1. Introduction
Forecasting of nonstationary processes plays an important role in different areas such as weather forecasting or prediction in economics. Prediction of chemical processes has continued to arouse the interest of the research community in recent years. Forecasting of these processes can enable shorter downtimes and more effective maintenance of setups, which results in higher operation reliability and lower costs. Depending on the applied methods and features of the process, different routes for forecasting are possible. The classical statistical approaches are based on generative models such as AutoRegressive-Moving Average (ARMA) and AutoRegressive Integrated Moving Average (ARIMA) [
1,
2]. Thus, these models need strict assumptions concerning noise of the investigated process.
The majority of real processes, which are formed by monitoring systems do not meet these constraints. A system component
of real processes is often generated by chaotic dynamics and can be classified as a nonperiodical oscillatory process. The main feature of them is that the system component represents the realization of deterministic chaos [
3,
4,
5]. In this case the process to be forecasted represents an additive mixture of oscillatory non-periodic process with non-stationary noise. Examples of such processes are variations in gas-dynamic environment state vectors or dynamics of electrical field driven micromixers [
6], especially of hybrid rapid micromixers [
7]. The hybrid micromixer combines the advantages of asymmetric serpentine structures and the electrokinetic relay actuation. The mixing efficiency in an electrokinetic micromixer can be optimized at different relay frequencies, external electric potential and microchannel width.
The simplest analysis of independency and stationarity by checking statistical hypotheses, shows that the majority of real processes, generated by monitoring systems, do not possess the specified constraints [
8,
9,
10]. In particular, this applies to many technological processes in chemical, petrochemical and petroleum refining industries, which take place in non-stationary gas-dynamic environments and in microreactors.
Therefore, traditional extrapolative prediction methods of random processes are unsuitable if the dynamics of continuous processes change by unknown rules of parameters are to be predicted. However, due to the physical inertia, which is typical for real technological processes, some methods of analysis, widely used in tasks for pattern recognition and machine learning, may be suitable. In particular, the variants related to the k-nearest neighbors (k-NN) method are to be considered [
11,
12,
13,
14]. In this case, retrospective observations similar to the current state of the process are examined. If the search in the database was successful, then the subsequent observation intervals can be accepted as prototypes for the prediction. The proposed technique can be effectively used for traditional models with system components formed by an unknown deterministic process. For non-stationary flow processes with chaotic system components, the effects used as predictive prototypes may significantly differ from each other, as well as from current process dynamics. As a result, the algorithms for detecting such situations turn out to be weak qualifiers with a relatively low reliability level of obtained solutions.
The present article is focused on analysis of the forecast efficiency of non-stationary flow processes and possibility of its improvement based on joint processing of local solutions formed by weak classifiers.
2. Materials and Methods
2.1. Solving Method
A series of observations for a real physical non-stationary process is provided. All components are observable, no item imputation is provided. The simplest model of such a process can be defined by the known additive scheme of direct observations , with —random process imitating system noises or measurement errors and —system component of the real process. Then the detection of a piece of data similar to the current situation in retrospective data, ordered in time series databases, is provided. The current situation (current window) is defined as a time series of observations directly adjacent to the current moment of time, i.e., , with —size of the current window. The size of the current window is chosen a priori based on inertness of the forecast process. If there is no information about the process, then can be considered as a parameter for model fitting. Thereafter, a sliding window with length is formed and arrays of retrospective experimental data of size which are stored in a chronological database, are being sequentially scanned. At each scanning step, the similarity of the current situation to historical data from the sliding window according to (2) is evaluated. The situation with the highest level of similarity, i.e., minimum difference between current state window and scan window, forms the case precedent.
The main assumption of the considered method is a hypothesis that similar process changes can be observed at identical situations. In other words, the precedent effect can serve as a basis for building a prediction of the current situation.
This approach is quite intuitive, obviously, it works as a mental prognosis. In order to recognize the situation, the brain neural network reveals precedents which are stored in memory, and then based on analysis of retrospective effects, forms predictive control.
2.2. Formalization of the Problem Definition
The square distance between the current window and the sliding window , which is formed during the retrospective scanning of the database, is usually used as the measure of accuracy . Here is the size of the current and sliding windows. For nonstationary processes the size of the window and the forecast time interval can be specified during the model adaptation. However, for some type of processes prediction, interval is defined by process conditions and can’t be changed.
