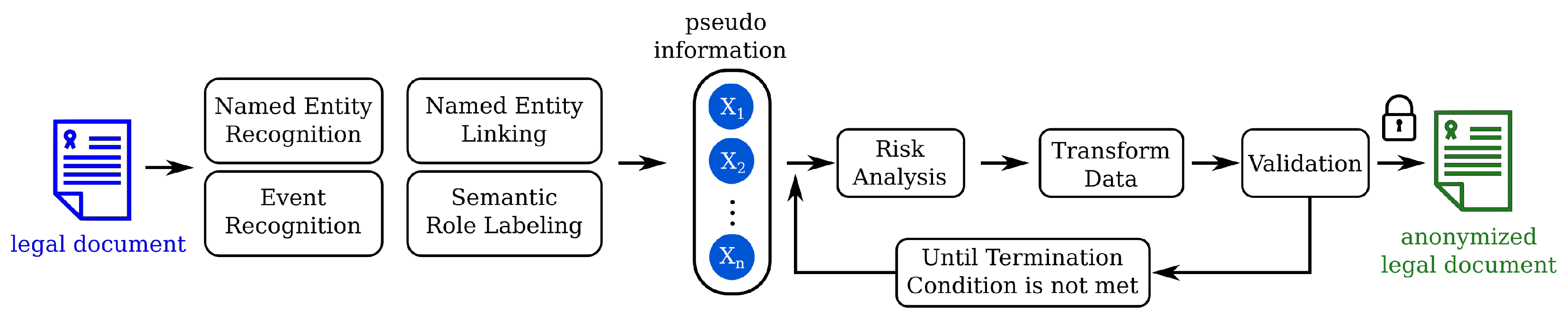
6. Automatized Workflows for Pseudonymization
About the Feasibility of a GDPR Compatible Automatized Pseudonymization Framework
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Comission, E. Digitalisation of Justice. Available online: https://ec.europa.eu/info/policies/justice-and-fundamental-rights/digitalisation-justice_en (accessed on 1 June 2021).
- Oksanen, A.; Tamper, M.; Tuominen, J.; Hietanen, A.; Hyvönen, E. ANOPPI: A Pseudonymization Service for Finnish Court Documents. In Proceedings of the Legal Knowledge and Information Systems JURIX 2019, Groningen, The Netherlands, 12–14 December 2019; pp. 251–254. [Google Scholar]
- Velicogna, M. In Search of Smartness: The EU e-Justice Challenge. Informatics 2017, 4, 38. [Google Scholar] [CrossRef] [Green Version]
- Hyvönen, E.; Tamper, M.; Ikkala, E.; Sarsa, S.; Oksanen, A.; Tuominen, J.; Hietanen, A. LawSampo: A semantic portal on a linked open data service for Finnish legislation and case law. In Proceedings of the ESWC, Heraklion, Greece, 31 May–4 June 2020. [Google Scholar]
- Oksanen, A.; Tuominen, J.; Mäkelä, E.; Tamper, M.; Hietanen, A.; Hyvönen, E. Semantic Finlex: Transforming, publishing, and using Finnish legislation and case law as linked open data on the web. Knowl. Law Big Data Age 2019, 317, 212–228. [Google Scholar]
- Csányi, G.; Orosz, T. Comparison of data augmentation methods for legal document classification. Acta Technica Jaurinensis 2021. [Google Scholar] [CrossRef]
- Van Opijnen, M.; Peruginelli, G.; Kefali, E.; Palmirani, M. On-Line Publication of Court Decisions in the eu: Report of the Policy Group of the Project ‘Building on the European Case Law Identifier’. SSRN 3088495. 2017. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3088495 (accessed on 1 June 2021).
- Országos Bírósági Hivatal (National Office for the Judiciary). 26/2019. (XI. 25.) OBH Utasítás. 2019. Available online: https://birosag.hu/obh/szabalyzat/262019-xi-25-obh-utasitas-birosagi-hatarozatok-anonimizalasaval-es-kozzetetelevel (accessed on 7 August 2021).
