2.1. Fuzzy Commitment
Juels and Wattenberg [
6] introduced the fuzzy commitment scheme by combining knowledge from the area of Error Correction Codes (ECC) and cryptography to protect the cryptography key. The fuzzy commitment scheme has a function
, which is used to commit a codeword
and a witness
. The witness is the enrolled biometric template represented by
-bits binary string, while
is a set of error correcting codewords
of length
. The difference vector of
and
,
can be obtained through bit-wise XOR operation:
. The
is denoted as the helper data, which will be stored together with
into the database where
is the hash function. The commitment is termed
. Given a query biometric template
, a corrupted codeword
can be reconstructed through
using the stored helper data. At the authentication stage, if the query binary string is sufficiently similar to the enrolled template within the capability of the ECC, a hash of the result will be tested against
where a successful authentication yields if
.
The first application of the fuzzy commitment scheme to iris codes was implemented by Hao et al. [
14]. Hadamard and Reed-Solomon error correction codes were used in their scheme to bind 2048-bit iris codes into 140-bit cryptographic keys. The main idea was to apply Hadamard codes to eliminate bit errors caused by the natural variance such as background errors while burst errors were corrected by Reed-Solomon codes. The Genuine Acceptance Rate (GAR) of 99.53% and zero False Acceptance Rate (FAR) are reported in an in-house dataset. Two-dimensional iterative min-sum decoding was then introduced [
15] for the iris-based fuzzy commitment scheme with higher correction capacity and efficiency. This was because a high False Rejection Rate (FRR) was discovered on a noisy channel using the Reed-Solomon code. Instead, two different Reed-Muller codes were used to form a matrix for efficient decoding. This approach achieved a GAR of 94.38% and a zero FAR on the ICE 2005 iris database [
16] with 40 bits of bound keys. A context-based approach which constructs keys based on reliable bits within the iris codes bound by BCH-code is proposed in [
17]. User-specific masks and check bits were used to form the helper data. A variety of techniques focusing on biometric template protection, random bit-permutation, biometric feature binarization, and concatenated coding scheme were then proposed to improve the performance and security of the iris fuzzy commitment schemes, see [
18,
19,
20,
21] for examples.
Ideally, fuzzy commitment is proven secure under the random oracle model, hence, helper data contains no information about the secret. In other words, the secret is expected to be uniformly and independently distributed where an adversary can only perform brute force attacks. However, practically speaking, this is hard to achieve due to the inherent structure of the biometric data and the correlation between features [
22]. Privacy leakage is another concern in fuzzy commitment caused by the redundancy in an ECC, which is unavoidable [
22]. Cross matching can happen if large privacy leakage is discovered. There are several attacks, such as decodability attacks [
19], statistical attacks [
23], and attack via record multiplicity (ARM) [
24].
Kelkboom et al. [
19] proposed a bit-permutation process for the fuzzy commitment scheme to prevent it from a decodability attack that exploits the correlation of the multiple helper data generated from the biometric data of a same subject. The decodability attack was first initiated by Carter and Stoinov [
25] to verify the possibility of whether decoding two helper data leads to a valid codeword. When there are two helper data
being generated by two biometric data from the same subject,
, in a decommitment process, the attacker can leverage the helper data by performing
, which equates to
. If the two helper data are derived from the same subject,
is small and the outcome will be most likely close to the correct codeword. In short, the bit-permutation mechanism helps to improve the security through distribution of entropy across biometric feature vectors.
Rathgeb et al. [
23] presented a statistical attack against the iris fuzzy commitment scheme. Binary biometric feature vectors of an impostor are randomly chosen, and decommitment is performed successively with the stored helper data, assuming that attackers are knowledgeable about the applied ECC. The frequency of each possible codeword is collected, and a corresponding histogram is generated for each chunk. The ECC based histograms of all the chunks can be analyzed after repeating the chunk-based decommitment processes using an adequate amount of imposter templates. The most likely error correction codeword for a chunk can be decided based on the bin, which corresponds to the histogram maximum.
Scheirer and Boult [
24] launched an attack via record multiplicity on the fuzzy vault. This refers to an imposter in possession of multiple invocations of the same secret, which are combined to reconstruct secrets that lead to the retrieval of biometric templates. The introduced attack on the fuzzy vault, namely Surreptitious Key-Inversion (SKI), is an equivalent attack against fuzzy commitment. Under this attack, the biometric string blended with the codeword can be recovered through XOR operation using the compromised cryptographic key (secret) and the secure sketch.
