

A Low-Cost Deep-Learning-Based System for Grading Cashew Nuts
 , ,
, ,  , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. A System for Grading Cashew Nuts
2.1.1. A Framework
2.1.2. Classification Model
2.1.3. Grading Actuation
2.2. Data Collection for Building an Efficient Classification Model
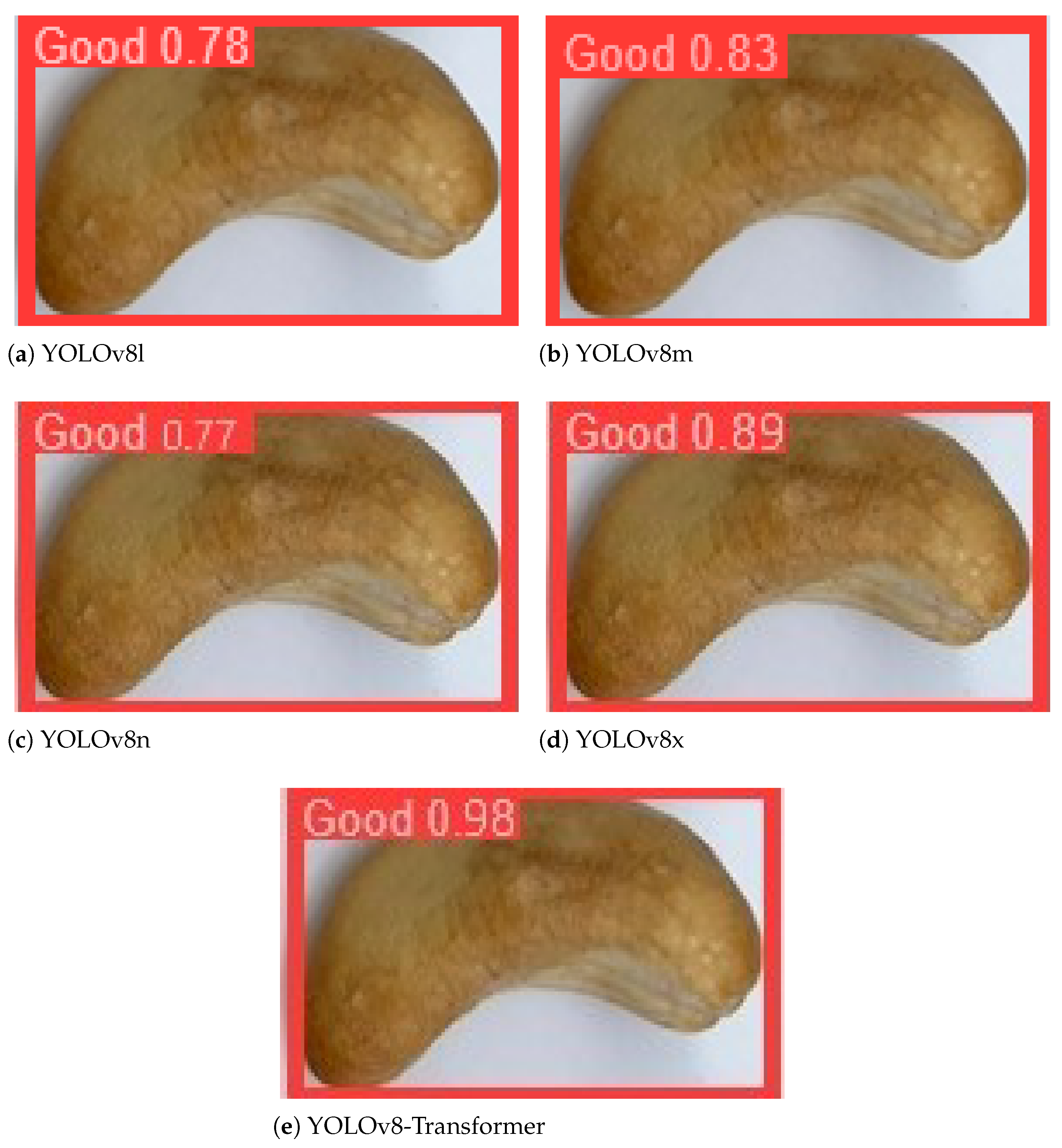
- The “good” grade includes the products that are white/light ivory in color, not cracked or broken, and fully peeled, as shown in Figure 5a.
