
Proposal and Definition of an Intelligent Clinical Decision Support System Applied to the Screening and Early Diagnosis of Breast Cancer
 , , , ,
, , , ,
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Definition of the System
2.1.1. Database Description
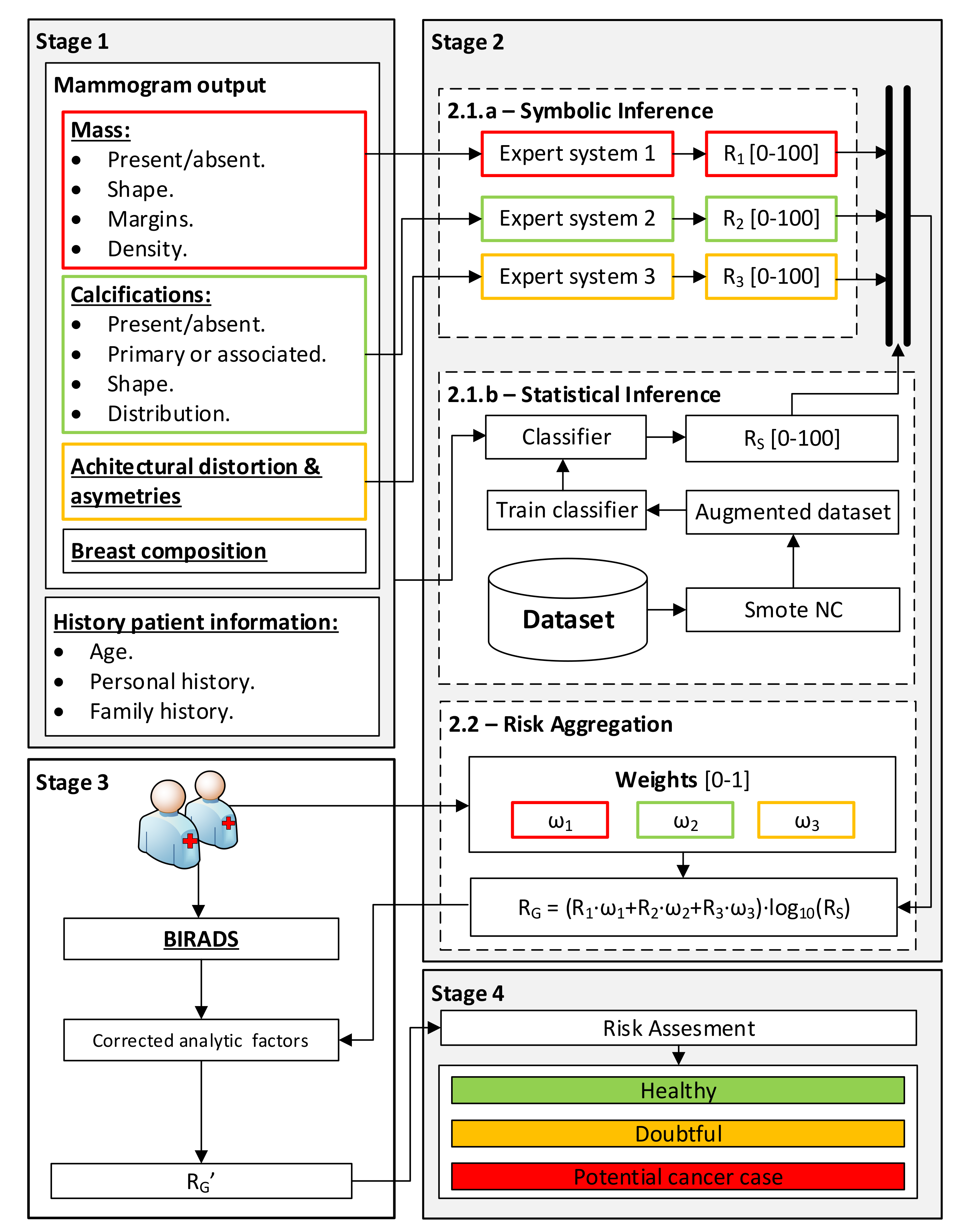
2.1.2. Conceptual System Design
Gathering and Interpretation of Patient Information
Data Processing
- Stage 2.1.a—Determination of Symbolic Risks: once the information regarding the findings in the mammogram, introduced in Stage 1, has been gathered, the processing is carried out using a series of expert systems that work concurrently [12,13,17,25,26,27] which are based on Mamdani-type fuzzy inference systems [29,30,31]. Each of these expert systems is assigned the processing of the data subsets associated with the different findings (masses, calcifications, asymmetries and distortions) in order to obtain a series of risk indicators, the Symbolic Risks (R1, R2 and R3), with values ranging between 0 and 100, each of them related to the risk of developing breast cancer.
