
Tiny Deep Learning Architectures Enabling Sensor-Near Acoustic Data Processing and Defect Localization

Abstract
:1. Introduction
1.1. Related Works
1.2. Contribution
- We propose two DL architectures for the purpose of ToA identification, one based on a dilated convolutional neural network (DilCNN) and the latter being an improvement of the capsule neural network (CapsNet) described in [4];
- We extensively validate the performances of the two novel models against various noise levels, proving their superiority in addressing two different tasks: (i) accuracy in the pure ToA estimation while working on synthetic data, (ii) precision in acoustic source localization for the experimental use case of a metallic aluminum plate; in particular, we will show that DilCNN and CapsNet can achieve a localization error which is up to 70% more accurate than STA/LTA and AIC even when the SNR is considerably below 4 dB;
- We implemented the devised NN models in a tiny machine learning environment and eventually deployed on a general-purpose and resource-constrained microprocessor, namely the STM32L4 microcontroller unit based on the ARM ®Cortex-M4®core: we demonstrate that these tiny variants score negligible loss of performances with respect to the full-precision alternatives.
2. Neural Network Architectures for ToA Extraction
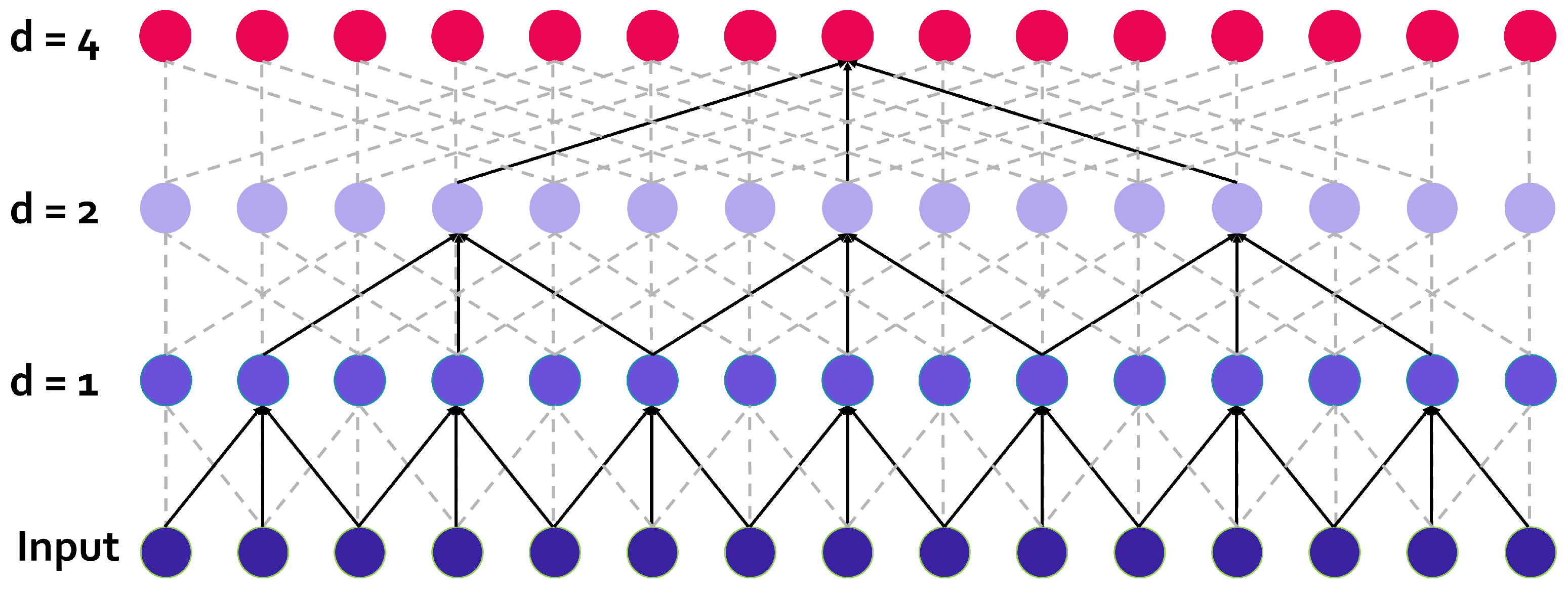
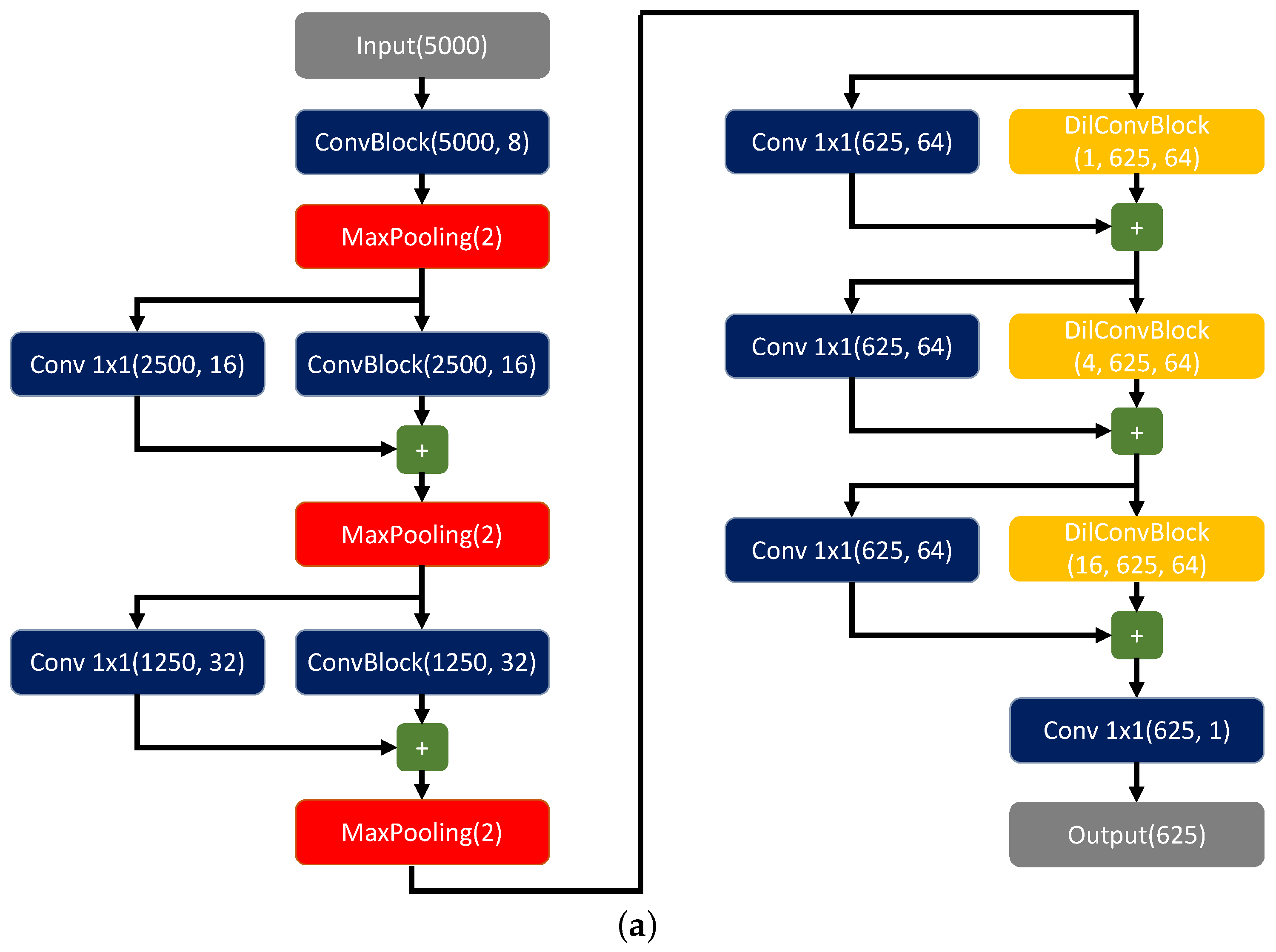
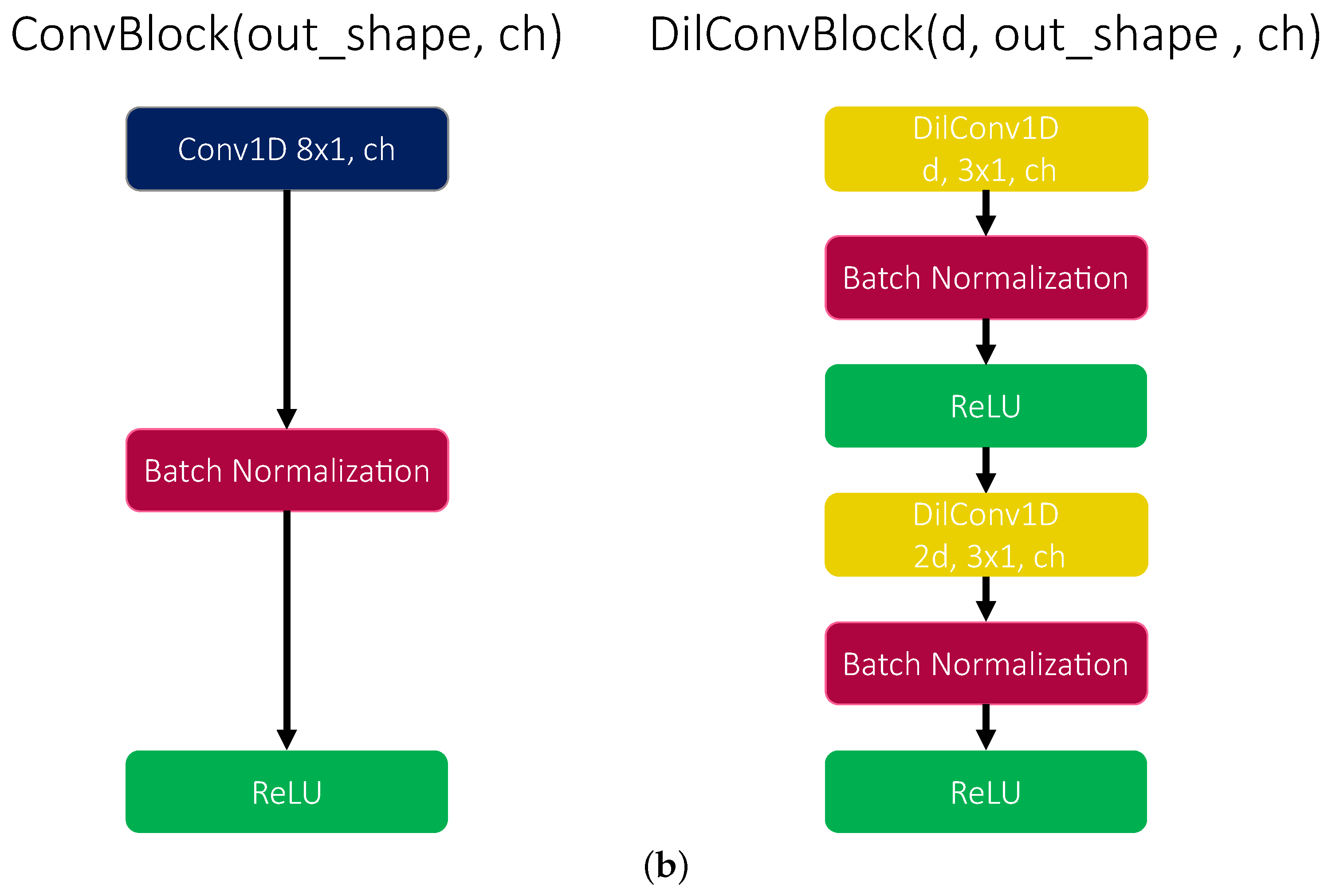
2.1. Dilated Convolutional Neural Networks
2.2. Capsule Neural Networks