- The “error 1” grade includes the products that are partly cracked or broken at the edges, as illustrated in Figure 5b.
- The “error 2” grade includes the products that are not fully peeled, as depicted in Figure 5c.
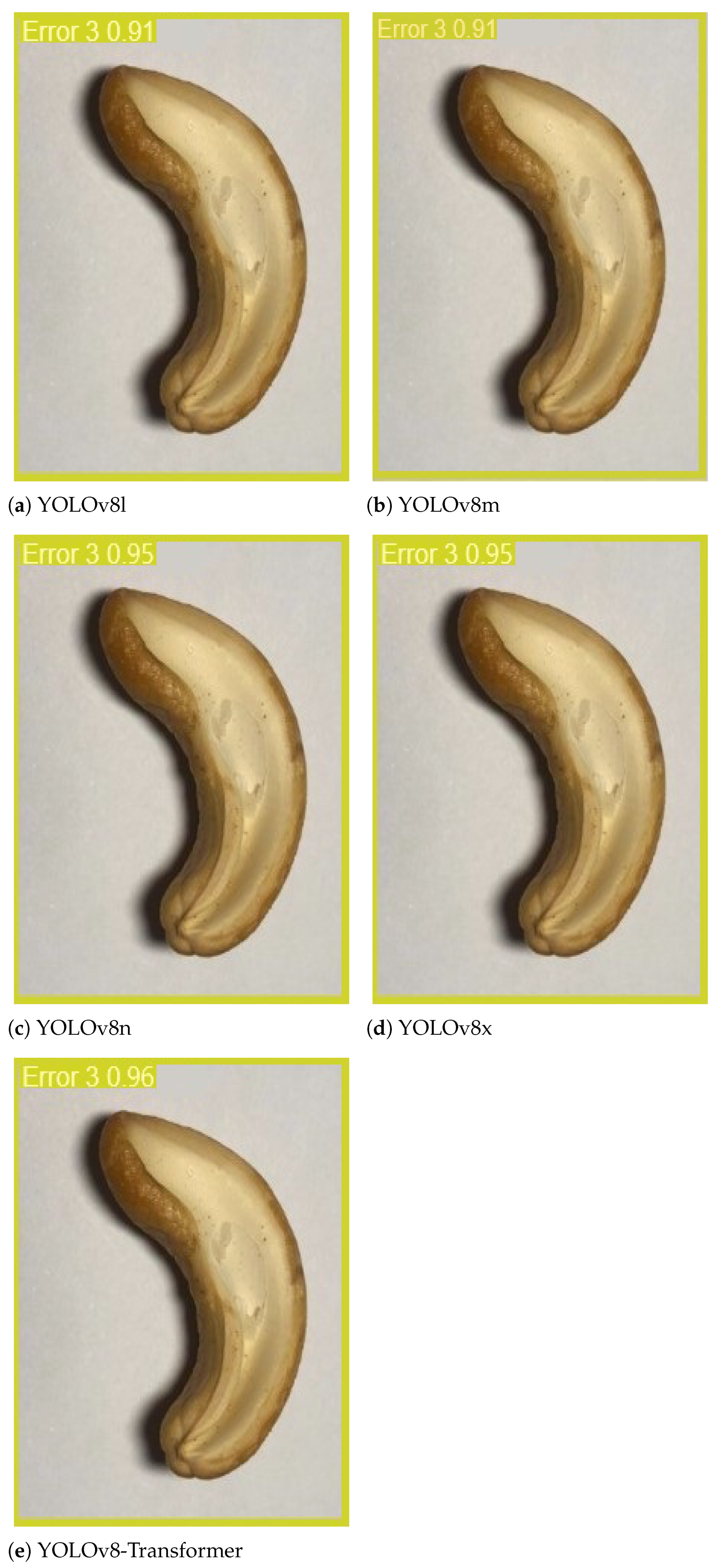
- The “error 3” grade includes the products that are almost half cracked or broken, as demonstrated in Figure 5d.
