Dynamic Job Scheduling Strategy Using Jobs Characteristics in Cloud Computing

 ,
, 
Abstract
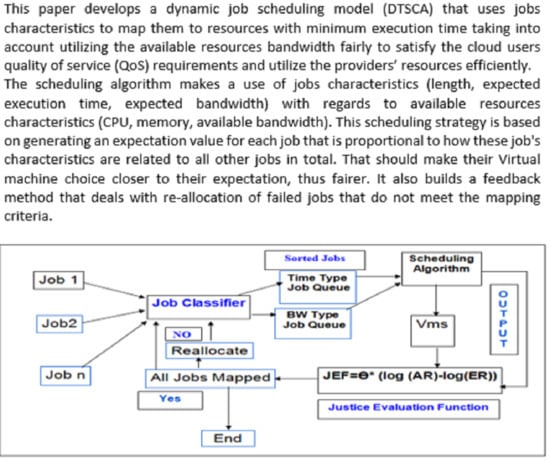
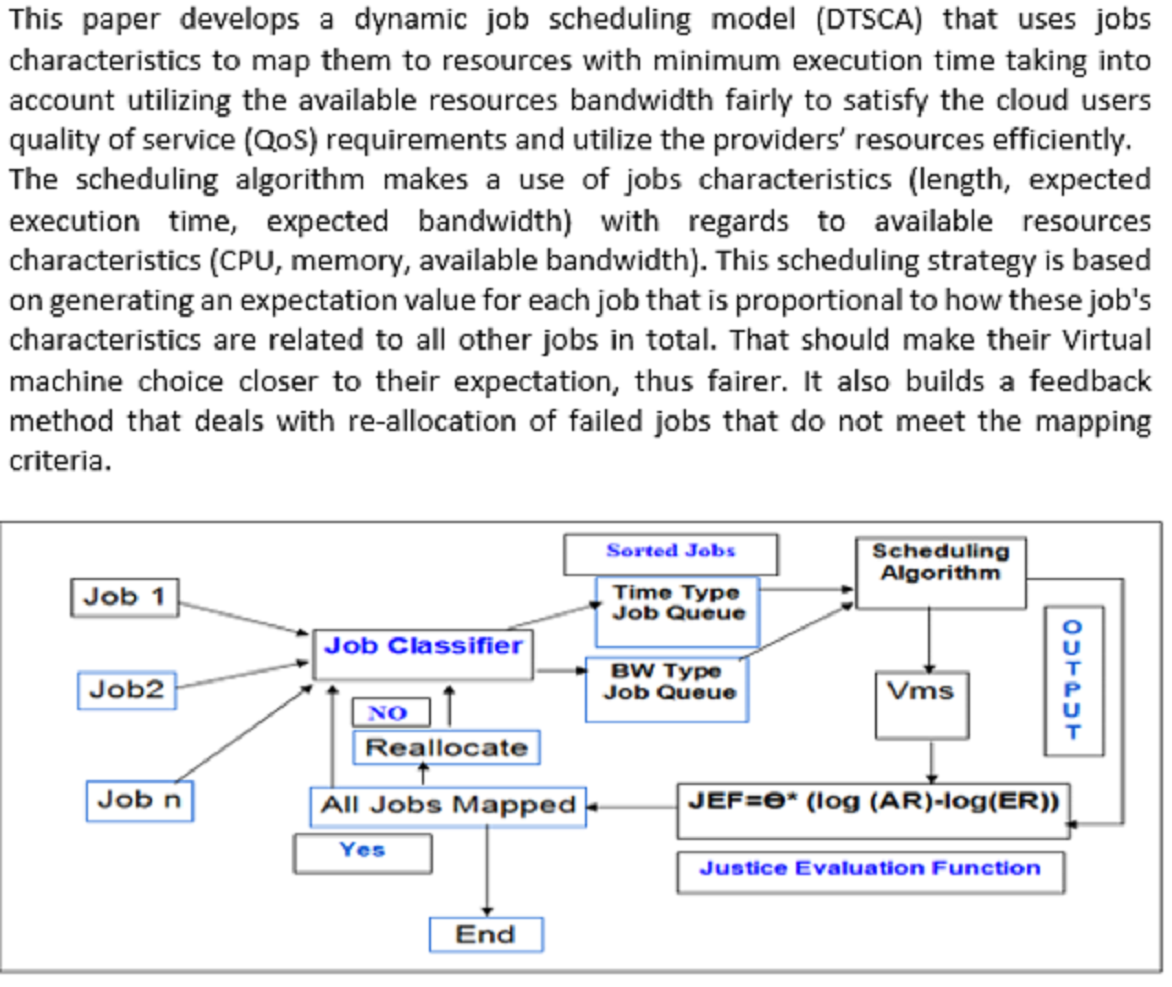
:
1. Introduction
2. Related Work
3. Proposed Model
3.1. Job Classification
- Class-Type: the job class type can be either time type or bandwidth type.
