

Agile Development Methodologies and Natural Language Processing: A Mapping Review
 , , and
, , and
Abstract
:1. Introduction
2. Background and Related Work
- Processing Techniques: This category encompasses those techniques that process the information of the text to find and extract specific data to be analyzed.
- –
- Part-of-Speech (POS) Tagging. This technique categorizes the elements of a sentence as nouns, verbs, adjectives, and adverbs. The labeling grants that differentiation of the elements of a sentence or a complete text inclusive [35].
- –
- Tokenization. The tokenization process consists of converting some text into a correspondent representative token; this token is an object that could be an array, an alphanumeric string, a number, or a customized object. Tokenizing text elements can be from a word-to-word conversion or a group conversion of sentences that share characteristics of interest. Before applying another technique, this technique is commonly used as a pre-processing or first step in NLP pipelines. Even POS Tagging has an implicit tokenization step to carry out the tagging [33].
- –
- –
- Chunking. This technique can be defined as a process used to identify parts of speech and even short phrases present in a sentence. The identification goes hand in hand with grouping these for later analysis by identifying all the nouns, verbs, adverbs, etc. [38].
- –
- Lemmatization. The goal of this technique is to reduce the inflectional and derived forms of a word to a common base form for the entire text. A word’s base or simple form is a lemma, hence the technique’s name. Unlike a simpler technique called stemming, which heuristically clips a word in the hope that clipping will obtain the base form of that word, lemmatization is carried out through morphological analysis and the use of a vocabulary dictionary for proper and efficient conversion [39].
- Text representation: This category encompasses those techniques that transform the input text to obtain a new representation of the same information on a different format.
- –
- Word2Vec. This technique focuses on word-centered processing, which can be approached as a bag of words to see the importance of words in a text, the frequency and weight that each one implies, and to seek to perform certain operations to obtain information as the main topic of a text [40].
- –
- Bag-of-Words. The bag-of-words (BoW) model is one of the simplest feature extraction techniques used in many natural language processing applications, such as text classification, sentiment analysis, and topic modeling. Bag-of-words is built by counting the number of occurrences of unique features such as words and symbols in a document. The bag-of-words model is a representation that turns arbitrary text into fixed-length vectors by counting how many times each word appears. This process is often referred to as vectorization [41].
- Extraction techniques: This category encompasses those techniques that process the input to extract desired data. The input could be text or the output of processing or text representation techniques.
- –
- Semantic Analysis. Semantic analysis is the process of understanding a text written in natural language based on context and meaning. In general, semantic analysis processes the whole text to identify the real meaning of a text using the identification of elements and to assign logical and grammar roles to each based on the complete analysis [42].
- –
- Correlation and Dependencies Analysis. A dependency analysis and a correlation analysis are closely related to parsing. Both seek to identify the elements that make up the text structure and the relationships between them, and their impact on the functionality of the wanted text message. This process can be seen as relevant to POS Tagging [43].
- –
- Sequence Analysis. This technique is based on the use of number sequencing generated by tokenizing elements of a text corpus. By assigning a number to each word present in the text, different sequences found in the text can be generated and analyzed and, in this way, locate the importance of the order of the words or the effect it has on the text when analyzing other elements of it [44].
- Grouping techniques: This category encompasses those techniques that process the input to create groups based on some specified characteristic of the data.
- –
- Clustering. It is based on locating different words or sentences and grouping them by some common characteristic; the greater the similarity of the text, the closer they will be. The topics of different sentences could define similarity, the type of language used, or even the text grouping depending on which person is referred to by each sentence. The purpose of clustering is to create a dynamic number of groups (compound of similar words or sentences) without the need to analyze all the text manually [45].
- Neural Networks. Although artificial neural networks are not an NLP technique, it was decided to group all those approaches that use different types of neural networks in this category. Some types are recurrent networks (RNN), convolutional networks (CNN), or Long Short Term Memory (LSTM). This type of approach uses neural networks for the processing of text data, either for classification or obtaining information [15].
Related Work
3. Materials and Methods
3.1. Definition of Research Questions
- RQ1. What approaches have been made to improve the agile documentation process using NLP techniques?
- RQ2. What NLP techniques and toolkits have been used to improve the documentation process of agile development?
