Water End Use Disaggregation Based on Soft Computing Techniques


Abstract
:1. Introduction
2. Materials and Methods
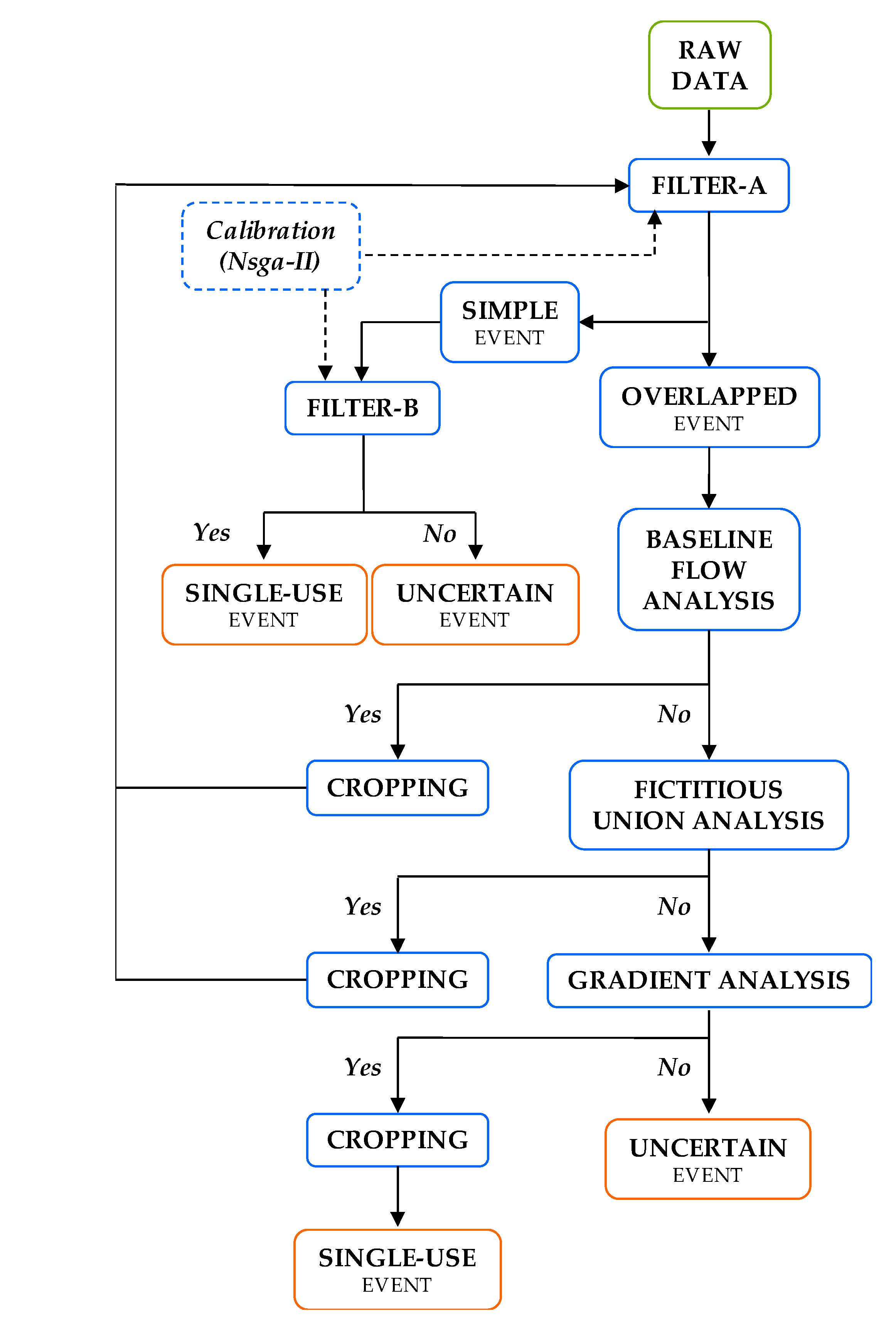
2.1. Disaggregation Process
2.2. Classification Process
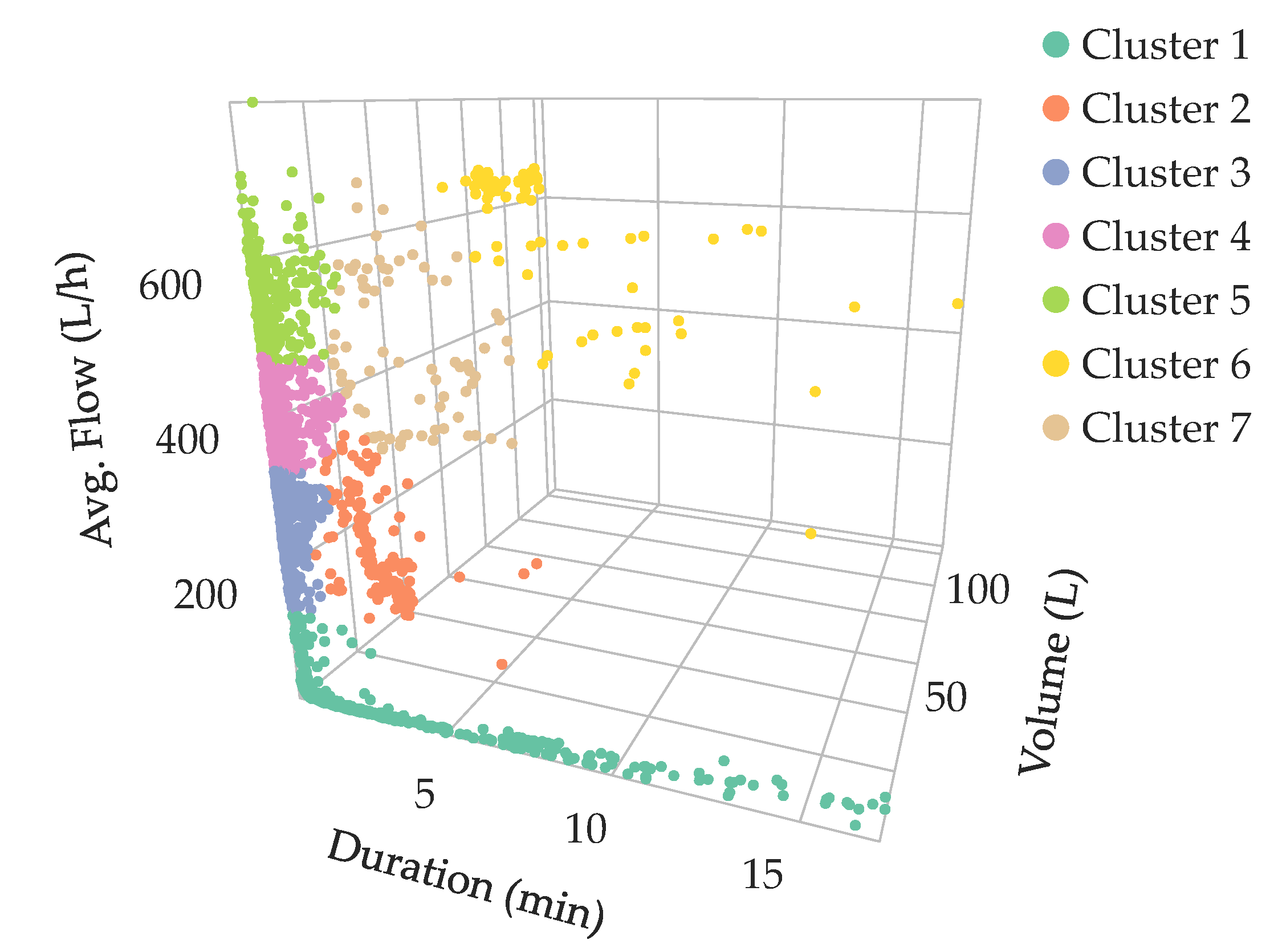
