
Spline Analysis of Biomarker Data Pooled from Multiple Matched/Nested Case–Control Studies


Abstract
:Simple Summary
Abstract
1. Introduction
2. Methods
2.1. Notation and Model
2.2. Approximate Conditional Likelihood and Calibration Methods
2.3. Parameter Estimation
3. Simulations
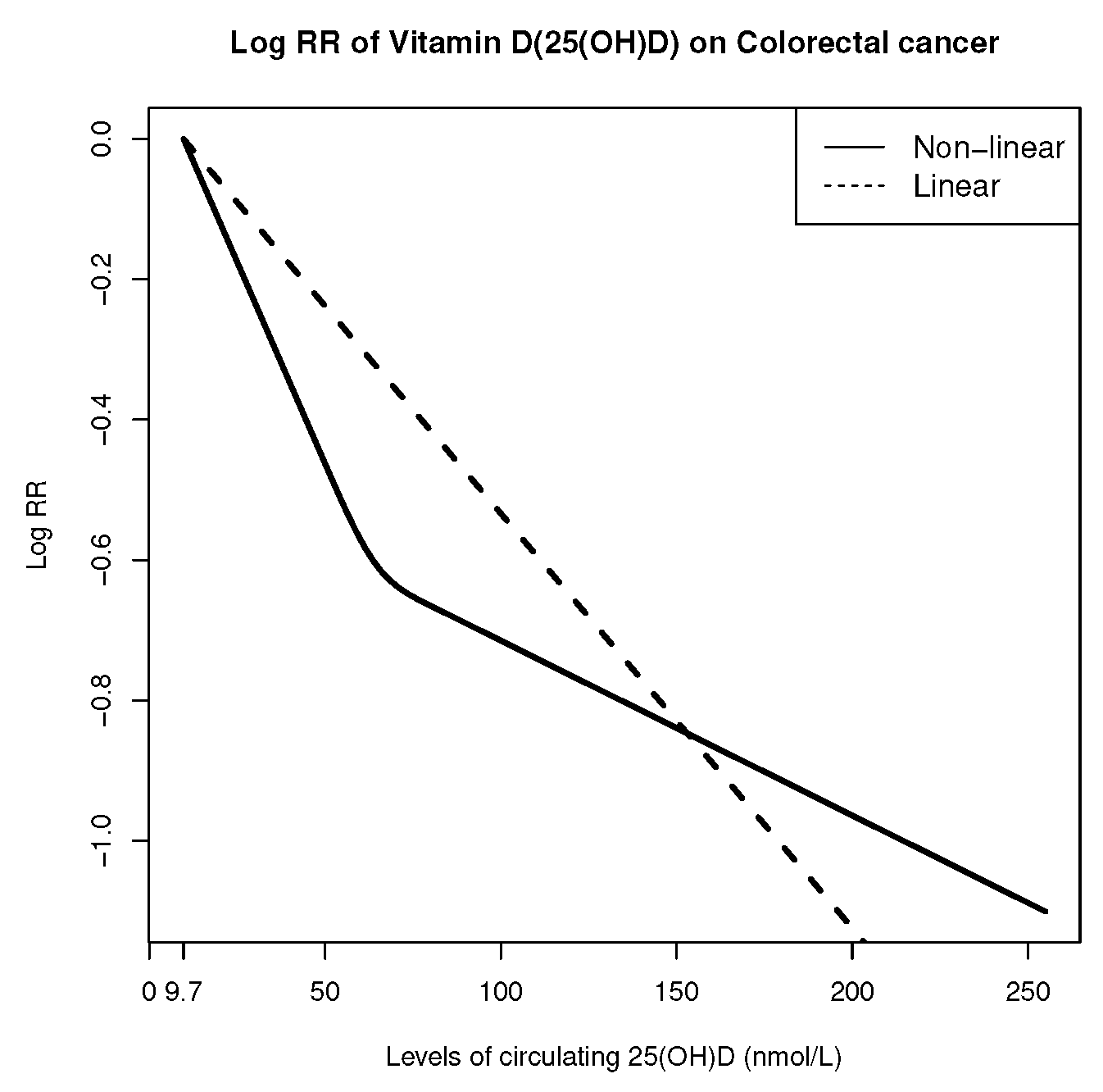
4. Applied Example
5. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Key, T.J.; Appleby, P.N.; Allen, N.E.; Reeves, G.K. Pooling biomarker data from different studies of disease risk, with a focus on endogenous hormones. Cancer Epidemiol. Biomarkers Prev. 2010, 19, 960–965. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Smith-Warner, S.A.; Spiegelman, D.; Ritz, J.; Albanes, D.; Beeson, W.L.; Bernstein, L.; Berrino, F.; Van Den Brandt, P.A.; Buring, J.E.; Cho, E.; et al. Methods for pooling results of epidemiologic studies: The Pooling Project of Prospective Studies of Diet and Cancer. Am. J. Epidemiol. 2006, 163, 1053–1064. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tworoger, S.S.; Hankinson, S.E. Use of biomarkers in epidemiologic studies: Minimizing the influence of measurement error in the study design and analysis. Cancer Causes Control 2006, 17, 889–899. [Google Scholar] [CrossRef] [PubMed]
- McCullough, M.L.; Zoltick, E.S.; Weinstein, S.J.; Fedirko, V.; Wang, M.; Cook, N.R.; Eliassen, A.H.; Zeleniuch-Jacquotte, A.; Agnoli, C.; Albanes, D.; et al. Circulating vitamin D and colorectal cancer risk: An international pooling project of 17 cohorts. J. Natl. Cancer Inst. 2019, 111, 158–169. [Google Scholar] [CrossRef] [PubMed]
- Gallicchio, L.; Helzlsouer, K.J.; Chow, W.H.; Freedman, D.M.; Hankinson, S.E.; Hartge, P.; Hartmuller, V.; Harvey, C.; Hayes, R.B.; Horst, R.L.; et al. Circulating 25-hydroxyvitamin D and the risk of rarer cancers: Design and methods of the Cohort Consortium Vitamin D Pooling Project of Rarer Cancers. Am. J. Epidemiol. 2010, 172, 10–20. [Google Scholar] [CrossRef] [PubMed]
- Crowe, F.L.; Appleby, P.N.; Travis, R.C.; Barnett, M.; Brasky, T.M.; Bueno-de Mesquita, H.B.; Chajes, V.; Chavarro, J.E.; Chirlaque, M.D.; English, D.R.; et al. Circulating fatty acids and prostate cancer risk: Individual participant meta-analysis of prospective studies. J. Natl. Cancer Inst. 2014, 106, dju240. [Google Scholar] [CrossRef] [PubMed]
- Key, T.J.; Appleby, P.N.; Travis, R.C.; Albanes, D.; Alberg, A.J.; Barricarte, A.; Black, A.; Boeing, H.; Bueno-de Mesquita, H.B.; Chan, J.M.; et al. Carotenoids, retinol, tocopherols, and prostate cancer risk: Pooled analysis of 15 studies. Am. J. Clin. Nutr. 2015, 102, 1142–1157. [Google Scholar] [CrossRef] [Green Version]