- RQ3. How is the performance measurement of the NLP techniques when applied to support the documentation process of an agile project?
3.2. Search Strategy
- ACM Digital Library;
- ELSEVIER—ScienceDirect;
- IEEE Digital Library;
- Springer;
- Wiley.
- NLP;
- –
- Natural Language Processing;
- –
- Natural Language;
- –
- NLP.
- Agile Methodologies;
- –
- User Story;
- –
- User Stories;
- –
- Agile;
- –
- Documentation.
3.3. Selection Strategy
- Primary studies published in journals and conference proceedings
- Studies in which the main topics were NLP, Agile methodologies, and agile documentation;
- Studies published in the last ten years to consider the recent research works in the field.
- Articles which not published in English;
- Secondary or tertiary studies.
Quality Assessment
- It presents results that do not correspond to the information expressed in the paper.
- It presents results without any performance measurement.
- The paper does not present the information necessary to replicate the work.
- The paper results are based on assumptions or decisions that could be biased.
3.4. Conducting the Review
Study Selection
4. Results
4.1. Summary of Studies
4.2. (RQ1) What Approaches Have Been Made to Improve the Agile Documentation Process Using NLP?
- Improve Requirements Engineering: This category is about improving all the requirements engineering that includes recollection, analysis, validation, and management of requirements. Some works are talking about being a tool for the recollection of requirements [P19, P24, P43], these approaches focus on making more accessible the recollection process. Some approaches in this sense intend to improve the recollection using NLP tools to analyze the clients’ requirements on audio or text to produce a clear requirement or artifact with the information. Other approaches focus on enhancing the quality of the requirements on the artifacts [P5, P6, P7, P47]; some papers did this by verifying the quality of user stories and detecting redaction problems like redundancy on other artifacts.
