Dynamic Partitioning Supporting Load Balancing for Distributed RDF Graph Stores


Abstract
:1. Introduction
- We propose a detailed algorithm for creating clusters and subclusters, and propose a partitioning method using clusters and subclusters.
- We analyze existing and proposed methods according to various criteria such as partitioning policy, replication policy, load discrimination, partition size, and partitioning condition.
- We demonstrate the improvement of the proposed method by comparing the performance of the proposed method with that of the existing method as well as evaluating its own performance.
2. Related Work
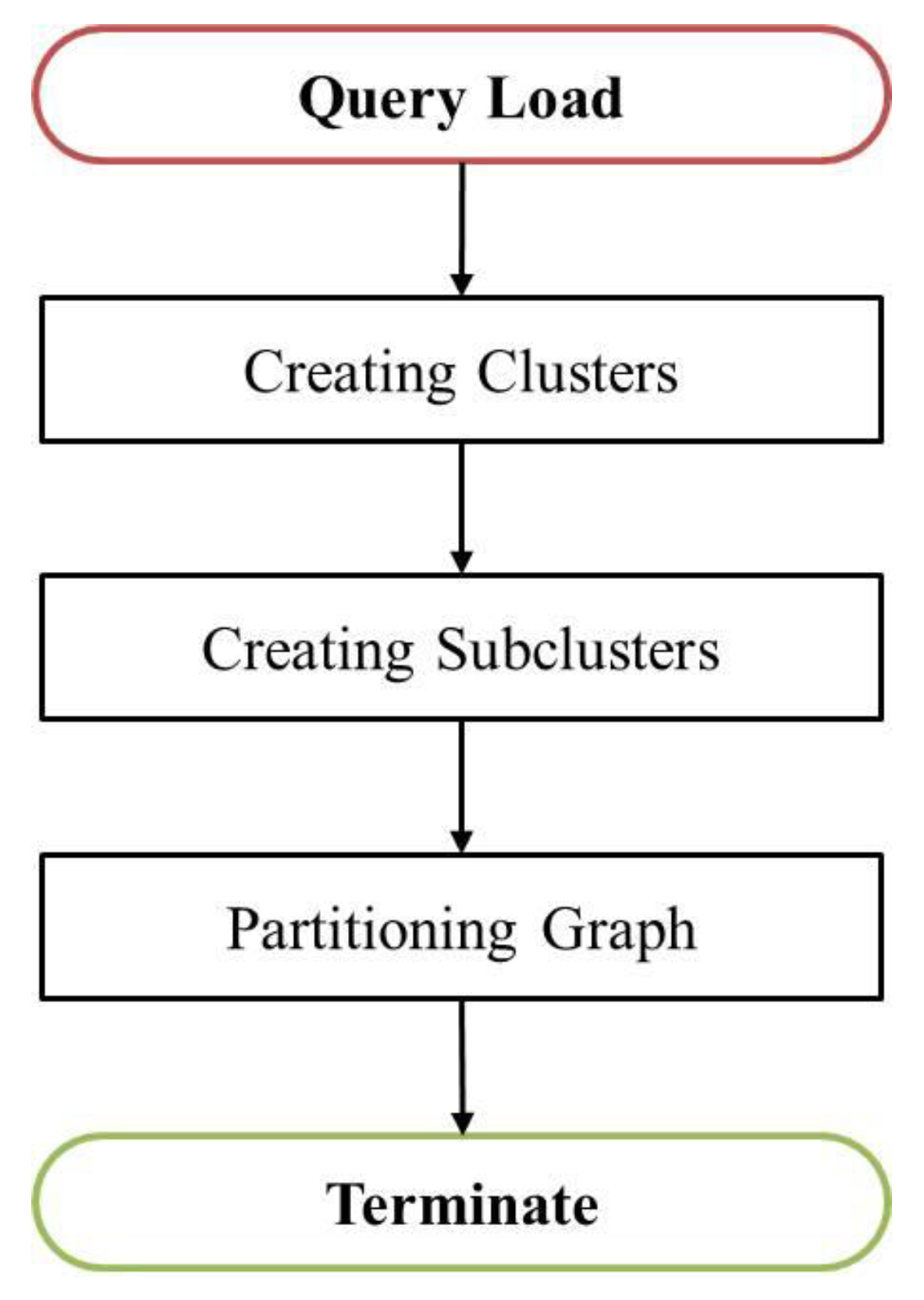
3. The Proposed Dynamic Partitioning Method
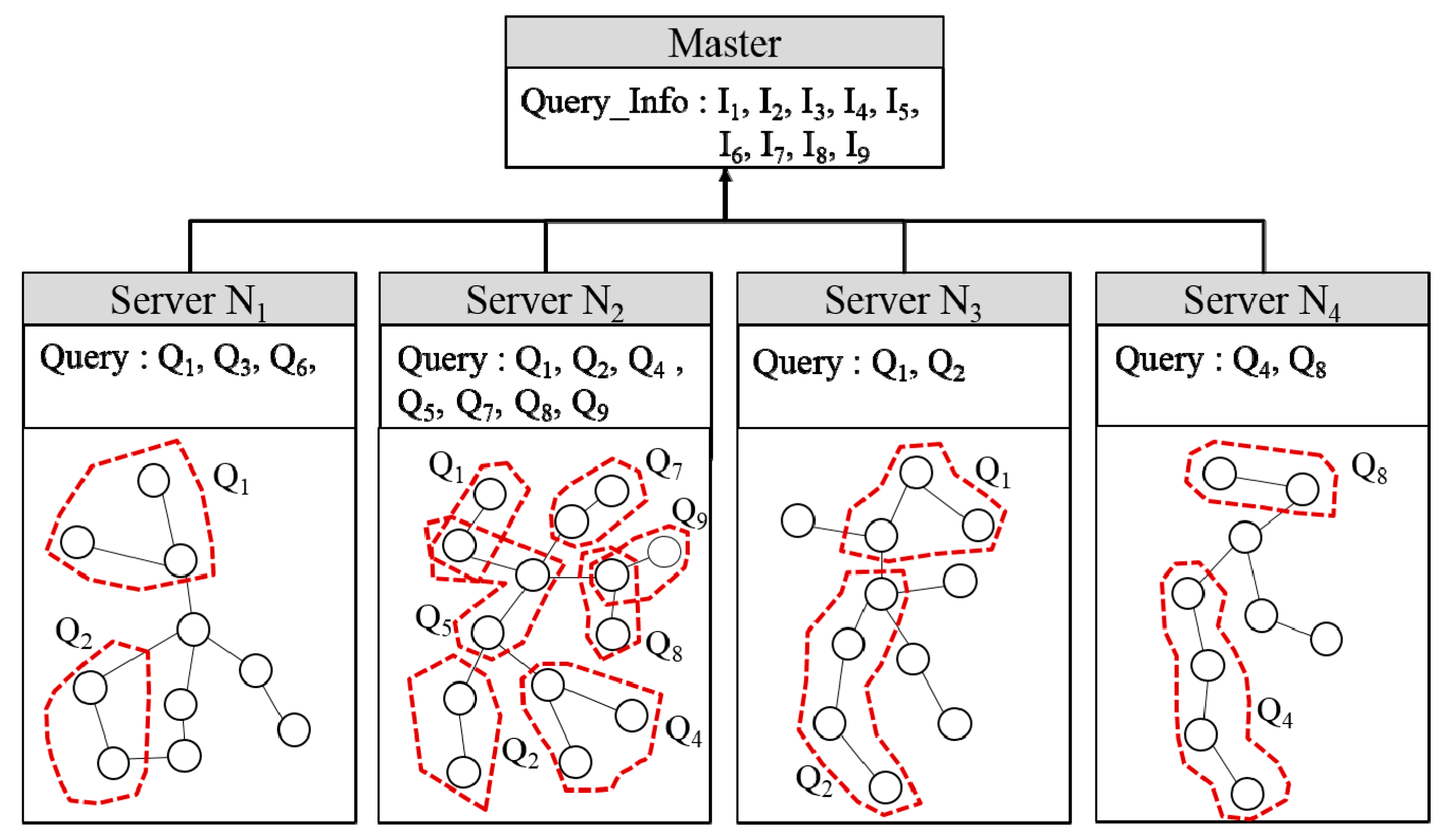
3.1. Architeucture
3.2. Statistical Data
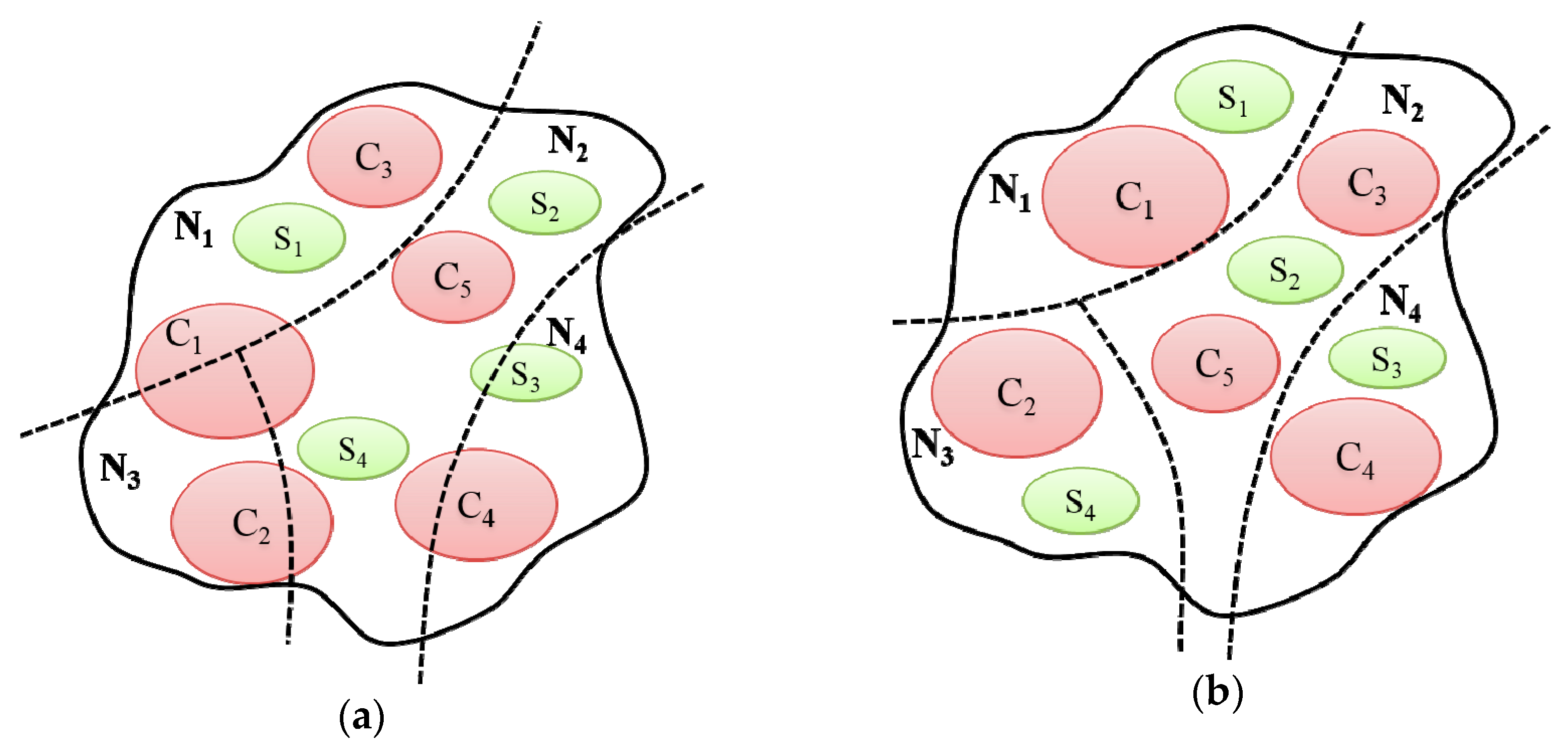
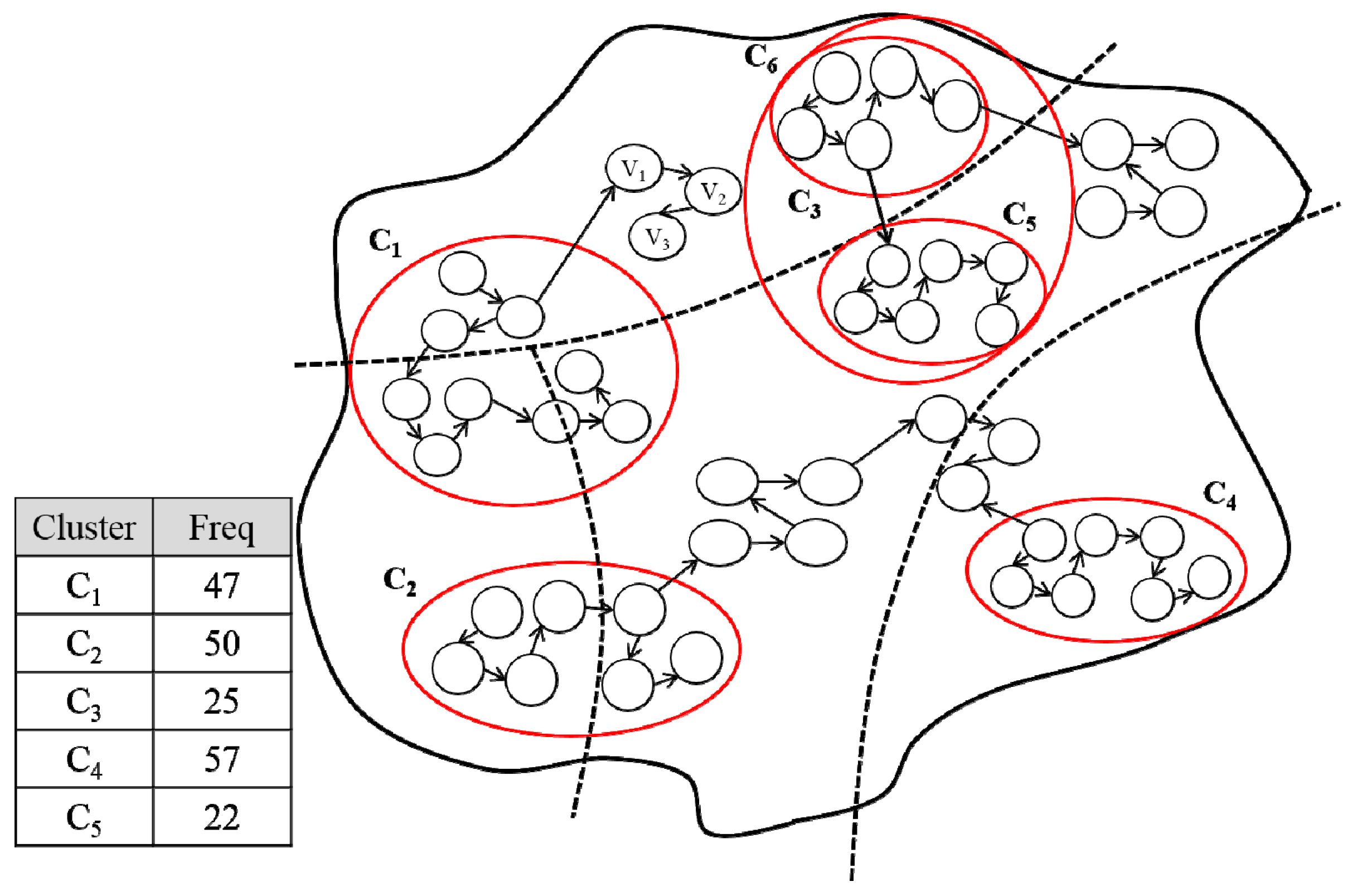
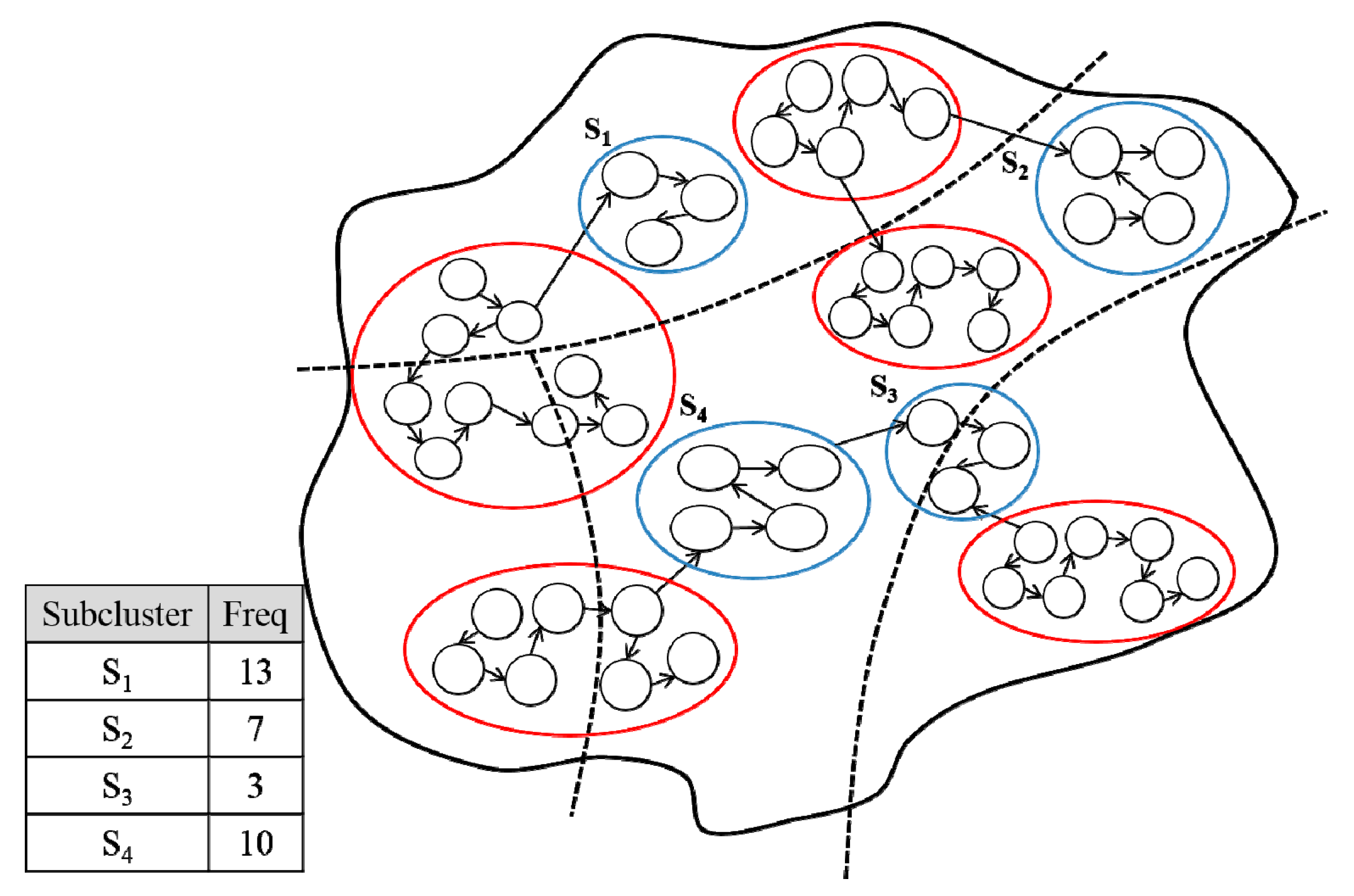
3.3. Cluster Creation
| Algorithm 1 Generating Clusters | |
| 1: | procedure Creating_Cluster (Statistical_data ) |
| 2: | sort Query_data in data frequency based on descending order |
| 3: | for CN ∈ CntServer do |
| 4: | new ClusterCN |
| 5: | for QDN ∈ CntQuery_data do |
| 6: | add Query_dataQDN in ClusterCN |
| 7: | if Freq_Query_dataQDN ≤ AvgCF then exit |
| 8: | add ClusterCN in Clusters |
| 9: | return Clusters |
3.4. Subcluster Creation
| Algorithm 2 Generating Subclusters | |
| 1: | procedure Creating_Subcluster (Statistical_data, Clusters) |
| 2: | for SN ∈ CntClusters do |
| 3: | new Sub_clusters |
| 4: | for QDN ∈ Cnt_QD_2HCSN do |
| 5: | if Freq_Query_dataQDN ≥ 1 |
| 6: | add Query_dataQDN in Sub_clusters |
| 7: | add Sub_clusterSN in Sub_clusters |
| 8: | return Sub_clusters |
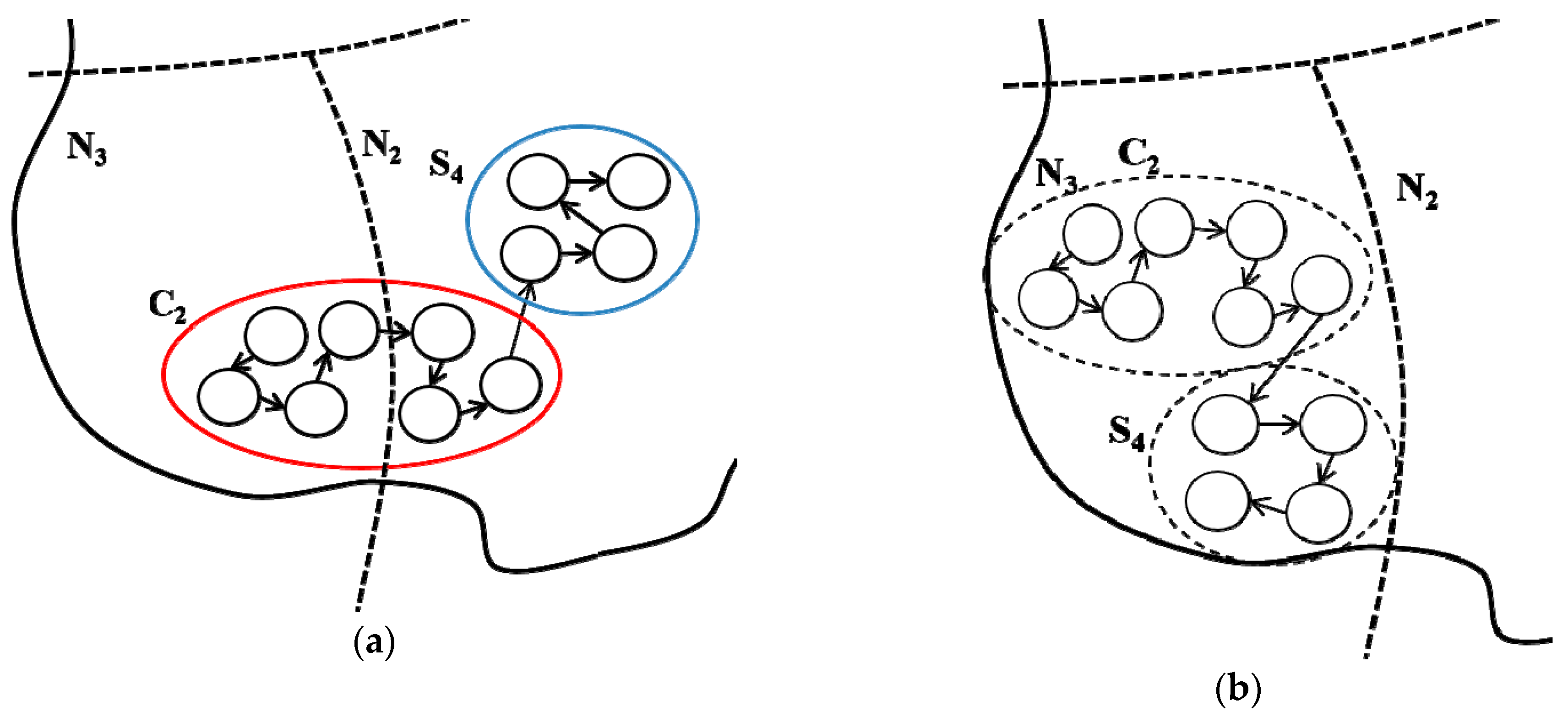
3.5. Graph Partitioning
| Algorithm 3 Partitioning Graphs | |
| 1: | procedure Partitioning_Graph (Clusters, Sub_clusters) |
| 2: | for PCSN ∈ CntClusters do |
| 3: | new PartitionPCSN |
| 4: | add ClustersPCSN in PartitionPCSN |
| 5: | for SN ∈ CntSub_clustersPCSN do |
