
Unsupervised Deep Learning Registration of Uterine Cervix Sequence Images




Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Datasets
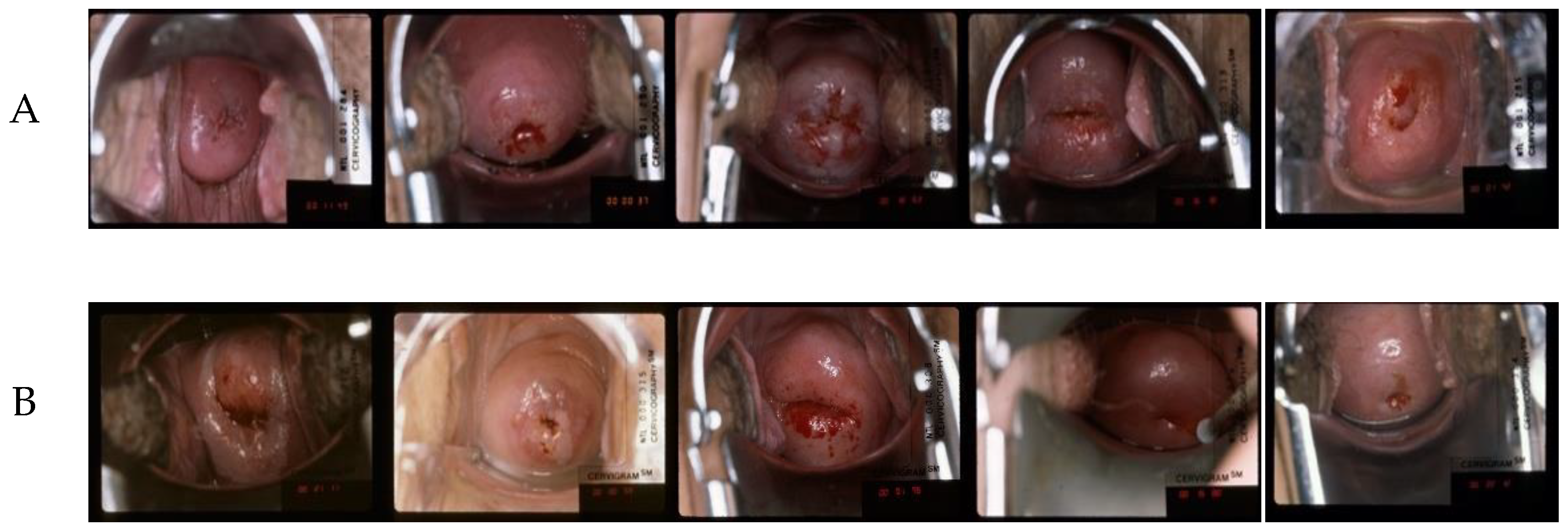