- Artifacts Transformation: This category is about transforming an artifact, such as a user story, into another artifact corresponding with the same information, such as a use case scenario. The approaches center their efforts on specific artifact conversion, taking the original as the basis of the process. The transformations that we found in the relevant papers include the following: user stories to use case diagrams [P15], user stories to use case scenario [P10, P33], user stories to conceptual models [P8, P28, P54], use cases to class model [P2], user stories to BPM processes [P32], user stories to goal model [P30], user stories to class diagram [P40], and user stories to behavioral UML models [P50]. The methods used to transform artifacts are implemented using distinct NLP techniques.
- Agile Software Development Process: The papers grouped in this category intend to improve one or many of the elements of the agile development process. The generation of artifacts like estimation of time and cost [P13, P51], acceptance tests [P1]; and code generation of unit tests [P44]. This category includes works focused on project management [P22], prototype generation [P23] and product release [P17].
- Team Communication: This category focuses on improving team members’ communication. Some approaches focus on processing information with artificial intelligence (AI) to improve the project information and share it with the team [P31, P41]. Others focus on designing a domain language to facilitate communication among the team members [P39, P51].
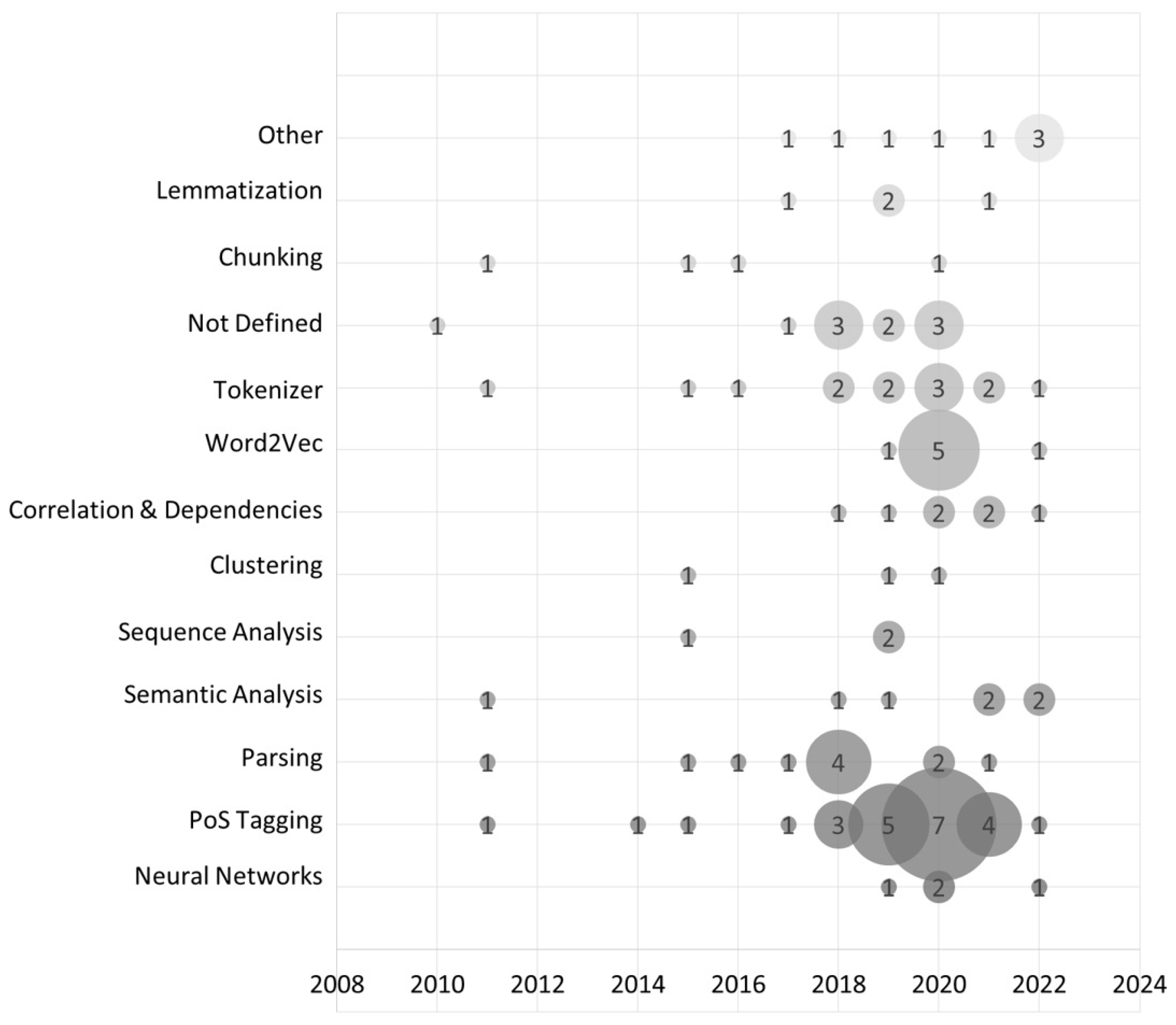
4.3. (RQ2) What NLP Techniques and Toolkits Have Been Used to Improve Any Agile Methodology?
4.3.1. NLP Techniques
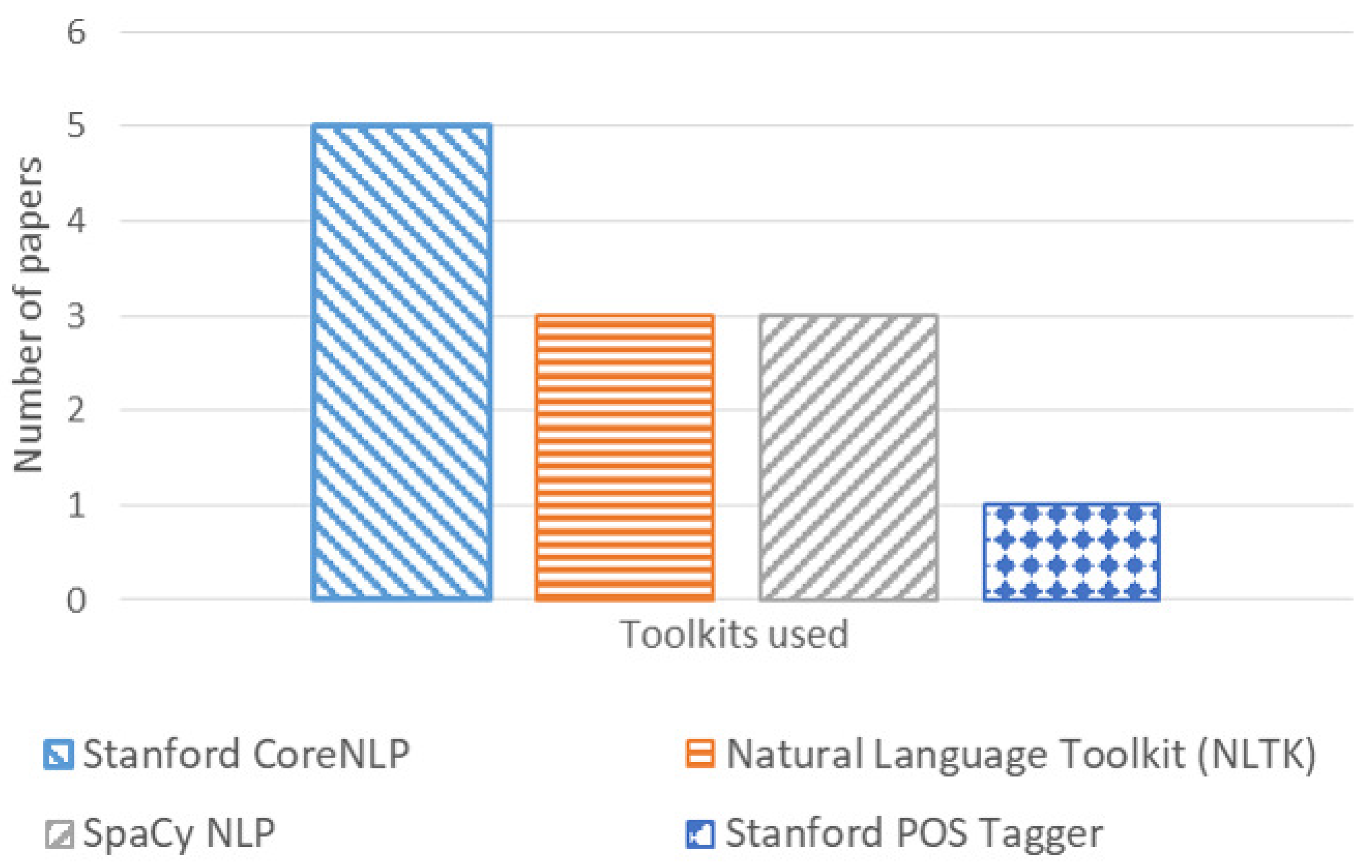
4.3.2. NLP Tools
- Stanford CoreNLP [50]: This is a complete tool to perform different operations such as tokenization, POS Tagging, and Lemmatization. It is a toolkit written in Java that can be used freely, having data dictionaries available for various languages such as English, Chinese, Spanish, French, German, Italian, and Arabic.
