
Dual Attention Network for Pitch Estimation of Monophonic Music

Abstract
:1. Introduction
- (i)
- For pitch estimation of monophonic music, we propose a data-driven DA-Net integrating the element-wise attention mechanism and the channel-wise attention mechanism.
- (ii)
- We explored three combination modes of the two attention mechanisms: serial mode, parallel mode, and tightly coupled mode. According to the experiments, the Dual Attention network with Tightly Coupled mode (DA-TC) obtained the best results.
- (iii)
- We validated our network on the iKala and MDB-stem-synth datasets, respectively. The DA-TC achieved improvement comparing with CREPE, especially on MDB- stem-synth.
2. Proposed Model
2.1. Dual Attention Network
2.2. Dual Attention Module
Tightly Coupled Mode
2.3. Channel-Wise Attention Mechanism
- Squeeze: Global Information Embedding
- Excitation: Adaptive Recalibration
2.4. Element-Wise Attention Mechanism
3. Experiments
3.1. Datasets and Setting
3.2. Label Processing and Postprocessing
3.3. Evaluation Metrics
- : The proportion of voiced frames where the estimated pitch is within tone (50 cents) of the ground truth pitch.
- : The proportion of voiced frames in which the estimated pitch and the ground truth pitch are mapped into a single octave. This gives a measure of pitch accuracy ignoring the octave errors.
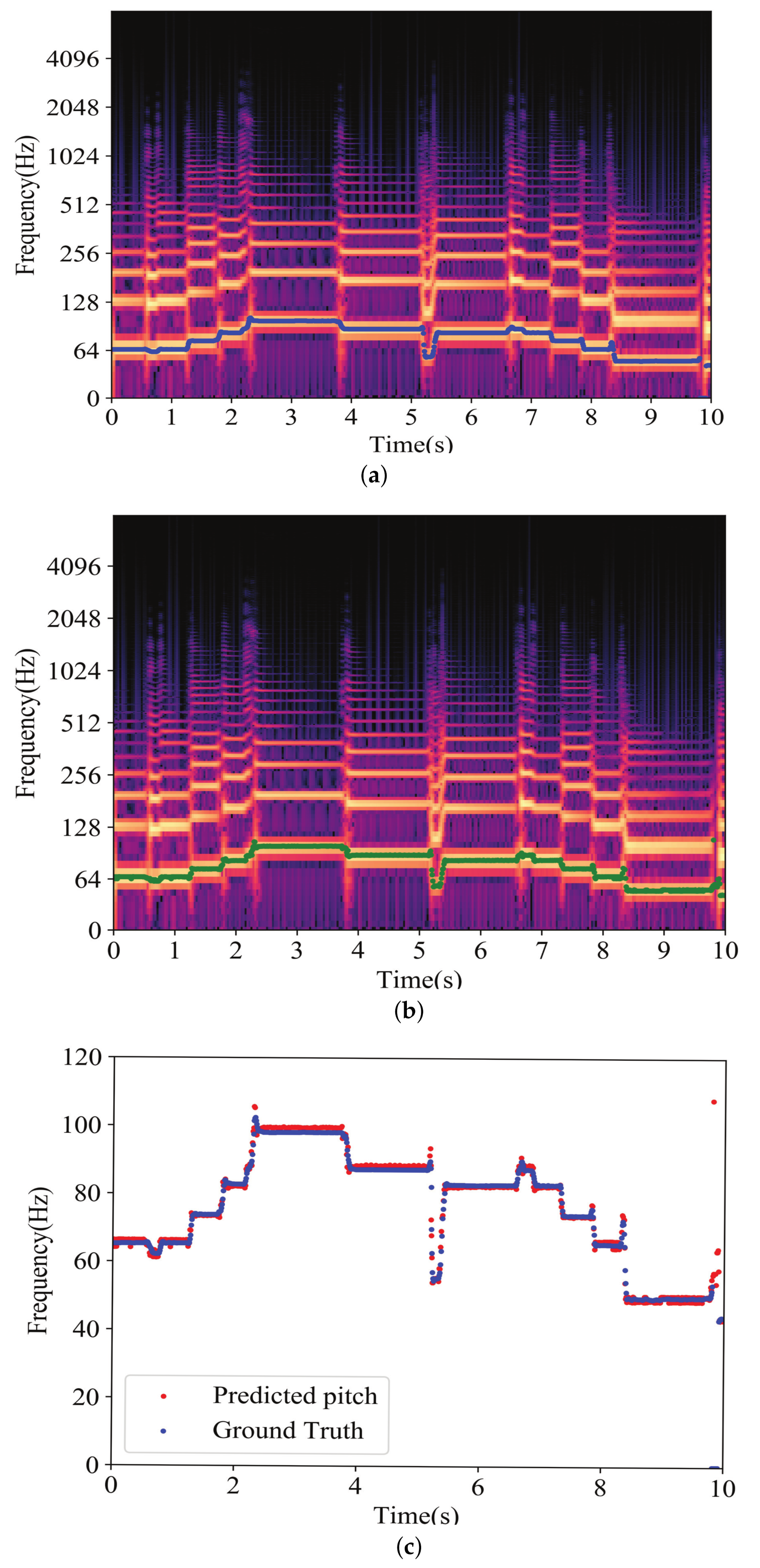
4. Results
4.1. Comparison of Single or Dual Attention Networks
4.2. Comparison with Previous Methods
5. Conclusions
- (i)
- The performances of the models when introducing single attention mechanisms, such as EA and CA, were better than CREPE.