- Start-Time: the starting time for each job.
- Finish-Time: the time needed for a job to complete execution.
- Expected-Time: the job’s expected finish time.
- Expected-Bandwidth: the expected bandwidth needed for each job.
- Priority: the priority value assigned to each job
- J-Value: the justice evaluation value for each job amongst other jobs (at the same job type).
3.2. Jobs and Resources Description
3.3. Generation of Expectation Initialization and Priority
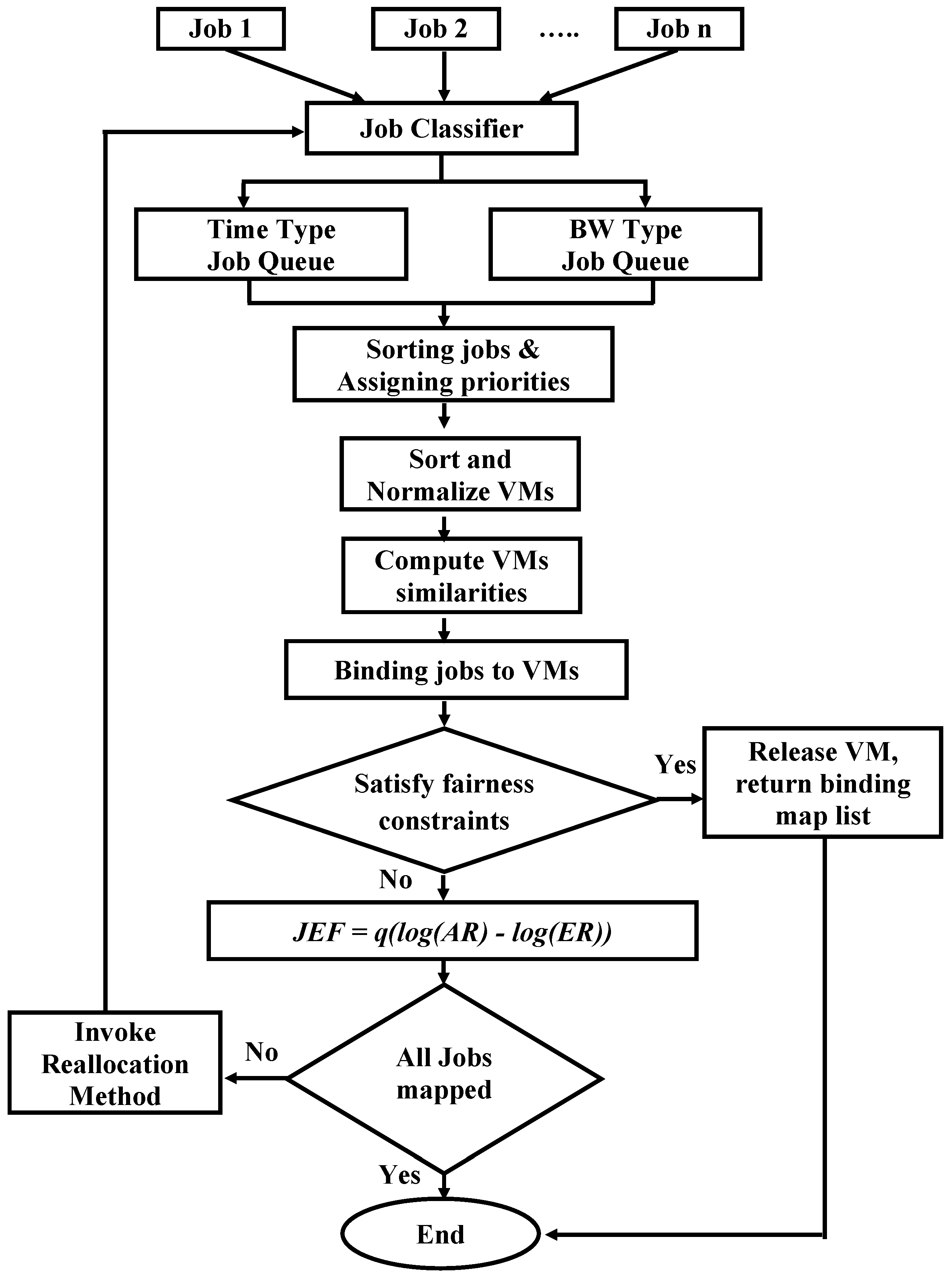
3.4. Scheduling Algorithm
| Algorithm 1: Jobs scheduling algorithm. |
 |
| Algorithm 2: Reallocation method. |
 |
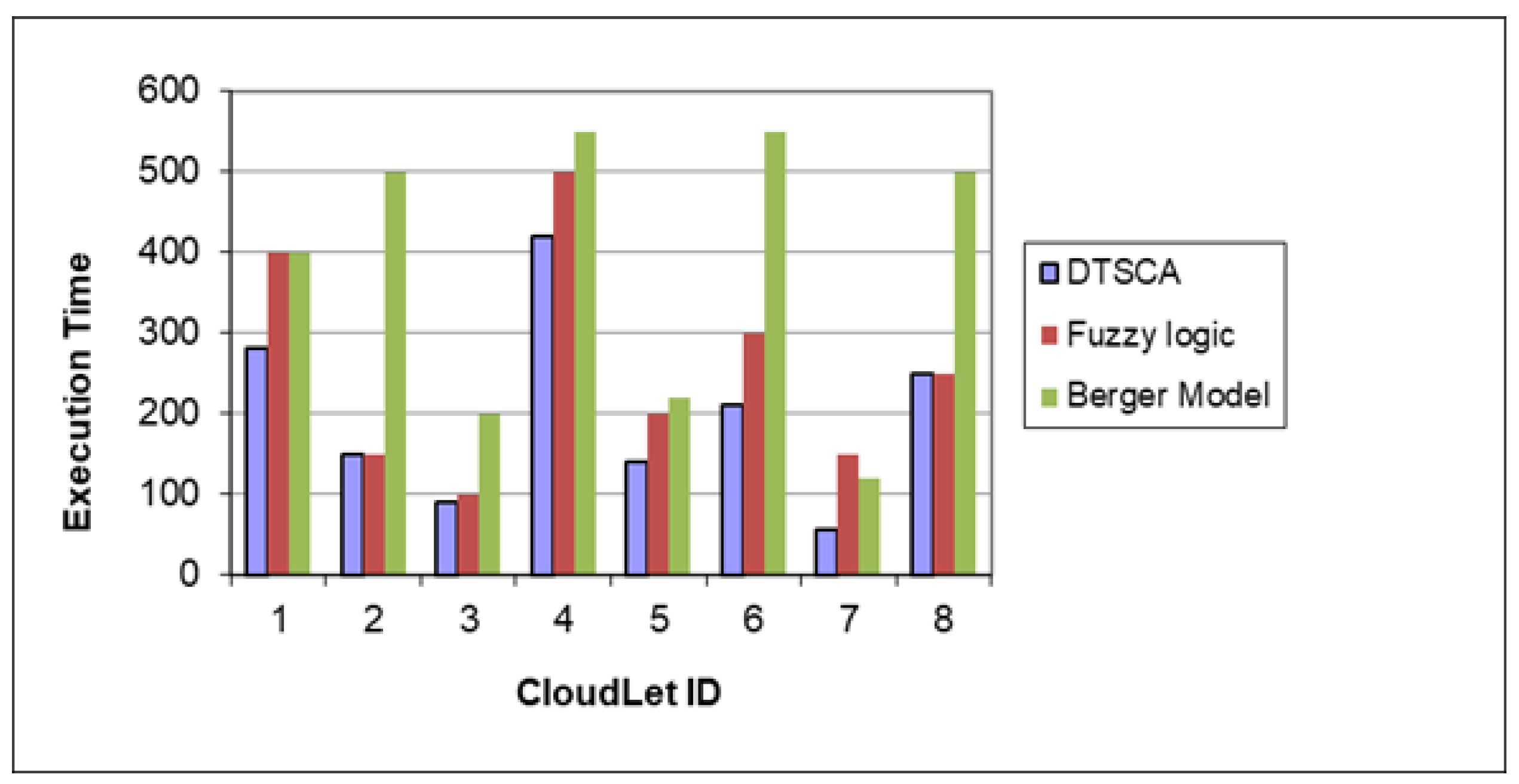
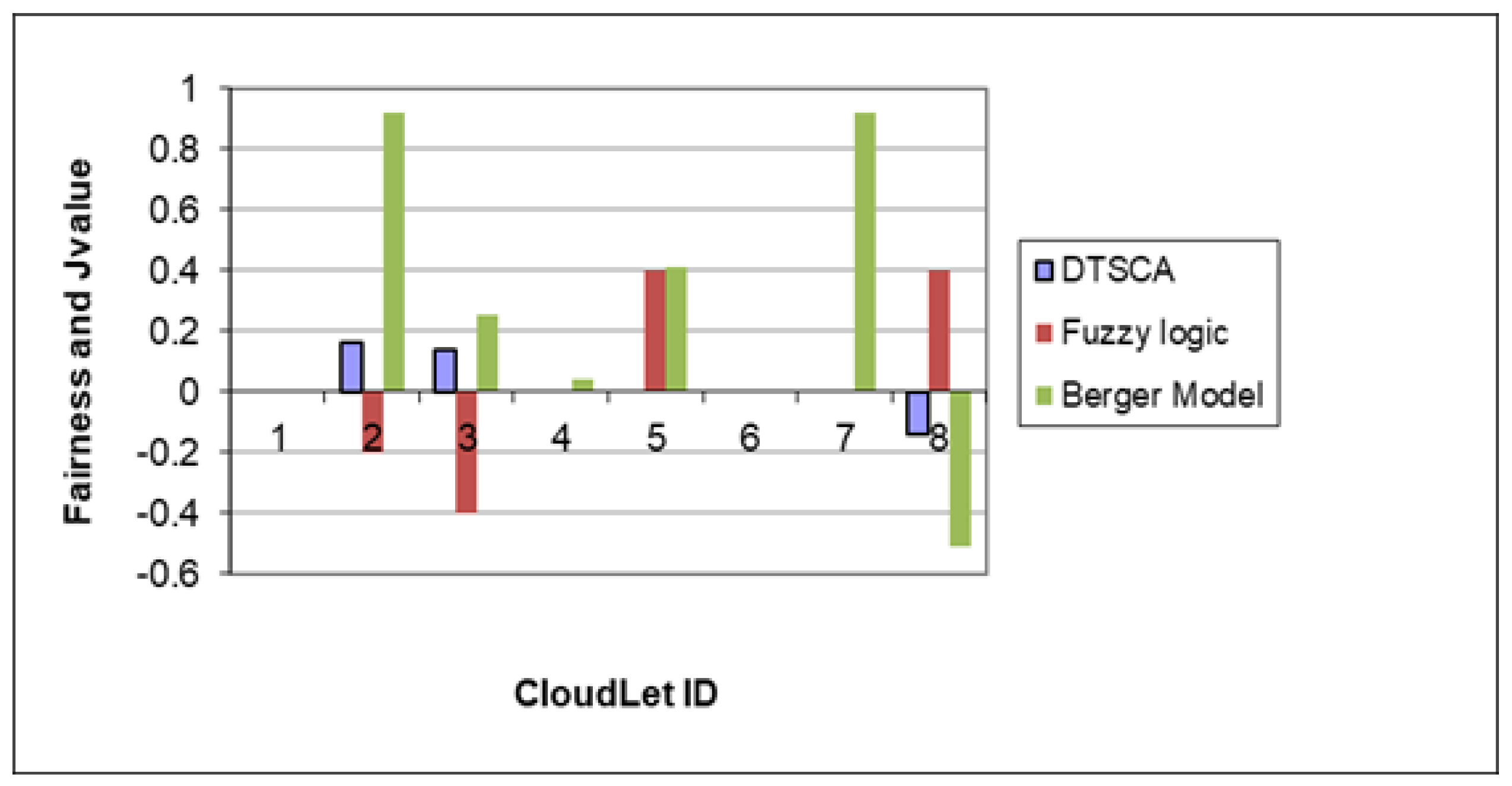
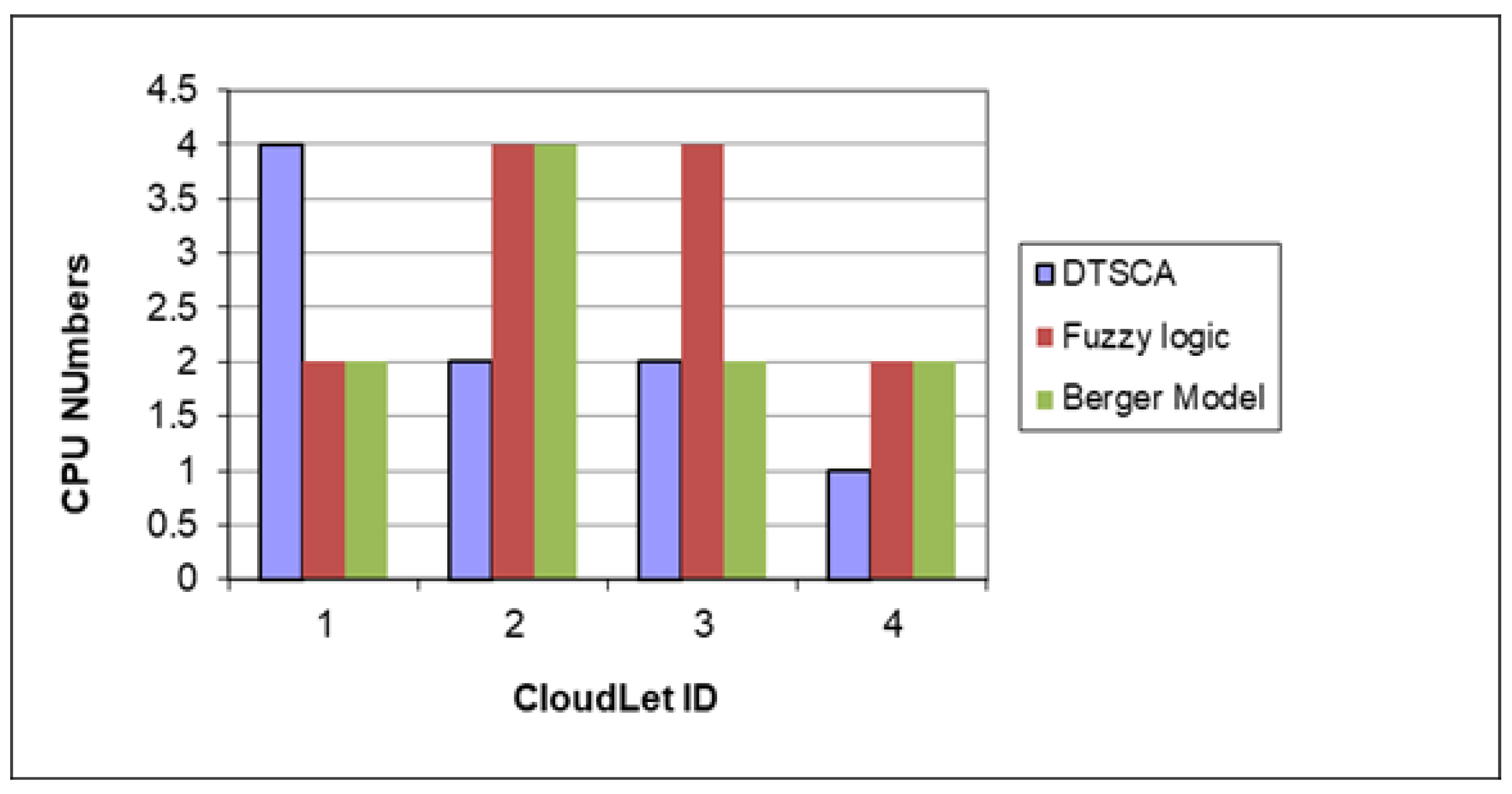
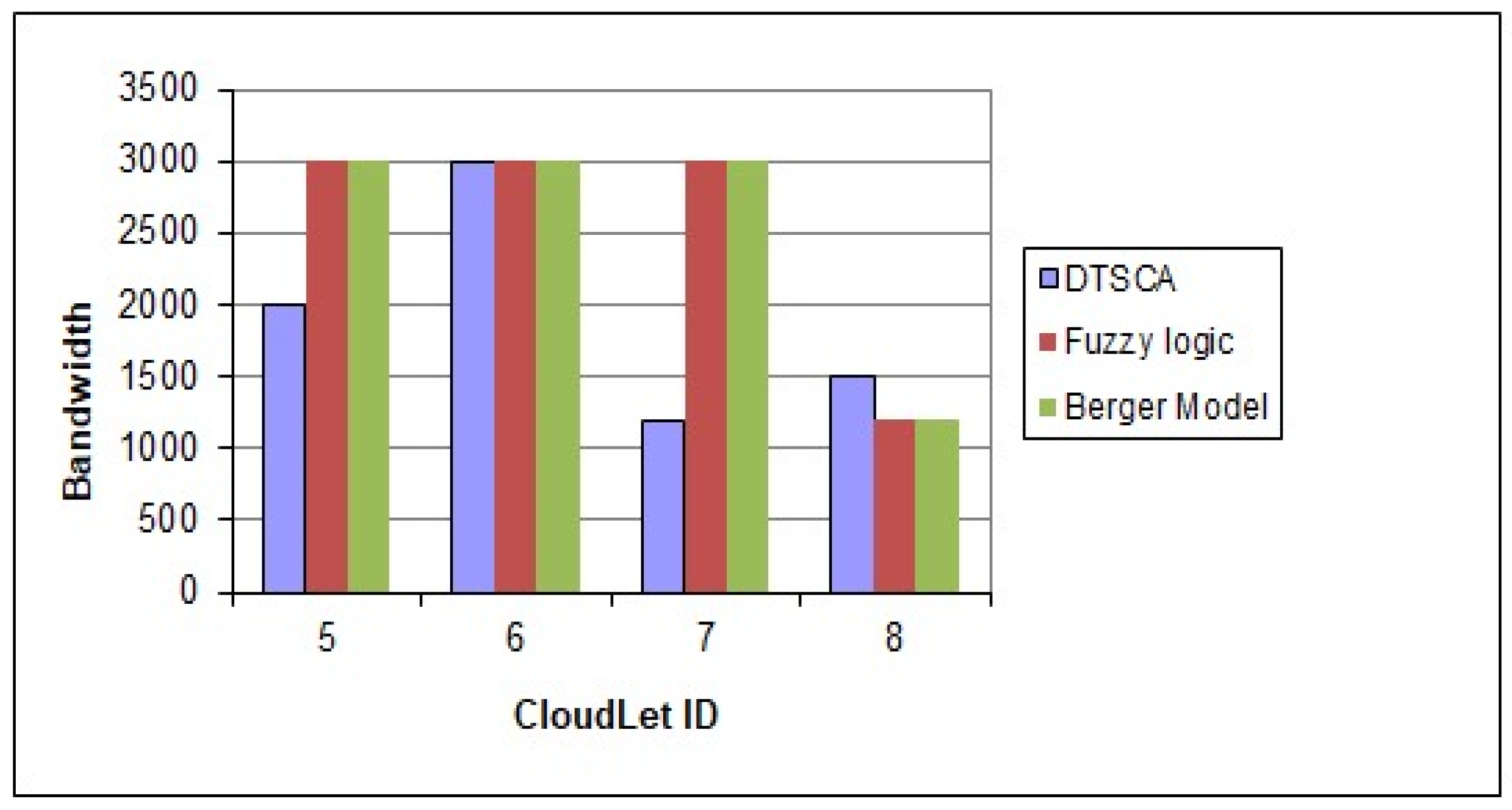
4. Simulation and Results