- Tsilidis, K.K.; Travis, R.C.; Appleby, P.N.; Allen, N.E.; Lindström, S.; Albanes, D.; Ziegler, R.G.; McCullough, M.L.; Siddiq, A.; Barricarte, A.; et al. Insulin-like growth factor pathway genes and blood concentrations, dietary protein and risk of prostate cancer in the NCI Breast and Prostate Cancer Cohort Consortium (BPC3). Int. J. Cancer 2013, 133, 495–504. [Google Scholar] [CrossRef] [Green Version]
- Barake, M.; Daher, R.T.; Salti, I.; Cortas, N.K.; Al-Shaar, L.; Habib, R.H.; Fuleihan, G.E.H. 25-hydroxyvitamin D assay variations and impact on clinical decision making. J. Clin. Endocrinol. Metab. 2012, 97, 835–843. [Google Scholar] [CrossRef] [Green Version]
- Lai, J.K.; Lucas, R.M.; Banks, E.; Ponsonby, A.L.; Ausimmune Investigator Group. Variability in vitamin D assays impairs clinical assessment of vitamin D status. Intern. Med. J. 2012, 42, 43–50. [Google Scholar] [CrossRef] [Green Version]
- Snellman, G.; Melhus, H.; Gedeborg, R.; Byberg, L.; Berglund, L.; Wernroth, L.; Michaelsson, K. Determining vitamin D status: A comparison between commercially available assays. PLoS ONE 2010, 5, e11555. [Google Scholar] [CrossRef]
- Sloan, A.; Smith-Warner, S.A.; Ziegler, R.G.; Wang, M. Statistical methods for biomarker data pooled from multiple nested case–control studies. Biostatistics 2021, 22, 541–557. [Google Scholar] [CrossRef] [Green Version]
- Carroll, R.J.; Ruppert, D.; Stefanski, L.A.; Crainiceanu, C.M. Measurement Error in Nonlinear Models: A Modern Perspective; CRC Press: Boca Raton, FL, USA, 2006. [Google Scholar]
- Rosner, B.; Spiegelman, D.; Willett, W. Correction of logistic regression relative risk estimates and confidence intervals for measurement error: The case of multiple covariates measured with error. Am. J. Epidemiol. 1990, 132, 734–745. [Google Scholar] [CrossRef]
- Sloan, A.; Song, Y.; Gail, M.H.; Betensky, R.; Rosner, B.; Ziegler, R.G.; Smith-Warner, S.A.; Wang, M. Design and analysis considerations for combining data from multiple biomarker studies. Stat. Med. 2019, 38, 1303–1320. [Google Scholar] [CrossRef]
- Abbas, S.; Chang-Claude, J.; Linseisen, J. Plasma 25-hydroxyvitamin D and premenopausal breast cancer risk in a German case-control study. Int. J. Cancer 2009, 124, 250–255. [Google Scholar] [CrossRef]
- Bauer, S.R.; Hankinson, S.E.; Bertone-Johnson, E.R.; Ding, E.L. Plasma vitamin D levels, menopause, and risk of breast cancer: Dose-response meta-analysis of prospective studies. Medicine 2013, 92, 123. [Google Scholar] [CrossRef] [Green Version]