| 6: | if PSizemin < Size_PartitionPCSN < PSizemax and Freq_PartitionPCSN ≤ AvgSF |
| 7: | add Sub_clustersPCSN_SN in PartitionPCSN |
| 8: | add PartitionPCSN in Partitions |
| 9: | return Partitions |
4. Performance Evaluation
4.1. Analysis
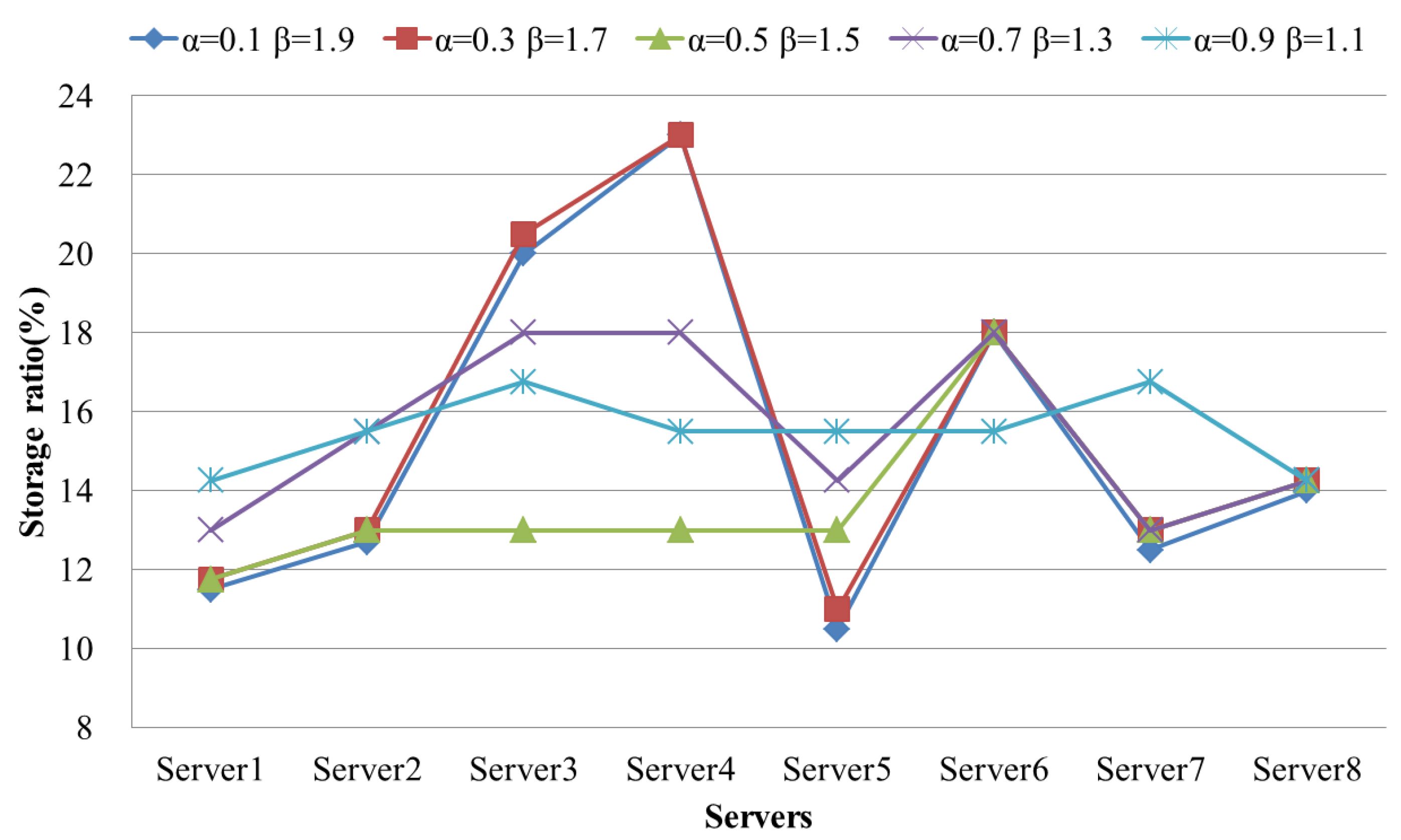
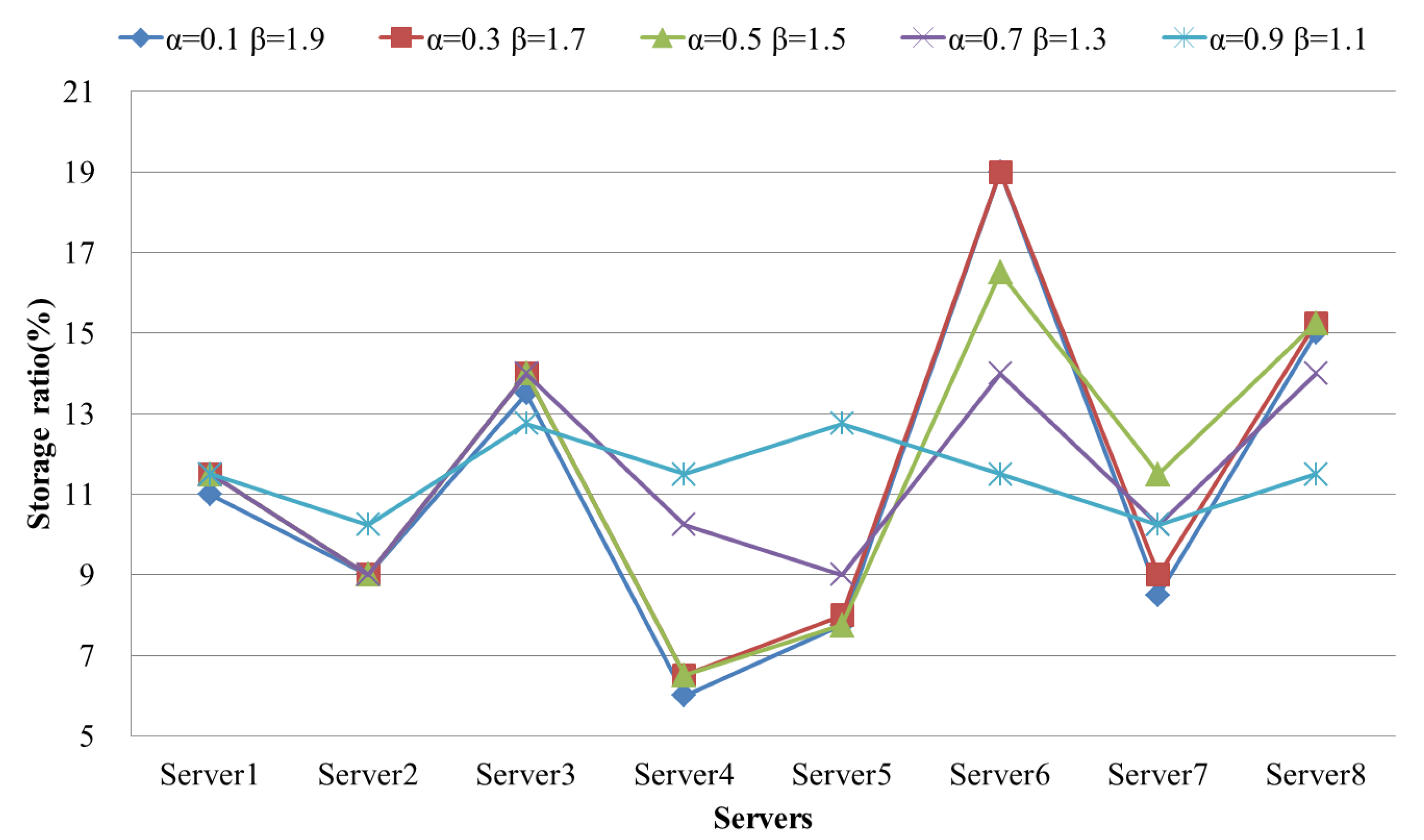
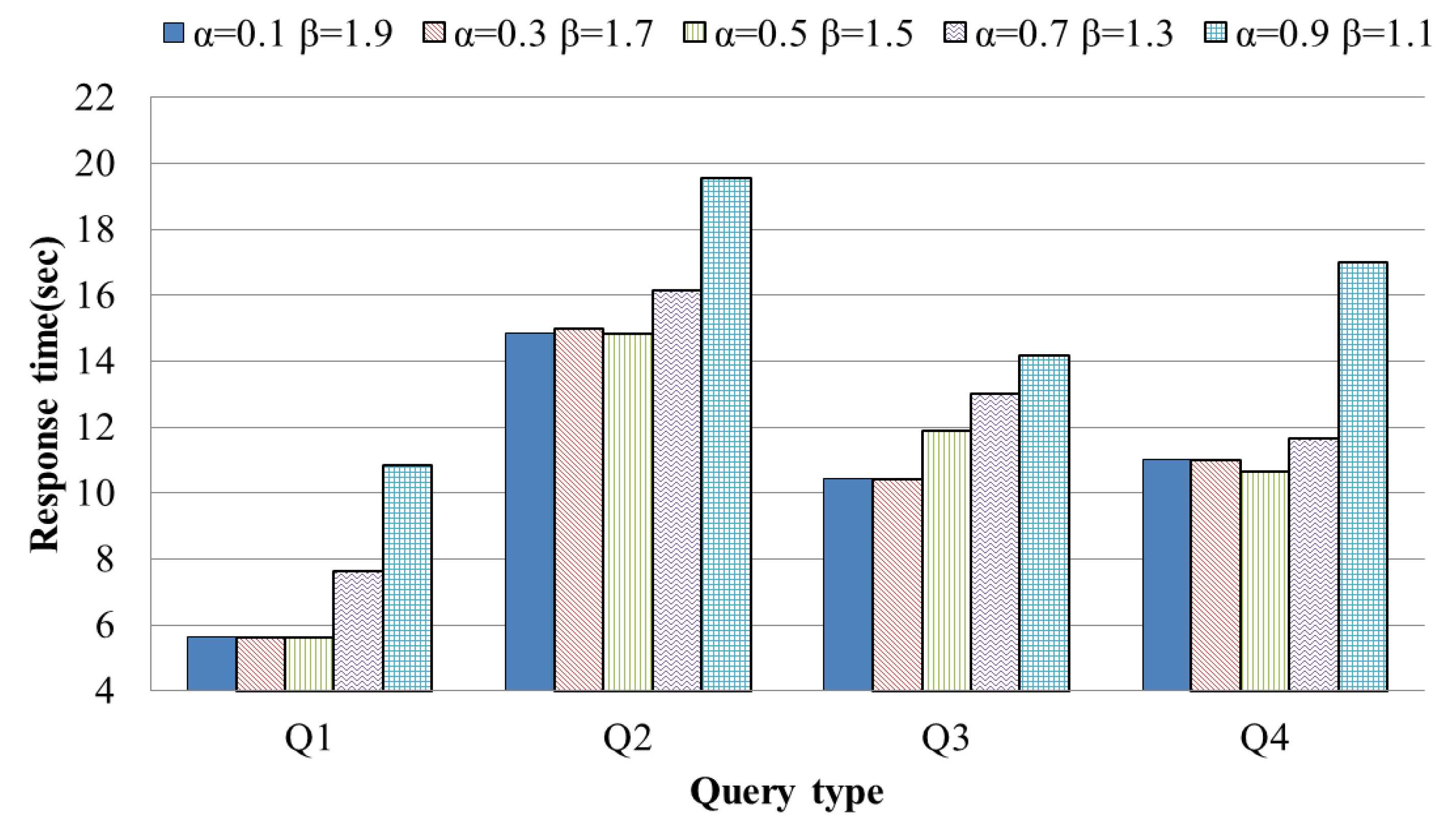
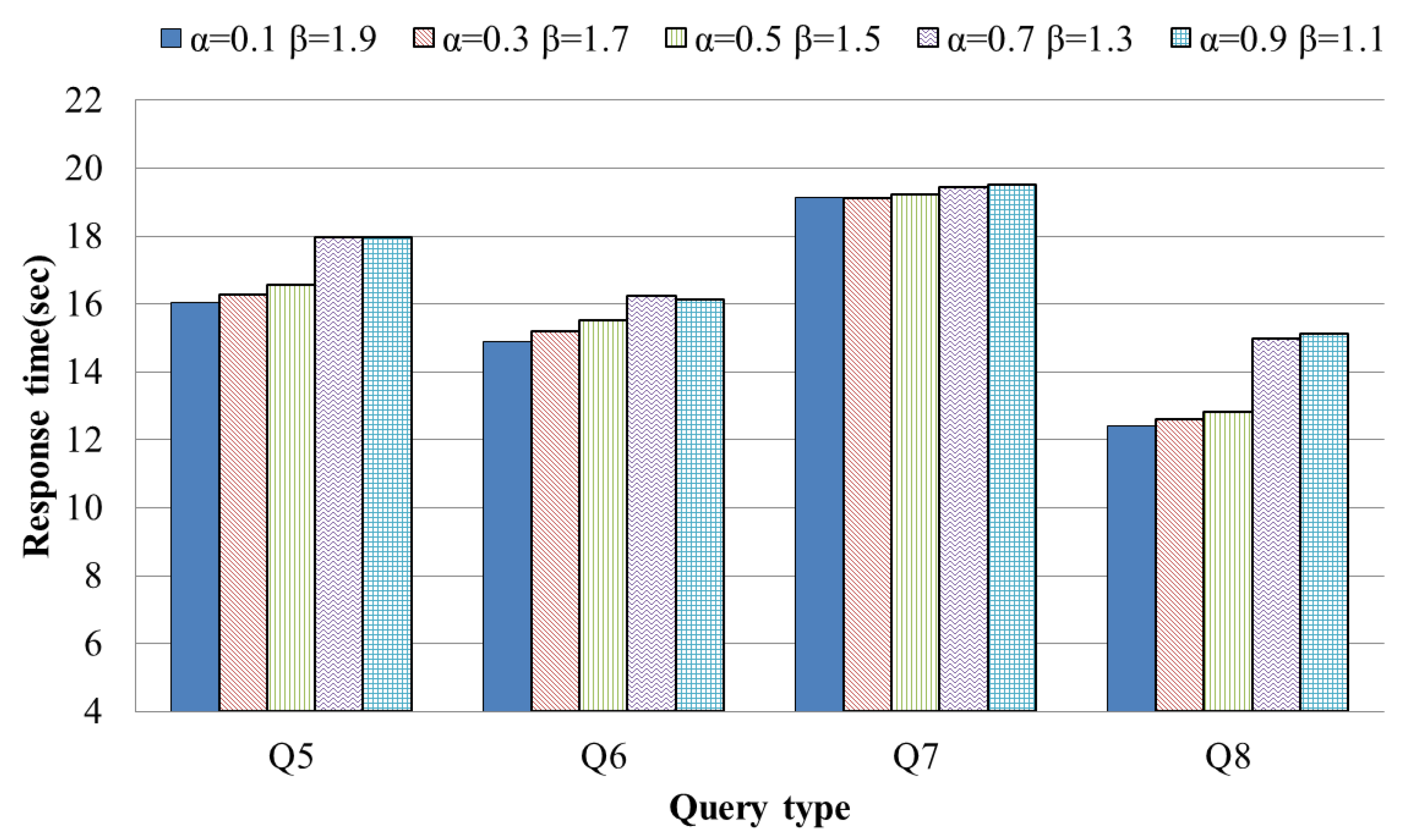
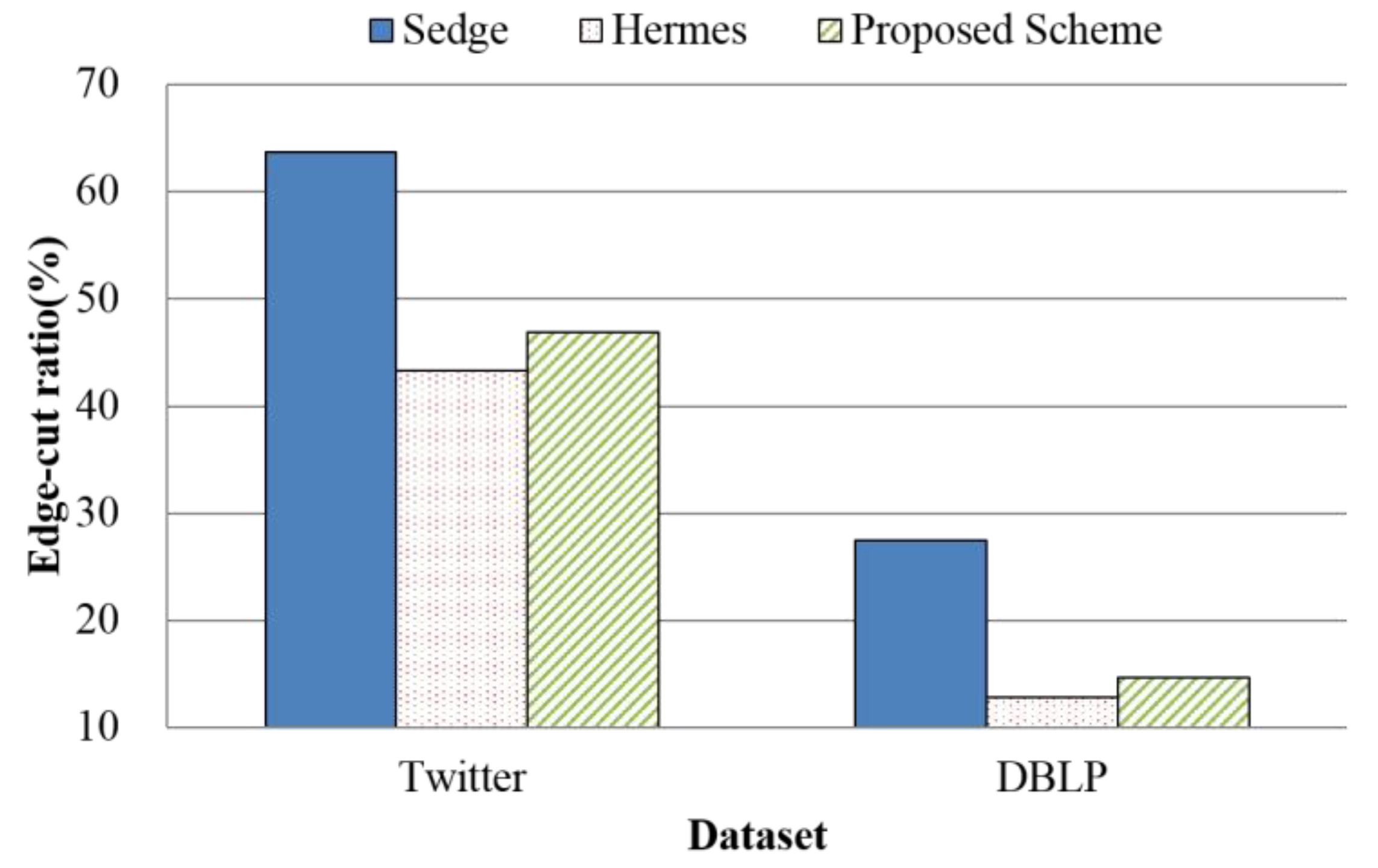
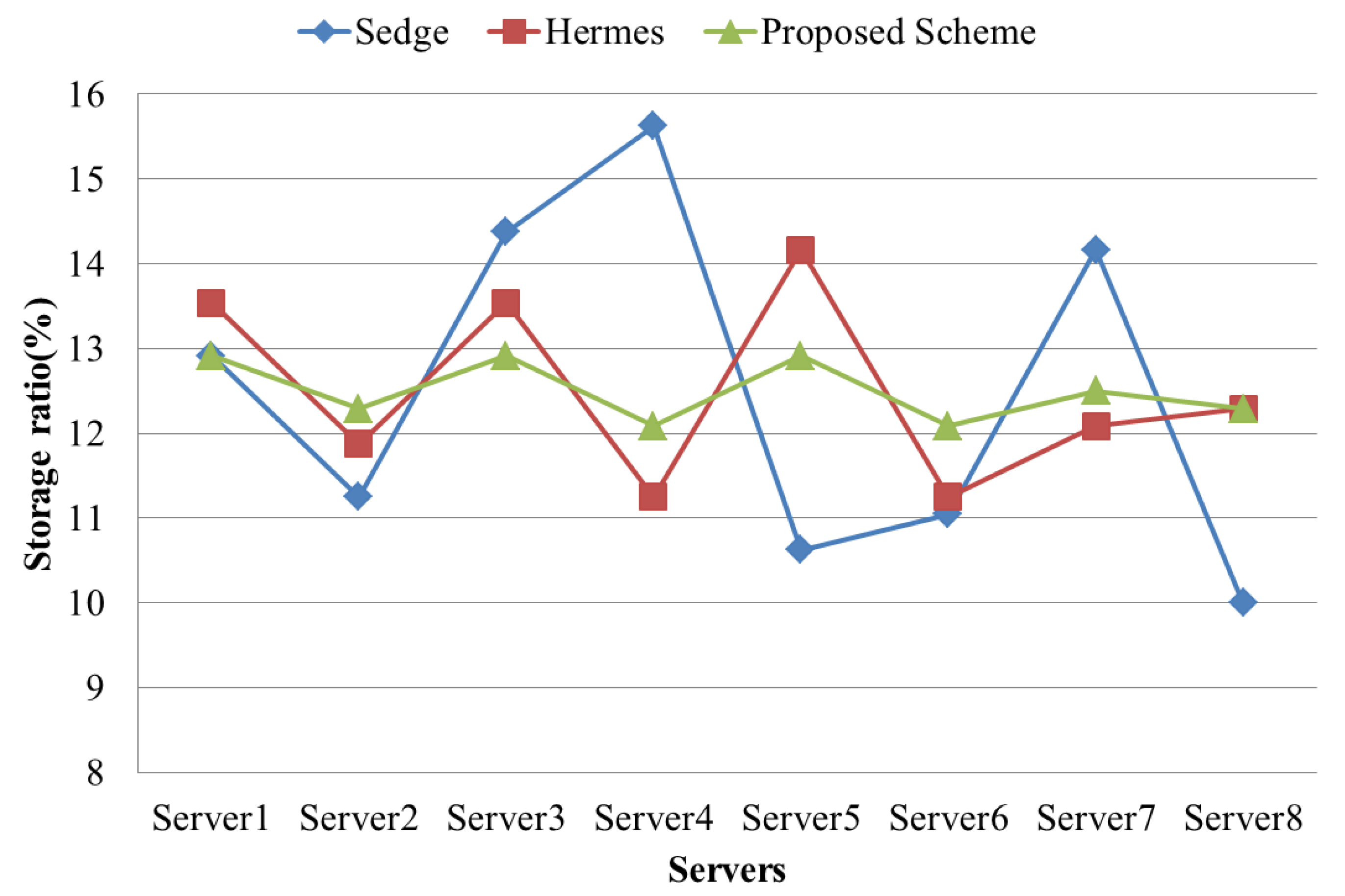
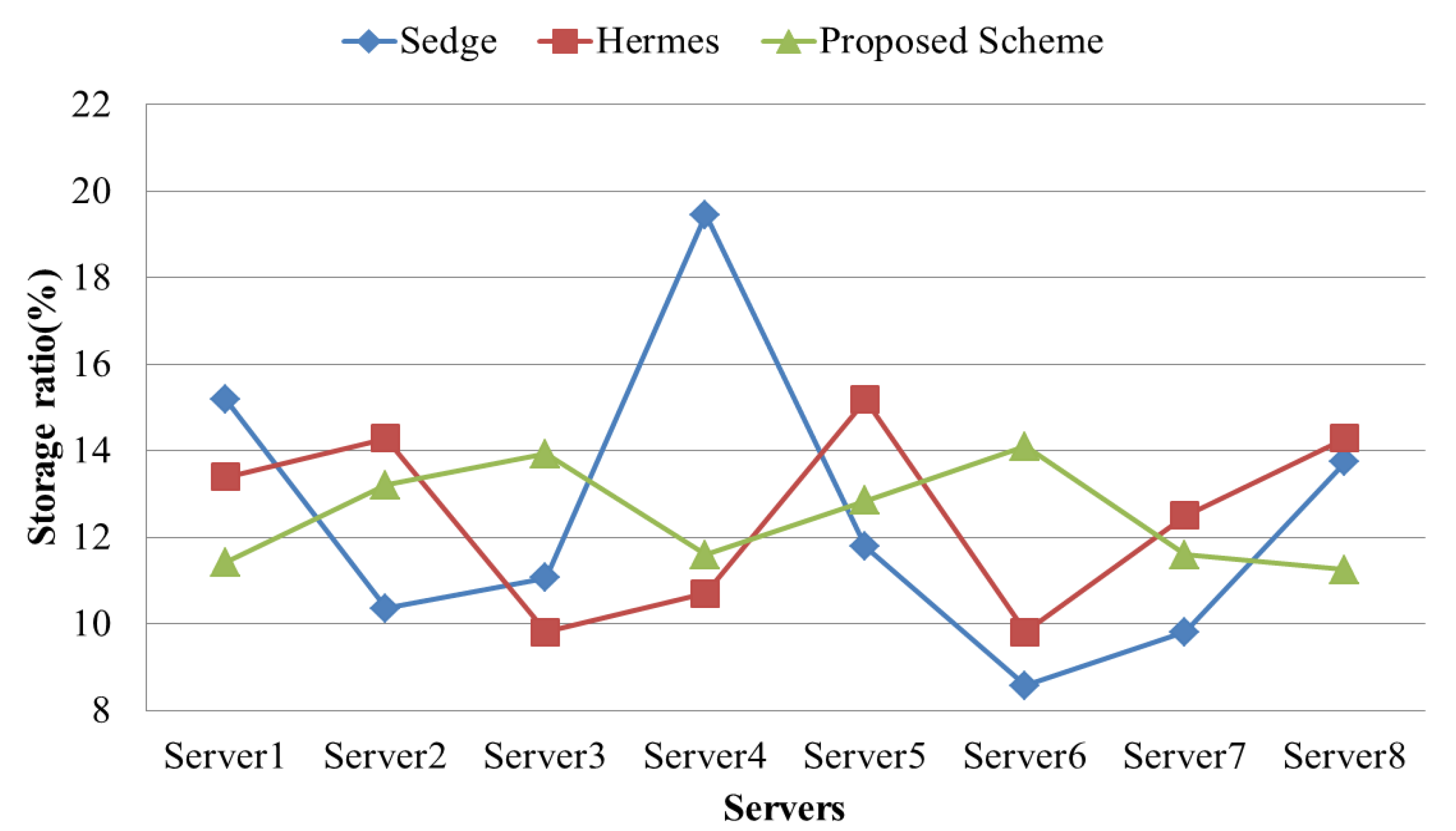
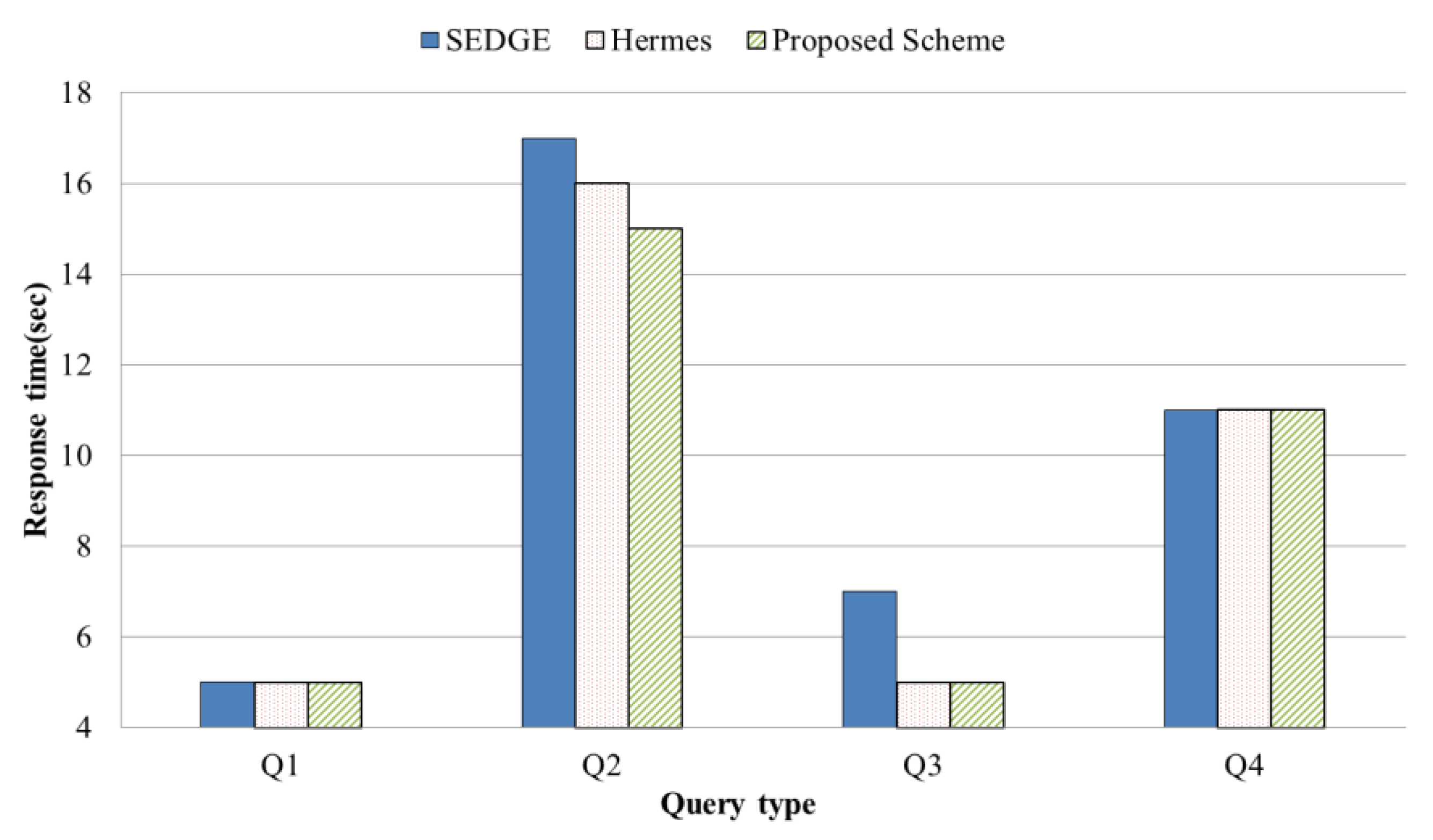
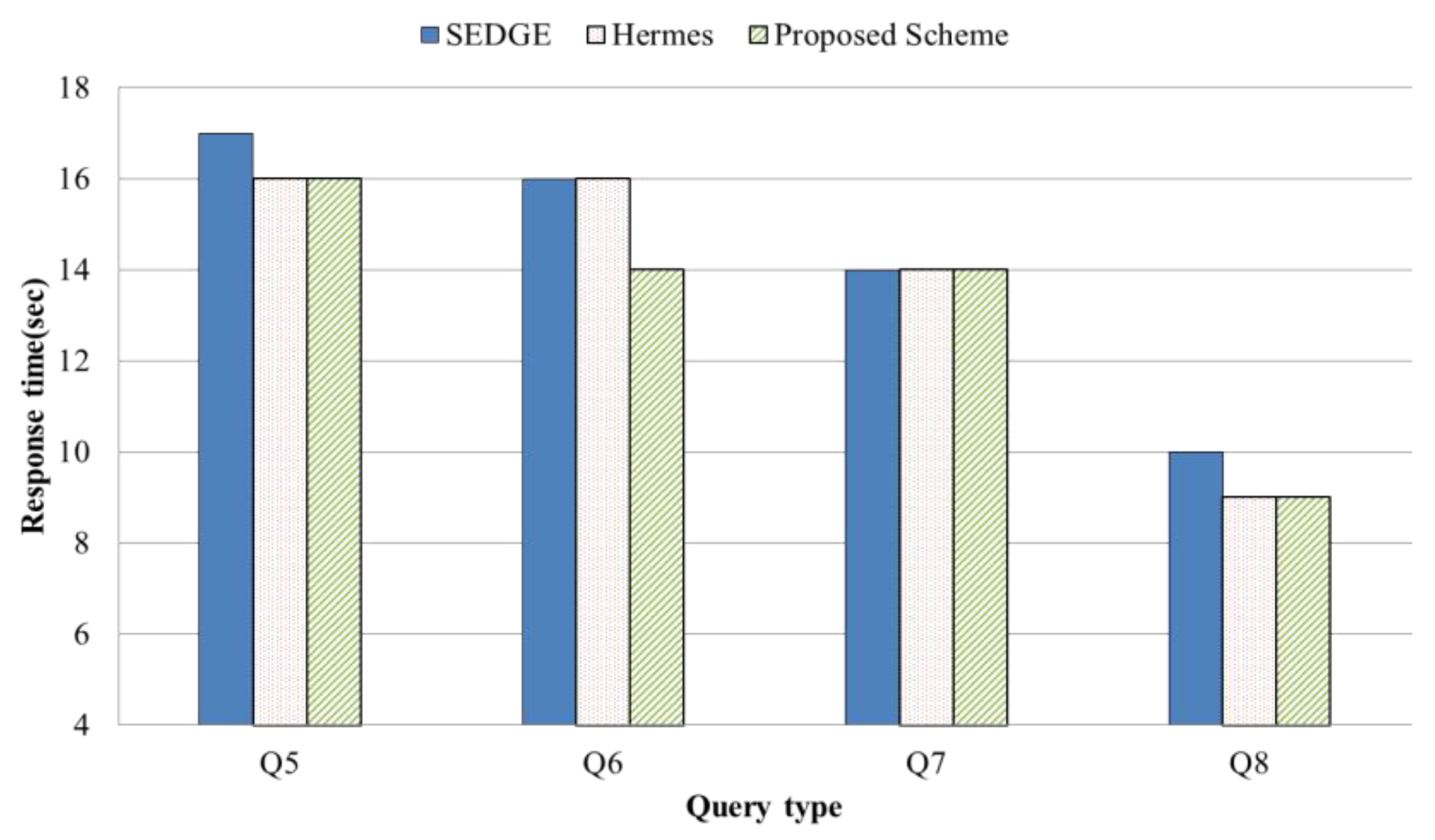
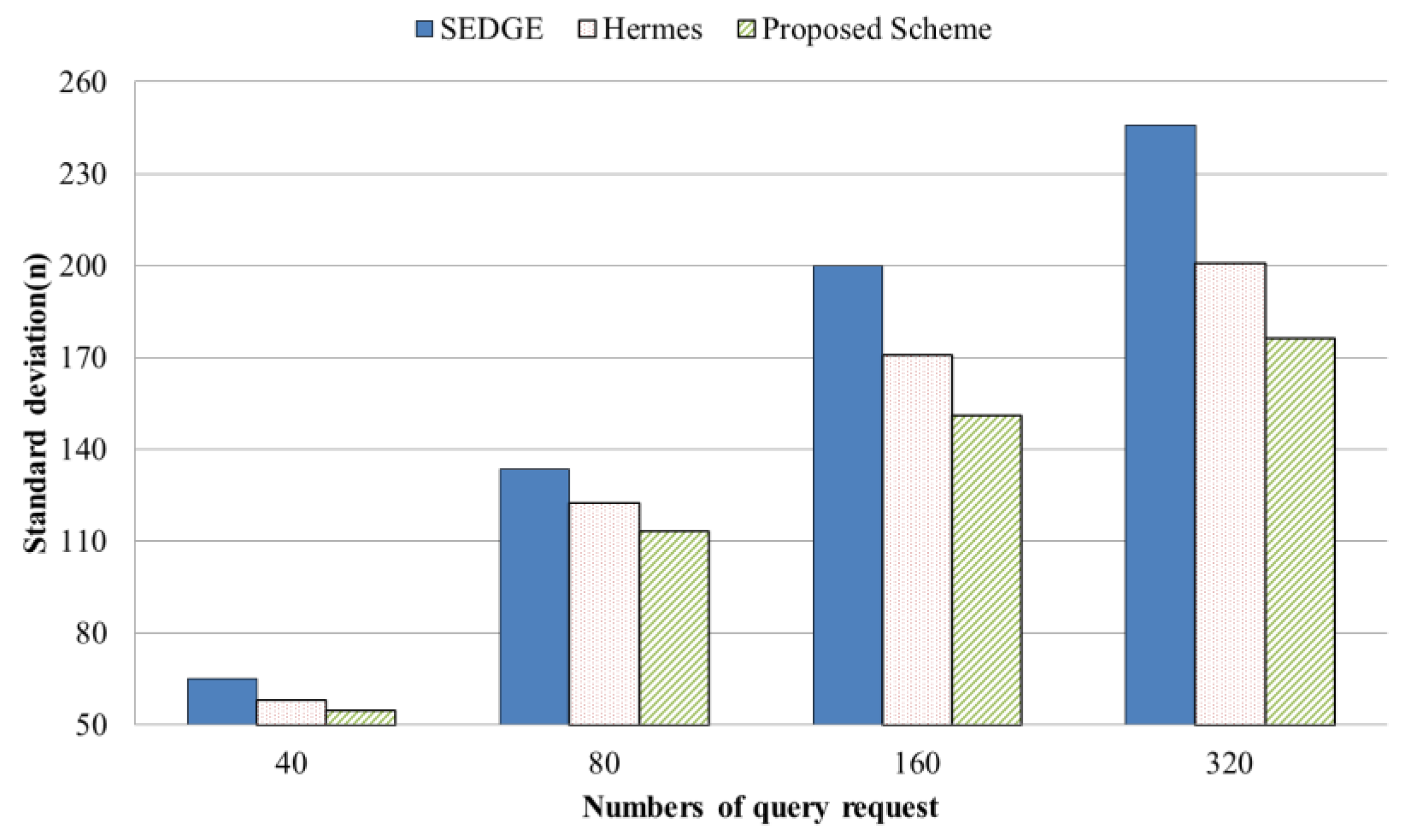
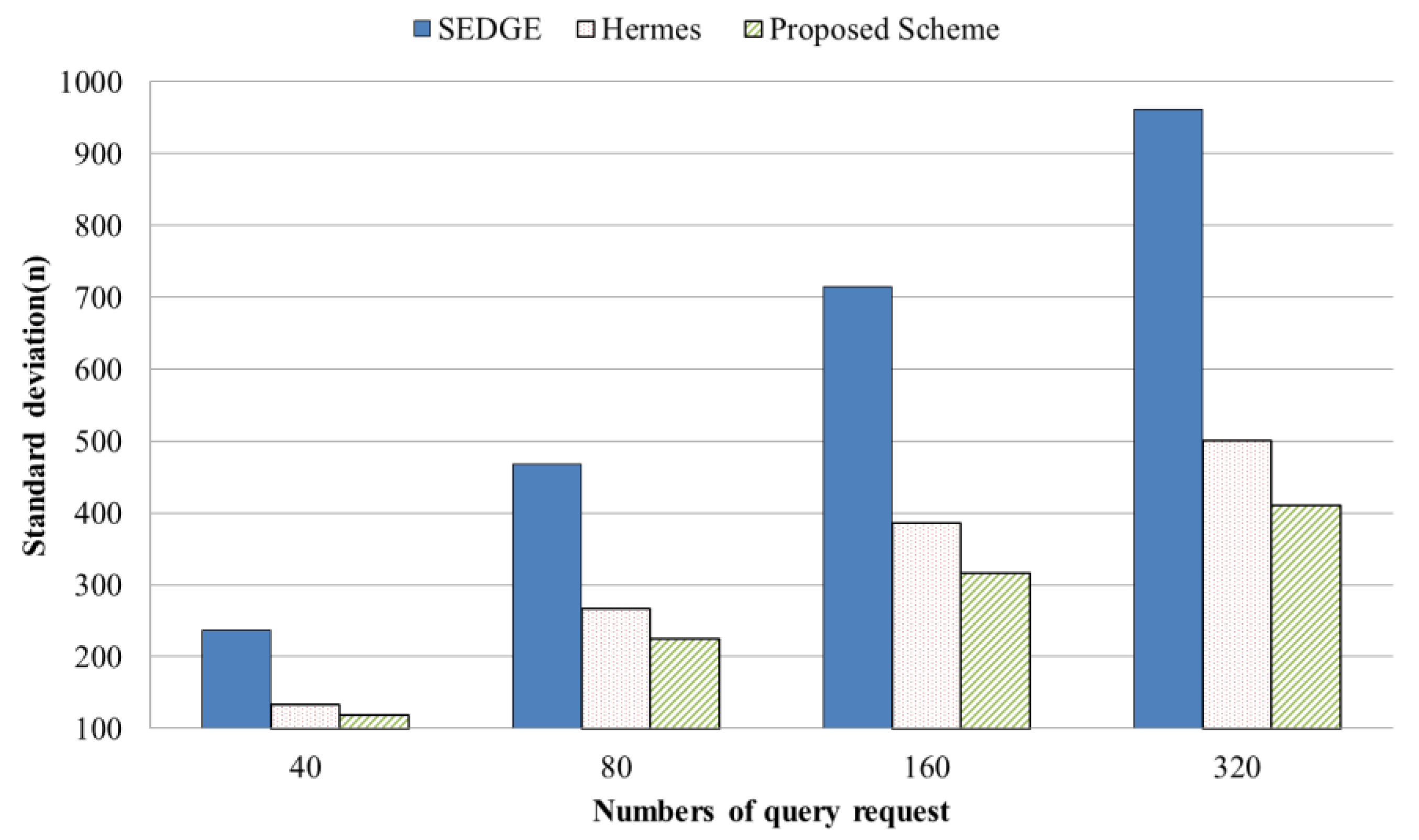
4.2. Evaluation Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Decker, S.; Melnik, S.; Harmelen, F.; Fensel, D.; Klein, M.C.A.; Broekstra, J.; Erdmann, M.; Horrocks, I. The Semantic Web: The Roles of XML and RDF. IEEE Internet Comput. 2000, 4, 63–73. [Google Scholar] [CrossRef]
- Gomez-Perez, A.; Corcho, O. Ontology Languages for the Semantic Web. IEEE Intell. Syst. 2002, 17, 54–60. [Google Scholar] [CrossRef]
- Arenas, M.; Pérez, J. Querying Semantic Web Data with SPARQL. In Proceedings of the ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Athens, Greece, 12–16 June 2011; pp. 305–316. [Google Scholar]
- Huang, J.; Abadi, D.J.; Ren, K. Scalable SPARQL Querying of Large RDF Graphs. Proc. VLDB Endow. 2011, 4, 1123–1134. [Google Scholar]
- Kim, K.; Moon, B.; Kim, H. R3F: RDF triple filtering method for efficient SPARQL query processing. World Wide Web 2015, 18, 317–357. [Google Scholar] [CrossRef]
- Neumann, T.; Weikum, G. The RDF-3X engine for scalable management of RDF data. VLDB J. 2010, 19, 91–133. [Google Scholar] [CrossRef]
- Frey, J.; Müller, K.; Hellmann, S.; Rahm, E.; Vidal, E. Evaluation of metadata representations in RDF stores. Semant. Web 2019, 10, 205–229. [Google Scholar] [CrossRef] [Green Version]
- Bae, M.; Kihm, J.; Kang, S.; Oh, S. Indexing and querying algorithm based on structure indexing for managing massive-scale RDF data. J. Intell. Fuzzy Syst. 2014, 27, 575–587. [Google Scholar]
