

Interpretable Machine Learning Analysis of Stress Concentration in Magnesium: An Insight beyond the Black Box of Predictive Modeling

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
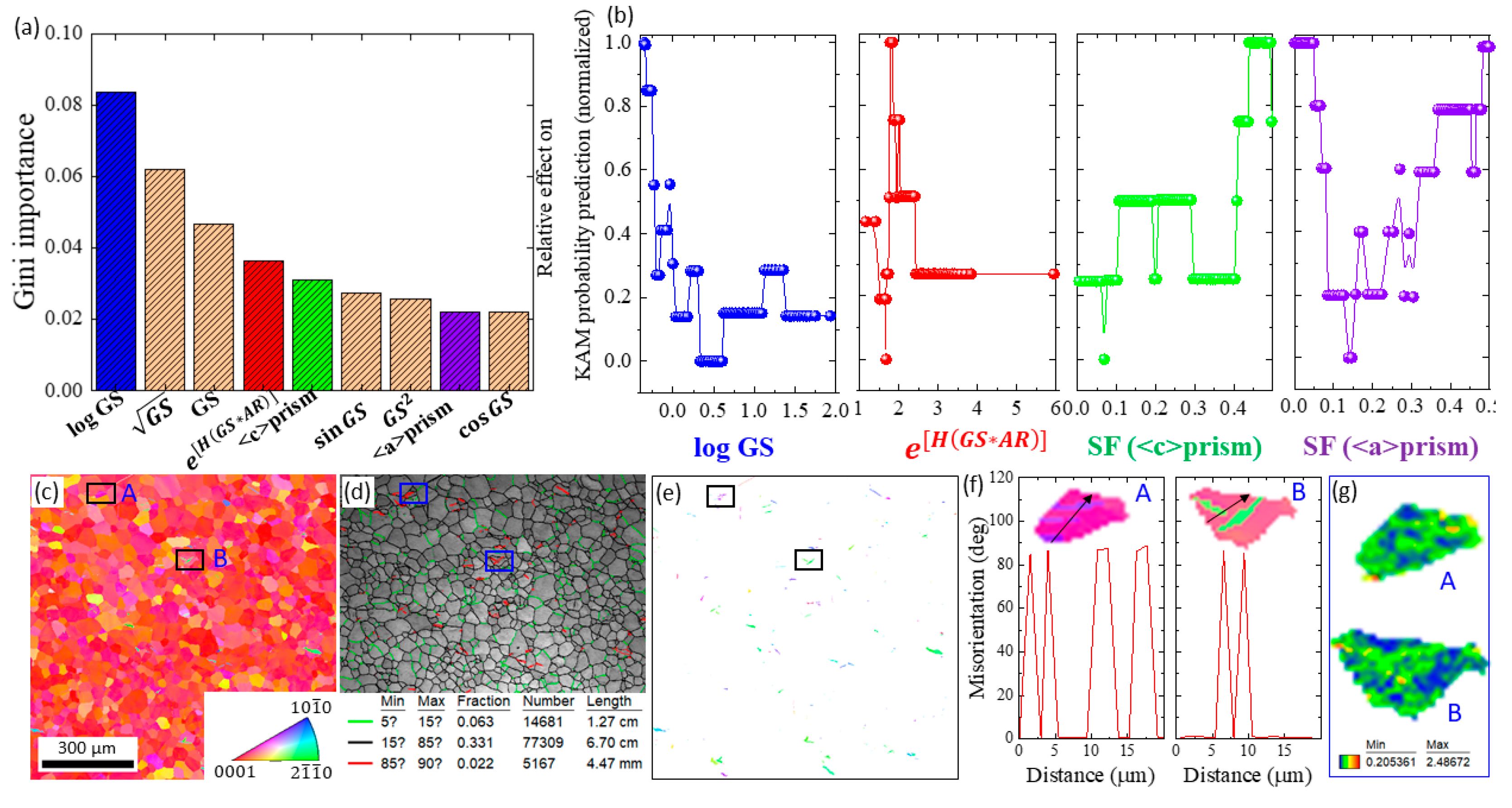{kind=link}
{kind=link}
Abstract
:1. Introduction
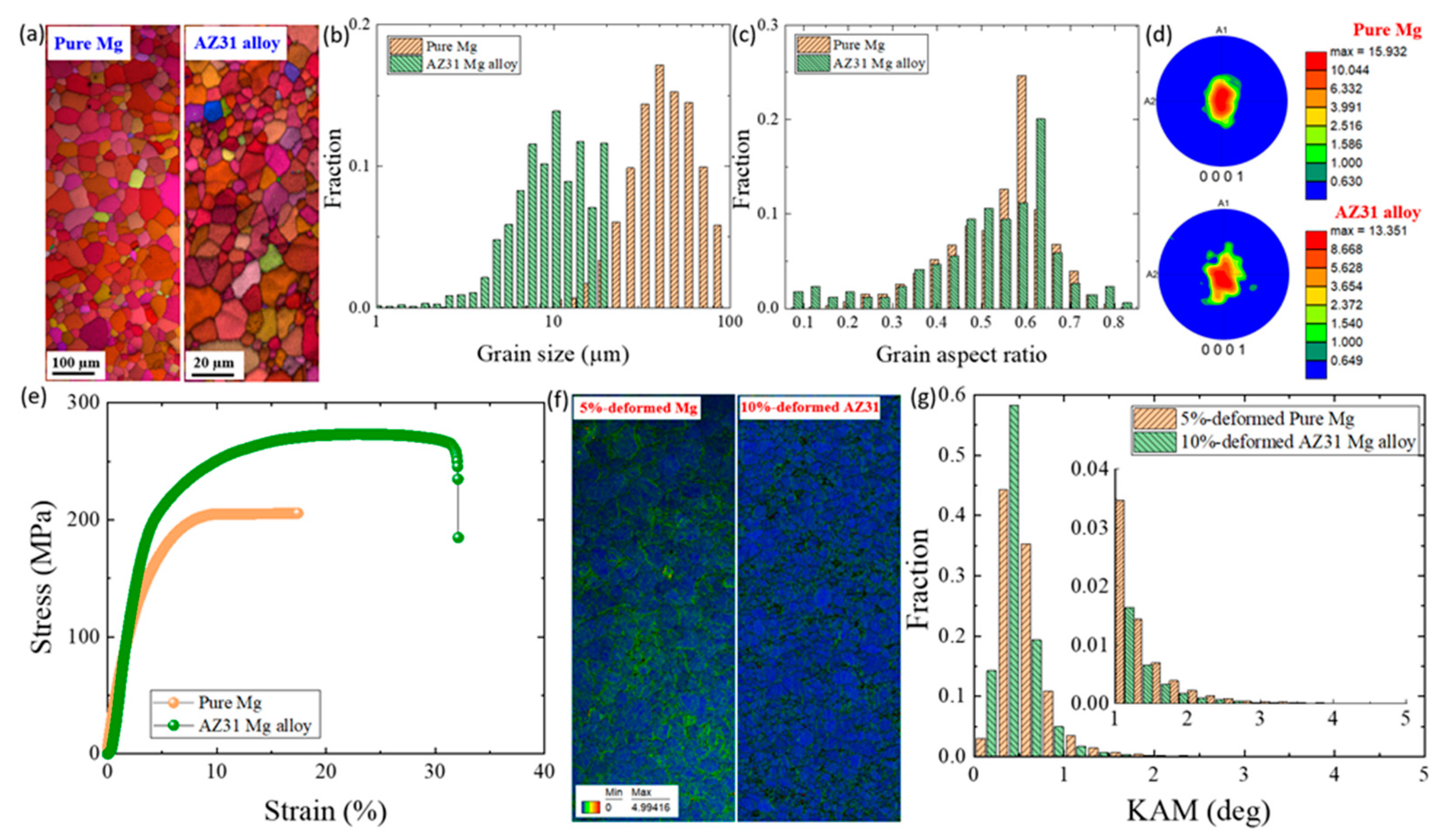
2. Materials and Experiments
3. Learning Procedure
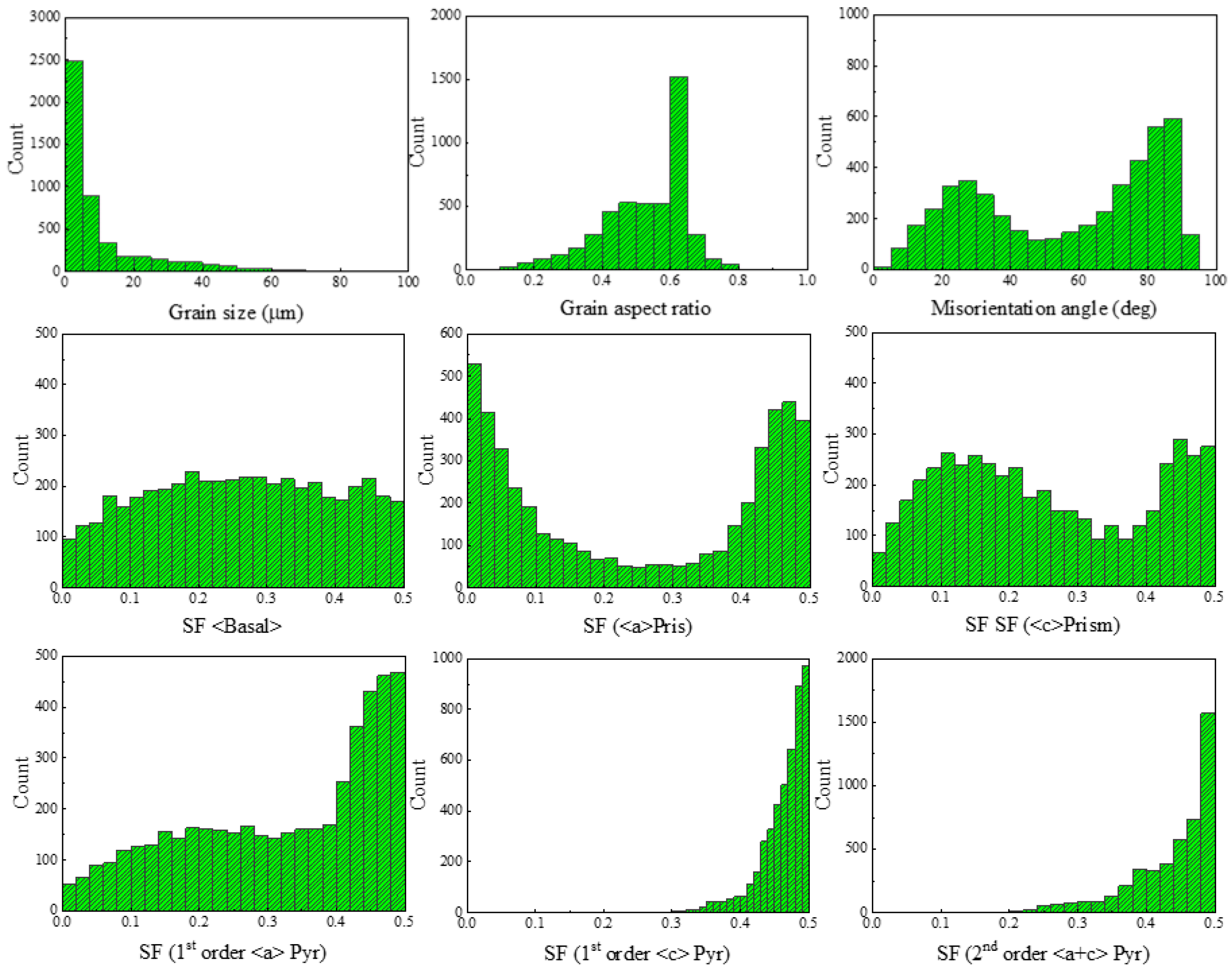
3.1. Microstructural Features
3.2. Features Engineering
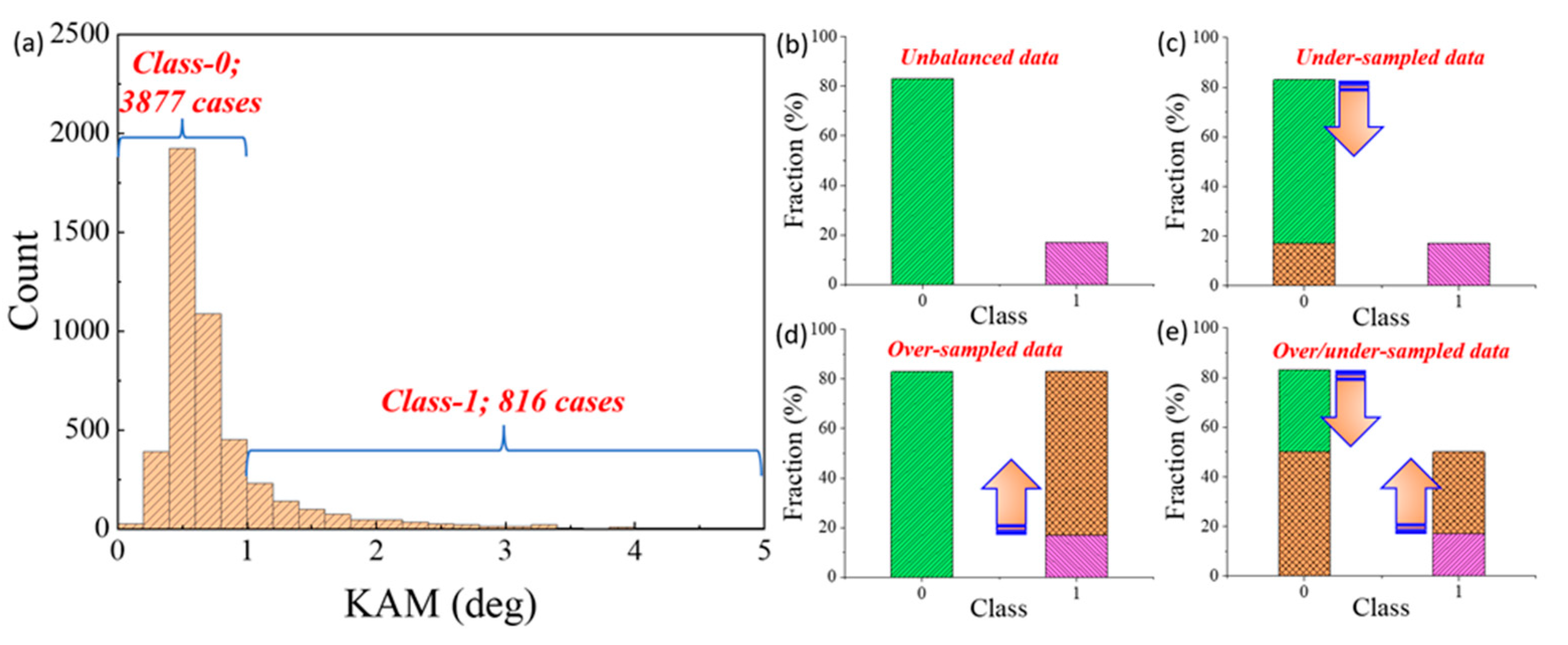
3.3. Initial Dataset and Data Analysis
3.4. Training and Testing
4. Results and Discussions
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. ADASYN Algorithm
- -
- Input:
- -
- Procedure:
Appendix A.2. Tomek Links
Appendix A.3. Accumulated Local Effects (ALE)
References
- Chaudry, U.M.; Tekumalla, S.; Gupta, M.; Jun, T.-S.; Hamad, K. Designing highly ductile magnesium alloys: Current status and future challenges. Crit. Rev. Solid State Mater. Sci. 2021, 47, 194–281. [Google Scholar] [CrossRef]
- Prasad, S.V.S.; Verma, K.; Mishra, R.K.; Kumar, V.; Singh, S. The role and significance of Magnesium in modern day research-A review. J. Magnes. Alloy. 2021, 10, 1–61. [Google Scholar] [CrossRef]