- Durrleman, S.; Simon, R. Flexible regression models with cubic splines. Stat. Med. 1989, 8, 551–561. [Google Scholar] [CrossRef]
- Breslow, N.; Day, N.; Halvorsen, K.; Prentice, R.; Sabai, C. Estimation of multiple relative risk functions in matched case-control studies. Am. J. Epidemiol. 1978, 108, 299–307. [Google Scholar] [CrossRef]
- Harrell, F.E. Regression Modeling Strategies: With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis; Springer: Berlin/Heidelberg, Germany, 2015; Volume 3. [Google Scholar]
- Gong, G.; Samaniego, F.J. Pseudo maximum likelihood estimation: Theory and applications. Ann. Stat. 1981, 9, 861–869. [Google Scholar] [CrossRef]
- Colditz, G.A.; Manson, J.E.; Hankinson, S.E. The Nurses’ Health Study: 20-year contribution to the understanding of health among women. J. Women’s Health 1997, 6, 49–62. [Google Scholar] [CrossRef]
- Choi, H.K.; Atkinson, K.; Karlson, E.W.; Curhan, G. Obesity, weight change, hypertension, diuretic use, and risk of gout in men: The health professionals follow-up study. Arch. Intern. Med. 2005, 165, 742–748. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
| Calib. Size | Relative Bias of (SD) | Coverage Rate of | Relative Bias of (SD) | Coverage Rate of | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IN | FC | N | IN | FC | N | IN | FC | N | IN | FC | N | ||
| 5% | −1.6% (2.621) | −0.1% (2.959) | −44.4% (0.110) | 0.970 | 0.972 | 0.458 | −3.6% (0.192) | −0.6% (0.196) | −72.2% (0.018) | 0.968 | 0.971 | 0.222 | |
| −1.2% (2.601) | −0.3% (2.972) | −23.7% (0.160) | 0.964 | 0.966 | 0.518 | −5.2% (0.220) | −2.1% (0.228) | −36% (0.025) | 0.962 | 0.962 | 0.736 | ||
| −1.1% (2.846) | −0.4% (3.288) | −16.6% (0.207) | 0.964 | 0.966 | 0.569 | −8.5% (0.258) | −5.3% (0.257) | −7.6% (0.033) | 0.957 | 0.959 | 0.941 | ||
| −1.4% (2.828) | −0.8% (3.212) | −12.8% (0.261) | 0.968 | 0.970 | 0.642 | −11.9% (0.337) | −8.7% (0.339) | 18.2% (0.040) | 0.955 | 0.958 | 0.888 | ||
| −1% (3.707) | −0.5% (4.481) | −10% (0.324) | 0.975 | 0.980 | 0.707 | −10.8% (0.357) | −7.5% (0.371) | 41.1% (0.051) | 0.954 | 0.955 | 0.766 | ||
| −1.1% (3.785) | −0.6% (4.486) | −8.2% (0.405) | 0.961 | 0.963 | 0.754 | −12% (0.385) | −8.5% (0.393) | 62% (0.066) | 0.944 | 0.944 | 0.609 | ||
| −1% (4.444) | −0.6% (5.136) | −7.2% (0.452) | 0.965 | 0.963 | 0.788 | −12% (0.517) | −8.7% (0.535) | 78% (0.075) | 0.954 | 0.954 | 0.497 | ||
| 15% | −7.1% (0.694) | −2.3% (0.874) | −44.1% (0.120) | 0.966 | 0.969 | 0.476 | −13.6% (0.095) | −4.3% (0.096) | −70.8% (0.019) | 0.944 | 0.953 | 0.267 | |