- Stage 2.1.b—Statistical Risk determination: In parallel to Stage 2.1.a, Stage 2.1.b carries out the processing of all the collected data, both those in Table 2 and Table 3, excluding the BI-RADS category determined by the expert, by means of a machine learning classification algorithm [32]. According to the nature and quality of these data, they may be subjected to a normalization process with a possible synthetic scaling of the sample [25]. The algorithm training is based on the dataset introduced in Section 2.1.1, where each case is labeled as either “cancer” or “non-cancer”. This allocation is indisputable within the study group since all the patients underwent a biopsy and their real condition is known. This considerably reduces the epistemological and interaction uncertainty of the training data itself. Once the model has been trained, a new patient’s data are presented, so that the model may determine a percentage indicator of risk at the output, the so-called Statistical Risk (Rs), ranging from 0 to 100, which is intended to indicate the risk that the patient may suffer from breast cancer.
- Stage 2.2—Risk aggregation and Global Risk determination: Having obtained the Symbolic Risks (R1, R2 and R3) as well as the Statistical Risk (Rs), they are then aggregated by means of the expression shown in Equation (1), which allows for the calculation of the Global Risk (RG). Said expression is based on the product of the weighted sum of the Symbolic Risks and the decimal logarithm of the Statistical Risk. The first term, the weighted sum, provides a measure of risk that brings together the different Symbolic Risk indicators according to the potential importance given by the medical team to each of the groups of findings (masses, calcifications and asymmetries, and distortions of the architecture). Meanwhile, the second term has a multiplicative effect, increasing the level of risk previously obtained in the event that the patient under analysis presents a similar pattern to that of a patient with breast cancer within the sample with which the statistical model was constructed. Note that in the event that any of the groups of findings used to calculate the Symbolic Risks is absent in the case under study, meaning that any of the risk indicators is null, an equitable weight redistribution will be performed among the rest of the findings. Alternatively, a new weight redistribution proposed by the medical team will be considered. Furthermore, it is also worth mentioning that the Global Risk value ranges between zero and one hundred; in case of a higher value, despite the multiplicative effect of the logarithm term, its maximum value shall be one hundred.
Global Risk Correction
Generation of Warnings and Decision Making
- Healthy case: Refer the patient for routine review;
- Dubious case: Reconsider the patient’s case, consider performing other tests as well as summoning the patient for a new visit in a period of time to be specified;
- Potential breast cancer case: Perform confirmatory tests.
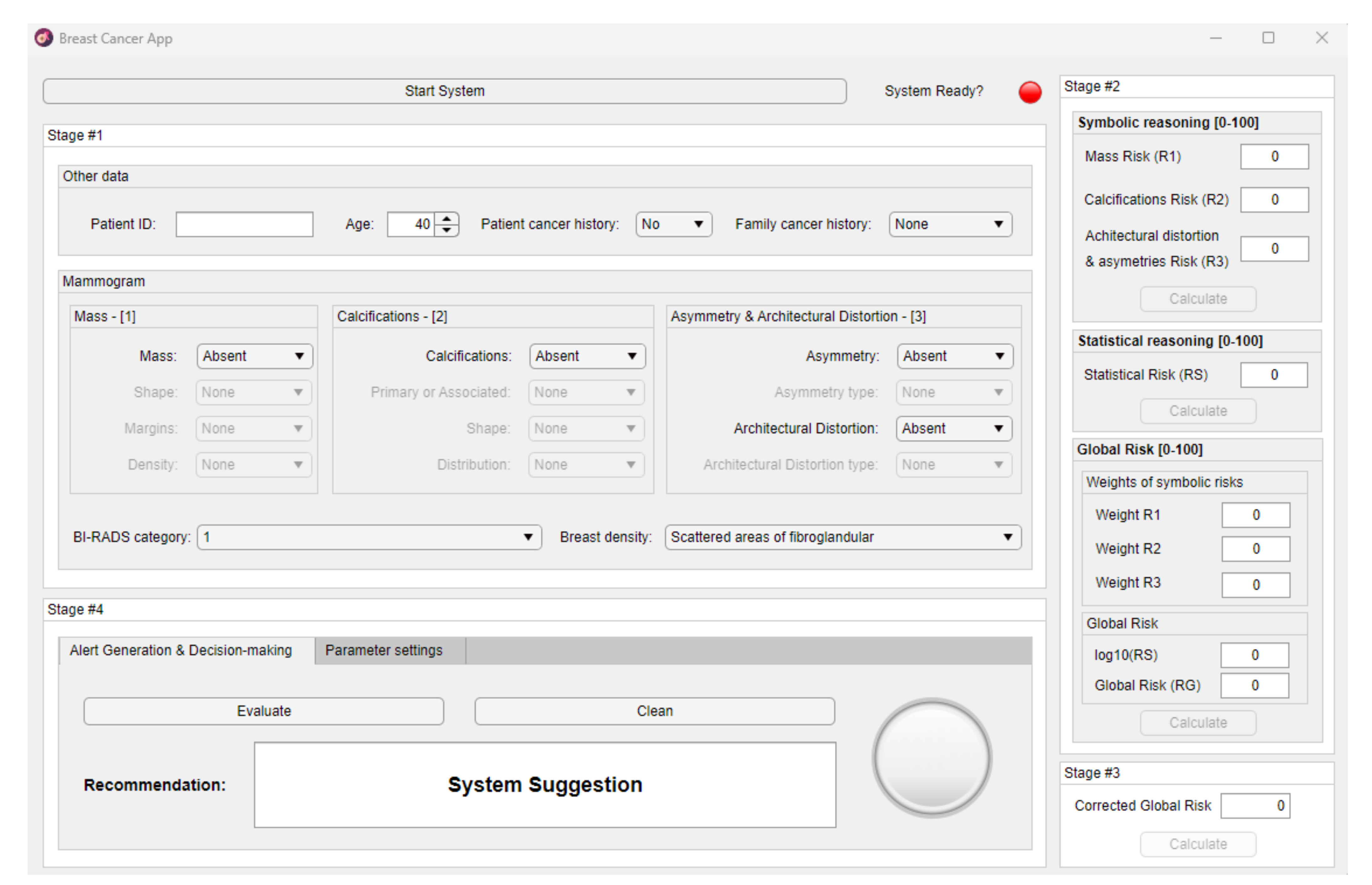
2.2. Implementation of the System
2.2.1. Data Collection
2.2.2. Data Processing
Determination of the Symbolic Risks
Determination of the Statistical Risk
Determination of the Global Risk
Determination of the Corrected Global Risk
2.2.3. Generation of Warnings and Decision Making
2.2.4. Analysis of Results
3. Results