- (ii)
- Dual attention networks (DA-S, DA-P, and DA-TC) outperformed the CREPE model. Among them, DA-TC, which maximizes the effect of the element-wise attention mechanism and the channel-wise attention mechanism, achieved the best performance.
- (iii)
- DA-TC obtained the best results and outperformed pYIN, SWIPE, and SPICE on the MDB-stem-synth dataset.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bittner, R.M.; Salamon, J.; Tierney, M.; Mauch, M.; Cannam, C.; Bello, J.P. Medleydb: A multitrack dataset for annotation-intensive mir research. ISMIR 2014, 14, 155–160. [Google Scholar]
- Bosch, J.; Gómez, E. Melody extraction in symphonic classical music: A comparative study of mutual agreement between humans and algorithms. In Proceedings of the 9th Conference on Interdisciplinary Musicology—CIM14, Berlin, Germany, 4–6 December 2014. [Google Scholar]
- Mauch, M.; Cannam, C.; Bittner, R.; Fazekas, G.; Salamon, J.; Dai, J.; Bello, J.; Dixon, S. Computer-aided melody note transcription using the Tony software: Accuracy and efficiency. 2015. Available online: https://qmro.qmul.ac.uk/xmlui/handle/123456789/7247 (accessed on 15 April 2021).
- Rodet, X. Synthesis and processing of the singing voice. In Proceedings of the 1st IEEE Benelux Workshop on Model based Processing and Coding of Audio (MPCA-2002), Leuven, Belgium, 15 November 2002; pp. 15–31. [Google Scholar]
- Downie, J.S. Music information retrieval. Annu. Rev. Inf. Sci. Technol. 2003, 37, 295–340. [Google Scholar] [CrossRef] [Green Version]
- Panteli, M.; Bittner, R.; Bello, J.P.; Dixon, S. Towards the characterization of singing styles in world music. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 636–640. [Google Scholar]
- Klapuri, A. Automatic transcription of music. Master’s Thesis, Tampere University of Technology, Tampere, Finland, April 1998. [Google Scholar]
- De Cheveigné, A.; Kawahara, H. YIN, a fundamental frequency estimator for speech and music. J. Acoust. Soc. Am. 2002, 111, 1917–1930. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mauch, M.; Dixon, S. pYIN: A fundamental frequency estimator using probabilistic threshold distributions. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 659–663. [Google Scholar]
- Camacho, A.; Harris, J.G. A sawtooth waveform inspired pitch estimator for speech and music. J. Acoust. Soc. Am. 2008, 124, 1638–1652. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zahorian, S.A.; Hu, H. A spectral/temporal method for robust fundamental frequency tracking. J. Acoust. Soc. Am. 2008, 123, 4559–4571. [Google Scholar] [CrossRef] [PubMed]
- Hua, K. Nebula: F0 estimation and voicing detection by modeling the statistical properties of feature extractors. arXiv 2017, arXiv:1710.11317. [Google Scholar]
- Zhang, J.; Tang, J.; Dai, L.-R. RNN-BLSTM Based Multi-Pitch Estimation. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016; pp. 1785–1789. [Google Scholar]
- Gonzalez, S.; Brookes, M. PEFAC-a pitch estimation algorithm robust to high levels of noise. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 518–530. [Google Scholar] [CrossRef]
- Verma, P.; Schafer, R.W. Frequency Estimation from Waveforms Using Multi-Layered Neural Networks. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016; pp. 2165–2169. [Google Scholar]
- Han, K.; Wang, D.L. Neural network based pitch tracking in very noisy speech. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 2158–2168. [Google Scholar] [CrossRef]
- Bittner, R.M.; McFee, B.; Salamon, J.; Li, P.; Bello, J.P. Deep Salience Representations for F0 Estimation in Polyphonic Music. In Proceedings of the ISMIR, Suzhou, China, 23–27 October 2017; pp. 63–70. [Google Scholar]
- Bittner, R.M.; McFee, B.; Bello, J.P. Multitask learning for fundamental frequency estimation in music. arXiv 2018, arXiv:1809.00381. [Google Scholar]
