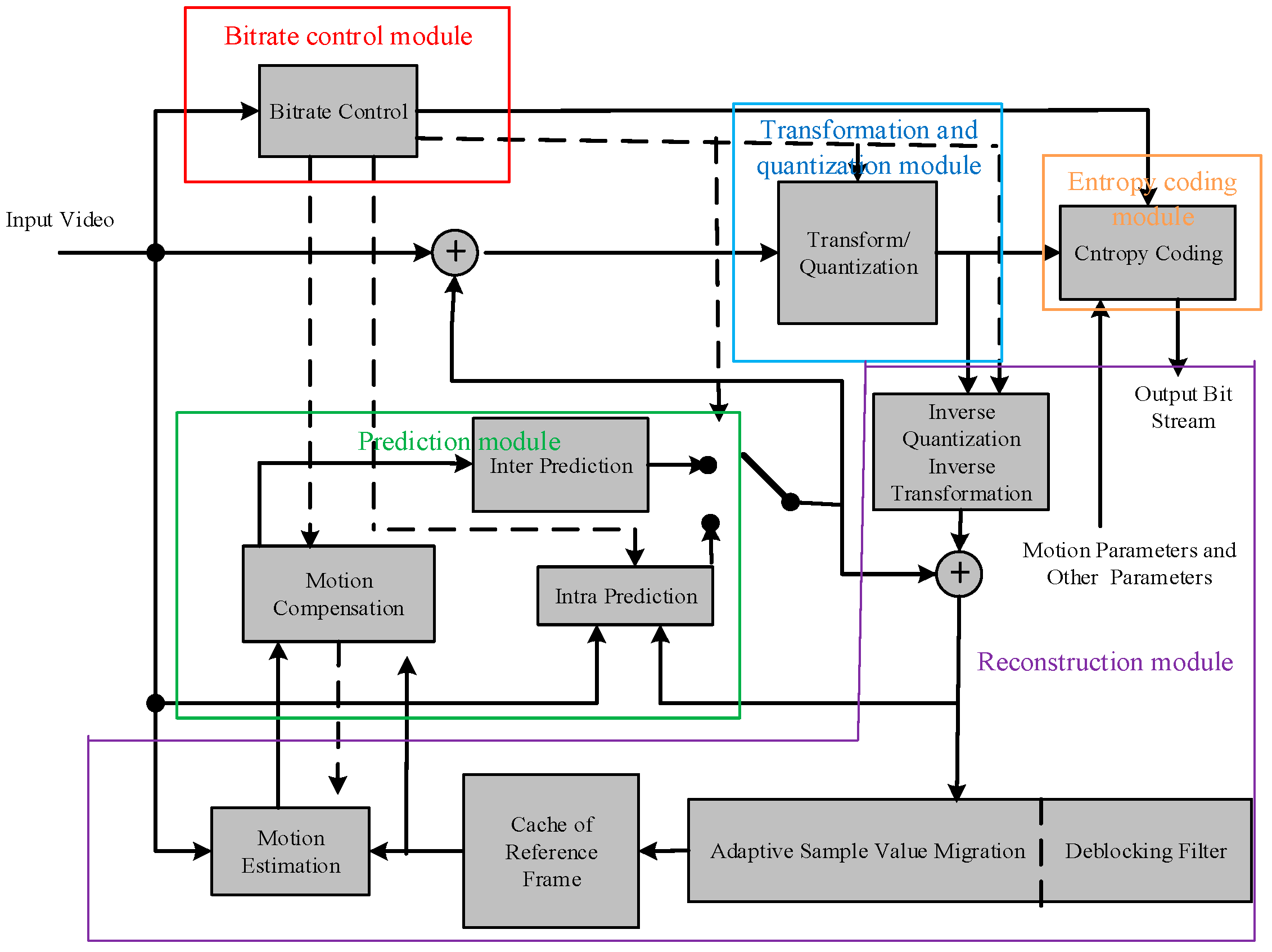
In this paper, we focus on proposing an effective algorithm to distinguish recompressed HEVC videos with fake bitrate from original videos. In the HEVC video recompression process, reconstruction error and quantization error are generated in the reconstruction process and quantization process, respectively. These two kinds of errors make the decoding video lose a part of content information, which further influence prediction variables: I-CU partitioning modes, I-PU partitioning modes, I-IPM, P-CU partitioning modes, P-PU partitioning modes, and P-IPM. The theoretical model and case study of the influence of irreversible coding errors on prediction variables will be described in detail in this section.
3.1. Theoretical Analysis and Modeling
For an original YUV (Luma and Chroma) sequence (), where denotes the nth frame and N is the total number of video frames. Given a bitrate r, the CU partitioning modes, PU partitioning modes, and IPM in I-picture and P-picture are successively determined. Let represents the bit allocation process of rate control module, the amount of bits allocated to the nth frame can be written as . Please note that in this paper, a picture contains only one slice.
For intra prediction process , it will select the optimal splitting of CTU into CUs, the optimal partitioning of CU into Pus, and the best IPM in PU to obtain the smallest rate-distortion value. Let k and represent the kth CU in the nth frame and the total number of CUs in the nth frame, respectively. The CU partitioning sequence with d partitioning depth in the nth frame can be denoted as , where d = 0, 1, 2, 3 means the CU size is 64 × 64, 32 × 32, 16 × 16, 8 × 8, respectively. When the CU depth is 0 to 2, the PU partitioning mode is the same as the CU partitioning mode. When the CU depth is 3, the PU can either be 8 × 8 or 4 × 4. Therefore, the PU partitioning sequence in the nth frame can be denoted as , where i and I represent the ith PU in the kth CU and the total number of PUs contained in the kth CU, respectively. The IPM sequence in the ith PU can be represented as , where denotes an IPM whose index is j of the ith PU in the kth CU whose depth is d in the nth frame.