3.1. Data Collection
3.2. Data Processing
3.3. Global Risk Correction
3.4. Warning Generation and Decision Making
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arnold, M.; Morgan, E.; Rumgay, H.; Mafra, A.; Singh, D.; Laversanne, M.; Vignat, J.; Gralow, J.R.; Cardoso, F.; Siesling, S.; et al. Current and Future Burden of Breast Cancer: Global Statistics for 2020 and 2040. Breast 2022, 66, 15–23. [Google Scholar] [CrossRef] [PubMed]
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Wilkinson, L.; Gathani, T. Understanding Breast Cancer as a Global Health Concern. Br. J. Radiol. 2021, 95, 20211033. [Google Scholar] [CrossRef]
- Sickles, E.A.; D’Orsi, C.J.; Bassett, L.W.; Appleton, C.M.; Berg, W.A.; Burnside, E.S.; Feig, S.A.; Gavenonis, S.C.; Newell, M.S.; Trinh, M.M. BI-RADS Del ACR: Mamografía. In Atlas BI-RADS del ACR, Sistema Normalizado para la Redacción de Informes de Estudios por Imágenes de la Mama; Colegio Estadounidense de Radiología: Reston, VA, USA, 2013. [Google Scholar]
- Elmore, J.G.; Jackson, S.L.; Abraham, L.; Miglioretti, D.L.; Carney, P.A.; Geller, B.M.; Yankaskas, B.C.; Kerlikowske, K.; Onega, T.; Rosenberg, R.D.; et al. Variability in Interpretive Performance at Screening Mammography and Radiologists’ Characteristics Associated with Accuracy. Radiology 2009, 253, 641–651. [Google Scholar] [CrossRef] [PubMed]
- Elmore, J.G.; Wells, C.K.; Lee, C.H.; Howard, D.H.; Feinstein, A.R. Variability in Radiologists’ Interpretations of Mammograms. N. Engl. J. Med. 1994, 331, 1493–1499. [Google Scholar] [CrossRef] [PubMed]
- Beam, C.A. Variability in the Interpretation of Screening Mammograms by US Radiologists. Arch. Intern. Med. 1996, 156, 209. [Google Scholar] [CrossRef]
- Anooj, P.K. Clinical Decision Support System: Risk Level Prediction of Heart Disease Using Weighted Fuzzy Rules. J. King Saud Univ.—Comput. Inf. Sci. 2012, 24, 27–40. [Google Scholar] [CrossRef] [Green Version]
- Montgomery, A.A.; Fahey, T.; Peters, T.J.; MacIntosh, C.; Sharp, D.J. Evaluation of Computer Based Clinical Decision Support System and Risk Chart for Management of Hypertension in Primary Care: Randomised Controlled Trial. Br. Med. J. 2000, 320, 686–690. [Google Scholar] [CrossRef] [Green Version]
- Hermsen, E.D.; VanSchooneveld, T.C.; Sayles, H.; Rupp, M.E. Implementation of a Clinical Decision Support System for Antimicrobial Stewardship. Infect. Control Hosp. Epidemiol. 2012, 33, 412–415. [Google Scholar] [CrossRef]
- Uzoka, F.M.E.; Osuji, J.; Obot, O. Clinical Decision Support System (DSS) in the Diagnosis of Malaria: A Case Comparison of Two Soft Computing Methodologies. Expert Syst. Appl. 2011, 38, 1537–1553. [Google Scholar] [CrossRef]
- Casal-Guisande, M.; Comesaña-Campos, A.; Cerqueiro-Pequeño, J.; Bouza-Rodríguez, J.-B. Design and Development of a Methodology Based on Expert Systems, Applied to the Treatment of Pressure Ulcers. Diagnostics 2020, 10, 614. [Google Scholar] [CrossRef] [PubMed]
- Comesaña-Campos, A.; Casal-Guisande, M.; Cerqueiro-Pequeño, J.; Bouza-Rodríguez, J.B. A Methodology Based on Expert Systems for the Early Detection and Prevention of Hypoxemic Clinical Cases. Int. J. Environ. Res. Public Health 2020, 17, 8644. [Google Scholar] [CrossRef] [PubMed]
