1. Introduction
Consider an square contingency table that has the same row and column classifications with nominal categories. Let denote the probability that an observation will fall in the ith row and jth column of the table ().
The symmetry (S) model proposed by Bowker [
1] is defined by
This S model is the most commonly used model for analyzing square contingency tables [
2,
3,
4].
The point symmetry (PS) model proposed by Wall and Lienert [
5] is defined by
where
and
. This PS model assumes the point of symmetry as a center of the square contingency table.
The double symmetry (DS) model proposed by Tomizawa [
6] is defined by
This DS model indicates that both the S and PS model hold.
When a model does not hold, we may be interested in measuring the degree of deviation from the model. For square contingency tables with nominal categories, Tomizawa et al. [
7] proposed an index
that represents the degree of deviation from the S model, Tomizawa et al. [
8] proposed an index
that represents the degree of deviation from the PS model, and Yamamoto et al. [
9] proposed an index
that represents the degree of deviation from the DS model.
This study focuses on the index that represents the degree of deviation from the DS model. Although the DS model satisfies both the S and PS models simultaneously, the above index
cannot concurrently measure the degree of deviation from S and PS. To address this gap, Ando et al. [
10] proposed a two-dimensional index that can concurrently measure those. This two-dimensional index was constructed by combining existing indexes
and
. Ando et al. [
10] points out that it is necessary to construct as a two-dimensional index rather than a univariate index because existing indexes
and
are not independent. Ando et al. [
10] considered three datasets: (1) the degree of deviation from the S model is large but the degree of deviation from the PS model is small, (2) the degree of deviation from the S model is small but the degree of deviation from the PS model is large, and (3) both the degree of deviation from the S model and the PS model are large. By using these datasets which have a different structure with respect to the deviation from the DS model, Ando et al. [
10] showed that the all values of the index
applied to these datasets are the same, whereas all the values of the two-dimensional index are different. Thus, this two-dimensional index gives more detailed results than the index
.
On the other hand, existing indexes
,
and
are constructed using power divergence, while the two-dimensional index is constructed using only Kullback-Leibler information, which is a special case of power divergence. Moreover, the power divergence includes several divergences, for example, the power divergence with
is equivalent to the Freeman-Tukey type divergence, the power divergence with
is equivalent to the Pearson chi-squared type divergence. For details on power divergence, see Cressie and Read [
11], Read and Cressie [
12]. Previous studies (e.g., [
7,
8]) pointed out that it is important to use several indexes of divergence to accurately measure the degree of deviation from a model. This study proposes a two-dimensional index that is constructed by combining existing indexes
and
based on power divergence.
The rest of this paper is organized as follows. In
Section 2, we propose a generalized two-dimensional index for measuring the degree of deviation from DS. In
Section 3, we develop an approximate confidence region for the proposed two-dimensional index. We then use numerical examples to show the utility of the proposed two-dimensional index in
Section 4. We also present results obtained by applying the proposed two-dimensional index to real data. We close with concluding remarks in
Section 5.
2. Two-Dimensional Index to Measure Deviation from DS
We propose a generalized two-dimensional index for measuring deviation from DS in square contingency tables. The proposed two-dimensional index can concurrently measure the degree of deviation from S and PS. The proposed two-dimensional index is based on power divergence.
Assume that
for all
, and
for all
, where
In order to measure the degree of deviation from DS, we consider the following two-dimensional index:
where indexes
and
are those considered by Tomizawa et al. [
7] and Tomizawa et al. [
8], respectively (see the
Appendix A and
Appendix B for the details of these indexes). Note that the
is a real value and is chosen by the user. We recommend choosing the
(e.g.,
) corresponding to the famous divergence. When
, the proposed two-dimensional index is equivalent to the index by Ando et al. [
10]. Thus,
is a generalization of the index by Ando et al. [
10]. The two-dimensional index
has the following characteristics: (i)
if and only if the DS model holds; (ii)
if and only if the degree of deviation from DS is maximum, in the sense that
(then
and
) or
(then
and
) for all
, and either
or
for
(when
r is even) or
(when
r is odd); (iii)
if and only if the degree of deviation from S is maximum and the degree of deviation from PS is not maximum, in the sense that
(then
) for all
; and (iv)
if and only if the degree of deviation from PS is maximum and the degree of deviation from S is not maximum, in the sense that
(then
) for all
.
3. Approximate Confidence Region for the Proposed Two-Dimensional Index
Assume that
has a multinomial distribution with sample size
N and probability vector
. The
has an asymptotically Gaussian distribution with mean zero and covariance matrix
, where
=
and
is a diagonal matrix with the elements of
on the main diagonal (see, e.g., Agresti [
13]). We estimate
by
, where
and
are given by
and
with
replaced by
, respectively. Using the delta method (see Agresti [
13]),
has an asymptotically bivariate Gaussian distribution with mean zero and covariance matrix
with
=
. Let
The elements
,
, and
are expressed as follows:
where for
with
Note that the asymptotic variances
and
of
and
, respectively, have been given by Tomizawa et al. [
7] and Tomizawa et al. [
8], however, the asymptotic covariance
of
and
is first derived in this study. An approximate bivariate
confidence region for the index
is given by
where
is the upper
percentile of the central chi-square distribution with two degrees of freedom and
is given by
with
replaced by
.