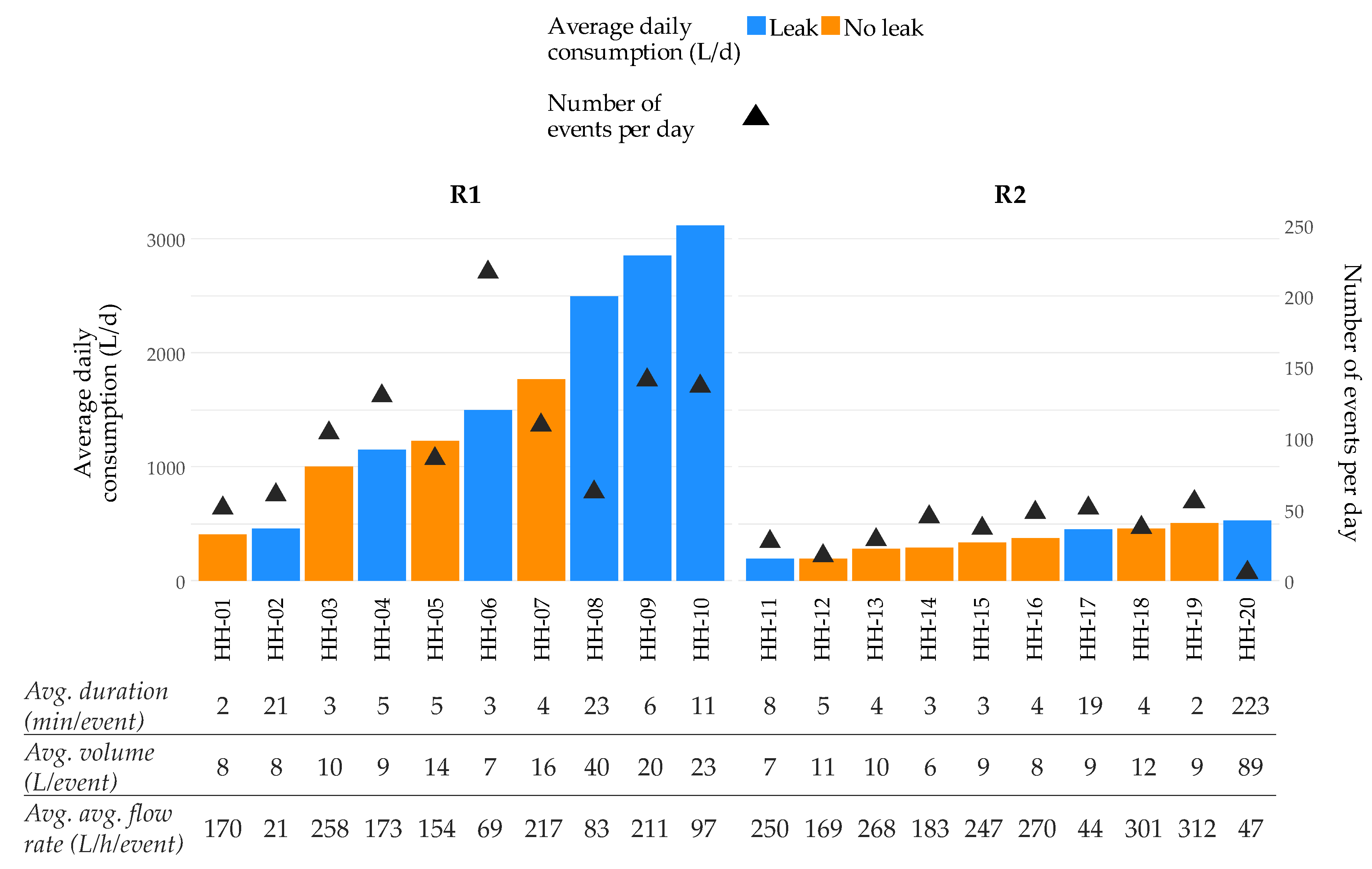
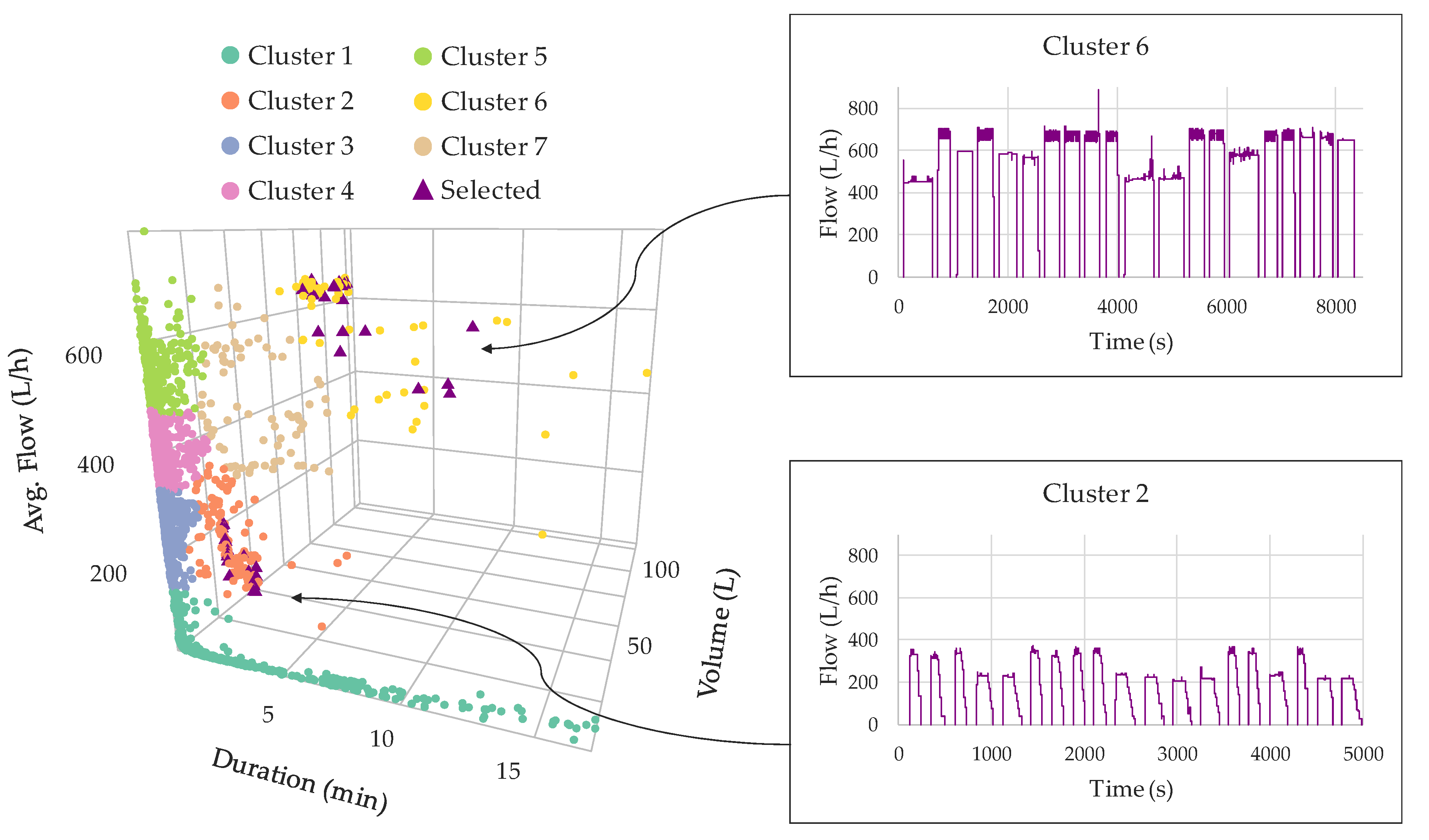
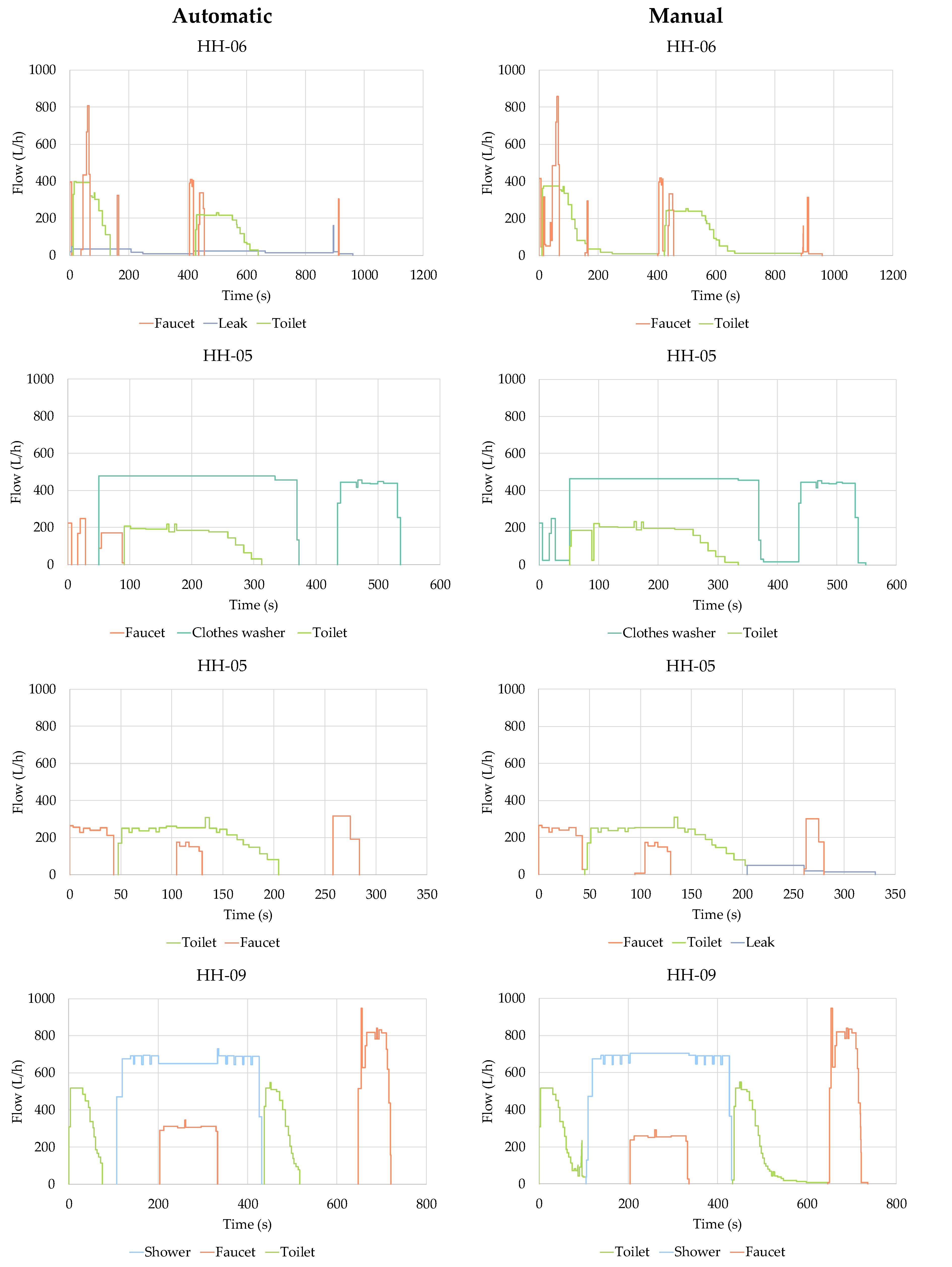
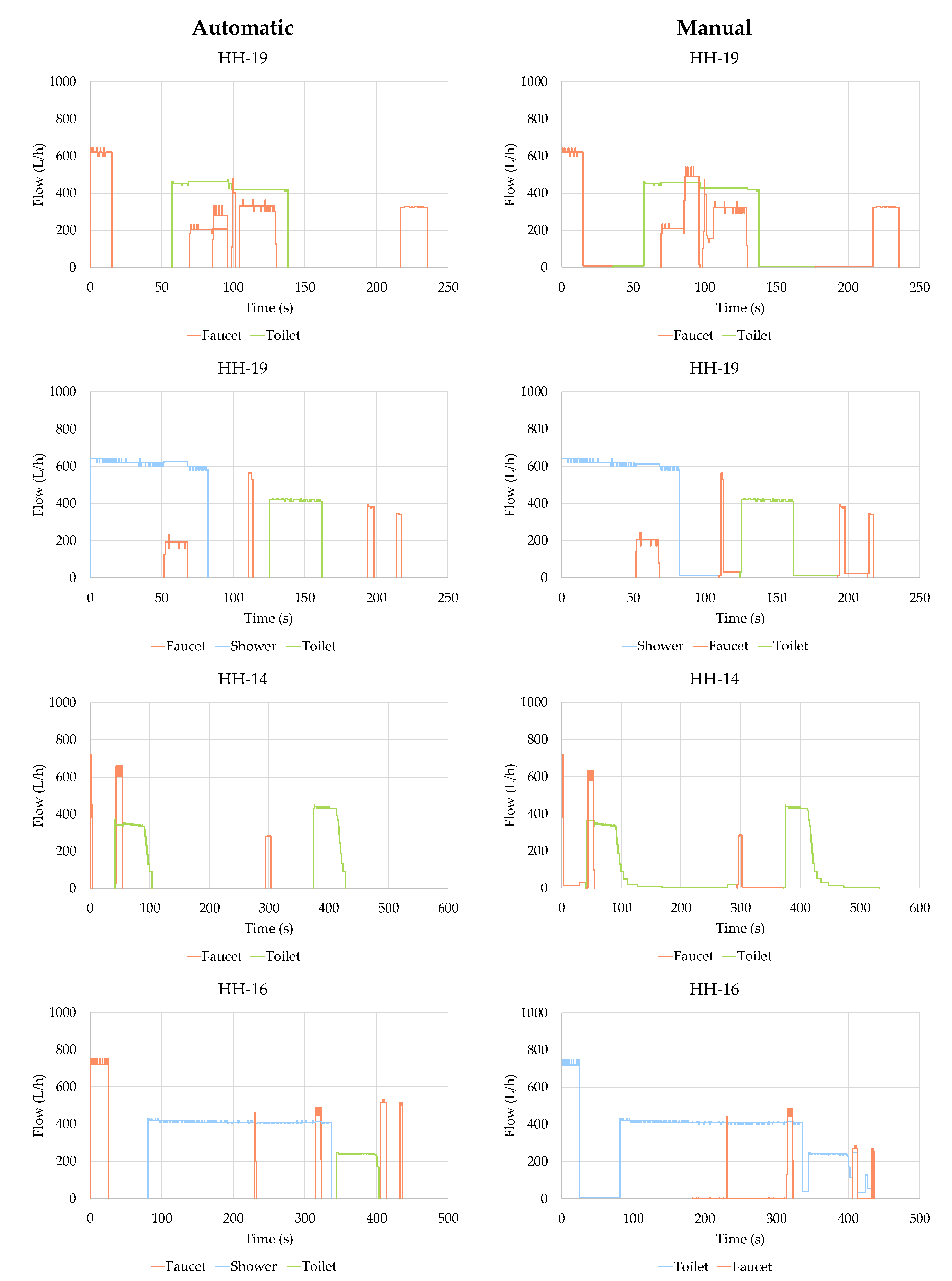
3. Case Study
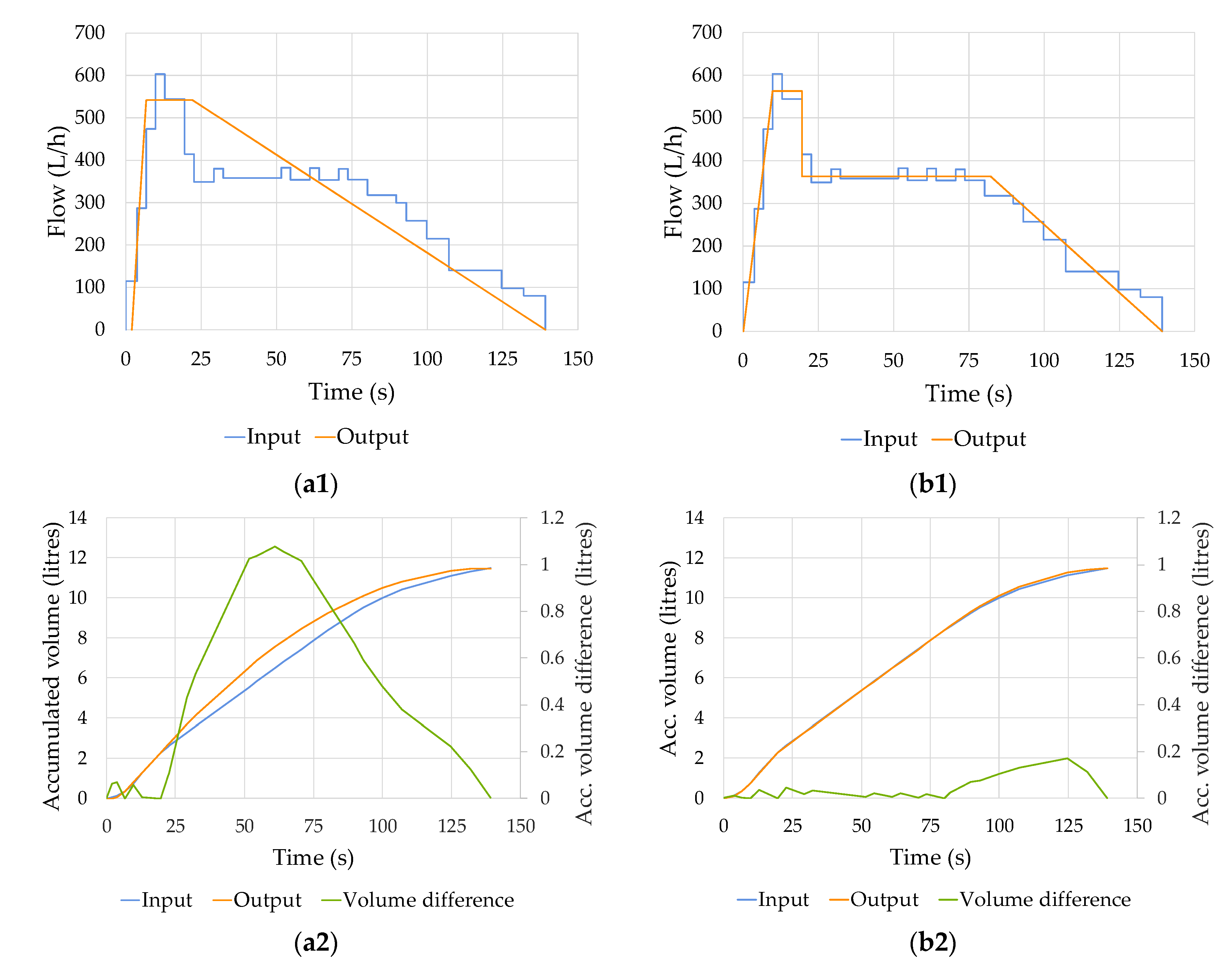
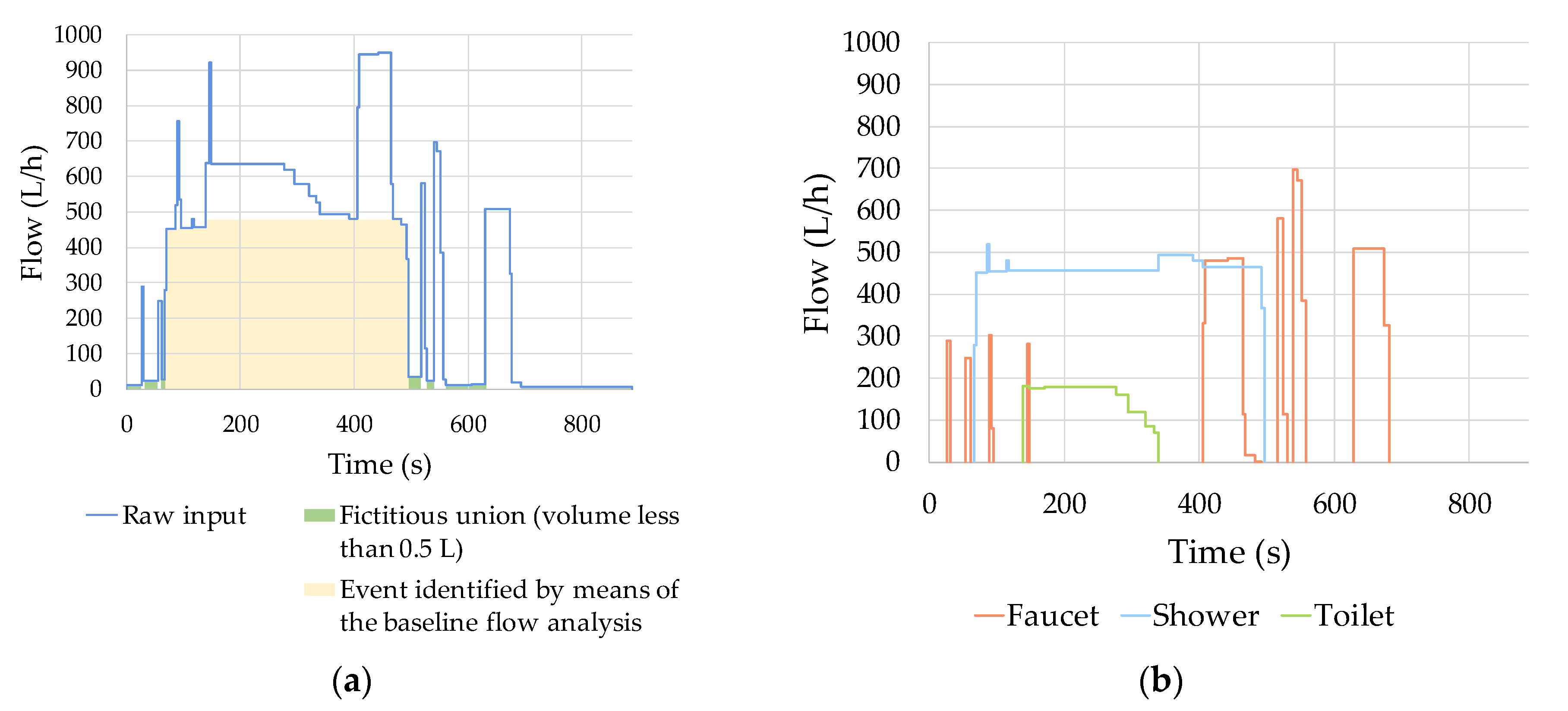