- Chen, J.; Tan, L.; Yu, X.; Etim, I.P.; Ibrahim, M.; Yang, K. Mechanical properties of magnesium alloys for medical application: A review. J. Mech. Behav. Biomed. Mater. 2018, 87, 68–79. [Google Scholar] [CrossRef] [PubMed]
- Chaudry, U.M.; Farooq, A.; Malik, A.; Nabeel, M.; Sufyan, M.; Tayyeb, A.; Asif, S.; Inam, A.; Elbalaawy, A.; Hafez, E.; et al. Biodegradable properties of AZ31-0.5Ca magnesium alloy. Mater. Technol. 2022, 1–12. [Google Scholar] [CrossRef]
- Chaudry, U.M.; Hamad, K.; Ko, Y.G. Effect of calcium on the superplastic behavior of AZ31 magnesium alloy. Mater. Sci. Eng. A 2021, 815, 140874. [Google Scholar] [CrossRef]
- Liu, B.-Y.; Zhang, Z.; Liu, F.; Yang, N.; Li, B.; Chen, P.; Wang, Y.; Peng, J.-H.; Li, J.; Ma, E.; et al. Rejuvenation of plasticity via deformation graining in magnesium. Nat. Commun. 2022, 13, 1060. [Google Scholar] [CrossRef]
- Han, G.; Noh, Y.; Chaudry, U.M.; Park, S.H.; Hamad, K.; Jun, T.-S. {10–12} extension twinning activity and compression behavior of pure Mg and Mg-0.5Ca alloy at cryogenic temperature. Mater. Sci. Eng. A 2022, 831, 142189. [Google Scholar] [CrossRef]
- Muzyk, M.; Pakiela, Z.; Kurzydlowski, K. Generalized stacking fault energy in magnesium alloys: Density functional theory calculations. Scr. Mater. 2012, 66, 219–222. [Google Scholar] [CrossRef]
