


User-Centered Pipeline for Synthetic Augmentation of Anomaly Detection Datasets †

Abstract
:1. Introduction
- Extending the approach for augmenting datasets with synthetic elements [20] with a customizable solution with a visual user interface specialized in high usability;
- Refocusing the solution to an anomaly detection in traffic surveillance context where synthetic pedestrians, cars, and cyclists can be augmented into the scene;
- Training the MNAD anomaly detection model on a combination of real and synthetic data and demonstrating that it produces better results on the complex Street Scene dataset
2. Background Research
2.1. Anomaly Datasets
2.2. Synthetic Datasets
3. Proposed Application
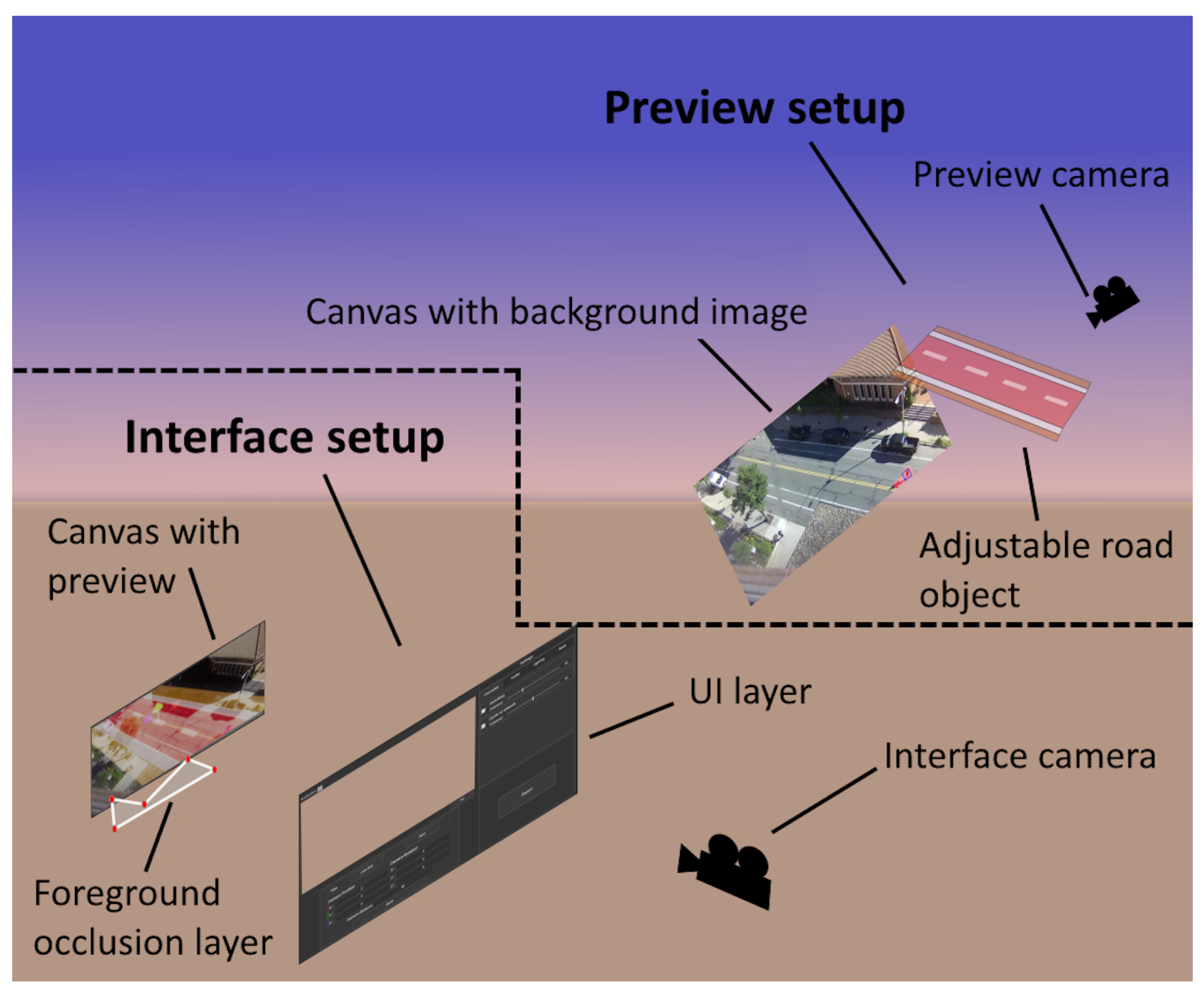
3.1. Overview
3.2. User Interface Development
- The visualization screen used for manually tweaking the position of the camera, road, bike lanes, and sidewalks (A);
- The Unity camera positioning group where fSpy can be started and an initial camera position can be loaded and later tweaked if needed (B);
- The synthetic objects group which contains the tabs for adding anomalies; synthetic traffic in the form of cars, pedestrians, and cyclists; changing of light color, direction, and intensity; and finally manual separation of the input image space into streets, bicycle lanes, and sidewalks (C);
- The export tab contains options for setting up the length of the augmented video sequence, generating multiple videos one after the other, adding or removing anomalies depending on the training or testing data being generated, and an option if video files or image sequences should be saved (D).
3.3. Synthetic Object Placement
3.4. Occlusion between Foreground and Background Elements
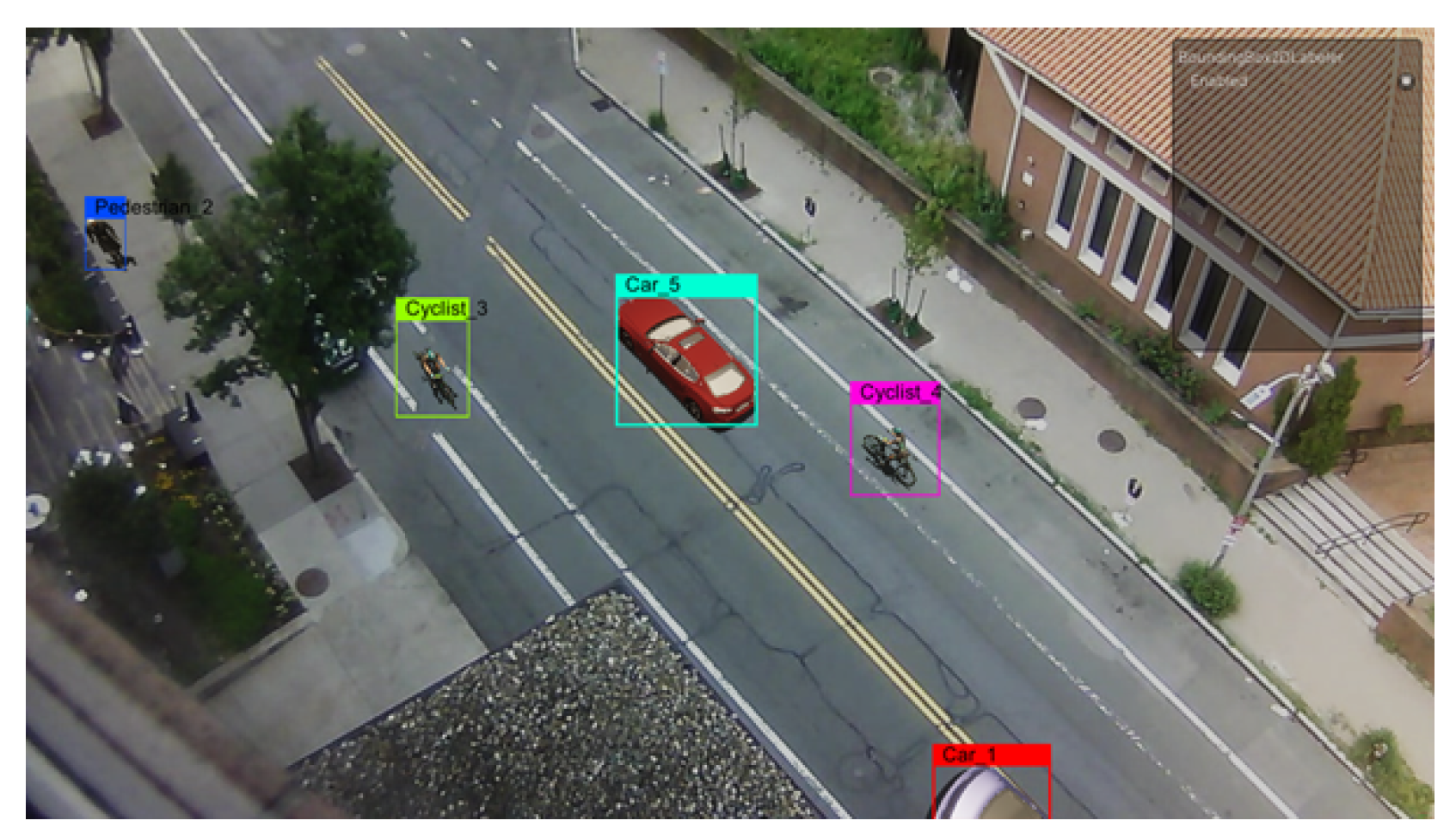
3.5. Synthetic Data Annotation
3.6. Lighting and Shadows
4. Experiments
4.1. RITE Experimental Procedure
4.2. Expert Interviews
4.3. Anomaly Detection Model Test
5. Results
5.1. RITE Experiment and Expert Interviews
- First iteration —four errors were encountered by participants—two when annotating the background elements used for occlusion, one when using fSpy through the application, and one when adjusting the road position;
- Second iteration—one error was encountered by the participant, again connected to adjusting the road, when using the menu to set offsets;
- Third iteration—one error was encountered by the participant when annotating the occlusion elements, as it was not known if the occlusion area was created or another button needed to be pressed;
