
Modelling Freshwater Eutrophication with Limited Limnological Data Using Artificial Neural Networks

 ,
,  , , , and
, , , and 
Abstract
:1. Introduction
2. Materials and Methods
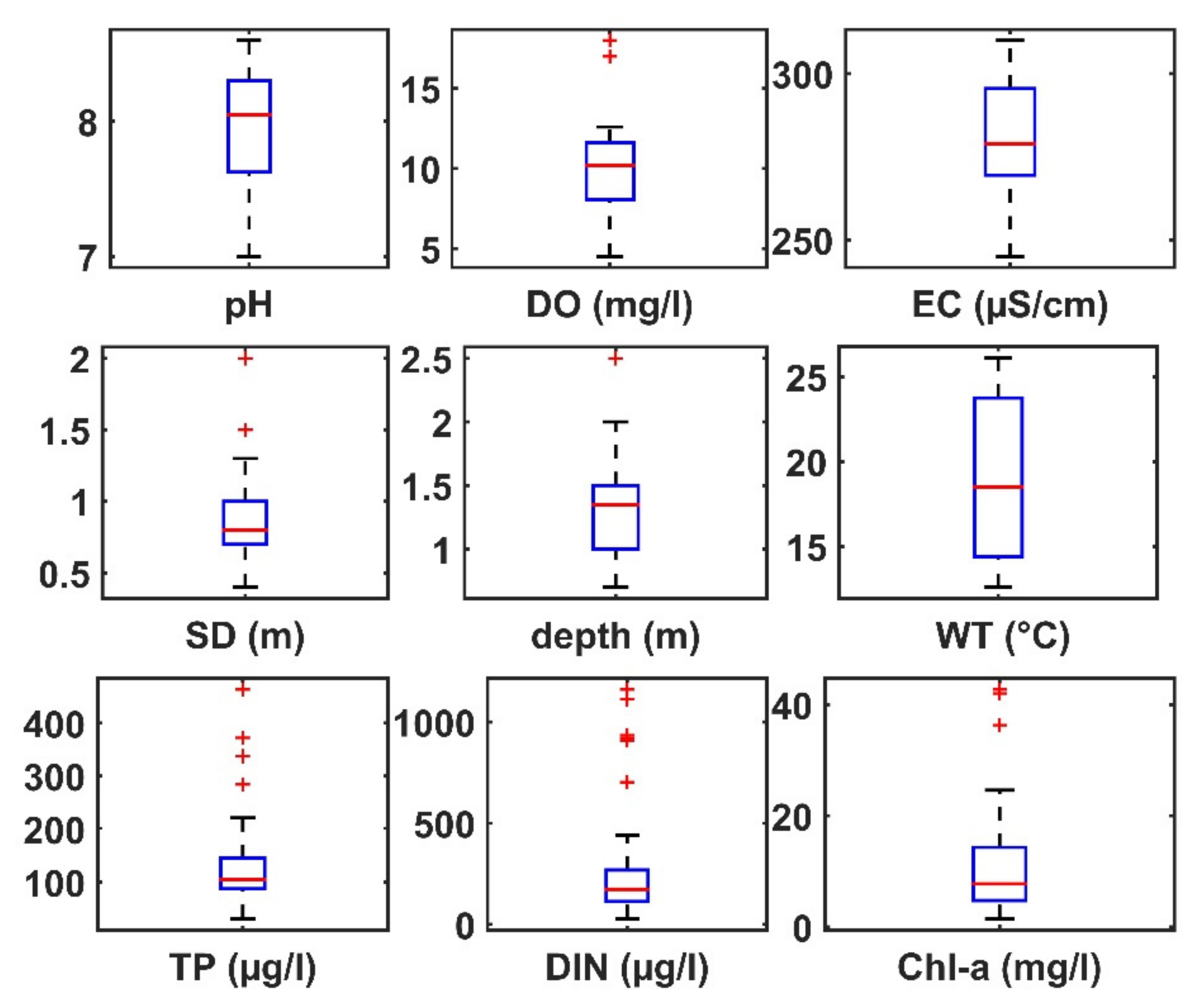
2.1. Study Area and Data Collection
2.2. Preliminaries on ANN and Model Construction
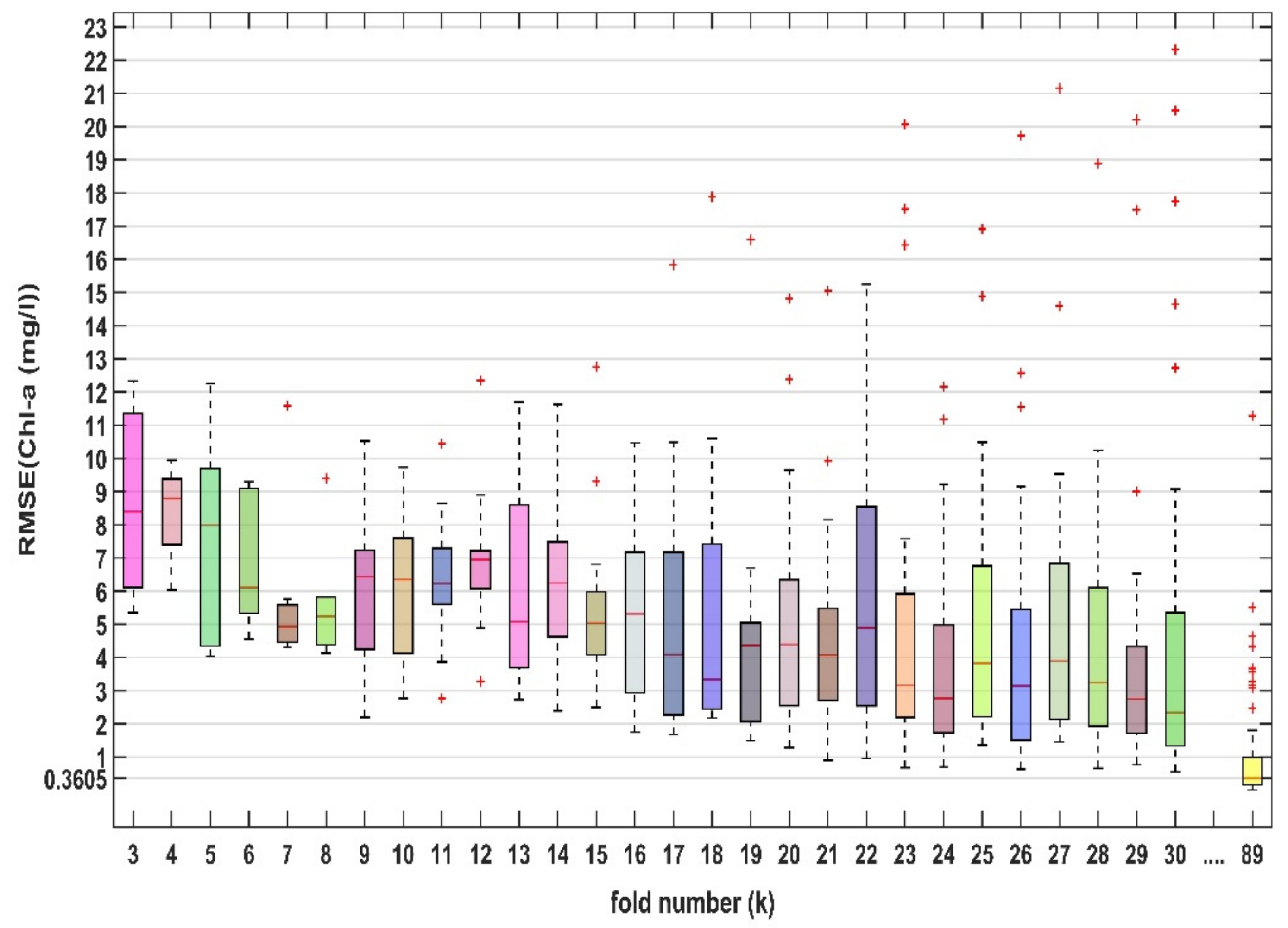
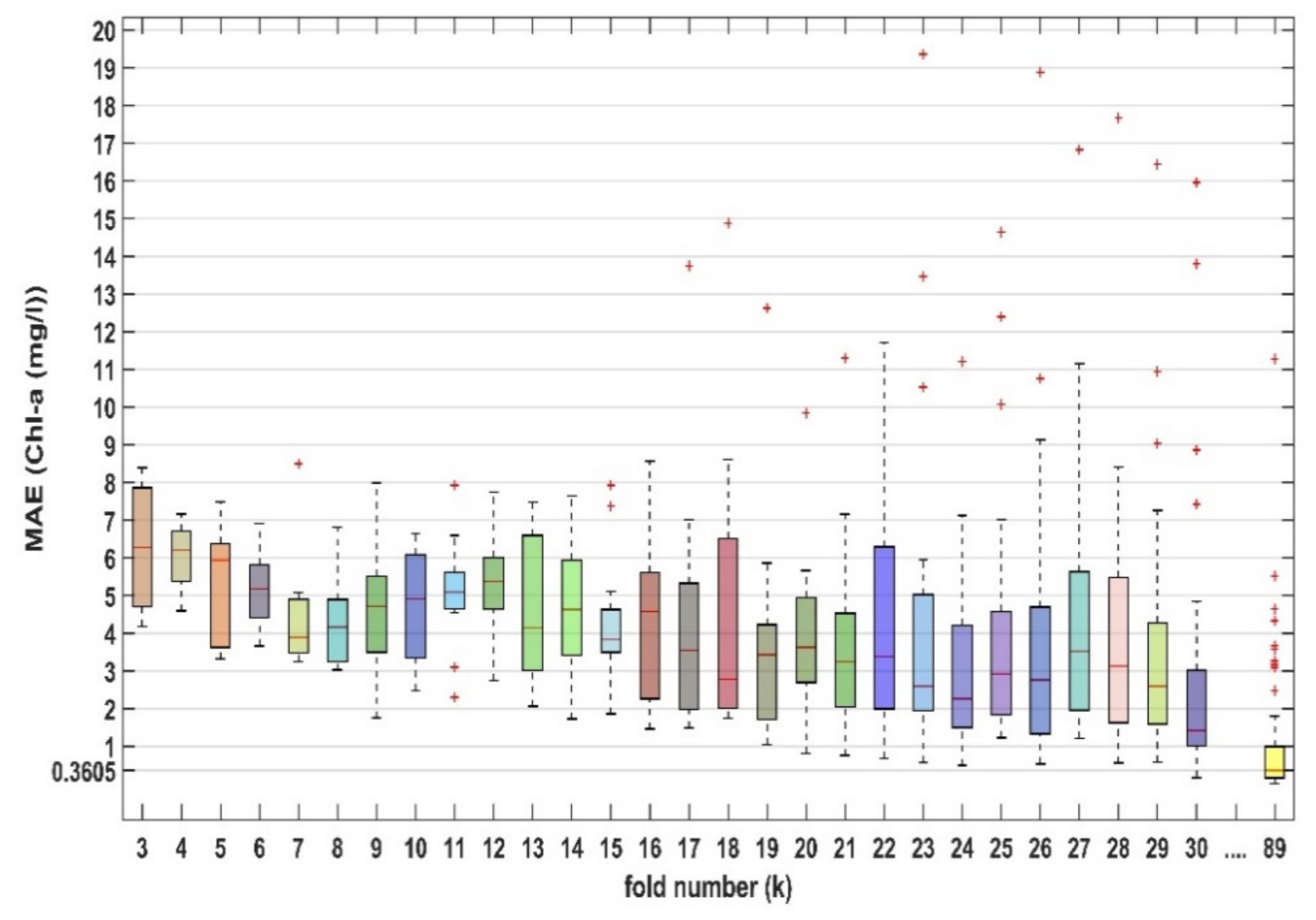
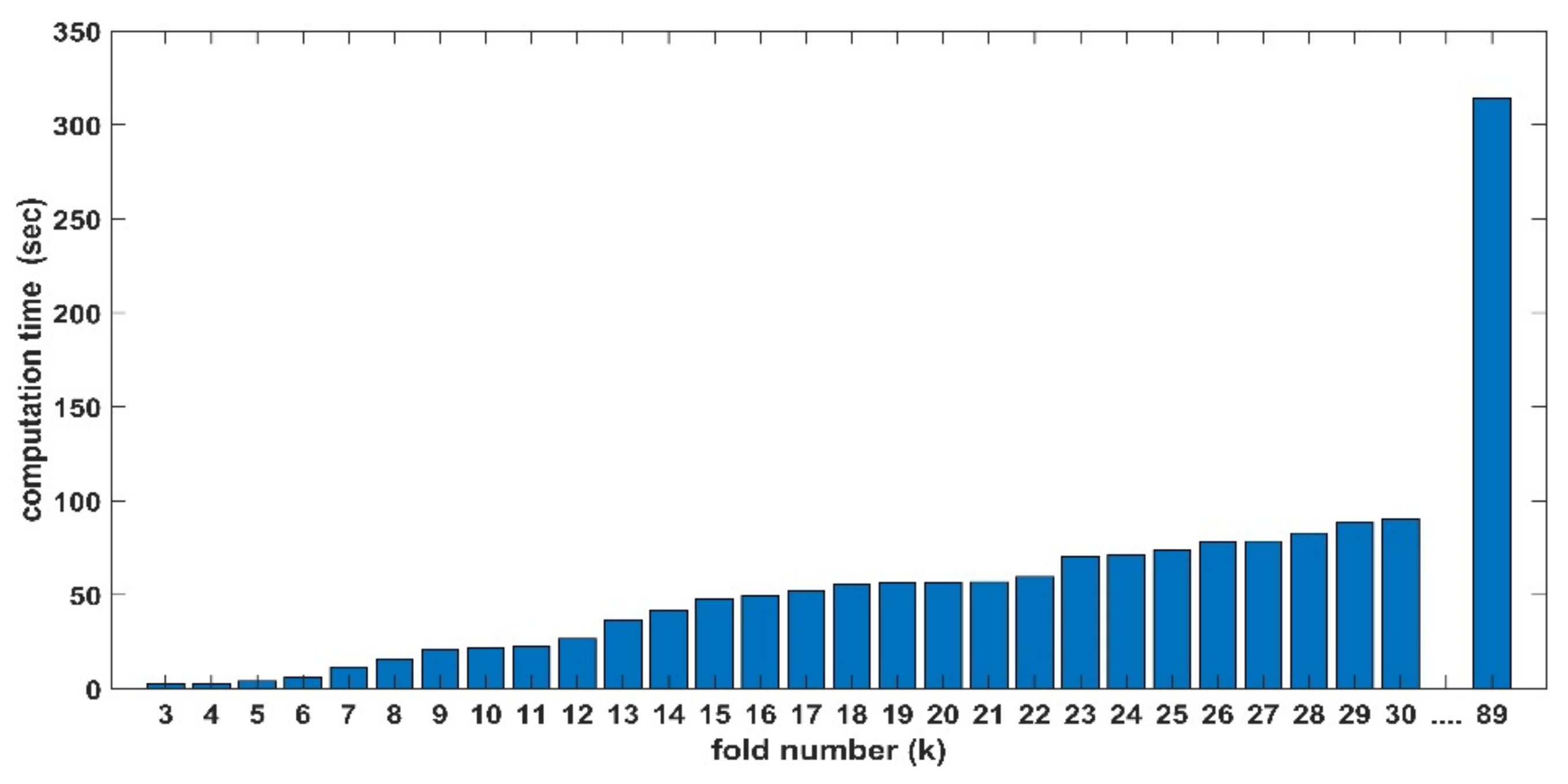
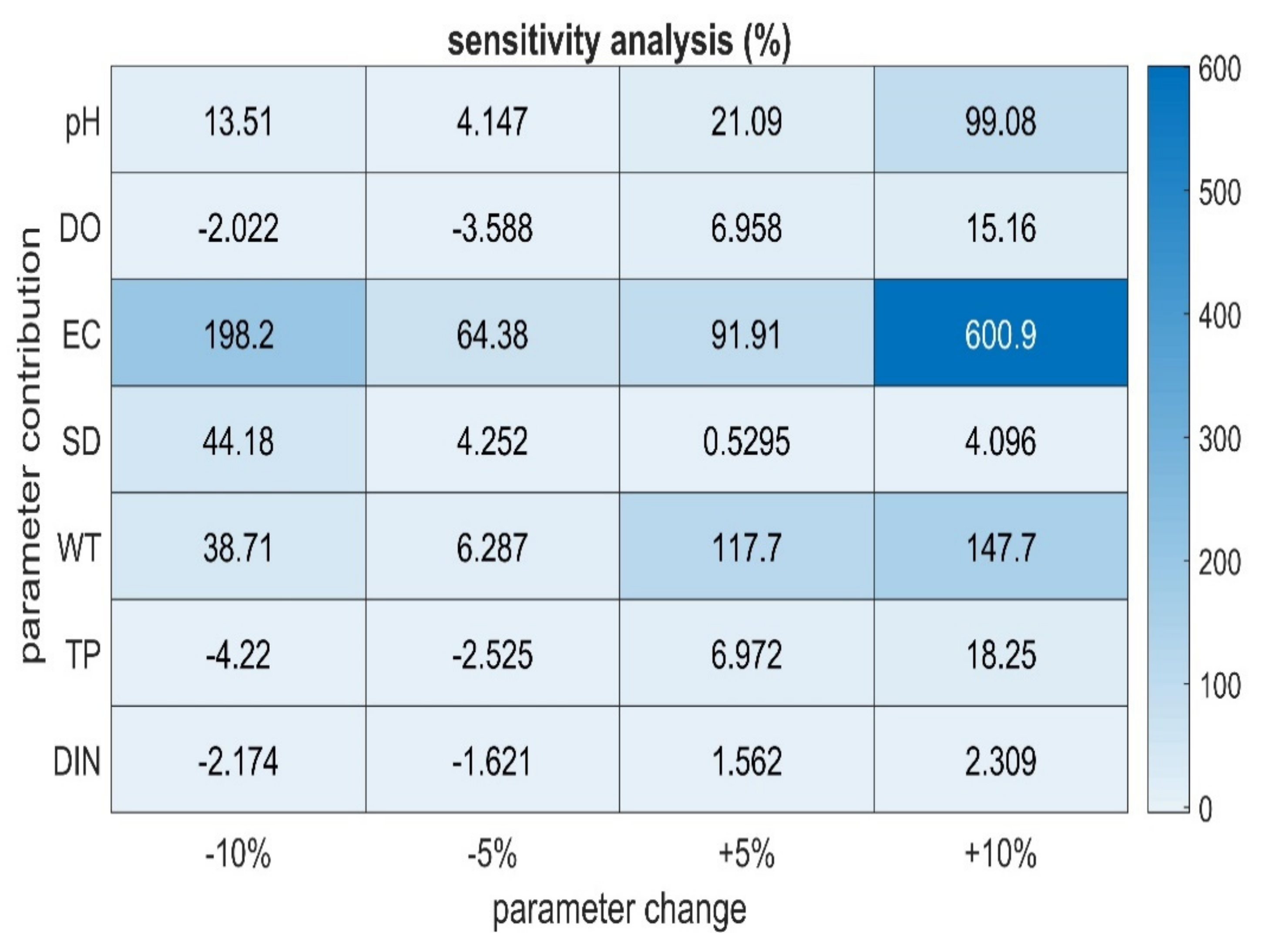
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Adnan, R.M.; Zounemat-Kermani, M.; Kuriqi, A.; Kisi, O. Machine Learning Method in Prediction Streamflow Considering Periodicity Component. In Springer Transactions in Civil and Environmental Engineering; Springer: Singapore, 2020; pp. 383–403. [Google Scholar]
- Oyebode, O.; Stretch, D. Neural network modeling of hydrological systems: A review of implementation techniques. Nat. Resour. Model. 2019, 32, e12189. [Google Scholar] [CrossRef] [Green Version]
- Kim, D.-K.; Park, K.; Jo, H.; Kwak, I.-S. Comparison of Water Sampling between Environmental {DNA} Metabarcoding and Conventional Microscopic Identification: A Case Study in Gwangyang Bay, South Korea. Appl. Sci. 2019, 9, 3272. [Google Scholar] [CrossRef] [Green Version]
- Muttil, N.; Chau, K.W. Neural network and genetic programming for modelling coastal algal blooms. Int. J. Environ. Pollut. 2006, 28, 223. [Google Scholar] [CrossRef] [Green Version]
- Goethals, P.L.M.; Dedecker, A.P.; Gabriels, W.; Lek, S.; De Pauw, N. Applications of artificial neural networks predicting macroinvertebrates in freshwaters. Aquat. Ecol. 2007, 41, 491–508. [Google Scholar] [CrossRef] [Green Version]
- Zounemat-Kermani, M. Principal Component Analysis (PCA) for estimating Chlorophyll concentration using forward and generalized regression neural networks. Appl. Artif. Intell. 2014, 28, 16–29. [Google Scholar] [CrossRef]
- Bennett, C.; Stewart, R.A.; Beal, C.D. ANN-based residential water end-use demand forecasting model. Expert Syst. Appl. 2013, 40, 1014–1023. [Google Scholar] [CrossRef] [Green Version]
