
Daily Streamflow Forecasting Based on the Hybrid Particle Swarm Optimization and Long Short-Term Memory Model in the Orontes Basin


Abstract
:1. Introduction
2. Materials and Methods
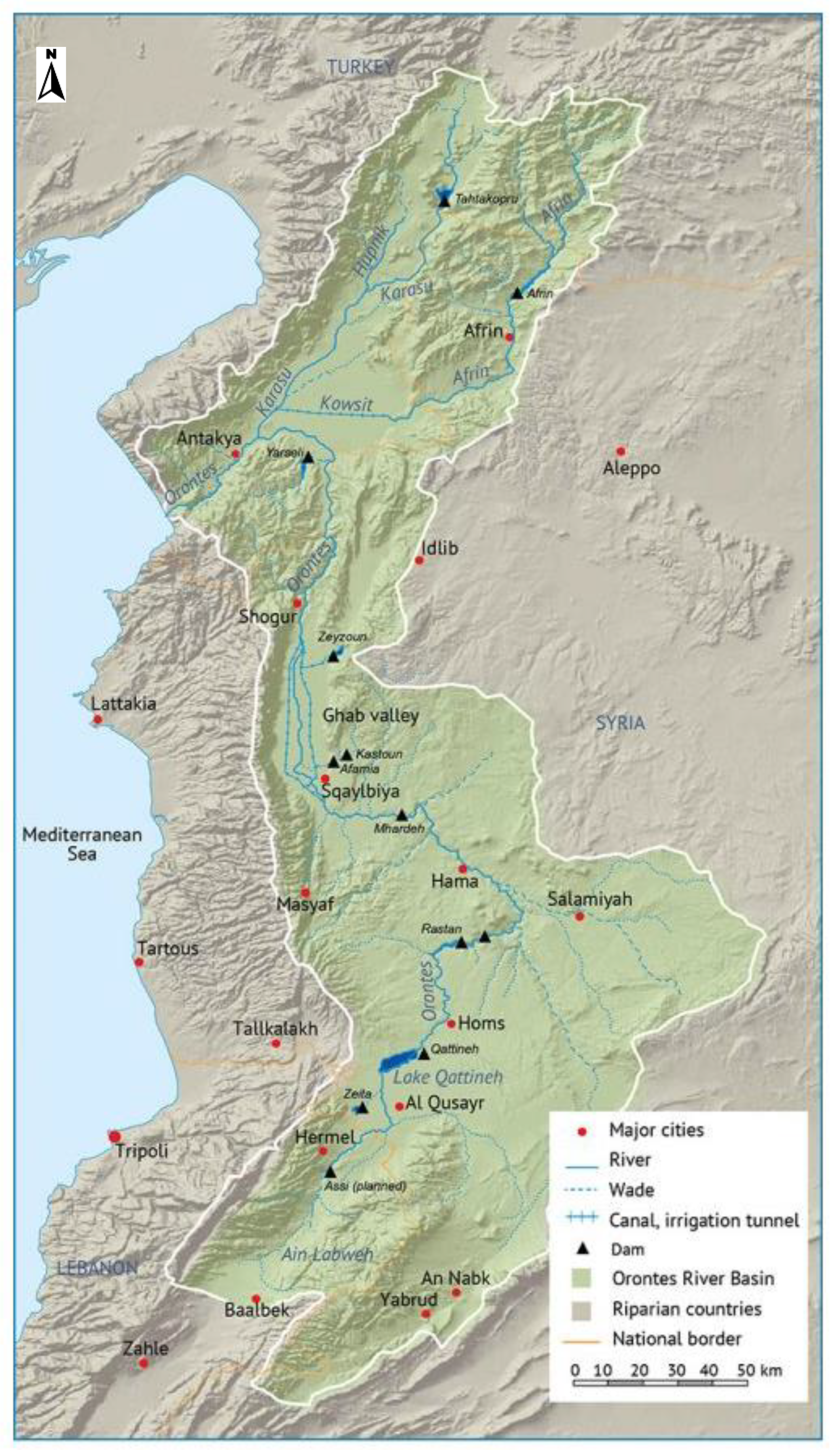
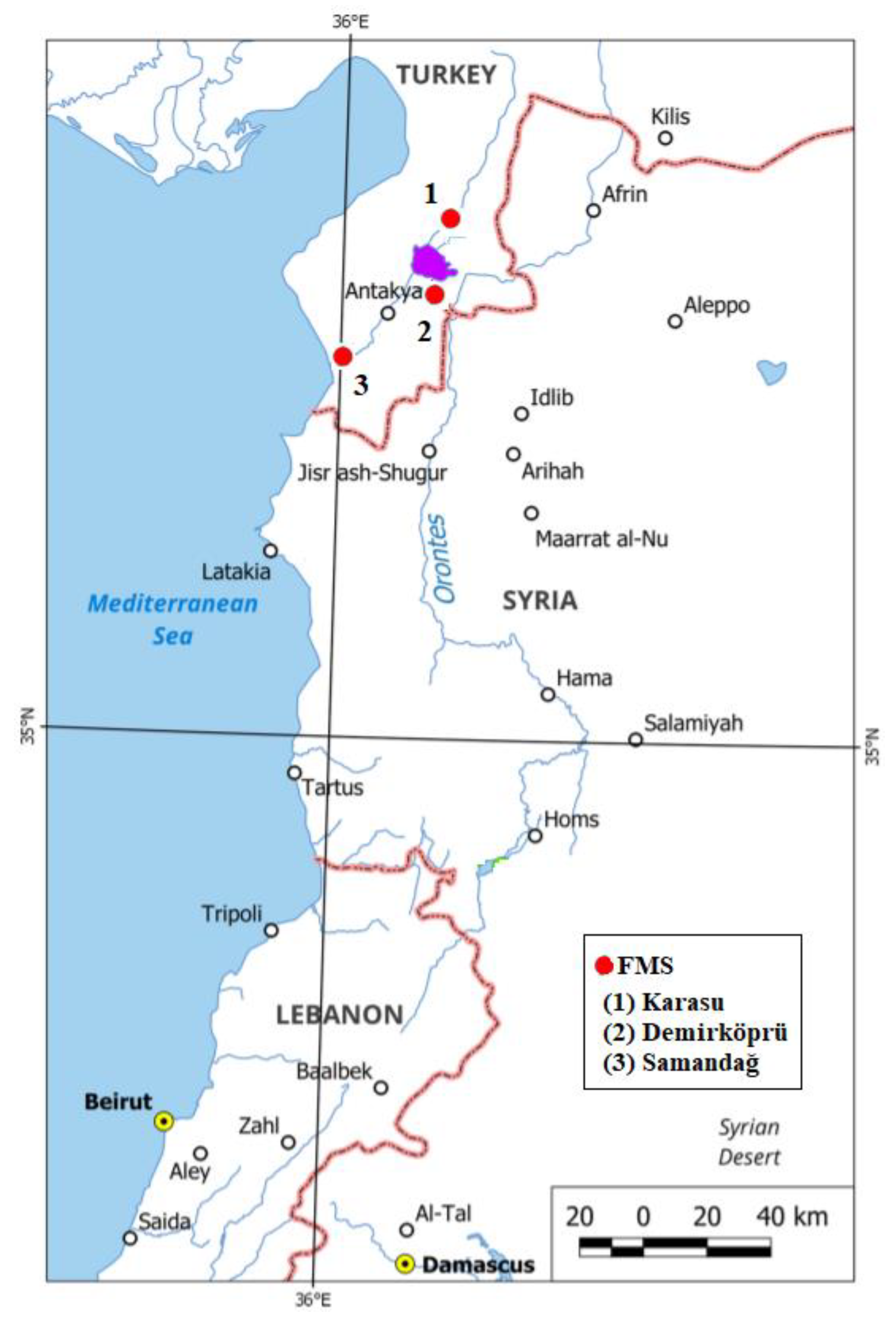
2.1. Study Region
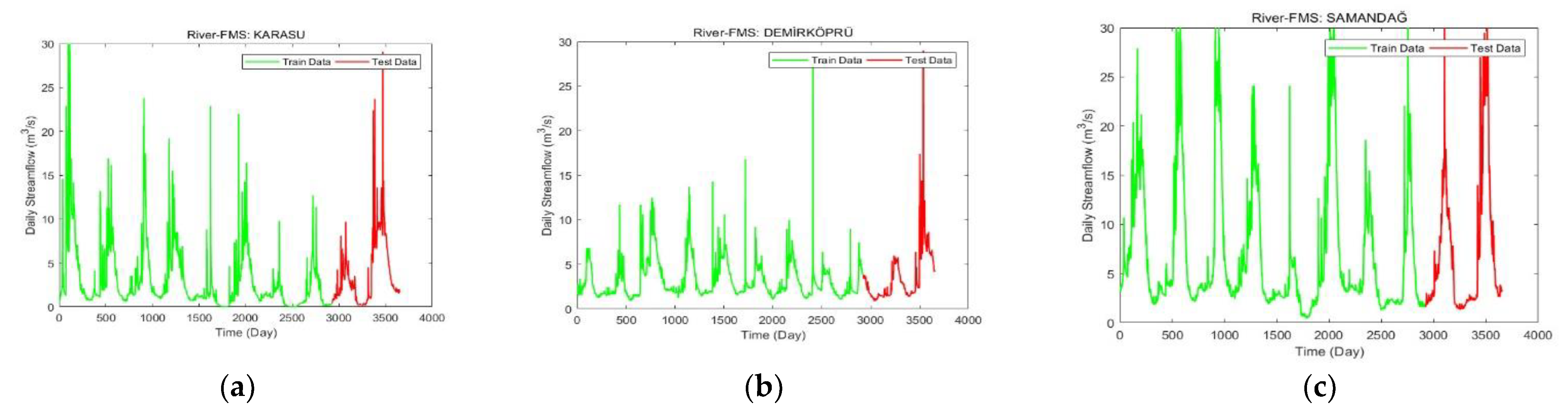
2.2. Datasets and Pre-Processing
2.3. Methods
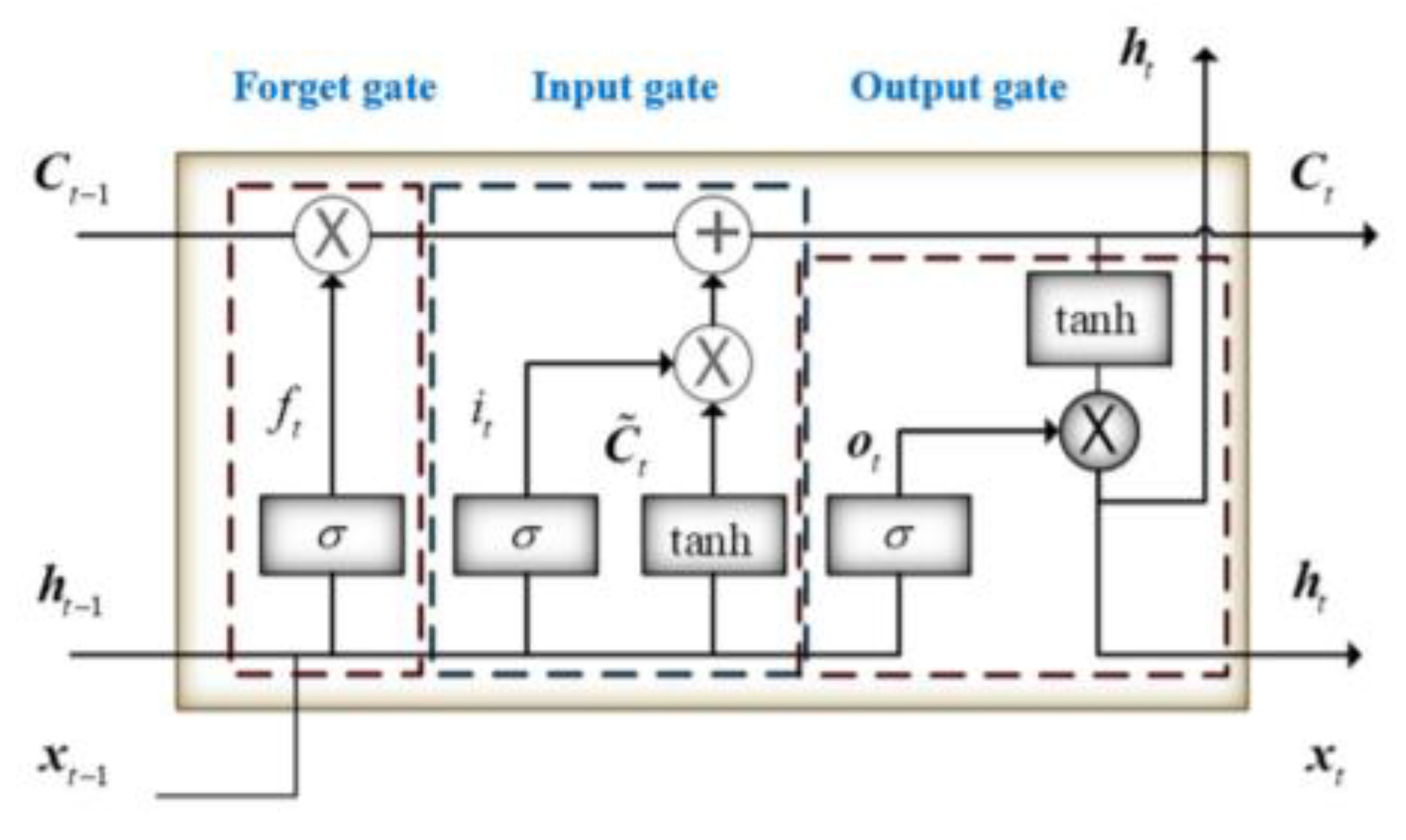
2.3.1. Long Short-Term Memory Network
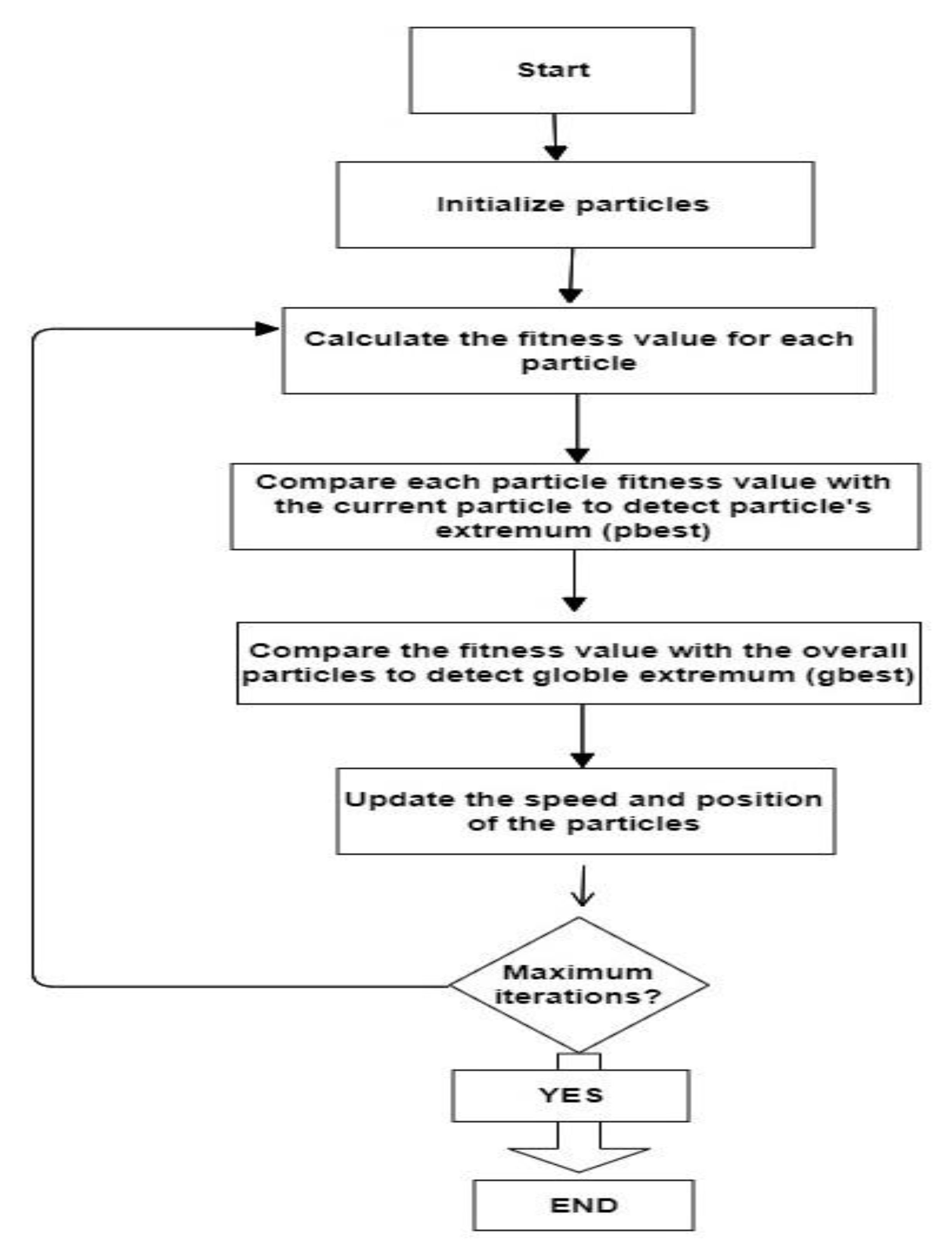
2.3.2. Particle Swarm Optimization
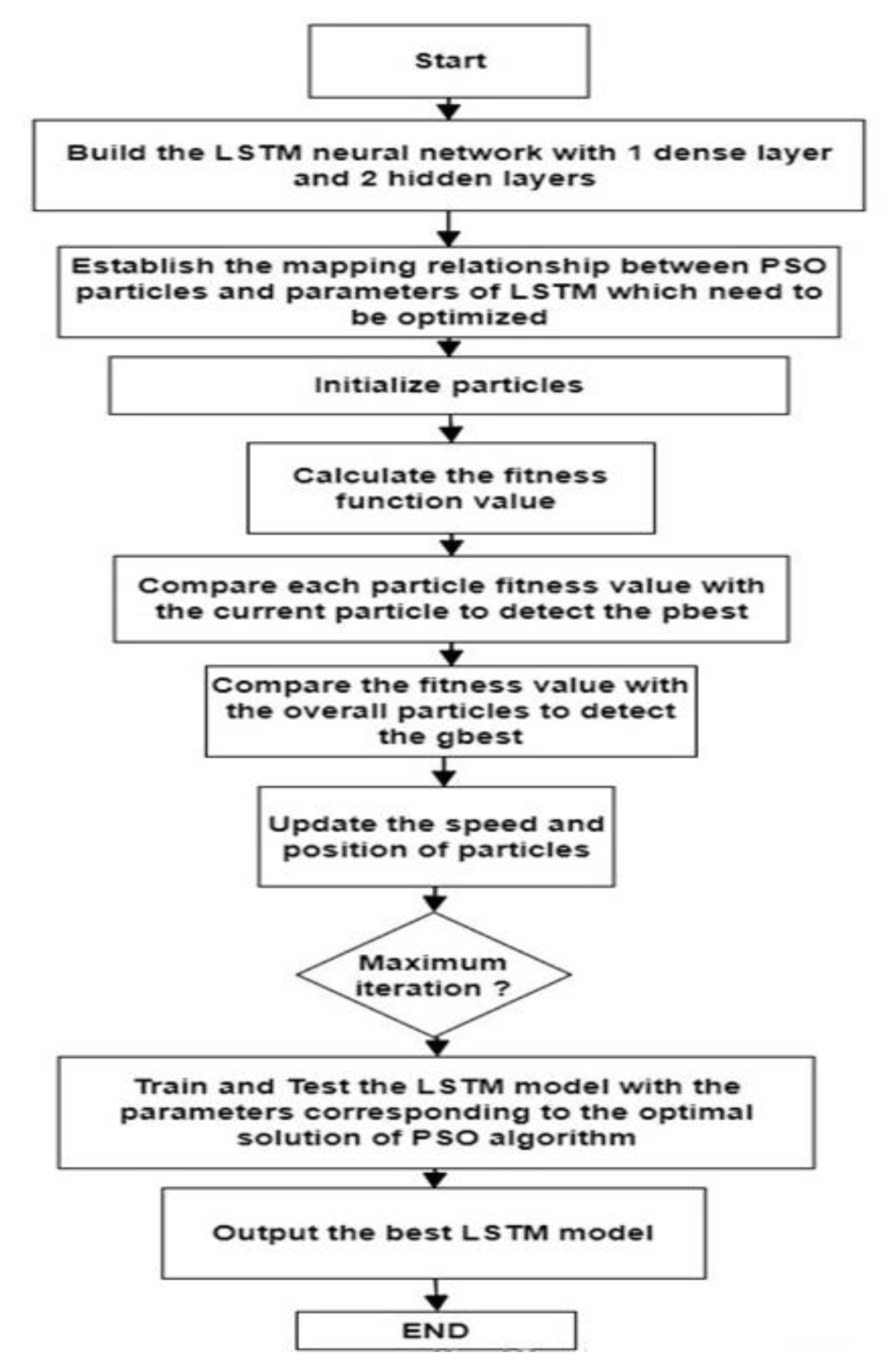
2.3.3. Forecasting Based on PSO-LSTM (Proposed) Model
3. Results
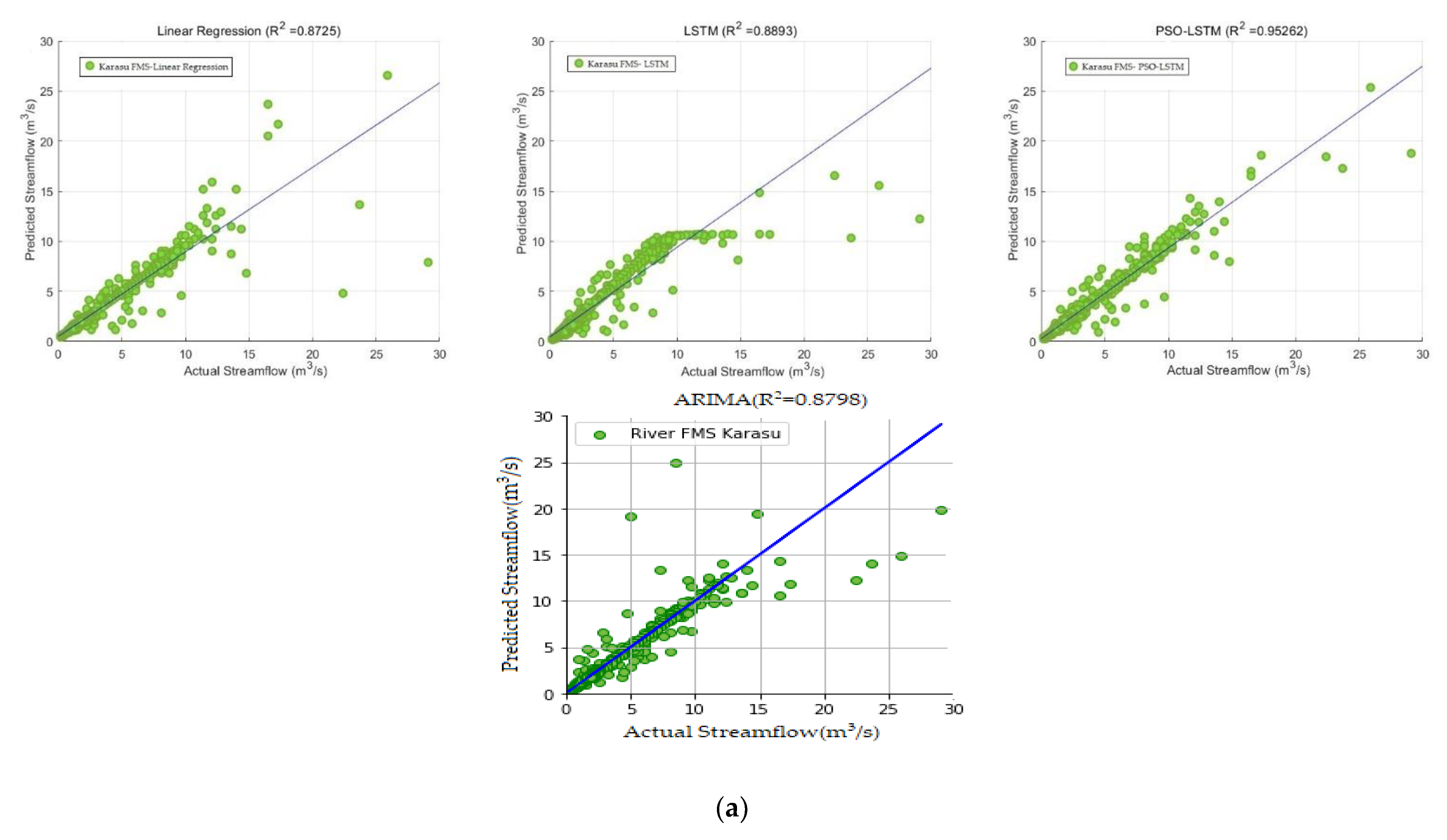
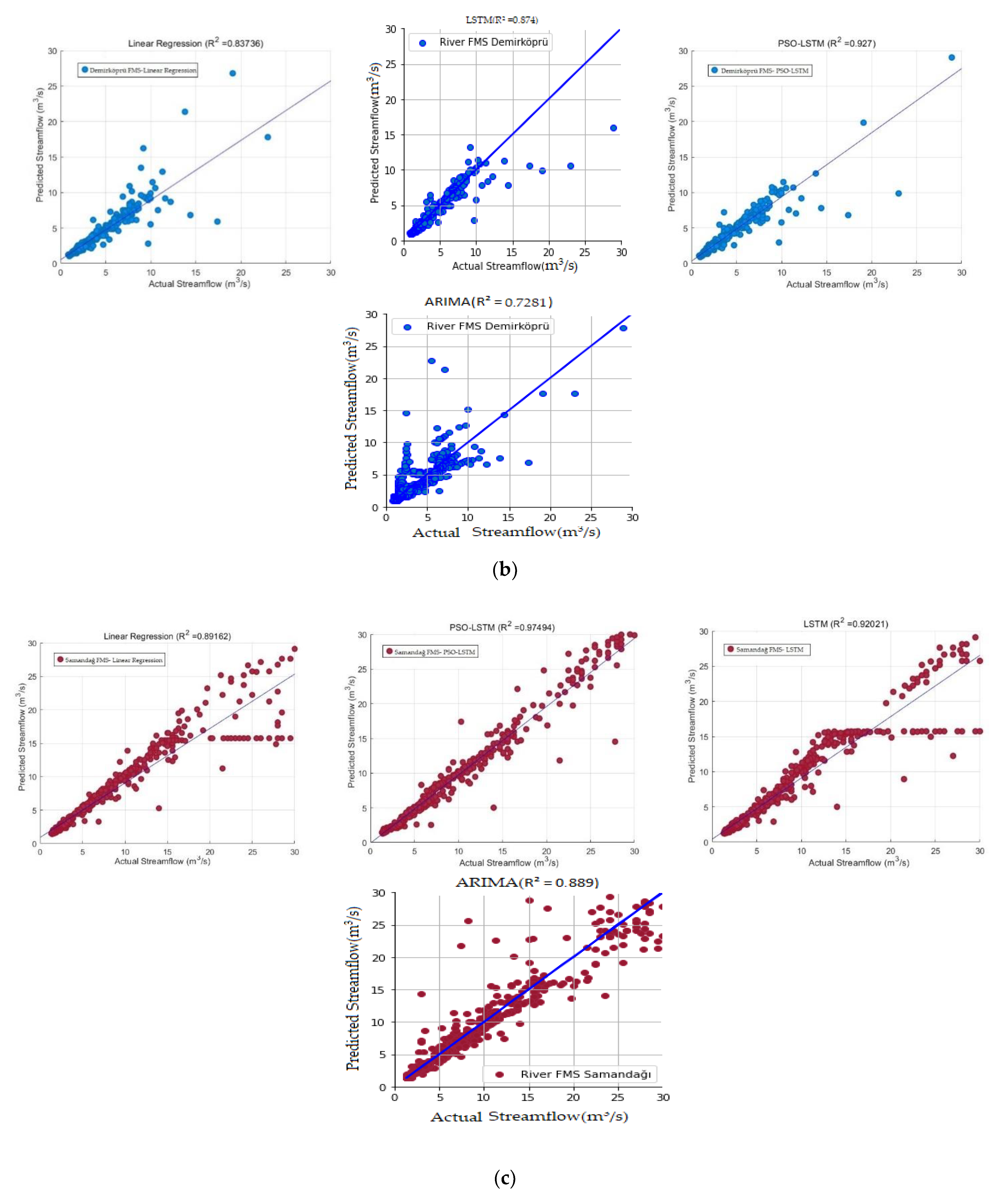
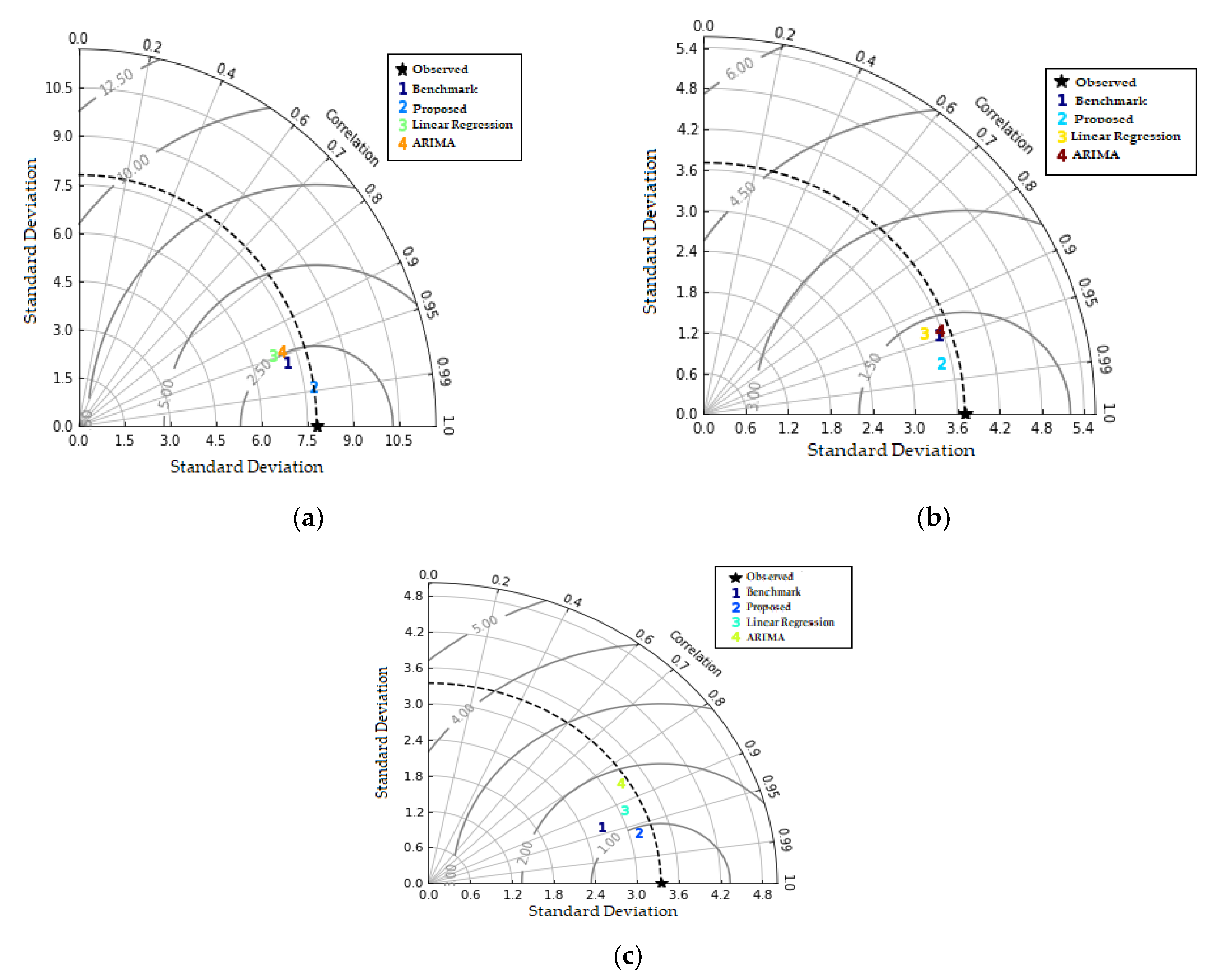
3.1. Performance Evaluation of Models
3.2. Comparative Analysis and Discussion
4. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbrevations
| ANN | artificial neural networks |
| DL | deep learning |
| DSI | Hydraulic State Works |
| EA | evolutionary algorithms |
| EIEI | Electrical Works Survey Administration General Directorate |
| FMS | flow measurement stations |
| GP | genetic programming |
| LSTM | long short-term memory |
| MAE | mean absolute error |
| MAPE | mean absolute percentage error |
| MSE | mean square error |
| PSO | particle swarm optimization |
| RMSE | root mean square error |
| RNN | recurrent neural networks |
| SD | standard deviation |
| SVM | support vector machine |
References
- Cosgrove, W.J.; Loucks, D.P. Water management: Current and future challenges and research directions. Water Resour. Res. 2015, 51, 4823–4839. [Google Scholar] [CrossRef] [Green Version]
- Özcan, T.İ.A. Multiple Reservoir Operation Applications in Water Resources Management. Master’s Thesis, Istanbul Technical University, Istanbul, Turkey, 2021. [Google Scholar]
