A Review of Unsupervised Keyphrase Extraction Methods Using Within-Collection Resources



Abstract
:1. Introduction
- Based on the characteristics of different methods, combined with the human language habit, the reasons for the performance differences between methods are analyzed in detail (Section 5.1).
- In keyphrase extraction, the characteristics of the datasets directly affect the performance of the methods, so we analyze how different datasets affect method performance (Section 5.2).
- We analyze the reasons for the limitations of the keyphrase methods and propose corresponding solutions, which will help the following researchers to explore further (Section 6).
2. Datasets, Evaluation Metrics and Features
2.1. What Datasets Are There in the Keyphrase Extraction Field?
2.2. What Are the Evaluation Metrics in the Keyphrase Extraction Field?
2.2.1. Statistics-Based Metrics
- Precision:
- Recall:
- F-score:
2.2.2. Linguistics-Based Metrics
- Mean Reciprocal Rank (MRR):
- Mean Average Precision (MAP):
- Binary Preference Measure (Bpref):
2.3. What Are the Features that Affect Keyphrase Extraction?
2.3.1. Linguistic-Based Features
- Topic distribution:
- Topic correlation:
2.3.2. Statistical-Based Features
- Keyphrase density:
- Lexical density:
- Structural features:
2.4. How to Use These Features for Keyphrase Extraction?
2.4.1. Linguistic-Based
- Topic distribution:
- Syntactic features:
2.4.2. Statistical-Based
- Frequency of words:
- Distance of words:
- Structural features:
3. Unsupervised Keyphrase Extraction Methods
3.1. Classification of Unsupervised Keyphrase Extraction Methods
3.2. Statistics-Based Methods
- TF-IDF:
- KP-miner:
- YAKE:
3.3. Graph-Based Methods
- TextRank:
- SingleRank:
- ExpandRank:
- PositionRank:
3.4. Topic-Based Methods
3.4.1. Transfer Learning-Based Methods
- KeyCluster:
- CommunityCluster:
- Topical PageRank (TPR):
- Single Topical PageRank:
3.4.2. Clustering-Based Methods
- TopicRank:
3.5. Language Model-Based Methods
4. The State of the Art
5. Analysis
5.1. The Performance of the Methods
5.2. The Impacts of Dataset on Performance
6. Limitation of Keyphrase Extraction Methods
6.1. The Impact of Gold Standard on Evaluation
6.2. The Impact of Manually Assigned Labels on Evaluation
6.3. Our Recommendations
7. Conclusions and Future Directions
Author Contributions
Funding
Conflicts of Interest
References
- Babar, S.A.; Patil, P.D. Improving Performance of Text Summarization. Procedia Comput. Sci. 2015, 46, 354–363. [Google Scholar] [CrossRef] [Green Version]
- Welleck, S.; Brantley, K.; Daumé, H., III; Cho, K. Non-Monotonic Sequential Text Generation. arXiv 2019, arXiv:1902.02192. [Google Scholar]
- Welleck, S.; Kulikov, I.; Roller, S.; Dinan, E.; Cho, K.; Weston, J. Neural Text Generation with Unlikelihood Training. arXiv 2019, arXiv:1908.04319. [Google Scholar]
- Puduppully, R.; Dong, L.; Lapata, M. Data-to-Text Generation with Content Selection and Planning. arXiv 2019, arXiv:1809.00582. [Google Scholar] [CrossRef]
- Shen, S.; Fried, D.; Andreas, J.; Klein, D. Pragmatically Informative Text Generation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4060–4067. [Google Scholar]
- Mallett, D.; Elding, J.; Nascimento, M.A. Information-content based sentence extraction for text summarization. In Proceedings of the International Conference on Information Technology: Coding and Computing, Las Vegas, NV, USA, 5–7 April 2004; IEEE: Las Vegas, NV, USA, 2004; Volume 2, pp. 214–218. [Google Scholar]
- Bougouin, A.; Boudin, F.; Daille, B. TopicRank: Graph-Based Topic Ranking for Keyphrase Extraction. In Proceedings of the IJCNLP, Nagoya, Japan, 14–18 October 2013. [Google Scholar]
- Liu, Z.; Liang, C.; Sun, M. Topical Word Trigger Model for Keyphrase Extraction. Available online: https://www.aclweb.org/anthology/C12-1105.pdf (accessed on 12 June 2020).