The simplest way of retrospective analysis can be reduced to the k-NN algorithm, choosing the sliding window at number
with a maximum similarity (the minimum discrepancy) to the current window
:
The root-mean-square deviation (RMSD) was used as measure of accuracy of a current window to a sliding window:
In this case the corresponding consequence of the sliding window is used as a forecast
, i.e., the observation value from the database located at interval
from the scan window border
Orientation to the nearest neighbor according to k-NN method with the chosen approximation measure under conditions of chaotic dynamics of a system component can lead to unstable results. In a more general case, averaging of effects on a group of
analogs
with the smallest values of the metric
can be used as prediction i.e.,
A disadvantage of the latter ratio is the equivalence of all analogs, regardless of their similarity to the current window
. In this context, it is reasonable to use a weighted sum of effects with weights as a forecast, which are proportional to a degree of similarity. If for (3) the weight
is chosen, then weights for other analogs can be defined
. The weighted value of the forecast is determined from the ratio:
2.3. Special Solution Details
It should be noted that the continuous search for analogs which meet criterion (2) can lead to the formation of similarity groups, which consist of several standing scan windows. Consequently, the proposed extension of the k-NN method practically does not bring new information and cannot improve the prediction quality.
Then, it is necessary to modify the selection of analogs obtained during the database scanning. For this case, a computational scheme based on an artificially formed area, prohibiting the selection of analogs, which sequentially includes —neighborhoods of the counts corresponding to the selected analogs, can be introduced. In cases where the next closeness metric increases and the scanning window appears in the prohibited area, it cannot be used as an analog. As a first approximation can be selected equal to the scan window .
2.4. Preliminary Smoothing
Preliminary smoothing of the predicted process is a significant feature when searching for analogs. Dynamic smoothing allows for an increase in the reliability of intermediate solutions for the selection of analogous situations.
The simplest exponential smoothing was used as preliminary smoothing:
where
—the smoothing factor, 0 <
< 1;
—the smoothed statistic;
—the current observation;
—the previous smoothed statistic. The smoothing factor
was used. Generally,
can be included in the parametric optimization.
3. Results and Discussion
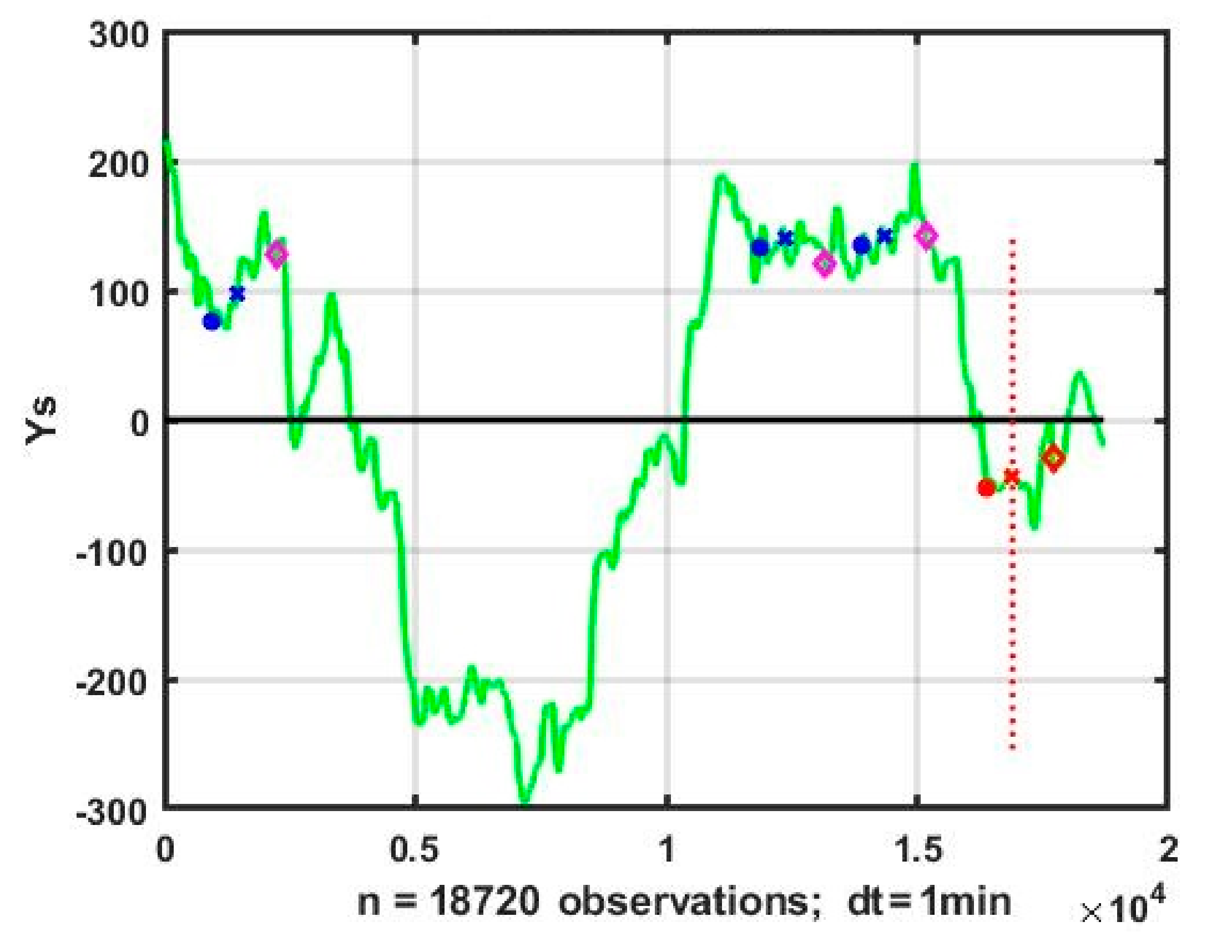
An example of selection of an analogous situation is shown in
Figure 1. The vertical red line marks the zone of retrospective data used to generate a precedent prediction from the working zone on which the algorithm is tested. Beginnings and ends of intervals corresponding to the current situation and analogs are marked with stars and crosses, prediction values—with diamonds. The first analog shows an upward trend, which has already passed its maximum and demonstrates downward signs, while the second and third analogues have an unstable sideway. It is reasonable to avoid making predictive decisions and, if necessary, to conclude about a sideway (i.e., no obvious upward or downward trend).
