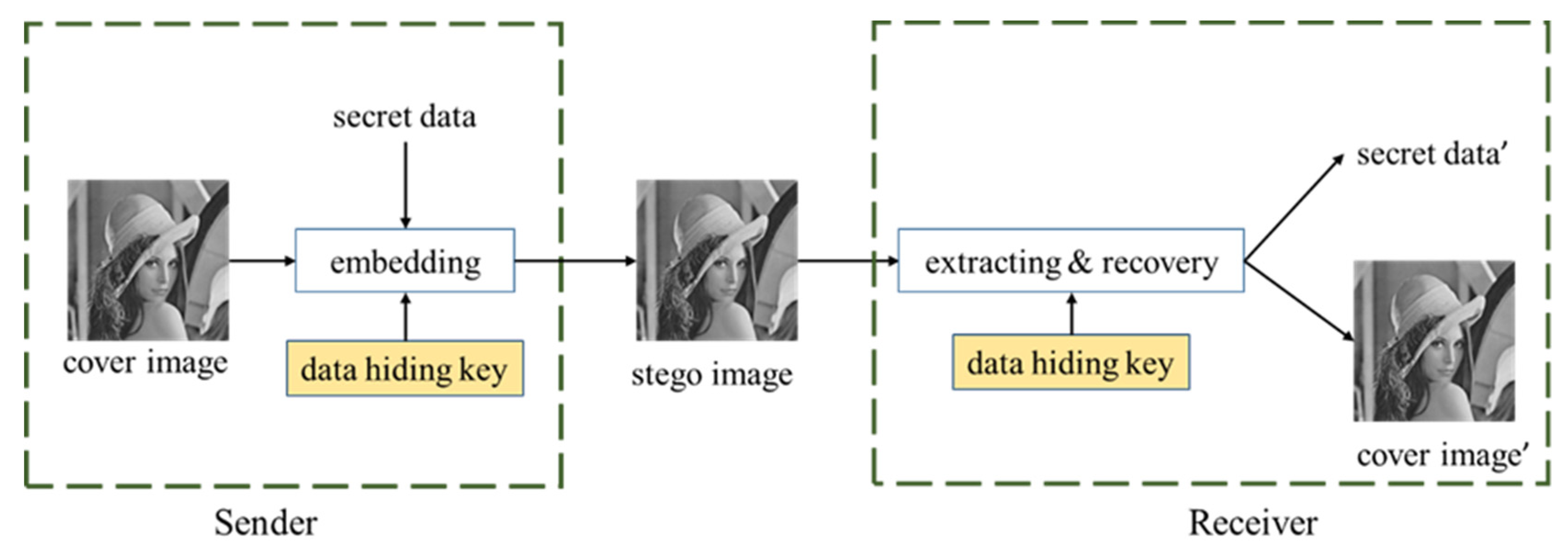
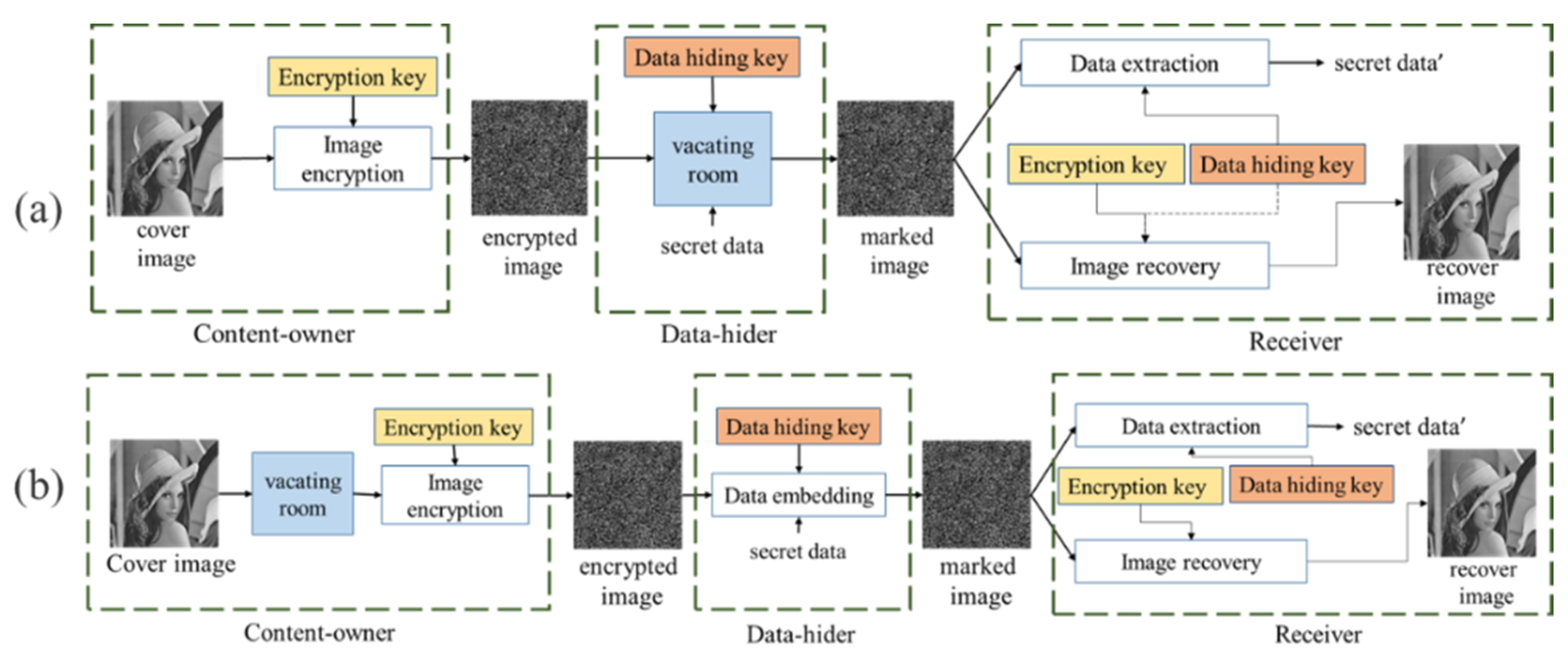
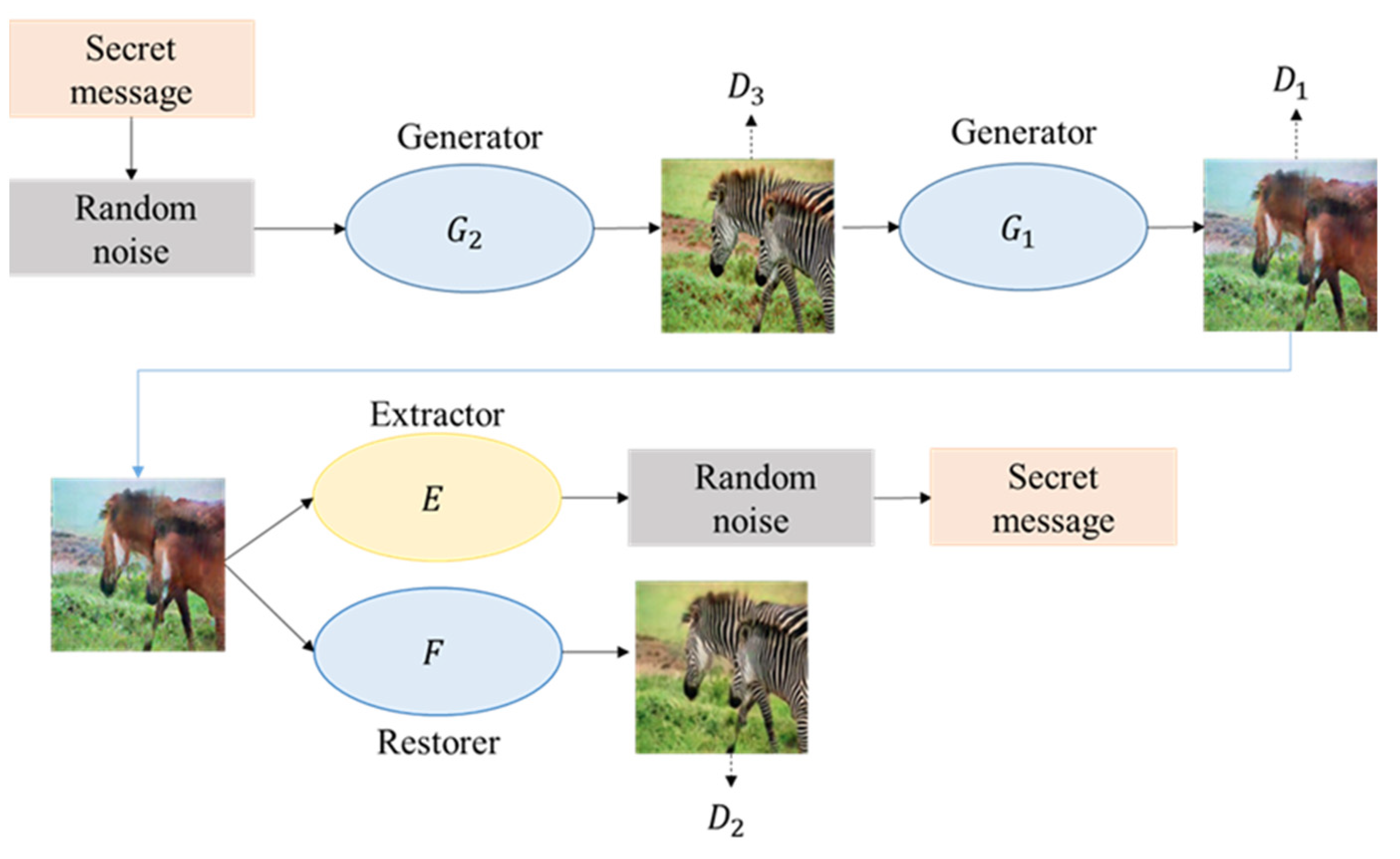
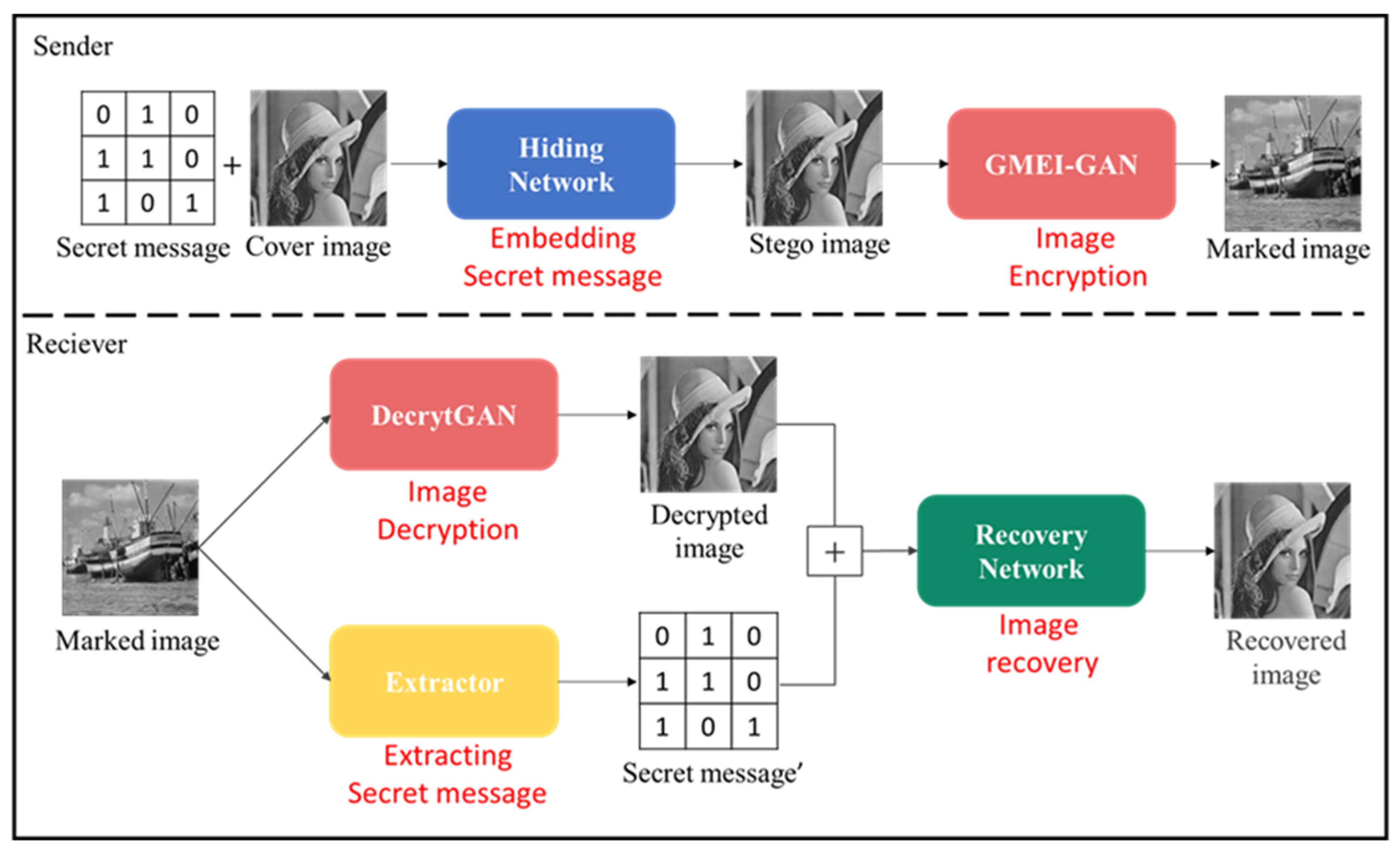
The purpose of the proposed method is to generate meaningful encrypted images and implement reversible data hiding techniques. Therefore, this study proposes an RDH scheme based on deep learning. The scheme consists of four networks, namely, the hiding network, the encryption/decryption network, the extractor, and the recovery network. The hiding network is responsible for hiding the secret message into the cover image to generate the stego image. The encryption/decryption network is responsible for transforming the cover image into the marked image (encryption) and from the marked image back to the cover image (decryption). The extractor is responsible for extracting the secret message from the marked image, and the recovery network is responsible for recovering the cover image from the decrypted image and the extracted secret message. The flowchart of the proposed method is shown in
Figure 11. In this section, the structure and the method for each network are introduced in
Section 3.1,
Section 3.2,
Section 3.3,
Section 3.4, respectively.