- Forth iteration—one error was encountered again in the annotation of the occlusion elements, in the size of the selected region, where the participant thought the region was smaller than it was.
- Fifth iteration—the users had three errors related to exporting functionality, and the personal preferences of the users were to have more feedback when creating the occlusion areas.
- Menu system for selecting behavior animations for the different synthetic objects;
- The ability to change the ordering of the pedestrian walkways and the bike lanes so that users can utilize the application with different types of road configurations;
- A preview window showing an animation of the anomaly before it has been augmented into images;
- Easier changes to the lighting via the ability to separate it into times of the day or by selecting a specific time.
5.2. Anomaly-Detection Results
6. Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RITE | Rapid Iterative Testing and Evaluation |
| MNAD | Memory-guided Normality for Anomaly Detection |
| GAN | Generative Adversarial Network |
| UI | User Interface |
| HDRP | High-Definition Rendering Pipeline |
References
- Ramachandra, B.; Jones, M.J.; Vatsavai, R.R. A survey of single-scene video anomaly detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2293–2312. [Google Scholar] [CrossRef] [PubMed]
- Ramachandra, B.; Jones, M.J. Street scene: A new dataset and evaluation protocol for video anomaly detection. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision, WACV 2020, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2558–2567. [Google Scholar] [CrossRef]
- Sun, C.; Jia, Y.; Hu, Y.; Wu, Y. Scene-aware context reasoning for unsupervised abnormal event detection in videos. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 184–192. [Google Scholar]
- Bo Bo, N.; Slembrouck, M.; Veelaert, P.; Philips, W. Distributed Multi-class Road User Tracking in Multi-camera Network for Smart Traffic Applications. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2020; Volume 12002 LNCS, pp. 517–528. [Google Scholar] [CrossRef]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6479–6488. [Google Scholar]
- Sreenu, G.; Durai, S. Intelligent video surveillance: A review through deep learning techniques for crowd analysis. J. Big Data 2019, 6, 48. [Google Scholar] [CrossRef]
- Robertson, N.; Reid, I.; Brady, M. Automatic human behaviour recognition and explanation for CCTV video surveillance. Secur. J. 2008, 21, 173–188. [Google Scholar] [CrossRef]