- Hammoud, M.; Rabbou, D.A.; Nouri, R.; Beheshti, S.; Sakr, S. DREAM: Distributed RDF Engine with Adaptive Query Planner and Minimal Communication. Proc. VLDB Endow. 2015, 8, 654–665. [Google Scholar] [CrossRef]
- Fernández, J.D.; Umbrich, J.; Polleres, A.; Knuth, M. Evaluating query and storage strategies for RDF archives. Semant. Web 2019, 10, 247–291. [Google Scholar] [CrossRef] [Green Version]
- Wylot, M.; Hauswirth, M.; Cudré-Mauroux, P.; Sakr, S. RDF Data Storage and Query Processing Schemes: A Survey. ACM Comput. Surv. 2018, 51, 84. [Google Scholar] [CrossRef]
- Pan, Z.; Zhu, T.; Liu, H.; Ning, H. A survey of RDF management technologies and benchmark datasets. J. Ambient Intell. Hum. Comput. 2018, 9, 1693–1704. [Google Scholar] [CrossRef]
- Özsu, M.T. A survey of RDF data management systems. Front. Comput. Sci. 2016, 10, 418–432. [Google Scholar] [CrossRef] [Green Version]
- Ouksili, H.; Kedad, Z.; Lopes, S.; Nugier, S. Pattern oriented RDF graphs exploration. Data Knowl. Eng. 2018, 113, 171–183. [Google Scholar] [CrossRef]
- Zou, L.; Özsu, M.T. Graph-Based RDF Data Management. Data Sci. Eng. 2017, 2, 56–70. [Google Scholar] [CrossRef] [Green Version]
- Galarraga, L.; Hose, K.; Schenkel, R. Partout: A Distributed Engine for Efficient RDF Processing. In Proceedings of the International World Wide Web Conference, Seoul, Korea, 7–11 April 2014; pp. 267–268. [Google Scholar]
- Janke, D.; Staab, S.; Thimm, M. Impact analysis of data placement strategies on query efforts in distributed RDF stores. J. Web Semant. 2018, 50, 21–48. [Google Scholar] [CrossRef] [Green Version]
- Guo, X.; Gao, H.; Zou, Z. Leon: A Distributed RDF Engine for Multi-query Processing. In Proceedings of the International Conference on Database Systems for Advanced Applications, Chiang Mai, Thailand, 22–25 April 2019; pp. 742–759. [Google Scholar]
