1. Introduction
In many real-world security domains, security agencies (defender) attempt to predict the attacker’s future behavior based on some collected attack data, and use the prediction result to determine effective defense strategies. A lot of existing work in security games has thus focused on developing different behavior models of the attacker [
1,
2,
3]. Recently, the challenge of playing against a deceptive attacker has been studied, in which the attacker can manipulate the attack data (by changing its behavior) to
fool the defender, making the defender learn a wrong behavior model of the attacker [
4]. Such deceptive behavior by the attacker can lead to an ineffective defender strategy.
A key limitation in existing work is the assumption that the defender has full access to the attack data, which means the attacker knows exactly what the learning outcome of the defender would be. However, in many real-world domains, the defender often has limited access to the attack data, e.g., in wildlife protection, park rangers typically cannot find all the snares laid out by poachers in entire conservation areas [
5]. As a result, the learning outcome the defender obtains (with limited attack data) may be different from the deception behavior model that the attacker commits to. Furthermore, the attacker (and the defender) may have imperfect knowledge about the relation between the deception choice of the attacker and the actual learning outcome of the defender.
We address this limitation by studying the challenge of attacker deception given such uncertainty. We consider a security game model in which the defender adopts Quantal Response (
), a well-known behavior model in economics and game theory [
2,
6,
7], to predict the attacker’s behavior, where the model parameter
is trained based on some attack data. On the other hand, the attacker plays deceptively by mimicking a
model with a different value of
, denoted by
. In this work, we incorporate the deception-learning uncertainty into this game model, where the learning outcome of the defender (denoted by
) can be any value within a range centered at
.
We provide the following key contributions. First, we present a new maximin-based algorithm to compute an optimal robust deception strategy for the attacker. At a high level, our algorithm works by maximizing the attacker’s utility under the worst-case of uncertainty. The problem comprises of three nested optimization levels, which is not straightforward to solve. We thus propose an alternative single-level optimization problem based on partial discretization. Despite this simplification, the resulting optimization is still challenging to solve due to the non-convexity of the attacker’s utility and the dependence of the uncertainty set on . By exploiting the decomposibility of the deception space and the monotonicity of the attacker’s utility, we show that the alternative relaxed problem can be solved optimally in polynomial time. The idea is to decompose the problem into a polynomial number of sub-problems (according to the decomposition of the deception space)—each sub problem can be solved in a polynomial time given the attacker optimal deception decision within each sub-space is shown to be one of the extreme points of that sub-space, despite the non-convexity of the sub-problem.
Second, we propose a new counter-deception algorithm, which generates an optimal defense function that outputs a defense strategy for each possible (deceptive) learning outcome. Our key finding is that there is a universal optimal defense function for the defender, regardless of any additional information he has about the relation between their learning outcome and the deception choice of the attacker (besides the common knowledge that the learning outcome is within a range around the deception choice). Importantly, this optimal defense function, which can be determined by solving a single non-linear program, only outputs two different strategies despite the infinite-sized learning outcome space. Our counter-deception algorithm is built based on an extensive in-depth analysis of intrinsic characteristics of the attacker’s adaptive deception response to any deception-aware defense solution. That is, under our propose defense mechanism, the attacker’s deception space remains decomposable (although the sub-spaces vary which depends on the counter-deception mechanism) and the attacker’s optimal deception remains one of the extreme points of the deception sub-spaces.
Third, we conduct extensive experiments to evaluate our proposed algorithms in various security game settings with different number of targets, various ranges of the defender capacity as well as different levels of the attacker uncertainty, and finally, different correlations between players’ payoffs. Our results show that (i) despite the uncertainty, the attacker still obtains a significantly higher utility by playing deceptively when the defender is unaware of the attacker deception; and (ii) the defender can substantially diminish the impact of the attacker’s deception when following our counter-deception algorithm.
Outline of the Article
We outline the rest of our article as follows. We discuss the Related Work and Background in
Section 2 and
Section 3. In
Section 4, we present our detailed theoretical analysis on the attacker behavior deception under the uncertainty of the defender’s learning outcome, given that the defender is
unaware of the attacker’s deception. In
Section 5, we describe our new counter-deception algorithm for the defender to tackle the attacker’s manipulation. In this section, we first extend theoretical results in
Section 4 as to analyzing the attacker manipulation
adaptation to the defender’s counter-deception. Based on the result of the attacker adaptation, we then provide theoretical results on computing the defender optimal counter-deception. In
Section 6, we show our experiment results, evaluating our proposed algorithms. Finally,
Section 7 concludes our article.
3. Background
Stackelberg Security Games (s). There is a set of
targets that a defender has to protect using
security resources. A pure strategy of the defender is an allocation of these
L resources over the
T targets. A mixed strategy of the defender is a probability distribution over all pure strategies. In this work, we consider the no-scheduling-constraint game setting, in which each defender mixed strategy can be compactly represented as a coverage vector
, where
is the probability that the defender protects target
t and
[
28]. We denote by
the set of all defense strategies. In
s, the defender plays first by committing to a mixed strategy, and the attacker responds against this strategy by choosing a single target to attack.
When the attacker attacks target
t, it obtains a reward
while the defender receives a penalty
if the defender is not protecting that target. Conversely, if the defender is protecting
t, the attacker gets a penalty
while the defender receives a reward
. The expected utility of the defender,
(and attacker’s,
), if the attacker attacks target
t are computed as follows:
Quantal Response Model (). is a well-known behavioral model used to predict boundedly rational (attacker) decision making in security games [
2,
6,
7]. Essentially,
predicts the probability that the attacker attacks each target
t using the softmax function:
where
is the parameter that governs the attacker’s rationality. When
, the attacker attacks every target uniformly at random. When
, the attacker is perfectly rational. Given that the attacker follows
, the defender and attacker’s expected utility is computed as an expectation over all targets:
The attacker’s utility
was proved to be increasing in
[
4]. We leverage this monotonicity property to analyze the attacker’s deception. In
s, the defender can learn
based on some collected attack data, denoted by
, and find an optimal strategy which maximizes their expected utility accordingly:
4. Attacker Behavior Deception under Unknown Learning Outcome
We first study the problem of imitative behavior deception in a security scenario in which the attacker does not know exactly the defender’s learning outcome. Formally, if the attacker plays according to a particular parameter value of
, denoted by
, the learning outcome of the defender can be any value within the interval
, where
represents the extent to which the attacker is uncertain about the learning outcome of the defender. We term this interval,
, as the
uncertainty range of
. We are particularly interested in the research question:
Given uncertainty about learning outcomes of the defender, can the attacker still benefit from playing deceptively?