- Natural Language Toolkit (NLTK) [51]: NLTK is a platform written in Python that allows it to work easily and quickly with language processing. It includes various elements and libraries that allow the user to carry out various operations. This tool is free to use and has some fairly complete tutorials that allow starting from the use of language to perform complex text analysis operations.
- SpaCy [52]: This toolkit features a variety of possible operations and claims to be designed for real-world jobs. It can be used in various languages as APIs and has some precompiled features. It also seeks to have a speed of operations at the current state-of-the-art level. In the same way as the previous ones, this is a free-to-use toolkit.
- Stanford POS Tagger [53]: This software is a Java implementation of the log-linear part-of-speech taggers described in [54]. Current downloads contain three trained tagger models for English, two for Chinese and Arabic, and one for French, German, and Spanish. The tagger can be retrained in any language, given POS-annotated training text for the language.
4.4. (RQ3) How Is the Performance Measurement of the NLP Techniques When Applied to Support the Documentation Process of an Agile Project?
5. Discussion
5.1. Approaches to Improve the Agile Documentation Process Using NLP Techniques
5.2. NLP Techniques and Toolkits Used to Improve the Documentation Process of Agile Development
5.3. Performance Measurement of NLP Techniques Applied to Support the Documentation Process of Agile Development
5.4. Threats to Validity
5.4.1. Internal Validity
- Research Method: One threat to validity is the restricted access to some databases that were excluded from the selection. To overcome this threat, we collected papers from databases used frequently in software engineering research [46]. Another threat could be improper research methods, which we overcome using the guidelines proposed by Petersen et al. [32]. The different search methods of each database were also a threat mitigated with the design of a base search string adapted to each database.