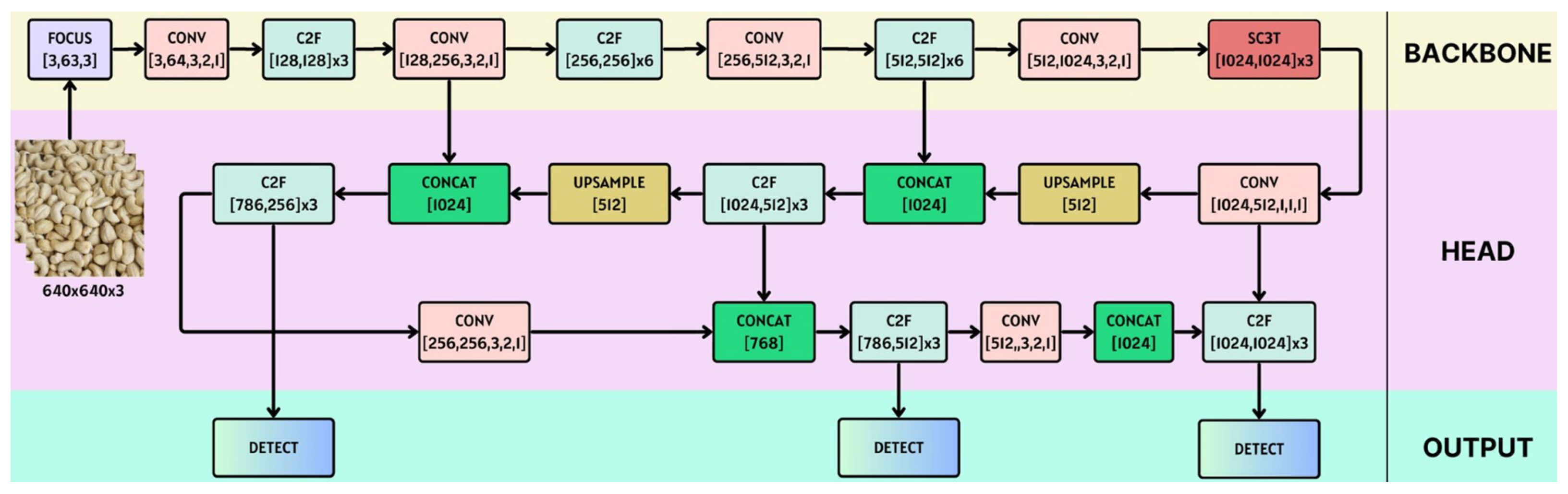
2.3. An Efficient YOLOv8- and Transformer-Based Classification
3. Results and Discussions
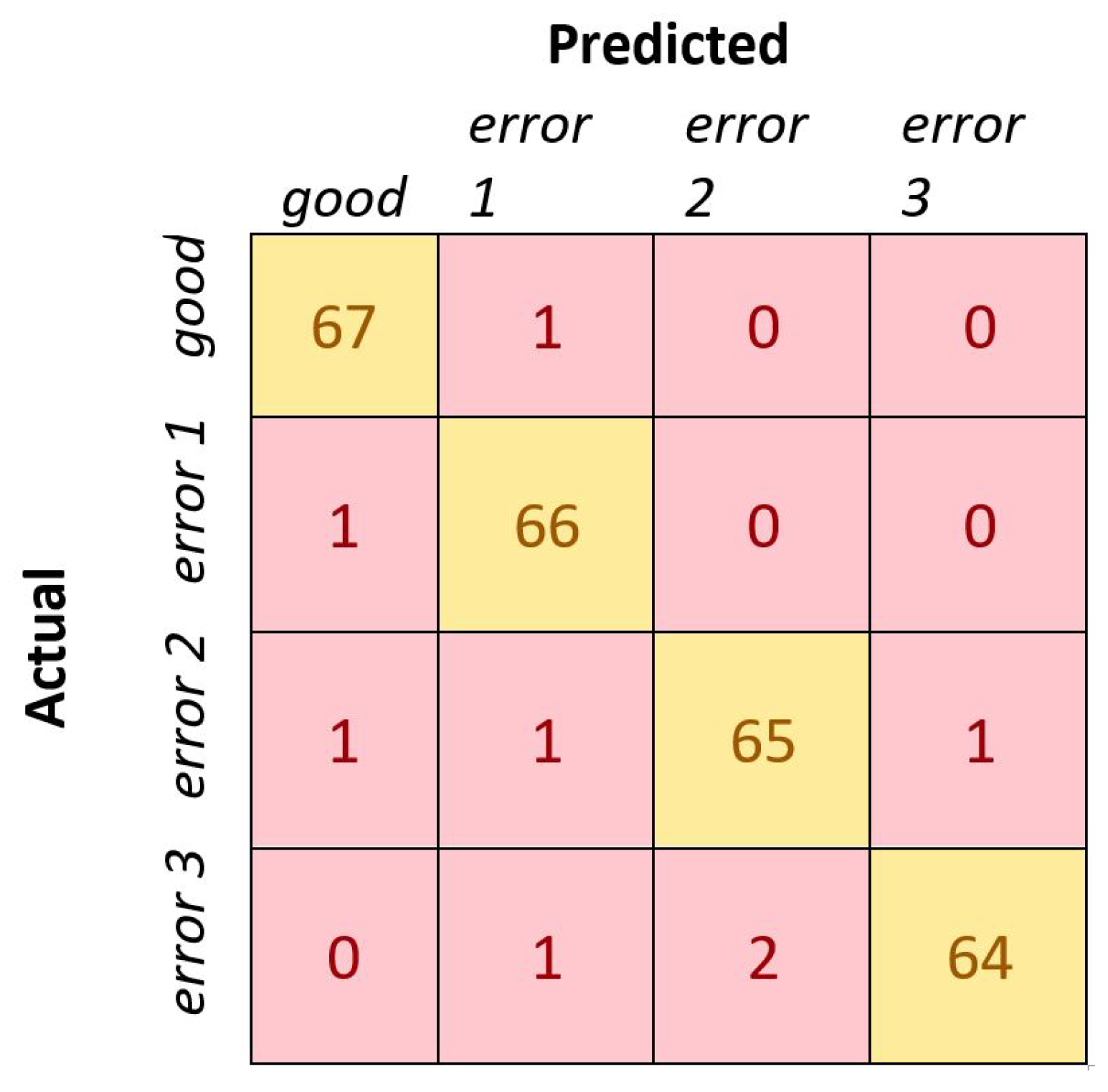
3.1. Metrics for Performance Evaluation in Classification
3.2. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| RGB | Red, green, blue |
| CBS | Conv + BatchNorm + SiLU |
| CPU | Central processing unit |
| GPU | Graphics processing unit |
| TN | True positive |
| FN | False negative |
| AP | Average precision |
| mAP | Mean average precision |
| ELAN | Efficient layer aggregation network |
| CIoU | Complete intersection over union |
| SPP | Spatial pyramid pooling |
Appendix A. Steps in the Proposed Algorithm
- Building Model Step