- Povlsen, C.; Jongejan, B.; Hansen, D.H.; Simonsen, B.K. Anonymization of court orders. In Proceedings of the 2016 11th Iberian Conference on Information Systems and Technologies (CISTI), Gran Canaria, Spain, 15–18 June 2016; pp. 1–4. [Google Scholar]
- Tamper, M.; Oksanen, A.; Tuominen, J.; Hyvönen, E.; Hietanen, A. Anonymization Service for Finnish Case Law: Opening Data without Sacrificing Data Protection and Privacy of Citizens. In Proceedings of the International Conference on Law via the Internet, LVI, Florence, Italy, 11–12 October 2018. [Google Scholar]
- Vokinger, K.N.; Stekhoven, D.J.; Krauthammer, M. Lost in Anonymization—A Data Anonymization Reference Classification Merging Legal and Technical Considerations. J. Law Med. Ethics 2020, 48, 228–231. [Google Scholar] [CrossRef]
- Pseudonymization according to the GDPR [Definitions and Examples]. Available online: https://dataprivacymanager.net/pseudonymization-according-to-the-gdpr/ (accessed on 15 February 2021).
- Pseudonymization vs. Anonymization: GDPR. Available online: https://www.tokenex.com/blog/general-data-protection-regulation-pseudonymization-vs-anonymization (accessed on 1 June 2021).
- Chen, B.; Kifer, D.; LeFevre, K.; Machanavajjhala, A. Privacy-Preserving Data Publishing. Found. Trends Databases 2009, 2, 1–167. [Google Scholar] [CrossRef]
- Sweeney, L. Computational Disclosure Control: A Primer on Data Privacy Protection. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2001. [Google Scholar]
- Prasser, F.; Eicher, J.; Spengler, H.; Bild, R.; Kuhn, K.A. Flexible data anonymization using ARX—Current status and challenges ahead. Softw. Pract. Exp. 2020, 50, 1277–1304. [Google Scholar] [CrossRef] [Green Version]
- Tamper, M.; Oksanen, A.; Tuominen, J.; Hietanen, A.; Hyvönen, E. Automatic annotation service appi: Named entity linking in legal domain. In Proceedings of the European Semantic Web Conference, Heraklion, Crete, Greece, 6–10 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 208–213. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vokinger, K.N.; Mühlematter, U.J. Re-Identifikation von Gerichtsurteilen Durch “Linkage” von Daten (banken): Eine Empirische Analyse Anhand von Bundesgerichtsbeschwerden Gegen (Preisfestsetzungs-) Verfügungen von Arzneimitteln. 2019. Available online: https://jusletter.weblaw.ch/juslissues/2019/990/re-identifikation-vo_21cb82c096.html__ONCE&login=false (accessed on 1 June 2021).
- Narayanan, A.; Shmatikov, V. How to break anonymity of the netflix prize dataset. arXiv 2006, arXiv:cs/0610105. [Google Scholar]
- Narayanan, A.; Shmatikov, V. Robust de-anonymization of large sparse datasets. In Proceedings of the 2008 IEEE Symposium on Security and Privacy (sp 2008), Oakland, CA, USA, 18–22 May 2008; pp. 111–125. [Google Scholar]
- Sweeney, L. Foundations of privacy protection from a computer science perspective. In Proceedings of the Joint Statistical Meeting, AAAS, Indianapolis, IN, USA, 13–17 August 2000. [Google Scholar]
- “Amnesia”, A Data Anonymization Tool Supported by the Institute for the Management of Information Systems, 2021. Available online: https://amnesia.openaire.eu/installation.html (accessed on 22 February 2021).
- Motwani, R.; Nabar, S.U. Anonymizing unstructured data. arXiv 2008, arXiv:0810.5582. [Google Scholar]
- Kleinberg, B.; Mozes, M.; van der Toolen, Y. NETANOS-Named Entity-Based Text Anonymization for Open Science. 2017. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwjEpbfG553yAhWFNaYKHRI2DHwQFnoECAUQAw&url=https%3A%2F%2Fwww.researchgate.net%2Fpublication%2F326121258_NETANOS_-_Named_entity-based_Text_Anonymization_for_Open_Science&usg=AOvVaw0Rlkb0yu7TugFx-LTS6cY9 (accessed on 1 June 2021).
- Kleinberg, B.; Mozes, M. Web-based text anonymization with Node. js: Introducing NETANOS (Named entity-based Text Anonymization for Open Science). J. Open Source Softw. 2017, 2, 293. [Google Scholar] [CrossRef] [Green Version]
- Mozes, M.; Kleinberg, B. No Intruder, no Validity: Evaluation Criteria for Privacy-Preserving Text Anonymization. arXiv 2021, arXiv:2103.09263. [Google Scholar]
- European Commission. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April on the Protection of Natural Persons with Regard to the Processing of Personal Data and on the Free Movement of Such Data and Repealing Directive 95/46/EC. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwinkevo553yAhVJBKYKHQ5-AGoQFnoECAUQAw&url=https%3A%2F%2Feur-lex.europa.eu%2Feli%2Freg%2F2016%2F679%2Foj&usg=AOvVaw1XAG3mHMtSjUcR1oFXnGgW (accessed on 1 June 2021).