- Yotova, G.; Lazarova, S.; Kudłak, B.; Zlateva, B.; Mihaylova, V.; Wieczerzak, M.; Venelinov, T.; Tsakovski, S. Assessment of the Bulgarian Wastewater Treatment Plants’ Impact on the Receiving Water Bodies. Molecules 2019, 24, 2274. [Google Scholar] [CrossRef] [Green Version]
- Moustaka-Gouni, M.; Sommer, U.; Economou-Amilli, A.; Arhonditsis, G.B.; Katsiapi, M.; Papastergiadou, E.; Kormas, K.A.; Vardaka, E.; Karayanni, H.; Papadimitriou, T. Implementation of the Water Framework Directive: Lessons Learned and Future Perspectives for an Ecologically Meaningful Classification Based on Phytoplankton of the Status of Greek Lakes, Mediterranean Region. Environ. Manag. 2019, 64, 675–688. [Google Scholar] [CrossRef]
- Cigizoglu, H.K.; Kisi, Ö. Flow prediction by three back propagation techniques using k-fold partitioning of neural network training data. Hydrol. Res. 2005, 36, 49–64. [Google Scholar] [CrossRef]
- Cunningham, P.; Carney, J.; Jacob, S. Stability problems with artificial neural networks and the ensemble solution. Artif. Intell. Med. 2000, 20, 217–225. [Google Scholar] [CrossRef] [Green Version]
- Smith, V.H.; Joye, S.B.; Howarth, R.W. Eutrophication of freshwater and marine ecosystems. Limnol. Oceanogr. 2006, 51, 351–355. [Google Scholar] [CrossRef] [Green Version]
- Smith, V.H.; Tilman, G.D.; Nekola, J.C. Eutrophication: Impacts of excess nutrient inputs on freshwater, marine, and terrestrial ecosystems. Environ. Pollut. 1999, 100, 179–196. [Google Scholar] [CrossRef]
- Dynowski, P.; Senetra, A.; Źróbek-Sokolnik, A.; Kozłowski, J. The Impact of Recreational Activities on Aquatic Vegetation in Alpine Lakes. Water 2019, 11, 173. [Google Scholar] [CrossRef] [Green Version]
- Hadjisolomou, E.; Stefanidis, K.; Papatheodorou, G.; Papastergiadou, E. Evaluating the contributing environmental parameters associated with eutrophication in a shallow lake by applying artificial neural networks techniques. Fresenius Environ. Bull. 2017, 26, 3200–3208. [Google Scholar]
- Brown, M.G.L.; Skakun, S.; He, T.; Liang, S. Intercomparison of Machine-Learning Methods for Estimating Surface Shortwave and Photosynthetically Active Radiation. Remote Sens. 2020, 12, 372. [Google Scholar] [CrossRef] [Green Version]