- (a)
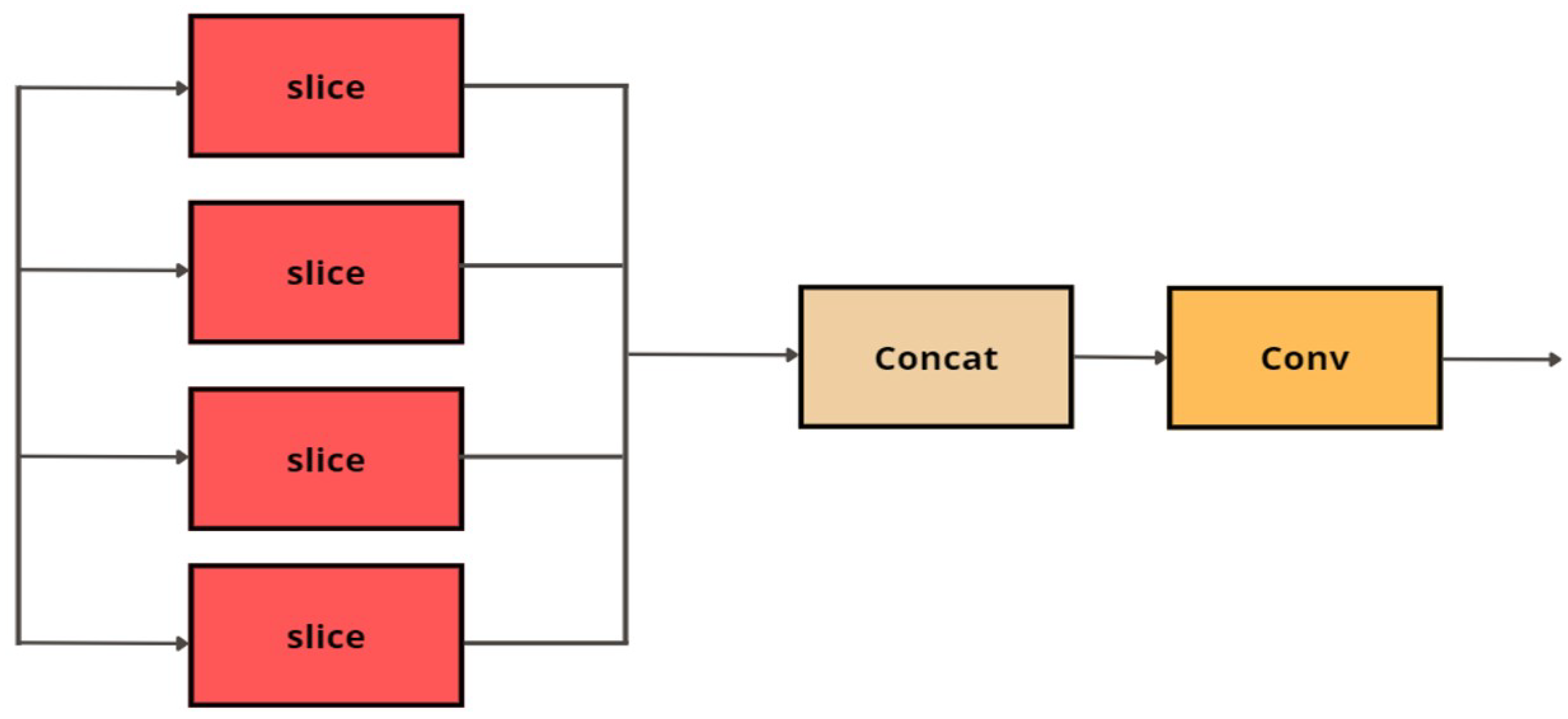
- Construct the SC3T module as presented in Figure 8.
- i.
- Set the spatial pyramid pooling (SPP) block as an input of SC3T.
- ii.
- Set all stride for kernels in the SPP block to 1.
- iii.
- Set the kernels of the SPP block to different sizes of 5 × 5, 9 × 9, and 13 × 13. The setup allows the proposed algorithm to accept any image with different sizes as input.
- iv.
- Connect output of the SPP block to the C3TR block. The Transformer is used to update and concatenate query, key and value vectors to form the global feature information from different subspace for linear projection.
- (b)
- Implement the SC3T module into the the final layer of the backbone network of YOLOv8 as illustrated in Figure 10.
- Training Model Step
- (a)
- Prepare cashew nut image data. Images can be captured by a low-cost camera sensor, which is normally employed in a low-cost agricultural system.
- Label each image with a cashew nut grade.
- (b)
- Implement the model in a training platform such as Python.
- (c)
- Train the model given the dataset on a powerful computer to speed up the training step.
- Implementation Step
- (a)
- Download the trained model.
- (b)
- Implement the trained model on an onboard computer in the cashew nut grading machine.
- (c)
- Input any cashew nut image captured by the camera sensor in the cashew nut grading machine into the trained model for prediction.