In this section, we consider the scenario when the attacker plays deceptively while the defender does not take into account the prospect of the attacker’s deception. We aim at analyzing the attacker deception decision in this no-counter-deception scenario. We assume that the attacker plays deceptively by mimicking any
within the range
. We consider
as this is the widely accepted range of the attacker’s bounded rationality in the literature. The value
represents the limit to which the attacker plays deceptively. When
, the deception range of the attacker covers the whole range of
. We aim at examining the impact of
on the deception outcome of the attacker later in our experiments. Given uncertainty about the learning outcome of the defender, the attacker attempts to find the optimal
to imitate that maximizes its utility in the worst case scenario of uncertainty, which can be formulated as follows:
where
is the defender’s optimal strategy w.r.t their learning outcome
. The objective
is the attacker’s utility when the defender plays
and the attacker mimics
with
to play (see Equations (1)–(3) for the detailed computation). In addition,
is the defender’s expected utility that the defender aims to maximize where
is the defender’s strategy and
is the learning outcome of the defender regarding the attacker’s behavior. Essentially, the last constraint of
ensures that the defender will play an optimal defense strategy according to their learning outcome. Finally, due to potential noises in learning, the defender’s learning outcome
may fall outside of the deception range of the attacker, which is captured by our constraint that
.
4.1. A Polynomial-Time Deception Algorithm
The optimization problem
involves three-nested optimization levels which is not straightforward to solve. We thus propose to limit the possible learning outcomes of the defender by discretizing the domain of
into a finite set
where
,
, and
where
is the discretization step size and
is the number of discrete learning values
1. For each deception choice
, the attacker’s
uncertainty set of defender’s possible learning outcomes
is now given by:
For each
, we can easily compute the corresponding optimal defense strategy
in advance [
2]. We thus obtain a simplified optimization problem:
where
U is the maximin utility for the attacker in the worst-case of learning outcome.
Remark on computational challenge. Although is a single-level optimization, solving it is still challenging due to (i) is a non-convex optimization problem since the attacker’s utility is non-convex in ; and (ii) the number of inequality constraints in vary with respect to , which complicates the problem further. By exploiting the decomposability property of the deception space and the monotonicity of the attacker’s utility function , we show that can be solved optimally in a polynomial time.
Theorem 1 (Time complexity). () can be solved optimally in a polynomial time.
Overall, the proof of Theorem 1 is derived based on (i) Lemma 1—showing that the deception space can be divided into an number of sub-intervals, and each sub-interval leads to the same uncertainty set; and (ii) Lemma 4—showing that () can be divided into a sub-problems which correspond to the decomposability of the deception space (as shown in Lemma 1), and each sub-problem can be solved in polynomial time.
4.1.1. Decomposability of Deception Space
In the following, we first present our theoretical analysis on the decomposability of the deception space. We then describe in detail our decomposition algorithm.
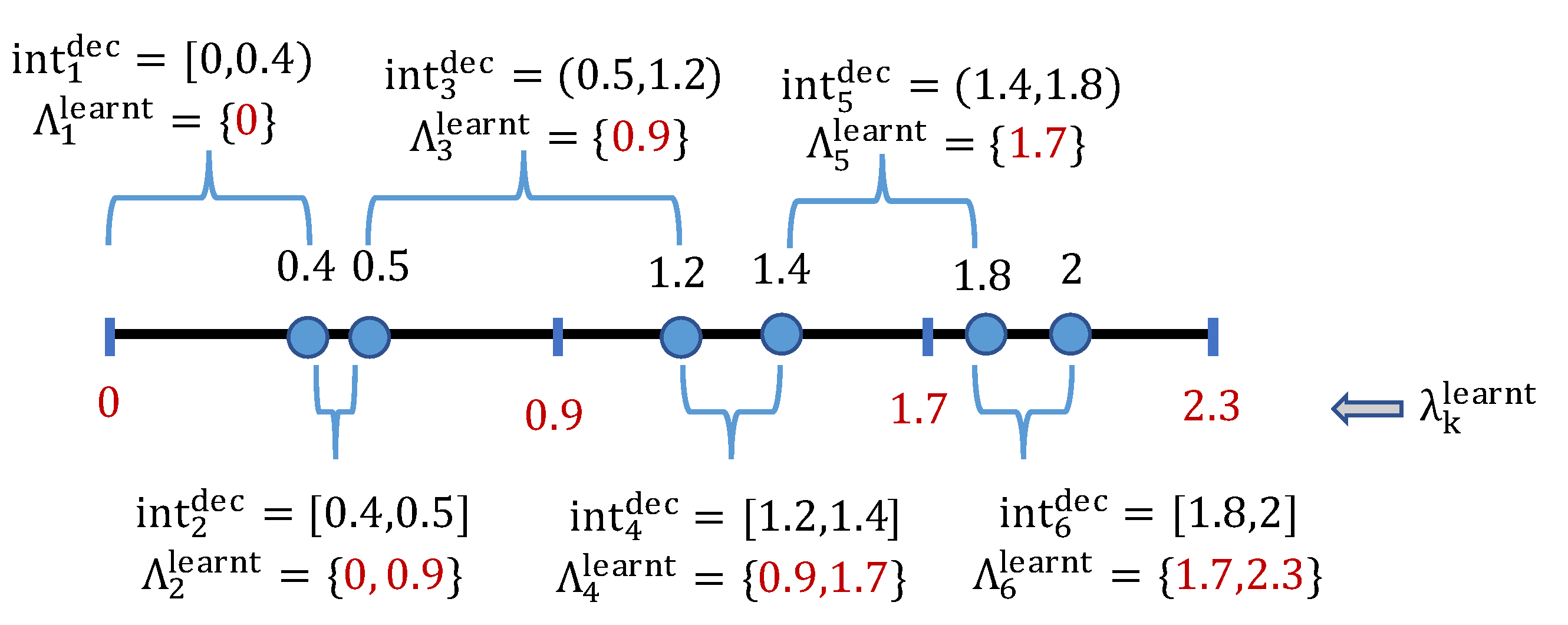
Lemma 1 (Decomposability of deception space). The attacker deception space can be decomposed into a finite number of disjointed sub-intervals, denoted by where and for all and , such that each leads to the same uncertainty set of learning outcomes, denoted by . Furthermore, these sub-intervals and uncertainty sets can be found in a polynomial time.
The proof of Lemma 1 is derived based on Lemmas 2 and 3. An example of the deception-space decomposition is illustrated in
Figure 1. Intuitively, although the deception space
is infinite, the total number of possible learning-outcome uncertainty sets is at most
(i.e., the number of subsets of the discrete learning space
). Therefore, the deception space can be divided into a finite number of disjoint subsets such that any deception value
within each subset will lead to the same uncertainty set. Moreover, each of these deception subsets form a sub-interval of
, which is derived from Lemma 2:
Lemma 2. Given two deception values , if the learning uncertainty sets corresponding to these two values are the same, i.e., , then for any deception value , its uncertainty set is also the same, that is: The remaining analysis for Lemma 1 is to show that these deception sub-intervals can be found in polynomial time, which is obtained based on Lemma 3:
Lemma 3. For each learning outcome , there are at most two deception sub-intervals such that is the smallest learning outcome in the corresponding learning uncertainty set. As a result, the total number of deception sub-intervals is , which is polynomial.
Since there is a number of deception sub-intervals, we now can develop a polynomial-time algorithm (Algorithm 1) which iteratively divides the deceptive range into multiple intervals, denoted by . Each of these intervals, , corresponds to the same uncertainty set of possible learning outcomes for the defender, denoted by .
