DA-OCBA: Distributed Asynchronous Optimal Computing Budget Allocation Algorithm of Simulation Optimization Using Cloud Computing

Abstract
:1. Introduction
2. Background and Related Works
2.1. Simulation Optimization, Ranking, and Selection
2.2. Cloud Computing with Ranking and Selection
2.3. Simulation Analytics and Random Number
- Simulation data are clean, complete, and can easily be organized (but should not be summarized) and generated. In addition, within the computation of budget constraints, the amount of data is under our control.
- Probability models that describe the underlying stochastic inputs are known and are also under our control, as are the random-number assignments that generate realizations [38].
- Logical structures that cause state transitions (e.g., entity networks or agent rules) are also known and can be manipulated.
3. Problem Statement
3.1. Discrete Event System
3.2. Probability of Correct Selection
3.3. The Asymptotic Allocation Rule
- Concentration: The peak of the normal curve is in the center, where the mean is located.
- Symmetry: The center of the normal curve is the mean, the normal curve is left–right symmetric, and the ends of the curve never intersect the horizontal axis.
- Uniform variability: The normal curve starts from the place where the mean is located, and the curve gradually decreases uniformly toward the left and right sides.
- The normal cumulative distribution function is an X-axis monotonically increasing function.
- The normal cumulative distribution function is normalized; this function is monotonically increasing, and it approaches 1.
| Algorithm 1 Theorem 1—Obtain the number of simulation samples for every competing design. |
| Input: mean of designs , variance of designs , one-step budget for simulation , total number of designs k, number of every design running , number of every design running in the next , best design b, second-best design s, Output: number of designs used to run