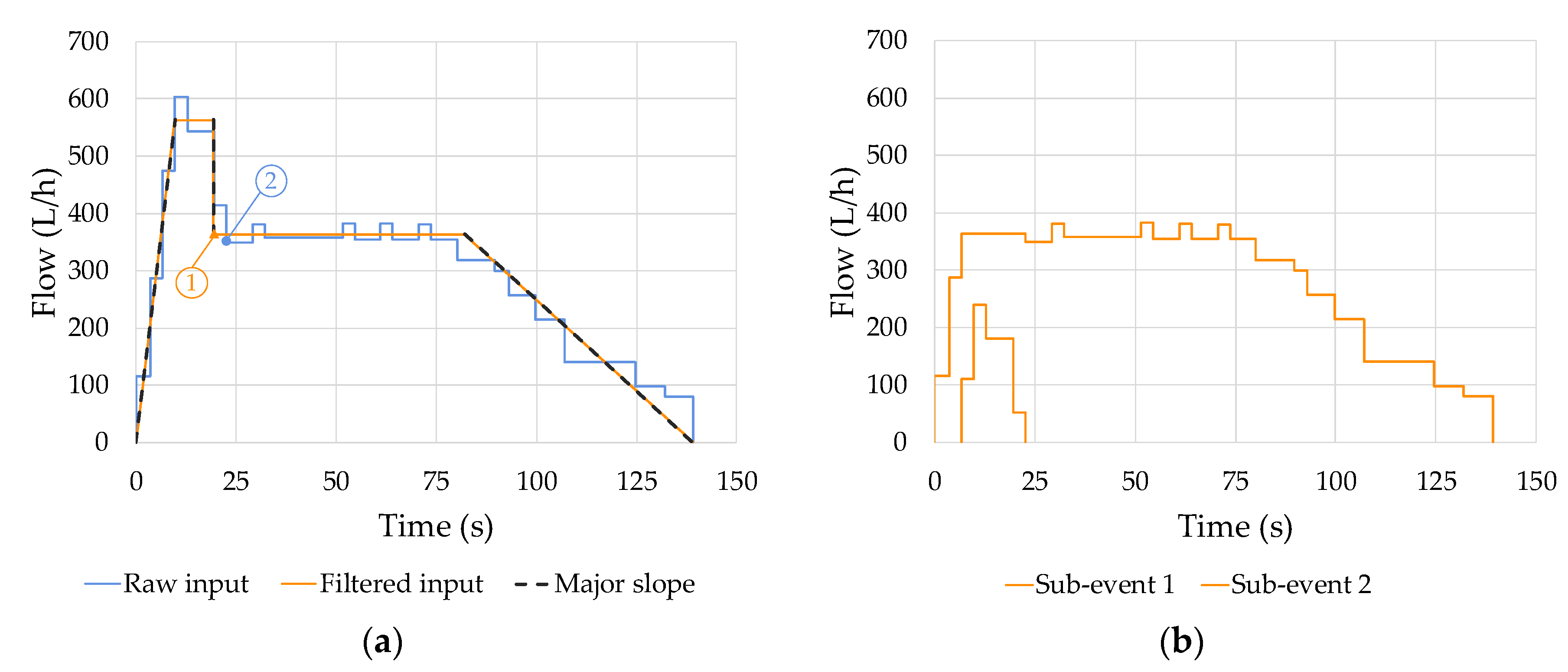
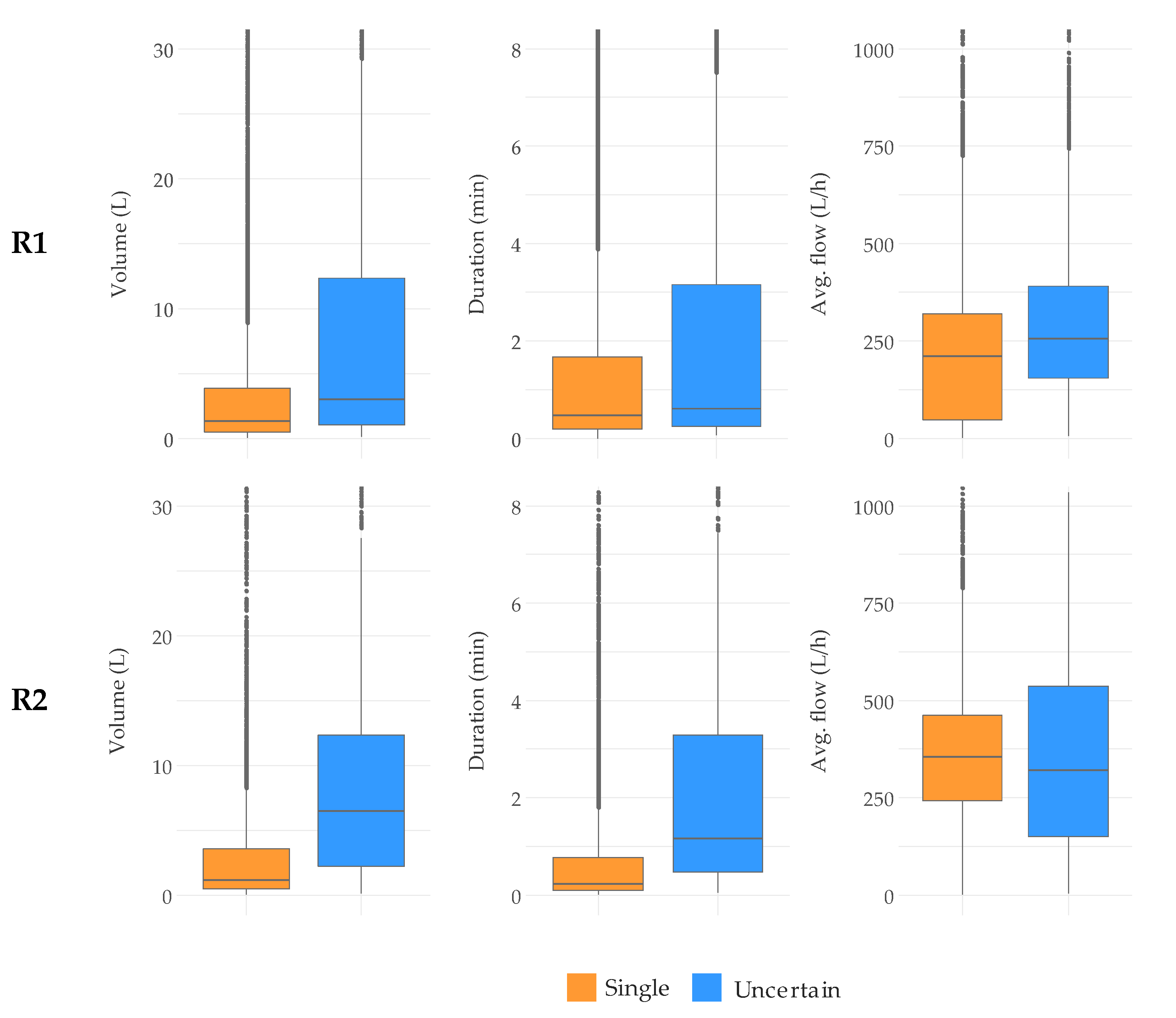
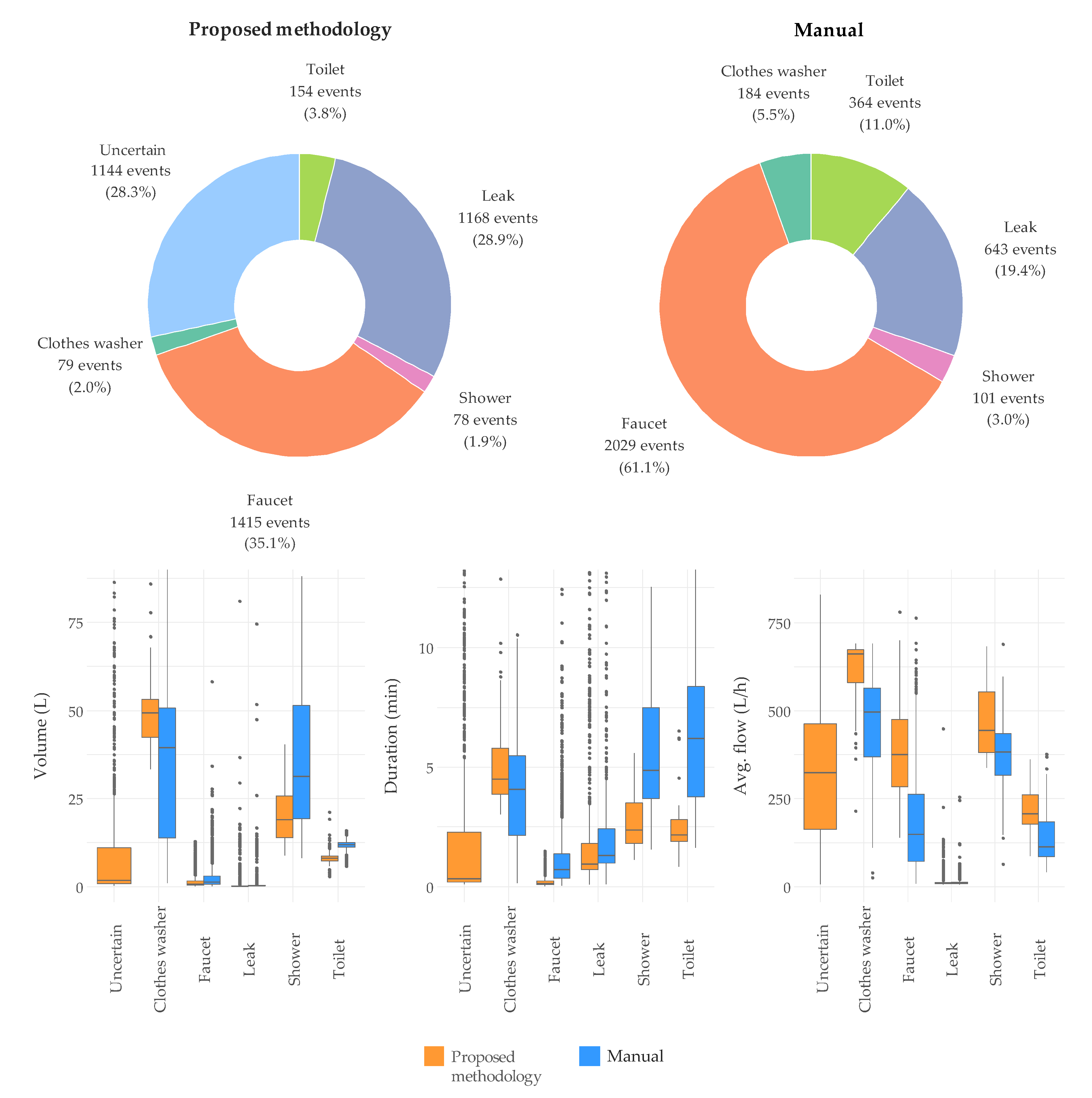
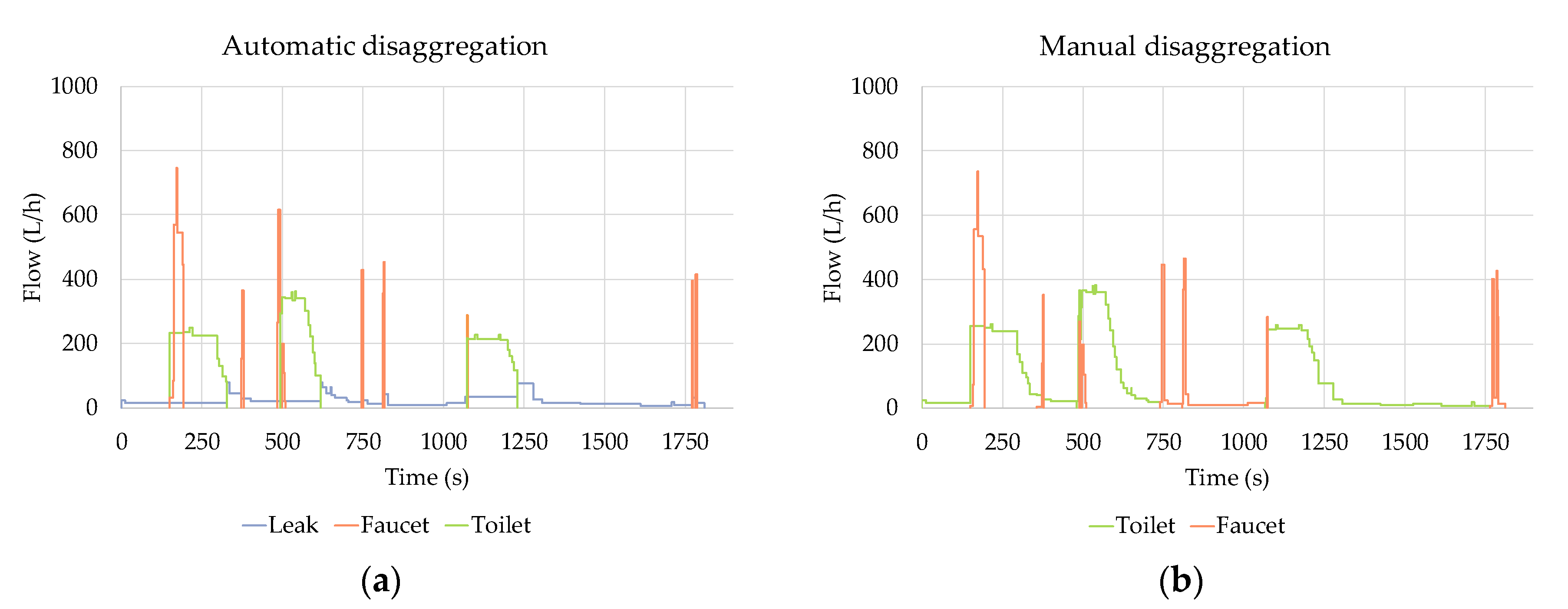
4. Results and Discussion
5. Conclusions
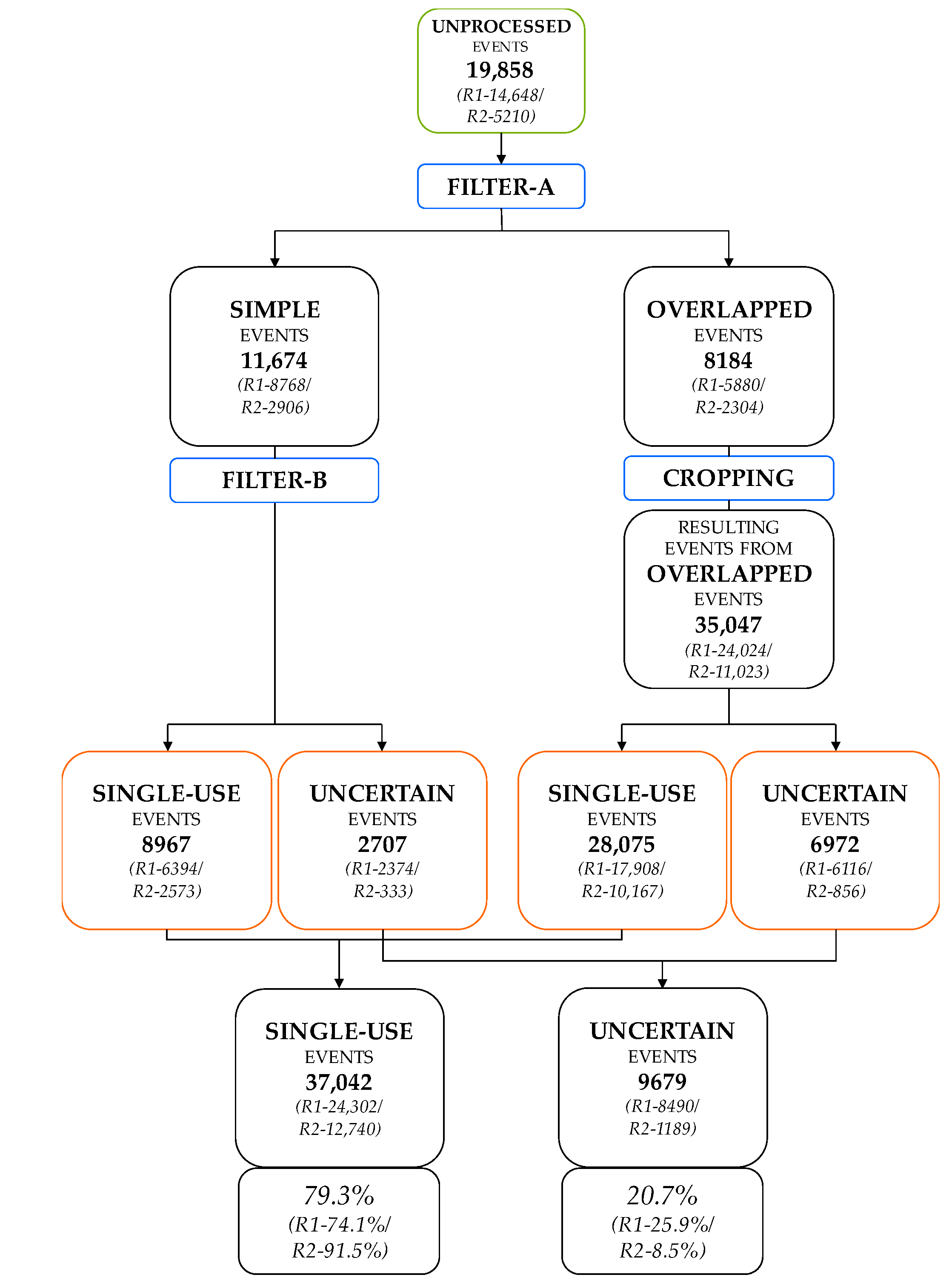
- (a)