- Hwang, R.H.; Peng, M.C.; Huang, C.W.; Lin, P.C.; Nguyen, V.L. An unsupervised deep learning model for early network traffic anomaly detection. IEEE Access 2020, 8, 30387–30399. [Google Scholar] [CrossRef]
- Doshi, K.; Yilmaz, Y. An efficient approach for anomaly detection in traffic videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4236–4244. [Google Scholar]
- Aboah, A. A vision-based system for traffic anomaly detection using deep learning and decision trees. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4207–4212. [Google Scholar]
- Mantini, P.; Li, Z.; Shah, K.S. A Day on Campus—An Anomaly Detection Dataset for Events in a Single Camera. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2021; Volume 12627 LNCS, pp. 619–635. [Google Scholar] [CrossRef]
- Cruz-Esquivel, E.; Guzman-Zavaleta, Z.J. An examination on autoencoder designs for anomaly detection in video surveillance. IEEE Access 2022, 10, 6208–6217. [Google Scholar] [CrossRef]
- Mahadevan, V.; Li, W.; Bhalodia, V.; Vasconcelos, N. Anomaly detection in crowded scenes. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1975–1981. [Google Scholar]
- Lu, C.; Shi, J.; Jia, J. Abnormal event detection at 150 fps in matlab. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2720–2727. [Google Scholar]
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future frame prediction for anomaly detection—A new baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6536–6545. [Google Scholar]
- Nikolov, I.A.; Philipsen, M.P.; Liu, J.; Dueholm, J.V.; Johansen, A.S.; Nasrollahi, K.; Moeslund, T.B. Seasons in drift: A long-term thermal imaging dataset for studying concept drift. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems, Online, 6–14 December 2021. [Google Scholar]
- Martinez, M.; Sitawarin, C.; Finch, K.; Meincke, L.; Yablonski, A.; Kornhauser, A. Beyond Grand Theft Auto V for Training, Testing and Enhancing Deep Learning in Self Driving Cars. arXiv 2017, arXiv:1712.01397. [Google Scholar]
- Johnson-Roberson, M.; Barto, C.; Mehta, R.; Sridhar, S.N.; Rosaen, K.; Vasudevan, R. Driving in the Matrix: Can Virtual Worlds Replace Human-Generated Annotations for Real World Tasks? arXiv 2017, arXiv:1610.01983. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar]
- Nikolov, I. Augmenting Anomaly Detection Datasets with Reactive Synthetic Elements. In Proceedings of the Computer Graphics and Visual Computing (CGVC), Wales, UK, 14–15 September 2023; Vangorp, P., Hunter, D., Eds.; The Eurographics Association: Munich, Germany, 2023. [Google Scholar] [CrossRef]
