
ACTS: An Ant Colony Based Transmission Scheduling Approach for Cloud Network Collaboration Environment


Abstract
:1. Introduction
- How to design an overall optimization model. In the overall scheduling process, we assume two kinds of transmission links. There are resource constraints and time window constraints, which should be respected for each link. We try to achieve the best overall optimization result while satisfying the different constraint limits of each link.
- How to solve the local optimum problem of ant colony algorithm. It is difficult for the ant colony algorithm to avoid falling into a local optimality. This problem is particularly serious when there are limited numbers of relay nodes.
- We propose a multi-link optimization mechanism based on the ant colony algorithm. The transmission is divided into two links. To meet the need, this mechanism uses an ant colony algorithm for the overall optimization. This mechanism also contains the store-and-forward transmission method in downlink relay link and the min–min method in uplink relay link. This mechanism is not only an overall optimization, but also contains optimization methods for each local link.
- We design a new update rule for the pheromone of the ant colony algorithm. The traditional ant colony algorithm is easy to fall into a local optimum, which is caused by a large number of pheromones gathered in non-optimal paths. To solve this problem, we improve the pheromone update rule.
- To achieve efficient data transmission scheduling, we propose the ACTS model for data transmission scheduling. In the ACTS model, we first design the node state prediction mechanism to obtain reliable relay node state information. Then, we design a multi-link optimization mechanism based on the ant colony algorithm as a way to take into account the respective constraints of each link. Finally, we refine the update rules of the pheromone of the ant colony algorithm to prevent the algorithm from falling into a local optimum.
- We conducted experiments to demonstrate that our method consistently outperforms the current state-of-the-art methods which support time window constraints.