|
4. System Architecture and the DA-OCBA Framework
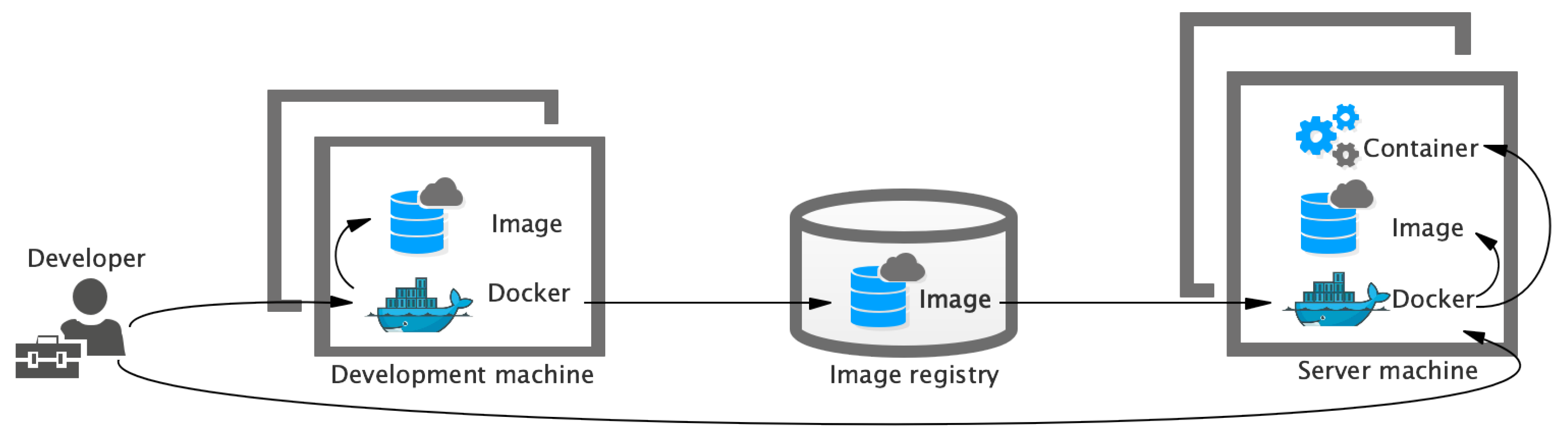
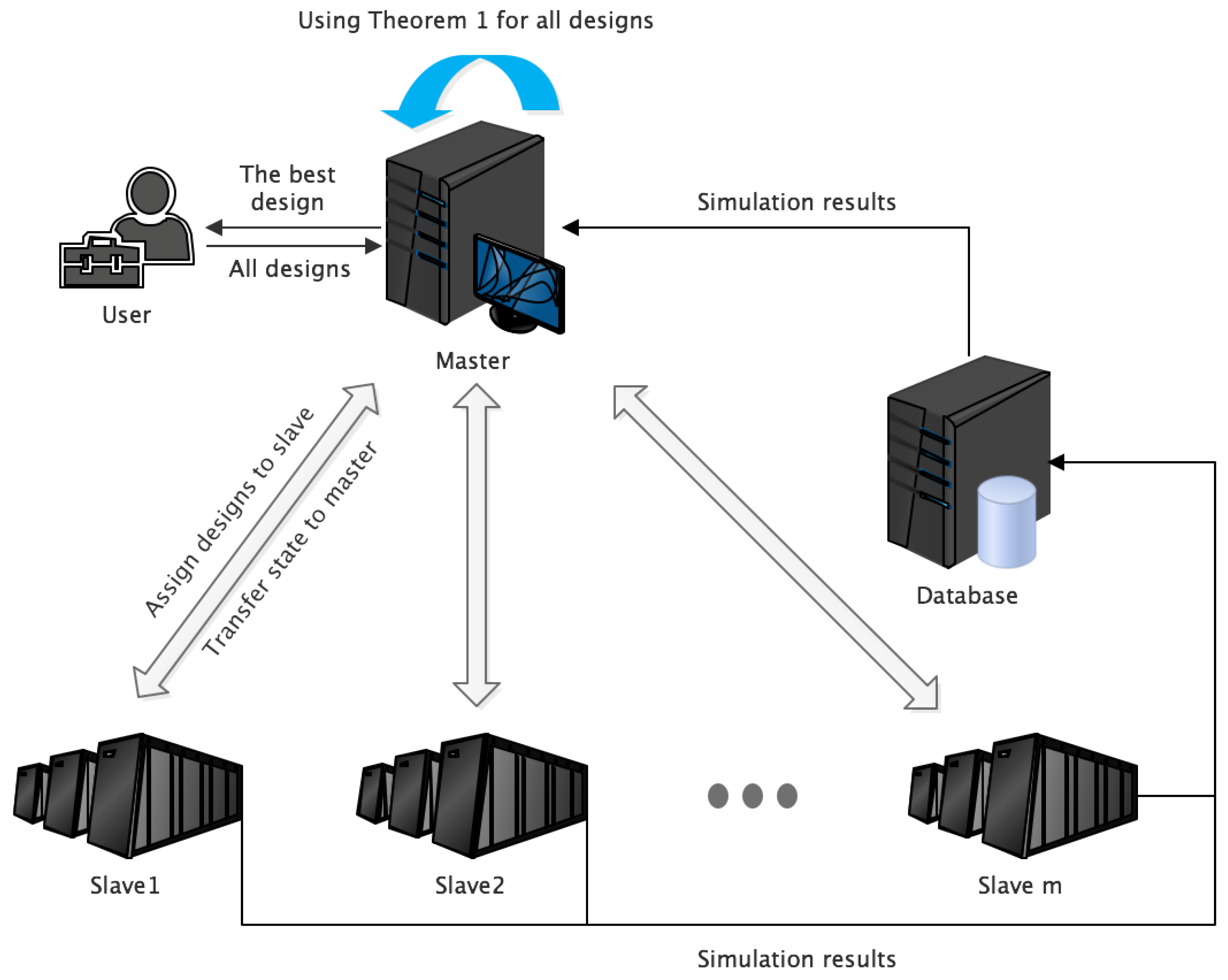
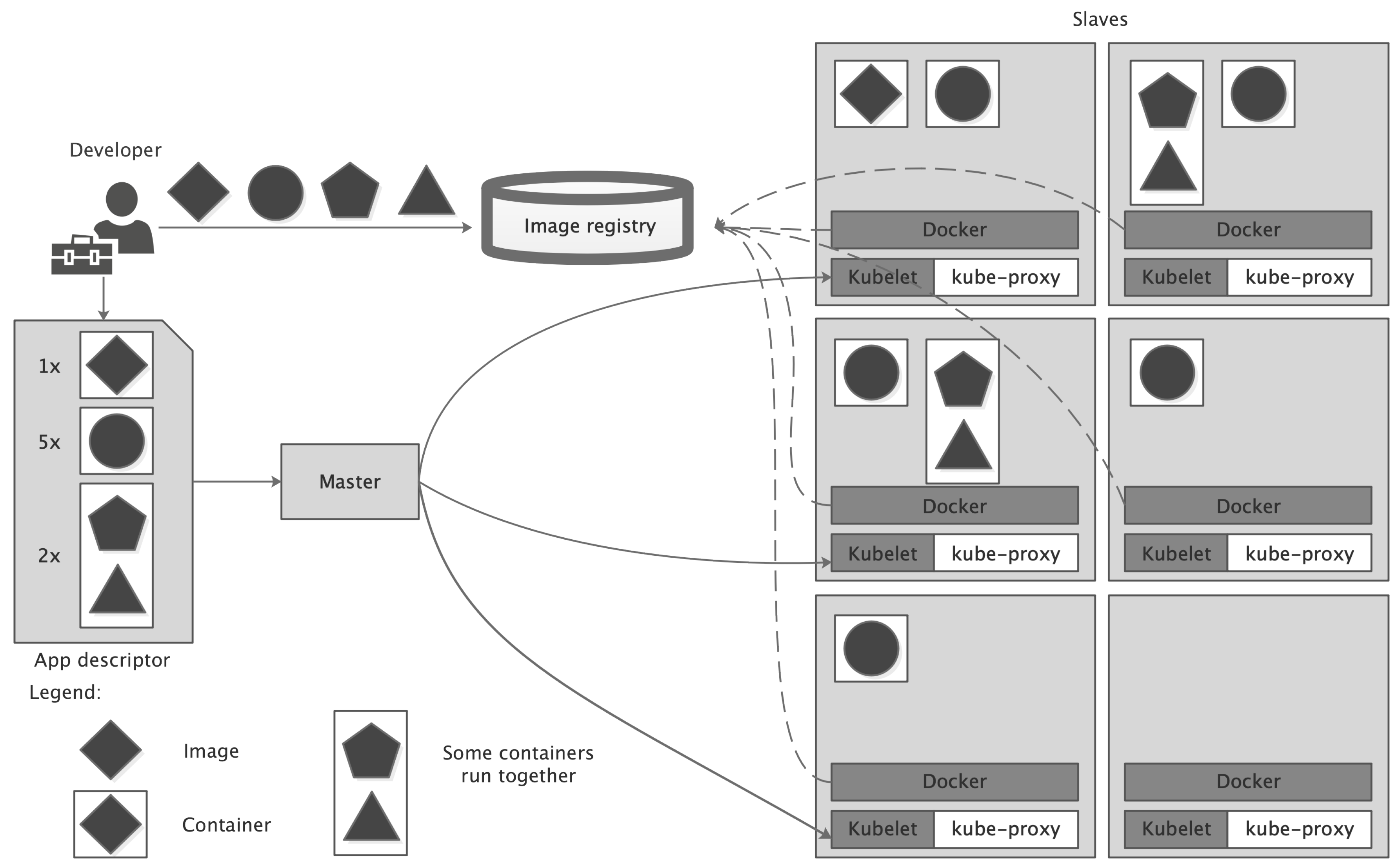
4.1. Architecture for Cloud Platform
4.2. DA-OCBA Framework
| Algorithm 2 APCS—Lower bound of the correct selection probability as the approximate PCS. |
| Input: the mean of designs , the executed number of designs , the variance of designs , the total number of designs k, the best design b, Output: the probability of correct selection PCS
|
| Algorithm 3 DA-OCBA—Distributed Asynchronous Optimal Computing Budget Allocation. |
| Input: number of initial implementations for all designs , number of docker containers , computing performance of cloud n, number of simulation designs k, one-step budget for simulation , probability of correct selection Output: the best design b, PCS, the sum budget
|
4.3. Random Number between Serial and Parallel
| Algorithm 4 Consistent random number sequence. |
| Input: number of random-number seeds n, array of random-number seed , probability of correct selection Output: random-number seeds
|
4.4. Time Complexity
5. Experiments
6. Results and Discussion
6.1. Inconsistent Random Number between Serial and Parallel
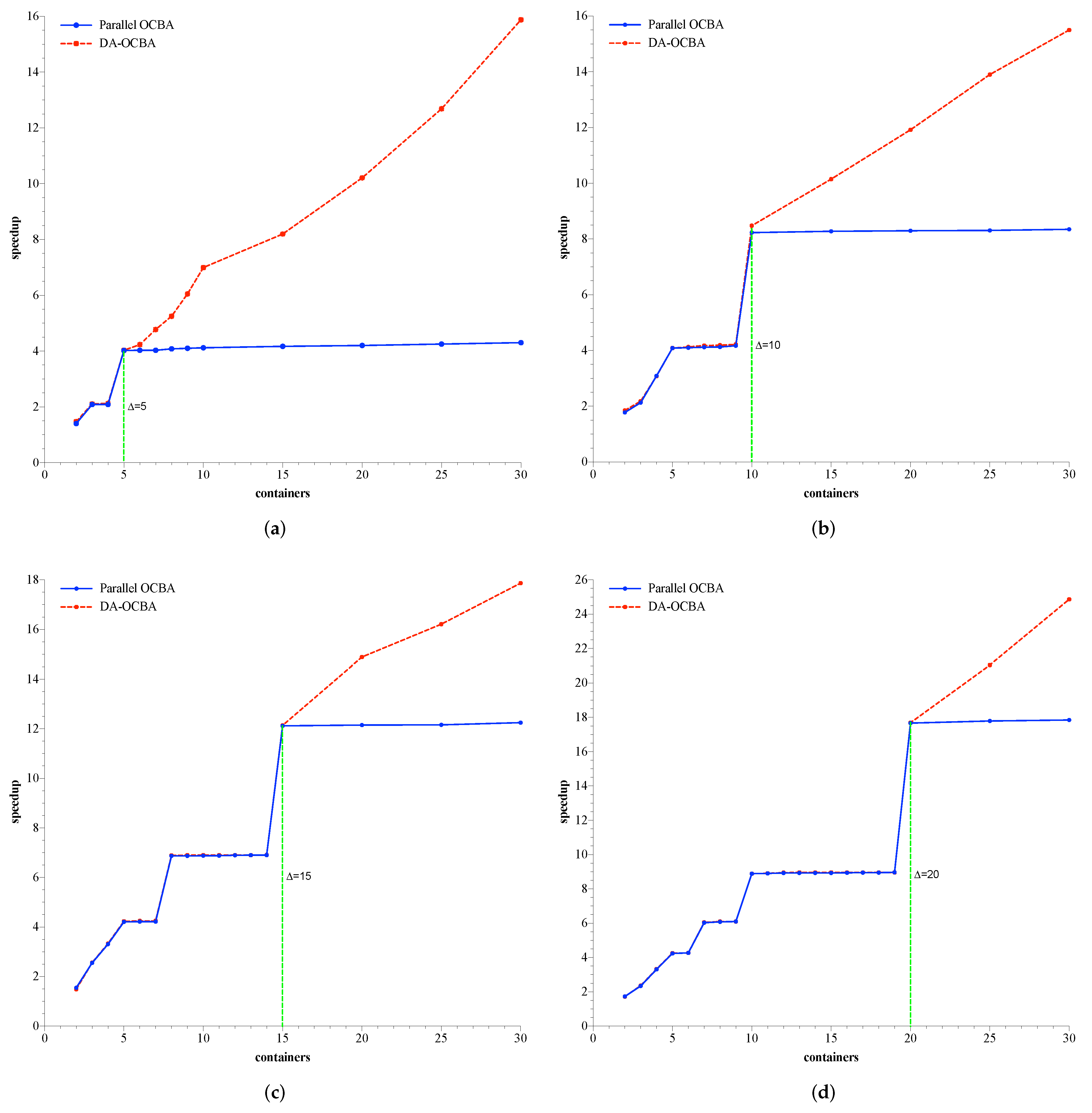
6.2. Performance Comparison
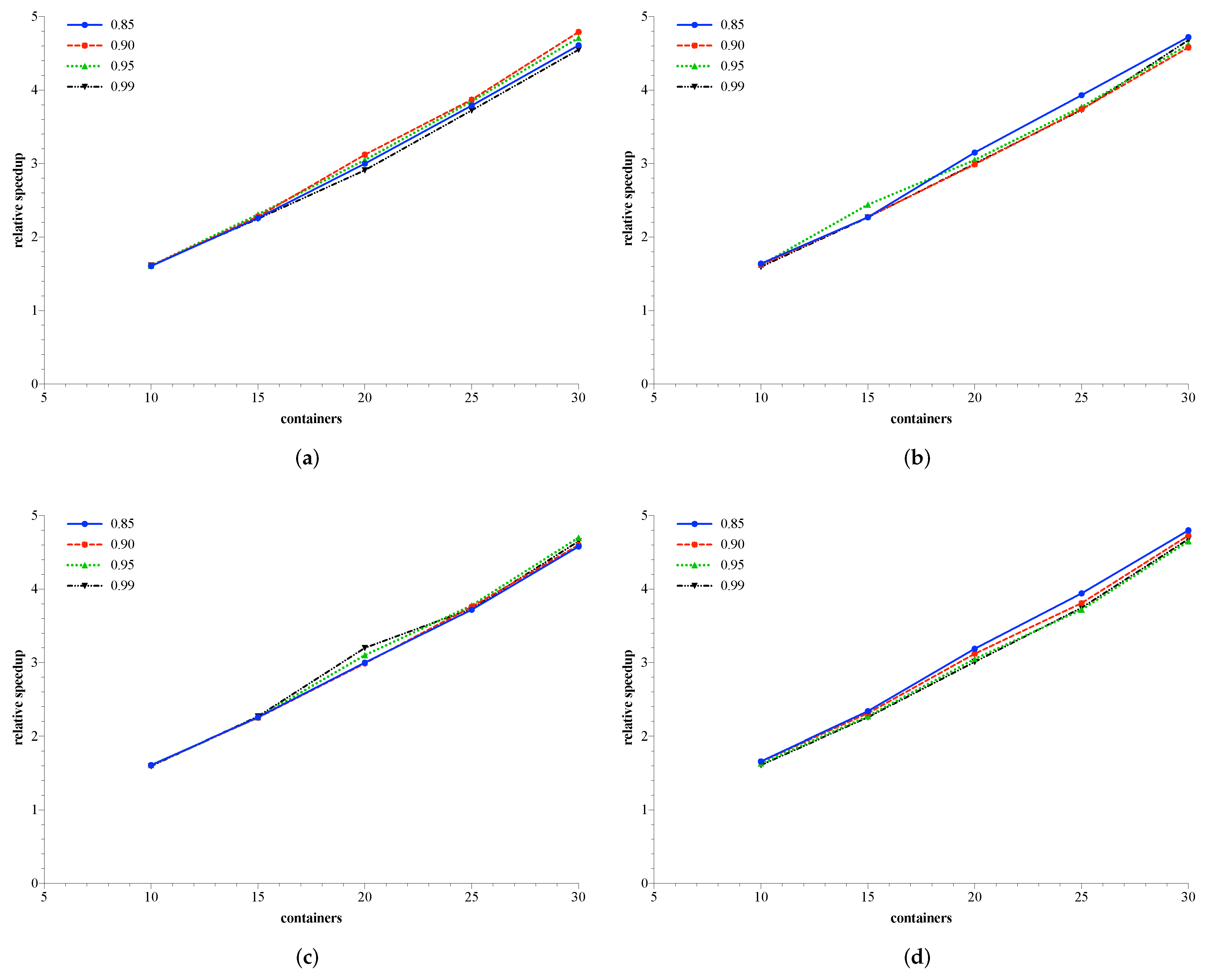
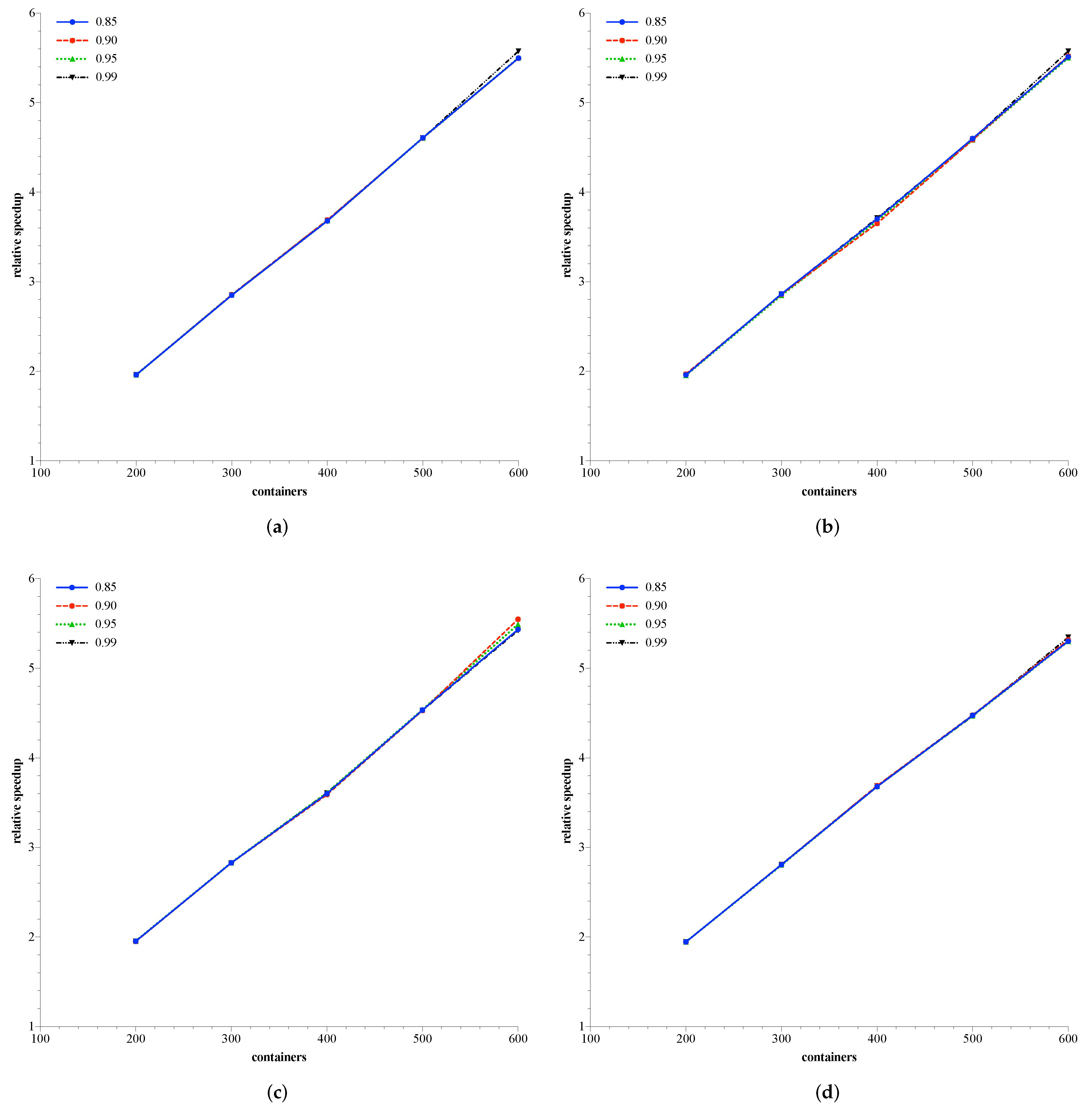
6.3. Relative Speedup of DA-OCBA
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| Notation | Description |
| search space, an arbitrary, huge, structureless but finite set. | |
| system design parameter vector for design i. | |
| the standard normal cumulative distribution function. | |
| L | sample performance, as a function of . |
| J | performance criterion that is the expectation of L. |
| random vector that represents uncertain factors in the systems. | |
| T | total number of simulation samples. |
| k | number for designs. |