From the perspective of machine learning, the proposed approach represents a solution of the forecasting problem based on weak machine classifiers. Low efficiency of classifiers is connected with the nature of observation time series, including chaotic system component and non-stationary random noises.
Figure 2 shows the expanded charts of the current state window (
Figure 2a) and analog windows (
Figure 2b–d). The solid lines in
Figure 2b–d represent analogs to the chart in
Figure 2a, which is imposed with a dot line. It allows for graphical verification of the problem solution, based on square metrics. The window in
Figure 2b is a precedent, obtained using the k-NN method, i.e., it has the greatest similarity to the current situation presented in the
Figure 2a. In this case, the degree of similarity is estimated with the measure (2).
For quality improvement it is necessary to obtain the degree of similarity for different analogs. In particular, the second analog (
Figure 1), provides a poor prediction quality because its degree of similarity is only 0.49. This means that preliminary definition of the numbers of analog situations for non-stationary processes does not improve the quality of the forecast. Therefore, the method should be supplemented with the second level analog selection defined by allowed similarity threshold.
On the other hand, it is necessary to consider the size of the forecast interval for a given class of processes. Obviously, reducing of a forecast interval allows the acquisition of more accurate results. For example, reducing the forecast interval from 200 to 100 counts allowed for a reduction in the prediction error in the considered example by 17.5% and to get a quite satisfactory solution for the task being solved.
However, reducing the forecast time is not always acceptable. For example, by estimation of quality parameters of the output flow in a technological process by values of state parameters, the forecast interval is determined by the production structure and cannot be modified.
Improvement of prediction quality can be achieved by using a system of distributed forecasters based on weak classifiers with subsequent joint processing. The classifiers based on (3)–(5) can be used independently, with the solution chosen to match the forecasting scheme with the most accurate prediction in the sliding observation area.
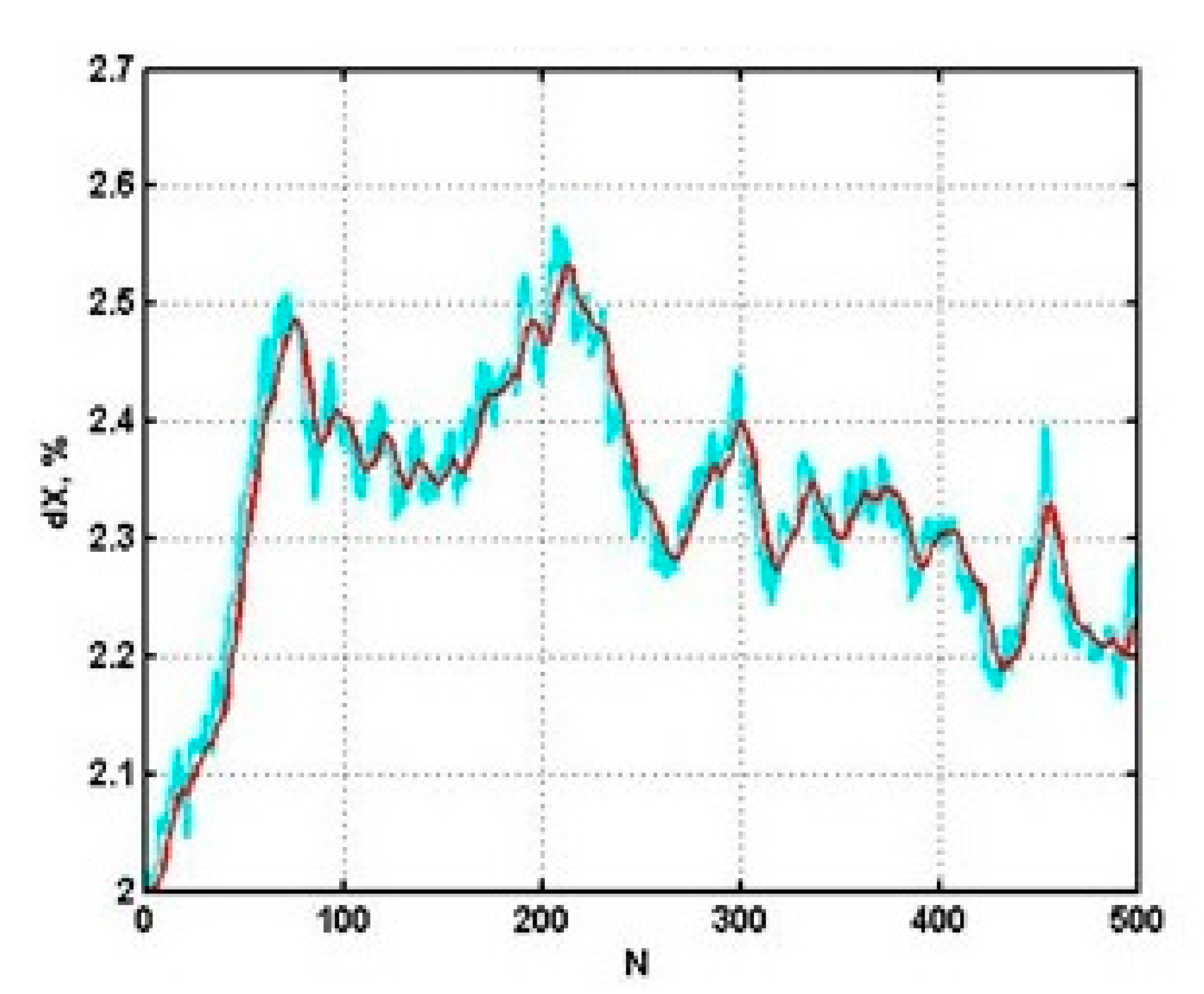
This scheme allows for the acquisition of quite satisfactory results for a certain class of applied tasks. For example, current temperature can be well predicted in a flow tube reactor used for production of aromatic hydrocarbons (
Figure 3). At the same time the most frequent preference was given to the computational scheme with three closest neighbors with selection of analogs at the similarity level less than 50% and exponential smoothing with first order astatism and
.