- Research Questions: The set of defined research questions for this study might not cover all the possible interest areas in the field, but we defined them in a way that covers the main fundamental points of interest.
5.4.2. Conclusion Validity
- Selected articles: The article selection might be improper because of the researcher’s bias. This threat was mitigated by doing a pair search with the help of another researcher. The results were similar not only on the first search (with the search string), but also in the reviews of the title, abstract and full text.
5.4.3. Construction Validity
- Analysis: Validity of construction is the threat that experimenters can influence the results of a study based on what they expect from their experience in the field. This threat is not present in our work because we only report data founded on the selected papers without changing them.
5.4.4. External Validity
- Generalization: As Wohlin et al. said in [57], the generalization of the results to the search field is very important, this could be a threat to our study depending on which studies were selected. To mitigate this threat, we defined all the search processes in a general form that could bring us a variety of studies; this is, using distinct databases with the same search string and analyzing each result by abstract, title, and full text.
6. Conclusions and Future Work
6.1. Conclusions
6.2. Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| NLP | Natural Language Processing |
| AI | Artificial Intelligence |
| UML | Unified Modeling Language |
Appendix A. Included Studies
References
- Highsmith, J.; Cockburn, A. Agile software development: The business of innovation. Computer 2001, 34, 120–127. [Google Scholar] [CrossRef] [Green Version]
- Beck, K.; Beedle, M.; Van Bennekum, A.; Cockburn, A.; Cunningham, W.; Fowler, M.; Grenning, J.; Highsmith, J.; Hunt, A.; Jeffries, R.; et al. Manifesto for agile software development twelve principles of agile software. Zugriff 2001, 5, 2020. [Google Scholar]
- Ken, S.; Beedle, M. Agile Software Development with Scrum; Prentice Hall: Upper Saddle River, NJ, USA, 2002; Volume 1. [Google Scholar]
- Collins-Cope, M.; Stephens, M.; Rosenberg, D. Agile Development with the ICONIX Process: People, Process and Pragmatism; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Ambler, S.W. The Elements of UML(TM) 2.0 Style; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Lindstrom, L.; Jeffries, R. Extreme programming and agile software development methodologies. In IS Management Handbook; Auerbach Publications: New York, NY, USA, 2003; pp. 531–550. [Google Scholar]
- Cockburn, A. Crystal Clear: A Human-Powered Methodology for Small Teams: A Human-Powered Methodology for Small Teams; Pearson Education: Upper Saddle River, NJ, USA, 2004. [Google Scholar]
- Tom, E.; Aurum, A.; Vidgen, R. An exploration of technical debt. J. Syst. Softw. 2013, 86, 1498–1516. [Google Scholar] [CrossRef]
- Cunningham, W. The WyCash portfolio management system. ACM SIGPLAN OOPS Messenger 1992, 4, 29–30. [Google Scholar] [CrossRef]
- Bosch, J. Software architecture: The next step. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2004; Volume 3047, pp. 194–199. [Google Scholar] [CrossRef]
- Clear, T. Documentation and agile methods: Striking a balance. ACM SIGCSE Bull. 2003, 35, 12–13. [Google Scholar] [CrossRef] [Green Version]
- Codabux, Z.; Williams, B. Managing Technical Debt: An Industrial Case Study. In Proceedings of the 2013 4th International Workshop on Managing Technical Debt (MTD), San Francisco, CA, USA, 20–20 May 2013. [Google Scholar]
- Casamayor, A.; Godoy, D.; Campo, M. Mining textual requirements to assist architectural software design: A state of the art review. Artif. Intell. Rev. 2012, 38, 173–191. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Loper, E.; Bird, S. Nltk: The natural language toolkit. arXiv 2002, arXiv:cs/0205028. [Google Scholar]