- Hassan, M.; Bansal, S.K. RDF Data Storage Techniques for Efficient SPARQL Query Processing Using Distributed Computation Engines. In Proceedings of the International Conference on Information Reuse and Integration, Salt Lake City, UT, USA, 6–9 July 2018; pp. 323–330. [Google Scholar]
- Abdelaziz, I.; Harbi, R.; Khayyat, Z.; Kalnis, P. A Survey and Experimental Comparison of Distributed SPARQL Engines for Very Large RDF Data. Proc. VLDB Endow. 2017, 10, 2049–2060. [Google Scholar] [CrossRef]
- Leng, Y.; Chen, Z.; Wang, H.; Zhong, F. A Partitioning and Index Algorithm for RDF Data of Cloud-Based Robotic Systems. IEEE Access 2018, 6, 29836–29845. [Google Scholar] [CrossRef]
- Peng, P.; Zou, L.; Chen, L.; Zhao, D. Adaptive Distributed RDF Graph Fragmentation and Allocation based on Query Workload. IEEE Trans. Knowl. Data Eng. 2019, 31, 670–685. [Google Scholar] [CrossRef]
- Hendrickson, B.; Leland, R. A multilevel algorithm for partitioning graphs. In Proceedings of the ACM/IEEE conference on Supercomputing, San Diego, CA, USA, 4–8 December 1995; pp. 1–14. [Google Scholar]
- Karypis, G.; Kumar, V. METIS-Unstructured Graph Partitioning and Sparse Matrix Ordering System Version 2.0; Technical Report; Department of Computer Science, University of Minnesota: Minneapolis, MN, USA, 1995. [Google Scholar]
- Malewicz, G.; Austern, M.H.; Bik, A.J.C.; Dehnert, J.C.; Horn, I.; Leiser, N.; Czajkowski, G. Pregel: A System for Large-Scale Graph Processing. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Indianapolis, IN, USA, 6–10 June 2010; pp. 135–146. [Google Scholar]
- Chawla, T.; Singh, G.; Pilli, E.S. HyPSo: Hybrid Partitioning for Big RDF Storage and Query Processing. In Proceedings of the ACM India Joint International Conference on Data Science and Management of Data, Kolkata, India, 3–5 January 2019; pp. 188–194. [Google Scholar]
- Xu, Q.; Wang, X.; Xin, Y.; Feng, Z.; Chen, R. PDSM: Pregel-Based Distributed Subgraph Matching on Large Scale RDF Graphs. In Proceedings of the Companion Proceedings of the Web Conference, Lyon, France, 23–27 April 2018; pp. 17–18. [Google Scholar]
