
Enhancing Triage Efficiency and Accuracy in Emergency Rooms for Patients with Metastatic Prostate Cancer: A Retrospective Analysis of Artificial Intelligence-Assisted Triage Using ChatGPT 4.0
 , , , , and
, , , , and
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Design and Patient Selection
2.2. Data Collection
2.3. Outcomes
2.4. Statistical Analysis
3. Results
3.1. Patient Characteristics
3.2. Sensitivity and Specificity of ChatGPT When Compared to ER Physicians
3.3. Agreement and Comprehensiveness of Diagnoses between ChatGPT and ER Physicians
3.4. The Prediction Value of the ESI Score Generated by ChatGPT
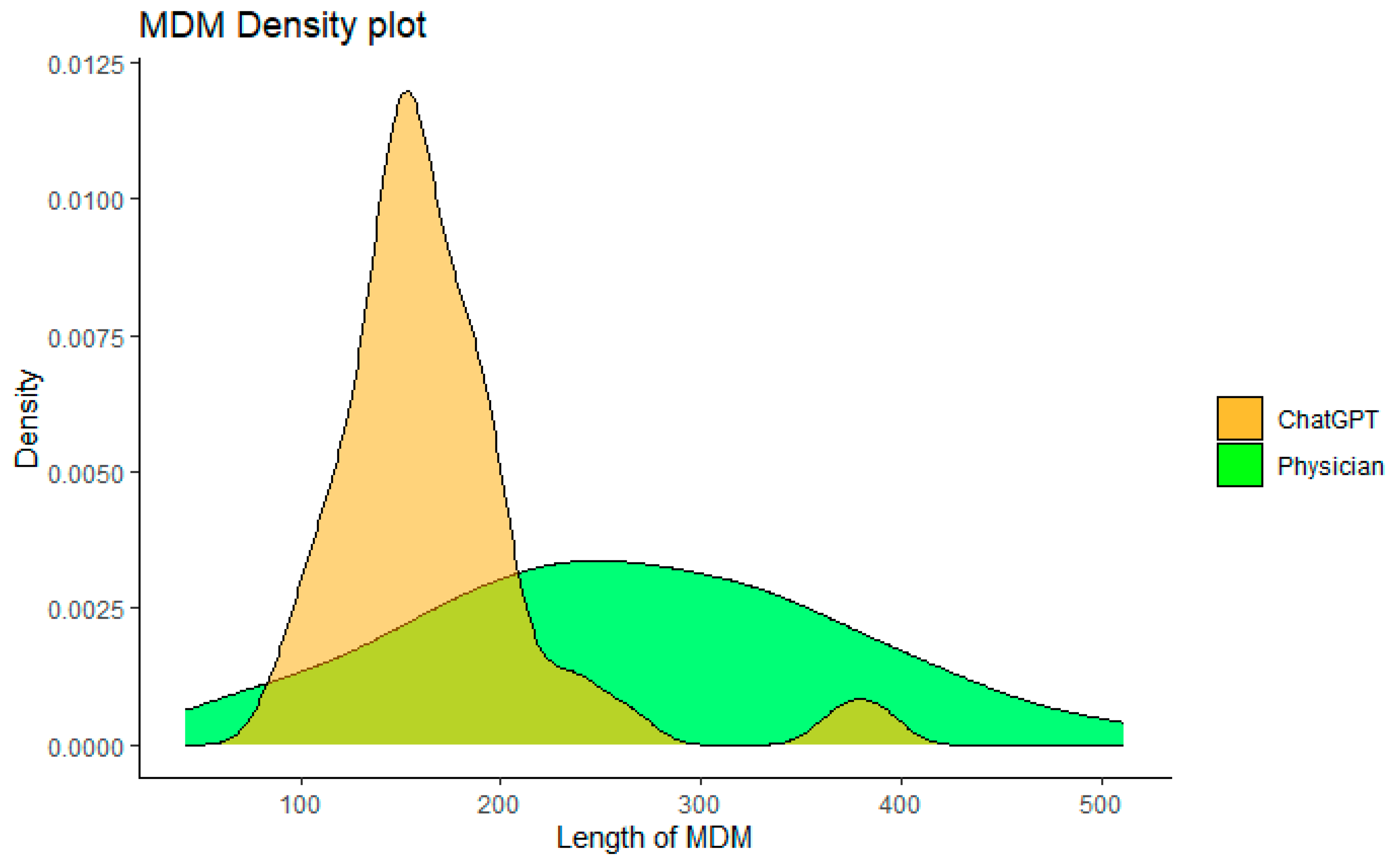
3.5. Comparison of MDM Complexity
3.6. Sensitivity Analysis
4. Discussion
5. Conclusions
6. Future Direction
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Siegel, R.L.; Miller, K.D.; Wagle, N.S.; Jemal, A. Cancer statistics, 2023. CA Cancer J. Clin. 2023, 73, 17–48. [Google Scholar] [CrossRef]
- Liu, J.M.; Hsu, R.J.; Chen, Y.T.; Liu, Y.P. Medical Utilization of Emergency Departments among Patients with Prostate Cancer: A Nationwide Population-Based Study in Taiwan. Int. J. Environ. Res. Public Health 2021, 18, 13233. [Google Scholar] [CrossRef]
- Iserson, K.V.; Moskop, J.C. Triage in medicine, part I: Concept, history, and types. Ann. Emerg. Med. 2007, 49, 275–281. [Google Scholar] [CrossRef]
- Grossmann, F.F.; Zumbrunn, T.; Frauchiger, A.; Delport, K.; Bingisser, R.; Nickel, C.H. At risk of undertriage? Testing the performance and accuracy of the emergency severity index in older emergency department patients. Ann. Emerg. Med. 2012, 60, 317–325. [Google Scholar] [CrossRef]
- Haug, C.J.; Drazen, J.M. Artificial Intelligence and Machine Learning in Clinical Medicine, 2023. N. Engl. J. Med. 2023, 388, 1201–1208. [Google Scholar] [CrossRef]
- Obermeyer, Z.; Emanuel, E.J. Predicting the Future—Big Data, Machine Learning, and Clinical Medicine. N. Engl. J. Med. 2016, 375, 1216. [Google Scholar] [CrossRef] [Green Version]
- Topol, E.J. High-performance medicine: The convergence of human and artificial intelligence. Nat. Med. 2019, 25, 44–56. [Google Scholar] [CrossRef]
- Weiss, S.; Kulikowski, C.A.; Safir, A. Glaucoma consultation by computer. Comput. Biol. Med. 1978, 8, 25–40. [Google Scholar] [CrossRef]