- Acsintoae, A.; Florescu, A.; Georgescu, M.I.; Mare, T.; Sumedrea, P.; Ionescu, R.T.; Khan, F.S.; Shah, M. Ubnormal: New benchmark for supervised open-set video anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20143–20153. [Google Scholar] [CrossRef]
- Mantini, P.; Shah, S.K. Camera tampering detection using generative reference model and deep learned features. In Proceedings of the VISIGRAPP 2019—14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Prague, Czech Republic, 25 February 2019; Volume 5, pp. 85–95. [Google Scholar] [CrossRef]
- Flaborea, A.; D’Amely, G.; D’Arrigo, S.; Sterpa, M.A.; Sampieri, A.; Galasso, F. Contracting Skeletal Kinematic Embeddings for Anomaly Detection. empharXiv 2023, arXiv:2301.09489. [Google Scholar]
- Madan, N.; Siemon, M.S.N.; Gjerde, M.K.; Petersson, B.S.; Grotuzas, A.; Esbensen, M.A.; Nikolov, I.A.; Philipsen, M.P.; Nasrollahi, K.; Moeslund, T.B. ThermalSynth: A Novel Approach for Generating Synthetic Thermal Human Scenarios. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 130–139. [Google Scholar]
- Park, H.; Noh, J.; Ham, B. Learning memory-guided normality for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 14372–14381. [Google Scholar]
- Chebiyyam, M.; Reddy, R.D.; Dogra, D.P.; Bhaskar, H.; Mihaylova, L. Motion anomaly detection and trajectory analysis in visual surveillance. Multimed. Tools Appl. 2018, 77, 16223–16248. [Google Scholar] [CrossRef]
- Li, W.; Mahadevan, V.; Vasconcelos, N. Anomaly Detection and Localization in Crowded Scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 18–32. [Google Scholar] [CrossRef] [PubMed]
- Mantini, P.; Shah, S.K. UHCTD: A Comprehensive Dataset for Camera Tampering Detection. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Pranav, M.; Zhenggang, L. A day on campus-an anomaly detection dataset for events in a single camera. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Islam, J.; Zhang, Y. GAN-based synthetic brain PET image generation. Brain Inform. 2020, 7, 3. [Google Scholar] [CrossRef] [PubMed]
- Abduljawad, M.; Alsalmani, A. Towards Creating Exotic Remote Sensing Datasets using Image Generating AI. In Proceedings of the 2022 International Conference on Electrical and Computing Technologies and Applications (ICECTA), Ras Al Khaimah, United Arab Emirates, 23–25 November 2022; pp. 84–88. [Google Scholar]