- Casal-Guisande, M.; Cerqueiro-Pequeño, J.; Comesaña-Campos, A.; Bouza-Rodríguez, J.B. Proposal of a Methodology Based on Expert Systems for the Treatment of Diabetic Foot Condition. In Proceedings of the Eighth International Conference on Technological Ecosystems for Enhancing Multiculturality, Association for Computing Machinery, Salamanca, Spain, 21 October 2020; pp. 491–495. [Google Scholar]
- Berkan Sesen, M.; Nicholson, A.E.; Banares-Alcantara, R.; Kadir, T.; Brady, M. Bayesian Networks for Clinical Decision Support in Lung Cancer Care. PLoS ONE 2013, 8, 82349. [Google Scholar] [CrossRef] [Green Version]
- Wagholikar, K.B.; MacLaughlin, K.L.; Henry, M.R.; Greenes, R.A.; Hankey, R.A.; Liu, H.; Chaudhry, R.C. Clinical Decision Support with Automated Text Processing for Cervical Cancer Screening. J. Am. Med. Inform. Assoc. 2012, 19, 833–839. [Google Scholar] [CrossRef] [Green Version]
- Casal-Guisande, M.; Torres-Durán, M.; Mosteiro-Añón, M.; Cerqueiro-Pequeño, J.; Bouza-Rodríguez, J.-B.; Fernández-Villar, A.; Comesaña-Campos, A. Design and Conceptual Proposal of an Intelligent Clinical Decision Support System for the Diagnosis of Suspicious Obstructive Sleep Apnea Patients from Health Profile. Int. J. Environ. Res. Public Health 2023, 20, 3627. [Google Scholar] [CrossRef] [PubMed]
- Sesen, M.B.; Peake, M.D.; Banares-Alcantara, R.; Tse, D.; Kadir, T.; Stanley, R.; Gleeson, F.; Brady, M. Lung Cancer Assistant: A Hybrid Clinical Decision Support Application for Lung Cancer Care. J. R. Soc. Interface 2014, 11, 20140534. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cooley, M.E.; Blonquist, T.M.; Catalano, P.J.; Lobach, D.F.; Halpenny, B.; McCorkle, R.; Johns, E.B.; Braun, I.M.; Rabin, M.S.; Mataoui, F.Z.; et al. Feasibility of Using Algorithm-Based Clinical Decision Support for Symptom Assessment and Management in Lung Cancer. J. Pain Symptom Manag. 2015, 49, 13–26. [Google Scholar] [CrossRef] [PubMed]
- Fernandes, A.S.; Alves, P.; Jarman, I.H.; Etchells, T.A.; Fonseca, J.M.; Lisboa, P.J.G. A Clinical Decision Support System for Breast Cancer Patients. IFIP Adv. Inf. Commun. Technol. 2010, 314, 122–129. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, P.; Dutra, I.; Salvini, R.; Burnside, E. Interpretable Models to Predict Breast Cancer. In Proceedings of the 2016 IEEE International Conference on Bioinformatics and Biomedicine, BIBM 2016, Shenzhen, China, 15–18 December 2016; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 1507–1511. [Google Scholar]
- Alaa, A.M.; Moon, K.H.; Hsu, W.; van der Schaar, M. ConfidentCare: A Clinical Decision Support System for Personalized Breast Cancer Screening. IEEE Trans. Multimed. 2016, 18, 1942–1955. [Google Scholar] [CrossRef] [Green Version]
- Jiang, X.; Wells, A.; Brufsky, A.; Neapolitan, R. A Clinical Decision Support System Learned from Data to Personalize Treatment Recommendations towards Preventing Breast Cancer Metastasis. PLoS ONE 2019, 14, e0213292. [Google Scholar] [CrossRef] [Green Version]
- Skevofilakas, M.T.; Nikita, K.S.; Templaleksis, P.H.; Birbas, K.N.; Kaklamanos, I.G.; Bonatsos, G.N. A Decision Support System for Breast Cancer Treatment Based on Data Mining Technologies and Clinical Practice Guidelines. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology, Shanghai, China, 1–4 September 2005; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2005; Volume 7, pp. 2429–2432. [Google Scholar]
- Casal-Guisande, M.; Comesaña-Campos, A.; Dutra, I.; Cerqueiro-Pequeño, J.; Bouza-Rodríguez, J.-B. Design and Development of an Intelligent Clinical Decision Support System Applied to the Evaluation of Breast Cancer Risk. J. Pers. Med. 2022, 12, 169. [Google Scholar] [CrossRef] [PubMed]