- Dalkiliç, H.Y.; Hashimi, S.A. Prediction of daily streamflow by using artificial neural networks (ANNs), wavelet neural networks (WNNs), and adaptive neuro-fuzzy inference system (ANFIS) models. Water Supply 2020, 20, 1396–1408. [Google Scholar] [CrossRef] [Green Version]
- Xie, T.; Zhang, G.; Hou, J.; Xie, J.; Lv, M.; Liu, F. Hybrid Forecasting Model for Non-stationary Daily Runoff Series: A Case Study in the Han River Basin, China. J. Hydrol. 2019, 577, 123915. [Google Scholar] [CrossRef]
- Zhu, S.; Zhou, J.; Ye, L. Streamflow estimation by support vector machine coupled with different methods of time series decomposition in the upper reaches of Yangtze River, China. Environ. Earth Sci. 2016, 75, 531. [Google Scholar] [CrossRef]
- Xu, Z.; Zhou, J.; Mo, L.; Jia, B.; Yang, Y.; Fang, W.; Qin, Z. A Novel Runoff Forecasting Model Based on the Decomposition-Integration Prediction Framework. Water 2021, 13, 3390. [Google Scholar] [CrossRef]
- Sharma, P.J.; Patel, P.L.; Jothiprakash, V. Data-driven modelling framework for streamflow prediction in a physio-climatically heterogeneous river basin. Soft Comput. 2021, 25, 5951–5978. [Google Scholar]
- Shortridge, J.E.; Guikema, S.D.; Zaitchik, B.F. Machine learning methods for empirical streamflow simulation: A comparison of model accuracy, interpretability, and uncertainty in seasonal watersheds. Hydrol. Earth Syst. 2016, 20, 2611–2628. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Luo, J.; Li, P.; Zuo, G.; Xie, J. A Hybrid Model Based on Variational Mode Decomposition and Gradient Boosting Regression Tree for Monthly Runoff Forecasting. Water Resour. Manag. 2020, 34, 865–884. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Kisi, O.; Demir, V. Enhancing long-term streamflow forecasting and predicting using periodicity data component: Application of artificial intelligence. Water Resour. Manag. 2016, 30, 4125–4151. [Google Scholar]