Privacy and security leakages of fuzzy commitment schemes are investigated in [
26] for several biometric data statistics. The scheme is found to leak information in bound keys and non-uniform templates. For instance, keys bound of 44 bits in fuzzy commitment schemes [
14] suffer from low entropy, reducing the complexity for brute force attacks [
20]. Zhou et al. [
22] conducted a quantitative assessment on the privacy and security leakage of the fuzzy commitment scheme. Biometric data are not uniformly and independently distributed, which further contributes to the security issue. Several evaluation metrics were proposed to conclude that fuzzy commitment is highly vulnerable due to the inherent dependency on the biometric features. Apart from that, fuzzy commitment is often bounded by the limitations introduced by ECC. The scheme was found to be affected by the tradeoff between security and performance [
27]. Similar perspective is reported by Bringer et al. [
15], where the decoding accuracy and maximum key length are bounded by the error correction capacity of the adopted ECC. Besides, another limitation comes from the design of the fuzzy commitment scheme in terms of input representation and matching [
9]. The input feature to fuzzy commitment is restricted to binary representation in order to conduct matching in the hamming domain. This hinders the scheme from achieving better performance since many effective feature extraction and matching techniques do not comply with this requirement. Considering the discussed attacks and limitations, the security and privacy provided by iris-based fuzzy commitment is doubtable.
2.2. Fuzzy Vault
Another design that provides protection and error-tolerant verification is the fuzzy vault scheme that was introduced by Juels et al. [
11]. The first implementation of a fuzzy vault scheme on iris was presented in [
28]. In this method, independent component analysis (ICA) was employed to extract important coefficients from multiple local regions in an iris image. The K-mean based pattern clustering method aimed to solve the variance of the extracted iris features, while ICA created unordered sets for fuzzy vault. On a challenging CASIAv3-Interval iris database [
29], a GAR of 80% was achieved at a zero FAR employing 128 bit keys. Reddy et al. [
30] hardened the fuzzy vault using the user’s password to prevent from attacks via record multiplicity. Iris features were extracted from minutiae-like coordinates obtained through image enhancement steps. At zero FAR, a degradation of 2% to 90% GAR was reported for CASIAv1 [
31] and the MMU iris database [
32] when the degree of polynomial was set to seven or eight. More proposals on iris vaults [
33,
34] omitted a detailed explanation about iris feature encoding or protocols. The majority of the proposed approaches to biometric cryptosystem lack a thorough security analysis, for example, larger entropy loss can be possible, especially for neighboring bits dependencies, and this can reduce the security all the way to 40 bits [
14].
The implementations of the fuzzy vault scheme by Juels and Sudan [
11] in biometrics exposed its vulnerability to correlation attacks and linkage attacks [
24,
35]. This conflicts with the unlinkability and irreversibility requirements defined for biometric template protection. The basic idea of fuzzy vault fingerprint systems to include auxiliary data was to help alignment issues affected by translation, rotation, and non-linear distortion. However, the attacker can make use of the publicly unprotected auxiliary alignment data in performing linkage attacks. An implementation for absolute fingerprint pre-alignment that resists any correlation between related records of the fuzzy vault scheme was proposed as the countermeasure [
36]. In designing an effective fuzzy vault-based cryptosystem, a practical decoding strategy is important. The error correcting capacity of the Reed-Solomon decoder in the original fuzzy vault is insufficient to achieve practical implementation for biometrics, especially single finger. To overcome this, the Lagrange-based decoder [
37] was proposed, but the decoding complexity would then become infeasible for implementation.
2.3. Cancelable Biometrics
Ratha et al. [
12] were the first to introduce cancelable biometrics. They applied a smooth but non-invertible surface folding transformation to preserve the accuracy performance. The proposed scheme preserved the change in minutiae position after the transformation while introducing many-to-one mapping for non-invertibility. Despite the satisfactory accuracy performance that was reported, the non-invertibility was found vulnerable [
38]. Since then, this work has inspired more research works into biometric template protection. In short, cancelable biometrics can be categorized into biometric salting and non-invertible transformation.