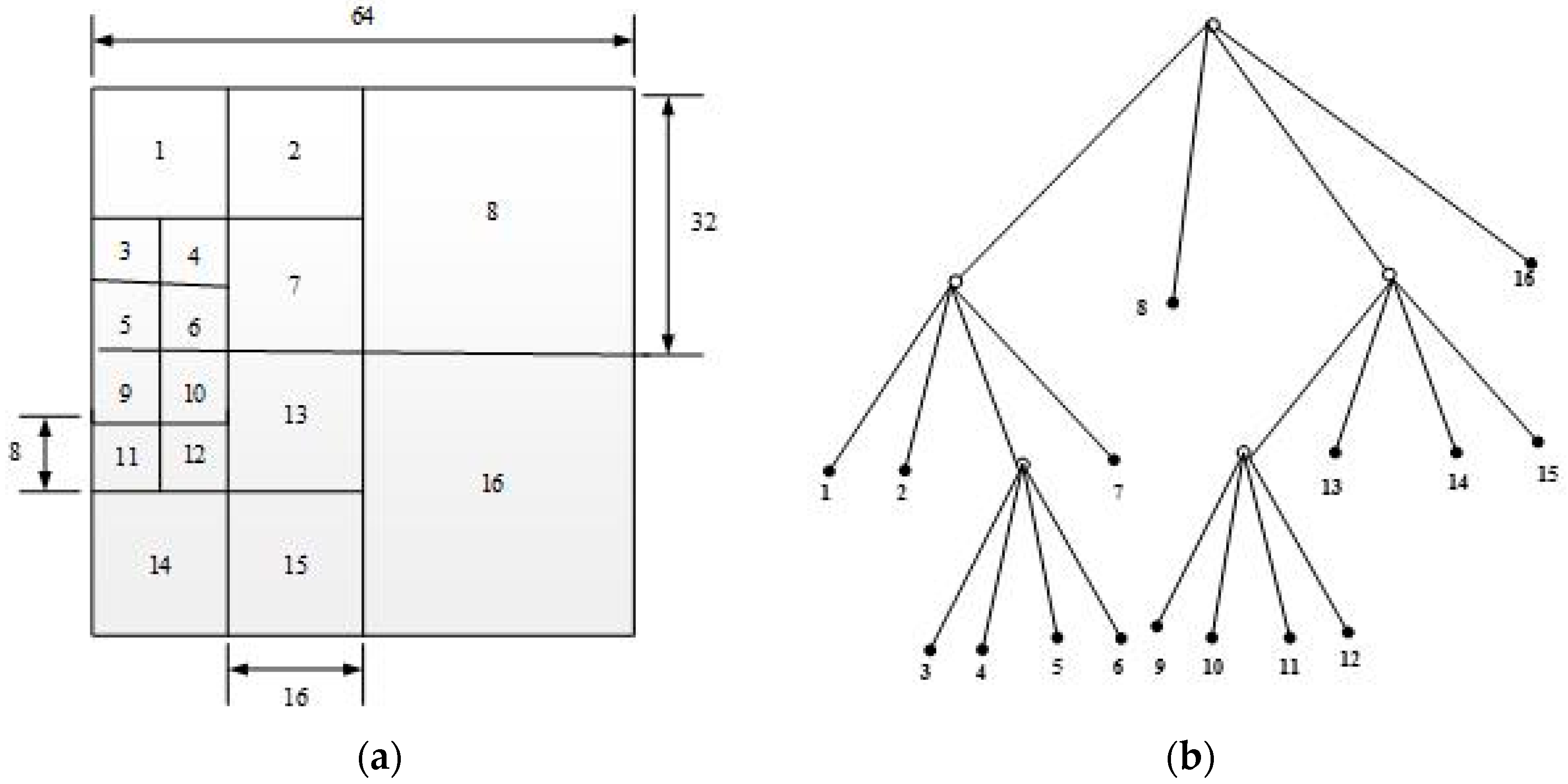
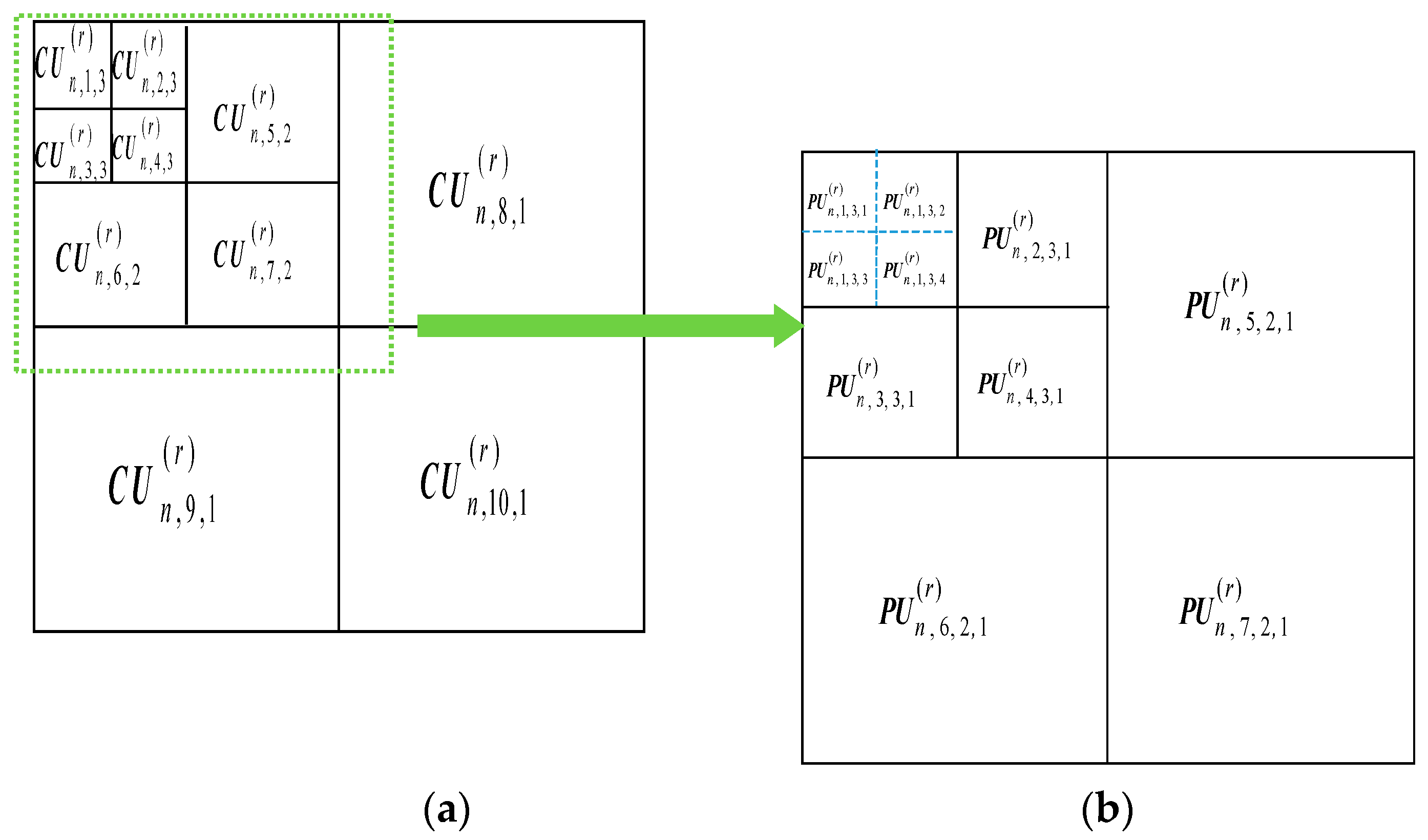
In order to demonstrate the subscript more clearly, we draw a CTU with size of 64 × 64 in the
nth frame as an example. The CU sequence of the CTU is shown in
Figure 6a, the PU sequence of the 32 × 32 CU in the upper left corner of
Figure 6a is shown in
Figure 6b. The index of each CU is counted from up to down and from left to right.
The sequences of CU partitioning modes, PU partitioning modes, and IPMs in intra prediction process can be represented as Equation (1). We can see that CU partitioning modes, PU partitioning modes, and IPMs in intra prediction are mainly affected by the picture content and the bits allocated to the frame.