- Montana Knowledge Management, Ltd. LEXPERT Database of Hungarian Court Decisions. Available online: https://lexpert.hu/ (accessed on 7 August 2021).
- Dwork, C.; Smith, A.; Steinke, T.; Ullman, J. Exposed! a survey of attacks on private data. Annu. Rev. Stat. Its Appl. 2017, 4, 61–84. [Google Scholar] [CrossRef] [Green Version]
- Microsoft. Differential Privacy for Everyone. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwix8bWi6J3yAhVlxosBHSRxAgMQFnoECAMQAw&url=https%3A%2F%2Fdownload.microsoft.com%2Fdownload%2FD%2F1%2FF%2FD1F0DFF5-8BA9-4BDF-8924-7816932F6825%2FDifferential_Privacy_for_Everyone.pdf&usg=AOvVaw11fKVVmW3XHZZjqLEnXgeR (accessed on 4 February 2021).
- Zhu, T.; Li, G.; Zhou, W.; Philip, S.Y. Differential Privacy and Applications; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Narayanan, A.; Shmatikov, V. Robust de-anonymization of large sparse datasets: A decade later. May 2019, 21, 2019. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwitiZDK6J3yAhVLL6YKHeIxBc0QFnoECA8QAw&url=https%3A%2F%2Fwww.semanticscholar.org%2Fpaper%2FRobust-de-anonymization-of-large-sparse-datasets-%253A-Narayanan-Shmatikov%2Ff41ef0fe589fdfbfe22c1ac5629638773f8d9fe9&usg=AOvVaw0hEX8iw1U22ZfIY-ZZhy5n (accessed on 1 June 2021).
- Datta, A.; Sharma, D.; Sinha, A. Provable de-anonymization of large datasets with sparse dimensions. In Proceedings of the International Conference on Principles of Security and Trust, Tallinn, Estonia, 24 March–1 April 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 229–248. [Google Scholar]
- Dalenius, T. Finding a needle in a haystack or identifying anonymous census records. J. Off. Stat. 1986, 2, 329. [Google Scholar]
- El Emam, K.; Jabbouri, S.; Sams, S.; Drouet, Y.; Power, M. Evaluating common de-identification heuristics for personal health information. J. Med Internet Res. 2006, 8, e28. [Google Scholar] [CrossRef] [PubMed]
- El Emam, K.; Jonker, E.; Sams, S.; Neri, E.; Neisa, A.; Gao, T.; Chowdhury, S. Pan-Canadian De-Identification Guidelines for Personal Health Information; Privacy Commissioner of Canada: Gatineau, QC, Canada, 2007.
- El Emam, K.; Brown, A.; AbdelMalik, P. Evaluating predictors of geographic area population size cut-offs to manage re-identification risk. J. Am. Med Inform. Assoc. 2009, 16, 256–266. [Google Scholar] [CrossRef] [Green Version]
- Canadian Institutes of Health Research Privacy Advisory Committee. CIHR Best Practices for Protecting Privacy in Health Research, September 2005; PublicWorks and Government Services Canada: Ottawa, ON, Canada, 2005.
