The goal of the experiment is to compare the quality of three stochastic methods in searching for optimal preference values of characteristic objects at different initial states. The initial state in the study determines the initial preference values of characteristic objects. The selected methods for the experiment are the hill-climbing algorithm, the simulated annealing method, and particle swarm optimization. Several particles in the PSO method have been set to 20, while parameters , , have been given values of 0.5, 0.3, and 0.9, respectively. The maximum number of iterations in each method has been set to 1000. Preference of characteristic objects has been determined using a set of alternatives. A set of alternatives determined the preference of characteristic objects.
The study was conducted with four initial state variants. The characteristic objects assumed a preference value equal to 0, 0.5, 1, or a random value.
3.1. Impact of the Initial Conditions
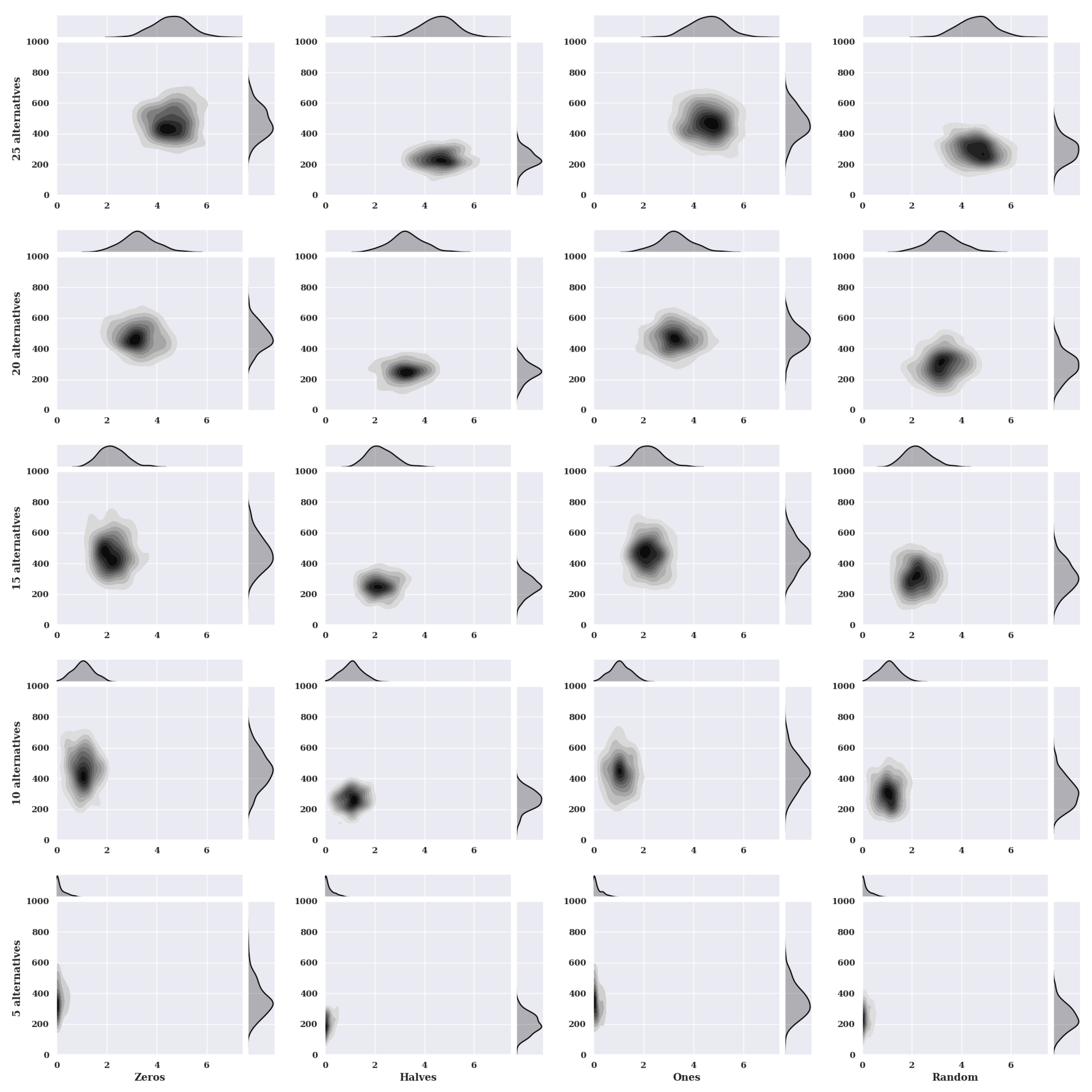
Figure 2 presents heat maps with nuclear density estimators for a hill-climbing algorithm for a static variant of criteria with a non-existent model, i.e., one in which the preferences of the alternatives were selected randomly. The charts show the solutions found about the number of iterations for the given number of alternatives in the set and the initial state variants.
For an increasing number of alternatives for characteristic objects assuming the value of preference 0 at the beginning, one can see an increase in the value of found solutions. The accuracy of the five alternatives in the set is high because the concentration of the smallest found values of the fitness function is close to the value of 0. The largest number of solutions found was between 300 and 500 iterations. With more alternatives, the number of iterations in which solutions have been found slightly increases. However, the values of the solutions were found to increase significantly. For the ten alternatives, the highest concentration of the smallest found fitness values oscillates between [1, 1.5]. For fifteen alternatives [2, 2.35], twenty alternatives [2.9, 3.1], and for twenty five alternatives [4.5, 5].
The initial state in which the preference of characteristic objects is set to 0.5 does not reach as large values in the range of the number of iterations needed to find a solution as in the initial state for the value 0. This range is [175, 280]. The clusters of solutions found about their costs are slightly different from the initial state for the value 0.
In the initial state, where characteristic objects take preference values equal to 1, the distribution of found solutions is much larger than in the case where the initial state value is 0.5. The most massive clusters of found solutions occur between iterations 390 and 500.
For a randomly selected preference value of the characteristic objects, the number of iterations needed to find a solution is much smaller than when the initial state takes a preference value of 0 or 1. However, compared with the initial state where the characteristic objects take a preference value of 0.5, the initial state with a random value is worse due to the density nuclear estimator. It shows that the method needed more iteration when estimating some of the smallest fitness function values.
Thermal maps, together with nuclear density estimators for a hill-climbing algorithm for a dynamic variant of criteria with a non-existent model, are presented using
Figure 3. Solutions found about the number of iterations for the given number of alternatives in the set and variants of the initial state are presented in the charts.
For characteristic objects taking at the beginning the value of preference 0 for an increasing number of alternatives, you can see an increase in the value of found solutions. For a set consisting of five alternatives, the concentration of the smallest found values of the fitness function is close to 0, which means that the accuracy is high. However, as the number of alternatives increases, the accuracy decreases. For the ten alternatives, the highest concentration of the smallest found fitness values is in the range [1.5, 1.6]. For fifteen alternatives [1.9, 2.2], twenty alternatives [3.1] and for twenty five alternatives [4.1, 4.9]. Most of the solutions found for 10, 15, 20, 25 alternatives were between 400 and 500 iterations. The exception is a set consisting of five alternatives in which most of the solutions were found before the 400 iterations. With more alternatives, the number of iterations in which solutions were found slightly increases. The value of the solutions found increases significantly.
The initial state where the preference of the characteristic objects is set to 0.5 does not reach as high values in the range of the number of iterations needed to find a solution as the preference of the characteristic objects is 0. This range is approximately [190, 280]. The clusters of solutions found about their values differ slightly from the initial state for 0.
In the initial state where the characteristic objects take values of 1, the distribution of solutions found is higher than for the initial state value of 0.5. The most significant clusters of solutions found occur between iterations 400 and 500. Compared with the initial state where the characteristic objects take a preference value of 0, the differences are slight.
The number of iterations needed to find a solution for a randomly selected preference value of the characteristic objects is much smaller than when the initial state takes a preference value of 0 or 1. However, compared with the initial state where the characteristic objects take a preference value of 0.5, the initial state with a random value is worse due to the nuclear density estimator. It shows that the method needed more iteration when estimating some of the smallest fitness function values.