| −3.9% (0.854) | −1.1% (1.134) | −24.2% (0.154) | 0.957 | 0.956 | 0.511 | −13.4% (0.115) | −3.8% (0.115) | −36.4% (0.024) | 0.947 | 0.952 | 0.739 | ||
| −2.4% (0.836) | −0.3% (1.123) | −17.1% (0.197) | 0.955 | 0.962 | 0.564 | −12.8% (0.145) | −2.9% (0.147) | −8.8% (0.031) | 0.941 | 0.950 | 0.937 | ||
| −1.8% (0.911) | 0% (1.243) | −12.7% (0.265) | 0.961 | 0.966 | 0.638 | −11.9% (0.174) | −1.9% (0.175) | 19.4% (0.043) | 0.951 | 0.949 | 0.897 | ||
| −1.4% (1.218) | 0.3% (1.797) | −9.7% (0.326) | 0.961 | 0.972 | 0.722 | −14.9% (0.215) | −4.6% (0.217) | 42.1% (0.051) | 0.944 | 0.947 | 0.765 | ||
| −2.1% (1.108) | −0.6% (1.595) | −8.3% (0.395) | 0.941 | 0.948 | 0.761 | −18.4% (0.247) | −7.6% (0.249) | 62.0% (0.064) | 0.938 | 0.950 | 0.620 | ||
| −1.4% (1.273) | 0.1% (1.926) | −6.7% (0.461) | 0.948 | 0.960 | 0.805 | −16.9% (0.295) | −6.1% (0.299) | 79.7% (0.076) | 0.941 | 0.950 | 0.481 | ||
| 30% | −9.9% (0.519) | −0.3% (0.455) | −43.3% (0.113) | 0.943 | 0.955 | 0.477 | −21.1% (0.083) | −2.3% (0.084) | −70.8% (0.019) | 0.937 | 0.954 | 0.265 | |
| −5.1% (0.514) | 0.6% (0.561) | −23.2% (0.164) | 0.944 | 0.951 | 0.533 | −19.7% (0.096) | −0.5% (0.096) | −35.9% (0.026) | 0.948 | 0.957 | 0.751 | ||
| −4.5% (0.564) | −0.2% (0.659) | −16.7% (0.211) | 0.940 | 0.960 | 0.576 | −23.6% (0.129) | −4.1% (0.129) | −7.7% (0.034) | 0.941 | 0.962 | 0.926 | ||
| −4.0% (0.581) | −0.3% (0.755) | −12.8% (0.258) | 0.937 | 0.961 | 0.631 | −25.5% (0.156) | −5.4% (0.155) | 18.7% (0.042) | 0.936 | 0.956 | 0.900 | ||
| −3.6% (0.661) | −0.3% (0.885) | −10.1% (0.328) | 0.926 | 0.931 | 0.698 | −28.1% (0.193) | −7.4% (0.193) | 41.1% (0.052) | 0.922 | 0.933 | 0.769 | ||
| −3.1% (0.719) | 0.1% (0.988) | −8.3% (0.409) | 0.939 | 0.954 | 0.749 | −24.2% (0.233) | −3% (0.234) | 62.1% (0.065) | 0.938 | 0.948 | 0.613 | ||
| −3.5% (0.835) | −0.6% (1.109) | −7.2% (0.459) | 0.926 | 0.954 | 0.794 | 30.1% (0.274) | −8.9% (0.272) | 78.6% (0.076) | 0.910 | 0.943 | 0.506 | ||
| Calib. Size | Relative Bias of (SD) | Coverage Rate of | Relative Bias of (SD) | Coverage Rate of | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IN | FC | N | IN | FC | N | IN | FC | N | IN | FC | N | ||
| 5% | 0.02 | −1.3% (2.838) | −0.4% (3.140) | −6.5% (0.178) | 0.968 | 0.970 | 0.898 | −21.6% (0.215) | −9.3% (0.218) | 188.8% (0.029) | 0.962 | 0.958 | 0.624 |
| 0.06 | −2.2% (3.199) | −1.2% (3.528) | −18.1% (0.159) | 0.960 | 0.967 | 0.686 | −12.9% (0.234) | −8.8% (0.247) | −12.4% (0.025) | 0.949 | 0.954 | 0.938 | |
| 0.10 | −2.5% (2.515) | −1.6% (2.956) | −29.5% (0.144) | 0.968 | 0.969 | 0.339 | −8.1% (0.197) | −5.6% (0.206) | 50.8% (0.023) | 0.959 | 0.957 | 0.399 | |