References
- Gonçalves, B.; Pinto, T.; Aires, A.; Morais, M.C.; Bacelar, E.; Anjos, R.; Ferreira-Cardoso, J.; Oliveira, I.; Vilela, A.; Cosme, F. Composition of nuts and their potential health benefits—An overview. Foods 2023, 12, 942. [Google Scholar] [CrossRef] [PubMed]
- Alasalvar, C.; Salvadó, J.S.; Ros, E. Bioactives and health benefits of nuts and dried fruits. Food Chem. 2020, 314, 126192. [Google Scholar] [CrossRef] [PubMed]
- Oliveira, N.N.; Mothé, C.G.; Mothé, M.G.; de Oliveira, L.G. Cashew nut and cashew apple: A scientific and technological monitoring worldwide review. J. Food Sci. Technol. 2020, 57, 12–21. [Google Scholar] [CrossRef] [PubMed]
- Berry, A.; Sargent, S. Cashew apple and nut (Anacardium occidentale L.). In Postharvest Biology and Technology of Tropical and Subtropical Fruits; Yahia, E.M., Ed.; Woodhead Publishing Series in Food Science, Technology and Nutrition; Woodhead Publishing: Cambridge, UK, 2011; pp. 414–423e. [Google Scholar] [CrossRef]
- Charlton, D.; Kostandini, G. Can technology compensate for a labor shortage? Effects of 287 (g) immigration policies on the US dairy industry. Am. J. Agric. Econ. 2021, 103, 70–89. [Google Scholar] [CrossRef]
- Nguyen, D.K.; Nguyen, L.; Le, D.V. A Low-Cost Efficient System for Monitoring Microalgae Density using Gaussian Process. IEEE Trans. Instrum. Meas. 2021, 70, 7504308. [Google Scholar] [CrossRef]
- Nguyen, D.K.; Nguyen, H.Q.; Dang, H.T.T.; Nguyen, V.Q.; Nguyen, L. A low-cost system for monitoring pH, dissolved oxygen and algal density in continuous culture of microalgae. HardwareX 2022, 12, e00353. [Google Scholar] [CrossRef]
- Nguyen, L.; Nguyen, D.K.; Nghiem, T.X.; Nguyen, T. Least square and Gaussian process for image based microalgal density estimation. Comput. Electron. Agric. 2022, 193, 106678. [Google Scholar] [CrossRef]
- Arakeri, M.; Lakshmana. Computer Vision Based Fruit Grading System for Quality Evaluation of Tomato in Agriculture industry. Procedia Comput. Sci. 2016, 79, 426–433. [Google Scholar] [CrossRef]
- Yossy, E.H.; Pranata, J.; Wijaya, T.; Hermawan, H.; Budiharto, W. Mango Fruit Sortation System using Neural Network and Computer Vision. Procedia Comput. Sci. 2017, 116, 596–603. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Behera, S.K.; Rath, A.K.; Mahapatra, A.; Sethy, P.K. Identification, classification & grading of fruits using machine learning & computer intelligence: A review. J. Ambient. Intell. Humaniz. Comput. 2020. [Google Scholar] [CrossRef]
- Liu, G.; Nouaze, J.C.; Touko Mbouembe, P.L.; Kim, J.H. YOLO-Tomato: A Robust Algorithm for Tomato Detection Based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef] [PubMed]
- Jhawar, J. Orange Sorting by Applying Pattern Recognition on Colour Image. Procedia Comput. Sci. 2016, 78, 691–697. [Google Scholar] [CrossRef]
- Jin, X.; Sun, Y.; Che, J.; Bagavathiannan, M.; Yu, J.; Chen, Y. A novel deep learning-based method for detection of weeds in vegetables. Pest Manag. Sci. 2022, 78, 1861–1869. [Google Scholar] [CrossRef] [PubMed]
- Asif, M.K.R.; Rahman, M.A.; Hena, M.H. CNN based Disease Detection Approach on Potato Leaves. In Proceedings of the 2020 3rd International Conference on Intelligent Sustainable Systems (ICISS), Thoothukudi, India, 3–5 December 2020; pp. 428–432. [Google Scholar] [CrossRef]
- Bhargava, A.; Bansal, A. Fruits and vegetables quality evaluation using computer vision: A review. J. King Saud Univ. Comput. Inf. Sci. 2021, 33, 243–257. [Google Scholar] [CrossRef]
- Cervantes-Jilaja, C.; Bernedo-Flores, L.; Morales-Muñoz, E.; Patiño-Escarcina, R.E.; Barrios-Aranibar, D.; Ripas-Mamani, R.; Valera, H.H.A. Optimal Selection and Identification of Defects in Chestnuts Processing, through Computer Vision, Taking Advantage of its Inherent Characteristics. In Proceedings of the 2019 24th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Zaragoza, Spain, 10–13 September 2019; pp. 513–520. [Google Scholar] [CrossRef]