- Azad, H.K.; Deepak, A. Query expansion techniques for information retrieval: A survey. Inf. Process. Manag. 2019, 56, 1698–1735. [Google Scholar] [CrossRef] [Green Version]
- Guo, J. A Deep Look into Neural Ranking Models for Information Retrieval. arXiv 2019, arXiv:1903.06902. [Google Scholar] [CrossRef] [Green Version]
- Gutierrez, C.E.; Alsharif, M.R. A Tweets Mining Approach to Detection of Critical Events Characteristics using Random Forest. Int. J. Next Gener. Comput. 2014, 5, 167–176. [Google Scholar]
- Gutierrez, C.E.; Alsharif, M.R.; He, C.; Khosravy, M.; Villa, R.; Yamashita, K.; Miyagi, H. Uncover news dynamic by principal component analysis. ICIC Express Lett. 2016, 7, 1245–1250. [Google Scholar]
- Dave, K.; Lawrence, S.; Pennock, D. Mining the peanut gallery: Opinion extraction and semantic classification of product reviews. In Proceedings of the WWW’03, Budapest, Hungary, 20–24 May 2003. [Google Scholar]
- Hemmatian, F.; Sohrabi, M.K. A survey on classification techniques for opinion mining and sentiment analysis. Artif. Intell. Rev. 2019, 52, 1495–1545. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Khan, A.; Zahra, S.R.; Ahmad, S.; Kundi, F.M. Aspect-based opinion mining framework using heuristic patterns. Cluster. Comput. 2019, 22, 7181–7199. [Google Scholar] [CrossRef]
- Frank, E.; Paynter, G.W.; Witten, I.; Gutwin, C.; Nevill-Manning, C. Domain-Specific Keyphrase Extraction. In Proceedings of the IJCAI, Stockholm, Sweden, 31 July–6 August 1999. [Google Scholar]
- Hulth, A.; Megyesi, B.B. A Study on Automatically Extracted Keywords in Text Categorization. Available online: https://www.aclweb.org/anthology/P06-1068.pdf (accessed on 15 June 2020).
- Turney, P.D. Learning to Extract Keyphrases from Text; Technical Report; National Research Council, Institute for Information Technolog: Ottawa, ON, Canada, 2002. [Google Scholar]
- Witten, I.H.; Paynter, G.W.; Frank, E.; Gutwin, C.; Nevill-Manning, C.G. KEA: Practical Automatic Keyphrase Extraction. In Proceedings of the Fourth ACM Conference on Digital Libraries, Berkeley, CA, USA, 11–14 August 1999. [Google Scholar]
- Wang, R.; Wang, G. Web Text Categorization Based on Statistical Merging Algorithm in Big Data. Environ. Int. J. Ambient. Comput. Intell. 2019, 10, 17–32. [Google Scholar] [CrossRef] [Green Version]
- Gutierrez, C.E.; Alsharif, M.R.; Khosravy, M.; Yamashita, K.; Miyagi, H.; Villa, R. Main Large Data Set Features Detection by a Linear Predictor Model. Available online: https://aip.scitation.org/doi/abs/10.1063/1.4897836 (accessed on 20 June 2020).
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.N.; Kan, M.Y. Re-examining automatic keyphrase extraction approaches in scientific articles. In Proceedings of the Workshop on Multiword Expressions Identification, Interpretation, Disambiguation and Applications—MWE’09, Singapore, 25–27 November 2009; p. 9. [Google Scholar]
- Liu, Z.; Huang, W.; Heng, Y.; Sun, M. Automatic Keyphrase Extraction via Topic Decomposition. Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Singapore, 2010. [Google Scholar]
- Liu, Z.; Li, P.; Zheng, Y.; Sun, M. Clustering to find exemplar terms for keyphrase extraction. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing—EMNLP’09, Singapore, 6–7 August 2009; Association for Computational Linguistics: Singapore, 2009; Volume 1, p. 257. [Google Scholar]
- Hasan, K.S.; Ng, V. Automatic Keyphrase Extraction: A Survey of the State of the Art. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 23–25 June 2014; Association for Computational Linguistics: Baltimore, MD, USA, 2014; pp. 1262–1273. [Google Scholar]
- El-Beltagy, S.R.; Rafea, A. KP-Miner: A keyphrase extraction system for English and Arabic documents. Inf. Syst. 2009, 34, 132–144. [Google Scholar] [CrossRef]