In this algorithm, for each
, we denote by
and
the smallest and largest possible values of
so that
belongs to the uncertainty set of
. In Algorithm 1,
is the variable which represents the left bound of each interval
. The variable
indicates if
is left-open (
) or not (
). If
is known for
, the uncertainty set
can be determined as follows:
Initially,
is set to 0 which is the lowest possible value of
such that the uncertainty range
contains
and
. Given
and its uncertainty range
, the first interval
of
corresponds to the uncertainty set determined as follows:
At each iteration
j, given the left bound
and the uncertainty set
of the interval
, Algorithm 1 determines the right bound of
, the left bound of the next interval
(by updating
), and the uncertainty set
, (lines (6–15)). Finally, we prove the correctness of Algorithm 1 by presenting Proposition 1, which shows that for any
within each interval
, the corresponding uncertainty interval
covers the same uncertainty set
.
| Algorithm 1: Imitative behavior deception—Decomposition of QR parameter domain into sub-intervals |
![Games 13 00081 i001]() |
Proposition 1 (Correctness of Algorithm 1).
Each iteration j of Algorithm 1 returns an interval such that each leads to the same uncertainty set: The rest of this section will provide details of missing proofs for the aforementioned theoretical results.
Proof of Lemma 2.
For any
, we have:
Since
, we obtain:
which implies
. As a result,
On the other hand, let us consider a
, or equivalently,
. We are going to show that this
as well. Indeed, let us assume
. It means the following inequalities must hold true:
which means that the uncertainty ranges with respect to
and
are not overlapped, i.e.,
, or equivalently,
, which is contradictory.
Therefore,
, meaning that:
The combination of (*) and (**) concludes our proof. □
Proof of Lemma 3.
First, although the deception space is infinite, the total number of possible learning-outcome uncertainty sets is at most (i.e., the number of subsets of the discrete learning space ). Therefore, the deception space can be divided into a finite number of disjoint subsets such that any deception value within each subset will lead to the same uncertainty set. Moreover, each of these deception subsets form a sub-interval of , which is a result of Lemma 2.
Now, in order to prove that the number of disjoint sub-intervals is
, we will show that for each learning outcome
, there are at most two deception sub-intervals such that
is the smallest learning outcome in the corresponding learning uncertainty set. Let us assume there is a deception sub-interval
which leads to an uncertainty set
for some
. We will prove that the following inequalities must hold:
where
is the discretization step size. Indeed, for any
, we have:
Therefore,
which concludes (
4). Now, according to (
4), for every
k, then
or
, which means that there are at most two deception sub-intervals such that
is the smallest learning outcome in their learning uncertainty sets. □
Proof of Proposition 1. Note that, for each , we denote by and the smallest and largest possible values of so that belongs to the uncertainty set of . In addition, and are the indices of the smallest and largest learning outcomes in the learnt uncertainty set for every deception value in the deception interval.
At each iteration j, given the learnt uncertainty set, Algorithm 1 attempts to find the corresponding deception interval as well as the next learnt uncertainty set. Essentially, Algorithm 1 considers two cases:
Case 1: and . This is when (i) the deception interval does not cover the maximum possible learning outcome ; and (ii) the smallest deception value w.r.t the learning outcome is less than the largest deception value w.rt the learning outcome . Intuitively, (ii) implies that the upper bound of the deception interval is strictly less than . Otherwise, this deception upper bound will correspond to an uncertainty set which covers the learning outcome , which is contradict to the fact that (which is strictly less that ) is the maximum learning outcome for the deception interval.
In this case, the interval
is determined as follows:
Note that, since
is the uncertainty set of
with the smallest and largest indices of (
), we have:
and
. Therefore, for any
, we obtain:
which means
and
belongs to the uncertainty set of
while
and
do not. Thus,
is the uncertainty set of
. Since
is open-right, the left bound of
is
and
, and
is determined accordingly.
In this case, deception interval
is determined as follows:
The argument for this case is similar. For the sake of analysis, since
which is the largest index of
in the entire set
, we set
. For any
, we have:
which implies
is the uncertainty set of
. Since
is closed-right, the left bound of
is
and
, concluding our proof. □
4.1.2. Divide and Conquer: (Divide ) into a Polynomial Sub-Problems
Lemma 4 (Divide-and-conquer). The problem () can be decomposed into sub-problems according to the decomposibility of the deception space. Each of these sub-problems can be solved in polynomial time.
Indeed, we can now divide the problem (
) into multiple sub-problems which correspond to the decomposition of the deception space (Lemma 1). Essentially, each sub-problem optimizes
(and
) over the deception sub-interval
(and its corresponding uncertainty set
), as shown in the following:
which maximizes the attacker’s worst-case utility w.r.t uncertainty set
. Note that the defender strategies
can be pre-computed for every outcome
. Each sub-problem
has a constant number of constraints, but still remain non-convex. Our Lemma 5 shows that despite of the non-convexity, the optimal solution for
is actually straightforward to compute.
Lemma 5. The optimal solution of for each sub-problem, , is the (right) upper limit of the corresponding deception sub-interval .
This observation is derived based on the fact that the attacker’s utility,
, is an increasing function of
[
4]. Therefore, in order to solve (
), we only need to iterate over right bounds of
and select the best
j such that the attacker’s worst-case utility (i.e., the objective of
), is the highest among all sub-intervals. Since there are
sub-problems, (
) can be solved optimally in a polynomial time, concluding our proof for Theorem 1.
4.2. Solution Quality Analysis
We now focus on analyzing the solution quality of our method presented in
Section 4.1 to approximately solve the deception problem
. Intuitively, let us denote by
the optimal solution of
and
is the corresponding worst-case utility of the attacker under the uncertainty of learning outcomes in
. We also denote by
the optimal solution of (
). Then, Theorem 2 states that:
Theorem 2. For any arbitrary , there always exists a discretization step size such that the optimal solution of the corresponding () is ϵ-optimal for .
Proof. Let us denote by
the optimal solution of
. Then the worst-case utility of the attacker is determined as follows:
On the other hand, let us denote by
the optimal solution of
. Then the discretized worst-case utility of the attacker is determined as follows:
Note that,
is not the actual worst-case utility of the attacker for mimicking
since it is computed based on the discrete uncertainty set, rather than the original continuous uncertainty set. In fact, the actual attacker worst-case utility is
. We will show that for any
, there exists a discretization step size
such that:
Observe that the first inequality is easily obtained since
the optimal solution of
. Therefore, we will focus on the second inequality. First, we obtain the following inequalities:
The first inequality is obtained based on the fact that the discretized uncertainty set is a subset of the actual continuous uncertainty range
. The second inequality is derived from the fact that
is the optimal solution of
. Therefore, in order to obtain the second inequality of (
5), we are going to prove that for any
, there exists
such that:
Let us denote by
the worst-case learning outcome with respect to
within the uncertainty range
. That is,
Since
is a discretization of
, there exist a
such that
. Now, according to the definition of the discretized worst-case utility of the attacker, we have:
Therefore, proving (
6) now induces to proving
:
where
. First, according to [
23], for any
, the defender’s corresponding optimal strategy
is a differentiable function of
. Second, the attacker’s utility
is a differentiable function of the defender’s strategy
for any
. Therefore,
is differentiable (and thus continuous) at
. According to the continuity property, for any
, there always exists
such that:
for all
such that
, concluding our proof. □
4.3. Heuristic to Improve Discretization
According to Theorem 2, we can obtain a high-quality solution for by having a fine discretization of the learning outcome space with a small step size . In practice, it is not necessary to have a fine discretization over the entire learning space right from the begining. Instead, we can start with a coarse discretization and solve the corresponding () to obtain a solution of . We then refine the discretization only within the uncertainty range of the current solution, . We keep doing that until the uncertainty range of the latest deception solution reaches the step-size limit which guarantees the -optimality. Practically, by doing so, we will obtain a much smaller discretized learning outcome set (aka. smaller K). As a result, the computational time for solving () is substantially faster while the solution quality remains the same.