- Borji, A. Generated faces in the wild: Quantitative comparison of stable diffusion, midjourney and dall-e 2. arXiv 2022, arXiv:2210.00586. [Google Scholar]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Learning from synthetic data for crowd counting in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8198–8207. [Google Scholar]
- Aranjuelo Ansa, N.; García Castaño, J.; Unzueta Irurtia, L.; García Torres, S.; Elordi Hidalgo, U.; Otaegui Madurga, O. Building synthetic simulated environments for configuring and training multi-camera systems for surveillance applications. In Proceedings of the 16th International Conference on Computer Vision Theory and Applications, Virtual Event, 8–10 February 2021. [Google Scholar]
- He, R.; Sun, S.; Yu, X.; Xue, C.; Zhang, W.; Torr, P.; Bai, S.; Qi, X. Is synthetic data from generative models ready for image recognition? arXiv 2022, arXiv:2210.07574. [Google Scholar]
- Desurvire, H.; Wiberg, C. Game Usability Heuristics (PLAY) for Evaluating and Designing Better Games: The Next Iteration. In Proceedings of the Online Communities and Social Computing: Third International Conference, OCSC 2009, Held as Part of HCI International 2009, San Diego, CA, USA, 19–24 July 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 557–566. [Google Scholar] [CrossRef]
- Laitinen, S. Better Games through Usability Evaluation and Testing. Gamasutra. 2005. Available online: https://www.gamedeveloper.com/production/better-games-through-usability-evaluation-and-testing (accessed on 30 January 2024).
- Gantelius, P. fSpy. 2018. Available online: https://fspy.io/ (accessed on 30 January 2024).
- Hamill, C. The Atlas of Lost Rooms: Digitally Reconstructing Dark Heritage Sites in Ireland. In Proceedings of the Emerging Technologies and the Digital Transformation of Museums and Heritage Sites: First International Conference, RISE IMET 2021, Nicosia, Cyprus, 2–4 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 199–216. [Google Scholar]
- Chao, G. Human-Computer Interaction: Process and Principles of Human-Computer Interface Design. In Proceedings of the 2009 International Conference on Computer and Automation Engineering, Bangkok, Thailand, 8–10 March 2009; pp. 230–233. [Google Scholar] [CrossRef]
- Dudley, J.J.; Kristensson, P.O. A Review of User Interface Design for Interactive Machine Learning. ACM Trans. Interact. Intell. Syst. 2018, 8, 1–37. [Google Scholar] [CrossRef]
- Wada, K. labelme: Image Polygonal Annotation with Python. 2018. Available online: https://github.com/wkentaro/labelme (accessed on 30 January 2024).