For inter prediction process
, the partition strategy is similar to intra prediction. The CU partitioning sequence with
d depth in the nth frame can be represented as
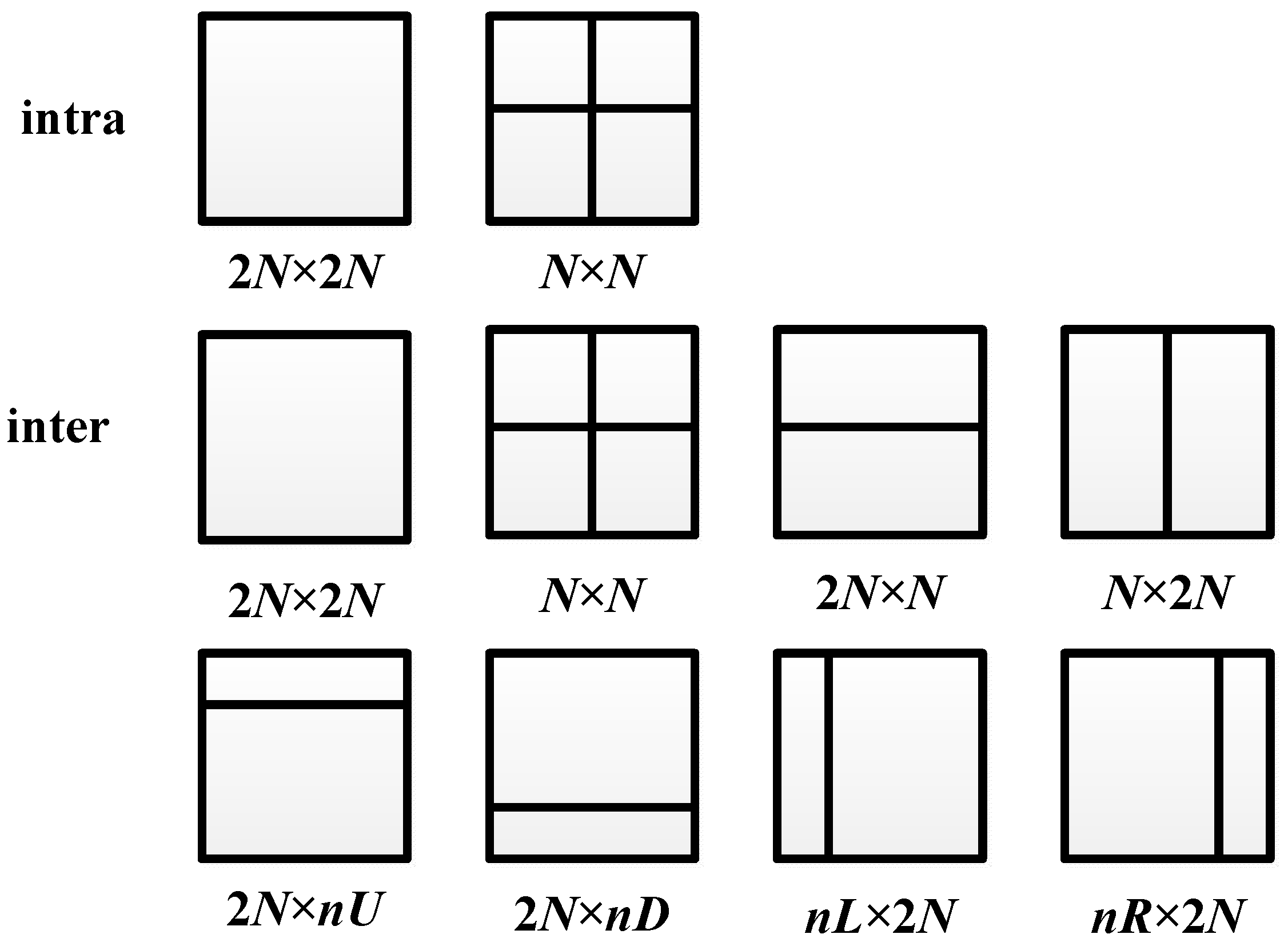
. Different from the case in intra prediction, apart from symmetric partitioning modes, inter prediction also has asymmetric PU partitioning modes, as shown in
Figure 4. Therefore, the inter PU partitioning sequence in the nth frame can be represented as
, where
i and
I represent the
ith PU in the
kth CU and the total number of PUs contained in the
kth CU, respectively. When the size of the
kth CU is 64 × 64 or 32 × 32 or 16 × 16 (
d = 0 or 1 or 2), the
kth CU can be symmetric or asymmetric partitioned, so
I = 1 or 2. When
d = 3, it is the same as intra prediction. There is no IPM exist in inter prediction. Thus, the CU partitioning sequence and PU partitioning sequence in inter prediction process can be represented as Equation (2), where
is the reference frame of
. That is to say, the CU partitioning modes and PU partitioning modes in inter prediction are not only determined by the content of the picture and the bits allocated to the frame, but also by the content of the reference frame.
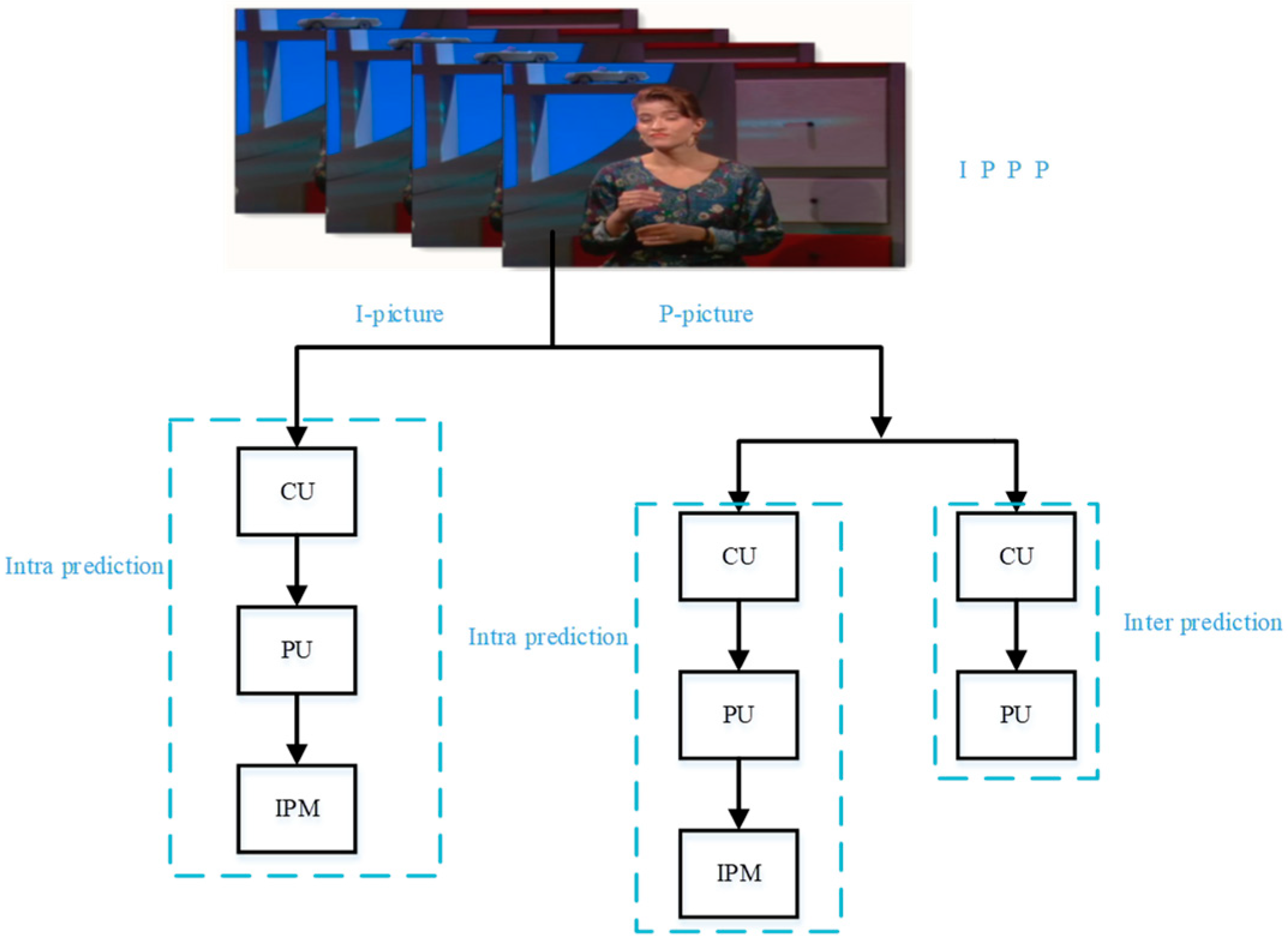
We use the P-PU partitioning sequence as an example to describe the difference between HEVC recompressed video with fake bitrate and single-compressed video. As shown in
Figure 2, P-picture can use either intra prediction or inter prediction. That is to say, P-PU partitioning sequence in a HEVC video denoted as
is composed of PU partitioning sequence by adopting intra prediction and that by adopting inter prediction. Therefore, the P-PU partitioning sequence
can be expressed as Equation (3).