5. Defender Counter-Deception
In order to counter the attacker’s imitative deception, we propose to find a counter-deception defense function
which maps a learnt parameter
to a strategy
of the defender. In designing an effective
, we need to take into account that the attacker will also adapt its deception choice accordingly, denoted by
. Essentially, the problem of finding an optimal defense function which maximizes the defender’s utility against the attacker’s deception can be abstractly represented as follows:
where
is the deception choice of the attacker with respect to the defense function
and
is the defender’s utility corresponding to
. Finding an optimal
is challenging since the domain
of
is continuous and there is no explicit closed-form expression of
as a function of
. For the sake of our analysis, we divide the entire domain
into a number of sub-intervals
where
,
, &,
with
, and
N is the number of sub-intervals. We define a defense function with respect to the interval set:
which maps each interval
to a single defense strategy
, i.e.,
, for all
. We denote the set of these strategies by
. Intuitively, all
will lead to a single strategy
. Our counter-deception problem now becomes finding an optimal defense function
that comprises of (i) an optimal interval set
; and (ii) corresponding defense strategies determined by the defense function
with respect to
, taking into account the attacker’s deception adaptation. Essentially, (
) is the optimal solution of the following optimization problem:
where
is the maximin deception choice of the attacker. Here,
is the
uncertainty set of the attacker when playing
. This uncertainty set contains all possible defense strategy outcomes with respect to the deceptive value
.
Main Result. To date, we have not explicitly defined the objective function, , except that we know this utility depends on the defense function and the attacker’s deception response . Now, since maps each possible learning outcome to a defense strategy, we know that if , then , which can be computed using Equation (3). However, due to the deviation of from the attacker’s deception choice, , different possible learning outcomes within may belong to different intervals (which correspond to different strategies ), leading to different utility outcomes for the defender. One may argue that to cope with this deception-learning uncertainty, we can apply the maximin approach to determine the defender’s worst-case utility if the defender only has the common knowledge that . Furthermore, perhaps, depending on any additional (private) knowledge the defender has regarding the relation between the attacker’s deception and the actual learning outcome of the defender, we can incorporate such knowledge into our model and algorithm to obtain an even better utility outcome for the defender. Interestingly, we show that there is, in fact, a universal optimal defense function for the defender, , regardless of any additional knowledge that he may have. That is, the defender obtains the highest utility by following this defense function, and additional knowledge besides the common knowledge cannot make the defender do better. Our main result is formally stated in Theorem 3.
Theorem 3. There is a universal optimal defense function, regardless of any additional information (besides the common knowledge) he has about the relation between their learning outcome and the deception choice of the attacker. Formally, let us consider the following optimization problem: Denote by an optimal solution of , then an optimal solution of (7), can be determined as follows: If , choose the interval set with covering the entire learning space, and function where .
If , choose the interval set with , . In addition, choose the defender strategies and correspondingly.
The attacker’s optimal deception against this defense function is to mimic . As a result, the defender always obtains the highest utility, , while the attacker receives the maximin utility of .
Example 1. Let us give a concrete example illustrating the result in Theorem 3. Considering a 3-target security game with the following payoff matrix shown in Table 1: In this game, the defender has 1 security resource. The maximum deception value of the attacker is and the uncertainty level . By solving , we obtain a corresponding defender strategy and the attacker behavior parameter . Since , the optimal counter-deception defense function is as follows:
If the defender learns , the defender will play a strategy .
Otherwise, if the defender learns , the defender then plays .
Given the defender follows this counter-deception function, the attacker’s optimal deception is to mimic , meaning the attacker just simply attacks each target uniformly at random. Here is the reason why this is the optimal choice for the attacker:
If the attacker chooses , the corresponding learning outcome for the defender can be any value within the range . According to the defense function, the defender will always play the strategy . As a result, the attacker’s expected utility is .
Now, if the attacker chooses , the corresponding learning outcome for the defender may fall into either or . In particular, if the learning outcome , it means the defender plays . In this case, the resulting attacker utility is (this inequality is due to the fact that the attacker utility is an increasing function of ). As a result, the worst-case utility of the attacker is no more than which is strictly lower than the utility of when the attacker mimics .
Corollary 1. When , the defense function (specified in Theorem 3) gives the defender a utility which is no less than their Strong Stackelberg equilbrium (SSE) utility.
The proof of Corollary 1 is straightforward. Since is a feasible solution of (), the optimal utility of the defender is thus no less than ( denotes the defender’s SSE strategy).
Now the rest of this section will be devoted to prove Theorem 3. The full proof of Theorem 3 can be decomposed into three main parts: (i) We first analyze the attacker deception adapted to the defender’s counter deception; (ii) Based on the result of the attacker adaptation, we provide theoretical results on computing the defender optimal defense function given a fixed set of sub-intervals ; and (iii) Finally, we complete the proof of the theorem leveraging the result in (ii).
5.1. Analyzing Attacker Deception Adaptation
In this section, we aim at understanding the behavior of the attacker deception against
. Overall, as discussed in the previous section, since the attacker is uncertain about the actual learning outcome of the defender, the attacker can attempt to find an optimal deception choice
that maximizes its utility under the worst case of uncertainty. Essentially,
is an optimal solution of the following maximin problem:
where:
is the
uncertainty set of the attacker with respect to the defender’s sub-intervals
. In this problem, the uncertainty set
depends on
that we need to optimize, making this problem challenging to solve.