- Hadjisolomou, E.; Stefanidis, K.; Papatheodorou, G.; Papastergiadou, E. Assessing the contribution of the environmental parameters to eutrophication with the use of the “PaD” and “PaD2” methods in a hypereutrophic lake. Int. J. Environ. Res. Public Health 2016, 13, 764. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stefanidis, K.; Sarika, M.; Papastegiadou, E. Exploring environmental predictors of aquatic macrophytes in water-dependent Natura 2000 sites of high conservation value: Results from a long-term study of macrophytes in Greek lakes. Aquat. Conserv. Mar. Freshw. Ecosyst. 2019, 29, 1133–1148. [Google Scholar] [CrossRef]
- Hadjisolomou, E.; Stefanidis, K.; Papatheodorou, G.; Papastergiadou, E. Assessment of the eutrophication-related environmental parameters in two mediterranean lakes by integrating statistical techniques and self-organizing maps. Int. J. Environ. Res. Public Health 2018, 15, 547. [Google Scholar] [CrossRef] [Green Version]
- Panagiotopoulos, K.; Aufgebauer, A.; Schäbitz, F.; Wagner, B. Vegetation and climate history of the Lake Prespa region since the Lateglacial. Quat. Int. 2013, 293, 157–169. [Google Scholar] [CrossRef]
- Stefanidis, K.; Papastergiadou, E. Linkages between Macrophyte Functional Traits and Water Quality: Insights from a Study in Freshwater Lakes of Greece. Water 2019, 11, 1047. [Google Scholar] [CrossRef] [Green Version]
- Vardaka, E.; Moustaka-Gouni, M.; Cook, C.M.; Lanaras, T. Cyanobacterial blooms and water quality in Greek waterbodies. J. Appl. Phycol. 2005, 17, 391–401. [Google Scholar] [CrossRef]
- Hagan, M.T.; Demuth, H.B.; Beale, M.H.; De Jesús, O. Neural Network Design, 2nd ed.; Martin Hagan: Stillwater, OK, USA, 2014. [Google Scholar]
- Chen, J.-C.; Wang, Y.-M. Comparing Activation Functions in Modeling Shoreline Variation Using Multilayer Perceptron Neural Network. Water 2020, 12, 1281. [Google Scholar] [CrossRef]
- Dedecker, A.P.; Goethals, P.L.M.; Gabriels, W.; De Pauw, N. Optimization of Artificial Neural Network ({ANN}) model design for prediction of macroinvertebrates in the Zwalm river basin (Flanders, Belgium). Ecol. Model. 2004, 174, 161–173. [Google Scholar] [CrossRef]