3.1. Hiding Network
In the hiding network, the input is the secret message and the cover image, and the secret message needs to be preprocessed. The amount of secret message in this paper is based on the length and width of the cover image (e.g., if the size of the cover image is
, then the amount of secret message hiding is
, where
n is the number of channels) and then the secret message is transformed from vector to matrix and combined with the cover image in a channel-wise way. The size of
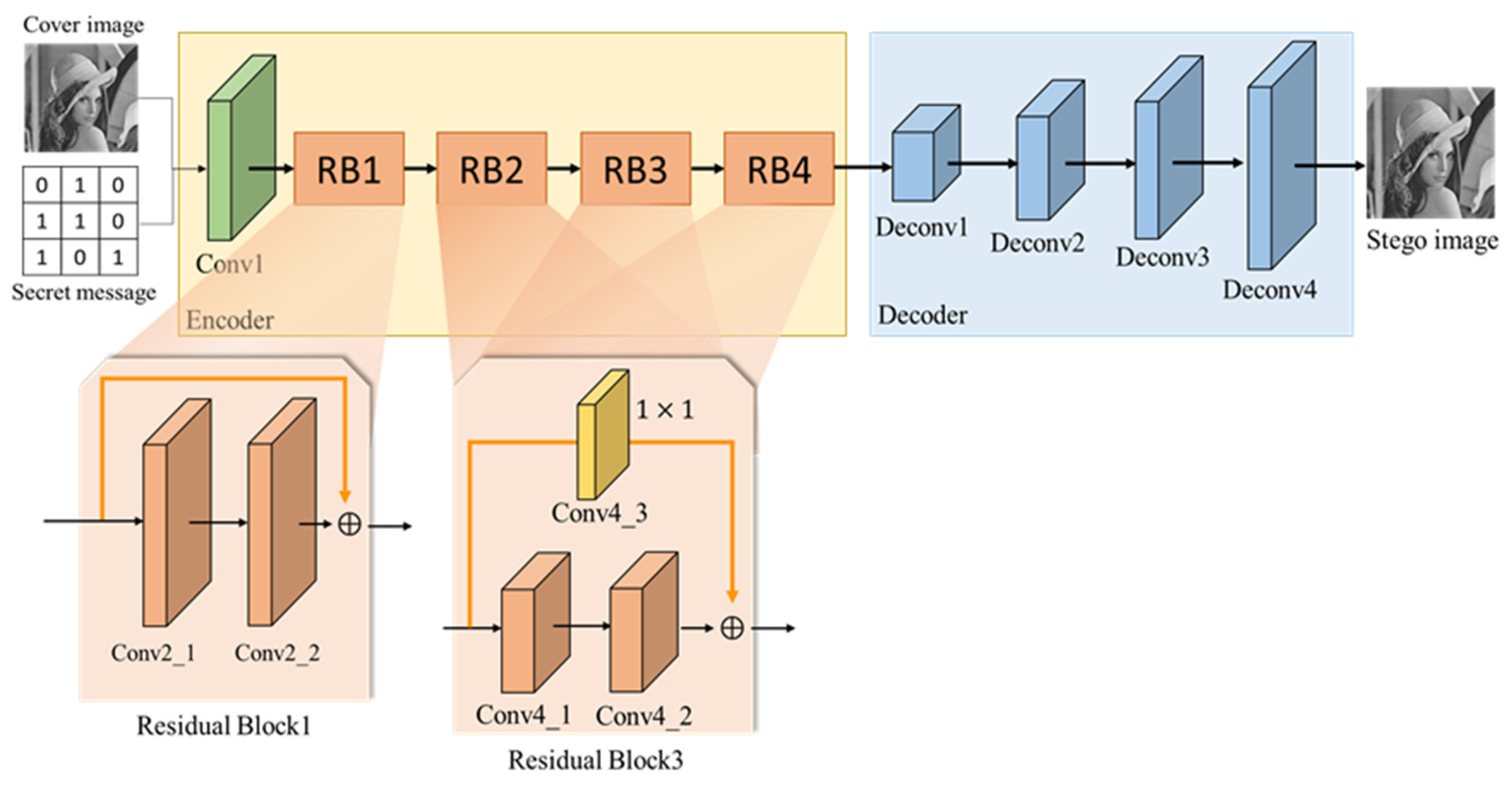
is used as the input for the network. The purpose of the hiding network is to hide secret message in the cover image, to find a suitable location in the cover image for hiding, and to minimize the difference between the generated cover image and the marked image. The hiding network architecture is shown in
Figure 12, and the number of layers of the network structure is shown in
Table 1.
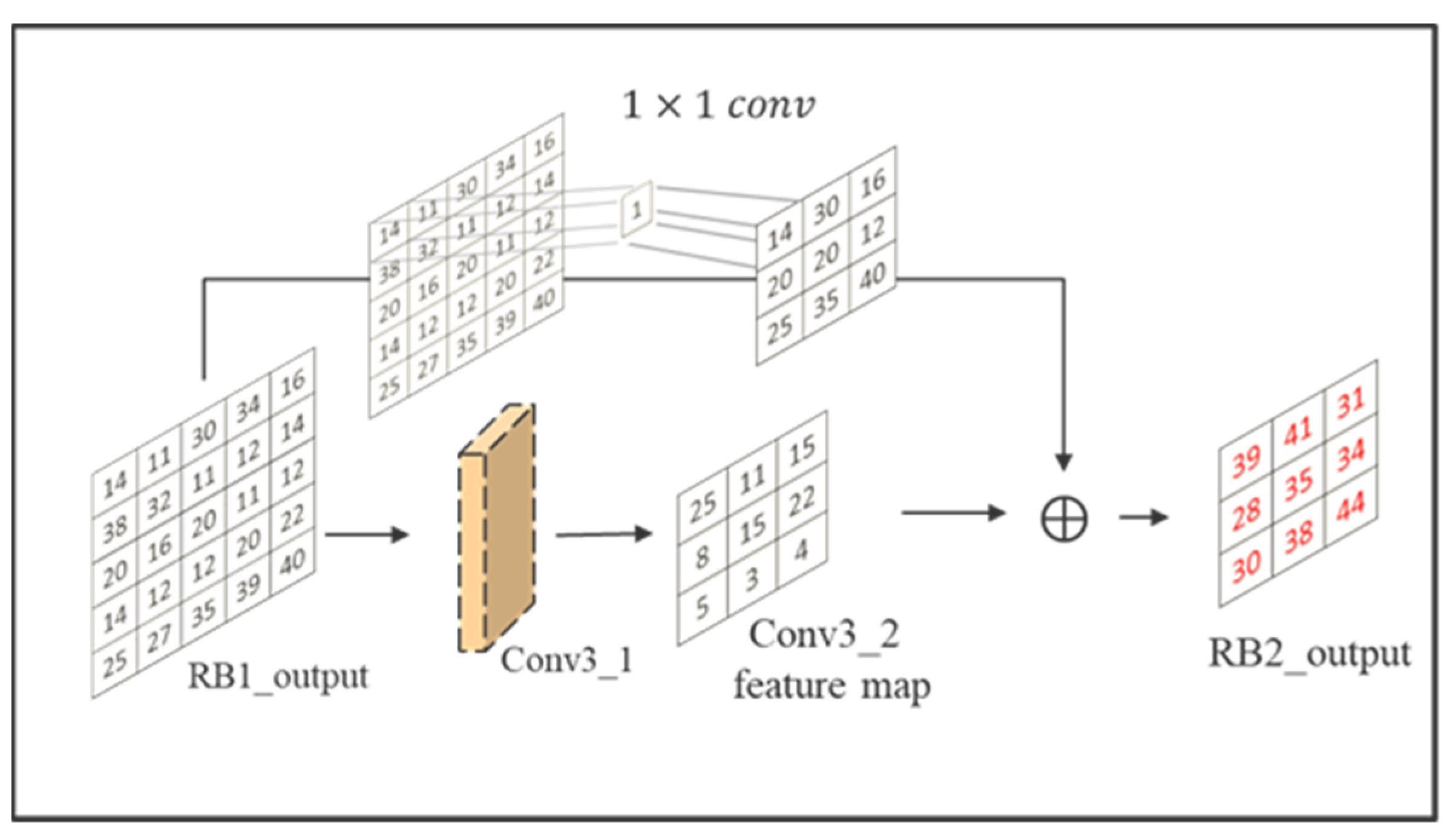
The network architecture can be divided into two parts, encoder and decoder. In the encoder, the concept of residual learning is mainly used to learn more complex features. Since a single-layer residual block cannot enhance the learning effect, the residual block usually needs to be designed with more than two layers of convolution layers. Therefore, this study designed one residual block for every two convolutional layers and each residual block for skip connection, so that the output of each residual block contained the output of the previous residual block. It is worth noting that because the output feature maps of residual blocks had different sizes, a convolution layer was added before each skip connection to make the feature maps have the same size, and the residual block calculation is shown in
Figure 13.