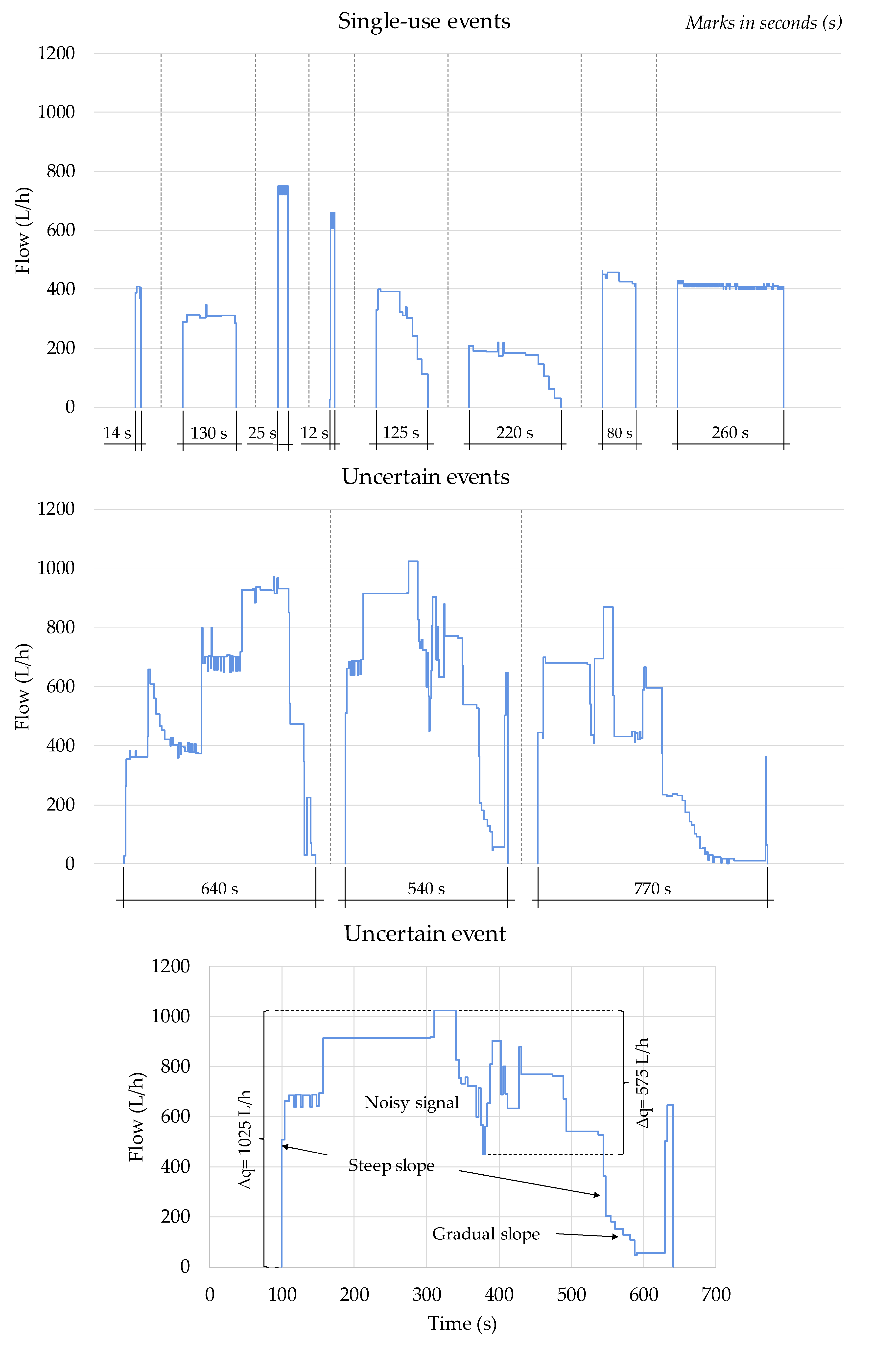
- The raw water consumption events are filtered and categorized as simple or overlapped to facilitate subsequent operations. The filtering relies on an advanced algorithm that is automatically calibrated for each water consumption event by means of NSGA-II genetic algorithm. Simple events are then characterized as single-use, which correspond to actual individual water uses, or uncertain events.
- (b)
- On the other hand, overlapped events, originated by simultaneous water uses, are cropped and separated into simpler single-use events. All cropping operations are implemented on the raw flow trace, and potential distortions in the filtered signal do not generate any loss of information in the resulting subevents. In other words, all the subevents created maintain the characteristics of the original flow trace. This particular feature increases the amount of information available for the classification algorithms that can be developed in the future, improving their effectiveness.