- Sweeney, L. Simple demographics often identify people uniquely. Health 2000, 671, 1–34. [Google Scholar]
- Hafner, K. If you liked the movie, a Netflix contest may reward you handsomely. N. Y. Times 2006, 2. [Google Scholar]
- Barbaro, M.; Zeller, T.; Hansell, S. A face is exposed for AOL searcher no. 4417749. N. Y. Times 2006, 9, 8. [Google Scholar]
- Zhu, T.; Li, G.; Zhou, W.; Philip, S.Y. Preliminary of differential privacy. In Differential Privacy and Applications; Springer: Berlin/Heidelberg, Germany, 2017; pp. 7–16. [Google Scholar]
- Dankar, F.K.; El Emam, K.; Neisa, A.; Roffey, T. Estimating the re-identification risk of clinical data sets. BMC Med Inform. Decis. Mak. 2012, 12, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Dwork, C.; Kenthapadi, K.; McSherry, F.; Mironov, I.; Naor, M. Our data, ourselves: Privacy via distributed noise generation. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Vienna, Austria, 8–12 May 2016; Springer: Berlin/Heidelberg, Germany, 2006; pp. 486–503. [Google Scholar]
- Prasser, F.; Kohlmayer, F.; Kuhn, K.A. The importance of context: Risk-based de-identification of biomedical data. Methods Inf. Med. 2016, 55, 347–355. [Google Scholar]
- Domingo-Ferrer, J.; Torra, V. A critique of k-anonymity and some of its enhancements. In Proceedings of the 2008 Third International Conference on Availability, Reliability and Security, Barcelona, Spain, 4–7 March 2008; pp. 990–993. [Google Scholar]
- Nergiz, M.E.; Atzori, M.; Clifton, C. Hiding the presence of individuals from shared databases. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; pp. 665–676. [Google Scholar]
- El Emam, K.; Arbuckle, L. Anonymizing Health Data: Case Studies and Methods to Get You Started; O’Reilly Media, Inc.: Newton, MA, USA, 2013. [Google Scholar]
- Truta, T.M.; Vinay, B. Privacy protection: P-sensitive k-anonymity property. In Proceedings of the 22nd International Conference on Data Engineering Workshops (ICDEW’06), Atlanta, GA, USA, 3–7 April 2006; p. 94. [Google Scholar]
- Samarati, P.; Sweeney, L. Protecting Privacy when Disclosing Information: K-Anonymity and Its Enforcement through Generalization and Suppression. 1998. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwjeos6j6Z3yAhXDDaYKHTTnABMQFnoECAQQAw&url=https%3A%2F%2Fepic.org%2Fprivacy%2Freidentification%2FSamarati_Sweeney_paper.pdf&usg=AOvVaw0UDf7utmmgKAgkKhXNegKB (accessed on 1 June 2021).
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. l-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data (TKDD) 2007, 1, 3–es. [Google Scholar] [CrossRef]
- Li, N.; Li, T.; Venkatasubramanian, S. t-closeness: Privacy beyond k-anonymity and l-diversity. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 106–115. [Google Scholar]
- Samarati, P. Protecting respondents identities in microdata release. IEEE Trans. Knowl. Data Eng. 2001, 13, 1010–1027. [Google Scholar] [CrossRef] [Green Version]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Sweeney, L. Achieving k-anonymity privacy protection using generalization and suppression. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2002, 10, 571–588. [Google Scholar] [CrossRef]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The earth mover’s distance as a metric for image retrieval. Int. J. Comput. Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]
- Vico, H.; Calegari, D. Software architecture for document anonymization. Electron. Notes Theor. Comput. Sci. 2015, 314, 83–100. [Google Scholar] [CrossRef] [Green Version]
- UTD Anonymization Toolbox. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwjrxazI6Z3yAhWawosBHZR8CyIQFnoECAUQAw&url=http%3A%2F%2Fwww.cs.utdallas.edu%2Fdspl%2Ftoolbox%2F&usg=AOvVaw1-orTi0L4d9eKuAGLNRtEA (accessed on 1 June 2021).
- Sánchez, D.; Martínez, S.; Domingo-Ferrer, J.; Soria-Comas, J.; Batet, M. μ-ANT: Semantic microaggregation-based anonymization tool. Bioinformatics 2020, 36, 1652–1653. [Google Scholar] [CrossRef] [PubMed]
- Cornell Anonymization Toolkit. Available online: https://sourceforge.net/projects/anony-toolkit/ (accessed on 15 February 2021).