- Liu, J.; Chen, J.; Rao, Z.; Sun, Z.; Yang, H.; Xu, R. A massive RDF storage approach based on graph database. In Proceedings of the International Conference on Geoinformatics and Data Analysis, Prague, Czech Republic, 20–22 April 2018; pp. 169–173. [Google Scholar]
- Xu, Q.; Wang, X.; Wang, J.; Yang, Y.; Feng, Z. Semantic-Aware Partitioning on RDF Graphs. In Proceedings of the International Joint Conference APWeb-WAIM, Beijing, China, 7–9 July 2017; pp. 149–157. [Google Scholar]
- Al-Ghezi, A.I.A.; Wiese, L. Adaptive Workload-Based Partitioning and Replication for RDF Graphs. In Proceedings of the International Conference on Database and Expert Systems Applications, Regensburg, Germany, 3–6 September 2018; pp. 250–258. [Google Scholar]
- Potter, A.; Motik, B.; Nenov, Y.; Horrocks, I. Distributed RDF Query Answering with Dynamic Data Exchange. In Proceedings of the International Semantic Web Conference, Kobe, Japan, 17–21 October 2016; pp. 480–497. [Google Scholar]
- Potter, A.; Motik, B.; Nenov, Y.; Horrocks, I. Dynamic Data Exchange in Distributed RDF Stores. IEEE Trans. Knowl. Data Eng. 2018, 30, 2312–2325. [Google Scholar] [CrossRef]
- Peng, P.; Zou, L.; Özsu, M.T.; Chen, L.; Zhao, D. Processing SPARQL queries over distributed RDF graphs. VLDB J. 2016, 25, 243–268. [Google Scholar] [CrossRef] [Green Version]
- Nicoara, D.; Kamali, S.; Daudjee, K.; Chen, L. Hermes: Dynamic Partitioning for Distributed Social Network Graph Databases. In Proceedings of the International Conference on Extending Database Technology, Brussels, Belgium, 23–27 March 2015; pp. 25–36. [Google Scholar]
- Pujol, J.M.; Erramilli, V.; Siganos, G.; Yang, X.; Laoutaris, N.; Chhabra, P.; Rodriguez, P. The little engine (s) that could: Scaling online social networks. In Proceedings of the ACM SIGCOMM 2010 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, New Delhi, India, 30 August–3 September 2010; pp. 375–386. [Google Scholar]
- Stanton, I.; Kliot, G. Streaming graph partitioning for large distributed graphs. In Proceedings of the International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 1222–1230. [Google Scholar]