- Campos, R.; Mangaravite, V.; Pasquali, A.; Jorge, A.M.; Nunes, C.; Jatowt, A. YAKE! Collection-Independent Automatic Keyword Extractor. In Advances in Information Retrieval; Pasi, G., Piwowarski, B., Azzopardi, L., Hanbury, A., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 10772, pp. 806–810. ISBN 978-3-319-76940-0. [Google Scholar]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Texts. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2004), Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Wan, X.; Xiao, J. CollabRank: Towards a collaborative approach to single-document keyphrase extraction. In Proceedings of the 22nd International Conference on Computational Linguistics—COLING’08, Manchester, UK, 18–22 August 2008; Association for Computational Linguistics: Manchester, UK, 2008; Volume 1, pp. 969–976. [Google Scholar]
- Papagiannopoulou, E.; Tsoumakas, G. A review of keyphrase extraction. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, e1339. [Google Scholar] [CrossRef] [Green Version]
- Krapivin, M.; Autayeu, A.; Marchese, M. Large Dataset for Keyphrases Extraction; Technical Report DISI-09-055; DISI, University of Trento: Trento, Italy, 2009. [Google Scholar]
- Medelyan, O.; Frank, E.; Witten, I.H. Human-competitive tagging using automatic keyphrase extraction. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing—EMNLP’09, Singapore, 6–7 August 2009; Association for Computational Linguistics: Singapore, 2009; Volume 3, p. 1318. [Google Scholar]
- Nguyen, T.D.; Kan, M.-Y. Keyphrase Extraction in Scientific Publications. In Asian Digital Libraries. Looking Back 10 Years and Forging New Frontiers; Goh, D.H.-L., Cao, T.H., Sølvberg, I.T., Rasmussen, E., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4822, pp. 317–326. ISBN 978-3-540-77093-0. [Google Scholar]
- Schutz, A. Keyphrase Extraction from Single Documents in the Open Domain Exploiting Linguistic and Statistical Methods. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.394.5372&rep=rep1&type=pdf (accessed on 30 June 2020).
- Hulth, A. Improved automatic keyword extraction given more linguistic knowledge. In Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, Sapporo, Japan, 11–12 July 2003; Volume 10, pp. 216–223. [Google Scholar]
- Gollapalli; Sujatha, D.; Cornelia, C. Extracting Keyphrases from Research Papers Using Citation Networks. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 1629–1635. [Google Scholar]
- Jiang, M.; Chen, Y.; Liu, M.; Rosenbloom, S.T.; Mani, S.; Denny, J.C.; Xu, H. A study of machine-learning-based approaches to extract clinical entities and their assertions from discharge summaries. J. Am. Med. Inform. Assoc. 2011, 18, 601–606. [Google Scholar] [CrossRef] [PubMed]
- Bougouin, A.; Barreaux, S.; Romary, L.; Boudin, F.; Daille, B. TermITH-Eval: A French Standard-Based Resource for Keyphrase Extraction Evaluation. In Proceedings of the Language Resources and Evaluation Conference (LREC), Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Wan, X.; Xiao, J. Single Document Keyphrase Extraction Using Neighborhood Knowledge. Available online: https://www.aaai.org/Papers/AAAI/2008/AAAI08-136.pdf (accessed on 25 June 2020).
- Marujo, L.; Gershman, A.; Carbonell, J.; Frederking, R.; Neto, J.P. Supervised Topical Key Phrase Extraction of News Stories using Crowdsourcing, Light Filtering and Co-reference Normalization. In Proceedings of the Eight International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 23–25 May 2012. [Google Scholar]
- Marujo, L.; Viveiros, M.; Neto, J.P. Keyphrase Cloud Generation of Broadcast News. In Proceedings of the 12th Annual Conference of the International Speech Communication Association (Interspeech), Florence, Italy, 27–31 August 2011. [Google Scholar]
- Grineva, M.; Grinev, M.; Lizorkin, D. Extracting Key Terms from Noisy and Multitheme Documents. Available online: https://dl.acm.org/doi/abs/10.1145/1526709.1526798 (accessed on 26 June 2020).
- Hammouda, K.M.; Matute, D.N.; Kamel, M.S. CorePhrase: Keyphrase Extraction for Document Clustering. In Machine Learning and Data Mining in Pattern Recognition; Perner, P., Imiya, A., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3587, pp. 265–274. ISBN 978-3-540-26923-6. [Google Scholar]
- Voorhees, E.M. The TREC-8 question answering track report. In Proceedings of the Eighth Text Retrieval Conference, TREC 1999, Gaithersburg, MD, USA, 17–19 November 1999. [Google Scholar]
- Buckley, C.; Voorhees, E.M. Retrieval Evaluation with Incomplete Information. Available online: https://dl.acm.org/doi/abs/10.1145/1008992.1009000 (accessed on 18 June 2020).