Within the limits of the considered scheme with nonstationary dynamics and chaotic system component, numerical comparison of quality of the prediction algorithms based on different variants of weak classifiers is possible. Variants of prognosis based on computational experiments can be formulated:
P1. Precedent prediction (using the nearest-neighbor method) (3);
P2. Average forecast based on three analogs (4);
P3. Weighted average forecast using the three analogs (5);
P4. Average forecast for analogs with similarity degree not lower than .
Four different one-day intervals (1440 counts) were considered. For each interval four variants of forecast P1–P4 were performed. The prediction quality was compared according to:
Average absolute deviation
Average square of deviations .
The values of the presented predictive quality indicators for four different one-day observation intervals and 4 prediction alternatives P1–P4 are presented in
Table 1.
It can be seen that the forecast by a single precedent provides a lower accuracy than an average forecast by three analogs. The weighing of analogs in proportion to the degree of their similarity to precedent, practically affects the result compared to standard averaging. Additional selection of analogs at an acceptable similarity , decreased the accuracy of the forecast.
Thus, the variant with standard averaging of analogs was considered as the most preferable forecast strategy for the considered data. In this case the analogs with the size of the scanning window were used.
The presented values of prediction errors are quite high. Even in the best case for averaging based on three analogs the relative accuracy of the forecast varies around 10–25%. The reason for the low accuracy, is caused by the non-stationarity of the system noise and the chaotic nature of the observation time sequences.
The degree of prediction applicability with such accuracy is dependent on the task. In general, an increase in forecast accuracy is achieved by applying structural and parametric adaptation of the used algorithm. Structural adaptation can be reduced for selection of the most preferable number of analogs, from the database of retrospective observations.
The main advantage of the presented technique of forecasting nonstationary processes is the ability to detect and predict discontinuous changes in the controlled process. This possibility can be realized only if the accumulated data already contain changes, which need to be predicted.
For non-stationary dynamics of a more complex nature, which do not have mass or energy inertia (e.g., fast processes in microreactors with high controllability), it was impossible to make an effective prediction based on the considered computational scheme. Further studies based on examination of external factors and multidimensional statistical metrics are necessary.





{kind=link}
{kind=link}
{kind=link}