Figure 4 shows thermal maps together with nuclear density estimators for a hill-climbing algorithm for a static variant of criteria with an existing model. A current model means a model in which the preferences of alternatives have been calculated using a randomly selected vector
. The individual charts show the solutions found concerning iteration numbers for the given alternatives and initial state variants.
For a start preference of characteristic objects of 0, the change in the value of found solutions with an increase in the number of alternatives is not substantial. The hill-climbing algorithm usually finds a solution between 400 and 600 iterations. However, the solutions found are in the range [0, 0.2], which indicates very high accuracy.
However, a better solution seems to be the starting value of the preference of characteristic objects of 0.5. This variant needs less iteration than finding solutions, and their cost is lower.
However, this cannot be said about the variant where the characteristic objects take a preference value of 1. The distribution of the values of the solutions found is much greater than in the case of the start preference value of 0. An example of this is ten alternatives where the cloud is more extensive when the start state has a value of 1 than when it takes the amount of 0.
In the initial state, where characteristic objects take random preference values, the number of iterations needed to find a solution is much smaller than for the initial state values of 0 and 1. However, the costs of solutions are much higher than for the initial state with a value of 0.5. The increase in the number of iterations compared to the number of alternatives is not so large.
Figure 5 shows thermal maps together with nuclear density estimators for a hill-climbing algorithm for a dynamic variant of criteria with an existing model. The individual charts show the solutions found concerning iteration numbers for the given alternatives and initial state variants.
In the case of a starting preference of characteristic objects of 0, the change in the value of found solutions decreases with the number of alternatives. The hill-climbing algorithm usually finds a solution between 400 and 600 iterations. Solutions found for five alternatives are in the range [0, 0.05], for ten and fifteen [0, 0.2], for twenty and twenty-five [0, 0.1], which indicates very high accuracy.
However, the starting value of the characteristic object preference of 0.5 seems to be a better solution. This option needs less iteration than finding solutions, and its cost is lower.
The variant in which the characteristic objects take the initial preference value of 1 needs more iterations to find solutions than for the start value of 0.5. The distribution of found solutions is much higher than for the start value of 0. An example is ten alternatives where the cloud is more extensive when the start state has the benefit of 1 than when it takes the amount of 0.
In the initial state where the characteristic objects take random preference values, the number of iterations needed to find a solution is much smaller than for the initial state values of 0 and 1. However, the costs of solutions are much higher than for the initial state with a value of 0.5. The increase in the number of iterations compared to the number of alternatives is not so large.
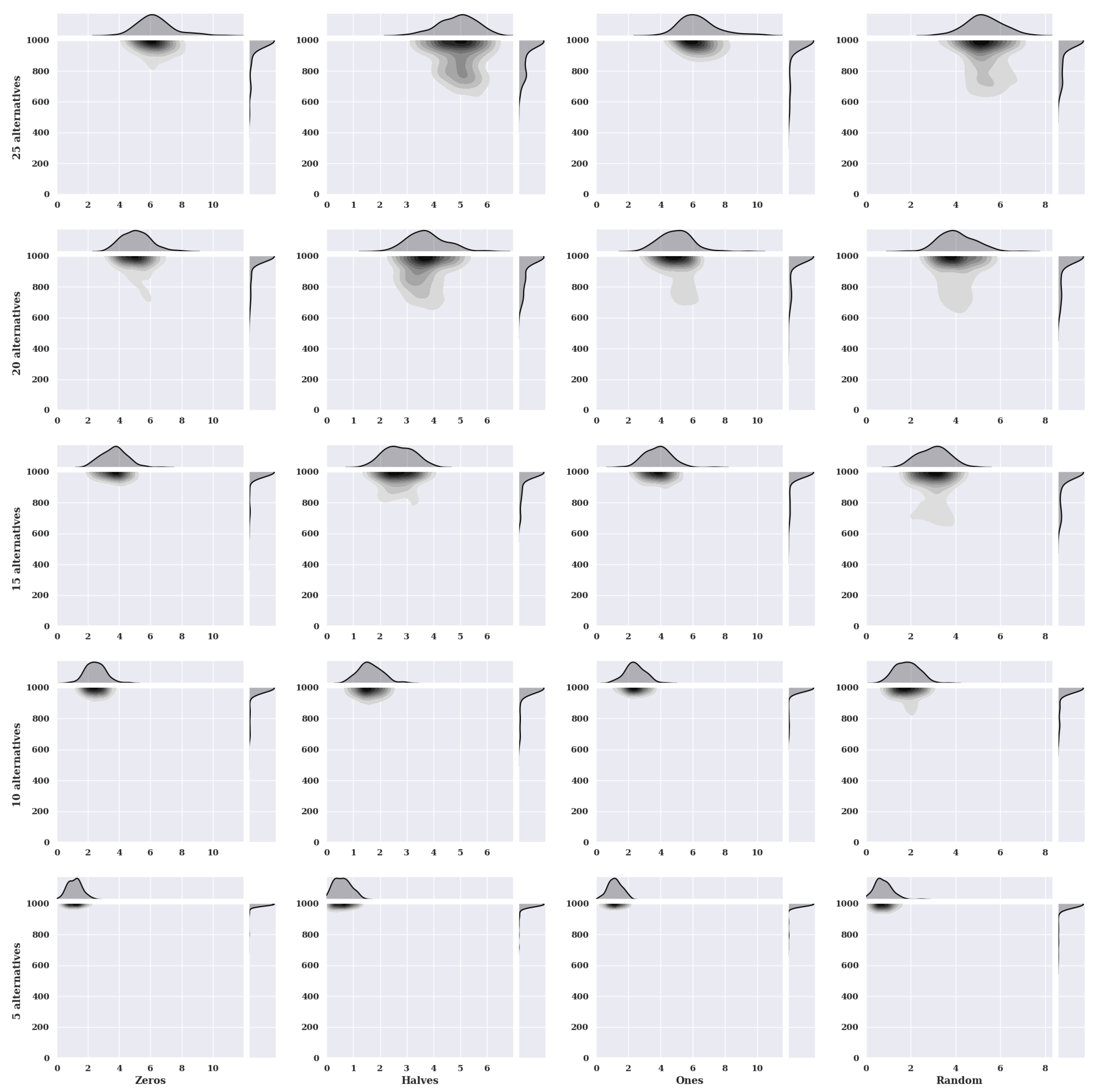
Figure 6 presents thermal maps with density nuclear estimators for simulated annealing method for a static variant of criteria with a non-existent model. The charts show the solutions found about the number of iterations for the given number of alternatives in the set and the initial state variants.
For an increasing number of alternatives for characteristic objects assuming the value of preference 0 at the beginning, one can see an increase in the value of found solutions. The accuracy of the five alternatives in the set is high because the concentration of the smallest found values of the fitness function is close to 0. Most of the solutions were found in 1000 iterations. With more alternatives, the number of iterations in which solutions were found slightly decreases. However, the values of the solutions were found to increase significantly. For the ten alternatives, the largest concentration of the smallest found fitness values is in the range [2, 3.1]. For fifteen alternatives [3, 4.1], twenty alternatives [4.05, 5.9], and for twenty-five alternatives [5.8, 6.2].
The initial state where the preference of the characteristic objects is set to 0.5 reaches as high values in the range of the number of iterations needed to find a solution as for the initial state for value 0. The clusters of found solution values differ significantly from the initial state for value 0 because they are smaller.
In the initial state, where characteristic objects take preference values equal to 1, the distribution of solutions found is much larger than in the case where the initial state value is 0.5. However, the number of iterations needed to find an answer is the same.
For a randomly selected preference value of the characteristic objects, the values of the solutions found are much smaller than when the initial state takes the value 0 or 1. However, compared with the initial state where the characteristic objects take the preference value 0.5, the initial state with a random value is worse due to the nuclear density estimator. It shows that the method has found smaller fitness function values.