- Dai, C.; Ghinita, G.; Bertino, E.; Byun, J.W.; Li, N. TIAMAT: A tool for interactive analysis of microdata anonymization techniques. Proc. VLDB Endow. 2009, 2, 1618–1621. [Google Scholar] [CrossRef]
- Poulis, G.; Gkoulalas-Divanis, A.; Loukides, G.; Skiadopoulos, S.; Tryfonopoulos, C. Secreta: A tool for anonymizing relational, transaction and rt-datasets. In Medical Data Privacy Handbook; Springer: Berlin/Heidelberg, Germany, 2015; pp. 83–109. [Google Scholar]
- Prasser, F.; Kohlmayer, F. Putting statistical disclosure control into practice: The ARX data anonymization tool. In Medical Data Privacy Handbook; Springer: Berlin/Heidelberg, Germany, 2015; pp. 111–148. [Google Scholar]
- Bild, R.; Kuhn, K.A.; Prasser, F. Better Safe than Sorry–Implementing Reliable Health Data Anonymization. Stud. Health Technol. Inform. 2020, 270, 68–72. [Google Scholar]
- Gardner, J.; Xiong, L. HIDE: An integrated system for health information DE-identification. In Proceedings of the 2008 21st IEEE International Symposium on Computer-Based Medical Systems, Jyvaskyla, Finland, 17–19 June 2008; pp. 254–259. [Google Scholar]
- Gardner, J.; Xiong, L. An integrated framework for de-identifying unstructured medical data. Data Knowl. Eng. 2009, 68, 1441–1451. [Google Scholar] [CrossRef]
- Kifer, D.; Machanavajjhala, A. No free lunch in data privacy. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; pp. 193–204. [Google Scholar]
- Wolpert, D.H. The supervised learning no-free-lunch theorems. Soft Comput. Ind. 2002, 25–42. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwi8j4_q6Z3yAhWIOpQKHU4bCq8QFnoECAQQAw&url=https%3A%2F%2Fwww.researchgate.net%2Fpublication%2F229078412_The_Supervised_Learning_No-Free-Lunch_Theorems&usg=AOvVaw0EcJCII1hyqvybrgKDOtqy (accessed on 1 June 2021).
- Gómez, D.; Rojas, A. An empirical overview of the no free lunch theorem and its effect on real-world machine learning classification. Neural Comput. 2016, 28, 216–228. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- El Emam, K. Guide to the De-Identification of Personal Health Information; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- El Emam, K. Risk-based de-identification of health data. IEEE Secur. Priv. 2010, 8, 64–67. [Google Scholar] [CrossRef]
- Newcombe, H.B.; Kennedy, J.M.; Axford, S.; James, A.P. Automatic linkage of vital records. Science 1959, 130, 954–959. [Google Scholar] [CrossRef] [PubMed]
- Fellegi, I.P.; Sunter, A.B. A theory for record linkage. J. Am. Stat. Assoc. 1969, 64, 1183–1210. [Google Scholar] [CrossRef]
- Schlörer, J. Identification and retrieval of personal records from a statistical data bank. Methods Inf. Med. 1975, 14, 7–13. [Google Scholar] [CrossRef]
- Schilder, F. Event extraction and temporal reasoning in legal documents. In Annotating, Extracting and Reasoning about Time and Events; Springer: Berlin/Heidelberg, Germany, 2007; pp. 59–71. [Google Scholar]
- Lagos, N.; Segond, F.; Castellani, S.; O’Neill, J. Event extraction for legal case building and reasoning. In Proceedings of the International Conference on Intelligent Information Processing, Manchester, UK, 13–16 October 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 92–101. [Google Scholar]
- GDPR Implementation of Denmark, 2020. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwjysPmK6p3yAhUDy4sBHZ8EBlUQFnoECAUQAw&url=https%3A%2F%2Fwww.opengovpartnership.org%2Fdocuments%2Fdenmark-implementation-report-2017-2019%2F&usg=AOvVaw2T8SMjFedIersA1V4Xa5pd (accessed on 1 June 2021).
- OpenAIRE Webinar—Amnesia, an Open-Source, Flexible Data Anonymization Tool, 2020. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwitsu6o6p3yAhVMIqYKHWpbCSAQFnoECAkQAw&url=https%3A%2F%2Famnesia.openaire.eu%2F&usg=AOvVaw0yXvLpjIfh7g5MrhDLXNN_ (accessed on 1 June 2021).
- Központi Statisztikai Hivatal (Central Office of Statistics). Population Data in Békés Country by Sexes and Age Groups; Central Office of Statistics: Budapest, Hungary, 2020.
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Joyce, J. Bayes’ Theorem. 2003. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwjDyufr6p3yAhXRw4sBHd6WCboQFnoECAQQAw&url=https%3A%2F%2Fccc.inaoep.mx%2F~villasen%2Findex_archivos%2FcursoTATII%2FEntidadesNombradas%2FSekine-%2520NEsHistory04.pdf&usg=AOvVaw1Rr_qUVeVK2_ycH15cxTbd (accessed on 1 June 2021).
- MacKay, D.J.; Mac Kay, D.J. Information Theory, Inference and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003; pp. 23–24, 138–139. [Google Scholar]
- Chinchor, N.; Robinson, P. MUC-7 named entity task definition. In Proceedings of the 7th Conference on Message Understanding, Fairfax, VA, USA, 29 April–1 May 1997; Volume 29, pp. 1–21. [Google Scholar]
- Sekine, S. Named Entity: History and Future. 2004. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwiok7XW653yAhWBHKYKHaVRAAAQFnoECAQQAw&url=https%3A%2F%2Fccc.inaoep.mx%2F~villasen%2Findex_archivos%2FcursoTATII%2FEntidadesNombradas%2FSekine-%2520NEsHistory04.pdf&usg=AOvVaw1Rr_qUVeVK2_ycH15cxTbd (accessed on 1 June 2021).