- Nourani, V. Davanlou.; Tajbakhsh, A.; Molajou, A.; Gokcekus, H. Hybrid wavelet-M5 model tree for rainfall-runoff modeling. J. Hydrol. Eng. 2019, 24, 90–102. [Google Scholar] [CrossRef]
- Mehdizadeh, S.; Fathian, F.; Adamowski, J.F. Hybrid artificial intelligence-time series models for monthly streamflow modeling. Appl. Soft Comput. 2019, 80, 873–887. [Google Scholar] [CrossRef]
- Arab, M.; Faramarz, M.G.; Hashim, K. Applications of Computational and Statistical Models for Optimizing the Electrochemical Removal of Cephalexin Antibiotic from Water. Water 2022, 14, 344. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; Volume 27, pp. 3104–3112. [Google Scholar]
- Kisi, O.; Choubin, B.; Deo, R.C.; Yaseen, Z.M. Incorporating synoptic-scale climate signals for streamflow modelling over the Mediterranean region using machine learning models. Hydrol. Sci. J. 2019, 64, 1240–1252. [Google Scholar] [CrossRef]
- Lin, S.S.; Zhang, N.; Zhou, A.; Shen, S.L. Time-series prediction of shield movement performance during tunneling based on hybrid model. Tunn. Und. Spc. Technol. 2022, 119, 104245. [Google Scholar] [CrossRef]
- Albo-Salih, H.; Mays, L.W.; Che, D. Application of an Optimization/Simulation Model for the Real-Time Flood Operation of River-Reservoir Systems with One and Two-Dimensional Unsteady Flow Modeling. Water 2022, 14, 87. [Google Scholar] [CrossRef]
- Raghuwanshi, N.S.; Singh, R.; Reddy, L.S. Runoff and sediment yield modeling using artificial neural networks: Upper Siwane River, India. J. Hydrol. Eng. 2006, 11, 71–79. [Google Scholar] [CrossRef]
- Santra, A.S.; Lin, J.-L. Integrating Long Short-Term Memory and Genetic Algorithm for Short-Term Load Forecasting. Energies 2019, 12, 2040. [Google Scholar] [CrossRef] [Green Version]
- Duc, H.N.; Le, X.H.; Heo, J.-Y.; Bae, D.-H. Development of an Extreme Gradient Boosting Model Integrated with Evolutionary Algorithms for Hourly Water Level Prediction. Access IEEE 2021, 9, 125853–125867. [Google Scholar]