| execution number for design i. | |
| sample mean of design i. | |
| expected mean of design i. | |
| variance of design i. | |
| b | design having the smallest sample mean performance measure. |
| initial number of simulations. | |
| computing budget at each stage. | |
| number of docker containers. | |
| CS | Correct Selection is defined as that since design b is actually the best design. |
| PCS | Probability of Correct Selection (the solution obtained by simulation optimization is actually optimal). |
| APCS | lower bound of the correct selection probability as the approximate PCS. |
References
- Gosavi, A. Simulation-Based Optimization; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Fu, M.C. Handbook of Simulation Optimization; Springer: Berlin/Heidelberg, Germany, 2015; Volume 216. [Google Scholar]
- Amaran, S.; Sahinidis, N.V.; Sharda, B.; Bury, S.J. Simulation optimization: A review of algorithms and applications. Ann. Oper. Res. 2016, 240, 351–380. [Google Scholar] [CrossRef]
- Zhu, C.; Xu, J.; Chen, C.H.; Lee, L.H.; Hu, J.Q. Balancing search and estimation in random search based stochastic simulation optimization. IEEE Trans. Autom. Control 2016, 61, 3593–3598. [Google Scholar] [CrossRef]
- Kleijnen, J.P. Design and analysis of simulation experiments. In International Workshop on Simulation; Springer: Berlin/Heidelberg, Germany, 2015; pp. 3–22. [Google Scholar]
- Peng, Y.; Chen, C.H.; Chong, E.K.; Fu, M.C. A review of static and dynamic optimization for ranking and selection. In Proceedings of the 2018 Winter Simulation Conference (WSC), Gothenburg, Sweden, 9–12 December 2018; pp. 1909–1920. [Google Scholar]
- Akl, A.M.; Sarker, R.A.; Essam, D.L. Simulation optimization approach for solving stochastic programming. In Proceedings of the 2017 2nd IEEE International Conference on Computational Intelligence and Applications (ICCIA), Beijing, China, 8–11 September 2017; pp. 161–165. [Google Scholar]