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Lingvisticae Investig. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Szarvas, G.; Farkas, R.; Kocsor, A. A multilingual named entity recognition system using boosting and c4. 5 decision tree learning algorithms. In Proceedings of the International Conference on Discovery Science, Barcelona, Spain, 7–10 October 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 267–278. [Google Scholar]
- Dernoncourt, F.; Lee, J.Y.; Uzuner, O.; Szolovits, P. De-identification of patient notes with recurrent neural networks. J. Am. Med Inform. Assoc. 2017, 24, 596–606. [Google Scholar] [CrossRef]
- Iglesias, A.; Castro, E.; Pérez, R.; Castaño, L.; Martínez, P.; Gómez-Pérez, J.M.; Kohler, S.; Melero, R. Mostas: Un etiquetador morfo-semántico, anonimizador y corrector de historiales clínicos. Proces. Del Leng. Nat. 2008, 41. [Google Scholar]
- Bagga, A.; Baldwin, B. Entity-Based Cross-Document Core f erencing Using the Vector Space Model. In Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics, Montréal, QC, Canada, 10–14 August 1998; pp. 79–85. [Google Scholar]
- Boros, E. Neural Methods for Event Extraction. Ph.D. Thesis, Université Paris-Saclay, Yvette, France, 2018. [Google Scholar]
- Shen, S.; Qi, G.; Li, Z.; Bi, S.; Wang, L. Hierarchical Chinese Legal event extraction via Pedal Attention Mechanism. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 13–18 September 2020; pp. 100–113. [Google Scholar]
- Subecz, Z. Event detection and classification in hungarian natural texts. Eur. Sci. J. 2019, 15. [Google Scholar] [CrossRef] [Green Version]
- He, L.; Lee, K.; Lewis, M.; Zettlemoyer, L. Deep semantic role labeling: What works and what is next. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 473–483. [Google Scholar]
- Office, I.C. Anonymisation: Managing data protection risk code of practice. ICO 2012. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| H (bit) | w (1/bit) | |
|---|---|---|
| World’s population | 32.86 | 0.03 |
| Hungary’s population | 23.22 | 0.04 |
| Budapest’s population | 20.74 | 0.05 |
| Age 85+ | 17.61 | 0.06 |
| Medical doctors | 15.33 | 0.07 |
| Professional football player | 10.19 | 0.10 |
| Nr. of companies | 20.28 | 0.05 |
| Nr. of Ltds | 19.54 | 0.05 |
| Nr. of Ltds founded in 2018 | 13.63 | 0.07 |
| Nr. of Ltds founded in Jan 2018 | 10.26 | 0.10 |
| Hungarian Academy of Sciences (HAS) member | 8.15 | 0.12 |
| Member of HAS in Engineering | 4.91 | 0.20 |
| Information Gain | |
|---|---|
| Sex | 1 |
| Month, when year given | 3.58 |
| 1 year from 30 years range | 4.91 |
| Year and month in 30 years range | 8.49 |
| Year, month day from 30 years range | 13.42 |
| Monogram Hungarian (1 letter) | 5.32 |
| Monogram Hungarian (2 letters) | 10.64 |
| Monogram Hungarian (3 letters) | 15.97 |
| Monogram English (1 letter) | 4.70 |
| Monogram English (2 letters) | 9.40 |
| Monogram English (3 letters) | 14.10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Csányi, G.M.; Nagy, D.; Vági, R.; Vadász, J.P.; Orosz, T. Challenges and Open Problems of Legal Document Anonymization. Symmetry 2021, 13, 1490. https://doi.org/10.3390/sym13081490
Csányi GM, Nagy D, Vági R, Vadász JP, Orosz T. Challenges and Open Problems of Legal Document Anonymization. Symmetry. 2021; 13(8):1490. https://doi.org/10.3390/sym13081490
Chicago/Turabian StyleCsányi, Gergely Márk, Dániel Nagy, Renátó Vági, János Pál Vadász, and Tamás Orosz. 2021. "Challenges and Open Problems of Legal Document Anonymization" Symmetry 13, no. 8: 1490. https://doi.org/10.3390/sym13081490