- Primary Capsule Layer: the first component of this layer is a convolutional operator with a number of channels , where indicates the number of primary capsules per spatial—or temporal—position. Thus, the output of this operator is reshaped, starting from the channel dimension, into a set of vectors with coordinates, which are the so called primary capsules , with K being the number of temporal positions. These primary capsules are activated by means of a non-linear squash function and finally mapped into a probability value, according with [18]:
- Capsule Layer: each primary capsule with generates a prediction for every j-th class—with —by means of a weight opinion matrix :Such opinion matrices are learned during training and encode the relationship between local low-level features and the high-level entities associated with classes; hence, they are invariant to transformations applied to the input. In this way, capsules provide a simple way to detect global features by recognizing the individual contributions of the parts [40]. A global prediction for each class is, indeed, computed as a linear combination of the vectors obtained via Equation (5), yielding to:Individual are then activated by the squash function in Equation (4). Coefficients are determined following the dynamic routing protocol [18]. This consists of an iterative process, summarized in Algorithm 1, which combines together the output of single capsules with the appropriate parent belonging to the layer above. The pairing procedure works as follows: if has a large scalar product with the global output of a possible parent class, there is a top-down feedback which increases the coupling coefficient for that parent while decreasing it for the other ones. It follows that the higher the norm of an output vector, i.e., the higher the level of agreement between low-level capsules which are associated with its parts, the higher the likelihood that the corresponding feature class describes the input data.