Definitions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A

Appendix B


References
- World Commission on Environment and Development. Our Common Future; Oxford University Press: Oxford, UK, 1987; ISBN 019282080X. [Google Scholar]
- Hoekstra, A.Y.; Mekonnen, M.M. The water footprint of humanity. Proc. Natl. Acad. Sci. USA 2012, 109, 3232–3237. [Google Scholar] [CrossRef] [PubMed]
- Jaramillo, F.; Destouni, G. Local flow regulation and irrigation raise global human water consumption and footprint. Science 2015, 350, 1248–1251. [Google Scholar] [CrossRef] [PubMed]
- Shiklomanov, I.A. Appraisal and Assessment of World Water Resources. Water Int. 2000, 25, 11–32. [Google Scholar] [CrossRef]
- Cominola, A.; Giuliani, M.; Piga, D.; Castelletti, A.; Rizzoli, A.E. Benefits and challenges of using smart meters for advancing residential water demand modeling and management: A review. Environ. Model. Softw. 2015, 72, 198–214. [Google Scholar] [CrossRef] [Green Version]
- Fielding, K.S.; Spinks, A.; Russell, S.; McCrea, R.; Stewart, R.A.; Gardner, J. An experimental test of voluntary strategies to promote urban water demand management. J. Environ. Manag. 2013, 114, 343–351. [Google Scholar] [CrossRef] [PubMed]
- Sahin, O.; Bertone, E.; Beal, C.D. A system approach for assessing water conservation potential through demand-based water tariffs. J. Clean. Prod. 2017, 148, 773–774. [Google Scholar] [CrossRef]
- Makki, A.A.; Stewart, R.A.; Beal, C.D.; Panuwatwanich, K. Novel bottom-up urban water demand forecasting model: Revealing the determinants, drivers and predictors of residential indoor end-use consumption. Resour. Conserv. Recycl. 2015, 95, 15–37. [Google Scholar] [CrossRef]
- Bennet, C.; Stewart, R.A.; Beal, C.D. ANN-Based residential water end-use demand forecasting model. Expert Syst. Appl. 2013, 40, 1014–1023. [Google Scholar] [CrossRef]
- DeOreo, W.B.; Heaney, J.P.; Mayer, P.W. Flow trace analysis to assess water use. Am. Water Works Assoc. 1996, 88, 79–90. [Google Scholar]
- Kowalski, M.; Marshallsay, D. A System for Improved Assessment of Domestic Water Use Components. II International Conference Efficient Use and Management of Urban Water Supply; International Water Association: Tenerife, Spain, 2003. [Google Scholar]
- Arregui, F. New software tool for water end-uses studies. Presented at the 8th IWA International Conference on Water Efficiency and Performance Assessment of Water Services, Cincinnati, OH, USA, 20–24 April 2015. [Google Scholar]
- Nguyen, K.A.; Zhang, H.; Stewart, R.A. Development of an intelligent model to categorise residential water end use events. J. Hydro-Environ. Res. 2013, 7, 182–201. [Google Scholar] [CrossRef]
- Nguyen, K.A.; Stewart, R.A.; Zhang, H. An intelligent pattern recognition model to automate the categorisation of residential water end-use events. Environ. Model. Softw. 2013, 47, 108–127. [Google Scholar] [CrossRef]
- Nguyen, K.A.; Stewart, R.A.; Zhang, H. An autonomous and intelligent expert system for residential water end-use classification. Expert Syst. Appl. 2014, 41, 342–356. [Google Scholar] [CrossRef]
- Nguyen, K.A.; Stewart, R.A.; Zhang, H.; Jones, C. Intelligent autonomous system for residential water end use classification: Autoflow. Appl. Soft Comput. 2015, 31, 118–131. [Google Scholar] [CrossRef]
- Piga, D.; Cominola, A.; Giuliani, M.; Castelletti, A.; Rizzoli, A.E. A convex optimization approach for automated water and energy end use disaggregation. In Proceedings of the 36th IAHR World Congress, Hague, The Netherlands, 28 June–3 July 2015. [Google Scholar]
- FLUID—The Learning Water Meter. Available online: http://www.fluidwatermeter.com (accessed on 17 November 2017).
- WaterSmart—Platform Features. Take a Look Under the Hood. Available online: https://www.watersmart.com (accessed on 17 November 2017).
- Aqubiq—Features. A Smart Path for a Greener Lifestyle. Available online: http://www.aqubiq.com (accessed on 17 November 2017).
- Pastor, L.; Arregui, F.; Cobacho, R. Filtering smart metering data to improve detection of water end use events. In Proceedings of the 9th International Conference on Efficient Use and Management of Urban Water, Bath, UK, 18–20 July 2017. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.A. Fast and Elitist Multiobjective Genetic Algorithm: NSGAII. IEEE Trans. Evolut. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling. J. Hydrol. 2009, 377, 80–91. [Google Scholar] [CrossRef]
- Reynolds, A.; Richards, G.; de la Iglesia, B.; Rayward-Smith, V. Clustering rules: A comparison of partitioning and hierarchical clustering algorithms. J. Math. Model. Algorithms 1992, 5, 475–504. [Google Scholar] [CrossRef]
- Amenta, V.; Tina, G.M. Load demand disaggregation based on simple load signature and user’s feedback. Energy Procedia 2015, 83, 380–388. [Google Scholar] [CrossRef]
- Elhamifar, E.; Sastry, S. Energy disaggregation via learning powerlets and sparse coding. In Proceedings of the National Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 629–635. [Google Scholar]
- Bonfigli, R.; Squartini, S.; Fagiani, M.; Piazza, F. Unsupervised algorithms for nonintrusive load monitoring: An up-to-date overview. In Proceedings of the 15th International Conference on Environment and Electrical Engineering (EEEIC), Rome, Italy, 10–13 June 2015; pp. 1175–1180. [Google Scholar]
- Cominola, A.; Giuliani, M.; Piga, D.; Castelletti, A.; Rizzoli, A.E. A Hybrid Signature-based Iterative Disaggregation algorithm for Non-Intrusive Load Monitoring. Appl. Energy 2017, 185, 331–344. [Google Scholar] [CrossRef]
- Guercio, R.; Magini, R.; Pallavicini, I. Instantaneous residential water demand as stochastic point process. WIT Trans. Ecol. Environ. 2001, 48, 129–138. [Google Scholar] [CrossRef]
- Alvisi, S.; Franchini, M.; Marinelli, A. A stochastic model for representing drinking water demand at residential level. Water Resour. Manag. 2003, 17, 197–222. [Google Scholar] [CrossRef]
- Garcıa, V.J.; Garcıa-Bartual, R.; Cabrera, E.; Arregui, F.; Garcıa-Serra, J. Stochastic model to evaluate residential water demands. J. Water Resour. Plan. Manag. 2004, 130, 386–394. [Google Scholar] [CrossRef]
- Blokker, E.J.M.; Vreeburg, J.H.G.; van Dijk, J.C. Simulating residential water demand with a stochastic end-use model. J. Water Resour. Plan. Manag. 2010, 136, 375–382. [Google Scholar] [CrossRef]
- Creaco, E.; Alvisi, S.; Farmani, R.; Vamvakeridou-Lyroudia, L.; Franchini, M.; Kapelan, Z.; Savic, D. Methods for preserving duration-intensity correlation on synthetically generated water-demand pulses. J. Water Resour. Plan. Manag. 2016, 142. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| R1 Study | R2 Study | Total | |
|---|---|---|---|
| Total number of unprocessed events (10 households) | 14,648 | 5210 | 19,858 |
| Total number of resulting events (10 households) | 32,792 | 13,929 | 46,721 |
| Total number of resulting events per household | 3279 | 1393 | 2336 |
| Average time consumed per cropping operation (s) | 18.6 | 28.3 | 21.8 |
| Average number of cropping operation per household and day | 121 | 58 | 90 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pastor-Jabaloyes, L.; Arregui, F.J.; Cobacho, R. Water End Use Disaggregation Based on Soft Computing Techniques. Water 2018, 10, 46. https://doi.org/10.3390/w10010046
Pastor-Jabaloyes L, Arregui FJ, Cobacho R. Water End Use Disaggregation Based on Soft Computing Techniques. Water. 2018; 10(1):46. https://doi.org/10.3390/w10010046
Chicago/Turabian StylePastor-Jabaloyes, L., F. J. Arregui, and R. Cobacho. 2018. "Water End Use Disaggregation Based on Soft Computing Techniques" Water 10, no. 1: 46. https://doi.org/10.3390/w10010046