Assume that the first and second compression bitrates of the recompressed video are
and
(
for abbreviation), respectively. Here, we only consider the fake bitrate recompression situation, that is, the bitrate up-converting, so
. In the second compression, the amount of bits allocated to the nth P-frame can be written as Equation (4), where
(
represents the decoded YUV sequence, and
is the decompressed picture of
. The P-PU partitioning sequence of HEVC recompressed video is
.
For HEVC single-compressed video with bitrate
,
is denoted as the amount of bits allocated to the
nth P-picture, and
is the P-PU partitioning sequence of this single-compressed video. We can achieve
Use
to represent the difference between
and
. According to Equations (1)–(7), we can get the difference between the P-PU partitioning sequence of HEVC single-compressed videos and its corresponding recompressed videos with fake bitrate, as shown in Equation (8), where
and
are the decompressed version of
and
, respectively.
It can be concluded from Equation (8) that the main difference between
and
comes from the contents of
,
,
, and
. The relation between
and
can be derived as Equation (9), where
and
are the quantization error of
and
under the given quantization step
, respectively, [] means rounding operation. Therefore, we can get
, which means the difference between
and
is caused by quantization error and reconstruction error. Quantization error contains rounding error and truncation error in the quantization process. Reconstruction error is caused by reference frame in the reconstruction process. It means that the difference between P-PU partitioning sequence in HEVC double-compressed video with fake bitrate and single-compressed video is mainly caused by quantization error and reconstruction error.
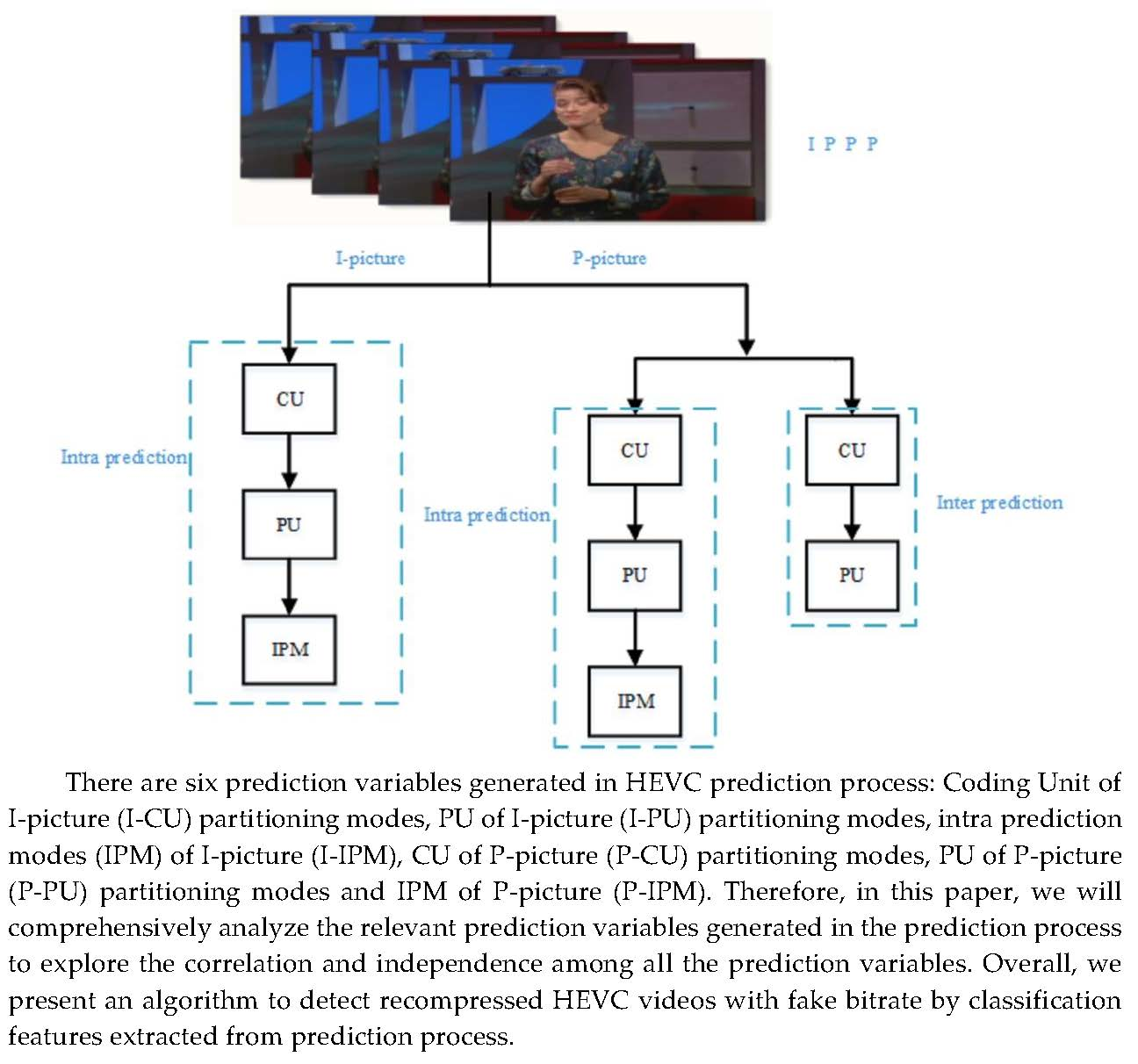
There are six kinds of prediction variables as illustrated in
Figure 2. Similar as P-PU partitioning sequence
, we can get other prediction sequences: I-CU partitioning sequence
, I-PU partitioning sequence
, I-IPM sequence
, P-CU partitioning sequence
, P-IPM sequence
. And the difference between other prediction sequences of HEVC recompressed video and that of single-compressed video can be illustrated in Equations (10)–(13), respectively. Please note that the theoretical model of
and
are the same because IPM only appears in the intra prediction process.
From Equations (10)–(13), we can conclude that the difference between the six prediction variable sequences in HEVC recompressed video and single-compressed video is mainly caused by irreversible quantization error and reconstruction error. Therefore, we consider that these six prediction variables can be used as classification features to distinguish HEVC recompression videos with fake bitrate and single ones.