5. Concluding Remarks
This study proposed a generalized two-dimensional index that concurrently measures the degree of deviation from S and PS. Since the two indexes ( and ) were used to measure the degree of deviation from S and PS are not independent (), it is necessary to concurrently measure the degree of deviation from S and PS when we measure the degree of deviation from DS. To compare degrees of deviation from DS in several datasets using the proposed two-dimensional index, we should use several rather than one specified . Therefore, we recommend to choose the several (e.g., ) corresponding to the famous divergence.
The estimator of the proposed two-dimensional index is the unbiased estimator when the sample size is large. When the sample size is small, however, the estimator of the proposed two-dimensional index may be the biased estimator. Through simulation study, Tomizawa et al. [
16] investigated the performance of the estimator
. Tomizawa et al. [
16] showed that (1) when the sample size was less than 300, the estimator
had a bias, (2) when the sample size was above 300, it had a slight bias, and (3) when the sample size was above 1000, it had almost no bias. We believe that the proposed two-dimensional estimator
may be similar results to the estimator
, although it is necessary to verify by simulation study. In future research, the above concern will be investigated.







{kind=link}
{kind=link}
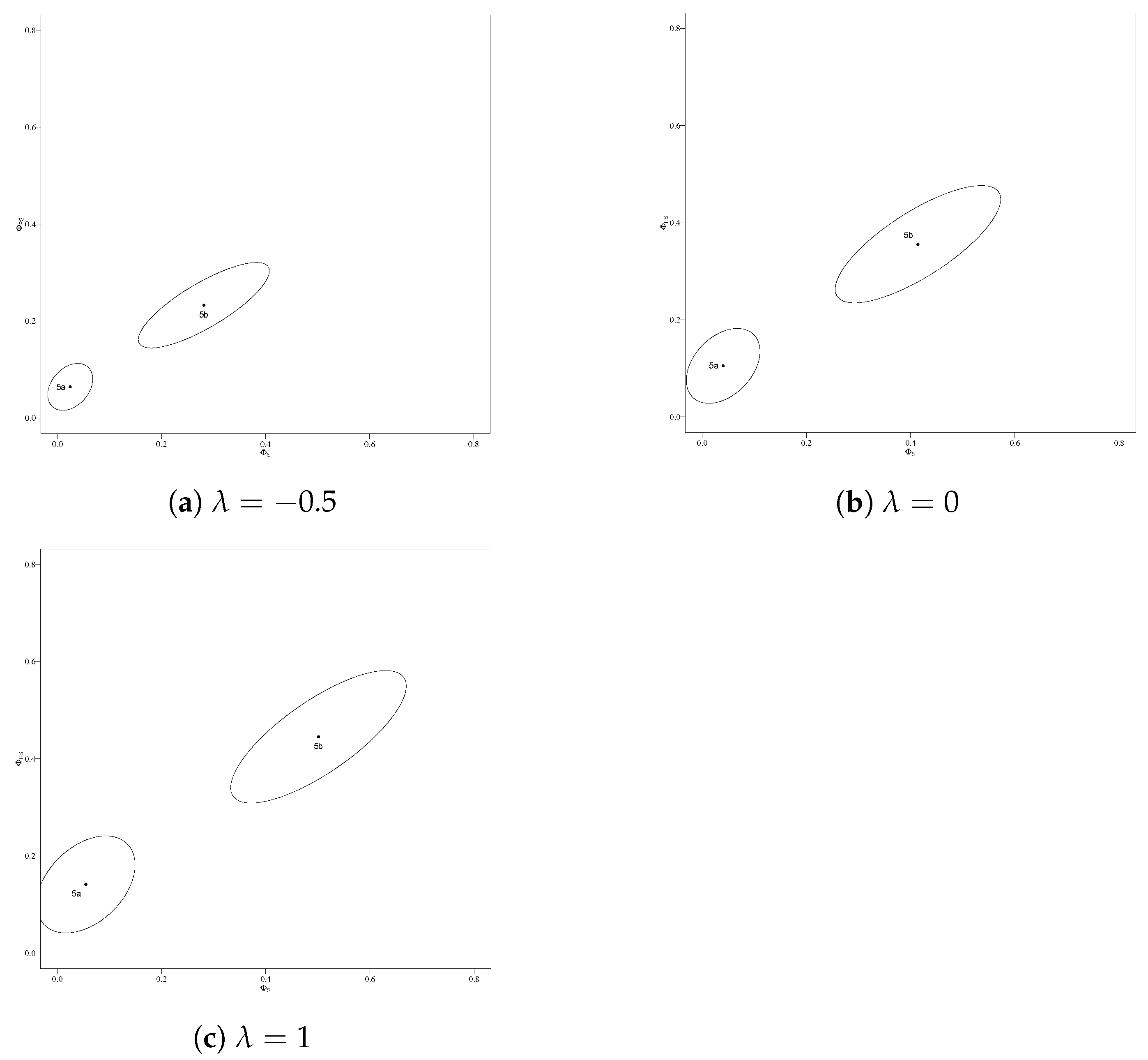{kind=link}