- Ghalkhani, H.; Golian, S.; Saghafian, B.; Farokhnia, A.; Shamseldin, A. Application of surrogate artificial intelligent models for real-time flood routing. Water Environ. J. 2012, 27, 535–548. [Google Scholar] [CrossRef]
- Vilas, L.G.; Spyrakos, E.; Palenzuela, J.M.T. Neural network estimation of chlorophyll a from MERIS full resolution data for the coastal waters of Galician rias (NW Spain). Remote Sens. Environ. 2011, 115, 524–535. [Google Scholar] [CrossRef]
- Heddam, S.; Ptak, M.; Zhu, S. Modelling of daily lake surface water temperature from air temperature: Extremely randomized trees (ERT) versus Air2Water, MARS, M5Tree, RF and MLPNN. J. Hydrol. 2020, 588, 125130. [Google Scholar] [CrossRef]
- Özesmi, S.L.; Tan, C.O.; Özesmi, U. Methodological issues in building, training, and testing artificial neural networks in ecological applications. Ecol. Model. 2006, 195, 83–93. [Google Scholar] [CrossRef] [Green Version]
- Maier, H.R.; Dandy, G.C.; Burch, M.D. Use of artificial neural networks for modelling cyanobacteria Anabaena spp. in the River Murray, South Australia. Ecol. Model. 1998, 105, 257–272. [Google Scholar] [CrossRef]
- Scardi, M.; Harding, L.W. Developing an empirical model of phytoplankton primary production: A neural network case study. Ecol. Model. 1999, 120, 213–223. [Google Scholar] [CrossRef]
- Herodotou, H.; Aslam, S.; Holm, H.; Theodossiou, S. Big Maritime Data Management. In Maritime Informatics, Progress in IS; Lind, M., Michaelides, M., Ward, R.T., Watson, R., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 313–334. [Google Scholar]
- Karamoutsou, L.; Psilovikos, A. The Use of Artificial Neural Network in Water Quality Prediction in Lake Kastoria, Greece. In Proceedings of the 14th Conference of the Hellenic Hydrotechnical Association, Volos, Greece, 16–17 May 2019; pp. 882–889. [Google Scholar]
- Gebler, D.; Kolada, A.; Pasztaleniec, A.; Szoszkiewicz, K. Modelling of ecological status of Polish lakes using deep learning techniques. Environ. Sci. Pollut. Res. 2020, 28, 5383–5397. [Google Scholar] [CrossRef]