- Blei, D.M. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Halliday, M.A.K.; Matthiessen, C.M.I.M. An Introduction to Functional Grammar, 3rd ed.; Distributed in the United States of America by Oxford University Press: Oxford, MS, USA, 2004; ISBN 978-0-340-76167-0. [Google Scholar]
- Johansson, V. Lexical Diversity and Lexical Density in Speech and Writing: A Developmental Perspective. Working Papers. Available online: https://www.semanticscholar.org/paper/Lexical-diversity-and-lexical-density-in-speech-and-Johansson/f0ec9ed698d5195220f80b732e30261eafbe1ad8?p2df (accessed on 10 June 2020).
- Yih, W.; Goodman, J.; Carvalho, V.R. Finding advertising keywords on web pages. In Proceedings of the 15th International Conference on World Wide Web—WWW’06, Edinburgh, UK, 23–26 May 2006; p. 213. [Google Scholar]
- Turney, P.D. Learning Algorithms for Keyphrase Extraction. Inf. Retr. 2000, 2, 303–336. [Google Scholar] [CrossRef] [Green Version]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web. Available online: http://ilpubs.stanford.edu:8090/422/ (accessed on 5 June 2020).
- Wang, H.; Ye, J.; Yu, Z.; Wang, J.; Mao, C. Unsupervised Keyword Extraction Methods Based on a Word Graph Network. Int. J. Ambient. Comput. Intell. 2020, 11, 68–79. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. Available online: https://ui.adsabs.harvard.edu/abs/2013arXiv1301.3781M/abstract (accessed on 1 June 2020).
- Florescu, C.; Caragea, C. PositionRank: An Unsupervised Approach to Keyphrase Extraction from Scholarly Documents. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1105–1115. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Mihalcea, R.; Csomai, A. Wikify!: Linking documents to encyclopedic knowledge. In Proceedings of the Sixteenth ACM Conference on Conference on information and Knowledge Management—CIKM’07, Lisbon, Portugal, 6–10 November 2007; p. 233. [Google Scholar]
- Sterckx, L.; Demeester, T.; Deleu, J.; Develder, C. Topical word importance for fast keyphrase extraction. Presented at the 24th International Conference on World Wide Web Companion, WWW 2015, Florence, Italy, 18–22 May 2015; pp. 121–122. [Google Scholar] [CrossRef] [Green Version]
- Tomokiyo, T.; Hurst, M. A language model approach to keyphrase extraction. In Proceedings of the ACL 2003 Workshop on Multiword Expressions Analysis, Acquisition and Treatment, Sapporo, Japan, 12 July 2003; Volume 18, pp. 33–40. [Google Scholar]
- Jernite, Y.; Bowman, S.R.; Sontag, D. Discourse-Based Objectives for Fast Unsupervised Sentence Representation Learning. arXiv 2017, arXiv:1705.00557. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Dataset | Contributor | Tokens/Doc | Docs | Keyphrases/Doc | Language | Annotation |
|---|---|---|---|---|---|---|---|
| Full-text papers | ACM | Krapivin et al. [32] | 2∼12k | 2304 | 6 | English | A |
| Citeulike-180 | Medelyan et al. [33] | 181 | 5 | English | A+R | ||