- Gao, S.; Xiao, H.; Zhou, E.; Chen, W. Robust ranking and selection with optimal computing budget allocation. Automatica 2017, 81, 30–36. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.h.; Lee, L.H. Stochastic Simulation Optimization: An Optimal Computing Budget Allocation; World Scientific: Singapore, 2011; Volume 1. [Google Scholar]
- Chen, C.H.; Yücesan, E.; Dai, L.; Chen, H.C. Optimal budget allocation for discrete-event simulation experiments. IIE Trans. 2009, 42, 60–70. [Google Scholar] [CrossRef]
- Jian, N.; Henderson, S.G. An introduction to simulation optimization. In Proceedings of the 2015 Winter Simulation Conference (WSC), Huntington Beach, CA, USA, 6–9 December 2015; pp. 1780–1794. [Google Scholar]
- Al-Salem, M.; Almomani, M.; Alrefaei, M.; Diabat, A. On the optimal computing budget allocation problem for large scale simulation optimization. Simul. Model. Pract. Theory 2017, 71, 149–159. [Google Scholar] [CrossRef]
- Marinescu, D.C. Cloud Computing: Theory and Practice; Morgan Kaufmann: Burlington, MA, USA, 2017. [Google Scholar]
- Chung, M.T.; Quang-Hung, N.; Nguyen, M.T.; Thoai, N. Using docker in high performance computing applications. In Proceedings of the 2016 IEEE Sixth International Conference on Communications and Electronics (ICCE), Ha Long, Vietnam, 27–29 July 2016; pp. 52–57. [Google Scholar]
- DeHaan, M.P.; Henson, S.J.; Eckersberg, I.J.J. Flexible Cloud Management with Power Management Support. U.S. Patent 9,104,407, 2015. [Google Scholar]
- Lee, L.H.; Chen, C.H.; Chew, E.P.; Li, J.; Zhang, S. A review of optimal computing budget allocation algorithms for simulation optimization problem. Int. J. Oper. Res. 2010, 7, 19–31. [Google Scholar]
- Fu, M.C.; Glover, F.W.; April, J. Simulation optimization: A review, new developments, and applications. In Proceedings of the Winter Simulation Conference, Orlando, FL, USA, 4–7 December 2005; p. 13. [Google Scholar]
