

Pm2.5 Time Series Imputation with Deep Learning and Interpolation
Abstract
:1. Introduction
- -
- A novel approach for pm2.5 time series imputation based on deep learning classification;
- -
- An ensemble deep learning model for NA values classification;
- -
- A comparative analysis between the proposal approach versus benchmark models.
2. Related Work
3. Materials and Methods
3.1. Data Preparation
3.2. Implementation of Classification Models
3.2.1. Feature Extraction and Labelling
3.2.2. Feature Selection
3.2.3. Normalization
- : normalized vector;
- : original feature vector;
- : mean of the feature vector;
- : standard deviation of the feature vector.
3.2.4. Deep Learning Classification Models
3.2.5. Evaluation
3.3. Imputation of NA Values
3.3.1. Generation of NA Values in Test Data
3.3.2. Class Estimation for NA Values
3.3.3. Interpolation according to Class Estimation
3.4. Implementation of Benchmark Models
3.5. Evaluation
- n: Number of observed/predicted values;
- Pi: Vector of predicted values;
- Oi: Vector of observed values;
- : Mean of observed values.
4. Results and Discussion
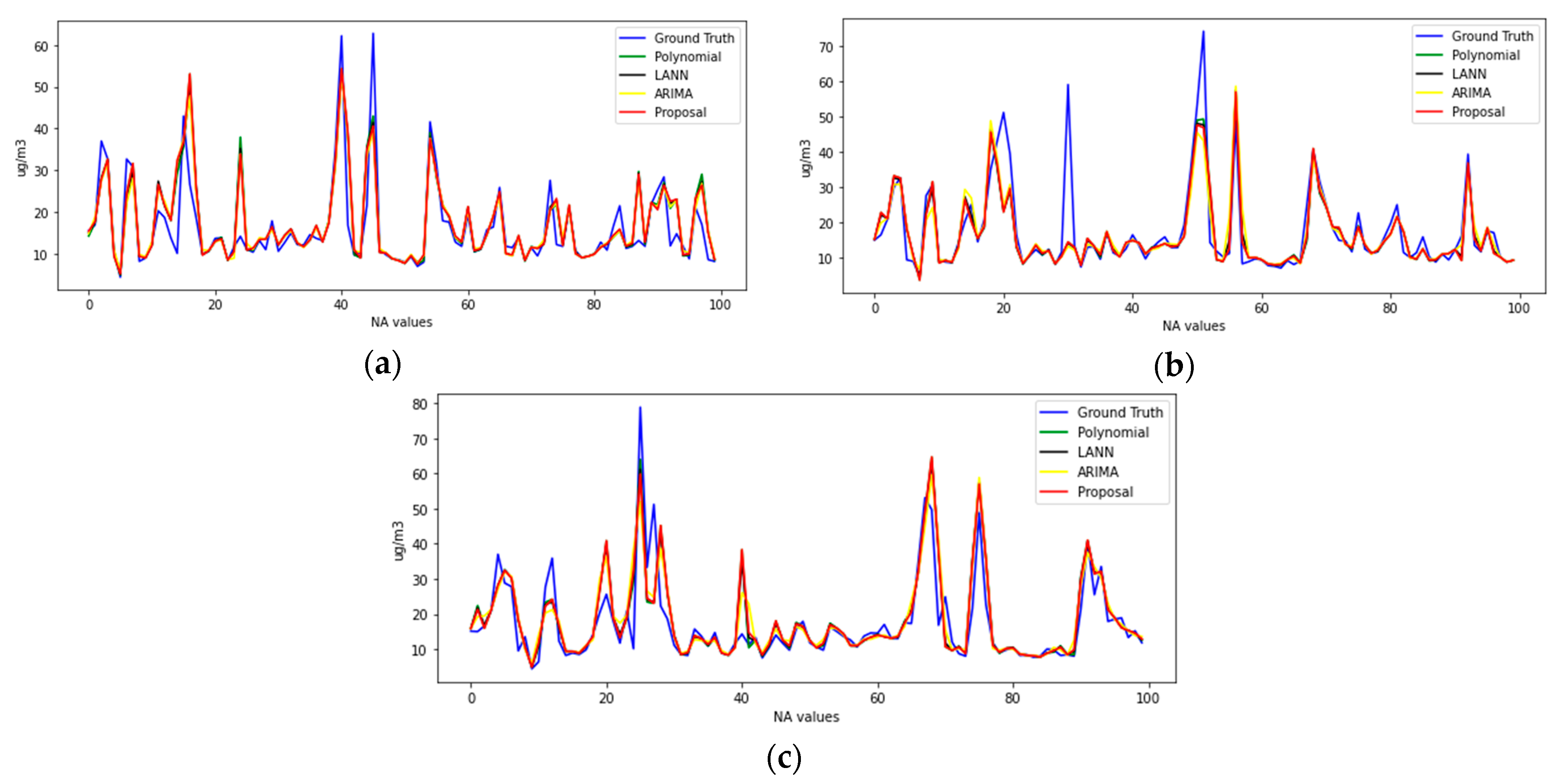
4.1. Results
4.2. Discussions
5. Conclusions and Future Work
5.1. Conclusions
5.2. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Spadon, G.; Hong, S.; Brandoli, B.; Matwin, S.; Rodrigues, J.F., Jr.; Sun, J. Pay Attention to Evolution: Time Series Forecasting with Deep Graph-Evolution Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5368–5384. [Google Scholar] [CrossRef] [PubMed]
- Moritz, S.; Bartz-Beielstein, T. imputeTS: Time series missing value imputation in R. R J. 2017, 9, 207–218. [Google Scholar] [CrossRef]
- Peker, N.; Kubat, C. A Hybrid modified deep learning data imputation method for numeric datasets. Int. J. Intell. Syst. Appl. Eng. 2021, 9, 6–11. [Google Scholar] [CrossRef]