3.2. Feature Analysis and Example Description
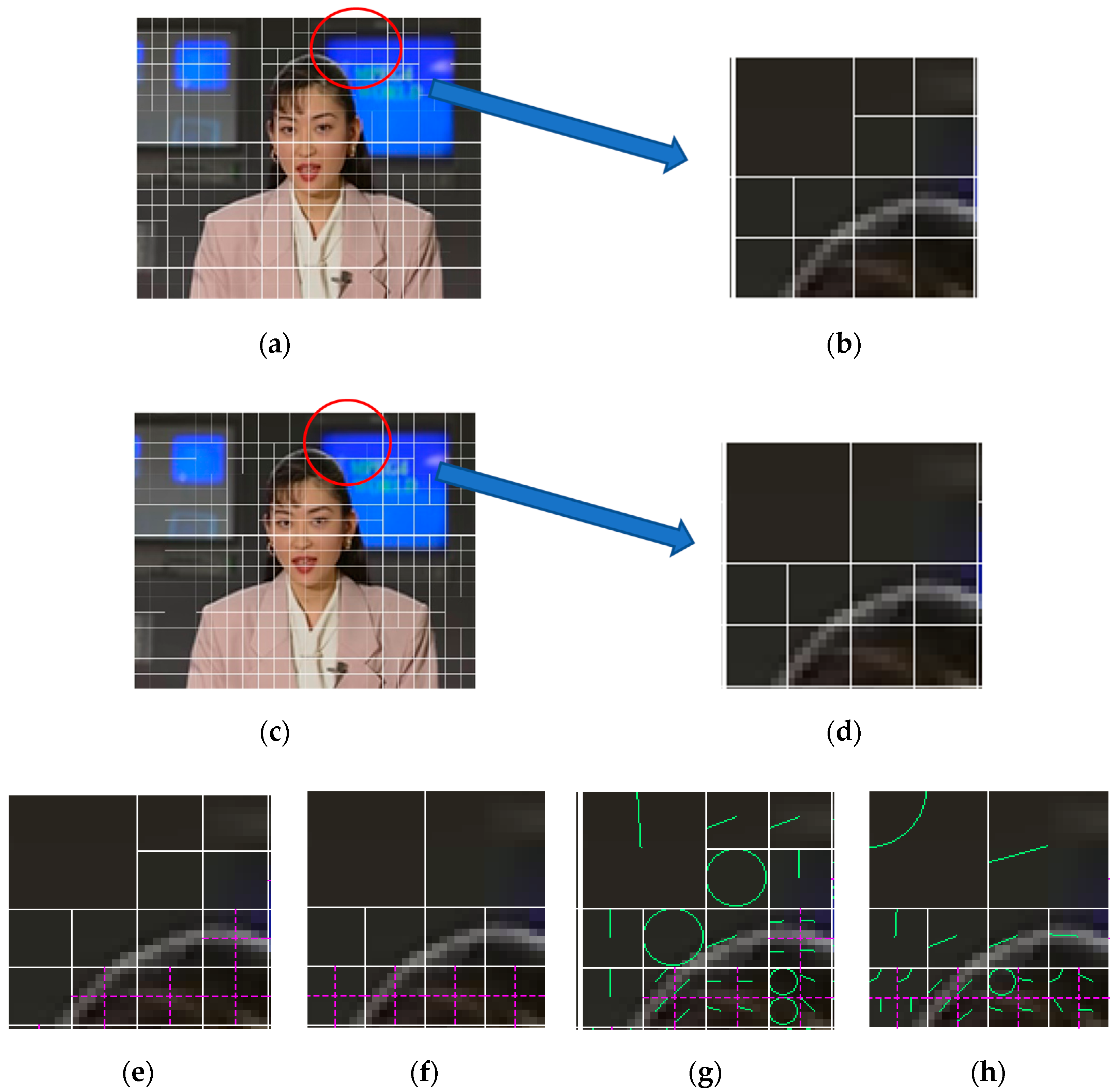
To illustrate the difference between prediction variables in fake bitrate recompressed video and single-compressed video, we will extract the CU partitioning modes, PU partitioning modes, and IPM of the same I-frame within the recompressed video with fake bitrate 100–400 Kbps and within the corresponding single-compressed video with bitrate 400 Kbps, as shown in
Figure 7. The 16th picture (I-picture) with CU partitioning is extracted from the double-compressed video with fake bitrate as shown in
Figure 7a, and the same frame of the single-compressed video is shown in
Figure 7c. Taking the 32 × 32 block (shown in
Figure 7b,d) surrounded by the red circle in the I-frame as an example for analysis. The block with PU partitioning modes in double- and single-compressed videos are shown in
Figure 7e,f, respectively.
Figure 7g,h exhibit the block with IPM in double- and single-compressed video, respectively. Observing
Figure 7, it can be found that the three prediction variables (I-CU partitioning modes, I-PU partitioning modes, I-IPM) in the same I-picture of single-compressed video and double-compressed video with fake bitrate are quite different. Therefore, these three prediction variables of I-picture can be used as independent classification features for detecting fake bitrate recompression videos. In addition, even within the same I-CU partitioning block, the I-PU partitioning mode in single-compressed frame and recompressed frame is not necessarily the same, as is IPM, so these three prediction variables of I-picture are interdependent. As we can see, I-IPM is based on I-PU partitioning modes, and I-PU partitioning modes is based on I-CU partitioning modes, thus, the fusion method of concatenating these three single features can be used to enhance feature expression.
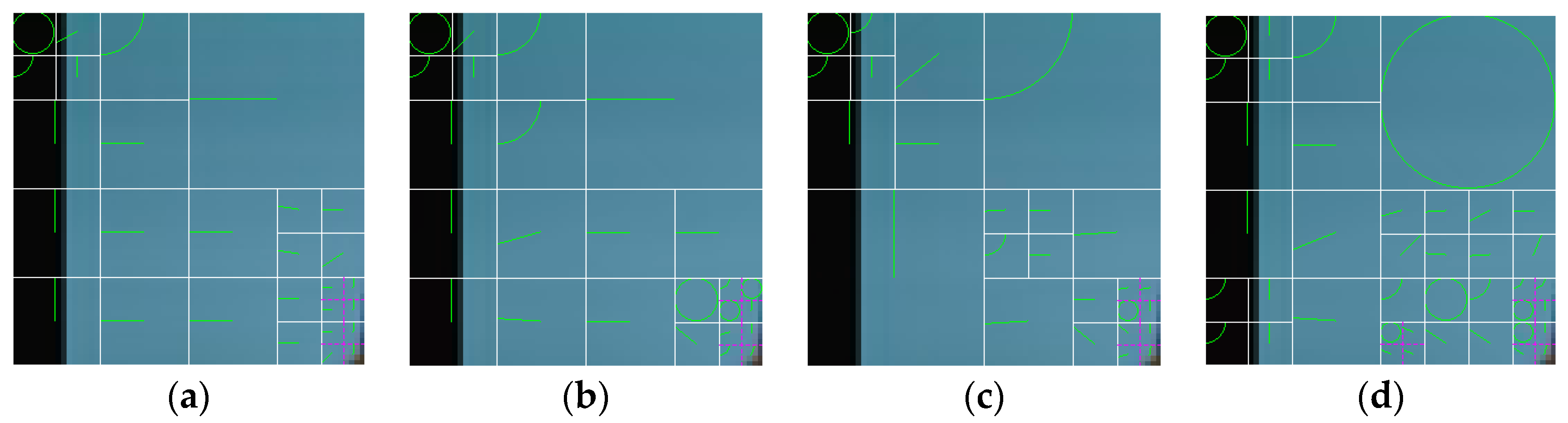
Four 64 × 64 blocks are extracted from the 7th I-picture in the “claire_qcif.yuv” with different bitrates, as shown in
Figure 8. The white line indicates the CU partitioning, the purple line indicates the PU partitioning under the CU, and the green line indicates the IPM under the PU.
Figure 8a is extracted from the single-compressed video with bitrate 400 Kbps,
Figure 8b is extracted from the recompressed video with bitrate 300–400 Kbps,
Figure 8c is extracted from the recompressed video with bitrate 200–400 Kbps, and
Figure 8d is extracted from the recompressed video with bitrate 100–400 Kbps. Compared with the single-compressed video block (
Figure 8a), the I-CU partitioning, I-PU partitioning, and I-IPM in the recompressed video blocks will change, the number of changes is shown in
Table 4. Both visually and statistically, it can be seen that when the difference between the first bitrate and the second bitrate of the recompressed video becomes smaller, the difference between the prediction variables of I-picture in single-compressed video and double-compressed video will become smaller, the same as the prediction variables of P-picture.