- Yan, J.; Chen, X.; Yu, Y.; Zhang, X. Application of a Parallel Particle Swarm Optimization-Long Short-Term Memory Model to Improve Water Quality Data. Water 2019, 11, 1317. [Google Scholar] [CrossRef] [Green Version]
- Mohammadi, B.; Guan, Y.; Moazenzadeh, R.; Safari, M.J.S. Implementation of hybrid particle swarm optimization-differential evolution algorithms coupled with multi-layer perceptron for suspended sediment load estimation. Catena 2020, 10, 105024. [Google Scholar] [CrossRef]
- Gharabaghi, B.; Bonakdari, H.; Ebtehaj, I. Hybrid evolutionary algorithm based on PSOGA for ANFIS designing in prediction of no-deposition bed load sediment transport in sewer pipe. In Intelligent Computing, Proceedings of the 2018 Computing Conference, London, UK, 10–12 July 2018; Springer: Cham, Switzerland, 2018; Volume 2, pp. 106–118. [Google Scholar]
- Meshram, S.G.; Ghorbani, M.A.; Deo, R.C.; Kashani, M.H.; Meshram, C.; Karimi, V. New approach for sediment yield forecasting with a two-phase feedforward neuron network-particle swarm optimization model integrated with the gravitational search algorithm. Water Resour. Manag. 2019, 33, 2335–2356. [Google Scholar] [CrossRef]
- Motahari, M.; Mazandaranizadeh, H. Development of a PSO-ANN Model for Rainfall-Runoff Response in Basins, Case Study: Karaj Basin. Civ. Eng. J. 2017, 3, 35–44. [Google Scholar] [CrossRef]
- Zounemat-Kermani, M.; Mahdavi-Meymand, A.; Fadaee, M.; Batelaan, O.; Hinkelmann, R. Groundwater quality modeling: On the analogy between integrative PSO and MRFO mathematical and machine learning models. Environ. Qual. Manag. 2021, 1–11. [Google Scholar] [CrossRef]
- Xinqing, Y.; Yuan, C.; Yang, Y.; Xuemei, L. Monthly runoff prediction using modified CEEMD-based weighted integrated model. J. Water Clim. Change 2021, 5, 1744–1760. [Google Scholar]
