
ViSTA: A Novel Network Improving Lung Adenocarcinoma Invasiveness Prediction from Follow-Up CT Series

 and
and
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. CT Scanning Parameters
2.3. Nodule Labeling, Segmentation and Imaging Preprocessing
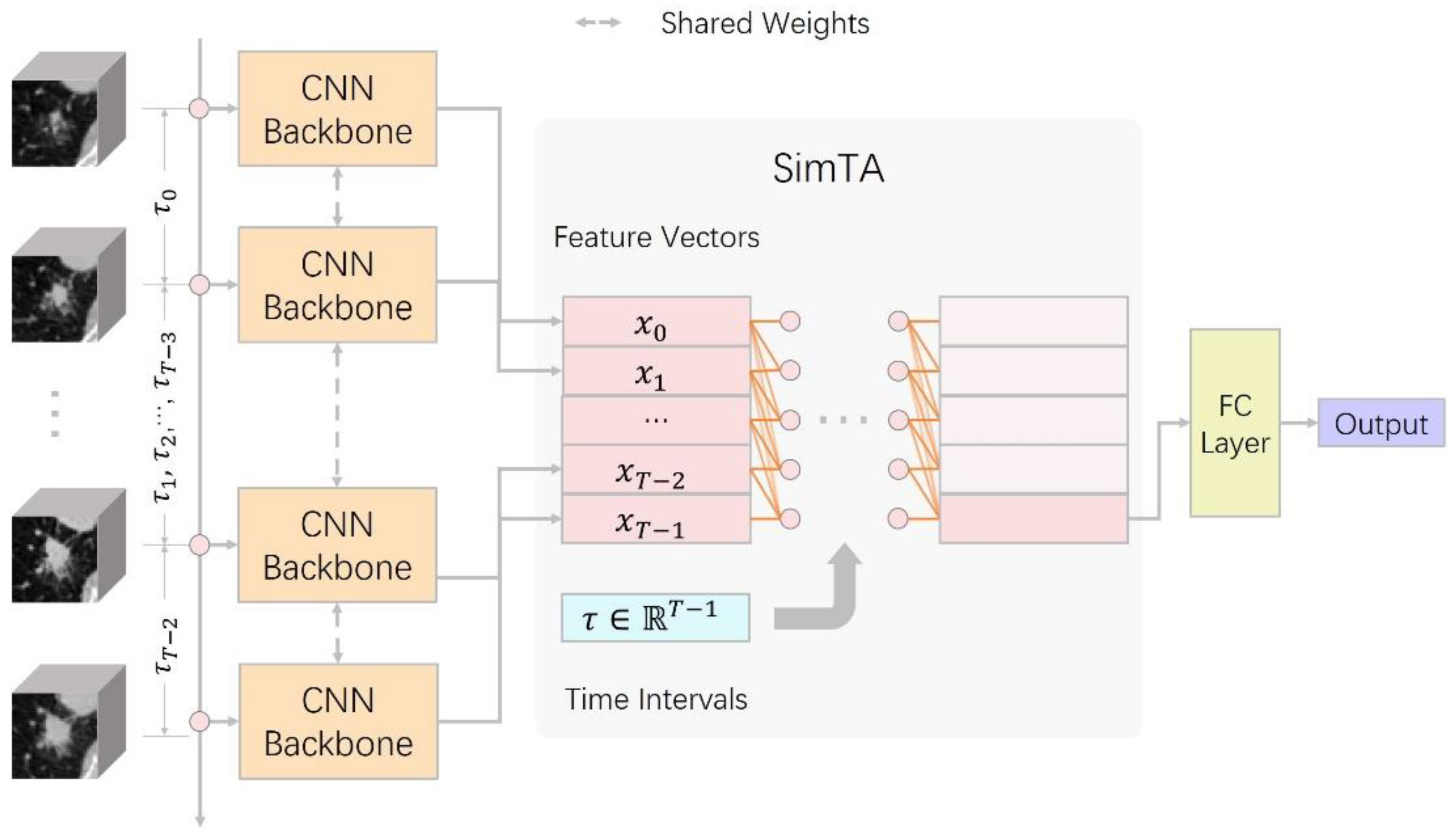
2.4. Development of the Deep Learning Model
2.5. Counterpart Methods
- –
- VDT (Volume Doubling Time). VDT is an important volumetric indicator used in follow-up examinations. It represents the time it takes for a nodule to double its volume. The formula of VDT is provided in Supplementary Section S1. Nodules with VDT < 400 days are considered fast-growing and are more likely to be malignant [23]. In this research, we evaluated VDT’s metrics under two different thresholds: 400 days and the cutoff that provides the best Youden index on the validation set. Youden index’s formula is presented in Supplementary Section S1;
- –
- CNN (Convolutional Neural Network): To compare ViSTA against static models, we introduced CNN as a counterpart. We conducted the following experiments to further investigate the source of performance difference between ViSTA and CNN;
- –
- CNN-last: This experiment was conducted to train and validate CNN only on the last time point of each follow-up series. It is obvious that the last time point is most relevant to the final diagnosis;
- –
- CNN-first: This experiment was conducted to train and validate CNN only on the first time point of each follow-up series. In this experiment, the first steps were treated as if they had the same label as the last one. This setting was used to confirm that earlier time points convey less information than later ones;
- –
- CNN-all: This experiment was conducted to train CNN on all time points of each follow-up series and validate it on the first and last time point separately (named CNN-all-first and CNN-all-last, respectively). This was used is to investigate if ViSTA’s superior performance only comes from the larger data size it enjoys;
- –