- Melesse, A.M.; Khosravi, K.; Tiefenbacher, J.P.; Heddam, S.; Kim, S.; Mosavi, A.; Pham, B.T. River Water Salinity Prediction Using Hybrid Machine Learning Models. Water 2020, 12, 2951. [Google Scholar] [CrossRef]
- Gevrey, M.; Dimopoulos, I.; Lek, S. Review and comparison of methods to study the contribution of variables in artificial neural network models. Ecol. Model. 2003, 160, 249–264. [Google Scholar] [CrossRef]
- Lee, J.H.W.; Huang, Y.; Dickman, M.; Jayawardena, A.W. Neural network modelling of coastal algal blooms. Ecol. Model. 2003, 159, 179–201. [Google Scholar] [CrossRef]
- Zhou, T.; Wang, F.; Yang, Z. Comparative Analysis of ANN and SVM Models Combined with Wavelet Preprocess for Groundwater Depth Prediction. Water 2017, 9, 781. [Google Scholar] [CrossRef] [Green Version]
- Olden, J.; Lawler, J.; Poff, N.L. Machine Learning Methods Without Tears: A Primer for Ecologists. Q. Rev. Biol. 2008, 83, 171–193. [Google Scholar] [CrossRef] [Green Version]
- Mamun, M.; Kim, J.-J.; Alam, M.A.; An, K.-G. Prediction of Algal Chlorophyll-a and Water Clarity in Monsoon-Region Reservoir Using Machine Learning Approaches. Water 2019, 12, 30. [Google Scholar] [CrossRef] [Green Version]
- Gebler, D.; Szoszkiewicz, K.; Pietruczuk, K. Modeling of the river ecological status with macrophytes using artificial neural networks. Limnologica 2017, 65, 46–54. [Google Scholar] [CrossRef]
- Palani, S.; Liong, S.-Y.; Tkalich, P. An ANN application for water quality forecasting. Mar. Pollut. Bull. 2008, 56, 1586–1597. [Google Scholar] [CrossRef]
- Tuhtan, J.A.; Fuentes-Perez, J.F.; Toming, G.; Kruusmaa, M. Flow velocity estimation using a fish-shaped lateral line probe with product-moment correlation features and a neural network. Flow Meas. Instrum. 2017, 54, 1–8. [Google Scholar] [CrossRef]
- Organisation for Economic Co-operation and Development. Eutrophication of Waters: Monitoring, Assessment and Control; Organisation for Economic Co-operation and Development: Paris, France, 1982; ISBN 9264122982. [Google Scholar]
