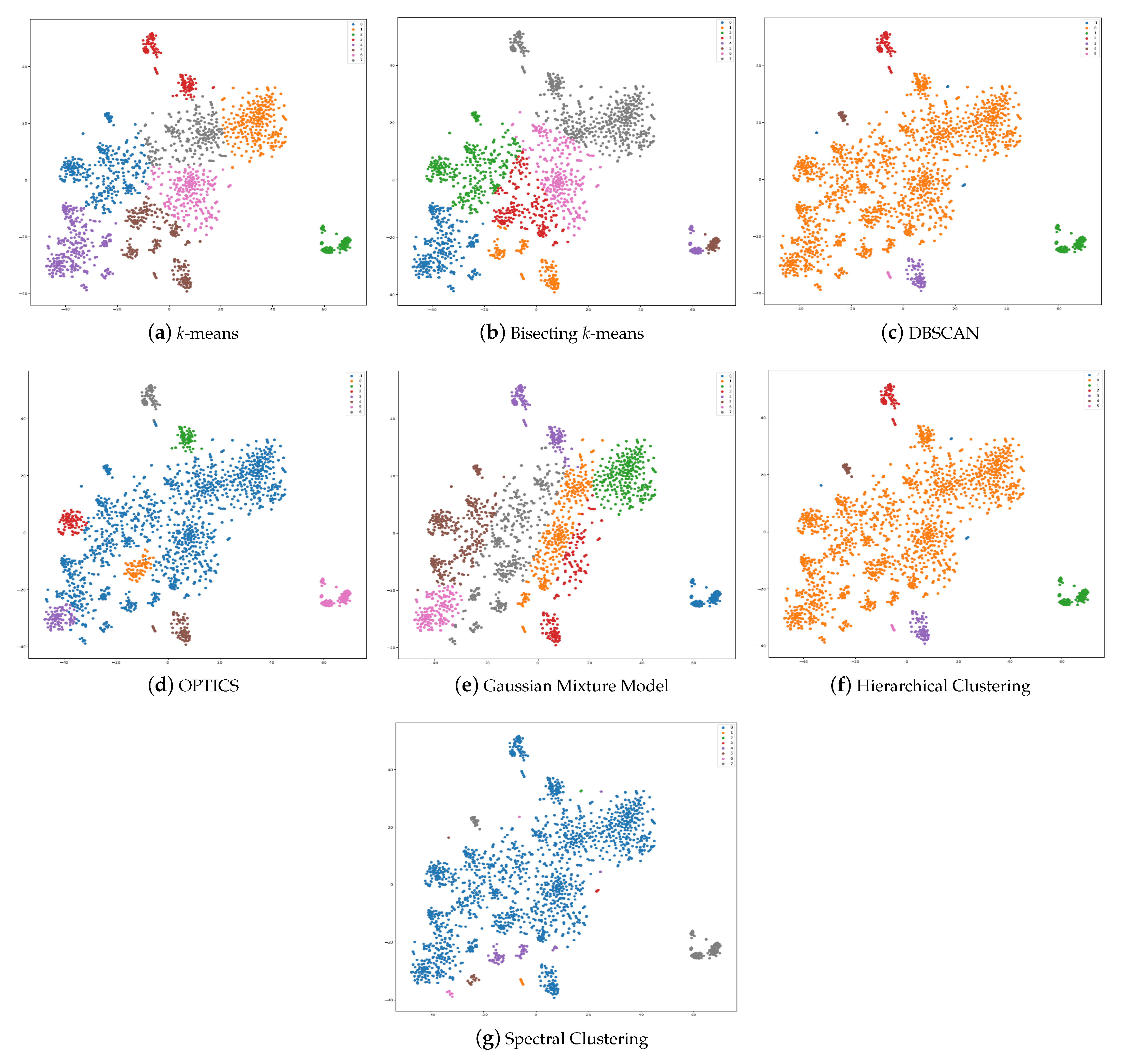
4.1. Proposed Method
In this study, the strength of relationships among active social network users is analyzed by examining data extracted from their profiles. By investigating the connections between users and the similarity of their profiles, valuable insights are gained regarding the degree of relationship strength [
34,
35]. Twitter is utilized as the data source for this analysis, providing a rich set of features extracted from user profiles. These features serve as key indicators for studying relationship strength, encompassing various aspects such as user connections and profile similarity [
36]. Notably, the similarity between two user profiles is regarded as a significant criterion for characterizing a powerful edge.
By leveraging the wealth of information available in user profiles on Twitter, this study delves into the examination of relationship strength among social network users. The analysis draws upon the connections established between users as well as the similarity of their profiles, shedding light on the dynamics and characteristics of powerful edges within the social network.
Overall, this paper focuses on addressing the problem of identifying user engagement levels based on the strength of their connections. The key steps involved in this analysis can be summarized as follows:
Data collection and network representation: The process begins by considering user profiles and extracting relevant features. These features are then used to create a graph that represents the social network.
Evaluation of user profiles: The next step involves evaluating the contribution of user profiles to the overall strength of the relationship. Various metrics and criteria are employed to assess the level of engagement.
Categorization of relationships: Based on the evaluated strength, the relationships are categorized into different levels or groups. This categorization provides insights into the varying degrees of engagement among users.
Presentation of statistical results: The study concludes by presenting statistical results and analyses related to the categorized relationships. These findings contribute to a deeper understanding of user engagement and the dynamics within the social network.