Algorithm 1 Dynamic Routing for all capsule i in layer l and capsule j (i.e., class) in layer :
for r iterations do
for all capsule i in layer l:
for all capsule j in layer :
for all capsule j in layer :
for all capsule i in layer l and capsule j in layer :
end for
return for all capsule j in layer
2.3. Quantization Schemes
3. Model Deployment Process, Training and Testing
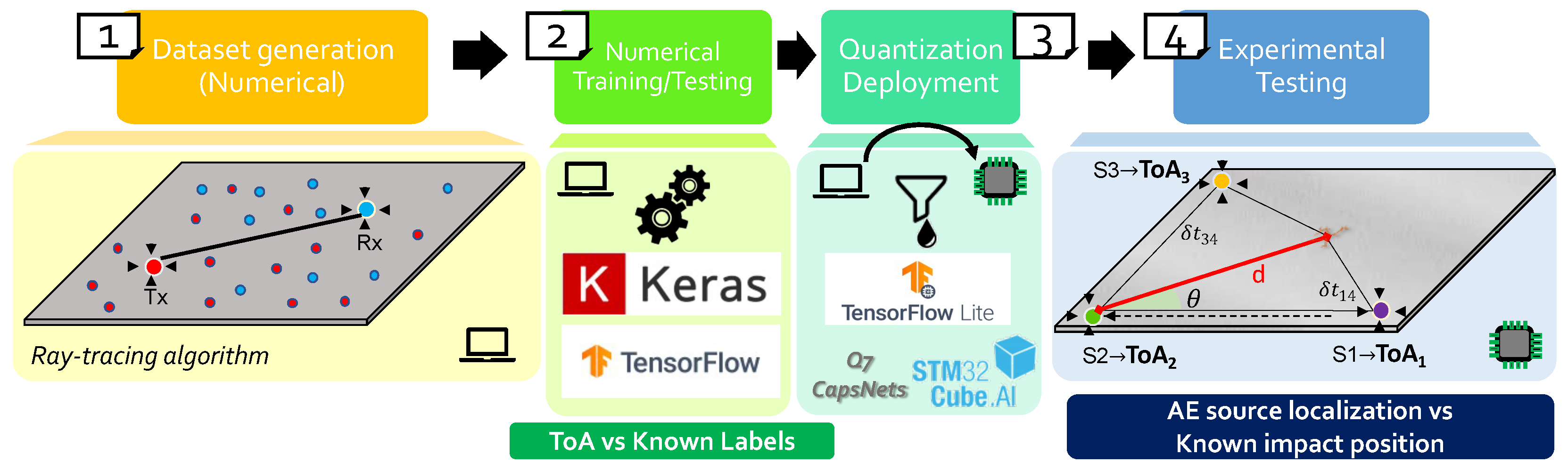
3.1. Materials
3.2. Dataset Generation
3.3. Validation Process
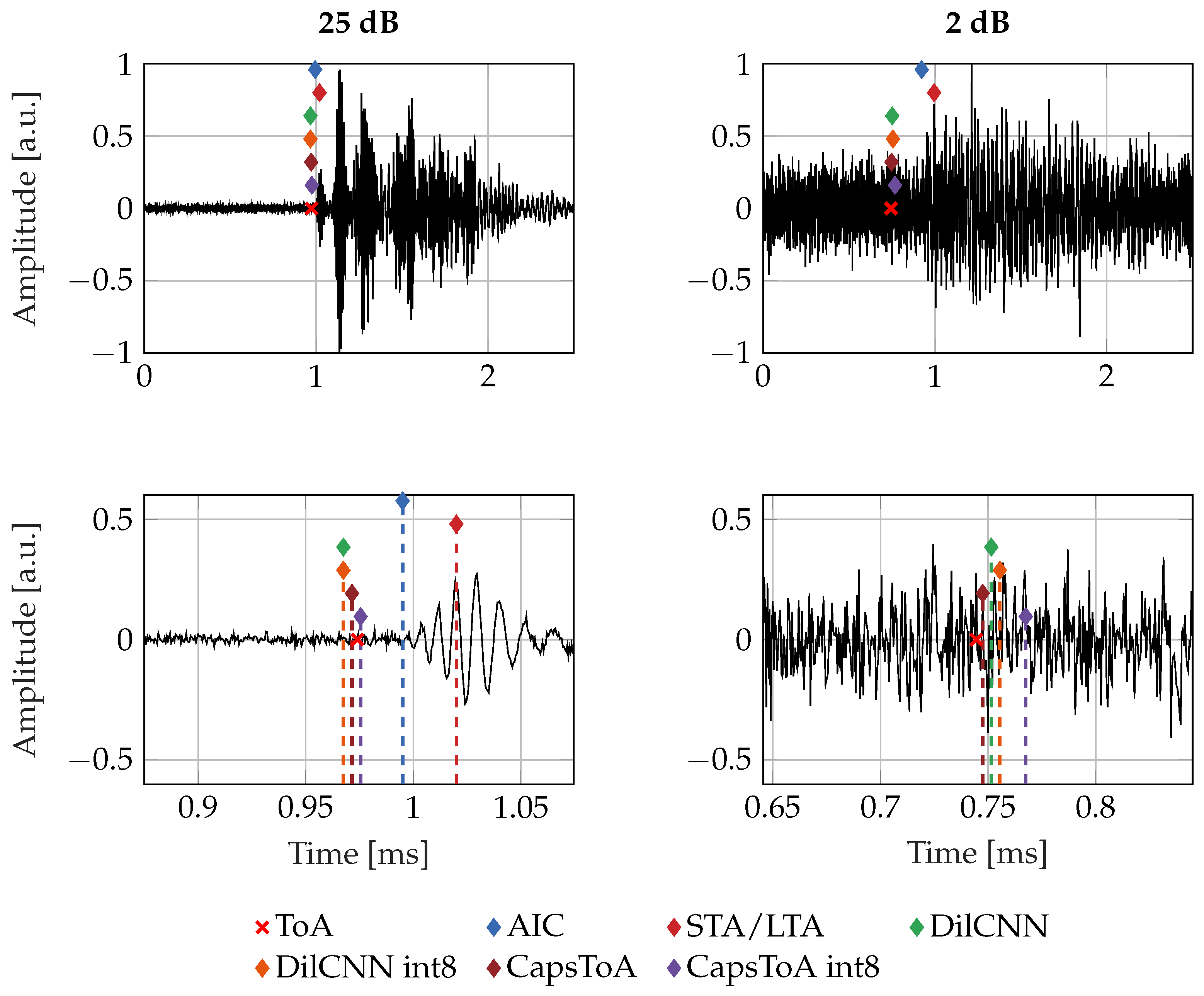
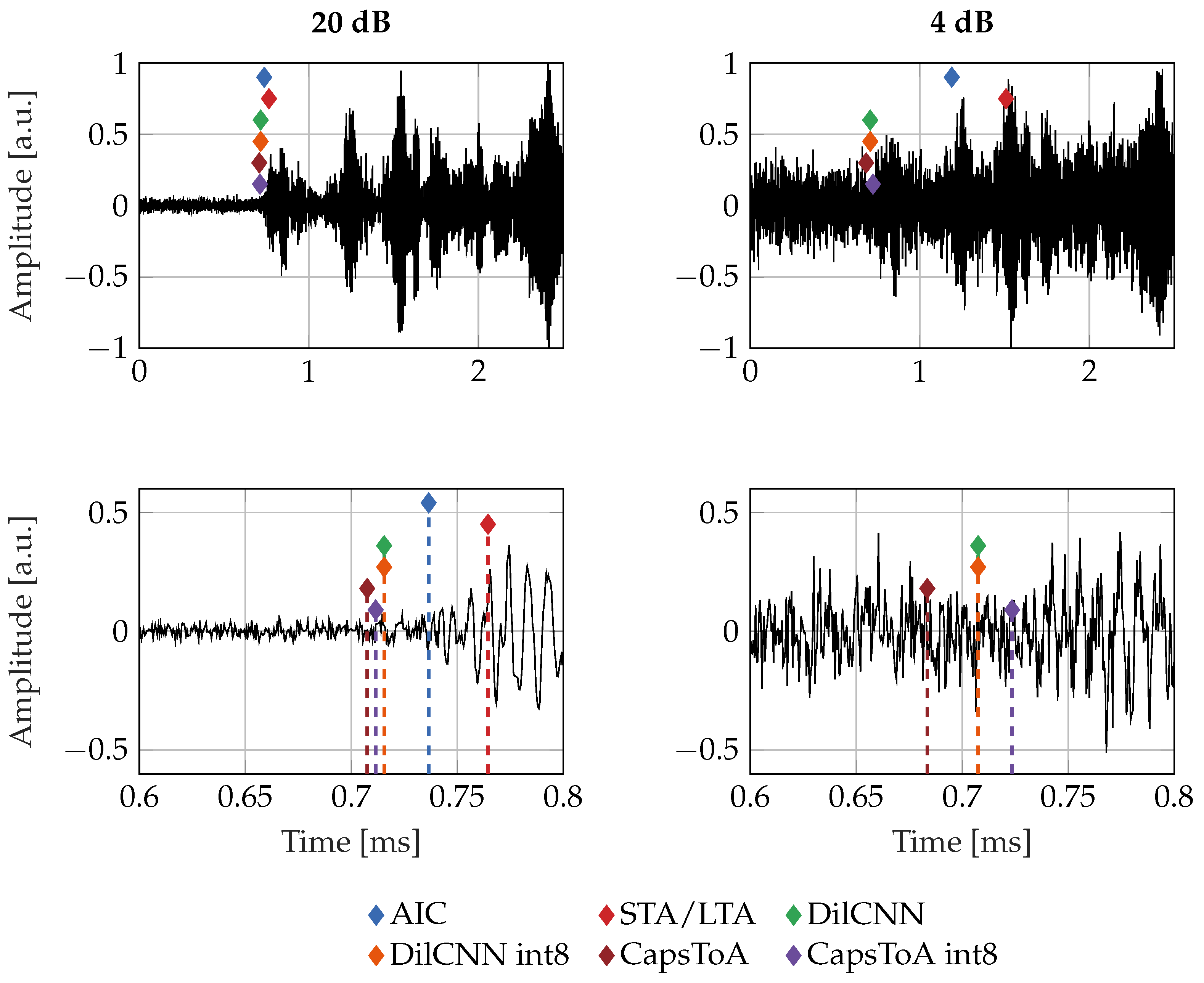
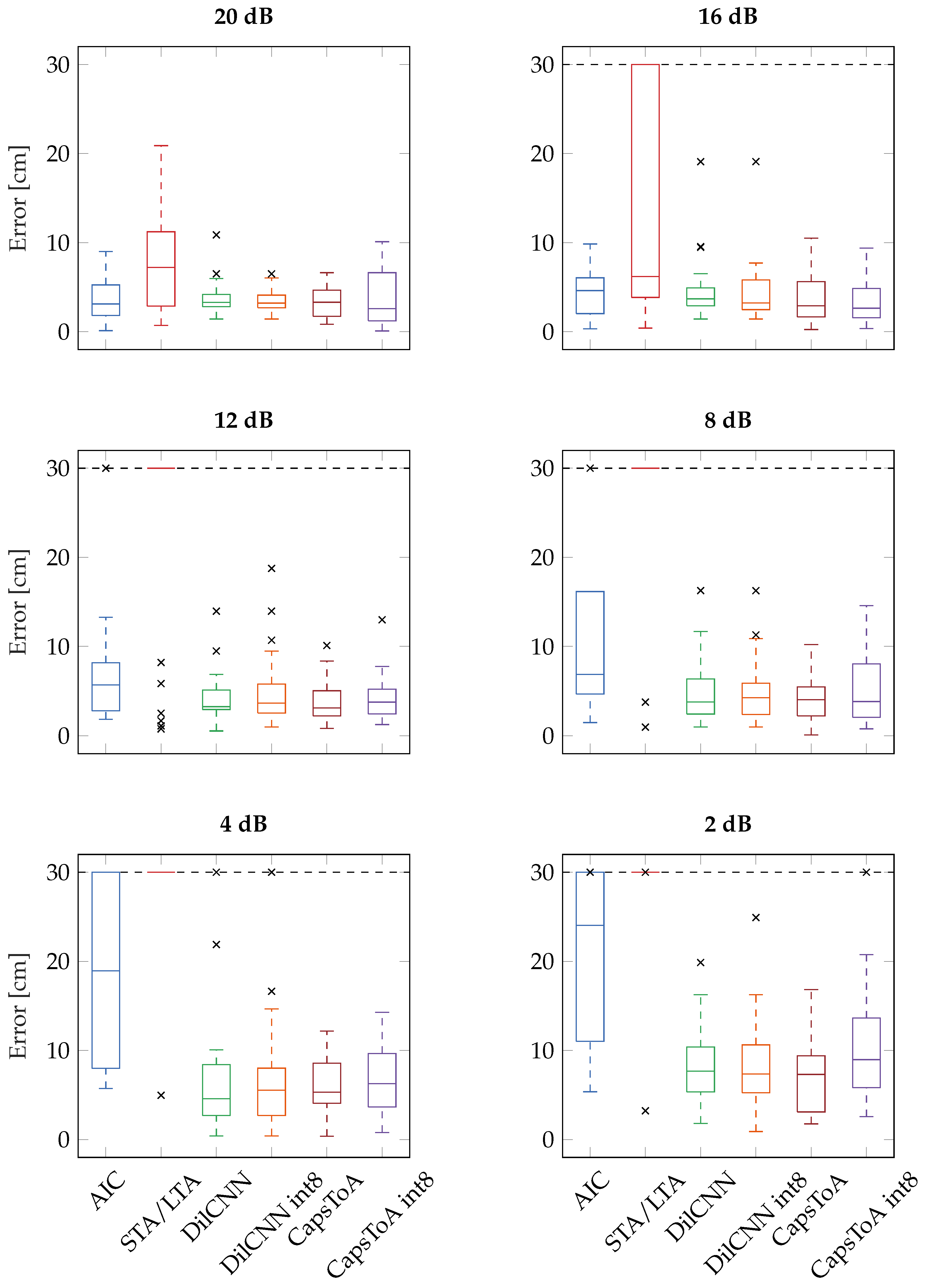
4. Results
4.1. Preliminary Validation on Synthetic Signals
4.2. Real-Field Validation for AE Localization
5. Discussion
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AE | Acoustic Emission |
| AI | Artificial Intelligence |
| AIC | Akaike Information Criterion |
| ANN | Artificial Neural Network |
| CapsNet | Capsule Neural Network |
| CapsToA | CapsNet for ToA Estimation |
| CNN | Convolutional Neural Network |
| CWT | Continuous Wavelet Transform |
| DilCNN | Dilated Convolutional Neural Network |
| DL | Deep Learning |
| DSP | Digital Signal Processing |
| ISA | Instruction Set |
| MACC | Multiply and Accumulate |
| MAE | Mean Absolute Error |
| MCU | Microcontroller Unit |
| RMSE | Root Mean Square Error |
| SHM | Structural Health Monitoring |
| SLA/STA | Short-Time Average on Long-Time Average |
| SNR | Signal-to-Noise Ratio |
| SVM | Support-Vector Machine |
| TinyML | Tiny Machine Learning |
| TF | Tensorflow |
| TF Lite | Tensorlflow Lite |
| ToA | Time of Arrival |
References
- Nair, A.; Cai, C. Acoustic emission monitoring of bridges: Review and case studies. Eng. Struct. 2010, 32, 1704–1714. [Google Scholar] [CrossRef]
- Pedersen, J.F.; Schlanbusch, R.; Meyer, T.J.; Caspers, L.W.; Shanbhag, V.V. Acoustic Emission-Based Condition Monitoring and Remaining Useful Life Prediction of Hydraulic Cylinder Rod Seals. Sensors 2021, 21, 6012. [Google Scholar] [CrossRef] [PubMed]
- Madarshahian, R.; Ziehl, P.; Todd, M.D. Bayesian Estimation of Acoustic Emission Arrival Times for Source Localization. In Model Validation and Uncertainty Quantification, Volume 3; Springer: Berlin/Heidelberg, Germany, 2020; pp. 127–133. [Google Scholar]
- Zonzini, F.; Bogomolov, D.; Dhamija, T.; Testoni, N.; De Marchi, L.; Marzani, A. Deep Learning Approaches for Robust Time of Arrival Estimation in Acoustic Emission Monitoring. Sensors 2022, 22, 1091. [Google Scholar] [CrossRef]