Any invertible transform of a biometric template can be referred to as biometric salting, even if the extraction is applied in a way that it is not feasible to reconstruct the original biometric template [
39]. Independent auxiliary data such as user specific token are blended with the biometric data to form a distorted version of the original template. Chong et al. [
40] proposed S-IrisCode encoding, which combines two authentication factors, iris feature and tokenized pseudo-random number via iterated inner-product and thresholding, to produce a set of cancelable binary codes per person. Noise mask is developed to eliminate the weaker inner-product and improve the accuracy in matching.
Another salting method by Zuo et al. [
41] can be applied to either real-valued (GRAY-SALT) or binary (BIN-SALT) iris data. For GRAY-SALT, the real-valued iris data and a random pattern are combined pixel-wise through addition or multiplication. Similar techniques can be applied to the binary iris code using XOR operation for BIN-SALT. In this case, the original iris pattern is concealed and cancelable iris template can be realized by replacing the auxiliary data. However, deterioration of accuracy performance is inevitable without the pre-alignment process. Another idea to achieve cancelable iris biometric is based on sectored random projections [
42]. In this method, an unwrapped iris image is first divided into different sectors where random projections will be applied on each sector separately via user specific random Gaussian matrix. The random matrices will then be concatenated to form the cancelable template. The sectored based strategy not only limits the effect of noise but also reduces the size of useful information. New templates can be generated by using different random projection matrices if the existing one is compromised. However, further research [
43,
44] found that the accuracy performance degraded if the same random matrix was applied to different users. Moreover, the cancelable template is likely to be inverted when the user-specific random matrices are disclosed. In short, biometric salting is feasible for cancelable biometrics if and only if the auxiliary data is kept secret.
Non-invertible transformation is a one way transformation function that can be implemented on the iris template to achieve non-invertibility so that the transformed template can be stored securely in the database [
7]. Zuo et al. [
41] provided two methods to ensure that the transforms are non-invertible and revocable. GRAY-COMBO and BIN-COMBO can be applied on the unwrapped iris image and binary iris codes, respectively. For GRAY-COMBO, rows are shifted circularly in a horizontal direction using random offsets. Then, two randomly selected rows are combined via addition or multiplication operation. A similar transform is adopted by BIN-COMBO, but the combination is changed to XOR or XNOR. The non-invertibility criterion is achieved through the distortion caused by data shifting. The shifting is always shifted in same orientation, hence no alignment is necessary for matching. Performance degradation is experienced due to the decrease in the valid iris area and occlusions. Nonetheless, this transformation shares the same risk as the salting approach, where stolen-token can happen since they use user-specific key.
A block remapping method was proposed by Hammerle-Uhl et al. [
45] to perform non-invertible transformation. The iris image is first normalized and partitioned into image blocks. Then, random permutation is applied to the each block, followed by the image remapping technique. The random and repeated remapping process prevents the reconstruction of the original iris image. Although the non-invertibility criterion was fulfilled through the block remapping process, Jenisch et al. [
46] demonstrated that 60% of the original iris image could be reconstructed from the stolen template.
Ouda et al. [
47] proposed a cancelable biometrics scheme—BioEncoding—without user-specific keys or tokens. The consistent bits,
where
denotes the length of the bit vector, are first determined from a series of iris codes of each user. This allows the elimination of bits with a higher probability to flip within several iris samples of the same individual. The positions of all consistent bits are stored. The bit vector is grouped
into
binary codewords and each codeword is mapped to a single bit value generated by a random sequence S of length
. The mapped binary bit values are then used to construct the final BioCode according to their associated positions. For the non-invertibility requirement, the many-to-one nature of the mapping guarantees its irreversibility. To improve the scheme’s resistance against correlation attacks, the original biometric template could be permuted or XORed with a different random sequence of the same length before applying BioEncoding transformation. However, Lacharme [
48] pointed out that restoration was feasible if the Boolean function used to generate the random sequence was discovered.