Thermal maps, together with nuclear density estimators for the simulated annealing method for a dynamic variant of criteria with a non-existent model, are presented using
Figure 7. The solutions found about the number of iterations for the given number of alternatives in the set and variants of the initial state are presented in the charts.
For characteristic objects assuming at the beginning, the value of preference 0 for an increasing number of alternatives, an increase in the amount of found solutions can be observed. For a set consisting of five choices, the concentration of the smallest found importance of the fitness function is close to 0, which means that the accuracy is high. However, as the number of alternatives increases, the efficiency decreases. For the ten alternatives, the highest concentration of the smallest found fitness values is in the range [2, 3], for the fifteen options [3.8, 4], for twenty alternatives [4.1, 5.8], and the twenty-five alternatives [5.95, 6.8]. The most significant number of solutions found for all the considered number of other options was between 980 and 1000 iterations. With a more substantial amount of alternatives, the number of iterations in which solutions were found slightly decreases.
The initial state in which the preference of characteristic objects is set to 0.5 does not need as large numbers of iterations to find a solution as in the case of the preference of characteristic objects of 0. The values of found solutions for a given amount of alternatives are increasing, but they are not as large as for the initial state with value 0.
In the initial state, where characteristic objects take preference values equal to 1, the distribution of found solutions is higher than in the case where the value of the initial state is 0.5. A large concentration of found solutions occurs between the iteration 985 and 1000. Compared to the initial state where characteristic objects take preference values equal to 0, the differences are insignificant.
The iteration numbers needed to find a solution for a randomly selected preference value of the characteristic objects are approximately the same as when the initial state takes the value 0, 0.5, or 1. However, the values of the solutions found are much smaller than when the initial state takes the value 0 or 1. Compared to the initial state where the characteristic objects take the preference value 0.5, the initial state with a random value is worse due to the nuclear density estimator. It shows that the method has found smaller fitness function values.
Figure 8 shows thermal maps together with nuclear density estimators for the simulated annealing method for a static variant of criteria with an existing model. Individual charts show solutions found against iteration numbers for given alternatives and initial state variants.
For a starting preference of characteristic objects of 0, the value of found solutions increases with the number of alternatives. The simulated annealing method usually finds solutions between 990 and 1000 iterations. The accuracy is high for five alternatives because the solution values found are less than 1. However, the efficiency decreases as the number of alternatives increases, e.g., for 25 alternatives numbers, several solutions reach amounts greater than 4.
A better solution seems to be the starting value of the characteristic object preference of 0.5. The increase of the smallest found values of the fitness function is not as big as in the case of a starting state with a value of 0. The accuracy is also very high because, for all considered numbers of alternatives, most of the solution values are in the range [0, 1].
This cannot be said about the variant, where the characteristic objects take the preference value of 1. The distribution of the found solution values is much larger than in the case of the starter preference value of 0.5. An example is the 25 alternatives, where the solution values are in the range [2.1, 4] in case the starter state takes the amount of 1, while for the starter state with the cost of 0.5 they are in the range [0, 1].
The number of iterations needed to find a solution for a randomly selected preference value of the characteristic objects is approximately the same as when the initial state takes the amount 0, 0.5, or 1. However, the amounts of solutions found are much smaller than when the initial state takes the value 0 or 1. Compared to the initial state where the characteristic objects take the preference value 0.5, the initial state with a random value is worse due to the nuclear density estimator. It shows that the method has found smaller fitness function values.
Figure 9 shows thermal maps together with nuclear density estimators for the simulated annealing method for a dynamic variant of criteria with an existing model. Individual charts show solutions for a given number of alternatives and initial parameters.
For a starting preference of characteristic objects of 0, the values of found solutions increase with the number of alternatives. The simulated annealing method usually gets final solutions between 900 and 1000 iterations. Solutions found for five alternatives are in the range [0.2, 1.4], for ten [0.8, 2.1], for fifteen [1.85, 2.8], for twenty and twenty-five [2.2, 3.4]. This indicates a decrease in accuracy as the number of alternatives increases.
A better solution seems to be the starting value of characteristic objects’ preferences amounting to 0.5. This variant, with the increase in the number of alternatives, needs less iteration to find solutions, and its value is lower compared to the initial state with the amount of 0. A variant in which the characteristic objects take an initial preference value of 1 needs more iterations to find solutions than for a start value of 0.5. The distribution of the costs of solutions found is the same as for a start value of 0.
In the initial state where the characteristic objects take random preference values, the number of iterations needed to find a solution is much smaller than for the initial state values of 0 and 1. However, the costs of solutions are much higher than for the initial state of 0.5. The increase of iterations compared to the number of alternatives is not significant.
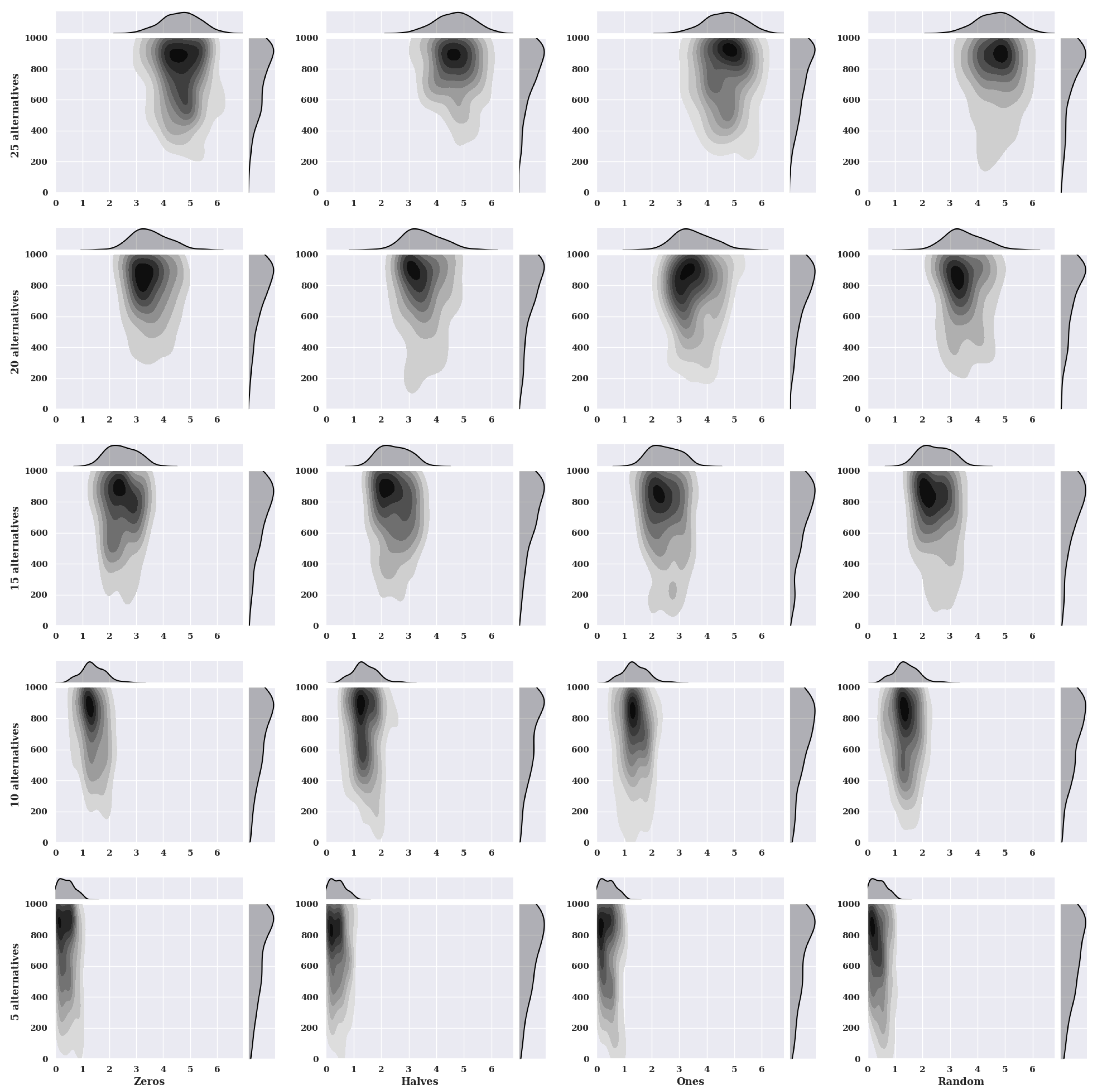
Figure 10 shows thermal maps with nuclear density estimators for particle swarm optimization for the static variant of criteria with the non-existent model. The charts show the solutions found about the number of iterations for the given number of alternatives in the set and the initial state variants.