- CNN+LSTM (Long Short-term Memory) [16]: LSTM is a subtype of RNN (Recurrent Neural Network) designed to analyze serial data and capture long-term relations. This setting is quite similar to previous research which combined CNN and RNN to predict lung cancer treatment response [22]. However, we did not limit time intervals to specific values so that we could fairly compare ViSTA and RNN-based methods. One major difference between CNN+LSTM and ViSTA is that CNN+LSTM treats all time points as if they had the same interval (synchronous). By comparing the previous two methods, we would like to see if ViSTA is more suitable for analyzing irregularly sampled time series.
2.6. Evaluation and Statistical Analysis
2.7. Observer Study
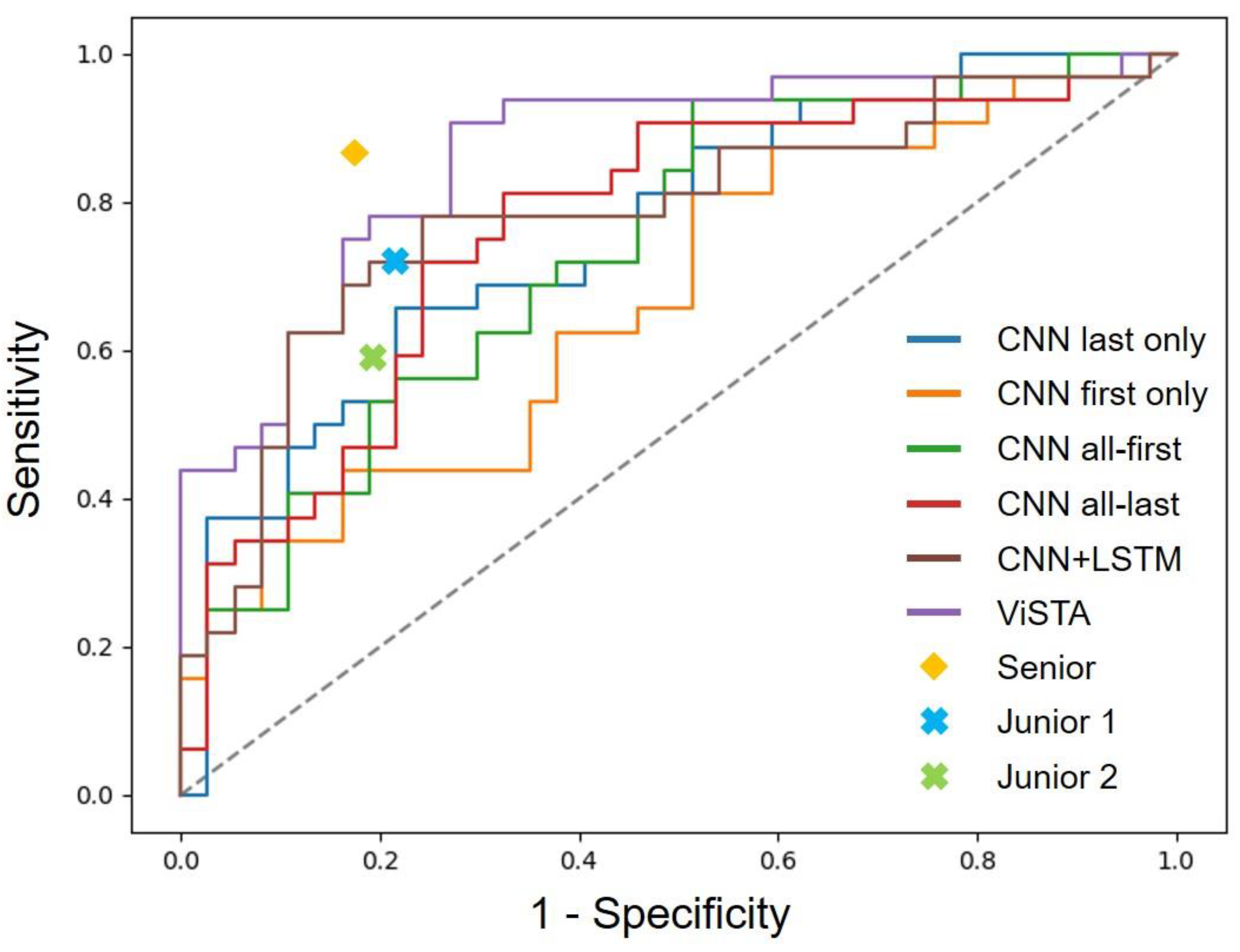
3. Results
3.1. Performance of Deep Learning Models in Predicting the Invasiveness of Early Lung Adenocarcinoma
3.2. Performance Comparison against Radiologists
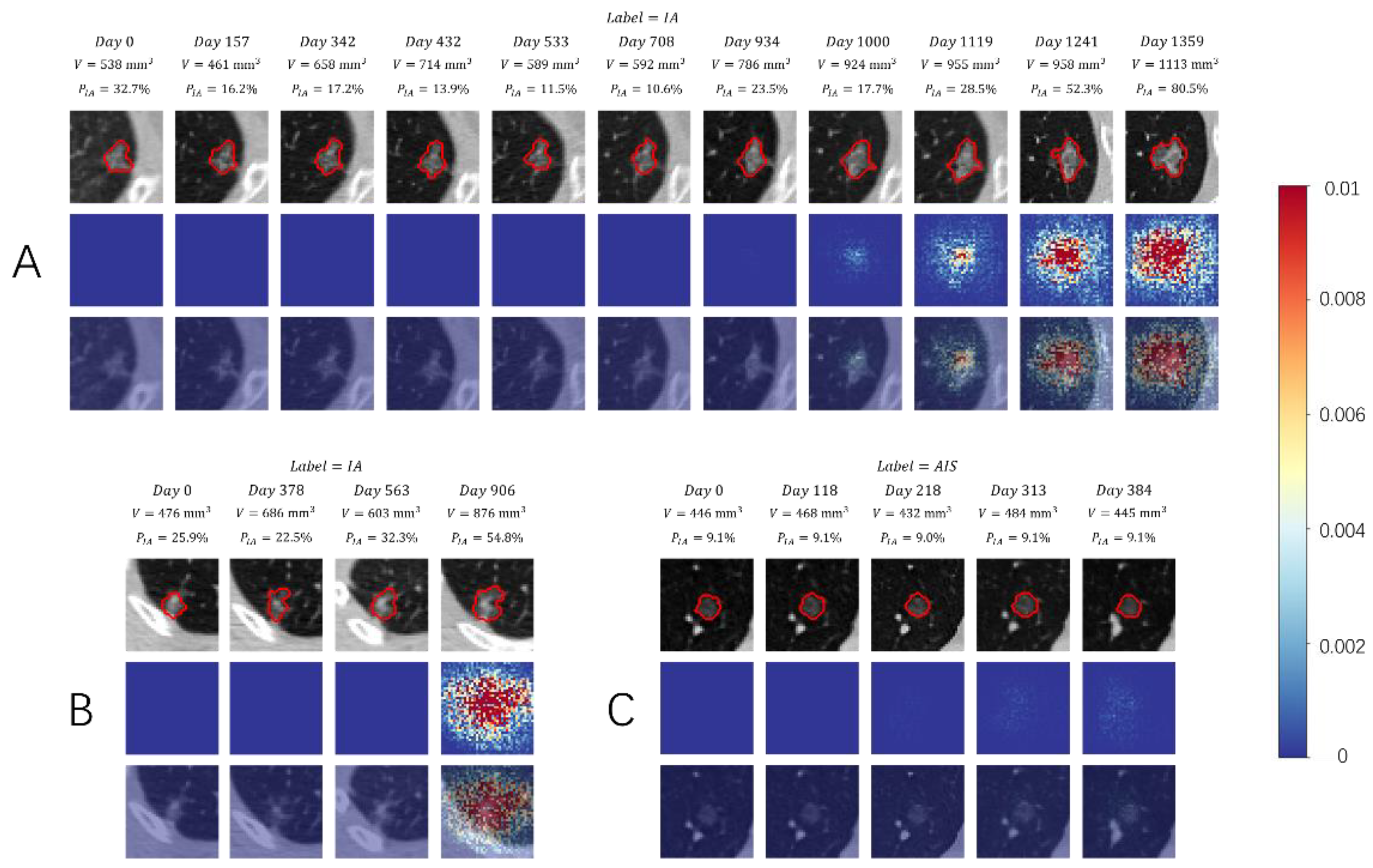
3.3. Visual Presentation Investigation
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ettinger, D.S.; Wood, D.E.; Aisner, D.L.; Akerley, W.; Bauman, J.R.; Bharat, A.; Bruno, D.S.; Chang, J.Y.; Chirieac, L.R.; D’Amico, T.A.; et al. Non-Small Cell Lung Cancer, Version 3.2022, NCCN Clinical Practice Guidelines in Oncology. J. Natl. Compr. Cancer Netw. 2022, 20, 497–530. [Google Scholar] [CrossRef] [PubMed]
- Shen, D.; Wu, G.; Suk, H.I. Deep Learning in Medical Image Analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krittanawong, C.; Johnson, K.W.; Rosenson, R.S.; Wang, Z.; Aydar, M.; Baber, U.; Min, J.K.; Tang, W.H.W.; Halperin, J.L.; Narayan, S.M. Deep learning for cardiovascular medicine: A practical primer. Eur. Heart J. 2019, 40, 2058–2073. [Google Scholar] [CrossRef] [PubMed]
- Bi, W.L.; Hosny, A.; Schabath, M.B.; Giger, M.L.; Birkbak, N.; Mehrtash, A.; Allison, T.; Arnaout, O.; Abbosh, C.; Dunn, I.F.; et al. Artificial intelligence in cancer imaging: Clinical challenges and applications. CA Cancer J. Clin. 2019, 69, 127–157. [Google Scholar] [CrossRef] [Green Version]