An alignment-free cancelable iris biometrics based on adaptive Bloom filters was introduced by Rathgeb et al. [
49]. Bloom filter-based representations of biometric templates such as iris codes enable an efficient alignment-invariant biometric comparison at matching stages. Besides, the many-to-one mapping of biometric features to a Bloom filter is non-invertible. For cancelable template refreshment, they applied an application-specific secret key—for example, seed values—to fulfill the unlinkability criterion. The accuracy performance of Bloom filter was comparable to its original counterparts. However, restoration of the biometric template was reported successful with low complexity of
[
50]. This was followed by possible unlinkability attacks where two Bloom filters generated from the same iris codes were identified with high probability when smaller key space was used to preserve the accuracy performance [
51]. Recent work from Gomez-Barrero et al. [
52] suggested an alternative to preventing cross-matching attacks in Bloom filter-based template protection schemes. Cancelable biometrics generation based on randomized look-up table mapping was initiated by Dwivedi et al. [
53]. Rotation invariant iris templates are first selected based on the minimum hamming distance. The row vector is then divided into
groups of
bits binary codewords. The corresponding decimal values for all the groups are encoded through a look-up table with
randomly generated bits for all possible decimal values ranging from
to
. The newly mapped binary codeword becomes the final cancelable template. The iris codes are at risk with information about block size and
being stolen, since look-up table and cancelable templates are stored in the database as well. The author emphasized the need to further secure the look-up table generation for stolen-token scenarios. Recent work from Umer et al. [
54] demonstrated a feature learning method for a cancelable iris recognition system. Among other feature representations, a sparse representation coding technique showed better discriminability, employing a multi-class linear support vector machine (SVM) classifier. The existing BioHashing scheme is applied and extended by using two tokens, which are subject specific and subject independent, respectively. Despite the flexibility in template renewal, no in-depth security analysis was discussed regarding the proposed scheme.
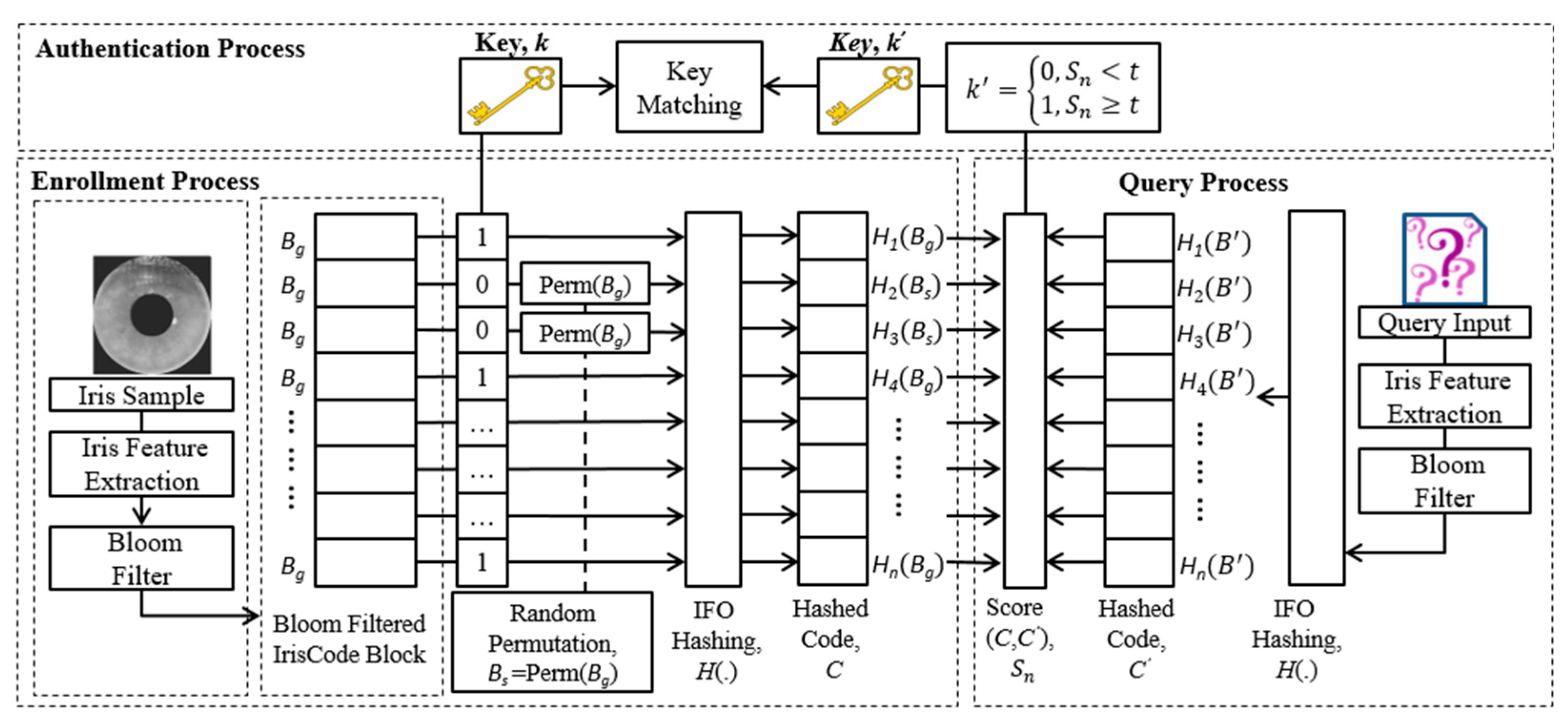
Our proposed scheme incorporated Bloom filter [
49] and Indexing First One hashing (IFO) [
55] for the purpose of alignment-free biometric template generation, as explained in our recent work [
56]. Thus, a brief introduction about IFO and Bloom filter are given to facilitate the understanding of our proposed scheme in the methodology section. For a detailed explanation of these two techniques, the reader is referred to [
49,
55].