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Buyya, R.; Ranjan, R.; Calheiros, R.N. Modeling and simulation of scalable Cloud computing environments and the CloudSim toolkit: Challenges and opportunities. In Proceedings of the 2009 International Conference on High Performance Computing & Simulation, Leipzig, Germany, 21–24 June 2009; pp. 1–11. [Google Scholar]
- Hewitt, C. ORGs for scalable, robust, privacy-friendly client cloud computing. IEEE Internet Comput. 2008, 12, 96–99. [Google Scholar] [CrossRef]
- Arunarani, A.; Manjula, D.; Sugumaran, V. Task scheduling techniques in cloud computing: A literature survey. Future Gener. Comput. Syst. 2019, 91, 407–415. [Google Scholar] [CrossRef]
- Radu, L.D. Green cloud computing: A literature survey. Symmetry 2017, 9, 295. [Google Scholar] [CrossRef] [Green Version]
- Xen Project. Available online: https://xenproject.org/2015/01/14/xen-project-announces-4-5-release/ (accessed on 20 January 2020).
- Virtual Box. Available online: https://www.virtualbox.org/ (accessed on 10 May 2020).
- VMware Server. Available online: https://www.vmware.com/ (accessed on 4 August 2020).
- Amazon Elastic Compute Cloud. Available online: https://aws.amazon.com/ec2 (accessed on 21 August 2020).