- Jeong, K.-S.; Kim, D.-K.; Chon, T.-S.; Joo, G.-J. Machine Learning Application to the Korean Freshwater Ecosystems. Korean J. Ecol. 2005, 28, 405–415. [Google Scholar] [CrossRef] [Green Version]
- Aria, S.H.; Asadollahfardi, G.; Heidarzadeh, N. Eutrophication modelling of Amirkabir Reservoir (Iran) using an artificial neural network approach. Lakes Reserv. Res. Manag. 2019, 24, 48–58. [Google Scholar] [CrossRef] [Green Version]
- Kavzoglu, T. Increasing the accuracy of neural network classification using refined training data. Environ. Model. Softw. 2009, 24, 850–858. [Google Scholar] [CrossRef]
- Solomatine, D.P.; Ostfeld, A. Data-driven modelling: Some past experiences and new approaches. J. Hydroinform. 2008, 10, 3–22. [Google Scholar] [CrossRef] [Green Version]
- Olomukoro, J.O.; Odigie, J.O. Ecological modelling using artificial neural network for macroinvertebrate prediction in a tropical rainforest river. Int. J. Environ. Waste Manag. 2020, 26, 325–348. [Google Scholar] [CrossRef] [Green Version]
- Deng, T.; Chau, K.-W.; Duan, H.-F. Machine learning based marine water quality prediction for coastal hydro-environment management. J. Environ. Manag. 2021, 284, 112051. [Google Scholar] [CrossRef]
- Chang, F.-J.; Tsai, Y.-H.; Chen, P.-A.; Coynel, A.; Vachaud, G. Modeling water quality in an urban river using hydrological factors—Data driven approaches. J. Environ. Manag. 2015, 151, 87–96. [Google Scholar] [CrossRef] [PubMed]
- Lek, S.; Guégan, J.F. Artificial neural networks as a tool in ecological modelling, an introduction. Ecol. Model. 1999, 120, 65–73. [Google Scholar] [CrossRef]
- Yotova, G.; Varbanov, M.; Tcherkezova, E.; Tsakovski, S. Water quality assessment of a river catchment by the composite water quality index and self-organizing maps. Ecol. Indic. 2021, 120, 106872. [Google Scholar] [CrossRef]
- Teles, L.O.; Vasconcelos, V.; Teles, L.O.; Pereira, E.; Saker, M.; Vasconcelos, V. Time Series Forecasting of Cyanobacteria Blooms in the Crestuma Reservoir (Douro River, Portugal) Using Artificial Neural Networks. Environ. Manag. 2006, 38, 227–237. [Google Scholar] [CrossRef]