- Mahata, A.; Sikdar, K. Molecular dynamics simulation of nanometer scale mechanical properties of hexagonal MgLi alloy. J. Magnes. Alloy. 2016, 4, 36–43. [Google Scholar] [CrossRef]
- Jaafreh, R.; Kang, Y.S.; Hamad, K. Lattice Thermal Conductivity: An Accelerated Discovery Guided by Machine Learning. ACS Appl. Mater. Interfaces 2021, 13, 57204–57213. [Google Scholar] [CrossRef]
- Jaafreh, R.; Kang, Y.S.; Kim, J.-G.; Hamad, K. Machine learning guided discovery of super-hard high entropy ceramics. Mater. Lett. 2022, 306, 130899. [Google Scholar] [CrossRef]
- Jaafreh, R.; Abuhmed, T.; Kim, J.-G.; Hamad, K. Crystal structure guided machine learning for the discovery and design of intrinsically hard materials. J. Mater. 2021, 8, 678–684. [Google Scholar] [CrossRef]
- Zhang, Z.; Tehrani, A.M.; Oliynyk, A.O.; Day, B.; Brgoch, J. Finding the Next Superhard Material through Ensemble Learning. Adv. Mater. 2021, 33, e2005112. [Google Scholar] [CrossRef]
- Ward, L.; Liu, R.; Krishna, A.; Hegde, V.I.; Agrawal, A.; Choudhary, A.; Wolverton, C. Including crystal structure attributes in machine learning models of formation energies via Voronoi tessellations. Phys. Rev. B 2017, 96, 24104. [Google Scholar] [CrossRef]
- Tehrani, A.M.; Oliynyk, A.O.; Parry, M.; Rizvi, Z.; Couper, S.; Lin, F.; Miyagi, L.; Sparks, T.D.; Brgoch, J. Machine Learning Directed Search for Ultraincompressible, Superhard Materials. J. Am. Chem. Soc. 2018, 140, 9844–9853. [Google Scholar] [CrossRef] [PubMed]