- Bulten, W.; Pinckaers, H.; van Boven, H.; Vink, R.; De Bel, T.; Van Ginneken, B.; Van der Laak, J.; Hulsbergen-van de Kaa, C.; Litjens, G. Automated deep-learning system for Gleason grading of prostate cancer using biopsies: A diagnostic study. Lancet Oncol. 2020, 21, 233–241. [Google Scholar] [CrossRef] [Green Version]
- Balakrishnan, G.; Zhao, A.; Sabuncu, M.R.; Guttag, J.; Dalca, A.V. VoxelMorph: A Learning Framework for Deformable Medical Image Registration. IEEE Trans. Med. Imaging 2019, 38, 103–111. [Google Scholar] [CrossRef] [Green Version]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.A.; Petersen, J.; Maier-Hein, K.H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef]
- Ahmad, M.; Qadri, S.F.; Ashraf, M.U.; Subhi, K.; Khan, S.; Zareen, S.S.; Qadri, S. Efficient Liver Segmentation from Computed Tomography Images Using Deep Learning. Comput. Intell. Neurosci. 2022, 2022, 2665283. [Google Scholar] [CrossRef]
- Qadri, S.F.; Shen, L.; Ahmad, M.; Qadri, S.; Zareen, S.S.; Akbar, M.A. SVseg: Stacked Sparse Autoencoder-Based Patch Classification Modeling for Vertebrae Segmentation. Mathematics 2022, 10, 796. [Google Scholar] [CrossRef]
- Massion, P.P.; Antic, S.; Ather, S.; Arteta, C.; Brabec, J.; Chen, H.; Declerck, J.; Dufek, D.; Hickes, W.; Kadir, T.; et al. Assessing the Accuracy of a Deep Learning Method to Risk Stratify Indeterminate Pulmonary Nodules. Am. J. Respir. Crit. Care Med. 2020, 202, 241–249. [Google Scholar] [CrossRef]
- Kim, H.; Lee, D.; Cho, W.S.; Lee, J.C.; Goo, J.M.; Kim, H.C.; Park, C.M. CT-based deep learning model to differentiate invasive pulmonary adenocarcinomas appearing as subsolid nodules among surgical candidates: Comparison of the diagnostic performance with a size-based logistic model and radiologists. Eur. Radiol. 2020, 30, 3295–3305. [Google Scholar] [CrossRef]
- Zhao, W.; Yang, J.; Sun, Y.; Li, C.; Wu, W.; Jin, L.; Yang, Z.; Ni, B.; Gao, P.; Wang, P.; et al. 3D Deep Learning from CT Scans Predicts Tumor Invasiveness of Subcentimeter Pulmonary Adenocarcinomas. Cancer Res. 2018, 78, 6881–6889. [Google Scholar] [CrossRef] [Green Version]