- Dudewicz, E.J.; Dalal, S.R. Allocation of observations in ranking and selection with unequal variances. Optim. Methods Stat. 1975, 37, 28–78. [Google Scholar]
- Rinott, Y. On two-stage selection procedures and related probability-inequalities. Commun. Stat. 1978, 7, 799–811. [Google Scholar] [CrossRef]
- Nelson, B.L.; Swann, J.; Goldsman, D.; Song, W. Simple procedures for selecting the best simulated system when the number of alternatives is large. Oper. Res. 2001, 49, 950–963. [Google Scholar] [CrossRef]
- Kim, S.H.; Nelson, B.L. A fully sequential procedure for indifference-zone selection in simulation. ACM Trans. Model. Comput. Simul. (TOMACS) 2001, 11, 251–273. [Google Scholar] [CrossRef]
- Goldsman, D.; Nelson, B.L.; Banks, J. Comparing systems via simulation. In Handbook of Simulation: Principles, Methodology, Advances, Applications, and Practice; John Wiley & Sons: Hoboken, NJ, USA, 1998; pp. 273–306. [Google Scholar]
- Law, A.M.; Kelton, W.D.; Kelton, W.D. Simulation Modeling and Analysis; McGraw-Hill: New York, NY, USA, 2000; Volume 3. [Google Scholar]
- Kim, S.H.; Nelson, B. Selecting the best system: Simulation. In Elsevier Handbooks in Operations Research and Management Science: Simulation; Elsevier: Amsterdam, The Netherlands, 2006. [Google Scholar]
- Chen, C.H.; Lin, J.; Yücesan, E.; Chick, S.E. Simulation Budget Allocation for Further Enhancing the Efficiency of Ordinal Optimization. Discret. Event Dyn. Syst. 2000, 10, 251–270. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.H.; Donohue, K.; Yücesan, E.; Lin, J. Optimal computing budget allocation for Monte Carlo simulation with application to product design. Simul. Model. Pract. Theory 2003, 11, 57–74. [Google Scholar] [CrossRef]
- Lin, C.T.; Chen, J.; Jiang, W.J.; He, L.Y.W.; Shih, P.T.; Ho, C.H.; Chi, S. Ultra-High Data-Rate 60 GHz Radio-over-Fiber Systems Employing Optical Frequency Multiplication and Adaptive OFDM Formats. J. Lightwave Technol. 2010, 28, 2296–2306. [Google Scholar]