- Barat, V.; Borodin, Y.; Kuzmin, A. Intelligent AE signal filtering methods. J. Acoust. Emiss. 2010, 28, 109–119. [Google Scholar]
- St-Onge, A. Akaike information criterion applied to detecting first arrival times on microseismic data. In SEG Technical Program Expanded Abstracts 2011; Society of Exploration Geophysicists: Houston, TX, USA, 2011; pp. 1658–1662. [Google Scholar]
- Trnkoczy, A. Understanding and parameter setting of STA/LTA trigger algorithm. In New Manual of Seismological Observatory Practice (NMSOP); Deutsches GeoForschungsZentrum GFZ: Potsdam, Germany, 2009; pp. 1–20. [Google Scholar]
- Gopinath, S.; Ghanathe, N.; Seshadri, V.; Sharma, R. Compiling KB-sized machine learning models to tiny IoT devices. In Proceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation, Phoenix, AZ, USA, 22–26 June 2019; pp. 79–95. [Google Scholar]
- Ross, Z.E.; Rollins, C.; Cochran, E.S.; Hauksson, E.; Avouac, J.P.; Ben-Zion, Y. Aftershocks driven by afterslip and fluid pressure sweeping through a fault-fracture mesh. Geophys. Res. Lett. 2017, 44, 8260–8267. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y. Automatic microseismic event picking via unsupervised machine learning. Geophys. J. Int. 2020, 222, 1750–1764. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhu, W.; Beroza, G.C. PhaseNet: A deep-neural-network-based seismic arrival-time picking method. Geophys. J. Int. 2019, 216, 261–273. [Google Scholar] [CrossRef] [Green Version]
- Zheng, J.; Lu, J.; Peng, S.; Jiang, T. An automatic microseismic or acoustic emission arrival identification scheme with deep recurrent neural networks. Geophys. J. Int. 2018, 212, 1389–1397. [Google Scholar] [CrossRef]
- Han, Z.; Li, Y.; Guo, K.; Li, G.; Zheng, W.; Liu, H. A Seismic Phase Recognition Algorithm Based on Time Convolution Networks. Appl. Sci. 2022, 12, 9547. [Google Scholar] [CrossRef]
- Rojas, O.; Otero, B.; Alvarado, L.; Mus, S.; Tous, R. Artificial neural networks as emerging tools for earthquake detection. Comput. Sist. 2019, 23, 335–350. [Google Scholar] [CrossRef]
- Saad, O.M.; Chen, Y. Earthquake detection and P-wave arrival time picking using capsule neural network. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6234–6243. [Google Scholar] [CrossRef]
- Saad, O.M.; Chen, Y. CapsPhase: Capsule neural network for seismic phase classification and picking. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Huang, W.; Zhou, F. DA-CapsNet: Dual attention mechanism capsule network. Sci. Rep. 2020, 10, 11383. [Google Scholar] [CrossRef]