- De Margerie-Mellon, C.; Gill, R.R.; Salazar, P.; Oikonomou, A.; Nguyen, E.T.; Heidinger, B.H.; Medina, M.A.; VanderLaan, P.A.; Bankier, A.A. Assessing invasiveness of subsolid lung adenocarcinomas with combined attenuation and geometric feature models. Sci. Rep. 2020, 10, 14585. [Google Scholar] [CrossRef]
- Wang, X.; Li, Q.; Cai, J.; Wang, W.; Xu, P.; Zhang, Y.; Fang, Q.; Fu, C.; Fan, L.; Xiao, Y.; et al. Predicting the invasiveness of lung adenocarcinomas appearing as ground-glass nodule on CT scan using multi-task learning and deep radiomics. Transl. Lung Cancer Res. 2020, 9, 1397–1406. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014; pp. 103–111. [Google Scholar] [CrossRef]
- Li, Y.; Yang, J.; Xu, Y.; Xu, J.; Ye, X.; Tao, G.; Xie, X.; Liu, G. Learning Tumor Growth via Follow-Up Volume Prediction for Lung Nodules. arXiv 2020, arXiv:2006.13890. [Google Scholar] [CrossRef]
- Wu, C.-Y.; Girshick, R.; He, K.; Feichtenhofer, C.; Krahenbuhl, P. A Multigrid Method for Efficiently Training Video Models. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Saon, G.; Kurata, G.; Sercu, T.; Audhkhasi, K.; Thomas, S.; Dimitriadis, D.; Cui, X.; Ramabhadran, B.; Picheny, M.; Lim, L.-L.; et al. English Conversational Telephone Speech Recognition by Humans and Machines. In Proceedings of the INTERSPEECH 2017: Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Rajkomar, A.; Oren, E.; Chen, K.; Dai, A.M.; Hajaj, N.; Hardt, M.; Liu, P.J.; Liu, X.; Marcus, J.; Sun, M.; et al. Scalable and accurate deep learning with electronic health records. NPJ Digit. Med. 2018, 1, 18. [Google Scholar] [CrossRef]
- Xu, Y.; Hosny, A.; Zeleznik, R.; Parmar, C.; Coroller, T.; Franco, I.; Mak, R.H.; Aerts, H.J. Deep Learning Predicts Lung Cancer Treatment Response from Serial Medical Imaging. Clin. Cancer Res. 2019, 25, 3266–3275. [Google Scholar] [CrossRef] [Green Version]