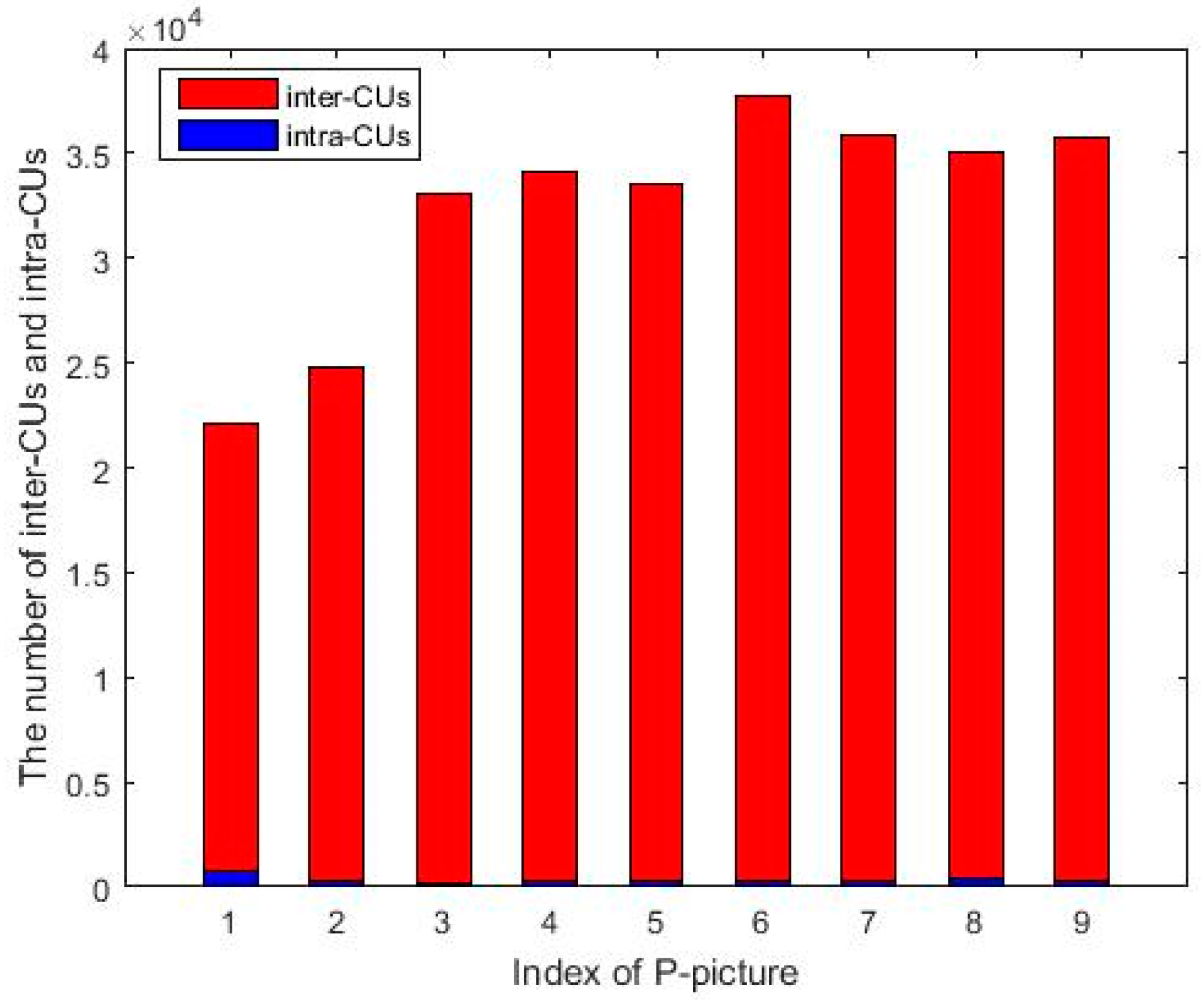
In P-picture, CU block traverses the various modes of inter prediction and intra prediction, and then selects the mode with the lowest rate distortion cost as the final optimal prediction mode. While the temporal redundancy in the video is more than the spatial redundancy, the efficiency of the general inter prediction is higher than that of the intra prediction. Therefore, most of the P-pictures select inter prediction instead of intra prediction. This phenomenon is indeed ubiquitous in HEVC videos, for example, randomly selecting 9 P-pictures from a HEVC single-compressed video. Then, separately counting the number of CU blocks which adopt intra prediction (abbreviated as “intra-CUs”) and the number of CU blocks which adopt inter prediction (abbreviated as “inter-CUs”) in each P-pictures, the statistical histogram is shown in
Figure 9. The red bars represent the inter-CUs and blue bars represent the intra-CUs. It can be seen that intra-CUs only take a tiny percentage of the total CUs and they are much smaller than inter-CUs. Furthermore, there are 35 IPM choices for each PU block, which makes the number of each IPM mode too small in P-pictures to be used as a single classification feature. Therefore, we ignore the P-IPM and only adopt the other two prediction variables for P-pictures: P-CU partitioning modes and P-PU partitioning modes. Similarly, the CU partitioning modes and the PU partitioning modes of P-picture are mutually dependent.