For the increasing number of alternatives for characteristic objects assuming the value of preference 0 at the beginning, one can see an increase in the value of found solutions. The accuracy of the five alternatives in the set is high because the concentration of the smallest found values of the fitness function is in the range [0, 1]. The number of iterations increases with the number of alternatives in the set and the value of the solutions found. For the ten alternatives, the largest concentration of the smallest found fitness values is in the range [1, 1.9]. For fifteen alternatives [2, 3.15], twenty alternatives [2.95, 4], and for twenty five alternatives [4, 5.4].
The initial state where the preference of the characteristic objects is set to 0.5 reaches as high values in the range of the number of iterations needed to find a solution as for the initial state for value 0. The clusters of found solution values differ significantly from the initial state for value 0 because the solution values are smaller.
In the initial state, where characteristic objects take preference values equal to 1, the distribution of solutions found is slightly different from the case where the initial state value is 0.5. However, the number of iterations needed to find a solution, as the number of alternatives increases is smaller.
For a randomly selected preference value of characteristic objects, the number of iterations needed to find solutions and the costs of solutions increase with the number of alternatives. An example is a graph for twenty-five alternatives where a minority of solutions were found in 400 iterations, which cannot be said about the chart for five alternatives.
Thermal maps, together with nuclear density estimators for particle swarm optimization for a dynamic variant of criteria with a non-existent model, are presented in
Figure 11. Solutions found about the number of iterations for the given number of alternatives in the set and variants of the initial state are presented on the charts.
For characteristic objects assuming at the beginning, the value of preference 0 for an increasing number of alternatives, an increase in the value of found solutions can be observed. For a set consisting of five alternatives, the concentration of the smallest found values of the fitness function is close to 0, which means that the accuracy is high. However, as the number of alternatives increases, the accuracy decreases. For the ten alternatives, the highest concentration of the smallest fitness values found is in the range [1, 1.4].For the fifteen alternatives [1.9, 2.9], twenty alternatives [3.1, 3.85] and for the twenty-five alternatives [4.05, 5.1]. The largest number of solutions found for all the considered number of alternatives was between 800 and 1000 iterations. With a larger number of alternatives, the number of iterations in which solutions have been found increases.
The initial state in which the preference of characteristic objects is set to 0.5 for ten alternatives needs smaller numbers of iterations to find a solution than the initial state of 0.
In other cases, there are no statistically significant differences.
Figure 12 shows thermal maps together with nuclear density estimators for particle swarm optimization for a static variant of criteria with an existing model. The individual charts show the solutions found for iteration numbers for the given alternatives and initial state variants.