- Chen, C.; Xue, X. A novel coupling preprocessing approach for handling missing data in water quality prediction. J. Hydrol. 2023, 617, 128901. [Google Scholar] [CrossRef]
- Oh, J.; Choi, S.; Han, C.; Lee, D.-W.; Ha, E.; Kim, S.; Bae, H.-J.; Pyun, W.B.; Hong, Y.-C.; Lim, Y.-H. Association of long-term exposure to PM2.5 and survival following ischemic heart disease. Environ. Res. 2023, 216, 114440. [Google Scholar] [CrossRef] [PubMed]
- Huang, F.; Pan, B.; Wu, J.; Chen, E.; Chen, L. Relationship between exposure to PM2.5 and lung cancer incidence and mortality: A meta-analysis. Oncotarget 2017, 8, 43322–43331. [Google Scholar] [CrossRef] [PubMed]
- Su, J.; Ye, Q.; Zhang, D.; Zhou, J.; Tao, R.; Ding, Z.; Lu, G.; Liu, J.; Xu, F. Joint association of cigarette smoking and PM2.5 with COPD among urban and rural adults in regional China. BMC Pulm. Med. 2021, 21, 87. [Google Scholar] [CrossRef]
- Bu, X.; Xie, Z.; Liu, J.; Wei, L.; Wang, X.; Chen, M.; Ren, H. Global PM2.5-attributable health burden from 1990 to 2017: Estimates from the Global Burden of disease study 2017. Environ. Res. 2021, 197, 111123. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, P.; Xia, X.; Wang, L.; Li, X. The underlying mechanism of PM2.5-induced ischemic stroke. Environ. Pollut. 2022, 310, 119827. [Google Scholar] [CrossRef]
- Lee, M.; Ohde, S. PM2.5 and diabetes in the Japanese population. Int. J. Environ. Res. Public Health 2021, 18, 6653. [Google Scholar] [CrossRef]
- Liu, Q.; Liu, W.; Mei, J.; Si, G.; Xia, T.; Quan, J. A New Support Vector Regression Model for Equipment Health Diagnosis with Small Sample Data Missing and Its Application. Shock. Vib. 2021, 2021, 6675078. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Fernández, S.; Schmidhuber, J. Bidirectional LSTM networks for improved phoneme classification and recognition. In Proceedings of the International Conference on Artificial Neural Networks, Warsaw, Poland, 11–15 September 2005; Lecture Notes in Computer Science; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2005; pp. 799–804. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Flores, A.; Tito, H.; Silva, C. Local average of nearest neighbors: Univariate time series imputation. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 45–50. [Google Scholar] [CrossRef]
- Xiao, Q.; Chang, H.H.; Geng, G.; Liu, Y. An Ensemble Machine-Learning Model To Predict Historical PM2.5 Concentrations in China from Satellite Data. Environ. Sci. Technol. 2018, 52, 13260–13269. [Google Scholar] [CrossRef]
- Yuan, H.; Xu, G.; Yao, Z.; Jia, J.; Zhang, Y. Imputation of missing data in time series for air pollutants using long short-term memory recurrent neural networks. In Proceedings of the 2018 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Singapore, 8–12 October 2018; pp. 1293–1300. [Google Scholar] [CrossRef]
- Belachsen, I.; Broday, D.M. Imputation of Missing PM2.5 Observations in a Network of Air Quality Monitoring Stations by a New kNN Method. Atmosphere 2022, 13, 1934. [Google Scholar] [CrossRef]
- Saif-Ul-Allah, M.W.; Qyyum, M.A.; Ul-Haq, N.; Salman, C.A.; Ahmed, F. Gated Recurrent Unit Coupled with Projection to Model Plane Imputation for the PM2.5 Prediction for Guangzhou City, China. Front. Environ. Sci. 2022, 9, 816616. [Google Scholar] [CrossRef]
- Alkabbani, H.; Ramadan, A.; Zhu, Q.; Elkamel, A. An Improved Air Quality Index Machine Learning-Based Forecasting with Multivariate Data Imputation Approach. Atmosphere 2022, 13, 1144. [Google Scholar] [CrossRef]