- Asadnia, M.; Chua, L.H.C.; Qin, X.S.; Asce, A.M.; Talei, A. Improved Particle Swarm Optimization–Based Artificial Neural Network for Rainfall-Runoff Modeling. J. Hydrol. Eng. 2014, 19, 1320–1329. [Google Scholar] [CrossRef]
- Dökme, F.S. Application of Particle Swarm Optimization for Computer Aided Diagnosis of Diseases. Master’s Thesis, Çukurova University, Adana, Turkey, 2019. [Google Scholar]
- Feng, R.; Fan, G.; Lin, J.; Yao, B.; Guo, Q. Enhanced long short-term memory model for runoff prediction. J. Hydrol. Eng. 2021, 26, 4020063. [Google Scholar] [CrossRef]
- Adnan, M.R.; Mostafa, R.R.; Kisi, O.; Yaseen, Z.M.; Shahid, S.; Kermani, Z.M. Improving streamflow prediction using a new hybrid ELM model combined with hybrid particle swarm optimization and grey wolf optimization. Knowl. Based Syst. 2021, 231, 107379. [Google Scholar] [CrossRef]
- Kuok, K.K.; Harun, S.; Shamsuddin, S.M. Particle swarm optimization feedforward neural network for modelling runoff. Int. J. Environ. Sci. Technol. 2010, 7, 67–78. [Google Scholar] [CrossRef] [Green Version]
- Sihag, P.; Esmaeilbeiki, F.; Singh, B.; Ebtehaj, I.; Bonakdari, H. Modeling unsaturated hydraulic conductivity by hybrid soft computing techniques. Soft Comput. 2019, 23, 12897–12910. [Google Scholar] [CrossRef]
- Gumus, V. Hydrological Drought Analysis of Asi River Basin with Streamflow Drought Index. GU J. Sci. Part C 2017, 5, 65–73. [Google Scholar]
- Tomilova, A.A.; Lyubas., A.A.; Kondakov, A.V.; Konopleva, E.S.; Vikhrev, I.V.; Gofarov, M.Y.; Bolotov, I.N. An endemic freshwater mussel species from the Orontes River basin in Turkey and Syria represents duck mussel’s intraspecific lineage: Implications for conservation. Limnologica 2020, 84, 125811. [Google Scholar] [CrossRef]
- Korkmaz, H.; Karataş, A. Water management on the Asi (Orontes) River and appeared problems. Mustafa Kemal Univ. J. Soc. Sci. Inst. 2009, 12, 18–40. [Google Scholar]