- Basaran, D.; Essid, S.; Peeters, G. Main melody extraction with source-filter nmf and crnn. In Proceedings of the 19th International Society for Music Information Retreival, Paris, France, 23–27 September 2018. [Google Scholar]
- Doras, G.; Esling, P.; Peeters, G. On the use of u-net for dominant melody estimation in polyphonic music. In Proceedings of the 2019 International Workshop on Multilayer Music Representation and Processing (MMRP), Milano, Italy, 24–25 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 66–70. [Google Scholar]
- Lu, W.T.; Su, L. Vocal Melody Extraction with Semantic Segmentation and Audio-symbolic Domain Transfer Learning. In Proceedings of the ISMIR, Paris, France, 23–27 September 2018; pp. 521–528. [Google Scholar]
- Chen, M.-T.; Li, B.-J.; Chi, T.-S. Cnn based two-stage multi-resolution end-to-end model for singing melody extraction. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1005–1009. [Google Scholar]
- Hsieh, T.-H.; Su, L.; Yang, Y.-H. A streamlined encoder/decoder architecture for melody extraction. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 156–160. [Google Scholar]
- Xu, S.; Shimodaira, H. Direct F0 Estimation with Neural-Network-Based Regression. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 1995–1999. [Google Scholar]
- Airaksinen, M.; Juvela, L.; Alku, P.; Räsänen, O. Data Augmentation Strategies for Neural Network F0 Estimation. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6485–6489. [Google Scholar]
- Kim, J.W.; Salamon, J.; Li, P.; Bello, J.P. Crepe: A convolutional representation for pitch estimation. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 161–165. [Google Scholar]
- Ardaillon, L.; Roebel, A. Fully-convolutional network for pitch estimation of speech signals. In Proceedings of the Insterspeech 2019, Graz, Austria, 15–19 September 2019. [Google Scholar]
- Dong, M.; Wu, J.; Luan, J. Vocal Pitch Extraction in Polyphonic Music Using Convolutional Residual Network. In Proceedings of the Insterspeech 2019, Graz, Austria, 15–19 September 2019; pp. 2010–2014. [Google Scholar]
- Gfeller, B.; Frank, C.; Roblek, D.; Sharifi, M.; Tagliasacchi, M.; Velimirović, M. Pitch Estimation Via Self-Supervision. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 3527–3531. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; PMLR: Mountain View, CA, USA, 2017; pp. 933–941. [Google Scholar]
- Tan, K.; Wang, D.L. Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 28, 380–390. [Google Scholar] [CrossRef] [PubMed]
- Tan, K.; Chen, J.; Wang, D.L. Gated residual networks with dilated convolutions for monaural speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 27, 189–198. [Google Scholar] [CrossRef] [PubMed]
- Shi, Z.; Lin, H.; Liu, L.; Liu, R.; Han, J.; Shi, A. Deep Attention Gated Dilated Temporal Convolutional Networks with Intra-Parallel Convolutional Modules for End-to-End Monaural Speech Separation. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 3183–3187. [Google Scholar]
- Geng, H.; Hu, Y.; Huang, H. Monaural Singing Voice and Accompaniment Separation Based on Gated Nested U-Net Architecture. Symmetry 2020, 12, 1051. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wu, Y. Deep convolutional neural network based on densely connected squeeze-and-excitation blocks. AIP Adv. 2019, 9, 065016. [Google Scholar] [CrossRef] [Green Version]
- Gu, J.; Sun, X.; Zhang, Y.; Fu, K.; Wang, L. Deep residual squeeze and excitation network for remote sensing image super-resolution. Remote. Sens. 2019, 11, 1817. [Google Scholar] [CrossRef] [Green Version]
- Park, Y.J.; Tuxworth, G.; Zhou, J. Insect classification using Squeeze-and-Excitation and attention modules-a benchmark study. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3437–3441. [Google Scholar]