- caBIG Strategic Planning Workspace. The Cancer Biomedical Informatics Grid (caBIG): Infrastructure and applications for a worldwide research community. Stud. Health Technol. Inform. 2007, 129 Pt 1, 330–334. [Google Scholar]
- Armstrong, A.J.; Lin, P.; Higano, C.S.; Sternberg, C.N.; Sonpavde, G.; Tombal, B.; Templeton, A.J.; Fizazi, K.; Phung, D.; Wong, E.K.; et al. Development and validation of a prognostic model for overall survival in chemotherapy-naïve men with metastatic castration-resistant prostate cancer. Ann. Oncol. 2018, 29, 2200–2207. [Google Scholar] [CrossRef]
- Rosenkrantz, A.B.; Chandarana, H.; Gilet, A.; Deng, F.M.; Babb, J.S.; Melamed, J.; Taneja, S.S. Prostate cancer: Utility of diffusion-weighted imaging as a marker of side-specific risk of extracapsular extension. J. Magn. Reason. Imaging 2013, 38, 312–319. [Google Scholar] [CrossRef]
- Rabaan, A.A.; Bakhrebah, M.A.; AlSaihati, H.; Alhumaid, S.; Alsubki, R.A.; Turkistani, S.A.; Al-Abdulhadi, S.; Aldawood, Y.; Alsaleh, A.A.; Alhashem, Y.N.; et al. Artificial Intelligence for Clinical Diagnosis and Treatment of Prostate Cancer. Cancers 2022, 14, 5595. [Google Scholar] [CrossRef]
- Mayo, C.S.; Mierzwa, M.; Yalamanchi, P.; Evans, J.; Worden, F.; Medlin, R.; Schipper, M.; Schonewolf, C.; Shah, J.; Spector, M.; et al. Machine Learning Model of Emergency Department Use for Patients Undergoing Treatment for Head and Neck Cancer Using Comprehensive Multifactor Electronic Health Records. JCO Clin. Cancer Inform. 2023, 7, e2200037. [Google Scholar] [CrossRef]
- Noel, C.W.; Sutradhar, R.; Gotlib Conn, L.; Forner, D.; Chan, W.C.; Fu, R.; Hallet, J.; Coburn, N.G.; Eskander, A. Development and Validation of a Machine Learning Algorithm Predicting Emergency Department Use and Unplanned Hospitalization in Patients with Head and Neck Cancer. JAMA Otolaryngol. Head. Neck. Surg. 2022, 148, 764–772. [Google Scholar] [CrossRef]
- Choi, A.; Choi, S.Y.; Chung, K.; Chung, H.S.; Song, T.; Choi, B.; Kim, J.H. Development of a machine learning-based clinical decision support system to predict clinical deterioration in patients visiting the emergency department. Sci. Rep. 2023, 13, 8561. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118, Erratum in Nature 2017, 546, 686. [Google Scholar] [CrossRef]