In order to resolve the head rotation issues in IrisCode, the Bloom filter technique [
49] can be adopted to transform the original IrisCode
into an alignment-free binary matrix named Bloom filtered IrisCode,
through
. Suppose we define
and
as the number of columns and rows, respectively. The matrix of IrisCode is first split into
blocks with a size
each, where
and
. Each block constitutes the formation of a Bloom filter with values within
. All elements of
are initially zeros and element ‘1’ is added to
based on the decimal position calculated from the column codeword,
in each block. In the scenario where the same
is being mapped multiple times within a Bloom filter,
thus results in a many-to-one mapping and loss of information. Hence, the reconstruction of the original IrisCode can be prevented with this feature of non-invertibility. The collection of every Bloom filter
of each block (for
) in an input matrix constitutes the final matrix of Bloom filtered IrisCode,
.
IFO hashing scheme [
55] is adopted to achieve cancelable template protection and flexibility in system storage. First, any arbitrary binary input of IrisCode with a dimension
is permuted with
number of random permutation sequences in a column-wise manner. All the randomly permuted IrisCodes are multiplied to generate a
-ordered Hadamard product code. Utilizing the concept of min-hashing, select the first ‘1’ among the first
elements for each row of the product code. The index value of the first occurrence of ‘1’ is then recorded. The concept is further extended by imposing a modulo thresholding function. The imposed security threshold value
can be used to regulate the security leakage while inducing a many-to-one mapping in strengthening the non-invertibility properties of this scheme. An
matrix of IFO hashed codes
is obtained by repeating these steps with
independent hash functions.
2.4. Motivation and Contribution
As highlighted in the previous section, there are limitations in both biometric cryptosystems and cancelable biometrics. ECC is often limited by its error correcting capacity and feasibility when it comes to practical implementation in biometrics. It is susceptible to attacks such as statistical attacks and trade-offs between performance and security. The performance of biometrics such as iris and fingerprint are always affected by an alignment issue, and the processes to reduce this effect are often tedious and time consuming.
The proposed design is leveraging on both biometric systems to tackle this open problem. In this paper, we proposed an alignment free iris key binding scheme with cancelable transform without depending on ECC. This idea is another approach based on chaffing and winnowing similar to Jin’s approach [
57]. This concept is often used in cryptology for data encryption when transferring through an insecure channel where direct application to biometrics is inappropriate due to the randomness and variability nature of the data. Our work adopted IFO hashing to achieve non-invertible and cancelable transformation for biometrics and the cryptographic key binding process under the proposed scheme. The contributions of this work are presented as follows:
Key regeneration: A new formulation to measure the success rate for key retrieval under genuine query is proposed and defined as Key Retrieval Rate (KRR). Thorough analysis was conducted to prove that KRR is in relation to Jaccard similarity. We demonstrated the calculation of KRR under certain configurations and its implementation in security analysis for indistinguishability game as well as false accept attacks.
Cancelability and renewal: A fast and simple method for key renewal is proposed. The proposed method requires neither re-enrollment of biometrics nor constant storage for seeds. This can be achieved by reshuffling the hashing functions randomly.
Security analysis: We performed in-depth analysis on the indistinguishability between synthetic and genuine biometric templates under the proposed scheme. The adversary’s advantages in distinguishing the genuine and synthetic templates were evaluated through our proposed indistinguishability game. Besides that, potential brute force attacks and false accept attacks were investigated in detail.