In the encoder, there is one convolutional layer with a kernel size of , three convolutional layers with a kernel size of , four residual blocks, and two convolutional layers with a kernel size of in each residual block. The purpose of the first convolutional layer is to extract the features from the input to obtain the features that combine the secret message and the cover image. The purpose of the convolutional layers is to allow the residual blocks to output the same feature maps to skip connections. The purpose of the residual blocks is to obtain the features and the original input.
These feature maps are used as input into the residual block. BN and activation function ReLU are added after each convolutional layer in the residual block. BN rescales the data distribution in the batch after each convolution according to the set batch size, so that the output of each layer is normalized to a distribution with and , which can increase the generalization ability and accelerate the training speed to make the model have a better learning rate. The ReLU function outputs 0 for input values smaller than zero and outputs the input values for input values larger than zero. By enhancing the nonlinear simulation capability of the model through activation functions, it can better integrate the secret message with the details of the cover image.
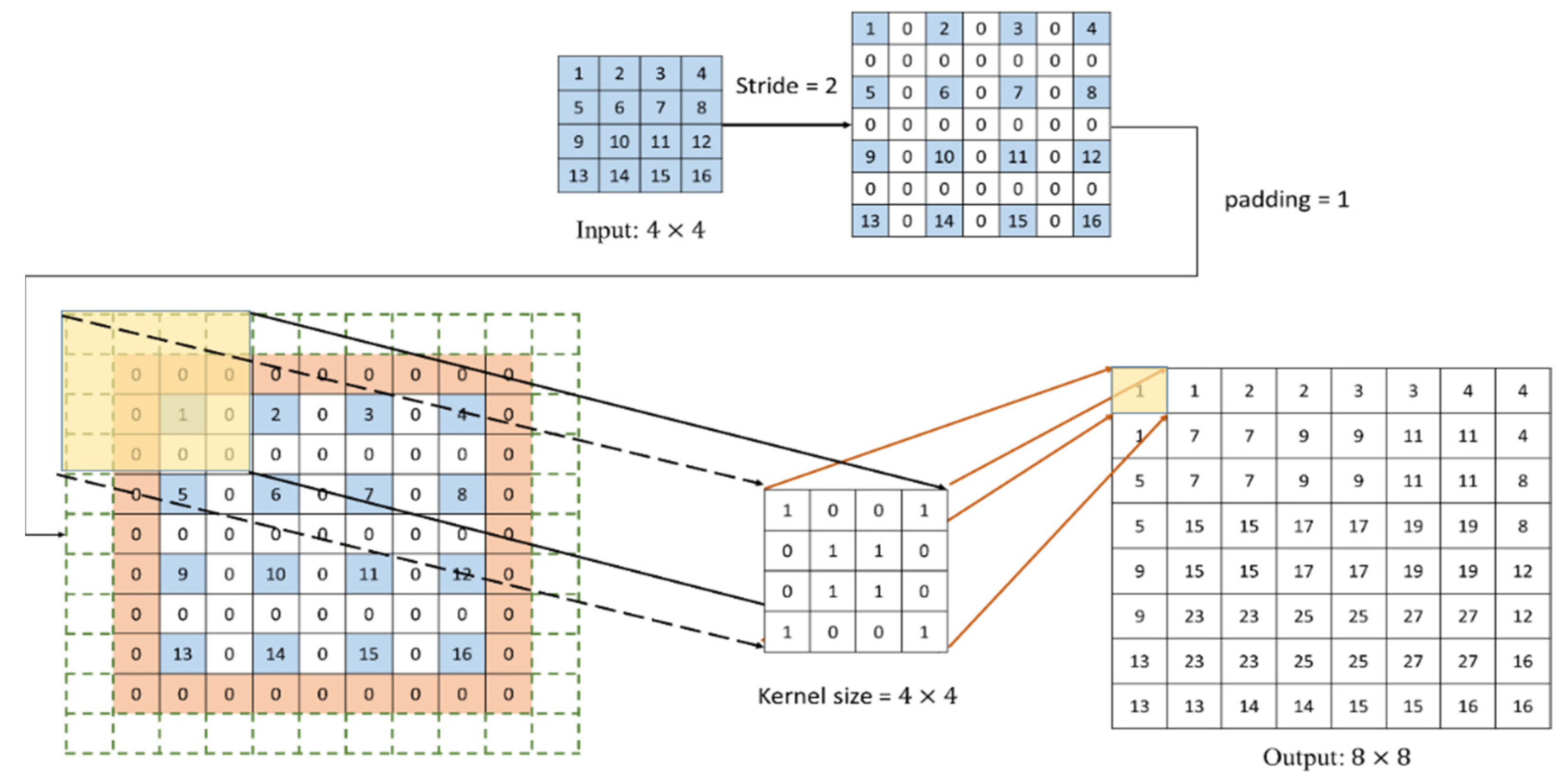
In the decoder, there are four deconvolutional layers. BN and ReLU function are added after each deconvolution layer because the image size is reduced by the convolutional operation in the encoder. Therefore, in the decoder, deconvolution is used for up-sampling so as to restore the image to the original image size, and finally the stego image is output. The process of deconvolution is shown in
Figure 14, where the input feature map is scaled up according to the stride size, then the padding is complemented, and finally the convolution is performed to output the feature map of the deconvolutional layer.
During the training process, the secret message and the cover image are combined as input. After the encoder training, the compressed feature map is obtained. For the decoder training, the compressed feature map is used as the input, and the output image is the same size as the cover image, called stego image.
In order to minimize the difference between the stego image and the cover image, the loss function, Mean Absolute Error (MAE), is used, which can better reflect the real situation of the predicted value and the error. Its formula is expressed in Equation (6).
where
is a cover image and
is a stego image;
is the weight of image and
N is the length of image.