- Yldz, A.Y.; Koc, E.; Koc, A. Multivariate Time Series Imputation with Transformers. IEEE Signal Process. Lett. 2022, 29, 2517–2521. [Google Scholar] [CrossRef]
- Lee, Y.S.; Choi, E.; Park, M.; Jo, H.; Park, M.; Nam, E.; Kim, D.G.; Yi, S.-M.; Kim, J.Y. Feature extraction and prediction of fine particulate matter (PM2.5) chemical constituents using four machine learning models. Expert Syst. Appl. 2023, 221, 119696. [Google Scholar] [CrossRef]
- Yang, J.; Lai, X.; Zhang, L. Auto-Associative LSTM for Multivariate Time Series Imputation. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Hefei, China, 25–27 July 2022. [Google Scholar] [CrossRef]
- Li, D.; Li, L.; Li, X.; Ke, Z.; Hu, Q. Smoothed LSTM-AE: A spatio-temporal deep model for multiple time-series missing imputation. Neurocomputing 2020, 411, 351–363. [Google Scholar] [CrossRef]
- Zaman, M.A.U.; Du, D. A Stochastic Multivariate Irregularly Sampled Time Series Imputation Method for Electronic Health Records. Biomedinformatics 2021, 1, 166–181. [Google Scholar] [CrossRef]
- Zhang, W.; Luo, Y.; Zhang, Y.; Srinivasan, D. SolarGAN: Multivariate solar data imputation using generative adversarial network. IEEE Trans. Sustain. Energy 2020, 12, 743–746. [Google Scholar] [CrossRef]
- Cao, W.; Zhou, H.; Wang, D.; Li, Y.; Li, J.; Li, L. BRITS: Bidirectional recurrent imputation for time series. In Proceedings of the Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Che, Z.; Purushotham, S.; Cho, K.; Sontag, D.; Liu, Y. Recurrent Neural Networks for Multivariate Time Series with Missing Values. Sci. Rep. 2018, 8, 6085. [Google Scholar] [CrossRef]
- Guo, Y.; Poh, J.W.J.; Wong, C.S.Y.; Ramasamy, S. Bayesian Continual Imputation and Prediction For Irregularly Sampled Time Series Data. In Proceedings of the ICASSP 2011—IEEE International Conference on Acoustics, Speech and Signal Processing, Singapore, 23–27 May 2022; pp. 4493–4497. [Google Scholar] [CrossRef]