- Heuvelmans, M.A.; Oudkerk, M.; De Bock, G.H.; De Koning, H.J.; Xie, X.; Van Ooijen, P.M.A.; Greuter, M.; De Jong, P.A.; Groen, H.J.M.; Vliegenthart, R. Optimisation of volume-doubling time cutoff for fast-growing lung nodules in CT lung cancer screening reduces false-positive referrals. Eur. Radiol. 2013, 23, 1836–1845. [Google Scholar] [CrossRef]
- Yang, J.; Chen, J.; Kuang, K.; Lin, T.; He, J.; Ni, B. MIA-Prognosis: A Deep Learning Framework to Predict Therapy Response. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2013, arXiv:1312.6034. [Google Scholar] [CrossRef]
- Park, S.; Lee, S.M.; Kim, S.; Lee, J.-G.; Choi, S.; Do, K.-H.; Seo, J.B. Volume Doubling Times of Lung Adenocarcinomas: Correlation with Predominant Histologic Subtypes and Prognosis. Radiology 2020, 295, 703–712. [Google Scholar] [CrossRef] [PubMed]
- Ardila, D.; Kiraly, A.P.; Bharadwaj, S.; Choi, B.; Reicher, J.J.; Peng, L.; Tse, D.; Etemadi, M.; Ye, W.; Corrado, G.; et al. End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography. Nat. Med. 2019, 25, 954–961. [Google Scholar] [CrossRef]
- Trebeschi, S.; Bodalal, Z.; Boellaard, T.N.; Bucho, T.M.T.; Drago, S.G.; Kurilova, I.; Calin-Vainak, A.M.; Pizzi, A.D.; Muller, M.; Hummelink, K.; et al. Prognostic Value of Deep Learning-Mediated Treatment Monitoring in Lung Cancer Patients Receiving Immunotherapy. Front. Oncol. 2021, 11, 609054. [Google Scholar] [CrossRef]
- Choi, Y.; Ahn, K.-J.; Nam, Y.; Jang, J.; Shin, N.-Y.; Choi, H.S.; Jung, S.-L.; Kim, B.-S. Analysis of heterogeneity of peritumoral T2 hyperintensity in patients with pretreatment glioblastoma: Prognostic value of MRI-based radiomics. Eur. J. Radiol. 2019, 120, 108642. [Google Scholar] [CrossRef]
- Beig, N.; Khorrami, M.; Alilou, M.; Prasanna, P.; Braman, N.; Orooji, M.; Rakshit, S.; Bera, K.; Rajiah, P.; Ginsberg, J.; et al. Perinodular and Intranodular Radiomic Features on Lung CT Images Distinguish Adenocarcinomas from Granulomas. Radiology 2019, 290, 783–792. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. Proc. AAAI Conf. Artif. Intell. 2020, 35, 11106–11115. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Clevert, D.-A.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). arXiv 2015, arXiv:1511.07289. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Pathological Type | No. CT Scans/Nodules | ||||