- Qi, P.; Zhang, Y.; Zhang, Y.; Bolton, J.; Manning, C.D. Stanza: A Python natural language processing toolkit for many human languages. arXiv 2020, arXiv:2003.07082. [Google Scholar]
- Wang, C.; Pastore, F.; Goknil, A.; Briand, L. Automatic generation of acceptance test cases from use case specifications: An nlp-based approach. IEEE Trans. Softw. Eng. 2020, 48, 585–616. [Google Scholar] [CrossRef]
- Elallaoui, M.; Nafil, K.; Touahni, R. Automatic transformation of user stories into UML use case diagrams using NLP techniques. Procedia Comput. Sci. 2018, 130, 42–49. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, L.; Wang, Y.; Sun, J. The role of requirements engineering practices in agile development: An empirical study. In Requirements Engineering; Springer: Berlin/Heidelberg, Germany, 2014; pp. 195–209. [Google Scholar]
- Plank, B.; Sauer, T.; Schaefer, I. Supporting agile software development by natural language processing. In International Workshop on Eternal Systems; Springer: Berlin/Heidelberg, Germany, 2012; pp. 91–102. [Google Scholar]
- Lucassen, G.; Dalpiaz, F.; Van Der Werf, J.M.E.M.; Brinkkemper, S. Forging high-quality user stories: Towards a discipline for agile requirements. In Proceedings of the 2015 IEEE 23rd International Requirements Engineering Conference (RE), Ottawa, ON, Canada, 24–28 August 2015; pp. 126–135. [Google Scholar]
- Cohn, M. User Stories Applied: For Agile Software Development; Addison-Wesley Professional: Boston, MA, USA, 2004. [Google Scholar]
- Cohn, M.; Advantages of User Stories for Requirements. InformIT Network. 2004. Available online: http://www.informit.com/articles (accessed on 6 September 2021).
- Cao, L.; Ramesh, B. Agile requirements engineering practices: An empirical study. IEEE Softw. 2008, 25, 60–67. [Google Scholar] [CrossRef]
- Paetsch, F.; Eberlein, A.; Maurer, F. Requirements engineering and agile software development. In Proceedings of the WET ICE 2003, Twelfth IEEE International Workshops on Enabling Technologies: Infrastructure for Collaborative Enterprises, Linz, Austria, 9–11 June 2003; pp. 308–313. [Google Scholar]
- Batool, A.; Motla, Y.H.; Hamid, B.; Asghar, S.; Riaz, M.; Mukhtar, M.; Ahmed, M. Comparative study of traditional requirement engineering and agile requirement engineering. In Proceedings of the 2013 15th International Conference on Advanced Communications Technology (ICACT), PyeongChang, Republic of Korea, 27–30 January 2013; pp. 1006–1014. [Google Scholar]
- Ambriola, V.; Gervasi, V. Processing natural language requirements. In Proceedings of the 12th IEEE International Conference Automated Software Engineering, Incline Village, NV, USA, 1–5 November 1997; pp. 36–45. [Google Scholar]
- Jackson, M. Problems and requirements [software development]. In Proceedings of the 1995 IEEE International Symposium on Requirements Engineering (RE’95), York, UK, 27–29 March 1995; pp. 2–8. [Google Scholar]
- Liddy, E.D. Natural language processing. In Encyclopedia of Library and Information Science, 2nd ed.; Marcel Decker, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Petersen, K.; Feldt, R.; Mujtaba, S.; Mattsson, M. Systematic mapping studies in software engineering. In Proceedings of the 12th International Conference on Evaluation and Assessment in Software Engineering (EASE) 12, Bari, Italy, 26–27 June 2008; pp. 1–10. [Google Scholar]
- Pinto, A.; Gonçalo Oliveira, H.; Oliveira Alves, A. Comparing the performance of different NLP toolkits in formal and social media text. In Proceedings of the 5th Symposium on Languages, Applications and Technologies (SLATE’16), Maribor, Slovenia, 20–21 June 2016; Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik: Dagstuhl, Germany, 2016. [Google Scholar]