- Brownlee, J. Ensemble Learning Algorithms with Python. Machine Learning Mastery. 2021. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description |
|---|---|
| p0 | Prior value to NA |
| p1 | Before p0 |
| p2 | Before p1 |
| n0 | Next value of NA |
| n1 | After n0 |
| n2 | After n1 |
| mid | Mean between prior (p0) and next value (n0) |
| mid1 | Mean between prior values (p1) and next value (p0) |
| mid2 | Mean between next values (n0) and next value (n1) |
| diff | Difference between prior and next values |
| slope1 | Slope between p1 and p0 |
| slope2 | Slope between n0 and n1 |
| label | Class of NA value. 0, corresponding to polynomial interpolation 1, corresponding to flipped polynomial interpolation. |
| Class | Conditions |
|---|---|
| 0 (polynomial interpolation) | According to Figure 1a, the conditions to apply polynomial interpolation are two cases: Case 1: When na is below the line (p0 to n0), it can be stated through the next conditions: na ≤ mid p1 ≥ p0 Case 2: When na is above the line (p0 to n0). The two conditions to be met are: na > mid p0 > p1 |
| 1 (flipped polynomial interpolation) | According to Figure 1b, the conditions to apply flipped polynomial interpolation are two: Case 1: When na is below the line (p0 to n0), it can be stated through the next conditions: na < mid p1 < p0 Case 2: When na is above the line (p0 to n0). The two conditions to be met are: na > mid p0 ≤ p1 |
| Model | Hyperparameters |
|---|---|
| DNN | (0, 20, 40, 10, 1), learning_rate: 0.0001, dropout_rate (0.1) |
| CNN | (20, 50, 10, 1), learning_rate: 0.0001, dropout_rate (0.1) |
| LSTM | (30, 30, 30, 1), learning_rate: 0.0001, dropout_rate (0.1) |