In summary, this paper employs a systematic approach that involves data collection, evaluation of user profiles, categorization of relationships, and statistical analysis to uncover the degree of user engagement based on the strength of their connections.
To determine the strength of the connections between two members, similarity features are considered, which encompass several aspects:
Common or close locations: The proximity or similarity of the locations associated with the user profiles is taken into account.
Similar scale in the number of friends: The comparison of the number of friends or connections between two user profiles helps gauge the similarity of their social network size.
Similar frequency of posts: The frequency at which users post on the platform is examined to identify similarities or patterns in their activity.
Interaction criteria: Various interaction metrics are considered, including friendship and follow relationships, as well as user mentions and retweets. These interactions indicate the level of engagement and connection between users.
By analyzing these similarity features, a score is derived for each edge, reflecting the strength of the connection between two members. The score is calculated based on the contribution of each feature, which may vary in terms of importance or weight. This scoring mechanism enables the categorization of relationships according to the calculated scores, providing insights into the varying strengths of connections within the social network.
4.2. Metrics
In the proposed method, two categories of metrics are utilized to calculate the score of each edge: similarity metrics and interaction metrics.
The similarity metrics focus on the popularity and characteristics of user accounts. These metrics include the number of followers and friends, which reflect the level of popularity and connectivity of an account. The number of tweets posted by each user is also considered, indicating their level of activity on the platform. Additionally, the geographic location of users is taken into account as a criterion of similarity. Users who are geographically closer are more likely to have a connection or friendship [
19,
24].
The interaction metrics capture the engagement and interaction between users. The mutual friendship condition is a crucial metric as it signifies a bidirectional connection, indicating a strong relationship between two users. The “following” feature is also considered, as it implies an interest in actively following the activities of another user on the social network. Mentions and replies in tweets are considered interaction features, indicating direct engagement and communication between users. Lastly, the exchange of messages, specifically the authorization from both sides to send and receive private messages, is included as a metric of interaction.
By incorporating these similarity and interaction metrics, the proposed method comprehensively captures various aspects of user engagement and connection on the social network, ultimately contributing to the calculation of the score for each edge.
4.3. Calculation of Connection Scores
The score of each edge is determined by considering the similarity and interaction metrics discussed above. The calculation process involves examining the set of collected edges and evaluating each metric based on specific conditions. The scores for the metrics are then summed up to obtain a final score for each edge.
The scores range from 0 to 10, where a score of 0 indicates no similarity or interaction between the profiles, while a score of 10 represents complete similarity and interaction.
However, not all metrics carry equal weight in determining the strength of a connection. Different weights are assigned to each metric to reflect their relative importance. The assigned weights for the metrics are presented in
Table 1.
These weights reflect the relative importance of each metric in determining the strength of the user connections. By incorporating these weights into the scoring calculation, the proposed method can effectively capture the contribution of different metrics in evaluating the strength of relationships in the social network.
The selection of weights for user connection features is a crucial aspect of our analysis. These weights determine the relative importance of different user interactions, such as retweets, replies, and mentions. While we have chosen specific weights based on established research and prior knowledge, it is important to acknowledge that different weight configurations can yield varying results and potentially introduce biases. In this paper, we aim to explore the implications of different weight configurations theoretically, considering the impact on clustering outcomes and the interpretation of user engagement patterns.
The weights assigned to each metric reflect their relative importance in determining the strength of user connections. Specifically, features such as friend count and status count are given a weight of 1, indicating their moderate contribution to the strength of the connection. The location metric, on the other hand, is assigned a weight of 2, highlighting the significance of geographical proximity in fostering stronger connections.
The metric of mutual friendship is assigned the highest weight of 3, emphasizing the importance of bidirectional connections in indicating a strong relationship. This captures the idea that a mutual friendship indicates a deeper level of connection compared to a one-sided friendship. Reciprocity in the following is considered a powerful metric and is assigned a weight of 1. It signifies that both parties have expressed interest in connecting with each other, indicating a strong connection between them.
Mentions and replies, with weights of , indicate a significant level of interaction between users. This interaction suggests a level of intimacy and engagement that goes beyond neutral or superficial connections. Lastly, both “following” and direct messages are assigned a weight of 1, denoting their contribution to the overall strength of the connection, but to a lesser extent compared to other metrics.
By assigning these weights, the proposed method takes into account the varying degrees of importance of different metrics in determining the strength of user connections, allowing for a more accurate assessment of relationship strength in the social network.
In the proposed method, the weights assigned to each metric are represented as elements of a weight vector, . Similarly, the features of each edge are collected into a feature vector, .
To calculate the total score for an edge connecting user
A to user
B in a specific Twitter subgraph, the weight vector
W is multiplied element-wise with the feature vector
V, and the resulting values are summed. Mathematically, the score is computed as follows:
After calculating the scores for each pair of edges using Equation (
1), the scores need to be normalized in order to categorize the edges effectively. The normalization process ensures that the scores are scaled to a range between 0 and 10.
The normalization formula is given by Equation (
2), where
represents the normalized score for the edge connecting node
A to node
B. The numerator in the equation represents the subtraction of the minimum score value from each calculated score, while the denominator represents the range between the maximum and minimum score values. The resulting value is then multiplied by 10 to scale it to the desired range.
By applying this normalization equation, the scores of each edge will be transformed to a standardized range of values between 0 and 10. This normalization step enables the categorization of the edges based on their normalized scores, providing a clearer representation of the strength of the connections within the social network.



_Karamitsos.jpg)





{kind=link}
{kind=link}
{kind=link}