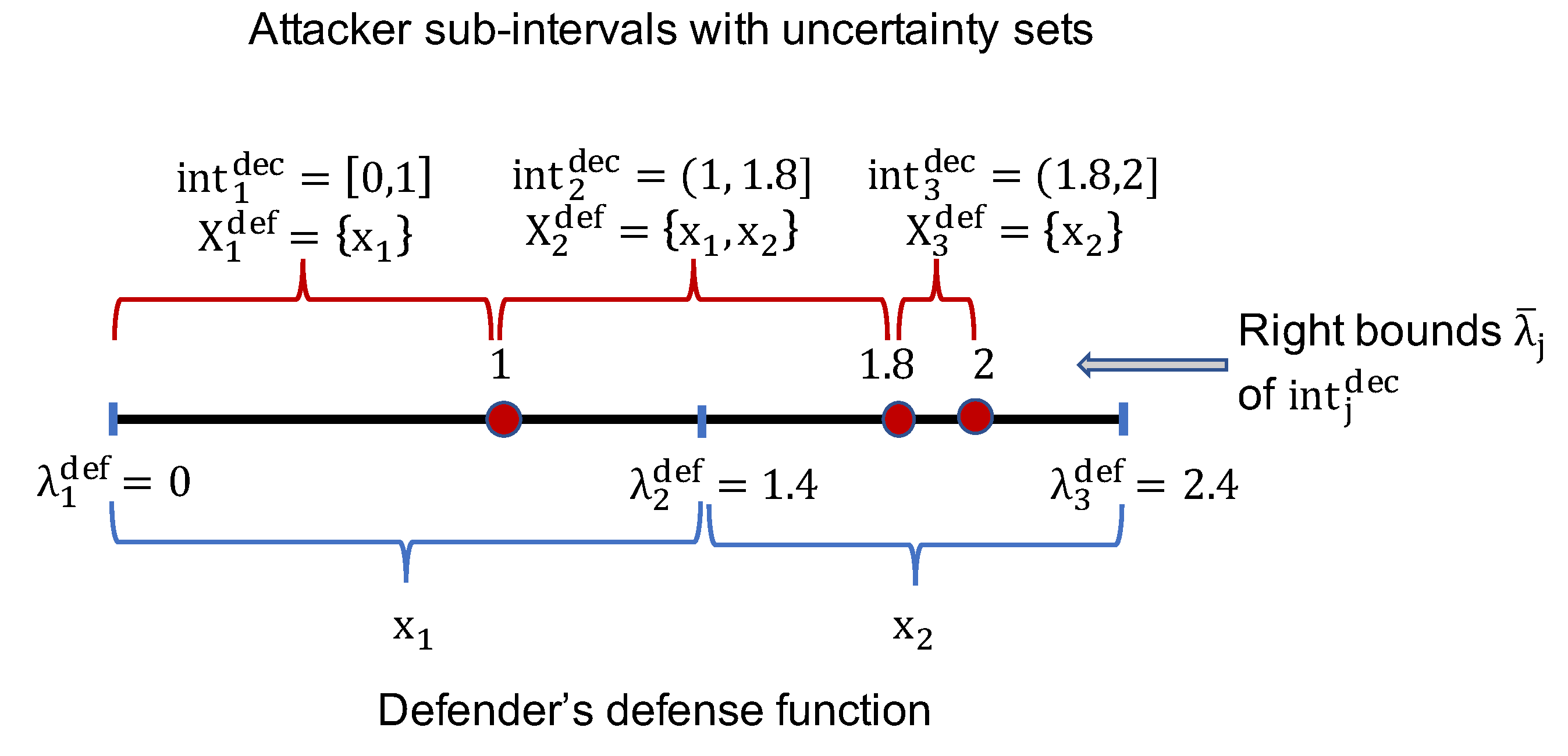
5.1.1. Decomposability of Attacker Deception Space
First, given
, we show that we can divide the range of
into several intervals, each interval corresponds to the same uncertainty set. This characteristic of the attacker uncertainty set is, in fact, similar to the no-counter-deception scenario as described in previous section. We propose Algorithm 2 to determine these intervals of
, which works in a similar fashion as Algorithm 1. The main difference is that in the presence of the defender’s defense function, the attacker’s uncertainty set
is determined based on whether the uncertainty range of the attacker
is overlapped with the defender’s intervals
or not.
| Algorithm 2: Counter-deception—Decomposition of QR parameter into sub-intervals |
![Games 13 00081 i002]() |
Essentially, similar to Algorithm 1, Algorithm 2 also iteratively divides the range of into multiple intervals, (with an abuse of notation) denoted by . Each of these intervals, , corresponds to the same uncertainty set of , denoted by . In this algorithm, for each interval of the defender , and represent the smallest and largest possible deceptive values of so that . In addition, and denote the smallest and largest indices of the defender’s strategies in the set that belongs to . Algorithm 2 relies on Lemma 6 and 7. Note that Algorithm 2 does not check if each interval of is left-open or not since all intervals of the defender is left-open (except for ), making all left-closed (except for ).
Lemma 6. Given a deceptive , for any such that , then for any .
Lemma 7. For any such that 2, the uncertainty range of overlaps with the defender’s interval , i.e., , or equivalently, . Otherwise, if or , then . The proofs of these two lemmas are straightforward so we omit them for the sake of presentation. Essentially, this algorithm divides the range of
into multiple intervals, (with an abuse of notation) denoted by
. Each of these intervals,
, corresponds to the same uncertainty set of
, denoted by
. An example of decomposing the deceptive range of
is shown in
Figure 2.
5.1.2. Characteristics of Attacker Optimal Deception
We denote by
M the number of attacker intervals. Given the division of the attacker’s deception range
, we can divide the problem of attacker deception into
M sub-problems. Each corresponds to a particular
where
, as follows:
Lemma 8. For each sub-problem () with respect to the deception sub-interval , the attacker optimal deception is to imitate the right-bound of , denoted by .
The proof of Lemma 8 is derived based on the fact that the attacker’s utility is increasing in . As a result, the attacker only has to search over the right bounds, , of all intervals to find the best one among the sub-problems that maximizes the attacker’s worst-case utility. We consider these bounds to be the deception candidates of the attacker. Let us assume is the best deception choice for the attacker among these candidates, that is, the attacker will mimic the . We obtain the following observations about important properties of the attacker’s optimal deception, which we leverage to determine an optimal defense function later.
Our following Lemma 9 says that any non-optimal deception candidate for the attacker, , such that the max index of the defender strategy in the corresponding uncertainty set , denoted by , satisfies , then the deception candidate is strictly less than , or equivalently, . Otherwise, cannot be a best deception response.
Lemma 9. For any s.t. , then , or equivalently, .
Proof. Lemma 9 can be proved by contradiction as follows. Let us assume if there is
such that
. According to Algorithm 2, for any attacker interval indices
, we have the min and max indices of the defender’s strategies in corresponding uncertainty sets must satisfy:
and
, and they can not be both equal. That is because the intervals
returned by Algorithm 2 are sorted in a strictly increasing order. Therefore, if there is
such that
, it means
and
. In other words, the uncertainty set
. Thus, we have the attacker’s optimal worst-case utility w.r.t deception intervals
j and
must satisfy:
since
is a strictly increasing function of
3. This strict inequality shows that
cannot be an optimal deception for the attacker, concluding our proof for Observation 9.
Note that we denote right bounds of attacker intervals by . Our Lemma 10 then says that if the max index of the defender strategy in the set is equal to the max index of the whole defense set, N, then is equal to the highest value of the entire deception range, i.e., , or equivalently, .
Lemma 10. If , then .
Proof. We also prove this observation using contradiction. Let us assume that
. Again, according to Algorithm 2, for any
, we have
and
, and they can not be both equal. Therefore, if
, then for all
, we have:
and
, which means
. Therefore, if
, then we obtain:
which shows that
cannot be an optimal deception of the attacker, concluding the proof of Lemma 10. □
Remark 1. According to Lemmas 9 and 10, we can easily determine which deception choices among the setcannot be an optimal attacker deception, regardless of defense strategies. These non-optimal choices are determined as follows: the deception choicecan not be optimal for:
For any other choices, there always exists defense strategiessuch thatis an optimal attacker deception.