3.2. Encryption and Decryption Networks
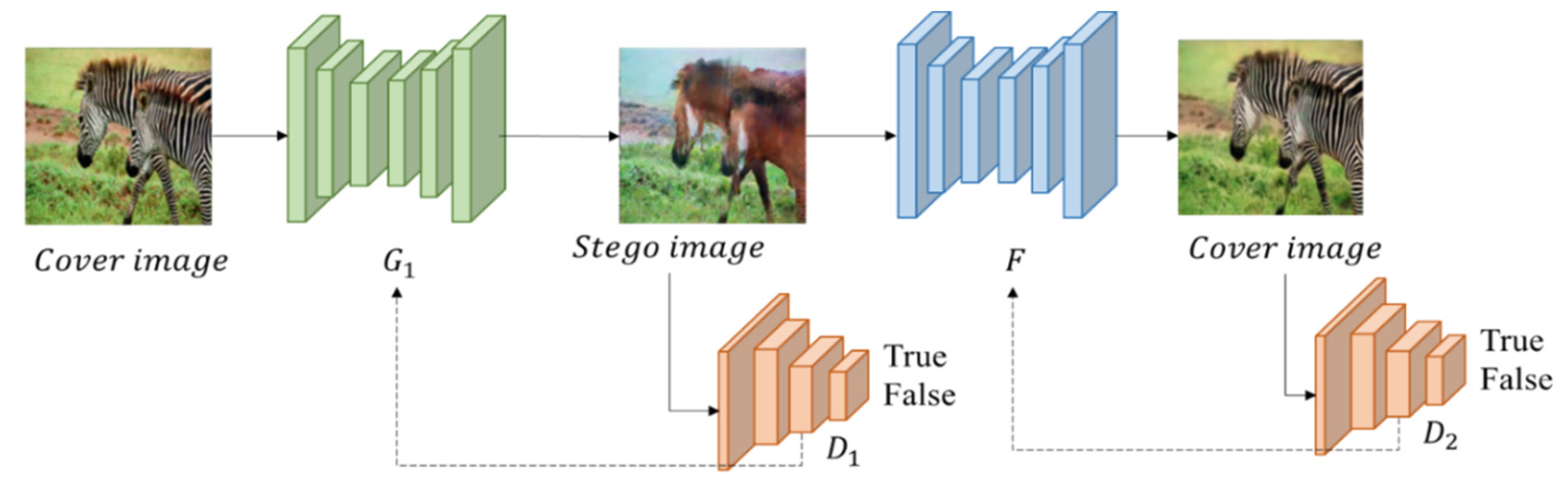
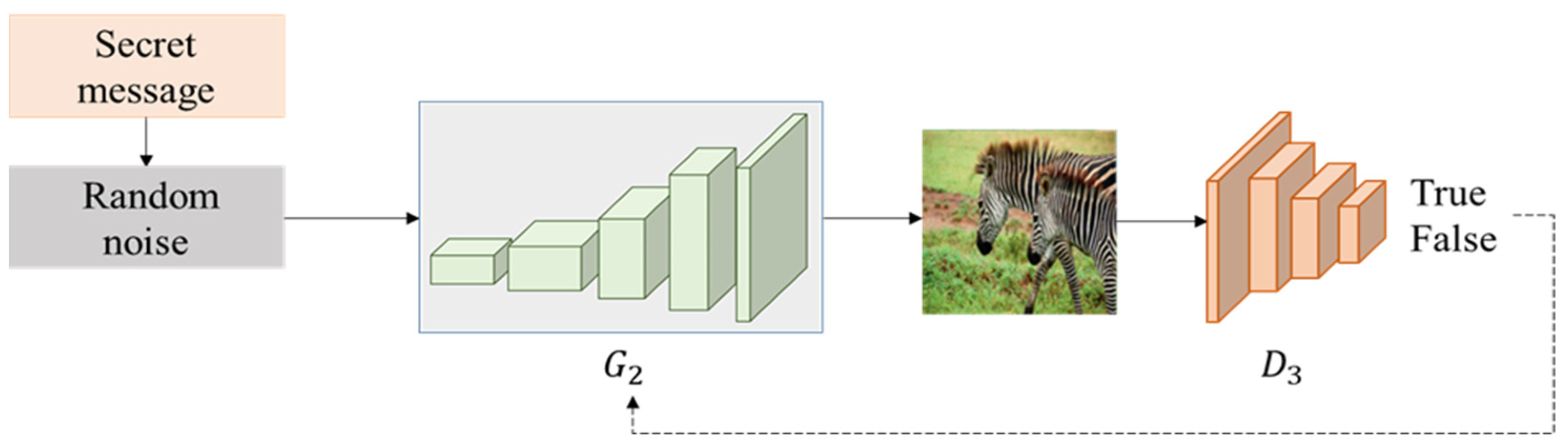
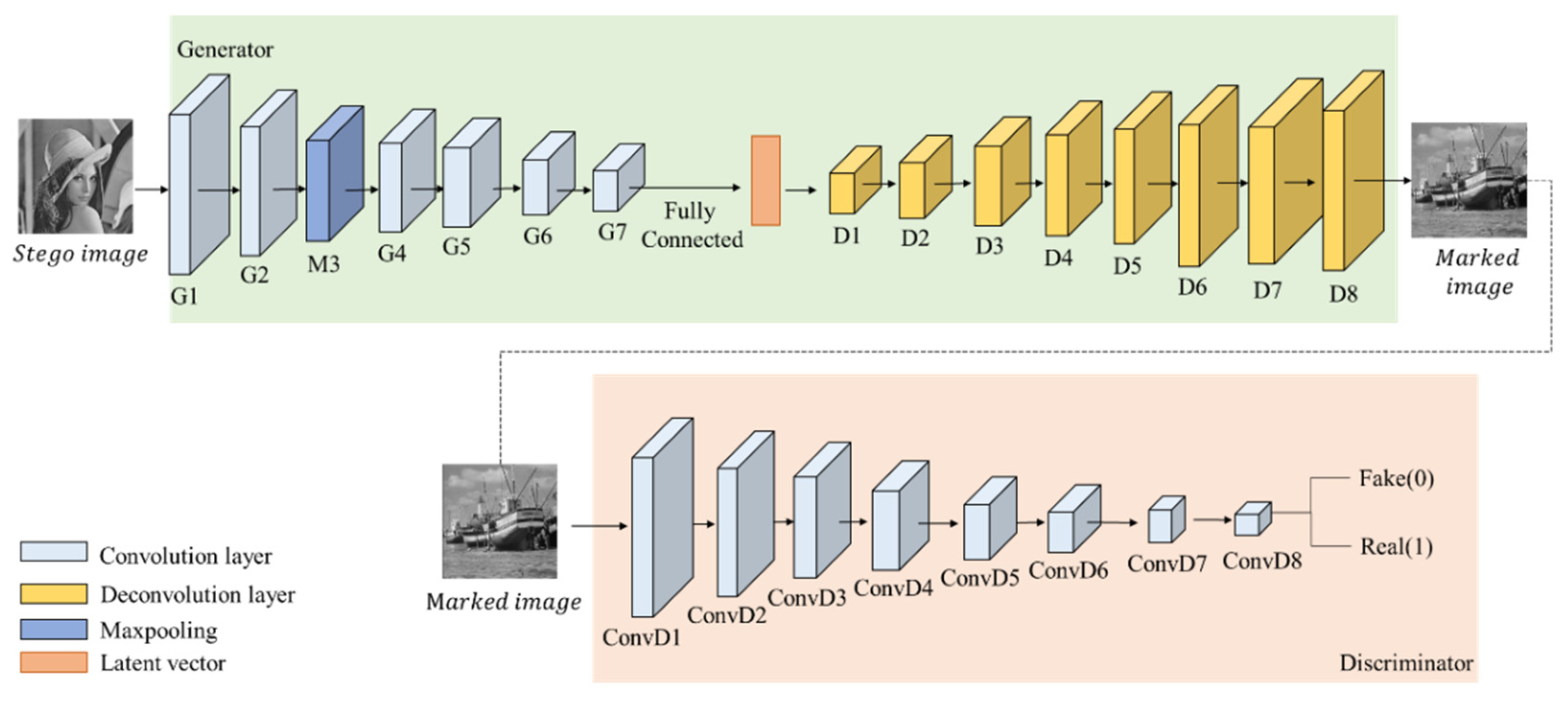
After hiding network, the stego image is obtained. In order to prevent the stego image from being easily detected in the process of data transmission, GMEI-GAN (generate meaningful encrypted images by GAN) is proposed in the encryption network, so that the stego image can generate a meaningful image, called marked image. Moreover, in the decryption network, the marked image can be restored by DecryptGAN. The architecture is displayed in
Figure 15. These two GANs have the same architecture. The structure of GMEI-GAN is presented in
Table 2 and
Table 3.