- Sekachev, B.; Manovich, N.; Zhiltsov, M.; Zhavoronkov, A.; Kalinin, D.; Hoff, B.; Osmanov, T.; Kruchinin, D.; Zankevich, A.; Dmitriy, S.; et al. Opencv/cvat: V1.1.0. 2020. Available online: https://zenodo.org/records/4009388 (accessed on 30 January 2024).
- Tzutalin. LabelImg. Free Software: MIT License. 2015. Available online: https://github.com/HumanSignal/labelImg (accessed on 5 March 2024).
- Supervisely. 2017. Available online: https://supervisely.com/ (accessed on 30 January 2024).
- VOTT Visual Object Tagging Tool. 2020. Available online: https://github.com/microsoft/VoTT (accessed on 30 January 2024).
- Unity Perception. 2020. Available online: https://github.com/Unity-Technologies/com.unity.perception (accessed on 8 January 2024).
- Astrid, M.; Zaheer, M.Z.; Lee, J.Y.; Lee, S.I. Learning not to reconstruct anomalies. arXiv 2021, arXiv:2110.09742. [Google Scholar]
- Zhao, M.; Liu, Y.; Liu, J.; Li, D.; Zeng, X. LGN-Net: Local-Global Normality Network for Video Anomaly Detection. arXiv 2022, arXiv:2211.07454. [Google Scholar]
- Lv, H.; Chen, C.; Cui, Z.; Xu, C.; Li, Y.; Yang, J. Learning normal dynamics in videos with meta prototype network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15425–15434. [Google Scholar]
- Medlock, M.C.; Wixon, D.; McGee, M.; Welsh, D. The rapid iterative test and evaluation method: Better products in less time. In Cost-Justifying Usability; Elsevier: Amsterdam, The Netherlands, 2005; pp. 489–517. [Google Scholar]
- Medlock, M.C.; Wixon, D.; Terrano, M.; Romero, R.; Fulton, B. Using the RITE method to improve products: A definition and a case study. Usability Prof. Assoc. 2002, 51, 1963813932–1562338474. [Google Scholar]
- Singh, A.; Jones, M.J.; Learned-Miller, E.G. EVAL: Explainable Video Anomaly Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18717–18726. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Hu, X.; Zhu, L.; Fu, C.W.; Qin, J.; Heng, P.A. Direction-aware spatial context features for shadow detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7454–7462. [Google Scholar]
- Wang, T.; Hu, X.; Wang, Q.; Heng, P.A.; Fu, C.W. Instance shadow detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1880–1889. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | AUC | Precision | Recall | F1-Score |
|---|---|---|---|---|
| 0.506 | 0.310 | 0.802 | 0.448 | |
| 0.511 | 0.311 | 0.850 | 0.459 | |
| 0.477 | 0.310 | 0.820 | 0.450 | |
| 0.524 | 0.315 | 0.860 | 0.452 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rosbak-Mortensen, A.; Jansen, M.; Muhlig, M.; Kristensen Tøt, M.B.; Nikolov, I. User-Centered Pipeline for Synthetic Augmentation of Anomaly Detection Datasets. Computers 2024, 13, 70. https://doi.org/10.3390/computers13030070
Rosbak-Mortensen A, Jansen M, Muhlig M, Kristensen Tøt MB, Nikolov I. User-Centered Pipeline for Synthetic Augmentation of Anomaly Detection Datasets. Computers. 2024; 13(3):70. https://doi.org/10.3390/computers13030070
Chicago/Turabian StyleRosbak-Mortensen, Alexander, Marco Jansen, Morten Muhlig, Mikkel Bjørndahl Kristensen Tøt, and Ivan Nikolov. 2024. "User-Centered Pipeline for Synthetic Augmentation of Anomaly Detection Datasets" Computers 13, no. 3: 70. https://doi.org/10.3390/computers13030070