- Mazzia, V.; Salvetti, F.; Chiaberge, M. Efficient-capsnet: Capsule network with self-attention routing. Sci. Rep. 2021, 11, 14634. [Google Scholar] [CrossRef]
- Chen, G.; Wang, W.; Wang, Z.; Liu, H.; Zang, Z.; Li, W. Two-dimensional discrete feature based spatial attention CapsNet For sEMG signal recognition. Appl. Intell. 2020, 50, 3503–3520. [Google Scholar] [CrossRef]
- Li, C.; Wang, B.; Zhang, S.; Liu, Y.; Song, R.; Cheng, J.; Chen, X. Emotion recognition from EEG based on multi-task learning with capsule network and attention mechanism. Comput. Biol. Med. 2022, 143, 105303. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Chen, C.; Li, J.; Wan, F.; Sun, Y.; Wang, H. ST-CapsNet: Linking Spatial and Temporal Attention with Capsule Network for P300 Detection Improvement. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 991–1000. [Google Scholar] [CrossRef]
- Kundu, T.; Nakatani, H.; Takeda, N. Acoustic source localization in anisotropic plates. Ultrasonics 2012, 52, 740–746. [Google Scholar] [CrossRef] [PubMed]
- Boffa, N.D.; Arena, M.; Monaco, E.; Viscardi, M.; Ricci, F.; Kundu, T. About the combination of high and low frequency methods for impact detection on aerospace components. Prog. Aerosp. Sci. 2022, 129, 100789. [Google Scholar] [CrossRef]
- Garofalo, A.; Testoni, N.; Marzani, A.; De Marchi, L. Multiresolution wavelet analysis to estimate Lamb waves direction of arrival in passive monitoring techniques. In Proceedings of the 2017 IEEE Workshop on Environmental, Energy, and Structural Monitoring Systems (EESMS), Milan, Italy, 24–25 July 2017; IEEE: Piscataway Township, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Malatesta, M.M.; Testoni, N.; De Marchi, L.; Marzani, A. Lamb waves Direction of Arrival estimation based on wavelet decomposition. In Proceedings of the 2019 IEEE International Ultrasonics Symposium (IUS), Glasgow, UK, 6–9 October 2019; IEEE: Piscataway Township, NJ, USA, 2019; pp. 1616–1618. [Google Scholar]
- Hesser, D.F.; Kocur, G.K.; Markert, B. Active source localization in wave guides based on machine learning. Ultrasonics 2020, 106, 106144. [Google Scholar] [CrossRef] [PubMed]
- Miorelli, R.; Kulakovskyi, A.; Chapuis, B.; D’almeida, O.; Mesnil, O. Supervised learning strategy for classification and regression tasks applied to aeronautical structural health monitoring problems. Ultrasonics 2021, 113, 106372. [Google Scholar] [CrossRef] [PubMed]