For a starting preference of characteristic objects of 0, the values of found solutions increase with the number of alternatives. Particle swarm optimization usually finds solutions between 600 and 1000 iterations. The accuracy is very high for all considered alternatives numbers because all solution values are less than 1.
A variant where the start value of the characteristic object preference is 0.5 performs worse for five alternatives than the start value of 0. The number of iterations that this variant achieves for the solution values found is much higher.
The variants in which the characteristic objects take the initial preference value of 1 and random are missing statistically significant differences.
Figure 13 shows thermal maps together with nuclear density estimators for particle swarm optimization for a dynamic variant of criteria with an existing model. The individual charts show the solutions found for iteration numbers for the given alternatives and initial state variants.
For a starting preference of characteristic objects of 0, the values of found solutions increase with the number of alternatives. Particle swarm optimization usually finds solutions between 600 and 1000 iterations. Solutions found for five alternatives are in the range [0, 0.05], for ten [0.15, 0.21], for fifteen [0.22, 0.38], for twenty [0.33, 0.42] and twenty-five [0.4, 0.6]. This indicates a small decrease in accuracy as the number of alternatives increases.
A better solution seems to be the starting value of characteristic objects’ preferences amounting to 0.5. In the case of sets consisting of 5 and 20 alternatives, the distribution of the found smallest values of the fitness function indicates lower values obtained than in the case of the initial state in which the characteristic objects’ preferences are 0. The variant that obtained the lowest values of solutions for 25 alternatives is the initial state with a value of 1. The highest concentration of solutions is close to 0.4, where for the initial state with a value of 0 and 0.5, the highest level was with an amount of solution 0.5.
For the initial state in which characteristic objects take a random preference value, there are no differences that would be statistically significant.
3.2. Fitness Function Distribution
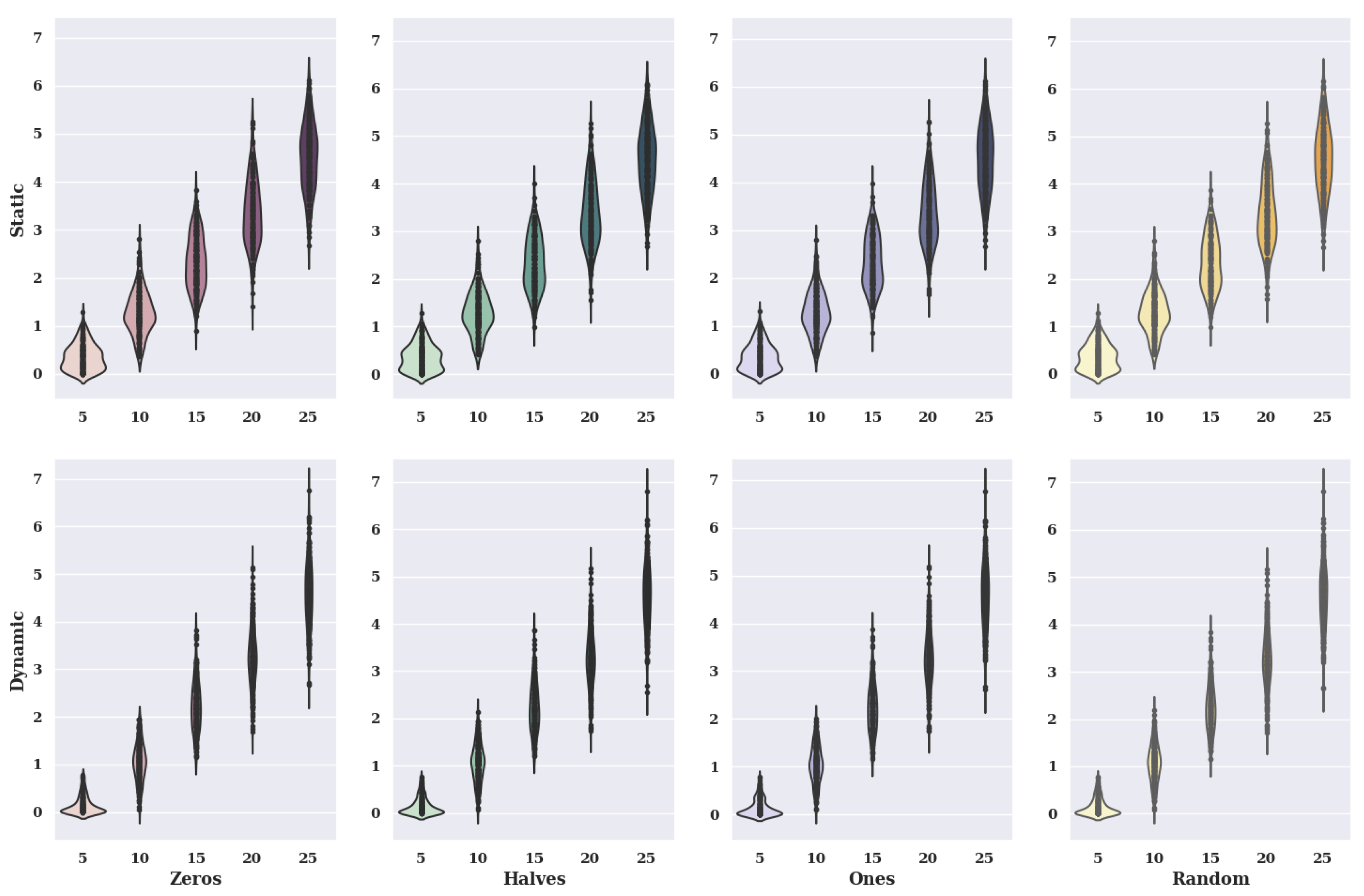
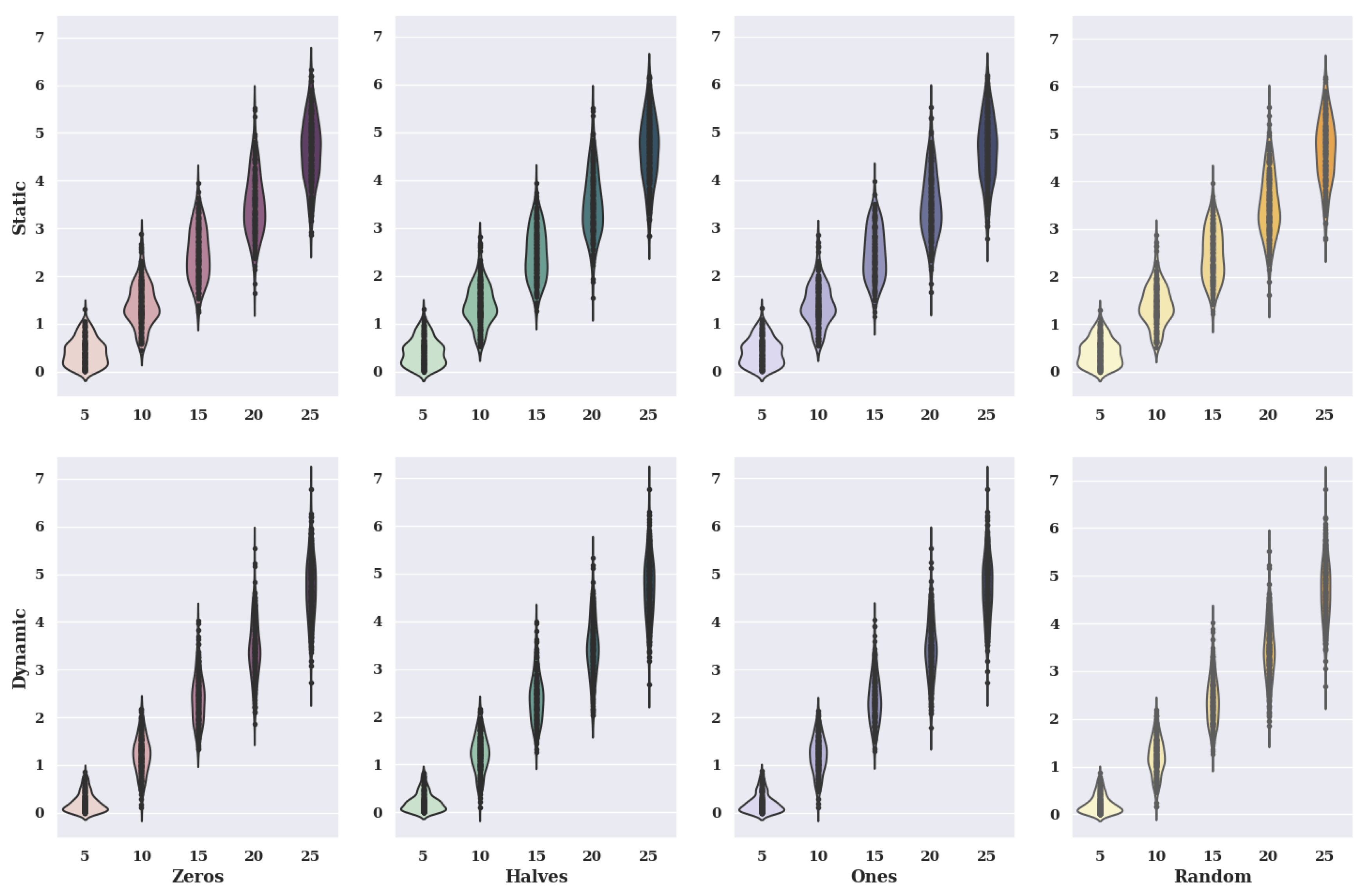
Figure 14 shows violin charts for a hill-climbing algorithm for a non-existent model. The graphs show variants of criteria and variants of initial states.
In the case of the charts for the initial state, in which the preferences of characteristic objects took the value of 0, the static value of criteria has smaller values of solutions than the dynamic value. Therefore, the size of the violin for a static case is much larger with small values of solutions. It is worth mentioning, however, that the data distribution for the five alternatives in the set for the dynamic case indicates that most of the smallest values of the fitness function obtained take values smaller than 0.2, which is a much better result than for the static variant.
For the initial state, where the preference of the characteristic objects took the value 0.5, 1, and random, the same relationship between the static values of the criteria and the dynamic values of the criteria occurs as for the initial state with the value 0.