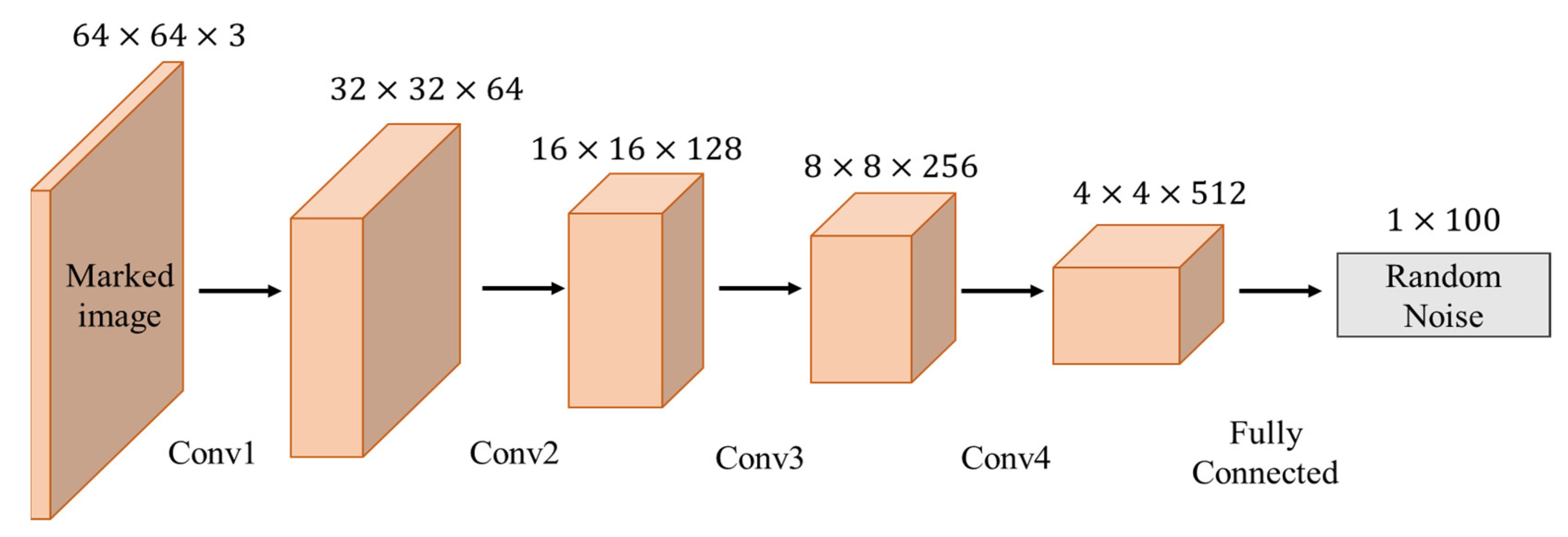
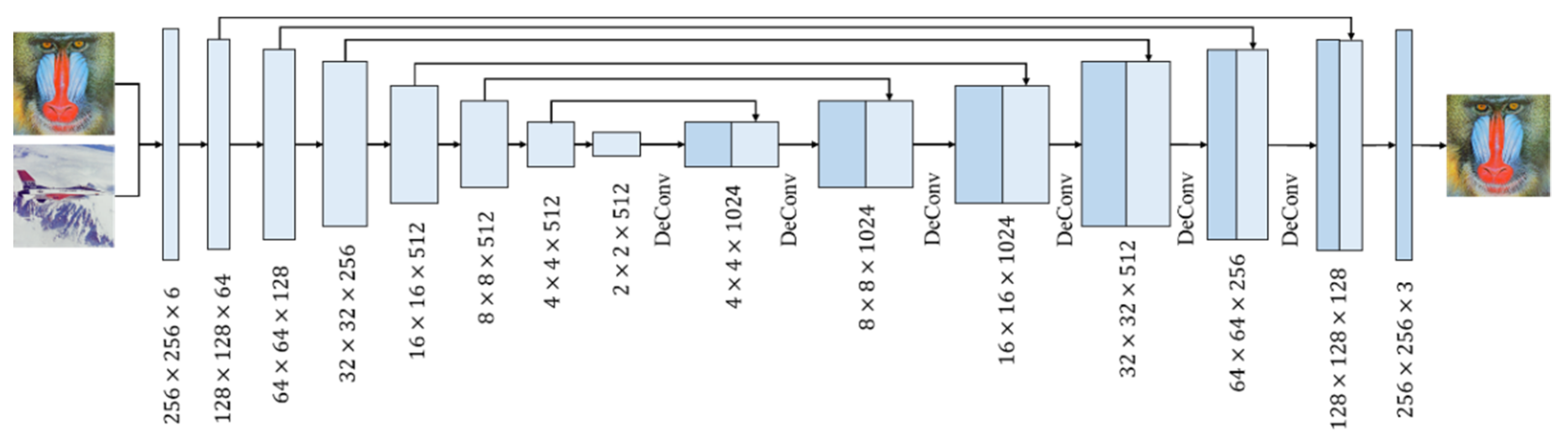
In GMEI-GAN, the generator built is based on the encoder and decoder, using six convolutional layers, eight deconvolutional layers, one max pooling layer, and one fully connected layer. In the encoder, the feature maps are extracted through the convolutional layer, and the dimensions are compressed to reduce the model computation. The final output of the encoder is , which is compressed into a latent vector by the fully connected layer. In the decoder, the latent vector is used as the input, and the feature vector of the low-dimensional space is converted to the high-dimensional space by deconvolution. The image returns to its initial size, and the output image is called the marked image.
The discriminator uses eight convolutional layers and adds BN and activation function LeakyReLU after each convolutional layer. The difference from ReLU is that LeakyReLU gives a non-zero gradient to negative values. Therefore, the gradient to negative values can be calculated and increases the nonlinear capability.