- Rajkomar, A.; Dean, J.; Kohane, I. Machine Learning in Medicine. N. Engl. J. Med. 2019, 380, 1347–1358. [Google Scholar] [CrossRef]
- Huang, M.L.; Han, Y.; Marshall, W. An Algorithm of Nonparametric Quantile Regression. J. Stat. Theory Pract. 2023, 17, 32. [Google Scholar] [CrossRef]
- Lukauskas, M.; Ruzgas, T. Reduced Clustering Method Based on the Inversion Formula Density Estimation. Mathematics 2023, 11, 661. [Google Scholar] [CrossRef]
- Wang, Y.G.; Wu, J.; Hu, Z.H.; McLachlan, G. A new algorithm for support vector regression with automatic selection of hyperparameters. Pattern Recognit. 2023, 133, 108989. [Google Scholar] [CrossRef]
- Patel, S.B.; Lam, K. ChatGPT: The future of discharge summaries? Lancet Digit. Health 2023, 5, e107–e108. [Google Scholar] [CrossRef]
- Hopkins, A.M.; Logan, J.M.; Kichenadasse, G.; Sorich, M.J. Artificial intelligence chatbots will revolutionize how cancer patients access information: ChatGPT represents a paradigm-shift. JNCI Cancer Spectr. 2023, 7, pkad010. [Google Scholar] [CrossRef]
- Uprety, D.; Zhu, D.; West, H.J. ChatGPT-A promising generative AI tool and its implications for cancer care. Cancer 2023, 129, 2284–2289. [Google Scholar] [CrossRef]
- Lee, P.; Bubeck, S.; Petro, J. Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. N. Engl. J. Med. 2023, 388, 1233–1239. [Google Scholar] [CrossRef]
- Alkaissi, H.; McFarlane, S.I. Artificial Hallucinations in ChatGPT: Implications in Scientific Writing. Cureus 2023, 15, e35179. [Google Scholar] [CrossRef]
- Sallam, M. ChatGPT Utility in Healthcare Education, Research, and Practice: Systematic Review on the Promising Perspectives and Valid Concerns. Healthcare 2023, 11, 887. [Google Scholar] [CrossRef]
- Rizzato Lede, D.A.; Inda, D.; Rosa, J.M.; Zin, Y.; Tentoni, N.; Médici, M.M.; Castaño, J.M.; Gambarte, M.L.; López, G.E.; Merli, M.; et al. Tana, a Healthcare Chatbot to Help Patients During the COVID-19 Pandemic at a University Hospital in Argentina. Stud. Health Technol. Inform. 2022, 290, 301–303. [Google Scholar]
- Dougall GPT. Available online: https://dougallgpt.com/ (accessed on 17 May 2023).