- Xu, B.; Zhao, C.; Hu, E.; Hu, B. Job scheduling algorithm based on Berger model in cloud environment. Adv. Eng. Softw. 2011, 42, 419–425. [Google Scholar] [CrossRef]
- Benoit, A.; Marchal, L.; Pineau, J.F.; Robert, Y.; Vivien, F. Offline and online master-worker scheduling of concurrent bags-of-tasks on heterogeneous platforms. In Proceedings of the 2008 IEEE International Symposium on Parallel and Distributed Processing, Miami, FL, USA, 14–18 April 2008; pp. 1–8. [Google Scholar]
- Dutta, D.; Joshi, R. A genetic: Algorithm approach to cost-based multi-QoS job scheduling in cloud computing environment. In Proceedings of the International Conference & Workshop on Emerging Trends in Technology, Mumbai, India, 25–26 February 2011; pp. 422–427. [Google Scholar]
- Ghanbari, S.; Othman, M. A priority based job scheduling algorithm in cloud computing. Procedia Eng. 2012, 50, 778–785. [Google Scholar]
- Potluri, S.; Rao, K.S. Quality of service based task scheduling algorithms in cloud computing. Int. J. Electr. Comput. Eng. 2017, 7, 1088. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Deng, M.; Zhang, R.; Zeng, B.; Zhou, S. A task scheduling algorithm based on QoS-driven in cloud computing. Procedia Comput. Sci. 2013, 17, 1162–1169. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Xu, X.; Tan, F.; Park, D.H. An utility-based job scheduling algorithm for cloud computing considering reliability factor. In Proceedings of the 2011 International Conference on Cloud and Service Computing, Hong Kong, China, 12–14 December 2011; pp. 95–102. [Google Scholar]
- Chang, R.S.; Lin, C.Y.; Lin, C.F. An adaptive scoring job scheduling algorithm for grid computing. Inf. Sci. 2012, 207, 79–89. [Google Scholar] [CrossRef]
- Varalakshmi, P.; Ramaswamy, A.; Balasubramanian, A.; Vijaykumar, P. An optimal workflow based scheduling and resource allocation in cloud. In Proceedings of the International Conference on Advances in Computing and Communications, Kochi, India, 22–24 July 2011; pp. 411–420. [Google Scholar]
- Gupta, P.K.; Rakesh, N. Different job scheduling methodologies for web application and web server in a cloud computing environment. In Proceedings of the 2010 3rd International Conference on Emerging Trends in Engineering and Technology, Goa, India, 19–21 November 2010; pp. 569–572. [Google Scholar]
- Xu, M.; Cui, L.; Wang, H.; Bi, Y. A multiple QoS constrained scheduling strategy of multiple workflows for cloud computing. In Proceedings of the 2009 IEEE International Symposium on Parallel and Distributed Processing with Applications, Chengdu, China, 10–12 August 2009; pp. 629–634. [Google Scholar]
- Li, L. An optimistic differentiated service job scheduling system for cloud computing service users and providers. In Proceedings of the 2009 Third international conference on Multimedia and Ubiquitous Engineering, Qingdao, China, 4–6 June 2009; pp. 295–299. [Google Scholar]
- Huang, Q.Y.; Huang, T.l. An optimistic job scheduling strategy based on QoS for cloud computing. In Proceedings of the 2010 International Conference on Intelligent Computing and Integrated Systems, Guilin, China, 22–24 October 2010; pp. 673–675. [Google Scholar]
- Ge, Y.; Wei, G. GA-based task scheduler for the cloud computing systems. In Proceedings of the 2010 International Conference on Web Information Systems and Mining, Sanya, China, 23–24 October 2010; Volume 2, pp. 181–186. [Google Scholar]
- Selvarani, S.; Sadhasivam, G.S. Improved cost-based algorithm for task scheduling in cloud computing. In Proceedings of the 2010 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, India, 28–29 December 2010; pp. 1–5. [Google Scholar]
- Ejarque, J.; Micsik, A.; Sirvent, R.; Pallinger, P.; Kovacs, L.; Badia, R.M. Job scheduling with license reservation: A semantic approach. In Proceedings of the 2011 19th International Euromicro Conference on Parallel, Distributed and Network-Based Processing, Ayia Napa, Cyprus, 9–11 February 2011; pp. 47–54. [Google Scholar]
- Guin, R.B.; Chakrabarti, S.; Tarafdar, C. Modelling & Simulation of a Smarter Job Scheduling System for Cloud Computing Service Providers and Users; Computer Science & Engineering Department Kalyani Government Engineering College: Kalyani, India, 2011.