|---|---|---|---|---|---|
| Training | Validation | Test | Total | ||
| Non-IA | AAH | 5/1 | 0/0 | 0/0 | 5/1 |
| AIS | 98/29 | 9/4 | 19/6 | 126/39 | |
| MIA | 383/104 | 40/16 | 114/31 | 537/151 | |
| Total | 486/134 | 49/20 | 133/37 | 668/191 | |
| IA | 398/111 | 64/17 | 104/32 | 566/160 | |
| Total | 884/245 | 113/37 | 237/69 | 1234/351 | |
| AUC | Acc. | Prec. | Sens. | F1 | |
|---|---|---|---|---|---|
| Senior | - | 85.5% | 82.4% | 87.5% | 84.8% |
| Junior 1 | - | 75.4% | 74.2% | 71.9% | 73.0% |
| Junior 2 | - | 71.0% | 73.1% | 59.4% | 65.5% |
| 1/VDT (best Youden index) | 60.6% | 62.3% | 56.3% | 84.4% | 67.5% |
| 1/VDT (400 days) | 60.6% | 58.0% | 71.4% | 15.6% | 25.6% |
| CNN last only | 75.9% | 72.5% | 72.4% | 65.6% | 68.9% |
| CNN first only | 66.9% | 65.2% | 70.0% | 43.8% | 64.3% |
| CNN all-first | 73.9% | 65.2% | 60.5% | 71.9% | 65.7% |
| CNN all-last | 76.5% | 73.9% | 71.9% | 71.9% | 71.9% |
| CNN+LSTM | 78.3% | 76.8% | 73.5% | 78.1% | 75.8% |
| ViSTA | 86.4% | 81.2% | 74.4% | 90.6% | 81.7% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, W.; Sun, Y.; Kuang, K.; Yang, J.; Li, G.; Ni, B.; Jiang, Y.; Jiang, B.; Liu, J.; Li, M. ViSTA: A Novel Network Improving Lung Adenocarcinoma Invasiveness Prediction from Follow-Up CT Series. Cancers 2022, 14, 3675. https://doi.org/10.3390/cancers14153675
Zhao W, Sun Y, Kuang K, Yang J, Li G, Ni B, Jiang Y, Jiang B, Liu J, Li M. ViSTA: A Novel Network Improving Lung Adenocarcinoma Invasiveness Prediction from Follow-Up CT Series. Cancers. 2022; 14(15):3675. https://doi.org/10.3390/cancers14153675
Chicago/Turabian StyleZhao, Wei, Yingli Sun, Kaiming Kuang, Jiancheng Yang, Ge Li, Bingbing Ni, Yingjia Jiang, Bo Jiang, Jun Liu, and Ming Li. 2022. "ViSTA: A Novel Network Improving Lung Adenocarcinoma Invasiveness Prediction from Follow-Up CT Series" Cancers 14, no. 15: 3675. https://doi.org/10.3390/cancers14153675