| 0.14 | −1.5% (2.815) | −0.6% (3.179) | −41.7% (0.131) | 0.967 | 0.970 | 0.078 | −4.1% (0.194) | −2.3% (0.198) | −69.3% (0.021) | 0.953 | 0.951 | 0.010 | |
| 0.18 | −2.1% (2.636) | −1.2% (3.149) | −52.8% (0.127) | 0.968 | 0.969 | 0.012 | −5.0% (0.219) | −3.6% (0.225) | −78.0% (0.020) | 0.950 | 0.954 | 0.000 | |
| 15% | 0.02 | −2.7% (0.889) | 0.1% (1.072) | −5.8% (0.176) | 0.951 | 0.953 | 0.922 | −49.7% (0.126) | −11.7% (0.126) | 191.9% (0.027) | 0.928 | 0.938 | 0.630 |
| 0.06 | −3.3% (0.771) | −0.5% (0.994) | −17.7% (0.161) | 0.954 | 0.970 | 0.699 | −19.0% (0.122) | −6.2% (0.123) | −11.6% (0.026) | 0.938 | 0.948 | 0.933 | |
| 0.10 | −3.3% (0.867) | −0.5% (0.982) | −29.8% (0.143) | 0.942 | 0.944 | 0.335 | −10.3% (0.114) | −2.6% (0.113) | −52.1% (0.023) | 0.933 | 0.948 | 0.376 | |
| 0.14 | −3.7% (0.790) | −0.9% (1.059) | −41.8% (0.136) | 0.952 | 0.961 | 0.083 | −7.9% (0.113) | −2.3% (0.114) | −69.2% (0.022) | 0.954 | 0.962 | 0.008 | |
| 0.18 | −4.3% (0.851) | −1.4% (1.163) | −53.6% (0.118) | 0.959 | 0.964 | 0.003 | −7.2% (0.108) | −2.7% (0.109) | −78.5% (0.019) | 0.956 | 0.958 | 0.000 | |
| 30% | 0.02 | −6.0% (0.546) | −0.5% (0.569) | −6.5% (0.175) | 0.945 | 0.963 | 0.916 | −85.6% (0.110) | −10.4% (0.111) | 189.7% (0.028) | 0.932 | 0.957 | 0.640 |
| 0.06 | −5.6% (0.556) | 0.0% (0.583) | −18.0% (0.162) | 0.939 | 0.955 | 0.682 | −28.5% (0.101) | −2.9% (0.101) | −12.3% (0.026) | 0.926 | 0.952 | 0.928 | |
| 0.10 | −6.1% (0.536) | −0.4% (0.619) | −29.4% (0.151) | 0.927 | 0.943 | 0.342 | −19.2% (0.097) | −3.6% (0.097) | −51.7% (0.024) | 0.929 | 0.942 | 0.369 | |
| 0.14 | −6.4% (0.458) | −0.8% (0.528) | −41.1% (0.135) | 0.951 | 0.954 | 0.080 | −13.9% (0.092) | −2.7% (0.091) | −68.2% (0.022) | 0.927 | 0.953 | 0.011 | |
| 0.l8 | −6.9% (0.493) | −1.2% (0.618) | −53.6% (0.125) | 0.935 | 0.957 | 0.006 | −11.8% (0.090) | −2.8% (0.091) | −78.6% (0.020) | 0.920 | 0.950 | 0.000 | |
| Calib. Size | Relative Bias of (SD) | Coverage Rate of | Relative Bias of (SD) | Coverage Rate of | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IN | FC | N | IN | FC | N | IN | FC | N | IN | FC | N | ||
| 5% | 0.75 | −14.1% (22.094) | −5.1% (27.250) | −40.6% (0.145) | 0.970 | 0.983 | 0.509 | −35.0% (1.966) | −15.2% (2.444) | −69.5% (0.023) | 0.942 | 0.968 | 0.375 |
| 0.85 | −9.0% (8.468) | −4.4% (9.954) | −40.9% (0.128) | 0.966 | 0.976 | 0.479 | −20.5% (0.700) | −10.4% (0.800) | −68.2% (0.020) | 0.944 | 0.958 | 0.364 | |
| 0.90 | −5.3% (4.876) | −2.5% (5.373) | −40.5% (0.125) | 0.967 | 0.976 | 0.460 | −10.6% (0.316) | −4.4% (0.336) | −67.0% (0.020) | 0.943 | 0.954 | 0.338 | |