- Nakache, D.; Metais, E.; Timsit, J.F. Evaluation and NLP. In Proceedings of the International Conference on Database and Expert Systems Applications, Valencia, Spain, 1–4 September 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 626–632. [Google Scholar]
- Brill, E. Transformation-based error-driven learning and natural language processing: A case study in part-of-speech tagging. Comput. Linguist. 1995, 21, 543–565. [Google Scholar]
- Mitchell, D.C. Sentence parsing. In Handbook of Psycholinguistics; Elsevier: Amsterdam, The Netherlands, 1994; pp. 375–409. [Google Scholar]
- Klein, D.; Manning, C.D. Accurate unlexicalized parsing. In Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics, Sapporo Japan, 7–12 July 2003; pp. 423–430. [Google Scholar]
- Kudo, T.; Matsumoto, Y. Chunking with support vector machines. In Proceedings of the Second Meeting of the North American Chapter of the Association for Computational Linguistics, Pittsburgh, PA, USA, 2 June 2001. [Google Scholar]
- Halácsy, P.; Trón, V. Benefits of deep NLP-based Lemmatization for Information Retrieval. In Proceedings of the CLEF (Working Notes), Alicante, Spain, 20–22 September 2006. [Google Scholar]
- Tshitoyan, V.; Dagdelen, J.; Weston, L.; Dunn, A.; Rong, Z.; Kononova, O.; Persson, K.A.; Ceder, G.; Jain, A. Unsupervised word embeddings capture latent knowledge from materials science literature. Nature 2019, 571, 95–98. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Jin, R.; Zhou, Z.H. Understanding bag-of-words model: A statistical framework. Int. J. Mach. Learn. Cybern. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Maulud, D.H.; Zeebaree, S.R.; Jacksi, K.; Sadeeq, M.A.M.; Sharif, K.H. State of art for semantic analysis of natural language processing. Qubahan Acad. J. 2021, 1, 21–28. [Google Scholar] [CrossRef]
- Choi, J.D.; Tetreault, J.; Stent, A. It depends: Dependency parser comparison using a web-based evaluation tool. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1: Long Papers, pp. 387–396. [Google Scholar]
- Lin, J.C.W.; Shao, Y.; Djenouri, Y.; Yun, U. ASRNN: A recurrent neural network with an attention model for sequence labeling. Knowl.-Based Syst. 2021, 212, 106548. [Google Scholar] [CrossRef]
- Xu, J.; Wang, P.; Tian, G.; Xu, B.; Zhao, J.; Wang, F.; Hao, H. Short text clustering via convolutional neural networks. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, Denver, CO, USA, 5 June 2015; pp. 62–69. [Google Scholar]
- Raharjana, I.K.; Siahaan, D.; Fatichah, C. User Stories and Natural Language Processing: A Systematic Literature Review. IEEE Access 2021, 9, 53811–53826. [Google Scholar] [CrossRef]
- Perkusich, M.; Chaves e Silva, L.; Costa, A.; Ramos, F.; Saraiva, R.; Freire, A.; Dilorenzo, E.; Dantas, E.; Santos, D.; Gorgônio, K.; et al. Intelligent software engineering in the context of agile software development: A systematic literature review. Inf. Softw. Technol. 2020, 119, 106241. [Google Scholar] [CrossRef]
- Wagner, S.; Fernández, D.M.; Felderer, M.; Vetrò, A.; Kalinowski, M.; Wieringa, R.; Pfahl, D.; Conte, T.; Christiansson, M.T.; Greer, D.; et al. Status quo in requirements engineering: A theory and a global family of surveys. ACM Trans. Softw. Eng. Methodol. 2019, 28, 1–48. [Google Scholar] [CrossRef] [Green Version]
- Petersen, K.; Vakkalanka, S.; Kuzniarz, L. Guidelines for conducting systematic mapping studies in software engineering: An update. Inf. Softw. Technol. 2015, 64, 1–18. [Google Scholar] [CrossRef]
- Stanford CoreNLP. Available online: https://stanfordnlp.github.io/CoreNLP/ (accessed on 21 January 2022).
- Natural Language Toolkit. Available online: https://www.nltk.org/ (accessed on 21 January 2022).
- spaCy. Available online: https://spacy.io/ (accessed on 21 January 2022).
- Stanford Log-Linear Part-of-Speech Tagger. Available online: https://nlp.stanford.edu/software/tagger.shtml (accessed on 21 January 2022).