- Şırlancı, M. Malicious Code Detection: Run Trace Analysis by LSTM. Master’s Thesis, Middle East Technical University, Ankara, Turkey, 2021. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975; p. 183. [Google Scholar]
- Chollet, A. Deep Learning with Pyhton, 1st ed.; Manning Publications: Shelter Islands, NY, USA, 2018; pp. 198–202. [Google Scholar]
- Liu, L.; Zou, S.; Yao, Y.; Wang, Z. Forecasting Global Ionospheric TEC Using Deep Learning Approach. Space Weather 2020, 18, e2020SW002501. [Google Scholar] [CrossRef]
- Yıldız, I. Forecasting of Global Vertical Total Electron Content Based on Trigonometric B-Spline with Long Short-Term Memory. Master’s Thesis, Hacettepe University, Ankara, Turkey, 2021. [Google Scholar]
- Kennedy, J.; Eberhart, R.C. A Discrete Binary Version of the Particle Swarm Algorithm. In Proceedings of the 1997 IEEE International Conference on Systems, Man, and Cybernetics. Computational Cybernetics and Simulation, Orlando, FL, USA, 12–15 October 1997. [Google Scholar]
- Medina, A.J.R.; Pulido, G.T.; Torres, J.G.R. A Comparative Study of Neighborhood Topologies for Particle Swarm Optimizers. In Proceedings of the International Joint Conference on Computational Intelligence, Funchal, Portugal, 5–7 October 2009. [Google Scholar]
- Khalaf, T.Z. Hybrid PSO-ANN and PSO Models Based Approach for Estimation of Costs and Duration of Construction Projects. Master’s Thesis, Kastamonu University, Kastamonu, Turkey, 2020. [Google Scholar]
- Tunchan, C. Particle Swarm Optimization Approach to Portfolio Optimization. Nonlinear Anal. Real World 2009, 10, 2396–2406. [Google Scholar]
- He, Q.Q.; Wu, C.; Si, Y.W. LSTM with particle Swam optimization for sales forecasting. Elect. Comm. Res. 2022, 51, 101118. [Google Scholar] [CrossRef]
- Taylor, K.E. Summarizing multiple aspects of model performance in a single diagram. J. Geophys Res. 2001, 106, 7183–7192. [Google Scholar] [CrossRef]