- Atoui, A.; Hafez, H.; Slim, K. Occurrence of toxic cyanobacterial blooms for the first time in Lake Karaoun, Lebanon. Water Environ. J. 2012, 27, 42–49. [Google Scholar] [CrossRef]
- Jeppesen, E.; Pekcan-Hekim, Z.; Lauridsen, T.L.; Sondergaard, M.; Jensen, J.P. Habitat distribution of fish in late summer: Changes along a nutrient gradient in Danish lakes. Ecol. Freshw. Fish 2006, 15, 180–190. [Google Scholar] [CrossRef]
- Søndergaard, M.; Larsen, S.E.; Jørgensen, T.B.; Jeppesen, E. Using chlorophyll a and cyanobacteria in the ecological classification of lakes. Ecol. Indic. 2011, 11, 1403–1412. [Google Scholar] [CrossRef]
- Napiórkowska-Krzebietke, A.; Kalinowska, K.; Bogacka-Kapusta, E.; Stawecki, K.; Traczuk, P. Cyanobacterial Blooms and Zooplankton Structure in Lake Ecosystem under Limited Human Impact. Water 2020, 12, 1252. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, G.; Sun, G.; Wu, Y.; Chen, Y. Assessment of Lake Water Quality and Eutrophication Risk in an Agricultural Irrigation Area: A Case Study of the Chagan Lake in Northeast China. Water 2019, 11, 2380. [Google Scholar] [CrossRef] [Green Version]
- Borowiak, M.; Borowiak, D.; Nowiński, K. Spatial Differentiation and Multiannual Dynamics of Water Conductivity in Lakes of the Suwałki Landscape Park. Water 2020, 12, 1277. [Google Scholar] [CrossRef]
- Heisler, J.; Glibert, P.M.; Burkholder, J.M.; Anderson, D.M.; Cochlan, W.; Dennison, W.C.; Dortch, Q.; Gobler, C.J.; Heil, C.A.; Humphries, E.; et al. Eutrophication and harmful algal blooms: A scientific consensus. Harmful Algae 2008, 8, 3–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Akagha, S.C.; Nwankwo, D.I.; Yin, K. Dynamics of nutrient and phytoplankton in Epe Lagoon, Nigeria: Possible causes and consequences of reoccurring cyanobacterial blooms. Appl. Water Sci. 2020, 10, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Paerl, H.W. Assessing and managing nutrient-enhanced eutrophication in estuarine and coastal waters: Interactive effects of human and climatic perturbations. Ecol. Eng. 2006, 26, 40–54. [Google Scholar] [CrossRef]