- Dipietrangelo, F.; Nicassio, F.; Scarselli, G. Structural Health Monitoring for impact localisation via machine learning. Mech. Syst. Signal Process. 2023, 183, 109621. [Google Scholar] [CrossRef]
- Zonzini, F.; Donati, G.; De Marchi, L. A Tiny Machine Learning Approach to the Edge Localization of Acoustic Sources via Convolutional Neural Networks. In Advances in System-Integrated Intelligence: Proceedings of the 6th International Conference on System-Integrated Intelligence (SysInt 2022), Genova, Italy, 7–9 September 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 340–349. [Google Scholar]
- Tabian, I.; Fu, H.; Sharif Khodaei, Z. A convolutional neural network for impact detection and characterization of complex composite structures. Sensors 2019, 19, 4933. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part I 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Xi, R.; Hou, M.; Fu, M.; Qu, H.; Liu, D. Deep dilated convolution on multimodality time series for human activity recognition. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: Piscataway Township, NJ, USA, 2018; pp. 1–8. [Google Scholar]
- Yazdanbakhsh, O.; Dick, S. Multivariate time series classification using dilated convolutional neural network. arXiv 2019, arXiv:1905.01697. [Google Scholar]
- Borovykh, A.; Bohte, S.; Oosterlee, C.W. Dilated convolutional neural networks for time series forecasting. J. Comput. Financ. 2018. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; IEEE: Piscataway Township, NJ, USA, 2018; pp. 1–2. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Hinton, G.E.; Krizhevsky, A.; Wang, S.D. Transforming auto-encoders. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2011: 21st International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; Proceedings, Part I 21. Springer: Berlin/Heidelberg, Germany, 2011; pp. 44–51. [Google Scholar]
- He, Z.; Peng, P.; Wang, L.; Jiang, Y. PickCapsNet: Capsule network for automatic P-wave arrival picking. IEEE Geosci. Remote Sens. Lett. 2020, 18, 617–621. [Google Scholar] [CrossRef]
- Lorenser, T. The DSP Capabilities of ARM® Cortex®-M4 and Cortex-M7 Processors; ARM Holdings: Cambridge, UK, 2016. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]
- Gholami, A.; Kim, S.; Dong, Z.; Yao, Z.; Mahoney, M.W.; Keutzer, K. A survey of quantization methods for efficient neural network inference. arXiv 2021, arXiv:2103.13630. [Google Scholar]