- Heo, K.Y.; Ha, K.J.; Yun, K.S.; Lee, S.S.; Kim, H.J.; Wang, B. Methods for uncertainty assessment of climate models and model predictions over East Asia. Int. J. Climatol. 2014, 34, 377–390. [Google Scholar] [CrossRef]
- Jabbari, A.; Bae, D.-H. Application of Artificial Neural Networks for Accuracy Enhancements of Real-Time Flood Forecasting in the Imjin Basin. Water 2018, 10, 1626. [Google Scholar] [CrossRef] [Green Version]
- Duan, J.; Wang, P.; Ma, W.; Fang, S.; Hou, Z. A novel hybrid model based on nonlinear weighted combination for short-term wind power forecasting. Int. J. Electr. Power Energy Syst. 2022, 134, 107452. [Google Scholar] [CrossRef]
- Wang, Z.Y.; Qiu, J.; Li, F.F. Hybrid Models Combining EMD/EEMD and ARIMA for Long-Term Streamflow Forecasting. Water 2018, 10, 853. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Zhu, Z.; Jiang, H.; Sun, S. Estimating Daily Reference Evapotranspiration Based on Limited Meteorological Data Using Deep Learning and Classical Machine Learning Methods. J. Hydrol. 2020, 591, 125286. [Google Scholar] [CrossRef]
- Di Nunno, F.; Granata, F.; Gargano, R.; de Marinis, G. Prediction of spring flows using nonlinear autoregressive exogenous (NARX) neural network models. Environ. Monit Assess. 2021, 193, 350. [Google Scholar] [CrossRef]
- Granata, F.; Di Nunno, F. Fabio. Forecasting evapotranspiration in different climates using ensembles of recurrent neural networks. Agric. Water Manag. 2021, 255, 107040. [Google Scholar] [CrossRef]
- Bonyadi, M.R.; Michalewicz, Z. Particle swarm optimization for single objective continuous space problems: A review. Evol. Comput. 2016, 8, 1–54. [Google Scholar] [CrossRef] [PubMed]
- Kilinc, H.C.; Haznedar, B. A Hybrid Model for Streamflow Forecasting in the Basin of Euphrates. Water 2022, 14, 80. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FMS | River FMS | Coordinates | Cathment Area (km2) | Elevation (m) | Observation(year) | |