- Paerl, H.W.; Xu, H.; McCarthy, M.J.; Zhu, G.; Qin, B.; Li, Y.; Gardner, W.S. Controlling harmful cyanobacterial blooms in a hyper-eutrophic lake (Lake Taihu, China): The need for a dual nutrient (N&P) management strategy. Water Res. 2011, 45, 1973–1983. [Google Scholar] [CrossRef]
- Jeppesen, E.; Søndergaard, M.; Meerhoff, M.; Lauridsen, T.L.; Jensen, J.P. Shallow lake restoration by nutrient loading reduction—some recent findings and challenges ahead. Hydrobiologia 2007, 584, 239–252. [Google Scholar] [CrossRef]
- Verstijnen, Y.J.M.; Maliaka, V.; Catsadorakis, G.; Lürling, M.; Smolders, A.J.P. Colonial nesting waterbirds as vectors of nutrients to Lake Lesser Prespa (Greece). Inland Waters 2021, 1–17. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| pH | DO | EC | SD | Depth | WT | TP | DIN | Chl-a | |
|---|---|---|---|---|---|---|---|---|---|
| pH | 1.000 | ||||||||
| DO | 0.089 | 1.000 | |||||||
| EC | 0.260 | −0.169 | 1.000 | ||||||
| SD | −0.385 | −0.229 | 0.094 | 1.000 | |||||
| depth | −0.153 | −0.186 | 0.051 | 0.722 | 1.000 | ||||
| WT | 0.442 | −0.077 | 0.602 | −0.278 | −0.006 | 1.000 | |||
| TP | −0.106 | −0.164 | 0.048 | 0.299 | 0.216 | −0.066 | 1.000 | ||
| DIN | −0.131 | 0.251 | 0.097 | 0.059 | −0.093 | −0.179 | 0.198 | 1.000 | |
| Chl-a | 0.234 | −0.101 | 0.267 | −0.124 | −0.163 | 0.362 | −0.014 | −0.172 | 1.000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hadjisolomou, E.; Stefanidis, K.; Herodotou, H.; Michaelides, M.; Papatheodorou, G.; Papastergiadou, E. Modelling Freshwater Eutrophication with Limited Limnological Data Using Artificial Neural Networks. Water 2021, 13, 1590. https://doi.org/10.3390/w13111590
Hadjisolomou E, Stefanidis K, Herodotou H, Michaelides M, Papatheodorou G, Papastergiadou E. Modelling Freshwater Eutrophication with Limited Limnological Data Using Artificial Neural Networks. Water. 2021; 13(11):1590. https://doi.org/10.3390/w13111590
Chicago/Turabian StyleHadjisolomou, Ekaterini, Konstantinos Stefanidis, Herodotos Herodotou, Michalis Michaelides, George Papatheodorou, and Eva Papastergiadou. 2021. "Modelling Freshwater Eutrophication with Limited Limnological Data Using Artificial Neural Networks" Water 13, no. 11: 1590. https://doi.org/10.3390/w13111590