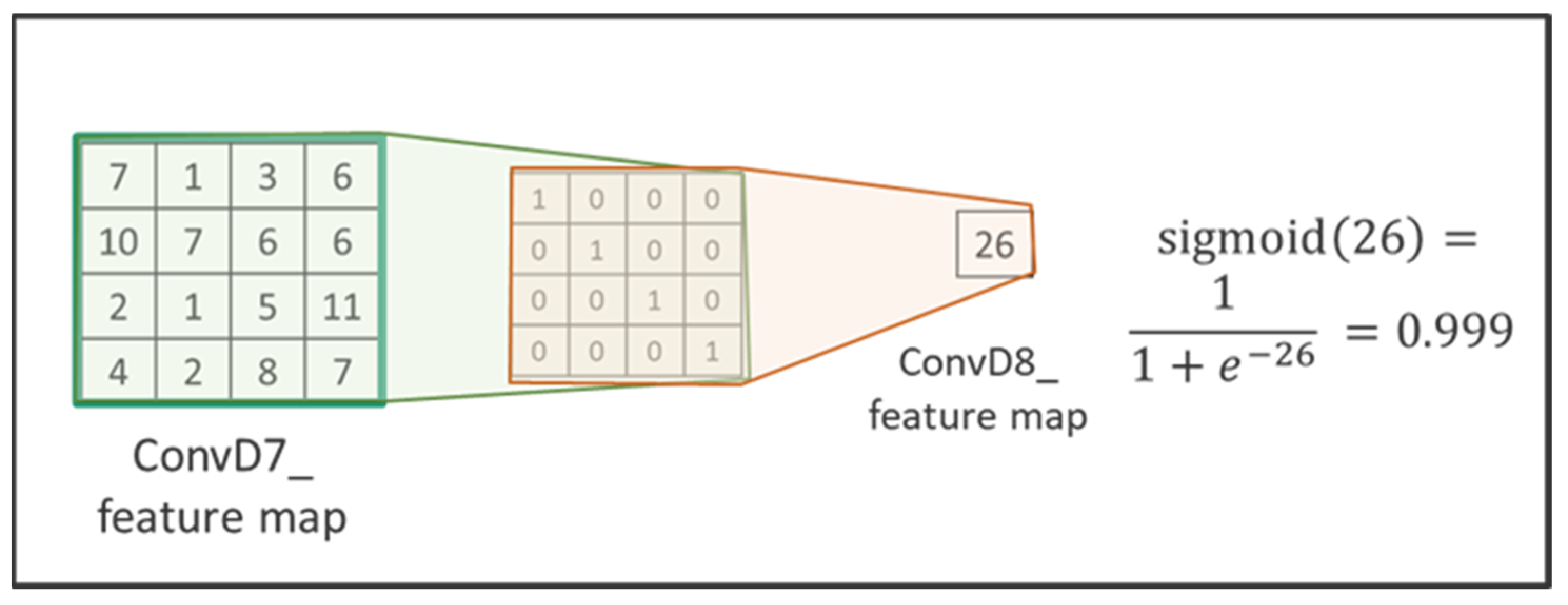
The sigmoid function is used in the last level of the activation function. Since the sigmoid outputs a value between 0 and 1, it can be used as a discriminator to evaluate whether the image is real (close to 1) or fake (close to 0). The calculation of the discriminator uses the sigmoid function as last layer is shown in
Figure 16.
In the training process, the stego image is the input of the generator, the encrypted image is considered as the training target of the generator, and the output is the marked image. MAE is used as the loss function for the purpose of minimizing the difference between the marked image and the encrypted image.
In addition, the aim of the generator is that the generated image can deceive the discriminator to be considered a real image. As for the discriminator, it aims to discriminate the real image from the generated image. The weights for the generator and discriminator models can be adjusted. During the training process, the generator and the discriminator back-propagate the loss function to implement weight updates repeatedly. The loss function of GAN is defined as:
where
G is the generator and
D is the discriminator. When the real image is the input of the discriminator, the discriminator needs to maximize the value of the item and determine its closeness to 1. When the image is trained by the generator and the generated image is a fake image, it is the item that the discriminator wants to minimize and determine its closeness to 0. In addition, the generator wants to deceive the discriminator to make its output value as close to 1 as possible. Therefore, the best way is to find a balanced state by updating the parameters of the discriminator and the generator through the loss function.
Although the architecture of DecryptGAN is the same as GMEI-GAN, its input is the marked image and its output is the decrypted image, which is different from GMEI-GAN. In an ideal state, the decrypted image is the same as the cover image. However, in reality, the decrypted image contains a secret message which has not been extracted yet. If the receiver does not know the extraction key, then the secret message cannot be taken out. As a result, the marked image can only be decrypted. In this way, the purpose of protecting the secret message is achieved.
Through GMEI-GAN and DecryptGAN, the images are transformed. The image transformation adopts the encryption and decryption techniques in the RDH, so that the secret message and the cover image have better protection, and the encrypted image is a meaningful image instead of a ciphertext.