5.2. Finding Optimal Defense Function Given Fixed I:
Divide-and-Conquer
Given a set of sub-intervals
, we aim at finding optimal defense function
or equivalently, strategies
corresponding to these sub-intervals. According to previous analysis on the attacker’s deception adaptation, since the attacker’s best deception is one of the bounds
, we propose to decompose the problem of finding an optimal defense function
into multiple sub-problems
, each corresponds to a particular best deception choice for the attacker. In particular, for each sub-problem
, we attempt to find
such that
is the best response of the attacker. As discussed in the remark of previous section, we can easily determine which sub-problem
is not feasible. For any
feasible optimal deception candidate
, i.e.,
is feasible,
can be formulated as follows:
where
is the defender’s utility when the defender commits to
and the attacker plays
. The constraints in
guarantee that the attacker’s worst-case utility for playing
is better than playing other
. Finally, our Propositions 2 and 3 determine an optimal solution for (
).
Proposition 2 (Sub-problem ). If , the best defense function for the defender is determined as follows:
For all , choose where is an optimal solution of the following optimization problem: For all , choose where is the optimal solution of the following optimization problem:
By following the above defense function, an optimal deception of the attacker is to mimic , and the defender obtains an utility of .
Proof. First, we show that the attacker optimal deception response is to
. Indeed, we have the uncertainty set
because the defender plays
for all
. In addition, for all
j such that
, the uncertainty set
contains
. Therefore, we have the attacker worst-case utility satisfying:
Furthermore, for all
j such that
, we have
according to Observation 9. Thus, we obtain:
Based on the above defense function and the fact that the attacker will choose
, the defender receives an utility of
. Next, we prove that this is the best the defender can obtain by showing that any defense function
such that
is the attacker’s best response will lead to a defender utility less than
. Indeed, since
, it means
or in other words,
. On the other hand, since
is the best choice of the attacker, the following inequality must hold:
This means that any defense function such that is the attacker’s best response has to satisfy the above inequality. As defined, is the highest utility for the defender among these defense functions that satisfy the above inequality. □
Proposition 3 (Sub-problem
).
If , the best counter-deception of the defender can be determined as follows: for all n, we set: where is an optimal solution ofBy following this defense function, the attacker’s best deception is to mimic and the defender obtains an utility of .
Proof. First, we observe that given
,
is the best response of the attacker. Indeed, since
or equivalently
according to Observation 10, we have:
Second, since
, then for any defense function such that
is the best deception choice of the attacker, the resulting utility for the defender must be no more than:
regardless of the learning outcome
. This is because the defender eventually plays one of the defense strategies in the set
. The RHS is the defender’s utility obtained by playing the counter-deception specified by the proposition. □
Based on Propositions 2 and 3, we can easily find the optimal counter-deception by choosing the solution of the sub-problem that provides the highest defender utility.