- Glynn, P.; Juneja, S. A large deviations perspective on ordinal optimization. In Proceedings of the 36th Conference on Winter Simulation, Washington, DC, USA, 5–8 December 2004; pp. 577–585. [Google Scholar]
- Bogon, T.; Timm, I.J.; Jessen, U.; Schmitz, M. Towards assisted input and output data analysis in manufacturing simulation: The EDASim approach. In Proceedings of the Winter Simulation Conference, Berlin, Germany, 9–12 December 2012; p. 257. [Google Scholar]
- Laporte, G.J.; Branke, J.; Chen, C.H. Optimal computing budget allocation for small computing budgets. In Proceedings of the 2012 Winter Simulation Conference (WSC), Berlin, Germany, 9–12 December 2012. [Google Scholar]
- Chen, C.H.; He, D.; Fu, M. Efficient dynamic simulation allocation in ordinal optimization. IEEE Trans. Autom. Control 2006, 51, 2005–2009. [Google Scholar] [CrossRef]
- Ni, E.C.; Ciocan, D.F.; Henderson, S.G.; Hunter, S.R. Efficient Ranking and Selection in Parallel Computing Environments. Oper. Res. 2016, 65, 821–836. [Google Scholar] [CrossRef]
- Radu, L.D. Green cloud computing: A literature survey. Symmetry 2017, 9, 295. [Google Scholar] [CrossRef]
- Kim, S.H.; Nelson, B.L. Selecting the best system. Handb. Oper. Res. Manag. Sci. 2006, 13, 501–534. [Google Scholar]
- Luo, J.; Hong, L.J. Large-scale ranking and selection using cloud computing. In Proceedings of the 2011 Winter Simulation Conference (WSC), Phoenix, AZ, USA, 11–14 December 2011; pp. 4046–4056. [Google Scholar]
- Xu, J.; Huang, E.; Chen, C.H.; Lee, L.H. Simulation optimization: A review and exploration in the new era of cloud computing and big data. Asia-Pac. J. Oper. Res. 2015, 32, 1550019. [Google Scholar] [CrossRef]
- Nelson, B.L. ‘Some tactical problems in digital simulation’for the next 10 years. J. Simul. 2016, 10, 2–11. [Google Scholar] [CrossRef]
- Chick, S.E.; Inoue, K. New procedures to select the best simulated system using common random numbers. Manag. Sci. 2001, 47, 1133–1149. [Google Scholar] [CrossRef]