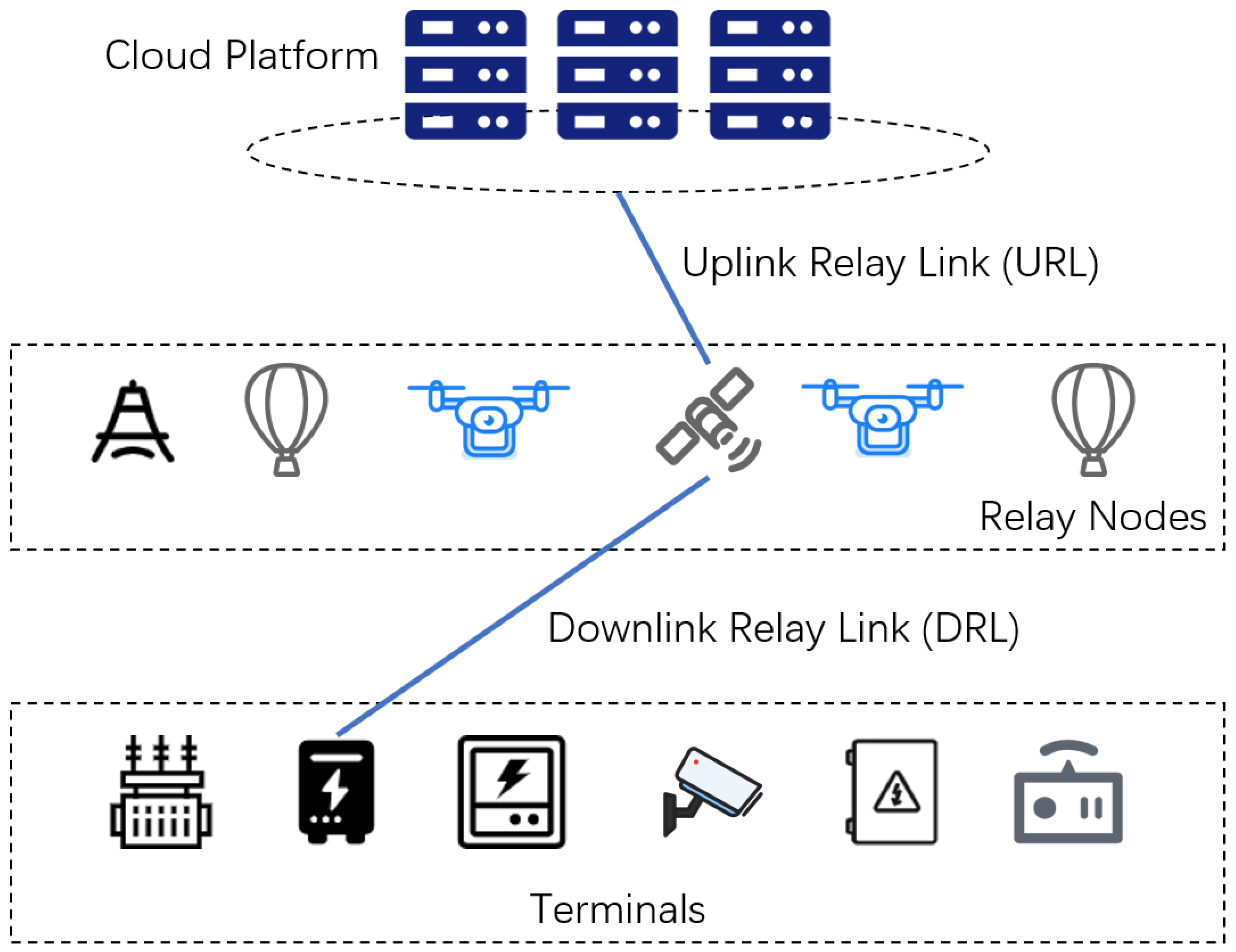
2. Background
3. Related Work
3.1. Resource Scheduling
3.2. Ant Colony Algorithm
3.2.1. Transition Probability
3.2.2. Pheromone Update Rule
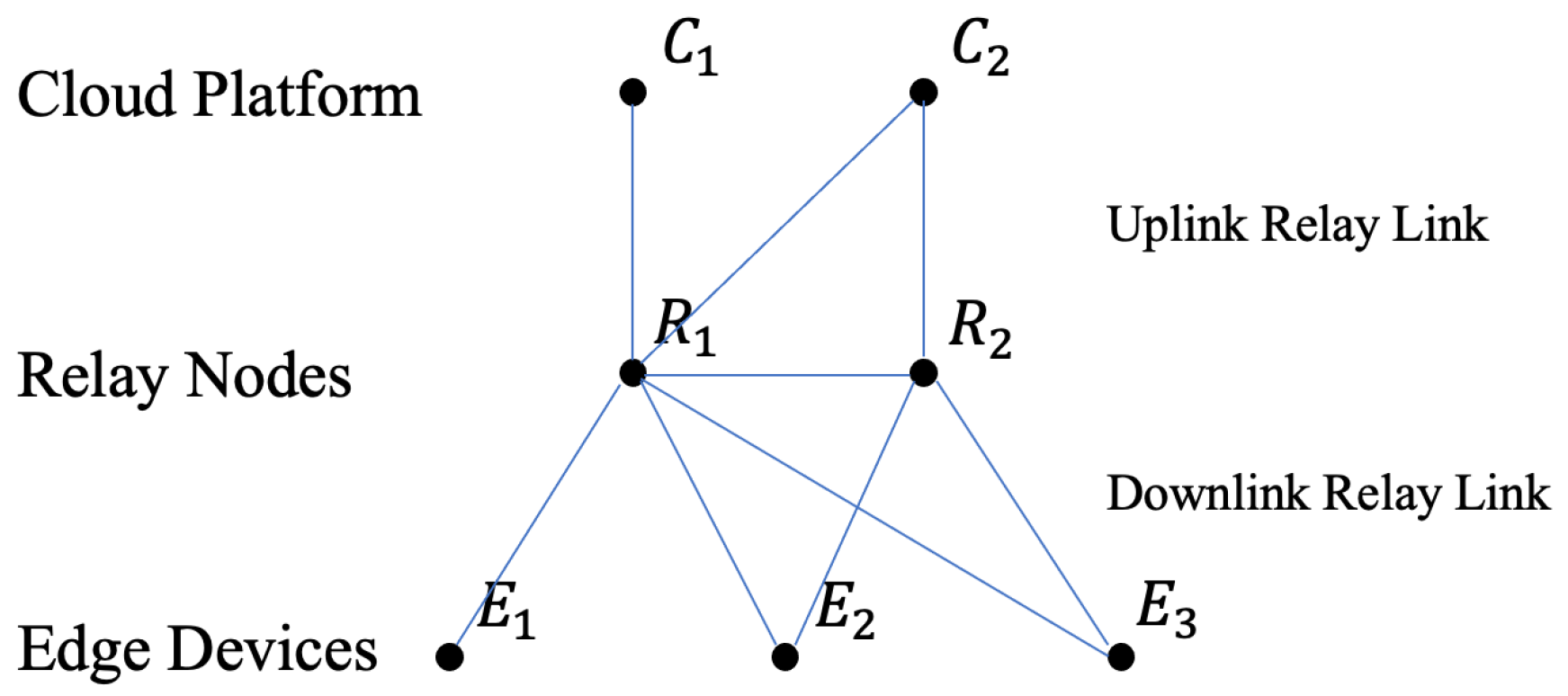
4. Problem Formulation
4.1. Downlink Relay Link Constraints
- Time window constraintEdge devices are far away and located in mostly harsh climatic environment. Therefore, the edge device and the relay node are visible to each other only within a specific time constraint. Figure 2 shows that the edge device is visible to the relay node and within the time windows and . The data can be downloaded by in or by in .For example, suppose that we have a number of terrestrial towers that act as relay nodes for data transmission. However, these towers are located in a very harsh geographical environment with frequent thunderstorms, rain and snow. These factors will make it impossible to transmit data with them at all times, but only during specific time windows when the weather conditions are met. If during a schedule, the edge device cannot transmit with any relay node, tasks will be stored and try to execute in the next schedule.
- Resource constraintEach relay node has limited resources, including CPU, memory and bandwidth. The large amount of data generated by edge devices needs to be transmitted. This process requires the CPU, memory and bandwidth of relay nodes. If these resources are not sufficient, then data transfer will be delayed or even blocked, and it is also difficult to guarantee real-time availability. Therefore, it is necessary to ensure that the relay node has sufficient resources for data transmission. The data transmissions between terminals and relay nodes are competitive; some tasks may not be completed due to insufficient resources by competition. These tasks are stored and participate in the next scheduling. The formalization of the constraint in Equation (5) is as follows:
- Task constraintEach task is marked as being completed only once and does not participate in subsequent task scheduling.