- Rusci, M.; Fariselli, M.; Croome, M.; Paci, F.; Flamand, E. Accelerating RNN-Based Speech Enhancement on a Multi-core MCU with Mixed FP16-INT8 Post-training Quantization. In Proceedings of the Machine Learning and Principles and Practice of Knowledge Discovery in Databases: International Workshops of ECML PKDD 2022, Grenoble, France, 19–23 September 2022; Proceedings, Part I. Springer: Berlin/Heidelberg, Germany, 2023; pp. 606–617. [Google Scholar]
- Costa, M.; Costa, D.; Gomes, T.; Pinto, S. Shifting capsule networks from the cloud to the deep edge. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–25. [Google Scholar] [CrossRef]
- Lai, L.; Suda, N.; Chandra, V. Cmsis-nn: Efficient neural network kernels for arm cortex-m cpus. arXiv 2018, arXiv:1801.06601. [Google Scholar]
- ST Microelectronics. UM2179 User Manual STM32 Nucleo-144 Boards (MB1312); ST Microelectronics: Geneva, Switzerland, 2019. [Google Scholar]
- Bogomolov, D.; Testoni, N.; Zonzini, F.; Malatesta, M.; de Marchi, L.; Marzani, A. Acoustic emission structural monitoring through low-cost sensor nodes. In Proceedings of the 10th International Conference on Structural Health Monitoring of Intelligent Infrastructure, Porto, Portugal, 30 June–2 July 2021. [Google Scholar]
- Zonzini, F.; Malatesta, M.M.; Bogomolov, D.; Testoni, N.; Marzani, A.; De Marchi, L. Vibration-based SHM with upscalable and low-cost sensor networks. IEEE Trans. Instrum. Meas. 2020, 69, 7990–7998. [Google Scholar]
- Jiang, Y.; Xu, F. Research on source location from acoustic emission tomography. In Proceedings of the 30th European Conference on Acoustic Emission Testing & 7th International Conference on Acoustic Emission, Granada, Spain, 12–15 September 2012. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
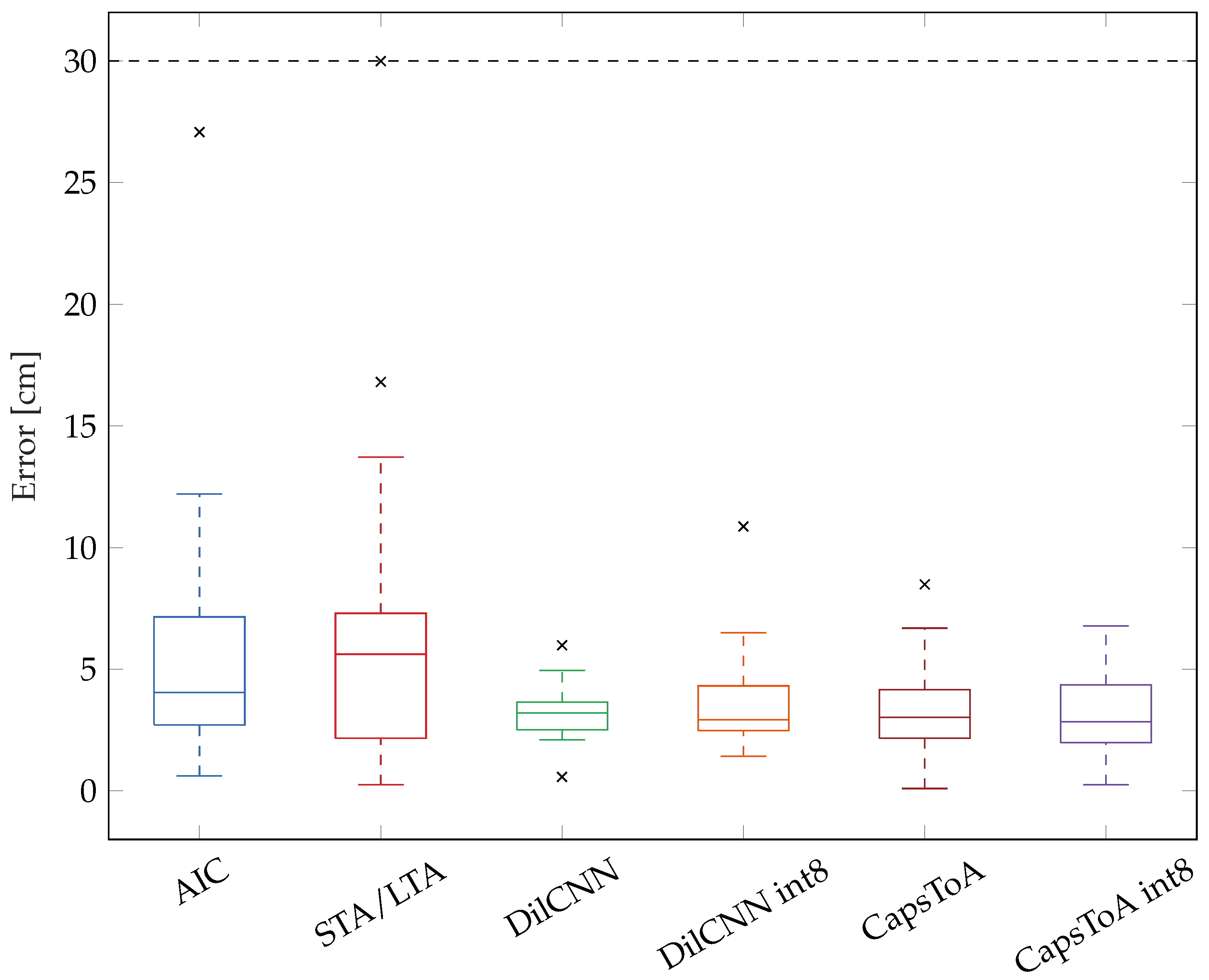{kind=link}
{kind=link}
| Method | SNR [dB] | MAE [μs] | RMSE [μs] |
|---|---|---|---|
| AIC | ≥20 | 29.47 | 40.10 |
| 12–20 | 68.96 | 89.02 | |
| 6–12 | 115.47 | 133.79 | |
| <6 | 132.74 | 151.74 | |
| STA/LTA | ≥20 | 59.56 | 106.23 |
| 12–20 | 150.38 | 213.31 | |
| 6–12 | 229.00 | 321.83 | |
| <6 | 301.88 | 401.31 | |
| CNN | ≥20 | 138.68 | 373.21 |
| 12–20 | 138.45 | 372.88 | |
| 6–12 | 138.43 | 372.86 | |
| <6 | 138.82 | 373.40 | |
| DilCNN | ≥20 | 8.29 | 29.98 |
| 12–20 | 8.25 | 29.89 | |
| 6–12 | 8.23 | 29.81 | |
| <6 | 8.24 | 29.78 | |
| DilCNN int8 | ≥20 | 8.27 | 29.93 |
| 12–20 | 8.24 | 29.85 | |
| 6–12 | 8.22 | 29.77 | |
| <6 | 8.26 | 29.79 | |
| CapsToA | ≥20 | 7.63 | 11.4 |
| 12–20 | 10.15 | 14.41 | |
| 6–12 | 14.54 | 28.51 | |
| <6 | 25.56 | 55.72 | |
| CapsToA int8 | ≥20 | 16.39 | 23.68 |
| 12–20 | 19.81 | 50.29 | |