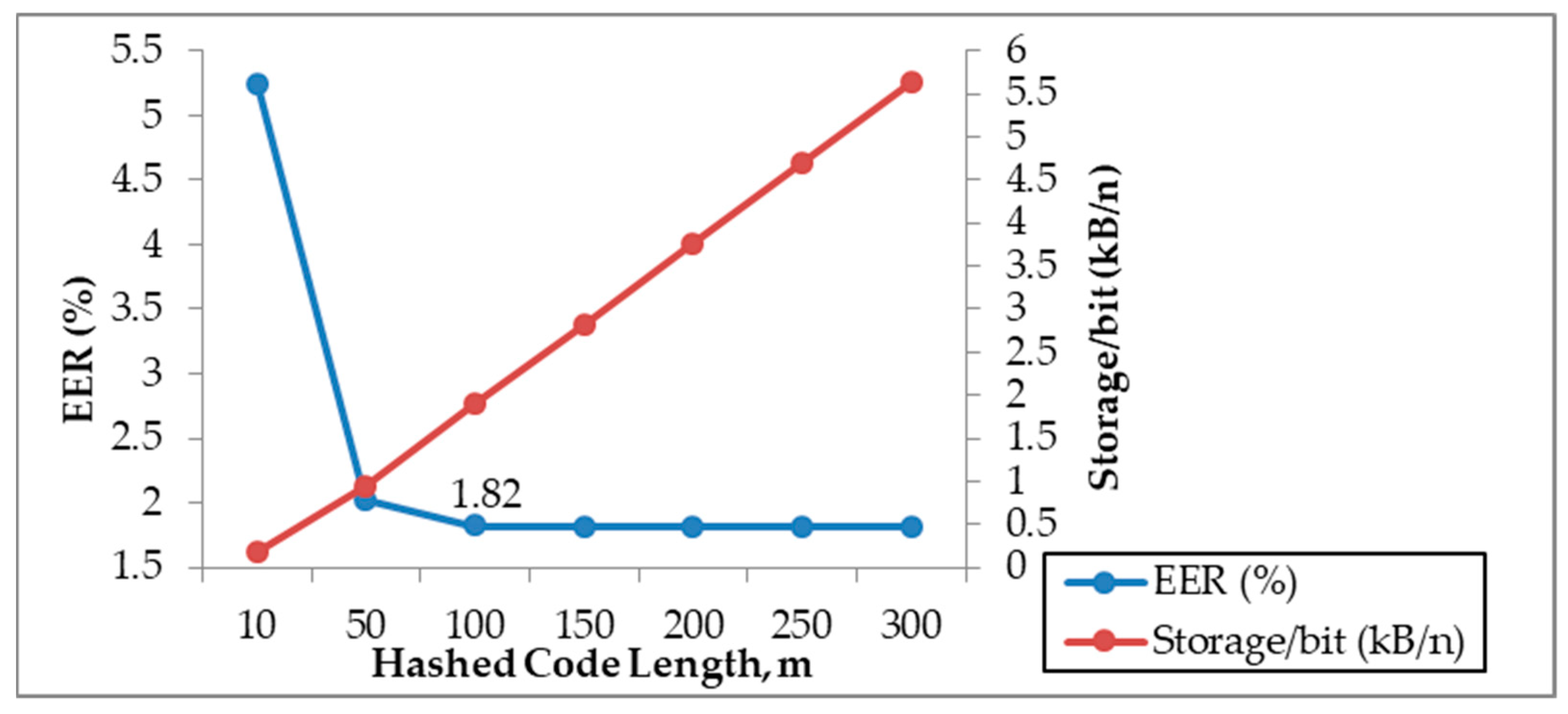
Feature representation and
storage: In this non-hierarchical key binding design, biometric template size and key length have critical effects on the storage space and computation power. The proposed format for biometric template in [
57] is not directly applicable for all types of biometrics, especially iris. Thus, we induced the scheme with more flexibility through tuneable storage. This is achievable via controllable hash code length.
Performance discrepancy: The key binding approach in [
57] reported FAR more than zero in their implementation on fingerprint. This implies the potential of this scheme to be compromised through FAR related attacks. This can lead to significant reduction in security and severe privacy leakage. Thus, there is a need to conduct in-depth analysis on security and privacy leakage to understand the full potential and the bottleneck of the chaffing and winnowing based key binding scheme.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}