4.2. Uplink Relay Link Constraints
- Resource constraintsWe assume that the resource of the cloud platform is sufficient. However, the resources of the relay nodes need to be taken into account, such as CPU, memory and bandwidth. Similar to the description in the downlink relay link constraint, the scarcity of these resources may cause delays or blockages in data transmission. The formalization of the constraint in Equation (6) is as follows:
- Task ConstraintsAfter each transmission task is done, it is marked as completed. That means there are no retransmissions, etc.
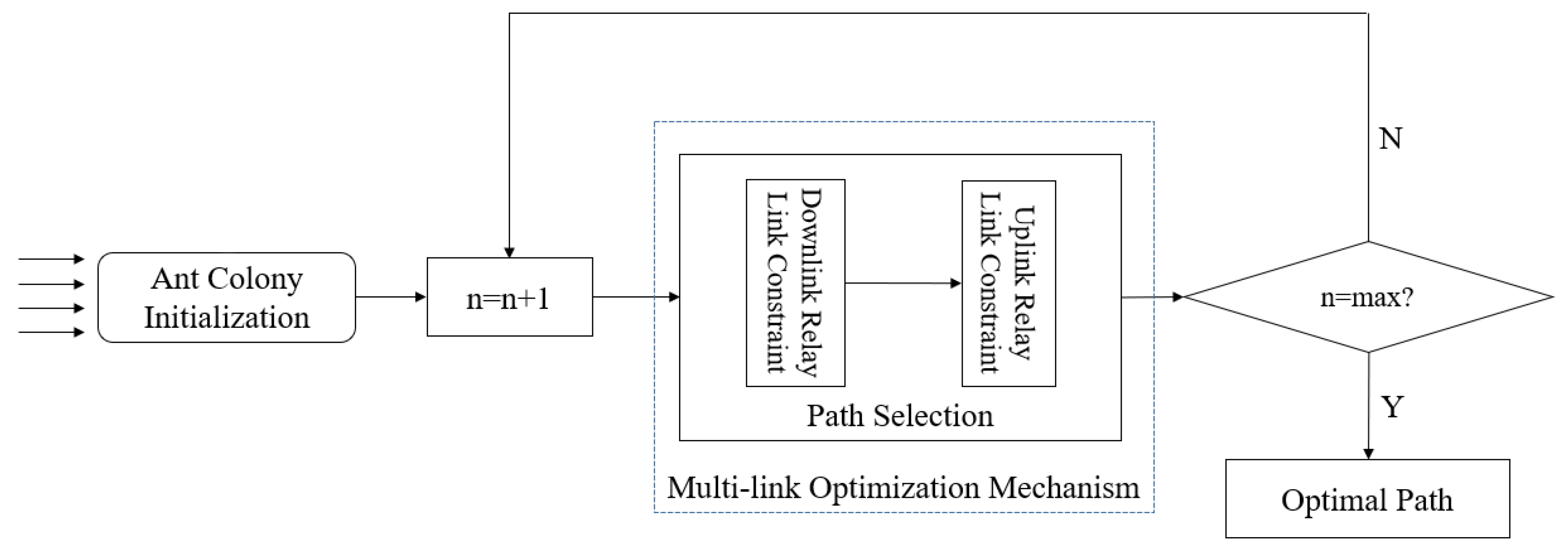
5. Methodology
- Initialization of ant colony algorithm parameters. Set the parameters of the ant colony algorithm, including the colony size M, number of iterations K, pheromone enhancement Q, pheromone evaporation factor , and the proportion of pheromone update ants . Initialize the task set, with each source node generating a certain number of scheduled tasks.
- Iterate to find the best path. This is the main part of the algorithm. Each iteration of every ant in the colony achieves the scheduling of all tasks, which will eventually result in a current optimal solution.
- (a)
- Randomly generate the starting node for each ant.
- (b)
- Optimal selection of paths and selection of suitable nodes based on state transfer probabilities.
- (c)
- Modify the taboo table by placing the node in the taboo table after selecting the path, using the taboo table to prevent repeated selection of the same node and avoid the loop path [17].
- (d)
- Calculate the path distance of individual ants to obtain the optimal path length.
- (e)
- Update the pheromones on each path according to the update rules.
- (f)
- Iterate incrementally while resetting the route record table used to record the path that each ant assigned to.
- Output the best path for each generation, and the optimal solution is obtained after several iterations. The overall transmission time is our optimization metric, and the solution with the smallest transmission time is optimal. The overall transmission time can be calculated by Equation (7). The specific calculation procedure is also provided in Algorithm Section 5.1.

- The transmission is divided into multiple links. Each link has different constraints. The traditional ant colony algorithm cannot reflect the difference between different links.
- The ant colony algorithm is easy to fall into the local optimum, especially when the number of the node is small.