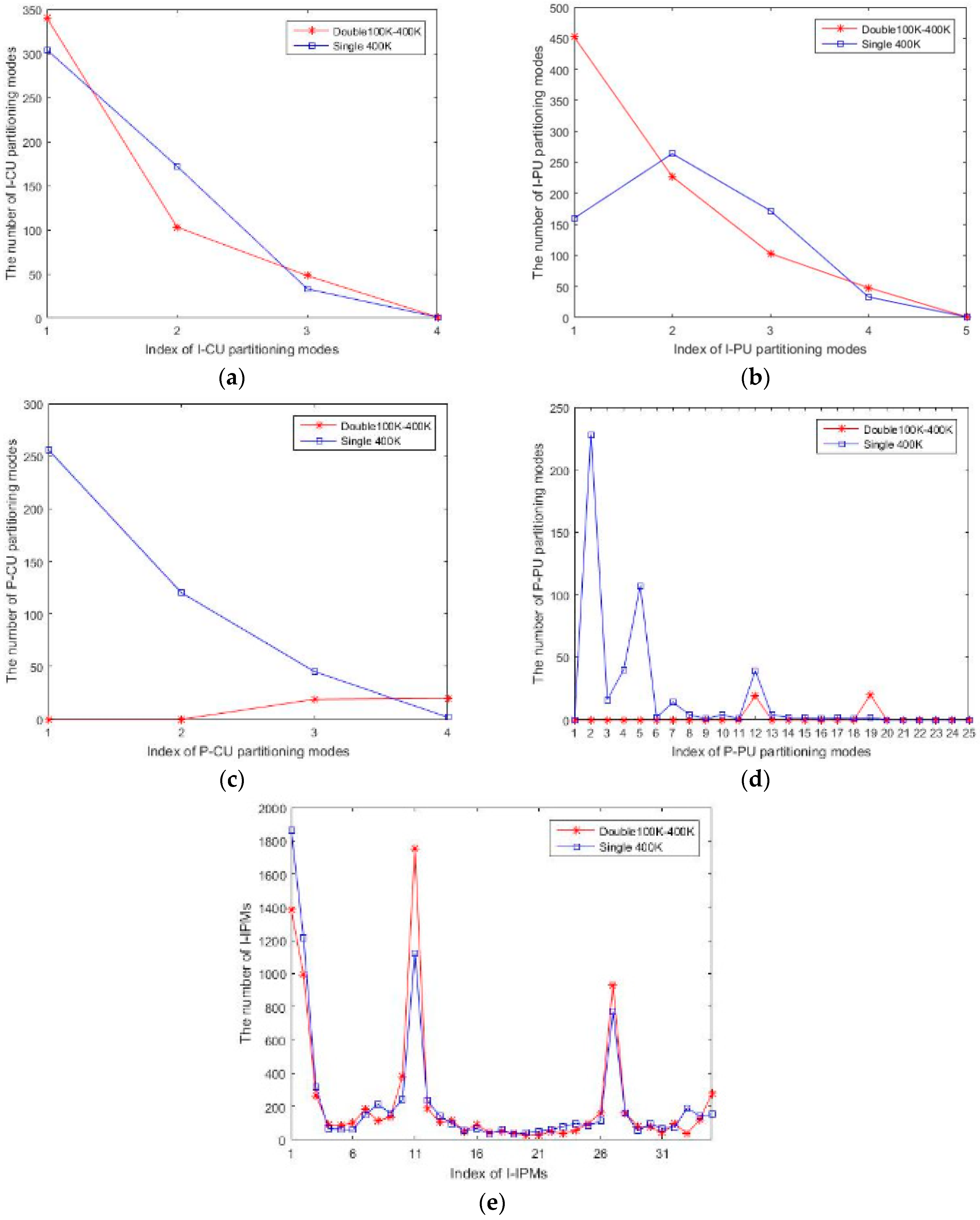
In the following, we will use a line chart to show the difference between the five prediction variables in the HEVC double-compressed video and the single-compressed video, as shown in
Figure 10. The bitrate of the HEVC single-compressed video is 400 Kbps (blue lines) and the corresponding recompressed video with the first compression bitrate
and the second compression bitrate
(red lines). The abscissa indicates the index of the mode used in the prediction variable, and the ordinate indicates the total number of times the mode used in the prediction variable appears in the video. It is clearly that the difference between the red and blue lines in
Figure 10a–d is obvious, which means the four prediction variables (I-CU partitioning modes, I-PU partitioning modes, P-CU partitioning modes, P-PU partitioning modes) can effectively distinguish HEVC single-and double-compressed videos. In
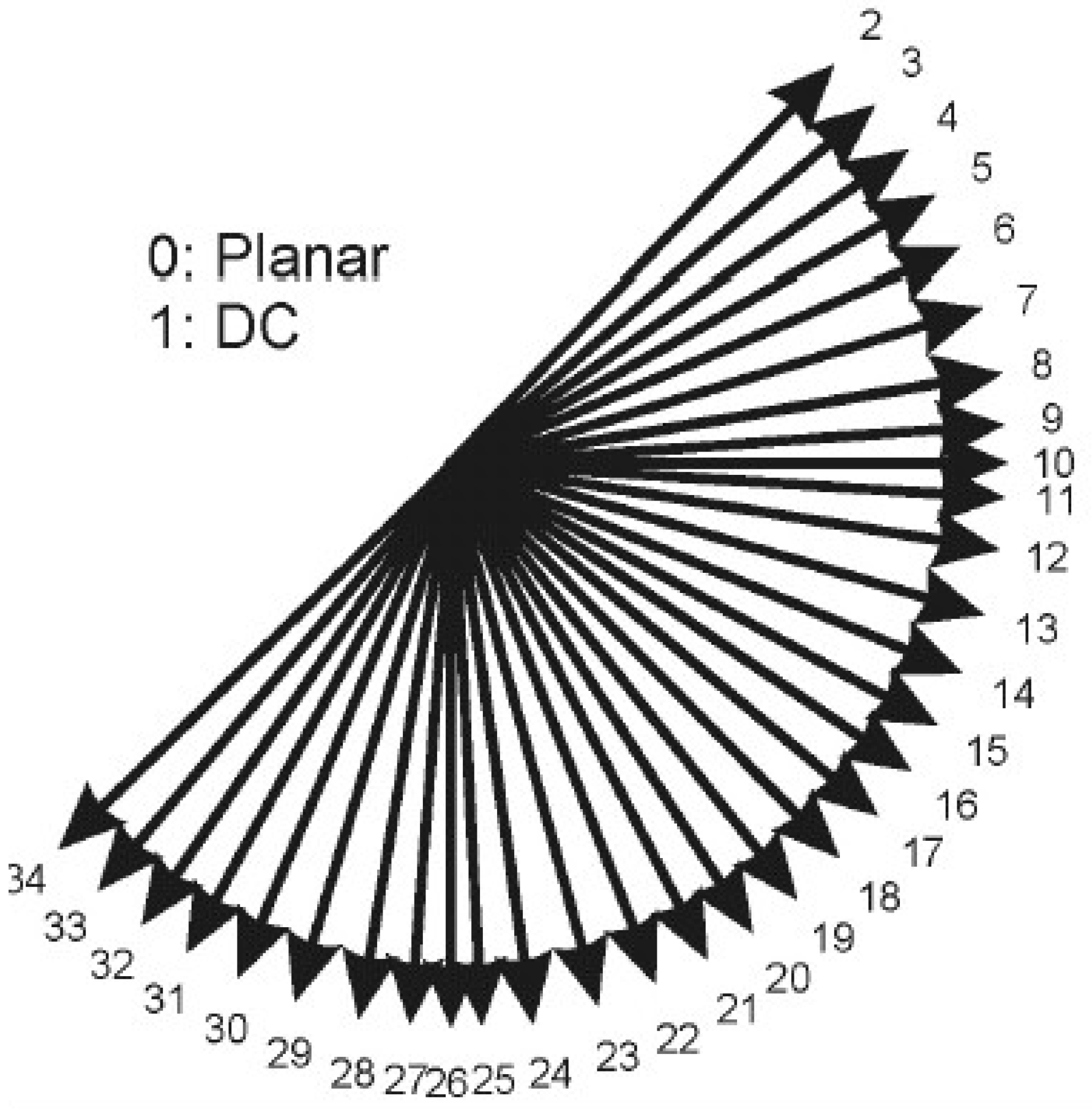
Figure 10e, we find that the number of I-IPM only differs greatly in the 1st, 2nd, 10th, 11th, 26th, and 27th intra prediction modes, and this phenomenon appears in most videos. Thus, we only use these six modes as the representatives of I-IPM.