| GRU | (30, 30, 30, 1), learning_rate: 0.0001, dropout_rate (0.1) |
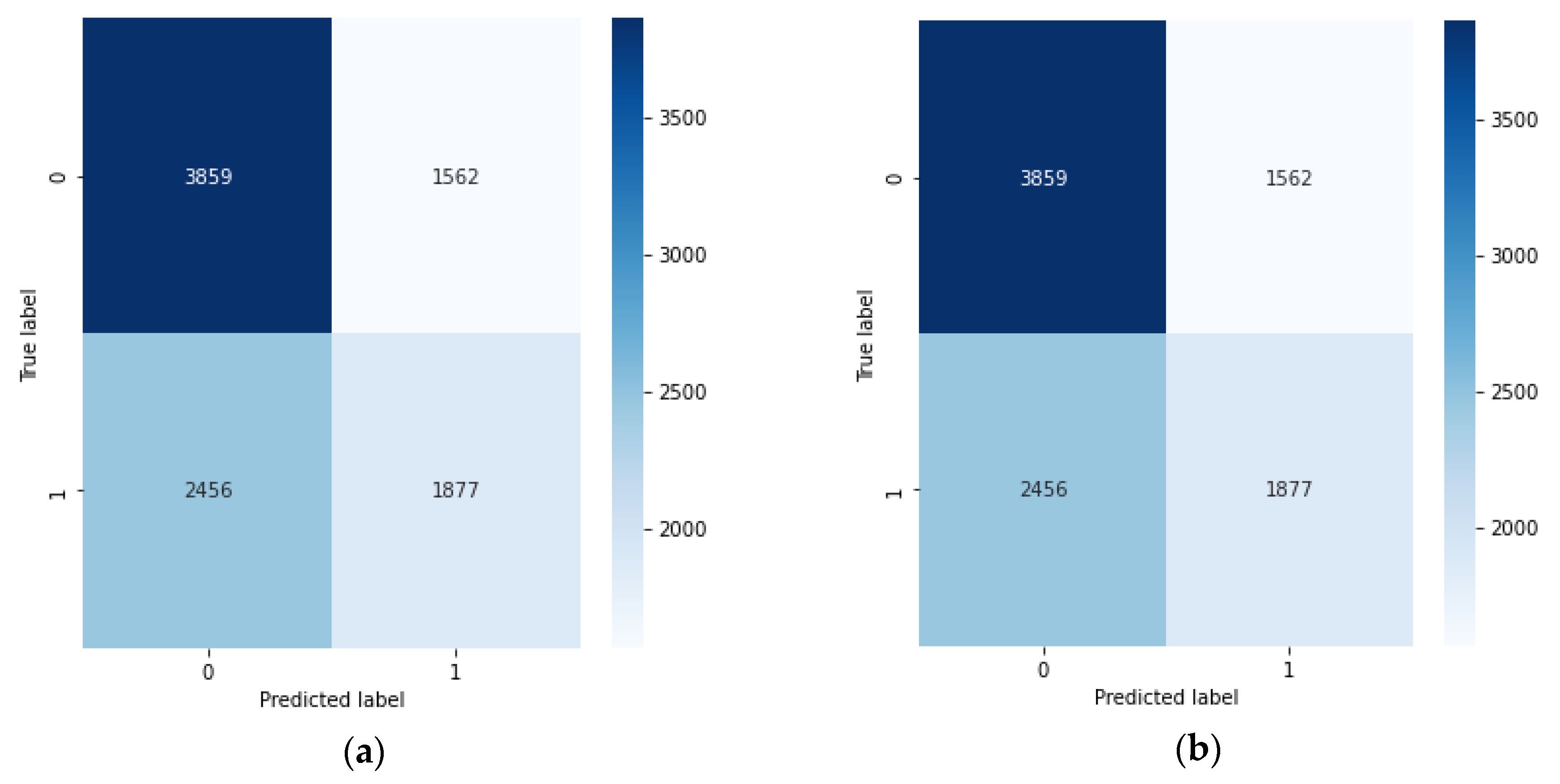
| Model | Accuracy | Recall | Precision | F1-Score |
|---|---|---|---|---|
| DNN | 0.5972 | 0.3083 | 0.5891 | 0.4048 |
| CNN | 0.5912 | 0.4223 | 0.5522 | 0.4786 |
| LSTM | 0.5859 | 0.3644 | 0.5513 | 0.4388 |
| GRU | 0.5859 | 0.4046 | 0.5458 | 0.4647 |
| Model | Hyperparameters |
|---|---|
| LSTM | architecture: [40, 30, 30, 40, 1], dropout_rate: 0.2 |
| BiLSTM | architecture: [30, 30, 30, 1], dropout_rate: 0.1 |
| GRU | architecture: [40, 30, 30, 40, 1], dropout_rate: 0.1 |
| BiGRU | architecture: [30, 30, 30, 1], dropout_rate: 0.1 |
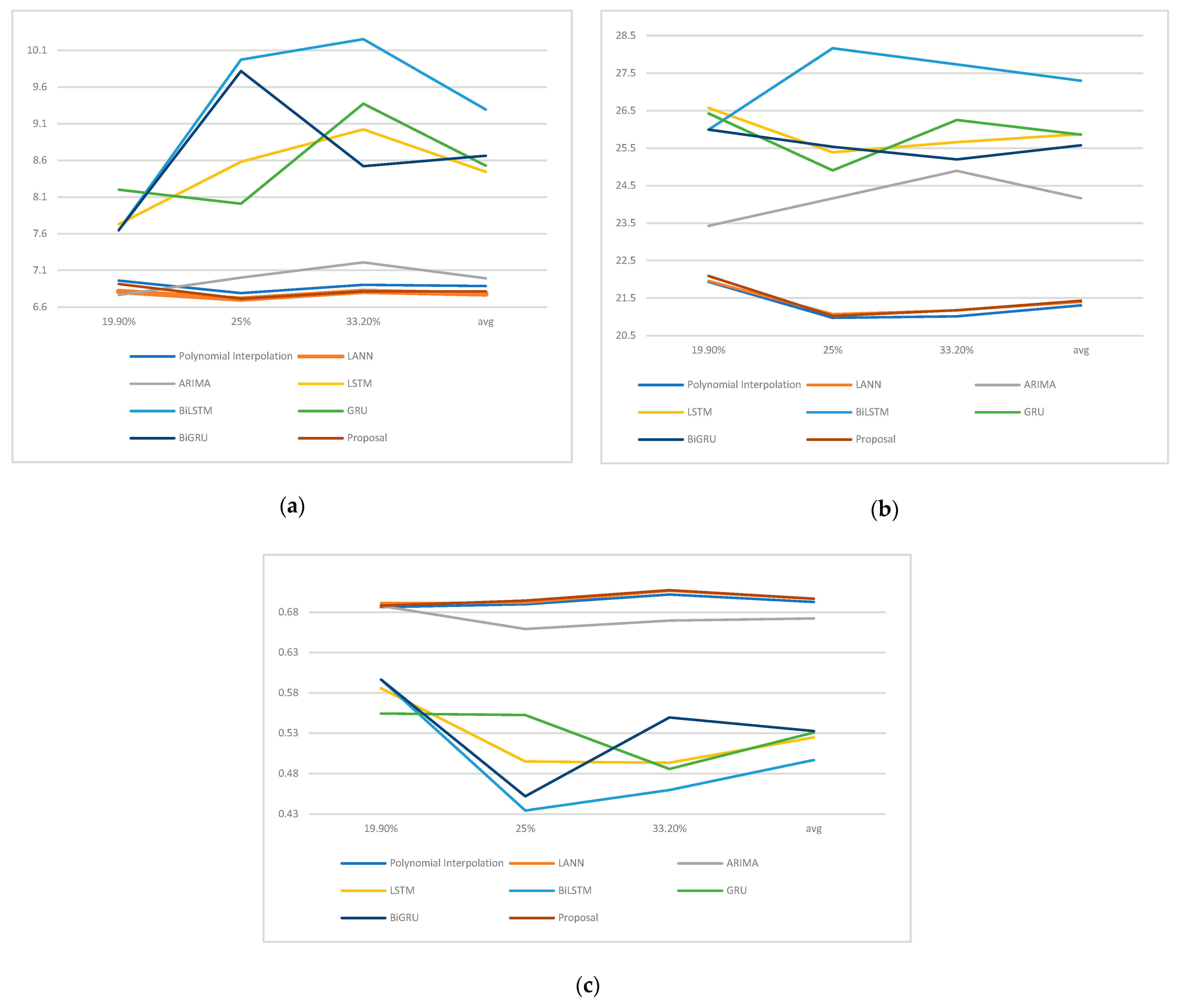
| Model | 19.98% NAs | 25.00% NAs | 33.32% NAs | Avg |
|---|---|---|---|---|
| Polynomial Interpolation | 6.9916 | 6.7912 | 6.9028 | 6.8852 ± 0.0866 |
| ARIMA | 6.7654 | 7.0014 | 7.2092 | 6.9920 ± 0.2220 |
| LANN | 6.8123 | 6.7088 | 6.8150 | 6.7787 ± 0.0606 |
| LSTM | 7.7294 | 8.5795 | 9.0225 | 8.4438 ± 0.6571 |
| BiLSTM | 7.6487 | 9.9728 | 10.2524 | 9.2913 ± 1.4294 |
| GRU | 8.1990 | 8.0098 | 9.3725 | 8.5271 ± 0.7382 |
| BiGRU | 7.6487 | 9.8169 | 8.5198 | 8.6618 ± 1.0910 |
| Proposal | 6.9148 | 6.7136 | 6.8134 | 6.8139 ± 0.1005 |
| Model | 19.98% NAs | 25.00% NAs | 33.32% NAs | Avg |
|---|---|---|---|---|
| Polynomial interpolation | 21.9339 | 20.9743 | 21.0103 | 21.3061 ± 0.5439 |
| ARIMA | 23.4291 | 24.1574 | 24.8961 | 24.1609 ± 0.7335 |
| LANN | 21.9548 | 21.0718 | 21.1710 | 21.3992 ± 0.4837 |
| LSTM | 26.5726 | 25.3866 | 25.6597 | 25.8730 ± 0.6211 |
| BiLSTM | 25.9940 | 28.1648 | 27.7320 | 27.2970 ± 1.1489 |
| GRU | 26.4241 | 24.9054 | 26.2472 | 25.8589 ± 0.8305 |
| BiGRU | 25.9940 | 25.5355 | 25.1984 | 25.5760 ± 0.3993 |
| Proposal | 22.0902 | 21.0242 | 21.1759 | 21.4301 ± 0.5767 |