- Wu, J.; Li, Q.; Liang, S.; Kuang, S.-F. Convolutional Neural Network with Squeeze and Excitation Modules for Image Blind Deblurring. In Proceedings of the 2020 Information Communication Technologies Conference (ICTC), Nanjing, China, 29–31 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 338–345. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Yu, S.; Sun, X.; Yu, Y.; Li, W. Frequency-temporal attention network for singing melody extraction. In Proceedings of the ICASSP 2021—-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–12 June 2021; pp. 251–255. [Google Scholar]
- Hu, Z.; Luo, Y.; Lin, J.; Yan, Y.; Chen, J. Multi-Level Visual-Semantic Alignments with Relation-Wise Dual Attention Network for Image and Text Matching. In Proceedings of the IJCAI 2019, Macao, 10–16 August 2019; pp. 789–795. [Google Scholar]
- Li, B.; Ye, W.; Sheng, Z.; Xie, R.; Xi, X.; Zhang, S. Graph enhanced dual attention network for document-level relation extraction. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 13–18 September 2020; pp. 1551–1560. [Google Scholar]
- Zhu, Y.; Zheng, W.; Tang, H. Interactive dual attention network for text sentiment classification. Comput. Intell. Neurosci. 2020, 2020, 8858717. [Google Scholar] [CrossRef] [PubMed]
- Wan, J.; Xie, Z.; Xu, Y.; Chen, S.; Qiu, Q. DA-RoadNet: A Dual-Attention Network for Road Extraction from High Resolution Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2021, 14, 6302–6315. [Google Scholar] [CrossRef]
- Chan, T.-S.; Yeh, T.-C.; Fan, Z.-C.; Chen, H.-W.; Su, L.; Yang, Y.-H.; Jang, R. Vocal activity informed singing voice separation with the iKala dataset. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 718–722. [Google Scholar]
- Salamon, J.; Bittner, R.M.; Bonada, J.; Bosch, J.J.; Gómez Gutiérrez, E.; Bello, J.P. An analysis/synthesis framework for automatic f0 annotation of multitrack datasets. In Proceedings of the ISMIR 2017 Proceedings of the 18th International Society for Music Information Retrieval Conference, Suzhou, China, 23–27 October 2017. [Google Scholar]
- Kingman, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. Conference paper. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015; 2015. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Raffel, C.; McFee, B.; Humphrey, E.J.; Salamon, J.; Nieto, O.; Liang, D.; Ellis, D.P.W.; Raffel, C.C. mir_eval: A transparent implementation of common MIR metrics. In Proceedings of the 15th International Society for Music Information Retrieval Conference, ISMIR 2014, Taipei, Taiwan, 27–31 October 2014. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Kernel Size/Stride/Pooling Size | Output Size (Channel, Time) |
|---|---|---|
| Input | - | (1, 1024) |
| DA-Module1 | 512/4/2 | (1024, 128) |
| DA-Module2 | 64/1/2 | (128, 64) |
| DA-Module3 | 64/1/2 | (128, 32) |
| DA-Module4 | 64/1/2 | (128, 16) |
| DA-Module5 | 64/1/2 | (256, 8) |
| DA-Module6 | 64/1/2 | (512, 4) |
| FC layer | - | (1, 360) |
| Structure | RPA | RCA |
|---|---|---|
| CREPE [26] | 91.36% | 91.48% |
| EA | 91.46% | 91.62% |
| CA | 91.71% | 91.92% |
| DA-S | 91.91% | 92.07% |
| DA-P | 91.68% | 91.83% |
| DA-TC | 92.08% | 92.26% |
| Structure | RPA | RCA |
|---|---|---|
| CREPE [26] | 87.55% | 89.53% |
| EA | 92.40% | 92.84% |
| CA | 88.77% | 89.63% |
| DA-S | 90.30% | 91.96% |
| DA-P | 91.31% | 91.76% |
| DA-TC | 93.15% | 93.41% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, W.; Hu, Y.; Huang, H. Dual Attention Network for Pitch Estimation of Monophonic Music. Symmetry 2021, 13, 1296. https://doi.org/10.3390/sym13071296
Ma W, Hu Y, Huang H. Dual Attention Network for Pitch Estimation of Monophonic Music. Symmetry. 2021; 13(7):1296. https://doi.org/10.3390/sym13071296
Chicago/Turabian StyleMa, Wenfang, Ying Hu, and Hao Huang. 2021. "Dual Attention Network for Pitch Estimation of Monophonic Music" Symmetry 13, no. 7: 1296. https://doi.org/10.3390/sym13071296