5.1. Overview of ACTS
- The specific meaning of entities in ACTSEach ant is assigned a path in an iteration and is updated only before the next iteration. The ant represents an assignment scheme of tasks to relay nodes; the path refers to the selection of relay nodes as paths from the edge nodes to the cloud; and the tasks refer to the transmitted data collections generated by the edge devices.
- Rules for updating pheromonesThe pheromone update rule follows Equation (10). The improvement to the ant colony algorithm is reflected in the fact that only the pheromones of some ant paths are updated. The ant paths’ updated pheromones are those with a short task transmission time, which improves the convergence speed and prevents the algorithm from falling into a local optimum.
- Probability of ant path selectionRandom path selection performs after all ants have completed their paths in each iteration. The probability of ant path selection follows Equation (1).
- Evaluation of the constraintsThe time window constraint is used to determine which nodes can participate in the scheduling of a particular task; the resource constraint is used to calculate of the task allocation ratio using the hierarchical analysis matrix.
- Calculation of transmission time in sub-linksThe transmission time can be calculated by the task data size, and the node bandwidth follows Equation (8).
| Algorithm 1 ACTS. |
| Input: The node state (CPU, memory, storage, etc.), S; current time window for edge devices, W; the colony size, M; number of iterations, K; pheromone enhancement Q; pheromone evaporation factor, ; the proportion of pheromone update ants, ; transmission tasks for edge devices, ; relay nodes, R; edge devices, E; total task allocation solution, P; |
| Output: Optimal task allocation solution, ; |
|
5.2. Multi-Link Optimization Mechanism
- For each transmission task in the task set, the minimum times allocated to n stations are calculated. Assume that the task has the shortest time to complete on the kth station, which is . represents the minimum complete time for task i to complete transmission on the kth station. There is an array MinTime with m elements.
- Assume that the a-th element is the smallest in , which corresponds with the bth station; then we assign the ath task to the bth station.