- Yang, S.; Yan, X.; Zong, B.; Khan, A. Towards effective partition management for large graphs. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; pp. 517–528. [Google Scholar]
- Pujol, J.M.; Erramilli, V.; Siganos, G.; Yang, X.; Laoutaris, N.; Chhabra, P.; Rodriguez, P. The Little Engine (s) That Could: Scaling Online Social Networks. IEEE/ACM Trans. Netw. 2012, 20, 1162–1175. [Google Scholar] [CrossRef]
- Bok, K.; Kim, C.; Jeong, J.; Lim, J.; Yoo, J. Dynamic Partitioning of Large Scale RDF Graph in Dynamic Environments. In Proceedings of the International Conference on Emerging Databases, Busan, Korea, 7–9 August 2017; pp. 43–49. [Google Scholar]
- Wang, R.; Chiu, K. A Graph Partitioning Approach to Distributed RDF Stores. In Proceedings of the International Conference on Parallel Processing, Leganes, Madrid, Spain, 10–13 July 2012; pp. 411–418. [Google Scholar]
- Troullinou, G.; Kondylakis, H.; Plexousakis, D. Semantic Partitioning for RDF Datasets. In Proceedings of the 11th International Workshop on Information Search, Integration, and Personalization (ISIP), Lyon, France, 1–4 November 2016; Volume 760, pp. 99–115. [Google Scholar]
- Leng, Y.; Chen, Z.; Zhong, F.; Li, X.; Hu, Y.; Yang, C. BRGP: A balanced RDF graph partitioning algorithm for cloud storage. Concurr. Comput. Pract. Exp. 2017, 29, e3896. [Google Scholar] [CrossRef]
- Hayes, J.; Gutiérrez, C. Bipartite Graphs as Intermediate Model for RDF. In Proceedings of the International Semantic Web Conference, Hiroshima, Japan, 7–11 November 2004; pp. 47–61. [Google Scholar]
- Tomaszuk, D.; Skonieczny, L.; Wood, D. RDF Graph Partitions: A Brief Survey. In Proceedings of the International Conference on Beyond Databases, Architectures and Structures, Ustroń, Poland, 26–29 May 2015; pp. 256–264. [Google Scholar]
- Akhter, A.; Ngomo, A.N.; Saleem, M. An Empirical Evaluation of RDF Graph Partitioning Techniques. In Proceedings of the International Conference on Knowledge Engineering and Knowledge Management, Nancy, France, 12–16 November 2018; pp. 3–18. [Google Scholar]