- Gui, Y.; Li, Q.; Xue, Y.; Ouyang, L. Twin-twin geometric structure effect on the twinning behavior of an Mg-4Y-3Nd-2Sm-0.5Zr alloy traced by quasi-in-situ EBSD. J. Magnes. Alloy. 2021. [Google Scholar] [CrossRef]
- Chaudry, U.M.; Hamad, K.; Kim, J.-G. On the ductility of magnesium based materials: A mini review. J. Alloy. Compd. 2019, 792, 652–664. [Google Scholar] [CrossRef]
- Dieter, G.E.; Bacon, D. Mechanical Metallurgy; McGraw-Hill: New York, NY, USA, 1988. [Google Scholar]
- Seret, A.; Moussa, C.; Bernacki, M.; Signorelli, J.; Bozzolo, N. Estimation of geometrically necessary dislocation density from filtered EBSD data by a local linear adaptation of smoothing splines. J. Appl. Crystallogr. 2019, 52, 548–563. [Google Scholar] [CrossRef]
- Zheng, A.; Casari, A. Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists; O’Reilly Media, Inc.: Boston, MA, USA, 2018. [Google Scholar]
- de Franca, F.O.; Aldeia, G.S.I. Interaction–Transformation Evolutionary Algorithm for Symbolic Regression. Evol. Comput. 2021, 29, 367–390. [Google Scholar] [CrossRef]
- Wright, S.I.; Nowell, M.M.; Field, D.P. A Review of Strain Analysis Using Electron Backscatter Diffraction. Microsc. Microanal. 2011, 17, 316–329. [Google Scholar] [CrossRef]
- Ertekin, S.; Huang, J.; Giles, C.L. Active learning for class imbalance problem. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007. [Google Scholar] [CrossRef]
- Elkan, C. The foundations of cost-sensitive learning. In Proceedings of the International Joint Conference on Artificial Itelligence, Seattle, WA, USA, 4–10 August 2001; pp. 973–978. [Google Scholar]
- Wu, G.; Chang, E. KBA: Kernel boundary alignment considering imbalanced data distribution. IEEE Trans. Knowl. Data Eng. 2005, 17, 786–795. [Google Scholar] [CrossRef]
- Mohammed, R.; Rawashdeh, J.; Abdullah, M. Machine Learning with Oversampling and Undersampling Techniques: Overview Study and Experimental Results. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 243–248. [Google Scholar] [CrossRef]
- Glazkova, A. A Comparison of Synthetic Oversampling Methods for Multi-class Text Classification. arXiv 2020, arXiv:2008.04636. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the IEEE International Joint Conference on Neural Networks, Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Cramer, J. The Origins of Logisitic Regression. Tinbergen Institute Working Paper No. 2002-119/4, December 2002. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=360300 (accessed on 10 August 2022).