- Cerqueiro-Pequeño, J.; Comesaña-Campos, A.; Casal-Guisande, M.; Bouza-Rodríguez, J.-B. Design and Development of a New Methodology Based on Expert Systems Applied to the Prevention of Indoor Radon Gas Exposition Risks. Int. J. Environ. Res. Public Health 2020, 18, 269. [Google Scholar] [CrossRef] [PubMed]
- Casal-Guisande, M.; Bouza-Rodríguez, J.-B.; Cerqueiro-Pequeño, J.; Comesaña-Campos, A. Design and Conceptual Development of a Novel Hybrid Intelligent Decision Support System Applied towards the Prevention and Early Detection of Forest Fires. Forests 2023, 14, 172. [Google Scholar] [CrossRef]
- Breast Imaging Reporting & Data System | American College of Radiology. Available online: https://www.acr.org/Clinical-Resources/Reporting-and-Data-Systems/Bi-Rads (accessed on 28 May 2021).
- Mamdani, E.H. Advances in the Linguistic Synthesis of Fuzzy Controllers. Int. J. Man. Mach. Stud. 1976, 8, 669–678. [Google Scholar] [CrossRef]
- Mamdani, E.H. Application of Fuzzy Logic to Approximate Reasoning Using Linguistic Synthesis. IEEE Trans. Comput. 1977, C–26, 1182–1191. [Google Scholar] [CrossRef]
- Mamdani, E.H.; Assilian, S. An Experiment in Linguistic Synthesis with a Fuzzy Logic Controller. Int. J. Man. Mach. Stud. 1975, 7, 1–13. [Google Scholar] [CrossRef]
- Wasserman, L. All of Statistics: A Concise Course in Statistical Inference; Springer: New York, NY, USA, 2004; Volume 26, ISBN 978-0-387-21736-9. [Google Scholar]
- Hevner, A.R.; March, S.T.; Park, J.; Ram, S. Design Science in Information Systems Research. MIS Q. 2004, 28, 75–105. [Google Scholar] [CrossRef] [Green Version]
- Hevner, A.R.; Chatterjee, S. Design Research in Information Systems: Theory and Practice; Springer: New York, NY, USA, 2010; ISBN 978-1-4419-6107-5. [Google Scholar]
- MATLAB App Designer—MATLAB & Simulink. Available online: https://es.mathworks.com/products/matlab/app-designer.html (accessed on 10 August 2022).
- Fuzzy Logic Toolbox—MATLAB. Available online: https://www.mathworks.com/products/fuzzy-logic.html (accessed on 1 November 2022).
- Classification Learner. Available online: https://www.mathworks.com/help/stats/classificationlearner-app.html (accessed on 18 October 2022).
- Imbalanced-Learn. Available online: https://imbalanced-learn.org/dev/index.html (accessed on 18 October 2022).
- Ross, T.J. Fuzzy Logic with Engineering Applications, 3rd edit.; John Wiley & Sons, Ltd.: Chichester, UK, 2010; ISBN 9781119994374. [Google Scholar]
- Agresti, A. Categorical Data Analysis; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2002; ISBN 0471360937. [Google Scholar]
- Powers, D.; Xie, Y. Statistical Methods for Categorical Data Analysis; Emerald Group Publishing: Bingley, UK, 2008. [Google Scholar]
- Mohammed, A.J.; Hassan, M.M.; Kadir, D.H. Improving Classification Performance for a Novel Imbalanced Medical Dataset Using Smote Method. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 3161–3172. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-Validation. Encycl. Database Syst. 2009, 532–538. [Google Scholar] [CrossRef]
- From the Lab Bench to the Marketplace: Improving Technology Transfer: Hearing Charter; U.S. House of Representatives Committee on Science and Technology, Subcommittee on Research and Science Education: Washington, DC, USA, 2010.