3.3. Extractor
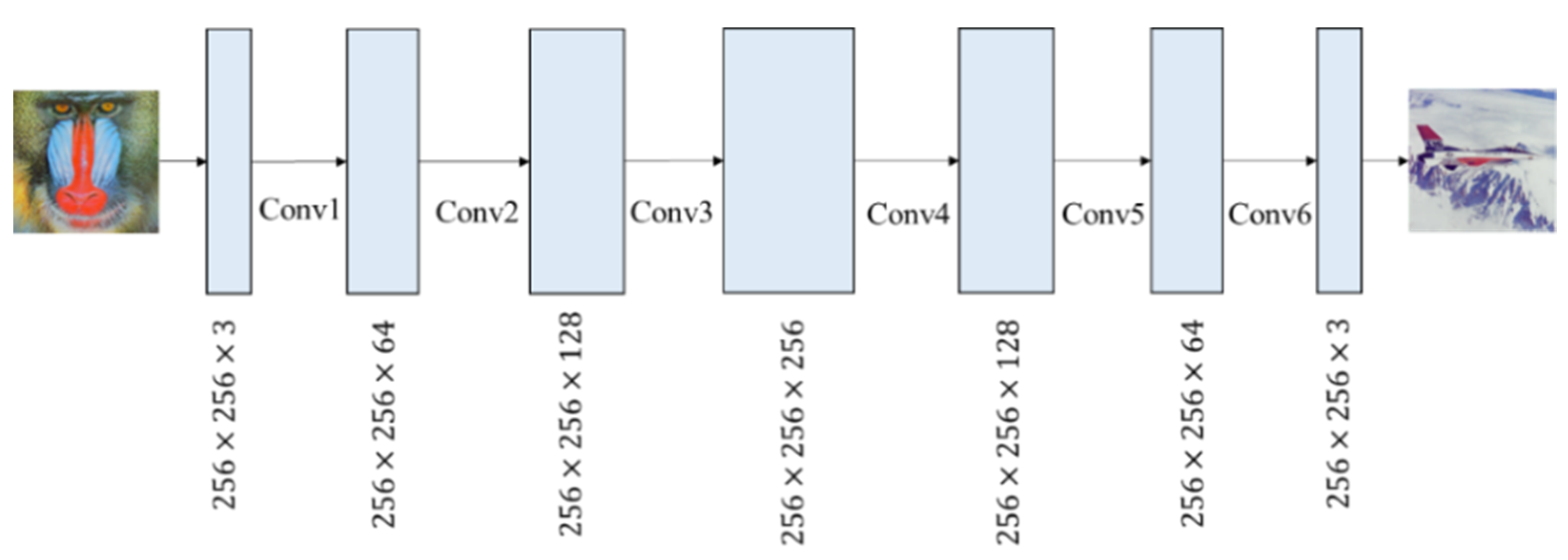
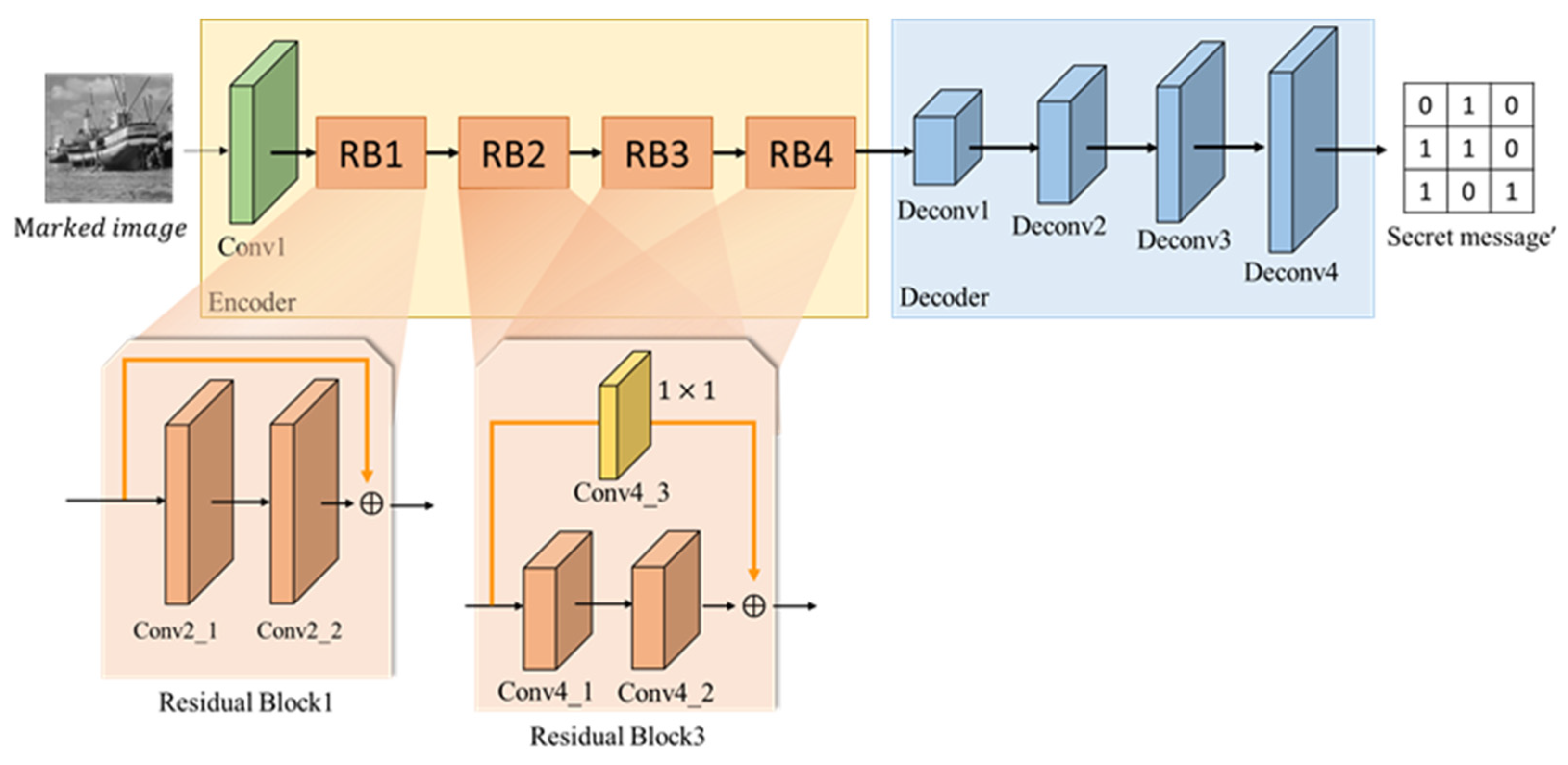
To extract the secret message from the marked image, the extractor is having specific architecture, as shown in
Figure 17. The network structure is illustrated in
Table 4. The extractor consists of an encoder, a decoder, one convolution layer with a kernel size of
, three convolutional layers with a kernel size of
, four residual blocks, and two convolutional layers with a kernel size of
in each residual block. ReLU and BN are added after each convolutional layer. The purpose of the encoder is to obtain the features of the secret message and compress them into a vector as the output of the encoder. As for the decoder, it is composed of five deconvolutional layers, and ReLU and BN are added after each convolutional layer to increase the non-linear emulation capability.
Here, the secret message can be any kinds of digital data including text, image, or voice. Before we embed the secret message into the cover image, we transform the message as a binary code, i.e., the secret message consists of 0 and 1. Since the secret message consists of all 0 or 1, the output value of sigmoid is between 0 and 1. Sigmoid is used for the last layer of the activation function, and a threshold value less than 0.5 is set as 0 and greater than 0.5 as 1, as shown in
Figure 18. In the training process, the decrypted image is used as the input into the extractor. A vector of the same size as the secret message is obtained from the extractor training. MAE is used as the loss function. The extractor can extract the secret message completely through the proposed network and loss function.
3.4. Recovery Network
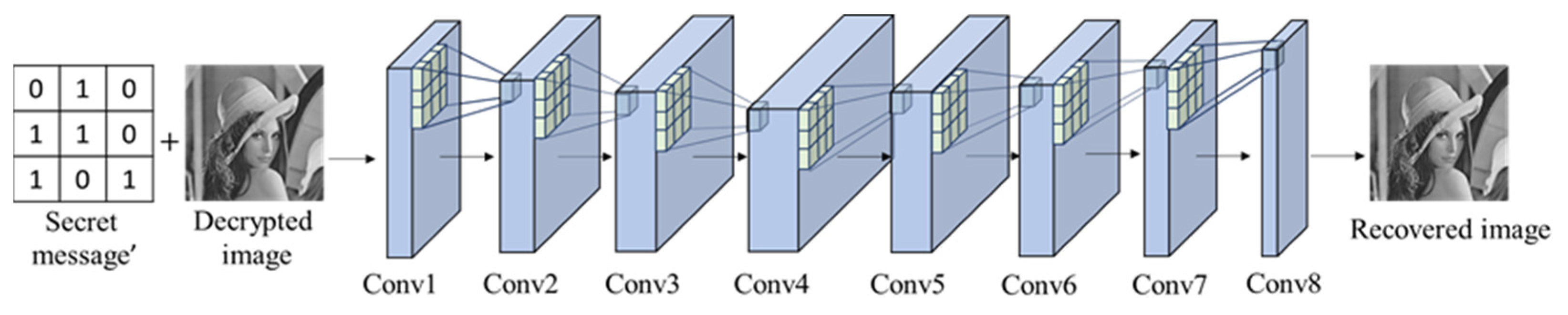
In the recovery network, the recovered image is restored by extracting secret message and decrypted image. Its architecture is shown in
Figure 19, and its structure is listed in
Table 5.
To prevent the image from being compressed and distorted, there are no pooling layers and dropout operations in the recovery network. In the recovery network, there are eight convolutional layers with a kernel size of , the padding is set to 1 for each layer, and the stride is set to 1. Furthermore, the feature map obtained from each convolution is the same size as the original image. ReLU and BN are added after each convolutional layer to increase the non-linear emulation capability, and the sigmoid function is added in the last layer. In the recovery network, MAE is used as a loss function to minimize the loss between recovered image and cover image.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}