- Domingos, P.; Pazzani, M. On the Optimality of the Simple Bayesian Classifier under Zero-One Loss. Mach. Learn. 1997, 29, 103–130. [Google Scholar] [CrossRef]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef]
- Baum, E.B. On the capabilities of multilayer perceptrons. J. Complex. 1988, 4, 193–215. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Costa, E.P.; Carvalho, A.C.P.L.F.; Lorena, A.C.; Freitas, A.A. A Review of Performance Evaluation Measures for Hierarchical Classifiers. AAAI Work. Tech. Rep. 2007, 1–6. Available online: https://www.aaai.org/Papers/Workshops/2007/WS-07-05/WS07-05-001.pdf (accessed on 10 August 2022).
- Louppe, G.; Wehenkel, L.; Sutera, A.; Geurts, P. Understanding variable importances in Forests of randomized trees. Adv. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Apley, D.W.; Zhu, J. Visualizing the effects of predictor variables in black box supervised learning models. J. R. Stat. Soc. Ser. B Stat. Methodol. 2020, 82, 1059–1086. [Google Scholar] [CrossRef]
- Baniecki, H.; Kretowicz, W.; Biecek, P. Fooling Partial Dependence via Data Poisoning. arXiv 2021, arXiv:2105.12837. 1–15. [Google Scholar]
- Zeng, Z.; Nie, J.-F.; Xu, S.-W.; Davies, C.; Birbilis, N. Super-formable pure magnesium at room temperature. Nat. Commun. 2017, 8, 972. [Google Scholar] [CrossRef]
- Barnett, M.R. Twinning and the ductility of magnesium alloys: Part I: “Tension” twins. Mater. Sci. Eng. A 2007, 464, 1–7. [Google Scholar] [CrossRef]
- Barnett, M. Twinning and the ductility of magnesium alloys: Part II. “Contraction” twins. Mater. Sci. Eng. A 2007, 464, 8–16. [Google Scholar] [CrossRef]
- Wei, K.; Hu, R.; Yin, D.; Xiao, L.; Pang, S.; Cao, Y.; Zhou, H.; Zhao, Y.; Zhu, Y. Grain size effect on tensile properties and slip systems of pure magnesium. Acta Mater. 2021, 206, 116604. [Google Scholar] [CrossRef]
- Ando, D.; Koike, J.; Sutou, Y. The role of deformation twinning in the fracture behavior and mechanism of basal textured magnesium alloys. Mater. Sci. Eng. A 2014, 600, 145–152. [Google Scholar] [CrossRef]
- De Souto, M.C.P.; Bittencourt, V.G.; Costa, J.A.F. An Empirical Analysis of Under-Sampling Techniques to Balance a Protein Structural Class Dataset. In Proceedings of the 13th International Conference on Neural Information Processing ICONIP 2006, Hong Kong, China, 3–6 October 2006; pp. 21–29. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jaafreh, R.; Kim, J.-G.; Hamad, K. Interpretable Machine Learning Analysis of Stress Concentration in Magnesium: An Insight beyond the Black Box of Predictive Modeling. Crystals 2022, 12, 1247. https://doi.org/10.3390/cryst12091247
Jaafreh R, Kim J-G, Hamad K. Interpretable Machine Learning Analysis of Stress Concentration in Magnesium: An Insight beyond the Black Box of Predictive Modeling. Crystals. 2022; 12(9):1247. https://doi.org/10.3390/cryst12091247
Chicago/Turabian StyleJaafreh, Russlan, Jung-Gu Kim, and Kotiba Hamad. 2022. "Interpretable Machine Learning Analysis of Stress Concentration in Magnesium: An Insight beyond the Black Box of Predictive Modeling" Crystals 12, no. 9: 1247. https://doi.org/10.3390/cryst12091247