5.3. Completing the Proof of Theorem 3
According to Propositions 2 and 3, given an interval set , the resulting defense function will only lead the defender to play either or , whichever provides a higher utility for the defender. Based on this result, our Theorem 3 then identifies an optimal interval set, and corresponding optimal defense strategies, as we prove below.
First, we will show that if the defender follows the defense function specified in Theorem 3, then the attacker’s optimal deception is to mimic . Indeed, if , then since the defender always plays , the attacker’s optimal deception is to play to obtain a highest utility .
On the other hand, if , we consider two cases:
Case 1, if
, then the intervals of the attackers are
and
. The corresponding uncertainty sets are
and
. In this case, the attacker’s optimal deception is to mimic
, since:
Case 2, if
, then the corresponding intervals for the attacker are
,
, and
. These intervals of the attacker have uncertainty sets
,
, and
, respectively. The attacker’s best deception is thus to mimic
, since the attacker’s worst-case utility is
, and
Now, since the attacker’s best deception is to mimic , according to the above analysis, the uncertainty set is , thus the defender will play in the end, leading to an utility of . This is the highest possible utility that the defender can obtain since both optimization problems presented in Propositions 2 and 3 are special cases of () when we fix the variable (for Proposition 3) or (for Proposition 2).
6. Experimental Evaluation
Our experiments are run on a 2.8 GHz Intel Xeon processor with 256 GB RAM. We use
(
https://www.mathworks.com, accessed on 1 October 2022) to solve non-linear programs and
(
https://www.ibm.com/analytics/cplex-optimizer, accessed on 1 October 2022) to solve
s involved in the evaluated algorithms. We use a value of
in all our experiments (except in
Figure 3g,h), and discretize the range
using a step size of
:
. We use the covariance game generator,
(
http://gamut.stanford/edu, accessed on 1 October 2022) to generate rewards and penalties of players within the range of
(for attacker) and
(for defender). GAMUT takes as input a covariance value
which controls the correlations between the defender and the attacker’s payoff. Our results are averaged over 50 runs. All our results are statistically significant under bootstrap-t (
).
Algorithms. We compare three cases: (i)
: the attacker is non deceptive and the defender also assumes so. As a result, both play Strong Stackelberg equilibrium strategies; (ii)
: the attacker is deceptive, while the defender does not handle the attacker’s deception (
Section 4). We examine different uncertainty ranges by varying values of
; and (iii)
: the attacker is deceptive while the defender tackle the attacker’s deception (
Section 5).
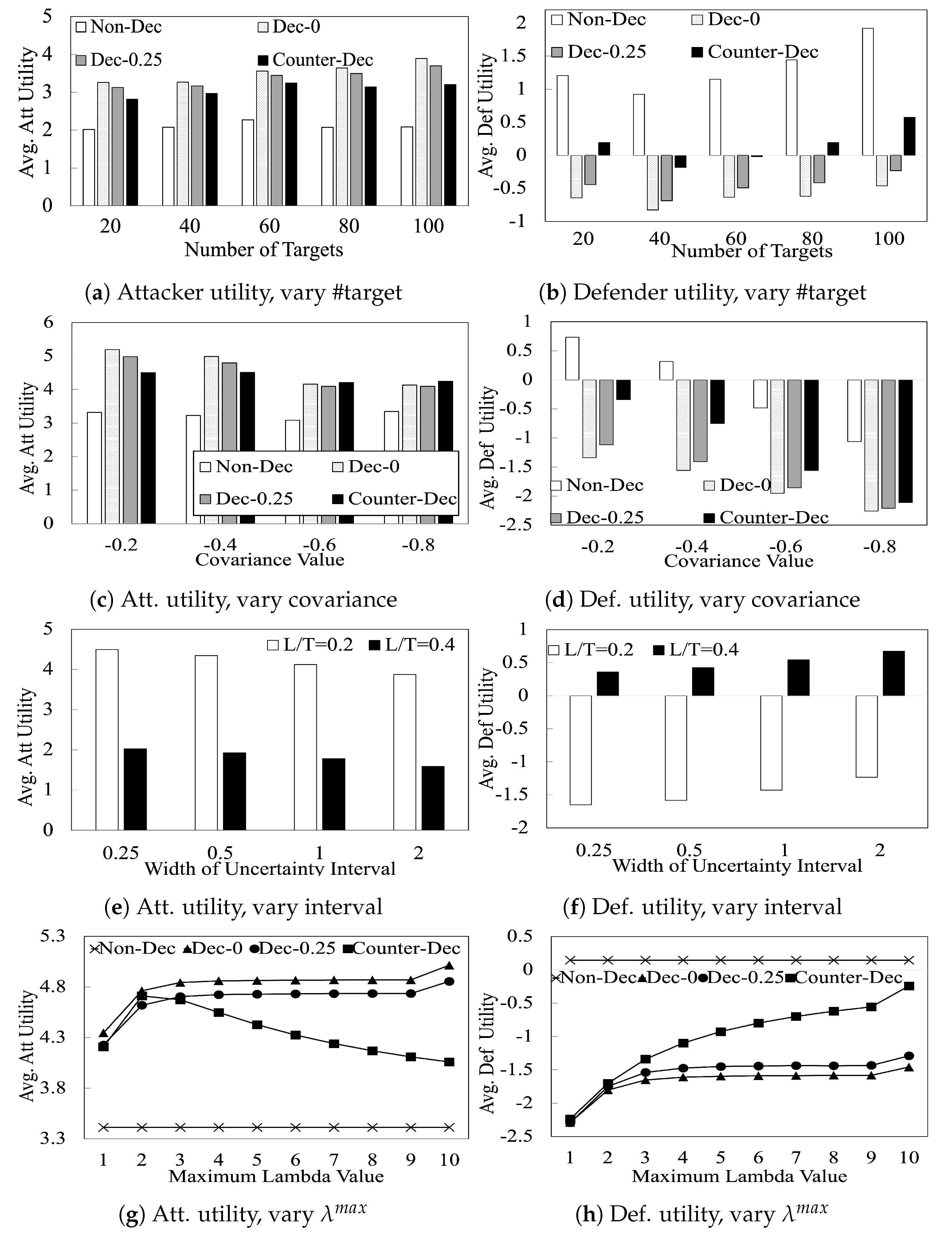
Figure 3a,b compare the performance of our algorithms with increasing number of targets. These figures show that (i) the attacker benefits by playing deceptively (
achieves 61% higher attacker utility than
); (ii) the benefit of deception to the attacker is reduced when the attacker is uncertain about the defender’s learning outcome. In particular,
achieves 4% lesser attacker utility than
; (iii) the defender suffers a substantial utility loss due to the attacker’s deception and this utility loss is reduced in the presence of the attacker’s uncertainty; and finally, (iv) the defender benefits significantly (in their utility) by employing counter-deception against a deceptive attacker.