- Sivaranjani, A.; Senthilrani, S.; Ashokumar, B.; Murugan, A.S. CashNet-15:An Optimized Cashew Nut Grading Using Deep CNN and Data Augmentation. In Proceedings of the 2019 IEEE International Conference on System, Computation, Automation and Networking (ICSCAN), Pondicherry, India, 29–30 March 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Parvathi, S.; Tamil Selvi, S. Detection of maturity stages of coconuts in complex background using Faster R-CNN model. Biosyst. Eng. 2021, 202, 119–132. [Google Scholar] [CrossRef]
- Ramos, P.; Prieto, F.; Montoya, E.; Oliveros, C. Automatic fruit count on coffee branches using computer vision. Comput. Electron. Agric. 2017, 137, 9–22. [Google Scholar] [CrossRef]
- Ganganagowder, N.V.; Kamath, P. Intelligent classification models for food products basis on morphological, colour and texture features. Acta Agronó. 2017, 66, 486–494. [Google Scholar] [CrossRef]
- Islam, K.T.; Wijewickrema, S.; Pervez, M.; O’Leary, S. An Exploration of Deep Transfer Learning for Food Image Classification. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 10–13 December 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Hameed, K.; Chai, D.; Rassau, A. A comprehensive review of fruit and vegetable classification techniques. Image Vis. Comput. 2018, 80, 24–44. [Google Scholar] [CrossRef]
- Thakkar, M.; Bhatt, M.; Bhensdadia, C.K. Performance Evaluation of Classification Techniques for Computer Vision based Cashew Grading System. Int. J. Comput. Appl. 2011, 18, 9–12. [Google Scholar] [CrossRef]
- Aran, M.O.; Nath, A.G.; Shyna, A. Automated cashew kernel grading using machine vision. In Proceedings of the 2016 International Conference on Next Generation Intelligent Systems (ICNGIS), Kottayam, India, 1–3 September 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Shyna, A.; George, R.M. Machine vision based real time cashew grading and sorting system using SVM and back propagation neural network. In Proceedings of the 2017 International Conference on Circuit, Power and Computing Technologies (ICCPCT), Kollam, India, 20–21 April 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Narendra, V.G.; Hareesh, K.S. Cashew kernels classification using colour features. Int. J. Mach. Intell. 2011, 3, 52–57. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Diao, Z.; Guo, P.; Zhang, B.; Zhang, D.; Yan, J.; He, Z.; Zhao, S.; Zhao, C.; Zhang, J. Navigation line extraction algorithm for corn spraying robot based on improved YOLOv8s network. Comput. Electron. Agric. 2023, 212, 108049. [Google Scholar] [CrossRef]
- Wu, W.K.; Chen, C.Y.; Lee, J.S. Embedded YOLO: Faster and lighter object detection. In Proceedings of the 2021 International Conference on Multimedia Retrieval, Taipei Taiwan, 21–24 August 2021; pp. 560–565. [Google Scholar]
- Madasamy, K.; Shanmuganathan, V.; Kandasamy, V.; Lee, M.Y.; Thangadurai, M. OSDDY: Embedded system-based object surveillance detection system with small drone using deep YOLO. EURASIP J. Image Video Process. 2021, 2021, 19. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 1 November 2023).
- Song, P.; Li, P.; Dai, L.; Wang, T.; Chen, Z. Boosting R-CNN: Reweighting R-CNN samples by RPN’s error for underwater object detection. Neurocomputing 2023, 530, 150–164. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Dai, M.; Hu, J.; Zhuang, J.; Zheng, E. A transformer-based feature segmentation and region alignment method for UAV-view geo-localization. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4376–4389. [Google Scholar] [CrossRef]
- Vietnam Cashew Nut Processing Industry. Available online: https://www.shellingmachine.com/application/Vietnam-cashew-nut-processing-industry.html (accessed on 20 February 2024).