| CSTR | Witten et al. [19] | 630 | - | English | A | ||
| SemEval-2010 | Kim et al. [23] | 283 | 15 | English | A+R | ||
| NUS | Nguyen and Kan [34] | 211 | 11 | English | A+R | ||
| PubMed | Schutz [35] | 1320 | 5 | English | A | ||
| Inspec | Hulth [36] | 2000 | 10 | English | I | ||
| KDD | Gollapalli et al. [37] | 755 | 4 | English | A | ||
| Papers abstracts | WWW | Gollapalli et al. [37] | 100∼200 | 1330 | 5 | English | A |
| TALN | Boudin [38] | 641 | 4 | English | A | ||
| TermLTH-Eval | Bougouin [39] | 400 | 12 | English | I | ||
| News | DUC-2001 | Wan and Xiao [40] | 300∼850 | 308 | 10 | English | R |
| 500N-KPCrowd | Marujo et al. [41] | 500 | 46 | English | R | ||
| 110-PT-BN-KP | Marujo et al. [42] | 110 | 28 | Portuguese | R | ||
| Wikinews | Bougouin et al. [7] | 100 | 10 | French | R | ||
| Web pages | Blogs | Grineva et al. [43] | 500∼1k | 252 | 8 | English | R |
| - | Hammouda et al. [44] | 312 | - | English | - |
| Evaluation Metrcis | precision | |
| recall | ||
| F-socre | ||
| MRR | ||
| AP | ||
| MAP | ||
| Bpref |
| S (W/V) | The score for a word W or node V |
| WE (Vk, Vm) | Edge weight of node Vk and node Vm |
| damping factor | |
| NB (V) | the neighboring node of node V |
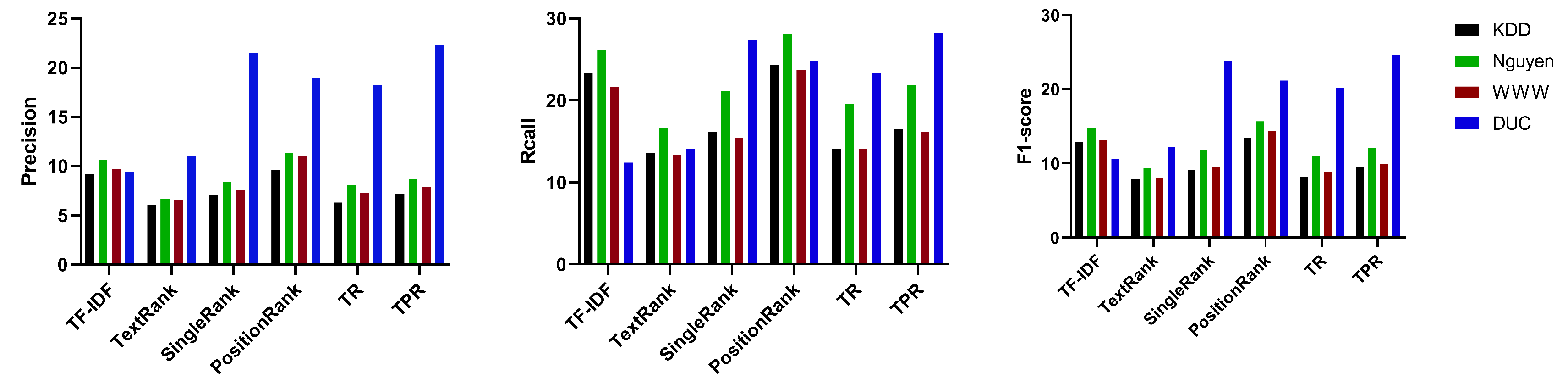
| Dataset | Method | P% | R% | F1% | Dataset | Method | P% | R% | F1% |
|---|---|---|---|---|---|---|---|---|---|
| DUC | TF-IDF | 9.4 | 12.4 | 10.6 | KDD | TF-IDF | 9.2 | 23.3 | 12.9 |
| TextRank | 11.1 | 14.1 | 12.2 | TextRank | 6.1 | 13.6 | 7.9 | ||
| SingleRank | 21.5 | 27.4 | 23.8 | SingleRank | 7.1 | 16.1 | 9.2 | ||
| PositionRank | 18.9 | 24.8 | 21.2 | PositionRank | 9.6 | 24.3 | 13.4 | ||
| TR | 18.2 | 23.3 | 20.2 | TR | 6.3 | 14.1 | 8.2 | ||
| TPR | 22.3 | 28.2 | 24.6 | TPR | 7.2 | 16.5 | 9.5 | ||
| Nguyen | TF-IDF | 10.6 | 26.2 | 14.8 | WWW | TF-IDF | 9.7 | 21.6 | 13.2 |
| TextRank | 6.7 | 16.6 | 9.3 | TextRank | 6.6 | 13.3 | 8.1 | ||
| SingleRank | 8.4 | 21.2 | 11.8 | SingleRank | 7.6 | 15.4 | 9.5 | ||
| PositionRank | 11.3 | 28.1 | 15.7 | PositionRank | 11.1 | 23.7 | 14.4 | ||
| TR | 8.1 | 19.6 | 11.1 | TR | 7.3 | 14.1 | 8.9 | ||
| TPR | 8.7 | 21.8 | 12.1 | TPR | 7.9 | 16.1 | 9.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, C.; Hu, L.; Li, S.; Li, T.; Li, H.; Chi, L. A Review of Unsupervised Keyphrase Extraction Methods Using Within-Collection Resources. Symmetry 2020, 12, 1864. https://doi.org/10.3390/sym12111864
Sun C, Hu L, Li S, Li T, Li H, Chi L. A Review of Unsupervised Keyphrase Extraction Methods Using Within-Collection Resources. Symmetry. 2020; 12(11):1864. https://doi.org/10.3390/sym12111864
Chicago/Turabian StyleSun, Chengyu, Liang Hu, Shuai Li, Tuohang Li, Hongtu Li, and Ling Chi. 2020. "A Review of Unsupervised Keyphrase Extraction Methods Using Within-Collection Resources" Symmetry 12, no. 11: 1864. https://doi.org/10.3390/sym12111864