- Delete the ath task from the task set and update the matrix.
5.3. Pheromone Update Rules
6. Experimental
6.1. Experimental Setup
6.2. Experimental Results
6.2.1. Experimental Results
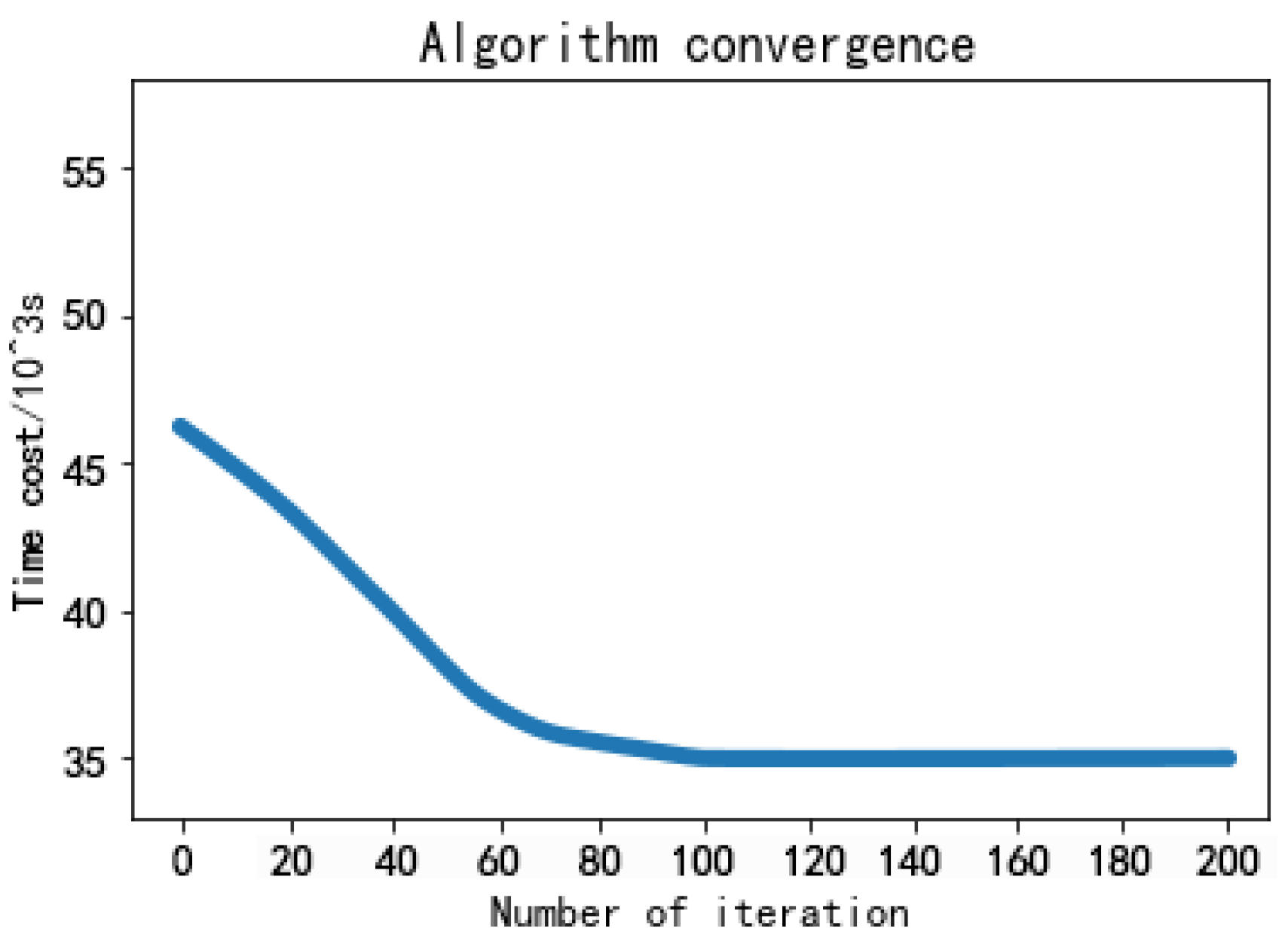
6.2.2. Effects of Parameters
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Manigandan, S.K.; Manjula, S. Hybrid Scheduling Queue Model for Efficient Resource Allocation in Cloud Data Centers. J. Comput. Theor. Nanosci. 2018, 15, 1038–1043. [Google Scholar] [CrossRef]
- Yildirim, E.; Kim, J.; Kosar, T. How GridFTP Pipelining, Parallelism and Concurrency Work: A Guide for Optimizing Large Dataset Transfers. In Proceedings of the 2012 SC Companion: High Performance Computing, Networking Storage and Analysis, Salt Lake City, UT, USA, 10–16 November 2012; IEEE Computer Society: Washington, DC, USA, 2012. SCC ’12. pp. 506–515. [Google Scholar] [CrossRef]
- Blamey, B.; Sintorn, I.; Hellander, A.; Toor, S. Resource- and Message Size-Aware Scheduling of Stream Processing at the Edge with application to Realtime Microscopy. arXiv 2019, arXiv:1912.09088. [Google Scholar]
- Kai, C.H.; Xiao, Y.; Fang, Q. Relay Satellite Scheduling Based on Artificial Bee Colony Algorithm. J. Electron. Inf. Technol. 2015, 37, 635–640. [Google Scholar]
- Chen, H.; Zhou, Y.; Du, C.; Li, J. A satellite cluster data transmission scheduling method based on genetic algorithm with rote learning operator. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; IEEE: Washington, DC, USA, 2016. [Google Scholar]
- Zhang, F.; Chen, Y.; Chen, Y. Evolving Constructive Heuristics for Agile Earth Observing Satellite Scheduling Problem with Genetic Programming. In Proceedings of the 2018 IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: Washington, DC, USA, 2018. [Google Scholar] [CrossRef]
- Zhang, Z.; Hu, F.; Zhang, N. Ant colony algorithm for satellite control resource scheduling problem. Appl. Intell. 2018, 48, 3295–3305. [Google Scholar] [CrossRef]
- Liang, Z.; Liu, L.; Jiang, J.W.; Guo, J.; Zhang, Y.; Yan, H. Data relay system data download scheduling algorithm for earth observation satellites. In Proceedings of the 2017 IEEE International Conference on Communication, Networks and Satellite (Comnetsat), Semarang, Indonesia, 5–7 October 2017; IEEE: Washington, DC, USA, 2017. [Google Scholar] [CrossRef]