- Cashew Nuts Supply Chains in Vietnam: A Case Study in Dak Nong and Binh Phuoc Provinces, Vietnam. Available online: https://agro.gov.vn/images/2007/04/Cashew_nut_Vietnam.En_(Full_document).pdf (accessed on 20 February 2024).
- Do, M.T.; Ha, M.H.; Nguyen, D.C.; Thai, K.; Ba, Q.H.D. Human Detection Based Yolo Backbones-Transformer in UAVs. In Proceedings of the 2023 International Conference on System Science and Engineering (ICSSE), Ho Chi Minh, Vietnam, 27–28 July 2023; pp. 576–580. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H. Designing network design strategies through gradient path analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Zhang, Z. Drone-YOLO: An Efficient Neural Network Method for Target Detection in Drone Images. Drones 2023, 7, 526. [Google Scholar] [CrossRef]
- Tan, X.; He, X. Improved Asian food object detection algorithm based on YOLOv5. E3S Web Conf. 2022, 360, 01068. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO:Transformer-Based YOLO for Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2799–2808. [Google Scholar] [CrossRef]
- Wang, W.; Chen, W.; Qiu, Q.; Chen, L.; Wu, B.; Lin, B.; He, X.; Liu, W. Crossformer++: A versatile vision transformer hinging on cross-scale attention. arXiv 2023, arXiv:2303.06908. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameter | F1-Score | Precision | Recall |
|---|---|---|---|---|
| YOLOv8l | 43.7M | 0.902 | 0.908 | 0.897 |
| YOLOv8m | 25.9M | 0.894 | 0.867 | 0.923 |
| YOLOv8n | 3.2M | 0.944 | 0.948 | 0.940 |
| YOLOv8x | 68.2M | 0.920 | 0.919 | 0.921 |
| YOLOv8–Transformer | 20.5M | 0.960 | 0.960 | 0.960 |
| Model | AP (Good) | AP (Error 1) | AP (Error 2) | AP (Error 3) | mAP |
|---|---|---|---|---|---|
| YOLOv8l | 0.969 | 0.963 | 0.957 | 0.972 | 0.965 |
| YOLOv8m | 0.979 | 0.966 | 0.959 | 0.967 | 0.968 |
| YOLOv8n | 0.990 | 0.972 | 0.974 | 0.979 | 0.979 |
| YOLOv8x | 0.972 | 0.957 | 0.945 | 0.964 | 0.960 |
| YOLOv8–Transformer | 0.992 | 0.976 | 0.980 | 0.986 | 0.984 |
| Model | Number of Incorrect Predictions | % of Incorrect Predictions |
|---|---|---|
| YOLOv8l | 16 | 5.92 |
| YOLOv8m | 19 | 7.03 |
| YOLOv8n | 10 | 3.70 |
| YOLOv8x | 13 | 4.81 |
| YOLOv8–Transformer | 8 | 2.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pham, V.-N.; Do Ba, Q.-H.; Tran Le, D.-A.; Nguyen, Q.-M.; Do Van, D.; Nguyen, L. A Low-Cost Deep-Learning-Based System for Grading Cashew Nuts. Computers 2024, 13, 71. https://doi.org/10.3390/computers13030071
Pham V-N, Do Ba Q-H, Tran Le D-A, Nguyen Q-M, Do Van D, Nguyen L. A Low-Cost Deep-Learning-Based System for Grading Cashew Nuts. Computers. 2024; 13(3):71. https://doi.org/10.3390/computers13030071
Chicago/Turabian StylePham, Van-Nam, Quang-Huy Do Ba, Duc-Anh Tran Le, Quang-Minh Nguyen, Dinh Do Van, and Linh Nguyen. 2024. "A Low-Cost Deep-Learning-Based System for Grading Cashew Nuts" Computers 13, no. 3: 71. https://doi.org/10.3390/computers13030071