- Law, A.M.; Kelton, W.D. Simulation Modeling and Analysis; McGraw-Hill: New York, NY, USA, 2009. [Google Scholar]
- Lee, L.H.; Pujowidianto, N.A.; Li, L.W.; Chen, C.H.; Yap, C.M. Approximate Simulation Budget Allocation for Selecting the Best Design in the Presence of Stochastic Constraints. IEEE Trans. Autom. Control 2012, 57, 2940–2945. [Google Scholar] [CrossRef]
- Chen, C.H.; Chen, H.C.; Dai, L. A gradient approach for smartly allocating computing budget for discrete event simulation. In Proceedings of the 28th Conference on Winter Simulation, Coronado, CA, USA, 8–11 December 1996; pp. 398–405. [Google Scholar]
- Inoue, K.; Chick, S.E. Comparison of Bayesian and frequentist assessments of uncertainty for selecting the best system. In Proceedings of the 1998 Winter Simulation Conference, Washington, DC, USA, 13–16 December 1998. [Google Scholar]
- Netto, H.V.; Lung, L.C.; Correia, M.; Luiz, A.F.; de Souza, L.M.S. State machine replication in containers managed by Kubernetes. J. Syst. Archit. 2017, 73, 53–59. [Google Scholar] [CrossRef]
- Chen, H.C.; Chen, C.H.; Lin, J.; Yucesan, E. An asymptotic allocation for simultaneous simulation experiments. In Proceedings of the Conference on Winter Simulation: Simulation-a Bridge to the Future, Phoenix, AZ, USA, 5–8 December 1999. [Google Scholar]
- Nakayama, M.K. Selecting the best system in steady-state simulations using batch means. In Proceedings of the 27th Conference on Winter Simulation, Arlington, VA, USA, 3–6 December 1995; pp. 362–366. [Google Scholar]
- Koenig, L.W.; Law, A.M. A procedure for selecting a subset of size m containing the l best of k independent normal populations, with applications to simulation. Commun. Stat. -Simul. Comput. 1985, 14, 719–734. [Google Scholar] [CrossRef]
- Boru, A.; Dosdoğru, A.T.; Göçken, M.; Erol, R. A Novel Hybrid Artificial Intelligence Based Methodology for the Inventory Routing Problem. Symmetry 2019, 11, 717. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Comparison | OCBA | IZ |