| 6–12 | 22.46 | 32.05 | |
| <6 | 43.79 | 71.08 |
| Model | SRAM | Flash | MACC | Tck | Tck/MACC | Exec Time | |
|---|---|---|---|---|---|---|---|
| [KB] | [KB] | [ms] | |||||
| DilCNN int8 | 171.50 | 120.27 | 59,120,625 | 332,758,980 | 5.628 | 4159.359 | |
| CapsToA int8 | CapsNet | 16.18 | 54.14 | 280,032 | 2,076,305 | 7.415 | 25.954 |
| DilCNN | 136.00 | 49.50 | 15,750,720 | 147,491,915 | 9.364 | 1843.551 | |
| Overall | 152.18 | 103.64 | 177,049,152 | 1,343,443,595 | 7.588 | 16,793.044 | |
| Model | Metric | ∞ | 20 dB | 16 dB | 12 dB | 8 dB | 4 dB | 2 dB |
|---|---|---|---|---|---|---|---|---|
| AIC | Median [cm] | 4.05 | 3.12 | 4.62 | 5.68 | 6.85 | 18.93 | 24.03 |
| Failure Rate | 0% | 0% | 0% | 7.7% | 23.1% | 34.6% | 23.1% | |
| STA/LTA | Median [cm] | 5.62 | 7.23 | 6.21 | Failed | Failed | Failed | Failed |
| Failure Rate | 3.8% | 0% | 34.6% | 76.9% | 92.3% | 96.2% | 88.5% | |
| DilCNN | Median [cm] | 3.21 | 3.3 | 3.69 | 3.24 | 3.76 | 4.58 | 7.67 |
| Failure Rate | 0% | 0% | 0% | 0% | 0% | 0% | 0% | |
| DilCNN int8 | Median [cm] | 2.92 | 3.22 | 3.23 | 3.64 | 4.24 | 5.54 | 7.36 |
| Failure Rate | 0% | 0% | 0% | 0% | 0% | 0% | 0% | |
| CapsToA | Median [cm] | 3.02 | 3.32 | 2.92 | 3.09 | 4.01 | 5.32 | 7.31 |
| Failure Rate | 0% | 0% | 0% | 0% | 0% | 0% | 0% | |
| CapsToA int8 | Median [cm] | 2.84 | 2.6 | 2.64 | 3.75 | 3.81 | 6.27 | 8.97 |
| Failure Rate | 0% | 0% | 0% | 0% | 0% | 0% | 7.7% |
| Ref. | Model |
MCU Deployment | Noise Analysis | Loc. Error | Pros/Cons |
|---|---|---|---|---|---|
| This work | DilCNN, CapsNet | ✓ | ✓ | 3–4 cm |
|
| [31] | CNN | ✓ | ✓ | 8 cm |
|
| [4] | CNN, CapsNet | ✗ | ✓ | 5 cm |
|
| [28] | Shallow ANN | ✗ | ✗ | 1–3 mm |
|
| [29] | PCA+SVM | ✗ | ✗ | 2–5 cm |
|
| [30] | Polynomial regressor+ ANN | ✗ | ✗ | 1–2 mm |
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Donati, G.; Zonzini, F.; De Marchi, L. Tiny Deep Learning Architectures Enabling Sensor-Near Acoustic Data Processing and Defect Localization. Computers 2023, 12, 129. https://doi.org/10.3390/computers12070129
Donati G, Zonzini F, De Marchi L. Tiny Deep Learning Architectures Enabling Sensor-Near Acoustic Data Processing and Defect Localization. Computers. 2023; 12(7):129. https://doi.org/10.3390/computers12070129
Chicago/Turabian StyleDonati, Giacomo, Federica Zonzini, and Luca De Marchi. 2023. "Tiny Deep Learning Architectures Enabling Sensor-Near Acoustic Data Processing and Defect Localization" Computers 12, no. 7: 129. https://doi.org/10.3390/computers12070129