In
Figure 3c,d, we show the performance of our algorithms with varying
r (i.e., covariance) values. In zero-sum games (i.e.,
), the attacker has no incentive to be deceptive [
4]. Therefore, we only plot the results of
with a step size of
. This figure shows that when
r gets closer to
(which implies zero-sum behavior), the attacker’s utility with deception (i.e.,
and
) gradually moves closer to its utility with
, reflecting that the attacker has less incentive to play deceptively. Furthermore, the defender’s average utility in all cases gradually decreases when the covariance value gets closer to
. This results show that in
s, the defender’s utility is always governed by the
adversarial level (i.e., the payoff correlations) between the players, regardless of whether the attacker is deceptive or not.
Figure 3e,f compare the attacker and defender utilities with varying uncertainty range, i.e.,
values, on 60-target games. These figures show that attacker utilities decrease linearly with increasing values of
. On the other hand, defender utilities increase linearly with increasing values of
. This is reasonable as increasing
corresponds to a greater width of the uncertainty interval that the attacker has to contend with. This increased uncertainty forces the attacker to play more conservatively, thereby leading to decreased utilities for the attacker and increased utilities for the defender.
In
Figure 3g,h, we analyze the impact of varying
on the players’ utilities in 60-target games. These figures show that (i) with increasing values of
, the action space of a deceptive attacker increases, hence, the attacker utility increases as a result (
,
in both sub-figures); (ii) When this
is close to zero, the attacker is limited to a less-strategic-attack zone and thus the defender’s strategies have less influence on how the attacker would response. The defender thus receives a lower utility when
gets close to zero; and (iii) most importantly, the attacker utility against a counter-deceptive defender decreases with increasing values of
. This result shows that when the defender plays counter-deception, the attacker can actually gain more benefit by committing to a more limited deception range.
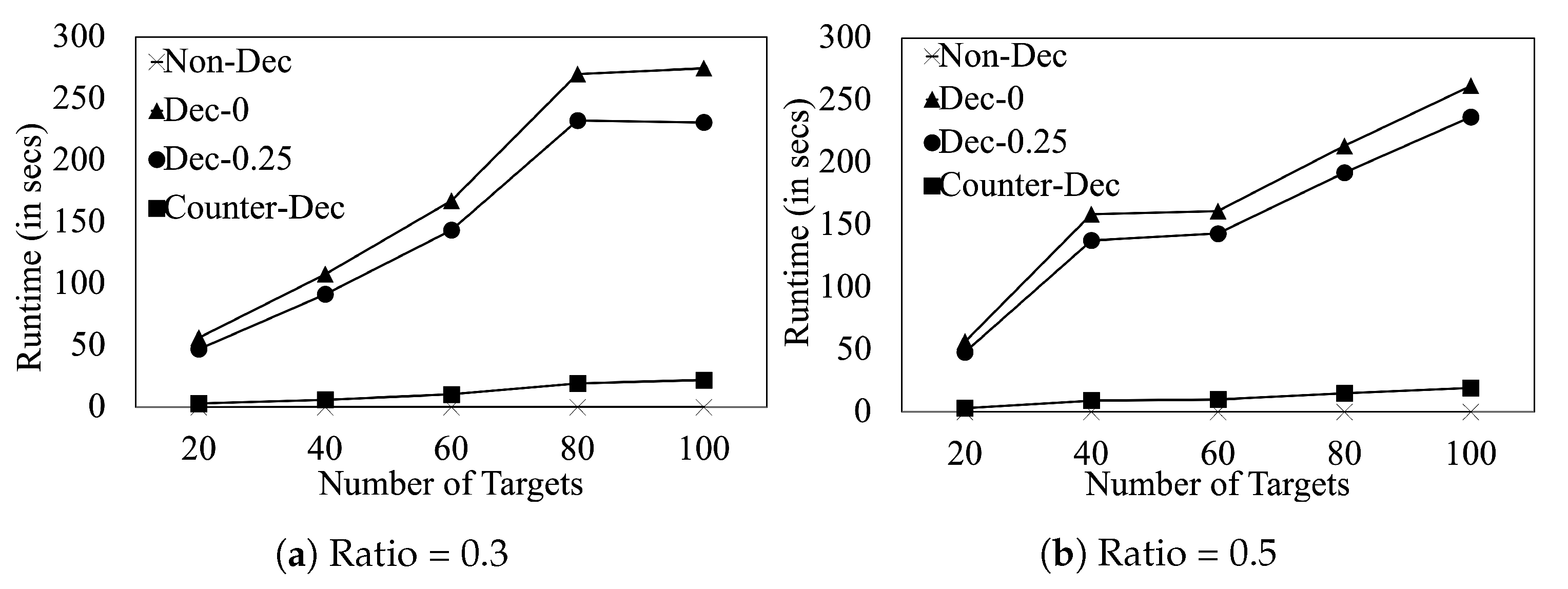
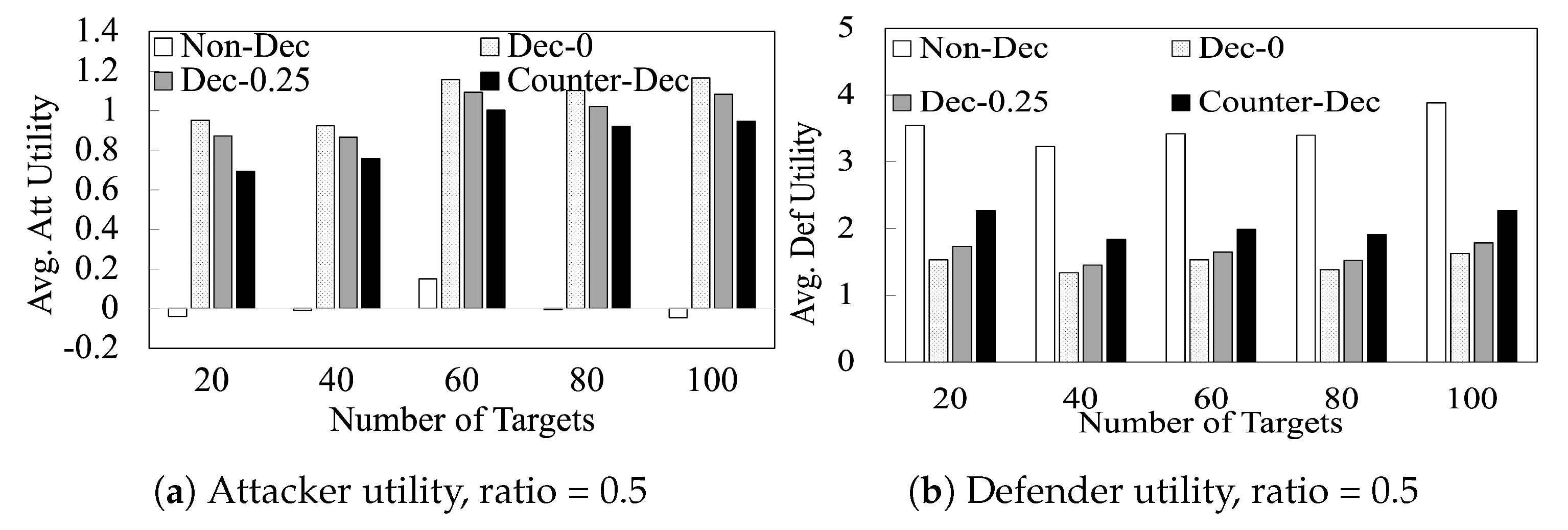
Finally, we evaluate the runtime performance of our algorithms in
Figure 4. We provide results for resource-to-target ratio
and
. This figure shows that (i) even on 100 target games,
finishes in ∼5 min. (ii) Due to the simplicity of the proposed counter-deception algorithm,
finishes in 13 s on 100 target games.
Additional Experiment Results
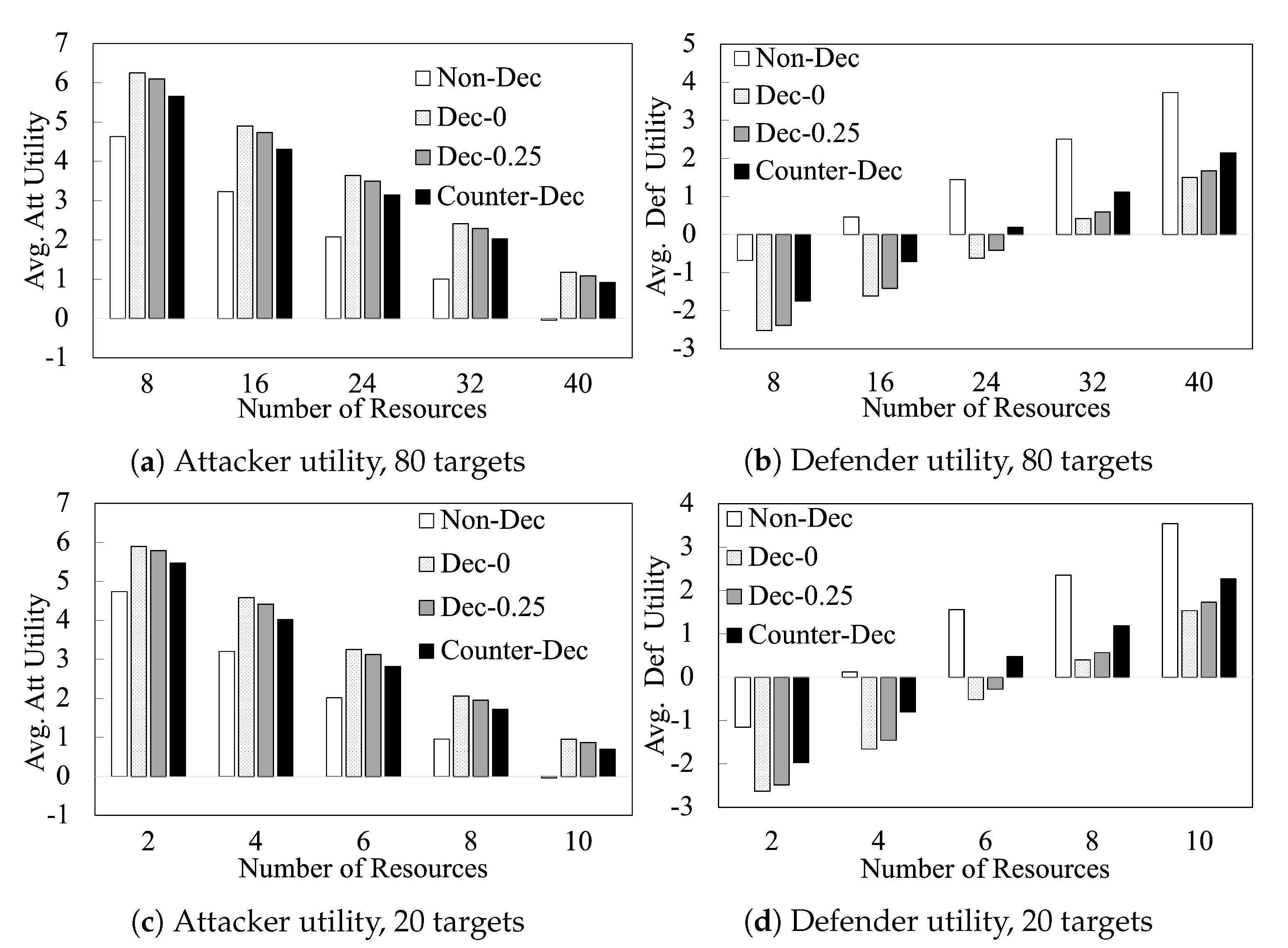
Figure 5 shows the performance of our algorithms as we vary the number of resources
L on 80-target games and 20-target games. This figure shows that the benefits of deception and counter-deception to the players are observed consistently when varying
L. It shows that (i) the defender (attacker) utilities steadily increase (decrease) with increasing
L; and (ii) the trends observed between the different algorithms in
Figure 5 are observed consistently at different values of
L. In
Figure 6, we compare different algorithms with increasing number of targets when
. We observe similar trends in these additional results.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}