| 0.95 | −1.5% (2.398) | −0.2% (2.626) | −38.0% (0.123) | 0.950 | 0.953 | 0.504 | −4.7% (0.184) | −1.7% (0.187) | −64.7% (0.019) | 0.947 | 0.953 | 0.352 | |
| 15% | 0.75 | −31.1% (5.298) | −3.9% (6.133) | −40.7% (0.151) | 0.908 | 0.976 | 0.528 | −71.3% (0.392) | −11.7% (0.420) | −68.9% (0.024) | 0.808 | 0.957 | 0.383 |
| 0.85 | −15.6% (2.250) | −1.8% (2.826) | −39.8% (0.135) | 0.954 | 0.975 | 0.500 | −35.4% (0.200) | −5.0% (0.213) | −67.0% (0.021) | 0.927 | 0.966 | 0.344 | |
| 0.90 | −10.4% (1.456) | −1.7% (1.794) | −38.7% (0.124) | 0.951 | 0.960 | 0.504 | −24.6% (0.145) | −5.4% (0.152) | −65.5% (0.020) | 0.933 | 0.960 | 0.351 | |
| 0.95 | −4.5% (0.732) | −0.5% (0.838) | −38.6% (0.130) | 0.961 | 0.961 | 0.476 | −11.4% (0.097) | −2.5% (0.098) | −65.6% (0.020) | 0.949 | 0.960 | 0.318 | |
| 30% | 0.75 | −58.0% (3.127) | −4.4% (3.189) | −40.3% (0.144) | 0.639 | 0.977 | 0.547 | −130.8% (0.209) | −13.4% (0.224) | −68.3% (0.023) | 0.390 | 0.951 | 0.379 |
| 0.85 | −31.6% (1.467) | −4.0% (1.350) | −40.1% (0.132) | 0.837 | 0.967 | 0.494 | −70.5% (0.128) | −9.8% (0.131) | −67.3% (0.021) | 0.780 | 0.951 | 0.361 | |
| 0.90 | −18.9% (0.913) | −1.7% (1.008) | −39.1% (0.127) | 0.91 | 0.961 | 0.478 | −42.8% (0.105) | −4.9% (0.108) | −66.4% (0.020) | 0.891 | 0.957 | 0.336 | |
| 0.95 | −9.5% (0.475) | −1.4% (0.456) | −37.7% (0.122) | 0.924 | 0.935 | 0.492 | −22.9% (0.083) | −5.1% (0.084) | −64.0% (0.019) | 0.920 | 0.935 | 0.336 | |
| Study | Cases/Controls | (SE) | (SE) | |
|---|---|---|---|---|
| NHS | 348/694 | 29 | −3.56 (2.72) | 1.13 (0.97) |
| HPFS | 267/519 | 29 | 3.38 (2.95) | 0.05 (0.04) |
| Method | ||
|---|---|---|
| Internalized calibration | −0.0116 (−0.0214, −0.0017) | 7.9307 (−4.6375, 2.0499) |
| Full calibration | −0.0115 (−0.0213, −0.0017) | 7.9885 (−4.8290, 2.0806) |
| Linear model (FC) | −0.0059 (−0.0108, −0.0010) | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Gail, M.; Smith-Warner, S.; Ziegler, R.; Wang, M. Spline Analysis of Biomarker Data Pooled from Multiple Matched/Nested Case–Control Studies. Cancers 2022, 14, 2783. https://doi.org/10.3390/cancers14112783
Wu Y, Gail M, Smith-Warner S, Ziegler R, Wang M. Spline Analysis of Biomarker Data Pooled from Multiple Matched/Nested Case–Control Studies. Cancers. 2022; 14(11):2783. https://doi.org/10.3390/cancers14112783
Chicago/Turabian StyleWu, Yujie, Mitchell Gail, Stephanie Smith-Warner, Regina Ziegler, and Molin Wang. 2022. "Spline Analysis of Biomarker Data Pooled from Multiple Matched/Nested Case–Control Studies" Cancers 14, no. 11: 2783. https://doi.org/10.3390/cancers14112783