- Toma, A.; Lawler, P.; Ba, J.; Krishnan, R.G.; Rubin, B.B.; Wang, B. Clinical Camel: An Open-Source Expert-Level Medical Language Model with Dialogue-Based Knowledge Encoding. arXiv 2023, arXiv:2305.12031. [Google Scholar]
- Price, W.N., 2nd; Cohen, I.G. Privacy in the age of medical big data. Nat. Med. 2019, 25, 37–43. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Baseline Characteristics | |
|---|---|
| Age, median (range) | 75 (50–87) |
| Race, n (%) | |
| Caucasian | 48 (85.7) |
| African American | 2 (3.6) |
| Hispanic | 3 (5.4) |
| Asian | 1 (1.8) |
| Hawaiian | 1 (1.8) |
| Other | 1 (1.8) |
| Adenocarcinoma, n (%) | 55 (98.2) |
| Gleason score, median (range) | 8 (6–10) |
| Metastatic sites, n (%) | |
| Bone | 39 (69.6) |
| Lymph node | 21 (37.5) |
| Lung | 2 (3.6) |
| ECOG, n (%) | |
| 0 | 11 (19.6) |
| 1 | 16 (28.6) |
| >1 | 29 (51.8) |
| Co-exisiting conditions, n (%) | |
| Diabetes | 11 (19.6) |
| Hypertension | 15 (26.8) |
| Hyperlipidemia | 7 (12.5) |
| Depression | 6 (10.7) |
| Atrial fibrillation | 8 (14.3) |
| Chronic heart failure | 4 (7.1) |
| Gastroesophageal reflux disease | 6 (10.7) |
| Clinical Scenarios | Diagnoses Made by ER Physician | Diagnoses Made by ChatGPT | Comparison |
|---|---|---|---|
| 67-year-old patient with a history of hypertension, obesity, overactive bladder, kidney stones, with mPC involving lymph nodes and bones, currently on a clinical trial with immunotherapy. He presented to ER for evaluation of abdominal pain. | Acute pancreatitis | Gastroenteritis | ER physician suspected possible immunotherapy-related pancreatitis, which ChatGPT did not notice. Pancreatitis was ruled out after admission. |
| 87-year-old patient with a history of myocardial infarction, deep venous thrombosis (DVT) on rivaroxaban, acute kidney injury, and mPC presented with a CT scan demonstrating free air and mild duodenal thickening. | Peritonitis | Perforated peptic ulcer, peritonitis. | Final diagnosis after diagnostic laparoscopy: Pneumoperitoneum from perforated gastroduodenal ulcer. |
| 62-year-old patient with a history of mPC, presented with shortness of breath. | Acute bronchitis due to rhinovirus | Acute respiratory distress, likely secondary to an asthma exacerbation, with a history of mPC. | Final diagnosis on discharge: asthma exacerbation and rhinovirus infection. |
| 79-year-old patient with a history of amyloidosis heart failure, atrial fibrillation and mPC presented with nausea for one week. | Dehydration | Exacerbation of congestive heart failure | Patient had a history of heart failure, but the clinical picture was more consistent with dehydration from reduced oral intake |
| 79-year-old patient with a history of DVT on wafarin, mPC presented with pain after a mechanical fall | Fall | Fall with soft tissue injury to the left arm and left knee | ChatGPT had a more accurate diagnosis. |
| 72-year-old patient with a history of heart failure, stroke with residual left-sided deficits, DVT on warfarin, coronary artery disease (CAD), diabetes, hypertension and mPC status post radiation presented with multiple complaints. | Fatigue | Decompensated heart failure with hypotension. | Orthostatic hypotension was noted in the triage, which was not addressed in the ER physician’s assessment. |