- Schmidt, M.; Hornung, T.; Lausen, G.; Pinkel, C. SP2Bench: A SPARQL Performance Benchmark. In Proceedings of the International Conference on Data Engineering, Shanghai, China, 29 March–2 April 2009; pp. 222–233. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Query | Server | Frequency | Size |
|---|---|---|---|---|
| I1 | Q1 | N1, N2, N3 | 47 | 2000 K |
| I2 | Q2 | N2, N3 | 50 | 1800 K |
| I3 | Q3 | N1 | 25 | 1200 K |
| I4 | Q4 | N2, N4 | 57 | 2000 K |
| I5 | Q5 | N2 | 22 | 1000 K |
| I6 | Q6 | N1 | 13 | 800 K |
| I7 | Q7 | N2 | 7 | 500 K |
| I8 | Q8 | N2, N4 | 3 | 500 K |
| I9 | Q9 | N2 | 10 | 800 K |
| Methods | Partitioning Policy | Replication | Load Discrimination | Partition Size | Partitioning Condition |
|---|---|---|---|---|---|
| MAPG [23] | Static | × | × | SS | Vertex weight, Edge-cut ratio |
| GPA [40] | Static | × | × | SS | Edge-cut ratio |
| SPAR [35,38] | Partial Dynamic | ○ | × | × | Replica |
| SGP [36] | Partial Dynamic | × | Partition Size | SS | Partition size |
| Sedge [37] | Dynamic | ○ | Communication cost, Hotspot | DS | Cross partition query |
| Hermes [34] | Dynamic | × | Read frequency | Vertex weight | Edge-cut ratio |
| Proposed | Dynamic | × | Query frequency | ~ | Cluster/subcluster, Edge-cut ratio, Partition size |
| Feature | Value |
|---|---|
| # of servers | 8 |
| Central processing unit (CPU) | Intel® Core™ i3 CPU 540 processor |
| Random access memory (RAM) | 4G |
| Size of hard disk | 1TB |
| Read speed of hard disk | 535MB/sec |
| Write speed of hard disk | 153MB/sec |
| Classification | DBLP | |
|---|---|---|
| # of vertices | 11.3 million | 317 thousand |
| # of edges | 85.3 million | 1 million |
| Type | Query |
|---|---|
| Q1 | SELECT ?journal ?year WHERE { ?journal rdf:type swrc:InProceedings. ?journal dc:type <http://purl.org/dc/dcmitype/Text>. ?journal dcterms:issued ?year } |