- Kalapatapu, A.; Sarkar, M. Cloud computing: An overview. Cloud Computing: Methodology, Systems, and Applications; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–29. [Google Scholar] [CrossRef]
- Varghese, B.; Buyya, R. Next generation cloud computing: New trends and research directions. Future Gener. Comput. Syst. 2018, 79, 849–861. [Google Scholar] [CrossRef] [Green Version]
- Paton, N.; De Aragão, M.A.; Lee, K.; Fernandes, A.A.; Sakellariou, R. Optimizing utility in cloud computing through autonomic workload execution. Bull. Tech. Comm. Data Eng. 2009, 32, 51–58. [Google Scholar]
- Farid, M.; Latip, R.; Hussin, M.; Abdul Hamid, N.A.W. A Survey on QoS Requirements Based on Particle Swarm Optimization Scheduling Techniques for Workflow Scheduling in Cloud Computing. Symmetry 2020, 12, 551. [Google Scholar] [CrossRef] [Green Version]
- Ambursa, F.U.; Latip, R.; Abdullah, A.; Subramaniam, S. A particle swarm optimization and min–max-based workflow scheduling algorithm with QoS satisfaction for service-oriented grids. J. Supercomput. 2017, 73, 2018–2051. [Google Scholar] [CrossRef]
- Feitelson, D.G.; Rudolph, L.; Schwiegelshohn, U. Parallel job scheduling—A status report. In Workshop on Job Scheduling Strategies for Parallel Processing; Springer: New York, NY, USA, 2004; pp. 1–16. [Google Scholar]
- Liu, X.; Zha, Y.; Yin, Q.; Peng, Y.; Qin, L. Scheduling parallel jobs with tentative runs and consolidation in the cloud. J. Syst. Softw. 2015, 104, 141–151. [Google Scholar] [CrossRef]
- Baraglia, R.; Capannini, G.; Pasquali, M.; Puppin, D.; Ricci, L.; Techiouba, A.D. Backfilling strategies for scheduling streams of jobs on computational farms. In Making Grids Work; Springer: New York, NY, USA, 2008; pp. 103–115. [Google Scholar]
- Raz, D.; Avi-itzhak, B.; Levy, H.; Levy, H. Fairness Considerations in Multi-Server and Multi-Queue Systems; RUTCOR: Piscataway, NJ, USA; Rutgers University: New Brunswick, NJ, USA; Citeseer: Princeton, NJ, USA, 2005. [Google Scholar]
- Jasso, G. The theory of the distributive-justice force in human affairs: Analyzing the three central questions. In Sociological Theories in Progress: New Formulations; Sage: Newbury Park, CA, USA, 1989; pp. 354–387. [Google Scholar]
- Li, J.; Feng, L.; Fang, S. An greedy-based job scheduling algorithm in cloud computing. JSW 2014, 9, 921–925. [Google Scholar] [CrossRef]
- Jayadivya, S.; Bhanu, S.M.S. Qos based scheduling of workflows in cloud computing. Int. J. Comput. Sci. Electr. Eng. 2012, 1, 2315–4209. [Google Scholar]
- Zekrizadeh, N.; Khademzadeh, A.; Hosseinzadeh, M. An Online Cost-Based Job Scheduling Method by Cellular Automata in Cloud Computing Environment. Wirel. Pers. Commun. 2019, 105, 913–939. [Google Scholar] [CrossRef]
- Pandey, P.; Singh, S. Fuzzy logic based job scheduling algorithm in cloud environment. Comput. Model New Technol. 2017, 21, 25–30. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cloudlet ID | Class Type | Length | File Size | Output Size | Expected Time | Expected Bandwidth |
|---|---|---|---|---|---|---|
| 0 | 1 | 4000 | 2500 | 500 | 400 | - |
| 1 | 1 | 3000 | 2000 | 400 | 200 | - |
| 2 | 1 | 2000 | 800 | 300 | 150 | - |
| 3 | 1 | 5000 | 5000 | 2000 | 500 | - |
| 4 | 2 | 2000 | 800 | 300 | - | 2000 |
| 5 | 2 | 3000 | 2000 | 400 | - | 3000 |
| 6 | 2 | 800 | 300 | 300 | - | 1200 |
| 7 | 2 | 2500 | 1000 | 500 | - | 2000 |
| VmId | CPU | Memory | Bandwidth |
|---|---|---|---|
| 0 | 4 | 2048 | 2000 |
| 1 | 2 | 1024 | 3000 |
| 2 | 2 | 1024 | 1200 |
| 3 | 1 | 512 | 2500 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsaih, M.A.; Latip, R.; Abdullah, A.; Subramaniam, S.K.; Ali Alezabi, K. Dynamic Job Scheduling Strategy Using Jobs Characteristics in Cloud Computing. Symmetry 2020, 12, 1638. https://doi.org/10.3390/sym12101638
Alsaih MA, Latip R, Abdullah A, Subramaniam SK, Ali Alezabi K. Dynamic Job Scheduling Strategy Using Jobs Characteristics in Cloud Computing. Symmetry. 2020; 12(10):1638. https://doi.org/10.3390/sym12101638
Chicago/Turabian StyleAlsaih, Mohammed A., Rohaya Latip, Azizol Abdullah, Shamala K. Subramaniam, and Kamal Ali Alezabi. 2020. "Dynamic Job Scheduling Strategy Using Jobs Characteristics in Cloud Computing" Symmetry 12, no. 10: 1638. https://doi.org/10.3390/sym12101638