- Sreenivasulu, G.; Paramasivam, I. Hybrid optimization algorithm for task scheduling and virtual machine allocation in cloud computing. Evol. Intell. 2021, 14, 1015–1022. [Google Scholar] [CrossRef]
- Song, B.; Yao, F.; Chen, Y.; Chen, Y.; Chen, Y.W. A Hybrid Genetic Algorithm for Satellite Image Downlink Scheduling Problem. Discret. Dyn. Nat. Soc. 2018, 2018, 1531452. [Google Scholar] [CrossRef] [Green Version]
- Yi, Z.; Jiang, D.; Cao, L.; Du, X. A Handover Decision Algorithm Based on Evolutionary Game Theory for Space-Ground Integrated Network; Atlantis Press: Paris, France, 2019. [Google Scholar]
- He, Y.; Wang, L.; Zhan, Y.; Cao, S.; Luo, X. Dynamic Bandwidth Scheduling Algorithm for Space Applications in FC-AE-1553 Switching Network. In Asia Communications and Photonics Conference; Optical Society of America: Washington, DC, USA, 2018; p. Su2A-54. [Google Scholar]
- Nalini, J.; Khilar, P. Reinforced Ant Colony Optimization for Fault Tolerant Task Allocation in Cloud Environments. Wirel. Pers. Commun. 2021, 1–19. [Google Scholar] [CrossRef]
- Tamilsenthil, S.; Kangaiammal, A. Chapman Kolmogorov and Jensen Shannon Ant Colony Optimization-Based Resource Efficient Task Scheduling in Cloud. In Inventive Systems and Control; Springer: Berlin/Heidelberg, Germany, 2021; pp. 911–926. [Google Scholar]
- Guangshun, L.; Jiping, W.; Junhua, W.; Jianrong, S. Data Processing Delay Optimization in Mobile Edge Computing. Wirel. Commun. Mob. Comput. 2018, 2018, 6897523. [Google Scholar]
- Zhang, X.; Shen, X.; Yu, Z. A Novel Hybrid Ant Colony Optimization for a Multicast Routing Problem. Algorithms 2019, 12, 18. [Google Scholar] [CrossRef] [Green Version]
- Shamsudin, H.; Yusof, U.K. Hybrid of Ant Colony Optimization-ANN for User Modeling System. Adv. Sci. Lett. 2018, 24, 1312–1315. [Google Scholar] [CrossRef]
- Luo, Z.; Zhao, X.; Xia, H. An ant colony algorithm and simulation for solving minimum MPR sets. CAAI Trans. Intell. Syst. 2011, 6, 166–171. [Google Scholar]
- Jung-Hyun, L.; Wang, S.M.; Chung, D.; Hee, K.K.; Jung, O. Multi-satellite control system architecture and mission scheduling optimization. In Proceedings of the IEEE Aerospace Conference, Big Sky, MT, USA, 3–10 March 2012. [Google Scholar]