- Kumari, R.; Srivastava, S. Machine Learning: A Review on Binary Classification. Int. J Comput. Appl. 2017, 160, 11–15. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; Wiley: Hoboken, NJ, USA, 2000. [Google Scholar]
- Boughorbel, S.; Jarray, F.; El-Anbari, M. Optimal Classifier for Imbalanced Data Using Matthews Correlation Coefficient Metric. PLoS ONE 2017, 12, e0177678. [Google Scholar] [CrossRef] [PubMed]
- Chicco, D.; Jurman, G. The Advantages of the Matthews Correlation Coefficient (MCC) over F1 Score and Accuracy in Binary Classification Evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guilford, J.P. Psychometric Methods; McGraw-Hill: New York, NY, USA, 1954. [Google Scholar]
- Cox, D.R. Principles of Statistical Inference; Cambridge University Press: New York, NY, USA, 2006; ISBN 9780511813559. [Google Scholar]
- Thunnissen, D.P. Propagating and Mitigating Uncertainty in the Design of Complex Multidisciplinary Systems; California Institute of Technology: Pasadena, CA, USA, 2005. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Patients | 130 |
| Number of biopsied patients | 130 |
| Confirmed cancer cases | 21 |
| Healthy individuals (controls) | 109 |
| Average age | 55.2 |
| Number of criteria | 13 Mass (shape, margins, density), calcifications (type, shape, distribution), asymmetries (type), distortion (type), breast tissue density, BI-RADS category, age, personal history and family history |
| Nature of the criteria | Quantitative and qualitative |
| Data | Data Type | Commentary |
|---|---|---|
| Age | Numeric | - |
| Patient with cancer history | Categorical | Yes, no and N/A. |
| Patient with family history of cancer | Categorical | None, minor, major and N/A. |
| Subgroup | Data | Type of Data | Commentary |
|---|---|---|---|
| Mass | Shape | Categorical | None, oval, round, lobulated and irregular. |
| Margins | Categorical | None, circumscribed, obscured, micro-lobulated, indistinct and spiculated. | |
| Density | Categorical | None, equal density, low density and high density. | |
| Calcifications | Type | Categorical | None, primary and associated. |