|---|---|---|
| Focus | Efficiency (maximizing probability of correct selection (PCS)) | Feasibility (finding a feasible way to guarantee PCS) |
| Total number of simulation samples | Equal to the computing budget which is set by the user | Uncertain (it depends on when the stopping rule is set to guarantee PCS) |
| PCS | The actual PCS is unknown. However, PCS can also be guaranteed as long as the value of Approximate PCS (APCS) is greater than the expected PCS. (Note that APCS is easy to calculate as shown in Section 3.2.) | The expected PCS is guaranteed to be achieved. The actual PCS is unknown and it is usually much higher than the expected PCS because the procedure is developed based on the most unfavorable configuration. |
| Assumptions | Based on Bayesian and Frequentist view | Based on Frequentist view |
| n = 10 | |||
|---|---|---|---|
| P(CS) % | Containers | ||
| 5 | 10 | 15 | |
| 95 | 6385 | 7830 | 9755 |
| 99 | 26,280 | 31,070 | 39,730 |
| n = 10 | |||
|---|---|---|---|
| SUM | Containers | ||
| 5 | 10 | 15 | |
| 4000 | 51.3% | 45.5% | 32.6% |
| 16,000 | 57.9% | 44.2% | 35.7% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Tang, W.; Yao, Y.; Zhu, F. DA-OCBA: Distributed Asynchronous Optimal Computing Budget Allocation Algorithm of Simulation Optimization Using Cloud Computing. Symmetry 2019, 11, 1297. https://doi.org/10.3390/sym11101297
Wang Y, Tang W, Yao Y, Zhu F. DA-OCBA: Distributed Asynchronous Optimal Computing Budget Allocation Algorithm of Simulation Optimization Using Cloud Computing. Symmetry. 2019; 11(10):1297. https://doi.org/10.3390/sym11101297
Chicago/Turabian StyleWang, Yukai, Wenjie Tang, Yiping Yao, and Feng Zhu. 2019. "DA-OCBA: Distributed Asynchronous Optimal Computing Budget Allocation Algorithm of Simulation Optimization Using Cloud Computing" Symmetry 11, no. 10: 1297. https://doi.org/10.3390/sym11101297