- Nandagopal, T.; Puttaswamy, K.P. Lowering Inter-datacenter Bandwidth Costs via Bulk Data Scheduling. In Proceedings of the 2012 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (ccgrid 2012), Ottawa, ON, Canada, 13–16 May 2012. [Google Scholar]
- Liu, M.; Zhang, X.; Ling, L. Hybrid heuristic algorithm for multi-objective scheduling problem. J. Syst. Eng. Electron. 2019, 30, 327–342. [Google Scholar]
- Fox, K.; Im, S.; Moseley, B. Energy efficient scheduling of parallelizable jobs. Theor. Comput. Sci. 2018, 726, 30–40. [Google Scholar] [CrossRef]
- Jo, S.J.; Na, K.S.; Park, J.E.; Lee, M.S. Decision Making Regarding Key Elements of Korean Disaster Psychiatric Assistance Teams Using the Analytic Hierarchy Process. Psychiatry Investig. 2018, 15, 663–669. [Google Scholar] [CrossRef] [PubMed]
- Patel, G.; Mehta, R.; Bhoi, U. Enhanced Load Balanced Min-min Algorithm for Static Meta Task Scheduling in Cloud Computing. Procedia Comput. Sci. 2015, 57, 545–553. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Qi, Z.; Jiang, L.; Zhang, C.; Xu, J. A Multi-objective Ant Colony Optimization Algorithm with Local Optimum Avoidance Strategy. In Machine Learning for Cyber Security; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Castaing, J. Scheduling Downloads for Multi-Satellite, Multi-Ground Station Missions. Small Satell. Conf. 2014, 8, 33–45. [Google Scholar]









{kind=link}
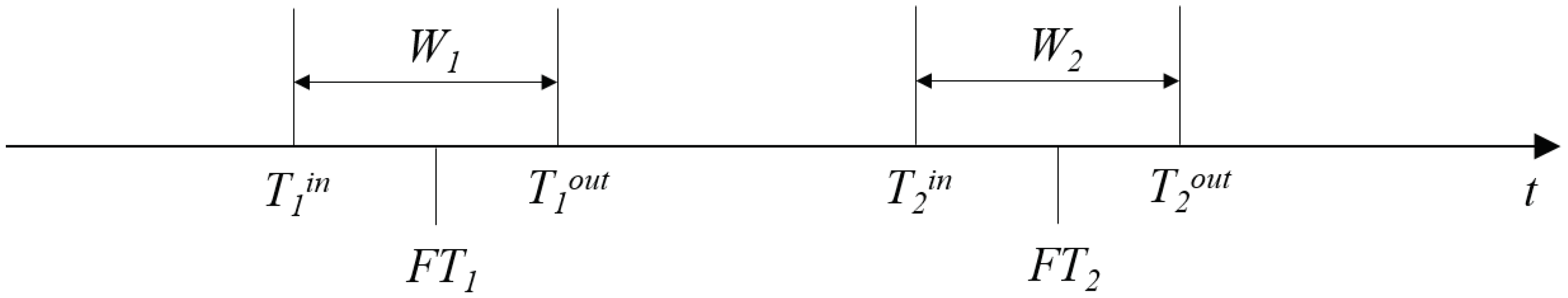{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| SS = { ,,…, } | Collection of source nodes. |
| RS = { ,,…, } | Collection of relay nodes. represents CPU, memory, hard disk and bandwidth. |
| = { } | The k-th visible time window of the i-th source node and the j-th relay node. During time window, data can be transmitted between these two nodes, is the length of time window, which is represented by [,]. |
| GS = { ,,… } | Collection of center cloud platform. |
| = { } | Data transmission tasks of the i-th node. represents task priority, data size and transmission link status (downlink relay link is 1 and uplink relay link is 0). |
| V = { , , , } | Scheduling decision variables. is bool type, and represents can be allocated; and represent the time of start and end of transmission; represents the constraint from i to j. |