| 73-year-old patient with a history of a defibrillator in place for atrial fibrillation, ventricular tachycardia and mPC presented with chest discomfort. | Malaise | Unstable angina | Extensive cardiac workup was done after cardiology was consulted, though ChatGPT was not given the information about ER process. |
| 67-year-old patient presented to the ER complaining of Foley catheter problems. | Obstruction of catheter | Urinary retention with complications associated with Foley catheter. | Both parties had the same diagnosis. |
| 87-year-old patient with history of mPC, atrial fibrillation not currently on anticoagulation, heart failure with preserved ejection fraction, CAD, chronic kidney disease (CKD) who presented with concern for a fall. | Fall from ground level | Acute varus impacted right femoral neck fracture. | ChatGPT had a more accurate diagnosis. |
| 75-year-old patient presented with sleepiness and weakness. Had a recent hospital stay for gastrointestinal (GI) bleeding. | Weakness | Suspected ongoing gastrointestinal bleeding with worsening anemia | ChatGPT had a more accurate diagnosis. |
| 54-year-old patient with deafness, abdominal hernia, hepatitis C, and mPC to the spine and iliac crest presented for worsened pain. | Malignant neoplasm metastatic to bone | Metastatic prostate cancer with suspected pain crisis | Both parties had a similar diagnosis. ChatGPT had a more accurate diagnosis. |
| 72-year-old patient with a history of chronic obstructive pulmonary disease (COPD), heart failure, CKD, hypertension, cirrhosis, stroke, mPC, chronic hydronephrosis, recurrent urinary tract infection (UTI), with bilateral percutaneous nephrostomy tubes, presented to the ER after his tube was displaced by accident. | Nephrostomy complication | Accidental dislodgment of the right percutaneous nephrostomy tube. | ChatGPT had a more accurate diagnosis. |
| 69-year-old patient with heavily-treated mPC presented with weakness and inability to tolerate solid and liquid food | Failure to thrive, nausea and vomit | Dehydration | ChatGPT recommended hospice. Patient deceased after admission |
| Hospital Admission | Hospital Stay Length | ICU Admission | |
|---|---|---|---|
| Partial correlation coefficient | −1.59 | −0.12 | −0.62 |
| p Value | 0.12 | 0.91 | 0.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gebrael, G.; Sahu, K.K.; Chigarira, B.; Tripathi, N.; Mathew Thomas, V.; Sayegh, N.; Maughan, B.L.; Agarwal, N.; Swami, U.; Li, H. Enhancing Triage Efficiency and Accuracy in Emergency Rooms for Patients with Metastatic Prostate Cancer: A Retrospective Analysis of Artificial Intelligence-Assisted Triage Using ChatGPT 4.0. Cancers 2023, 15, 3717. https://doi.org/10.3390/cancers15143717
Gebrael G, Sahu KK, Chigarira B, Tripathi N, Mathew Thomas V, Sayegh N, Maughan BL, Agarwal N, Swami U, Li H. Enhancing Triage Efficiency and Accuracy in Emergency Rooms for Patients with Metastatic Prostate Cancer: A Retrospective Analysis of Artificial Intelligence-Assisted Triage Using ChatGPT 4.0. Cancers. 2023; 15(14):3717. https://doi.org/10.3390/cancers15143717
Chicago/Turabian StyleGebrael, Georges, Kamal Kant Sahu, Beverly Chigarira, Nishita Tripathi, Vinay Mathew Thomas, Nicolas Sayegh, Benjamin L. Maughan, Neeraj Agarwal, Umang Swami, and Haoran Li. 2023. "Enhancing Triage Efficiency and Accuracy in Emergency Rooms for Patients with Metastatic Prostate Cancer: A Retrospective Analysis of Artificial Intelligence-Assisted Triage Using ChatGPT 4.0" Cancers 15, no. 14: 3717. https://doi.org/10.3390/cancers15143717