3.3. The Proposed Target Features
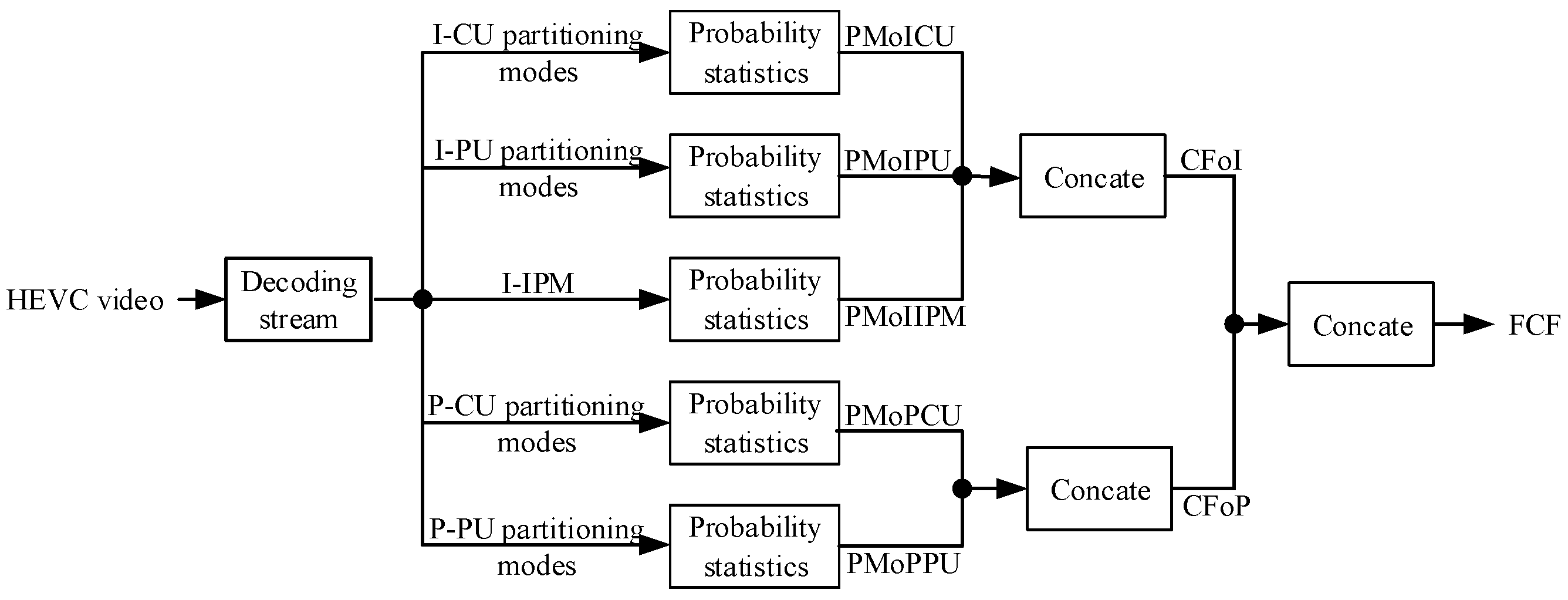
From the above analysis, we know that the numbers of the five prediction variables are different between double-compressed videos with fake bitrate and single ones. In order to make the characteristics of the prediction variables more universal, we consider using the probability matrix of prediction variables as the classification features. The probability set can be expressed as Equations (14) and (15), where
denotes the probability matrix of the
ith prediction variable, where
i = 1, 2, 3, 4, 5 represents 4-dimensional I-CU partitioning modes, 5-dimensional I-PU partitioning modes, 6-dimensional I-IPM, 4-dimensional P-CU partitioning modes, and 25-dimensional P-PU partitioning modes, respectively.
represents the dimensions of each prediction variable, so
.
represents the number of the
jth mode of the
ith prediction variable in a HEVC video.
represents the probability of the
jth mode for
ith prediction variable in the whole video. For example, for I-CU partitioning modes,
i = 1,
= 4,
j = 1, 2, 3, 4. The number of each I-CU partition modes in the HEVC video are
, respectively, and their probabilities are expressed as
, then, the probability matrix of I-CU partitioning modes is
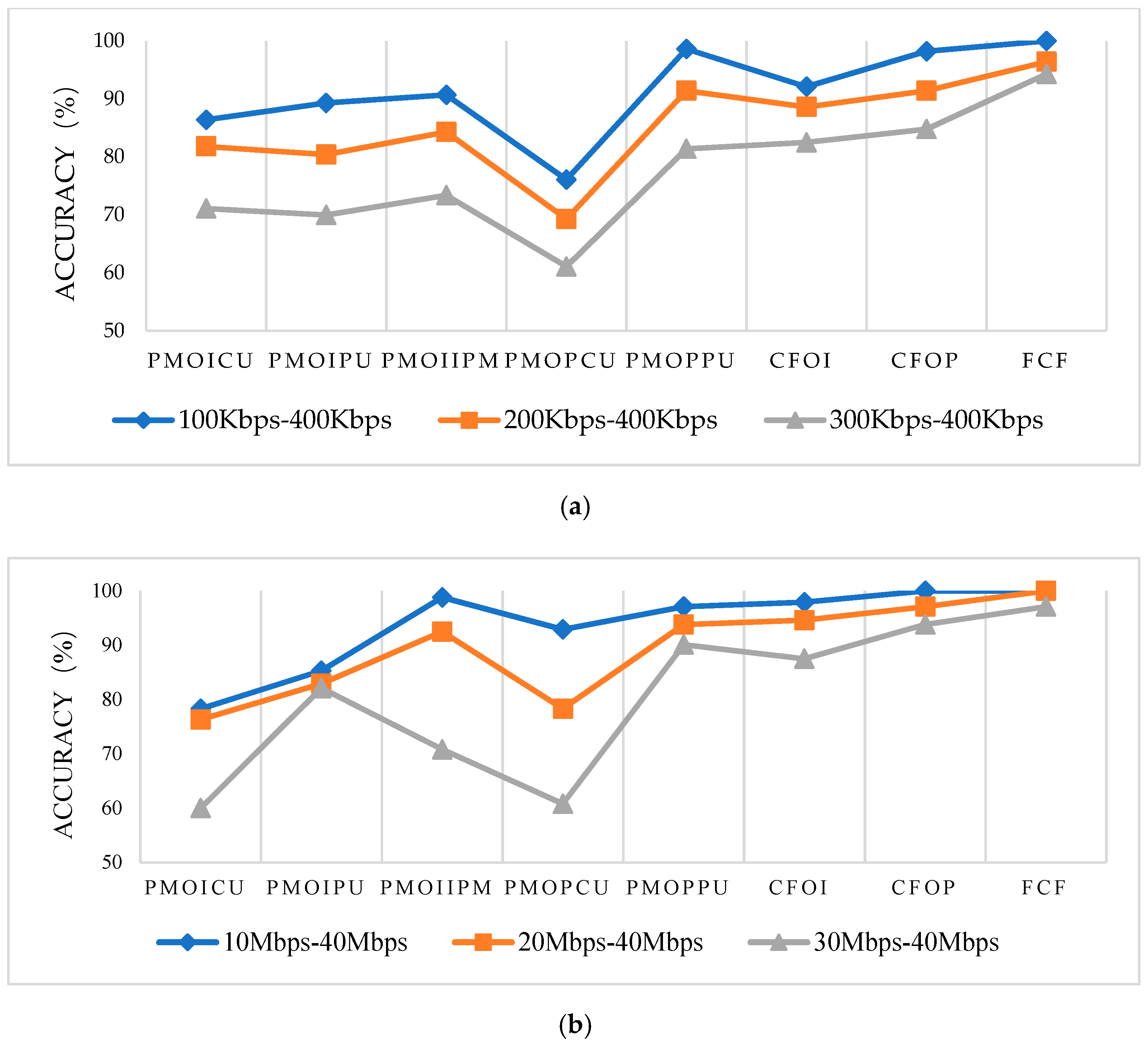
. The probability matrix of other prediction variables is similar to that of I-CU partitioning modes. Finally, we can get five single features: the probability matrix of I-CU partitioning modes (PMoICU) with dimensions of 4, the probability matrix of I-PU partitioning modes (PMoIPU) with dimensions of 5, the probability matrix of I-IPM (PMoIIPM) with dimensions of 6, the probability matrix of P-CU partitioning modes (PMoPCU) with dimensions of 4, and the probability matrix of P-PU partitioning modes (PMoPPU) with dimensions of 25.
According to
Section 3.2, CU partitioning modes, PU partitioning modes, and IPM are interdependent, the feature fusion method can enhance the expressiveness of single features. Therefore, we concatenate these single features from three aspects, which are called Concatenation Feature of I-picture (CFoI), Concatenation Feature of P-picture (CFoP), and Full Concatenation Feature (FCF). CFoI with dimensions of 15 is made up of PMoICU, PMoIPU, and PMoIIPM; CFoP with dimensions of 29 is composed of PMoPCU and PMoPPU, while FCF with dimensions of 44 is concatenated by all single features.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}