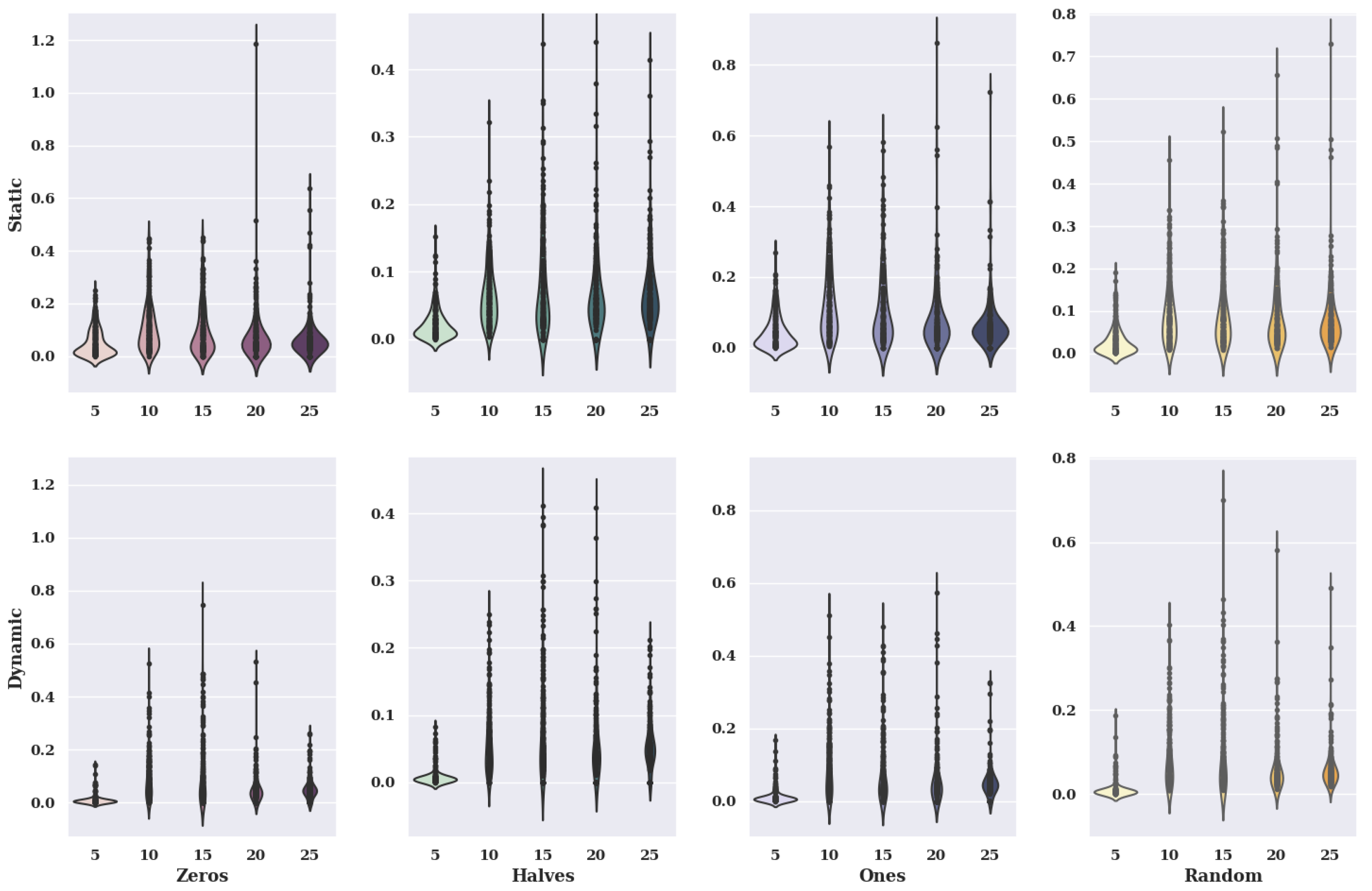
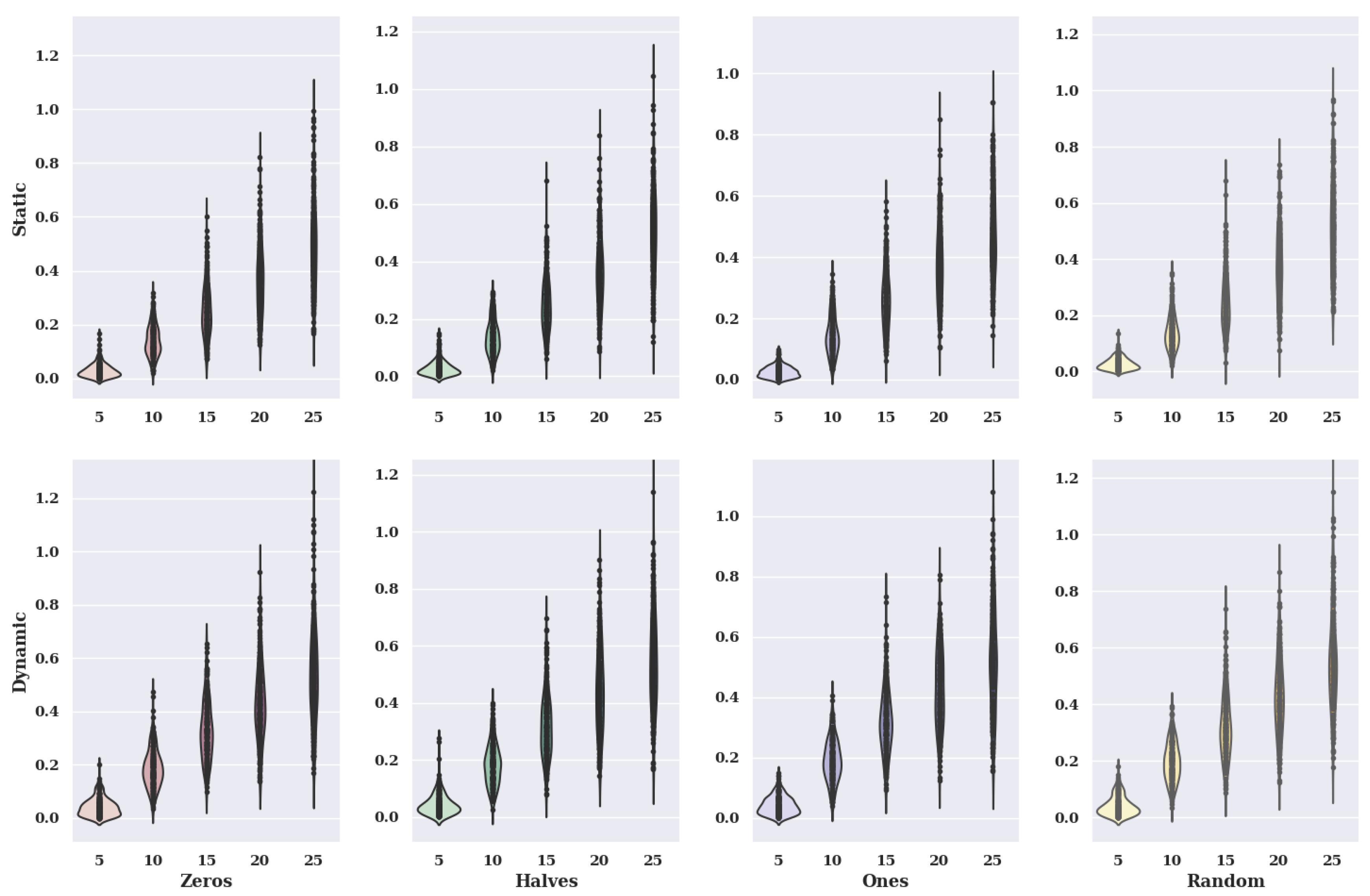
Figure 15 shows fiddle charts for the hill-climbing algorithm for an existing model. The charts show variants of criteria and variants of initial states.
In the case of the charts for the initial state, in which the preferences of characteristic objects took the value of 0, the static value of criteria has smaller values of solutions than the dynamic value. Therefore, the size of the violin for a static case is much larger with small values of solutions. It is worth mentioning, however, that the data distribution for the five alternatives in the set for the dynamic case indicates that most of the smallest values of the fitness function obtained take values smaller than 0.1, which is a much better result than for the static variant. However, the static variant has higher maximum found values for twenty and twenty-five alternatives than the dynamic variant.
For the initial state, where the preference of the characteristic objects takes the value of 0.5, the values of the solutions are lower than for the initial state, where the criteria are chosen statically, the accuracy is very high. In contrast, for the dynamic criteria variant, it is much lower. Many solutions in the static variant were found in the range [0, 0.1], which cannot be said for the dynamic variant. On the other hand, the static variant of criteria has much higher maximum values of solutions found for all the considered number of alternatives than the dynamic variant.
For initial state values equal to 1, the static variant of criteria takes smaller values of solutions than the static variant. The distribution of solutions found is similar for the distribution of the initial state variant with a value of 0. However, the found values of solutions are more significant than for the initial state in which the characteristic objects take preference values of 0.5.
In the case of graphs for the initial state where the preference of the characteristic objects took a random value, the static value of the criteria has smaller values of solutions than the dynamic value. The accuracy decreases with the increase of the number of alternatives in the set in the case of the static criteria variant.