- Toutanvoa, K.; Manning, C.D. Enriching the knowledge sources used in a maximum entropy part-of-speech tagger. In Proceedings of the 2000 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, Hong Kong, China, 7–8 October 2000; pp. 63–70. [Google Scholar]
- Park, S.; Song, J.H.; Kim, Y. A neural language model for multi-dimensional textual data based on CNN-LSTM network. In Proceedings of the 2018 19th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Busan, Republic of Korea, 27–29 June 2018; pp. 212–217. [Google Scholar]
- Cook, T.D.; Campbell, D.T.; Day, A. Quasi-Experimentation: Design & Analysis Issues for Field Settings; Houghton Mifflin Boston: Boston, MA, USA, 1979; Volume 351. [Google Scholar]
- Wohlin, C.; Runeson, P.; Höst, M.; Ohlsson, M.C.; Regnell, B.; Wesslén, A. Experimentation in Software Engineering; Springer Science & Business Media: Norwell, MA, USA, 2012. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Freq. | Studies |
|---|---|---|
| Improve Requirements Engineering | 24 | [P3], [P4], [P5], [P6], [P7], [P11], [P16], [P18], [P19], [P20], [P24], [P25], [P27], [P29], [P36], [P37], [P43], [P46], [P47], [P48], [P49], [P52], [P55], [P56] |
| Transformation of Artifacts | 11 | [P2], [P8], [P10], [P15], [P28], [P30], [P32], [P33], [P40], [P50], [P54] |
| Agile Software Development Process | 15 | [P1], [P9], [P12], [P13], [P17], [P21], [P22], [P23], [P26], [P34], [P38], [P42], [P44], [P45], [P53] |
| Team Communication | 6 | [P14], [P31], [P35], [P39], [P41], [P51] |
| Category | NLP Techniques | Freq. | Studies |
|---|---|---|---|
| Processing Techniques | POS Tagging | 23 | [P2], [P3], [P5], [P7], [P10], [P11], [P15], [P18], [P19], [P27], [P28], [P29], [P31], [P33], [P37], [P39], [P40], [P42], [P44], [P46], [P47], [P50], [P52] |
| Tokenizer | 13 | [P2], [P5], [P6], [P11], [P14], [P19], [P27], [P39], [P42], [P44], [P46], [P50], [P52] | |
| Parsing | 11 | [P2], [P5], [P6], [P7], [P10], [P11], [P13], [P14], [P30], [P34], [P50] | |
| Lemmatization | 4 | [P7], [P19], [P27], [P50] | |
| Text Representation | Word2Vec | 7 | [P21], [P36], [P37], [P42], [P44], [P45], [P53] |
| Extraction techniques | Semantic Analysis | 5 | [P16], [P25], [P41], [P47] |
| Correlation and Dependencies Analysis | 6 | [P10], [P27], [P32], [P33], [P50], [P52] | |
| Sequence Analysis | 4 | [P4], [P20], [P24], [P55] | |
| Grouping techniques | Clustering | 3 | [P4], [P24], [P25] |
| Uncategorized | Neural Networks | 3 | [P22], [P36], [P37] |
| Other | 9 | [P7], [P14], [P17], [P35], [P48], [P49], [P51], [P54], [P56] | |
| Not Defined | 10 | [P1], [P8], [P9], [P12], [P23], [P26], [P35], [P38], [P41], [P43] |
| NLP Tool | Features | Freq. | Studies |
|---|---|---|---|
| Stanford CoreNLP | Tokenization, Part-Of-Speech (POS) Tagging, Lemmatization | 5 | [P6], [P9], [P11], [P40], [P42] |
| Natural Language Toolkit (NLTK) | Tokenization, Part-Of-Speech (POS) Tagging, Dependency Parsing, Lemmatization | 3 | [P5], [P6], [P35] |
| SpaCy NLP | Tokenization, Part-Of-Speech (POS) Tagging, Dependency Parsing, Lemmatization, Similarity Analysis | 3 | [P10], [P18], [P52] |
| Stanford POS Tagger | Part-Of-Speech (POS) Tagging | 1 | [P22] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quintana, M.A.; Palacio, R.R.; Soto, G.B.; González-López, S. Agile Development Methodologies and Natural Language Processing: A Mapping Review. Computers 2022, 11, 179. https://doi.org/10.3390/computers11120179
Quintana MA, Palacio RR, Soto GB, González-López S. Agile Development Methodologies and Natural Language Processing: A Mapping Review. Computers. 2022; 11(12):179. https://doi.org/10.3390/computers11120179
Chicago/Turabian StyleQuintana, Manuel A., Ramón R. Palacio, Gilberto Borrego Soto, and Samuel González-López. 2022. "Agile Development Methodologies and Natural Language Processing: A Mapping Review" Computers 11, no. 12: 179. https://doi.org/10.3390/computers11120179