| Number | Start | End |
|---|---|---|
| 1 | 04:01 | 04:58 |
| 2 | 07:15 | 08:17 |
| 3 | 13:03 | 14:06 |
| 4 | 16:21 | 17:20 |
| 5 | 19:35 | 20:38 |
| Methods | Description |
|---|---|
| DT [19] | It directly transmits data by time window betweensource and target in downlink relay link. |
| ABC [4] | It uses artificial bee colony algorithm for datatransmission in downlink relay link. |
| SAF [20] | Our proposed approach in downlink relay link.It isbased on store and forward. |
| SOP [26] | It just includes the optimization of each link withoverall optimization. |
| ACTS | Our proposed approach for overall transmission. |
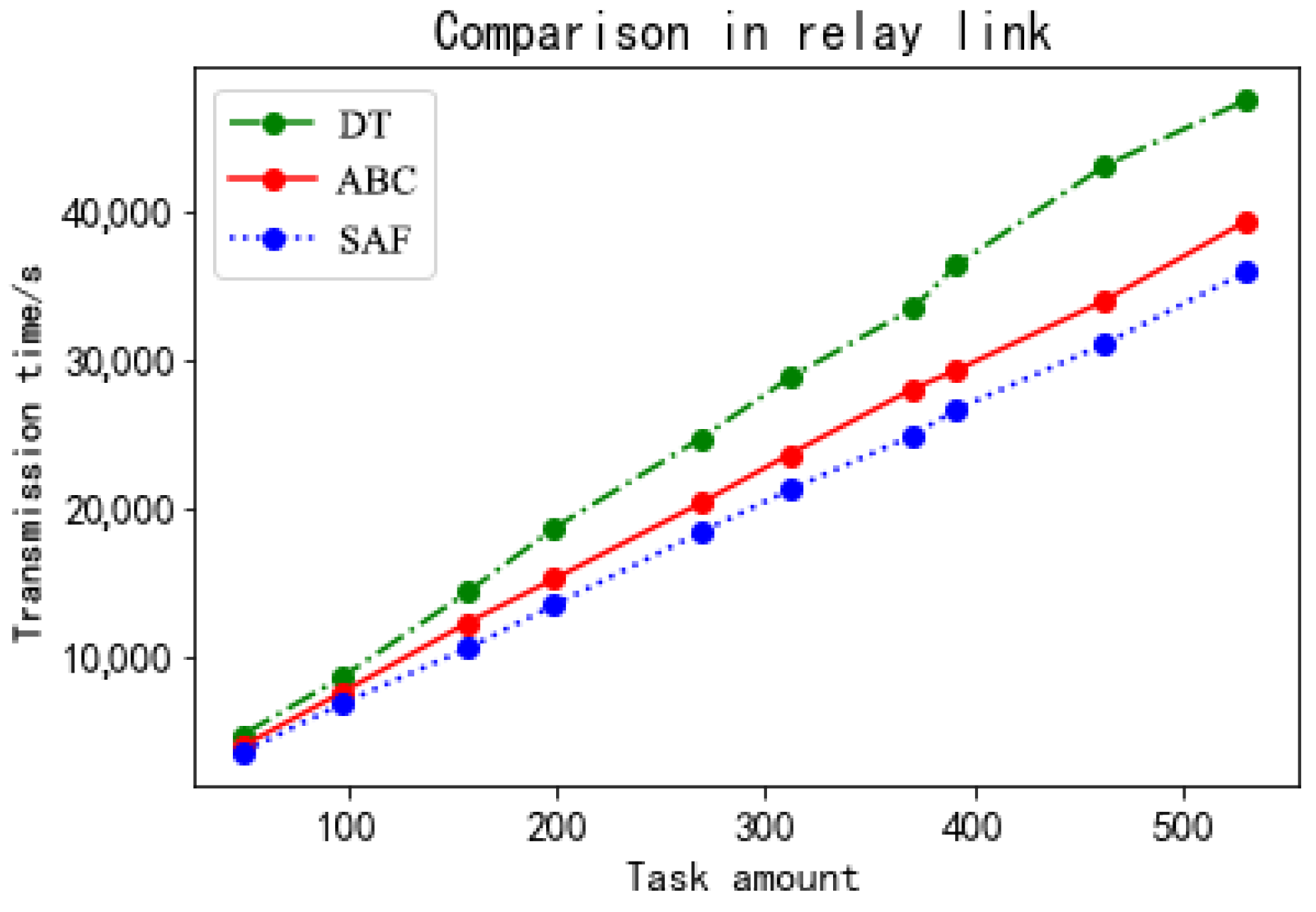
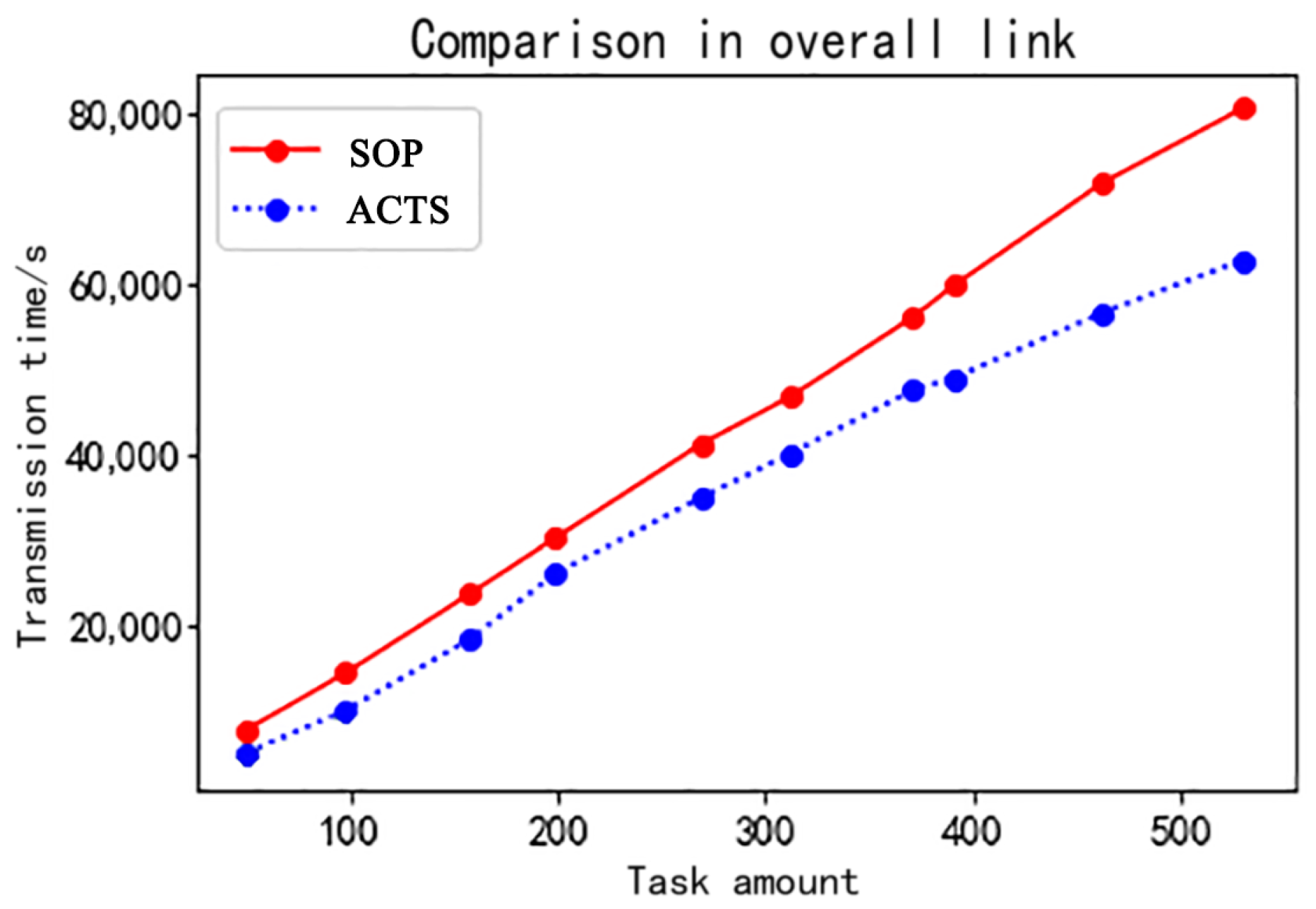
| Number | Task Amount | Transmission Time in Downlink Relay Link | Transmission Time in Overall Link | /% | |||
|---|---|---|---|---|---|---|---|
| DT/s | ABC/s | SAF/s | SOP/s | ACTS/s | |||
| 1 | 50 | 4636 | 3884 | 3479 | 7745 | 5019 | 35.2 |
| 2 | 98 | 8572 | 7536 | 6771 | 14,442 | 10,037 | 30.5 |
| 3 | 158 | 14,304 | 12,233 | 10,504 | 23,744 | 18,401 | 22.5 |
| 4 | 199 | 18,590 | 15,155 | 13,395 | 30,265 | 26,058 | 13.9 |
| 5 | 269 | 24,619 | 20,260 | 18,301 | 41,256 | 34,944 | 15.3 |
| 6 | 312 | 28,762 | 23,593 | 21,186 | 46,807 | 40,114 | 14.3 |
| 7 | 371 | 33,433 | 28,008 | 24,868 | 56,137 | 47,548 | 15.3 |
| 8 | 391 | 36,294 | 29,211 | 26,571 | 59,904 | 49,001 | 18.2 |
| 9 | 462 | 42,998 | 33,914 | 30,985 | 71,842 | 56,611 | 21.2 |
| 10 | 530 | 47,461 | 39,294 | 35,877 | 80,626 | 62,808 | 22.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, R.; Zhang, P.; Xie, L.; Ai, Y.; Xu, P. ACTS: An Ant Colony Based Transmission Scheduling Approach for Cloud Network Collaboration Environment. Symmetry 2021, 13, 2109. https://doi.org/10.3390/sym13112109
Cheng R, Zhang P, Xie L, Ai Y, Xu P. ACTS: An Ant Colony Based Transmission Scheduling Approach for Cloud Network Collaboration Environment. Symmetry. 2021; 13(11):2109. https://doi.org/10.3390/sym13112109
Chicago/Turabian StyleCheng, Ruiying, Pan Zhang, Lei Xie, Yongqi Ai, and Peng Xu. 2021. "ACTS: An Ant Colony Based Transmission Scheduling Approach for Cloud Network Collaboration Environment" Symmetry 13, no. 11: 2109. https://doi.org/10.3390/sym13112109