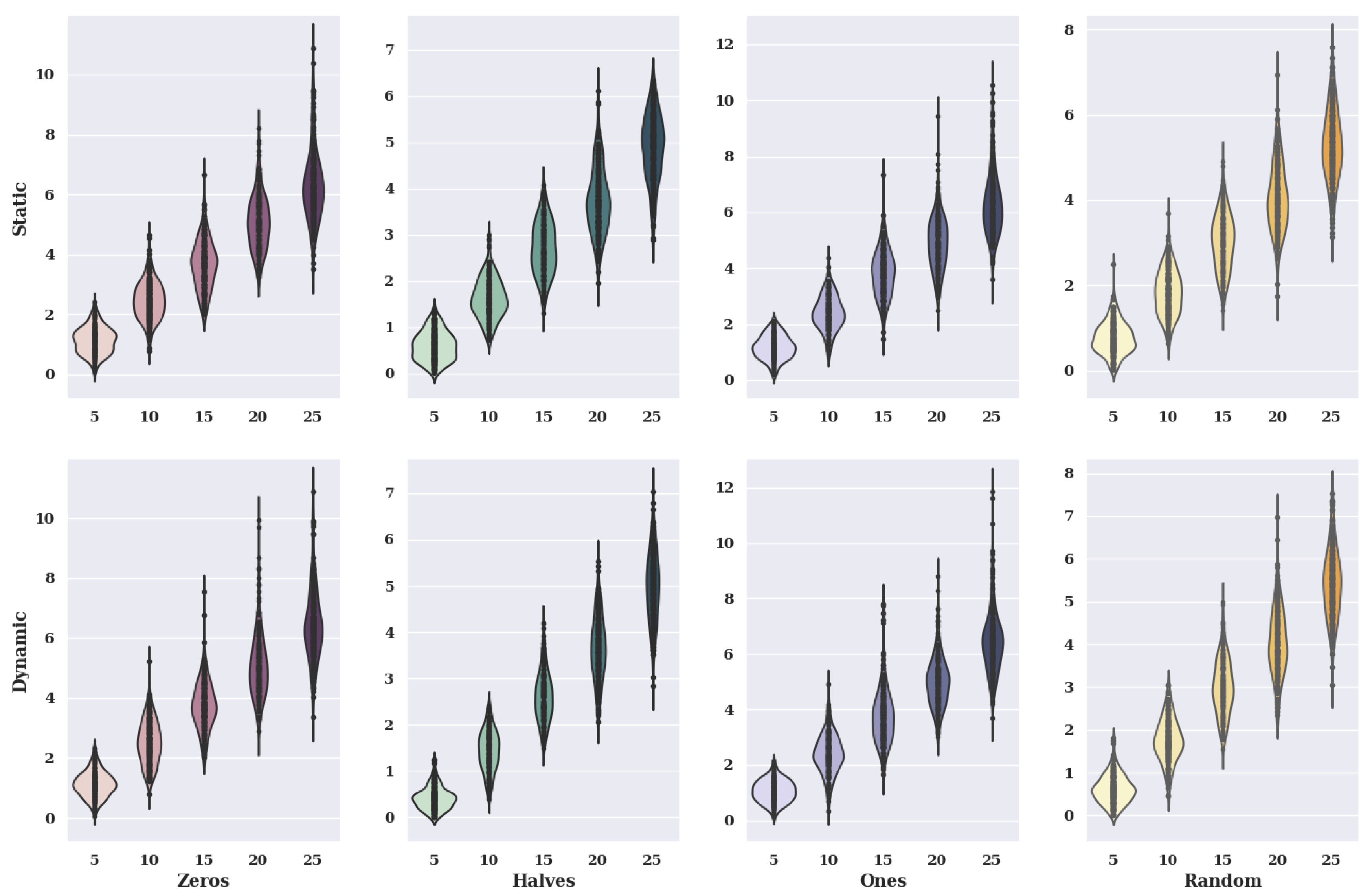
Figure 16 shows violin charts for the simulated annealing method for a non-existent model. The charts show variants of criteria and variants of initial states.
In the case of charts for the initial state, in which the preferences of characteristic objects took the value of 0, the static value of criteria has smaller values of solutions than the dynamic value. Therefore, the size of the violin for a static case is much larger with small values of solutions.
For the initial state, where the preference of the characteristic objects has taken the value of 0.5, the values of the solutions are smaller than when the initial state takes the value of 0. When the criteria are chosen statically, the accuracy is very high, while for the dynamic criteria variant, it is much lower. Moreover, the dynamic criteria variant has much higher maximum solution values found for 5, 15, and 25 alternatives than the static variant. For an initial state value of 1, the static variant of criteria has similar distributions of solution values as the dynamic variant due to its violin appearance. However, the most significant solution values found vary considerably.
In the case of the graphs for the initial state, in which the preferences of characteristic objects took a random value, there are no statistically significant differences between the static variant and the dynamic variant of the criteria.
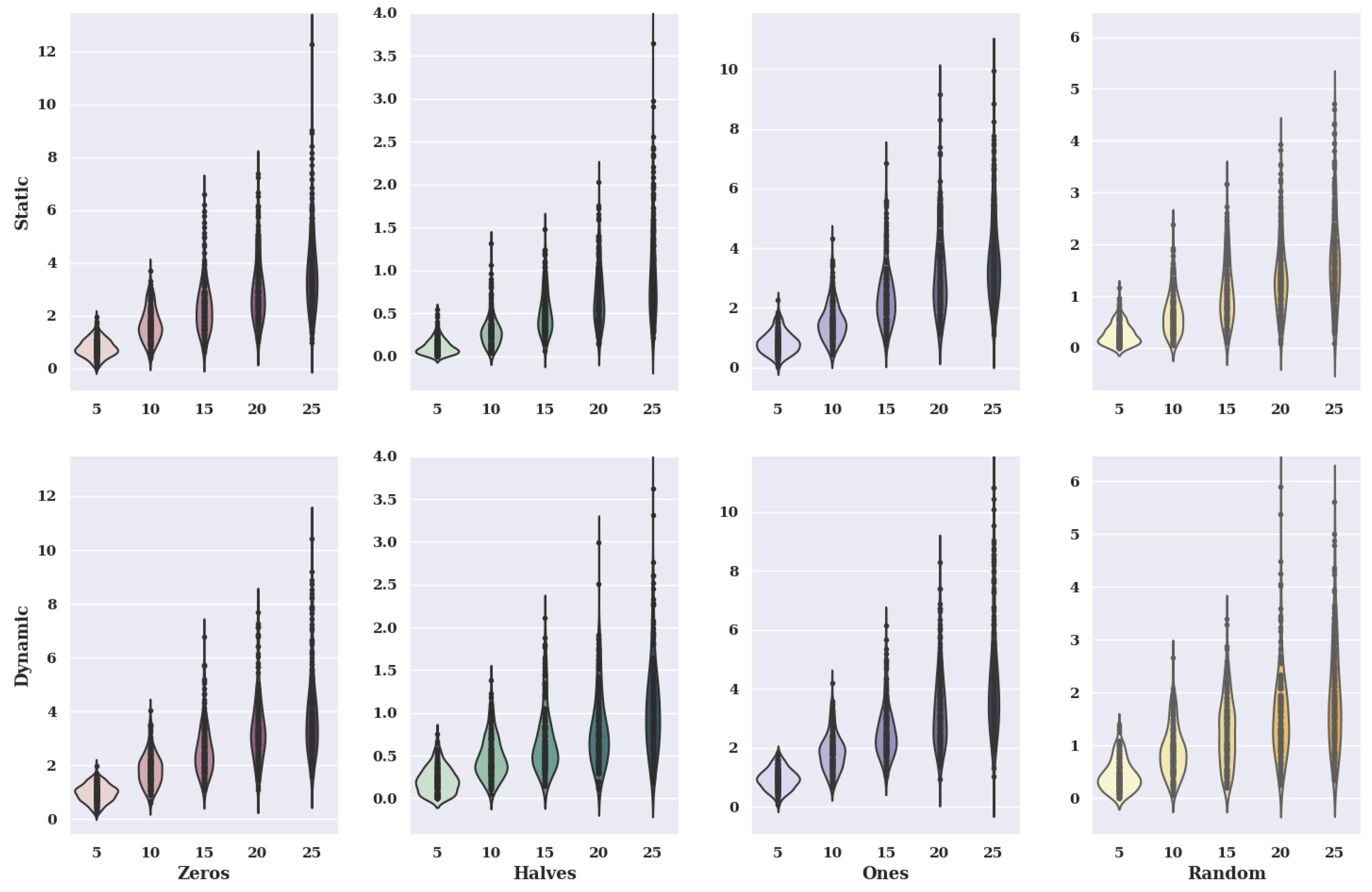
Figure 17 shows violin charts for the simulated annealing method for an existing model. The graphs show variants of criteria and options of initial states.