| Shape | Categorical | None, skin, vascular, coarse or “popcorn-like”, large rod-like, round, rim, dystrophic, milk of calcium, suture, amorphous, coarse heterogeneous, fine pleomorphic, fine linear or fine linear branching. | |
| Distribution | Categorical | None, diffuse, regional, grouped, linear and segmental. | |
| Asymmetries and distortions | Type of asymmetry | Categorical | None, missing, focal and developing. |
| Type of distortion | Categorical | None, primary and associated. | |
| Breast tissue density | - | Categorical | Missing, fatty, scattered areas of fibro glandular, heterogeneously dense and extremely dense. |
| BI-RADS category | - | Categorical | 0, 1, 2, 3, 4.a, 4.b, 4.c, 5 and 6. |
| BI-RADS | Weighting Factor () |
| 1 | |
| 2 | |
| 3 | |
| 4A | |
| 4B | |
| 4C | |
| 5 | |
| 6 |
| Toolbox | Commentary |
|---|---|
| App Designer [35] | Used for the design and development of the graphical user interface of the software artifact. |
| Fuzzy Logic Toolbox [36] | Used for the implementation of inference engines based on fuzzy logic. |
| Classification Learner [37] | Used for the training of classification machine learning algorithms. Allows massive and simultaneous testing of a wide variety of algorithms, making it easier for the user to select the best alternative. |
| Expert System 1—Masses | |
| Antecedents | Consequents [0, 100] |
| Present/absent Shape Margins Density | R1 |
| Expert System 2—Calcifications | |
| Antecedents | Consequents [0, 100] |
| Present/absent Type Shape Distribution | R2 |
| Expert System 3—Architectural Distortion and Asymmetries | |
| Antecedents | Consequents [0, 100] |
| Asymmetry present/absent Type of asymmetry Distortion of the architecture present/absent Type of distortion | R3 |
| Inference Engine Component | Type |
|---|---|
| Fuzzy structure | Mamdani-type |
| Defuzzification method | Centroid [39] |
| Implication method | MIN |
| Aggregation method | MAX |
| State | Threshold |
|---|---|
| Healthy case | Corrected Global Risk < 40 |
| Dubious case | 40 ≤ Corrected Global Risk < 60 |