| Q2 | SELECT ?inproc ?author ?booktitle ?title ?ee ?page ?url ?yr WHERE { ?inproc rdf:type swrc:Inproceedings. ?inproc dc:creator ?author. ?inproc swrc:booktitle ?booktitle. ?inproc dc:title ?title. ?inproc rdfs:seeAlso ?ee. ?inproc swrc:pages ?page. ?inproc foaf:homepage ?url. Inproc dcterms:issued ?yr } ORDER BY ?yr |
| Q3 | SELECT ?article WHERE { ?article rdf:type ontology:article. ?article dc:type dcmitype:Text. ?article ?property ?value FILTER (?property=swrc:pages) } |
| Q4 | SELECT DISTINCT ?name1 ?name2 WHERE { ?article1 rdf:type swrc:article. ?article2 rdf:type swrc:article. ?article1 dc:creator ?author1. ?author1 foaf:name ?name1. ?article2 dc:creator ?author2. ?author2 foaf:name ?name2 } |
| Q5 | SELECT DISTINCT ?person8 WHERE { twr:MattKeith foaf:knows ?person2. ?person2 foaf:knows ?person3. ?person3 foaf:knows twr:damn. twr:damn foaf:knows ?person4. ?person4 foaf:knows ?person5. ?person5 foaf:knows twr:paul. twr:paul foaf:knows ?person6. ?person6 foaf:knows ?person7. ?person7 foaf:knows person8 } |
| Q6 | SELECT ?name1 ?postid1 WHERE { twr:Roberts foaf:knows ?person2. ?person2 foaf:name ?name1. ?post1 sioc:has_creator ?name1. twr:paul foaf:knows ?person3. ?person3 foaf:name ?name2. ?post2 sioc:has_creator ?name2. FILTER(?name1=?name2) } |
| Q7 | SELECT ?person2 ?person3 WHERE { ?post1 sioc:has_creator twr:paul. ?post1 sioc:has_creator ?person2. ?post2 sioc:has_creator ?person2. ?post2 sioc:has_creator ?person3. } |
| Q8 | SELECT ?person1 ?post WHERE { twr:damn foaf:knows ?person. ?post foaf:has_creator ?person. ?post sioc:post ?postid } |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bok, K.; Kim, J.; Yoo, J. Dynamic Partitioning Supporting Load Balancing for Distributed RDF Graph Stores. Symmetry 2019, 11, 926. https://doi.org/10.3390/sym11070926
Bok K, Kim J, Yoo J. Dynamic Partitioning Supporting Load Balancing for Distributed RDF Graph Stores. Symmetry. 2019; 11(7):926. https://doi.org/10.3390/sym11070926
Chicago/Turabian StyleBok, Kyoungsoo, Junwon Kim, and Jaesoo Yoo. 2019. "Dynamic Partitioning Supporting Load Balancing for Distributed RDF Graph Stores" Symmetry 11, no. 7: 926. https://doi.org/10.3390/sym11070926