In the case of the charts for the initial state, in which the preferences of characteristic objects took the value 0, the static value of criteria has similar amounts of solutions as the dynamic value. The accuracy in both variants of criteria selection decreases with the increase in the number of alternatives.
For the initial state where the preference of the characteristic objects has assumed the value of 0.5, the amounts of the solutions are smaller than when the initial state assumes the cost of 0. This is indicated by the size of the violin, which is significantly higher when the initial value of the preference of the characteristic objects is 0.5. When criteria are selected dynamically, the accuracy is very high, while for the variant of static criteria, it is significantly lower. However, the dynamic criteria option has much higher maximum solution values found for 5, 10, 15, and 25 alternatives than the static variant.
For an initial state value of 1, the static variant of criteria has similar distributions of solution values as the dynamic variant due to its violin appearance. However, the most significant solution values found vary considerably.
In the case of the graphs for the initial state, in which the preference of characteristic objects took a random value, the static variant of the criteria is characterized by small benefits of solutions. Higher amounts of solutions assume the dynamic variant. The static variant is more accurate than the dynamic option.
Figure 18 shows violin charts for particle swarm optimization for a non-existent model. The graphs show variants of criteria and options of initial states.
In the case of charts for the initial state, in which the preference of characteristic objects took the value 0, the static value of criteria has smaller amounts of solutions than the dynamic value. Therefore, the size of the violin for a static case is much larger with small values of solutions.
For the initial state, where the preference of the characteristic objects has assumed the value of 0.5, the costs of solutions are similar to those of 0. When criteria are chosen statically, the accuracy decreases as the number of alternatives increases. In addition, the dynamic variant of criteria has much higher maximum solution values found for 15 and 25 alternatives than the static option.
For an initial state value of 1 fiddle size for solutions found are similar to those where the initial state is 0.5. The accuracy for static criteria is higher than for dynamic criteria. The smallest and largest solution values found are significantly different for dynamic and static criteria.
For a random initial state value, the distribution of solutions found is similar to when the initial state is 0.5 and 1. For five alternatives, the static variant has significantly higher amounts of solutions than the dynamic option. For ten, fifteen, twenty, and twenty-five choices, the static variant has higher accuracy than the static variant.
Figure 19 shows violin charts for particle swarm optimization for the existing model. The graphs show variants of criteria and options of initial states.
In the case of diagrams for the initial state, where the preference of characteristic objects took the value 0, the static value of criteria has smaller amounts of solutions than the dynamic value. For 5 and 10 alternatives, the accuracy of static criteria is higher than for dynamic criteria. However, where there are 15, 20 and 25 alternatives in a set, the accuracy for static criteria is lower than for dynamic criteria.
For an initial state where the preference of the characteristic objects has taken the value 0.5, the benefits of the solutions are more significant than when the initial state takes the amount 0. The accuracy decreases as the number of alternatives for each criterion selection variant increases. The dynamic variant of criteria has significantly higher maximum solution values found for 15, 20, and 25 options than the static option.
For an initial state value of 1, the static values of the criteria have smaller solution values than the static variant of the criteria. The accuracy for static criteria is higher than for dynamic criteria. The smallest and largest solution values found are significantly different for dynamic and static criteria.
For a random initial state value, the distribution of solutions found differs slightly from a 0 initial state. For all alternatives considered, the dynamic variant has significantly higher amounts of solutions than the static option. The accuracy of the static variant is much higher than for the dynamic variant.
3.3. Use of the Proposed Approach
A study was carried out to demonstrate the operation of the proposed approach. For dynamic and static criteria with an existing model, twenty alternatives were drawn. The preference for characteristic objects was set to 0.5 as the initial state, as this approach is more productive according to the previously presented surveys.
To calculate the similarity coefficient of final rankings between the reference ranking and the one obtained using stochastic methods, the alternatives were divided into a training set and a test set. The division of the set of alternatives was partial, i.e., the first half was a teaching set and the second a test set.
The static criteria were set to [0, 0.5, 0], while the dynamic ones were calculated with the use of the teaching set according to the Formula (
36). A randomly generated
vector evaluated the alternatives constituting the teaching and test set.
Then, the teaching set was used to determine the preferences of characteristic objects using selected stochastic methods. The defined model evaluated the alternatives from the test set using the calculated preferences of characteristic objects.
Training set of 10 alternatives for a static variant of the criteria are presented in
Table 1. The preference was calculated using a randomly generated
vector. The generated points served as input for HC, SA and PSO techniques. On their basis, decision models were identified using each method.
Table 2 presents alternatives included in the test set and their preferences as well as rankings for a static variant of the criteria. The simulated annealing method performed slightly worse than the hill-climbing algorithm and particle swarm optimization. The lowest value of fitness function obtained by it is much higher than the other two methods. The particle swarm optimization method did very well because the ranking of the assessed alternatives is approximate to a reference ranking. The same is true for the hill-climbing algorithm, whose preferences are very similar to those of the reference model.
Spearman’s correlation coefficients for a static variant of the criteria between the reference ranking and calculated by stochastic methods are 0.9879 (HC), 0.9152 (SA), 0.9636 (PSO). The high accuracy of the methods used can be seen here, however, the simulated annealing method differs significantly from the PSO and HC methods. The strongest correlation between the reference ranking and the calculated one has a hill-climbing algorithm.
Spearman’s weighted correlation coefficients for a static variant of the criteria for stochastic methods are as follows: 0.9835 (HC), 0.9096 (SA), 0.9736 (PSO). Similarly to Spearman’s correlation coefficients, the weighted coefficients show that the strongest correlation is with the hill-climbing algorithm and the weakest with the simulated overhang method. However, the difference between the coefficient for PSO and HC methods is much smaller than for Spearman’s correlation coefficient.
correlation coefficients calculated for the preference of a reference testing set and the preference calculated using stochastic methods for a static variant of the criteria are as follows: 0.9717 (HC), 0.9143 (SA), 0.9919 (PSO). The most substantial relation between the reference ranking and the calculated one is particle swarm optimization. In the case of and coefficient, the most correlated method was the HC method. Moreover, a much higher difference in the ws factor between the PSO method and the hill-climbing algorithm can be seen here than in the case of the Spearman weighted factor. On the other hand, the correlation of the simulated annealing method, as in the case of the rest of correlation coefficients, is the weakest of the methods considered.
Table 3 shows a training set of 10 alternatives and their preference for a dynamic variant of criteria. The preference was calculated using a randomly generated
vector. The generated points served as input for HC, SA, and PSO techniques. On their basis, decision models were identified using each method.
Table 4 shows the alternatives included in the test set and their preferences, as well as rankings for the dynamic variant of criteria. The simulated annealing method has fared worse than the hill-climbing algorithm and particle swarm optimization. The lowest value of fitness function obtained by it is much higher than the other two methods. The particle swarm optimization method did very well because the ranking of the assessed alternatives is the same as the reference ranking. The same is true for the hill-climbing algorithm, whose preferences are very similar to those of the reference model.
The obtained Spearman correlation coefficients between the reference ranking and the one calculated by stochastic methods for the dynamic variant of criteria are 1.0 (HC), 0.9273 (SA), 1.0 (PSO). The accuracy of HC and PSO methods is very high, whereas the simulated expression method has much lower accuracy.
Spearman’s weighted correlation coefficients for stochastic methods for the dynamic variant of criteria are as follows: 1.0 (HC), 0.9537 (SA), 1.0 (PSO). As with Spearman’s correlation coefficients, the weighted coefficients show that the strongest correlation occurs with the hill-climbing algorithm and particle swarm optimization, and the weakest with the simulated overhang method.
correlation coefficients calculated for the preference of the reference testing set and the preference calculated using stochastic methods for the dynamic variant of the criteria are as follows: 1.0 (HC), 0.9885(SA), 1.0 (PSO). The PSO and HC methods have the most substantial relationship between the reference ranking and the calculated one. However, the correlation of the simulated annealing method, as in the case of the rest of the correlation coefficients, is the weakest of the methods considered.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}