| Model | 19.98% NAs | 25.00% NAs | 33.32% NAs | Avg |
|---|---|---|---|---|
| Polynomial interpolation | 0.6862 | 0.6896 | 0.7019 | 0.6925 ± 0.0083 |
| ARIMA | 0.6877 | 0.6590 | 0.6721 | 0.6721 ± 0.0097 |
| LANN | 0.6911 | 0.6916 | 0.7063 | 0.6963 ± 0.0087 |
| LSTM | 0.5857 | 0.4950 | 0.4935 | 0.5248 ±0.0527 |
| BiLSTM | 0.5964 | 0.4344 | 0.4596 | 0.4968 ± 0.0872 |
| GRU | 0.5545 | 0.5524 | 0.4857 | 0.5309 ± 0.0391 |
| BiGRU | 0.5964 | 0.4519 | 0.5495 | 0.5326 ± 0.0737 |
| Proposal | 0.6880 | 0.6941 | 0.7072 | 0.6964 ± 0.0098 |
| Work | Technique | Data | Frequency | Metric | Value |
|---|---|---|---|---|---|
| Yuan et al., 2018 [17] | LSTM | 30,700 | Hourly | RMSE | 17.78 |
| Belachsen et al., 2022 [18] | KNN | 140,256 | Half-hourly | NMAE | [0.21–0.26] |
| Saif-ul-Allah et al., 2022 [19] | GRU | 2514 | Daily | RMSE | 10.60 |
| Alkabbani et al., 2022 [20] | Random forest | RMSE | 3.756 | ||
| Yldz et al., 2022 [21] | Transformers | 8760 | Hourly | MAE | 8.31 |
| Lee et al., 2023 [22] | GAIN | 26,281 | Hourly | R2 | 0.895 |
| Proposal | 56,424 | Hourly | RMSE | 6.8140 | |
| R2 | 0.6964 | ||||
| MAE | 3.4944 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Flores, A.; Tito-Chura, H.; Centty-Villafuerte, D.; Ecos-Espino, A. Pm2.5 Time Series Imputation with Deep Learning and Interpolation. Computers 2023, 12, 165. https://doi.org/10.3390/computers12080165
Flores A, Tito-Chura H, Centty-Villafuerte D, Ecos-Espino A. Pm2.5 Time Series Imputation with Deep Learning and Interpolation. Computers. 2023; 12(8):165. https://doi.org/10.3390/computers12080165
Chicago/Turabian StyleFlores, Anibal, Hugo Tito-Chura, Deymor Centty-Villafuerte, and Alejandro Ecos-Espino. 2023. "Pm2.5 Time Series Imputation with Deep Learning and Interpolation" Computers 12, no. 8: 165. https://doi.org/10.3390/computers12080165