| Potential case | Corrected Global Risk ≥ 60 |
| Global Risk | Corrected Global Risk | |
|---|---|---|
| Sensitivity | 90.5% | 100% |
| False negative rate | 9.52% | 0% |
| Specificity | 89.81% | 60.19% |
| False positive rate | 10.19% | 39.81% |
| Mcc | 0.7 | 0.44 |
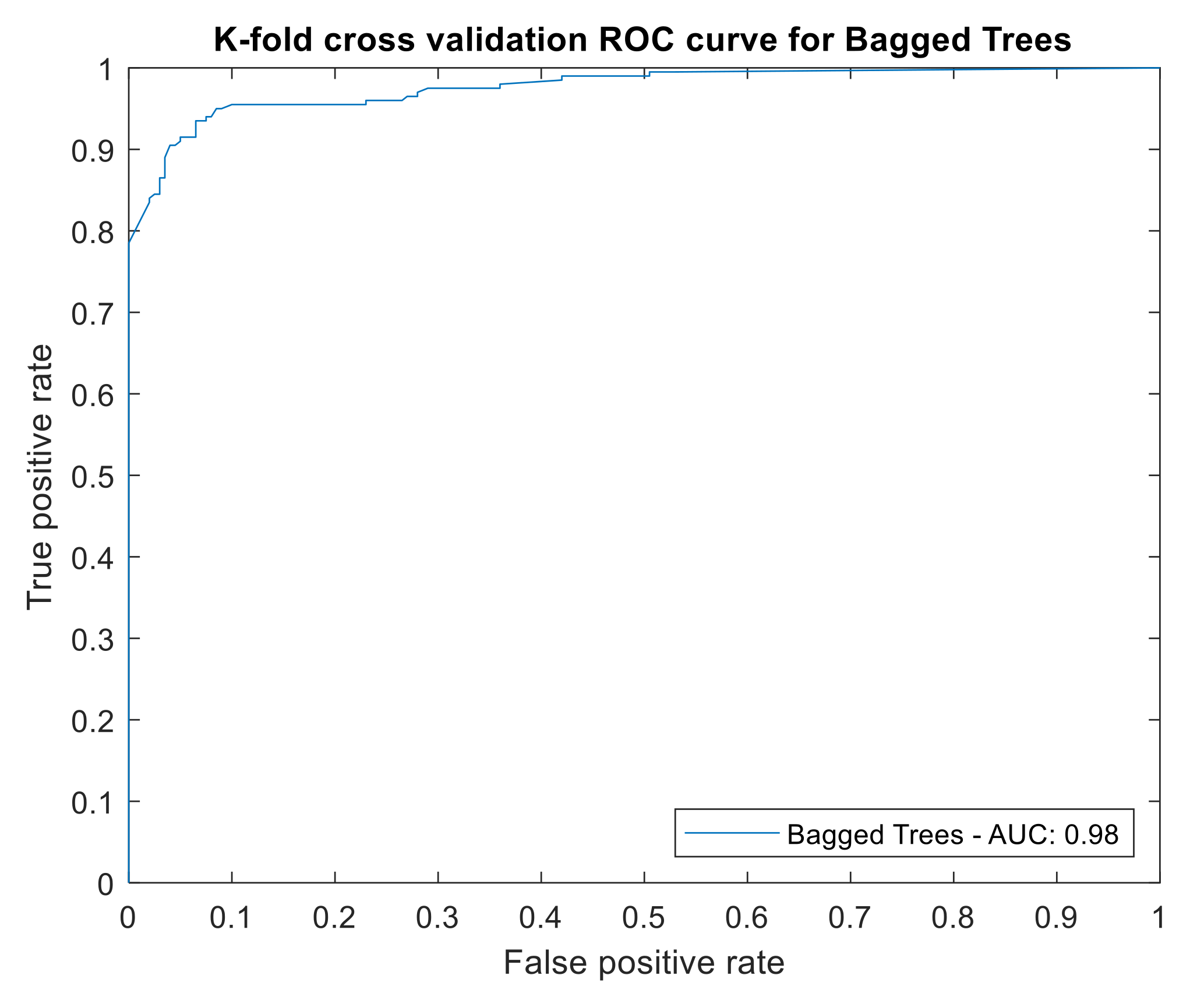
| AUC | 0.91 | 0.78 |
 | ||
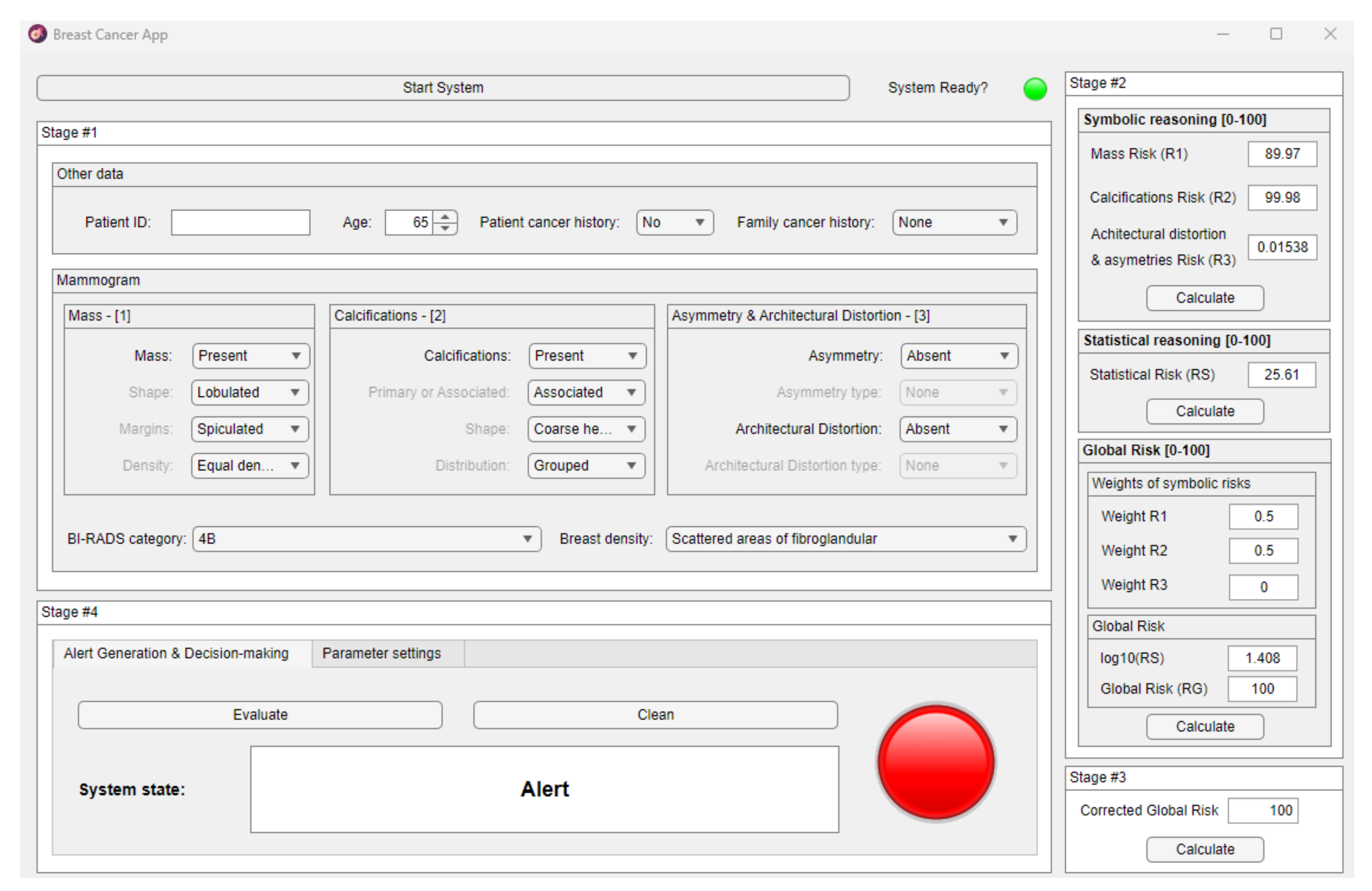
| Mammogram | ||
| Type of finding | Characteristic | Value |
| Mass | Present/absent | Present |
| Shape | Irregular | |
| Margins | Spiculated | |
| Density | Homogeneous | |
| Calcifications | Present/absent | Present |
| Primary/associated | Associated | |
| Shape | Coarse heterogeneous | |
| Distribution | Grouped | |
| Asymmetry | Present/absent | Absent |
| Type | - | |
| Architectural Distortion | Present/absent | Absent |
| Primary/associated | - | |
| Breast density | - | Heterogeneously dense |
| BI-RADS category | - | 4B |
| Other data | ||
| Data | Value | |
| Age | 65 | |
| Patient history | No | |
| Family history | No | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Casal-Guisande, M.; Álvarez-Pazó, A.; Cerqueiro-Pequeño, J.; Bouza-Rodríguez, J.-B.; Peláez-Lourido, G.; Comesaña-Campos, A. Proposal and Definition of an Intelligent Clinical Decision Support System Applied to the Screening and Early Diagnosis of Breast Cancer. Cancers 2023, 15, 1711. https://doi.org/10.3390/cancers15061711
Casal-Guisande M, Álvarez-Pazó A, Cerqueiro-Pequeño J, Bouza-Rodríguez J-B, Peláez-Lourido G, Comesaña-Campos A. Proposal and Definition of an Intelligent Clinical Decision Support System Applied to the Screening and Early Diagnosis of Breast Cancer. Cancers. 2023; 15(6):1711. https://doi.org/10.3390/cancers15061711
Chicago/Turabian StyleCasal-Guisande, Manuel, Antía Álvarez-Pazó, Jorge Cerqueiro-Pequeño, José-Benito Bouza-Rodríguez, Gustavo Peláez-Lourido, and Alberto Comesaña-Campos. 2023. "Proposal and Definition of an Intelligent Clinical Decision Support System Applied to the Screening and Early Diagnosis of Breast Cancer" Cancers 15, no. 6: 1711. https://doi.org/10.3390/cancers15061711