|---|---|---|---|---|---|---|
| East | North | |||||
| (° ′ ″) | (° ′ ″) | |||||
| 1907 | Demirköprü | 36 21 28.2 | 36 14 41 | 16.170 | 85 | 2010–2019 |
| 1905 | Karasu | 36 12 28.3 | 36 16 41.7 | 1.768 | 84 | 2010–2019 |
| 1909 | Samandağ | 35 59 20.6 | 36 04 01.9 | 23.205 | 11 | 2009–2018 |
| Station | Model | RMSE | MAE | MAPE | SD | R2 |
|---|---|---|---|---|---|---|
| Karasu | PSO-LSTM | 0.8276 | 0.1401 | 14.0196 | 0.2611 | 0.9526 |
| LSTM | 1.2363 | 0.1530 | 15.3023 | 0.2942 | 0.8893 | |
| ARIMA | 1.2886 | 0.0978 | 9.7838 | 0.1742 | 0.8798 | |
| Linear | 1.3308 | 0.1948 | 19.4855 | 0.3390 | 0.8725 | |
| Regression | ||||||
| Demirköprü | PSO-LSTM | 0.9073 | 0.0728 | 7.2830 | 0.1545 | 0.9270 |
| LSTM | 1.2836 | 0.0714 | 7.1450 | 0.1563 | 0.8740 | |
| ARIMA | 1.7860 | 0.2401 | 24.0195 | 0.3006 | 0.7281 | |
| Linear | 1.3498 | 0.0892 | 8.9201 | 0.2129 | 0.8373 | |
| Regression | ||||||
| Samandağ | PSO-LSTM | 1.2557 | 0.1025 | 10.2574 | 0.1541 | 0.9749 |
| LSTM | 2.3066 | 0.1270 | 12.7057 | 0.1865 | 0.9202 | |
| ARIMA | 2.6255 | 0.1066 | 10.6665 | 0.1647 | 0.8890 | |
| Linear | 2.6876 | 0.0951 | 9.5131 | 0.1902 | 0.8916 | |
| Regression |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kilinc, H.C. Daily Streamflow Forecasting Based on the Hybrid Particle Swarm Optimization and Long Short-Term Memory Model in the Orontes Basin. Water 2022, 14, 490. https://doi.org/10.3390/w14030490
Kilinc HC. Daily Streamflow Forecasting Based on the Hybrid Particle Swarm Optimization and Long Short-Term Memory Model in the Orontes Basin. Water. 2022; 14(3):490. https://doi.org/10.3390/w14030490
Chicago/Turabian StyleKilinc, Huseyin Cagan. 2022. "Daily Streamflow Forecasting Based on the Hybrid Particle Swarm Optimization and Long Short-Term Memory Model in the Orontes Basin" Water 14, no. 3: 490. https://doi.org/10.3390/w14030490