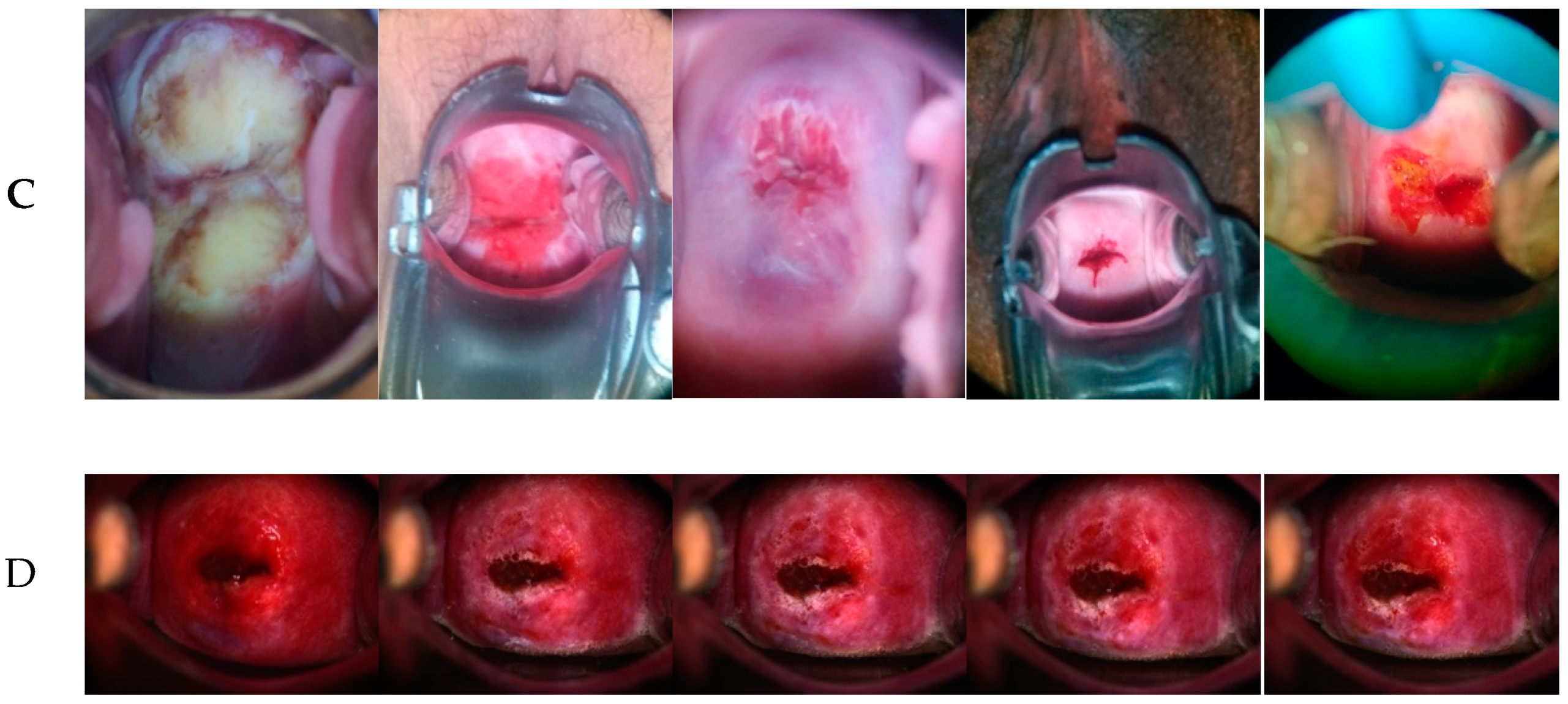
2.1.1. CVT Dataset
2.1.2. ALTS Dataset
2.1.3. Kaggle Dataset
2.1.4. DYSIS Dataset
2.2. Dataset Split
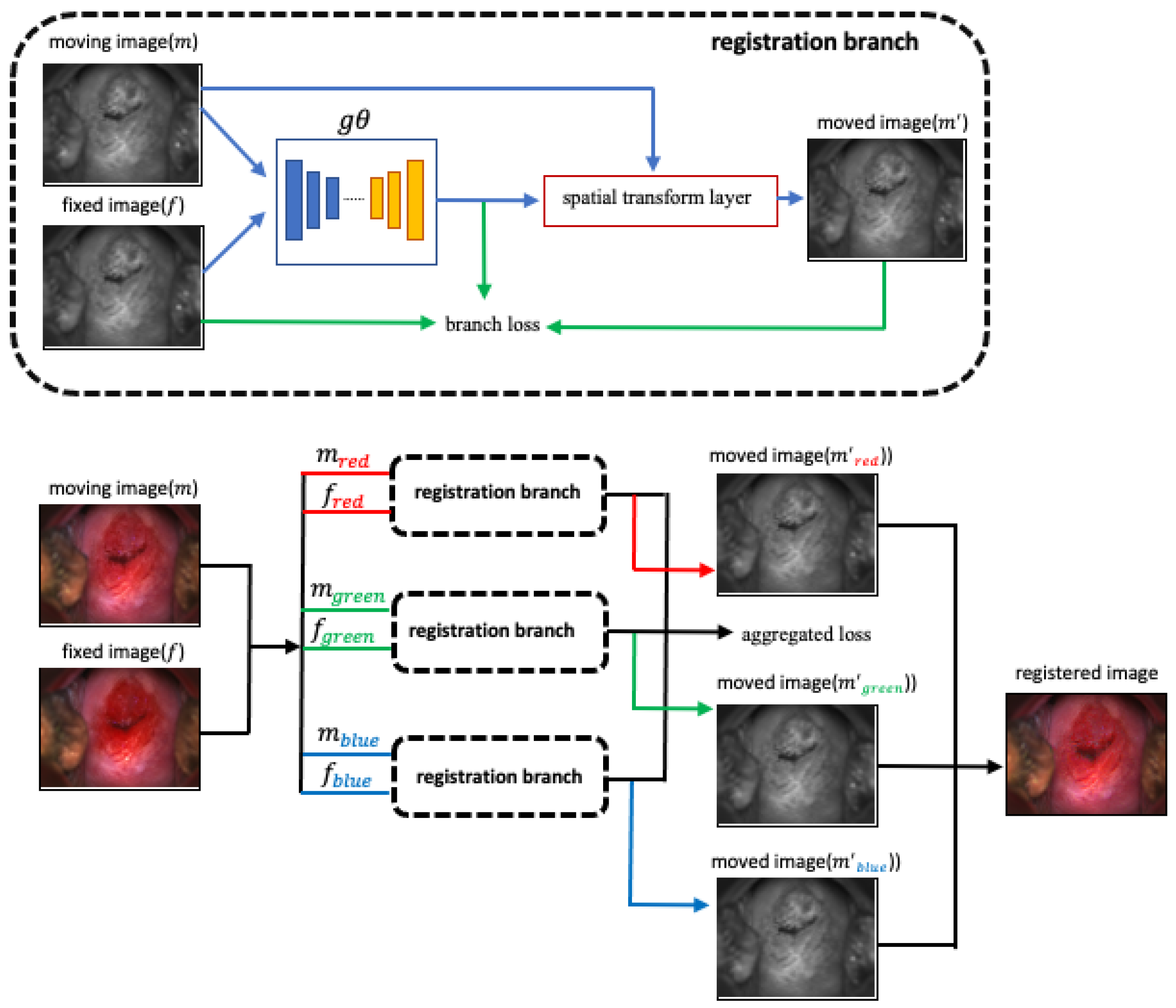
2.3. Registration Network
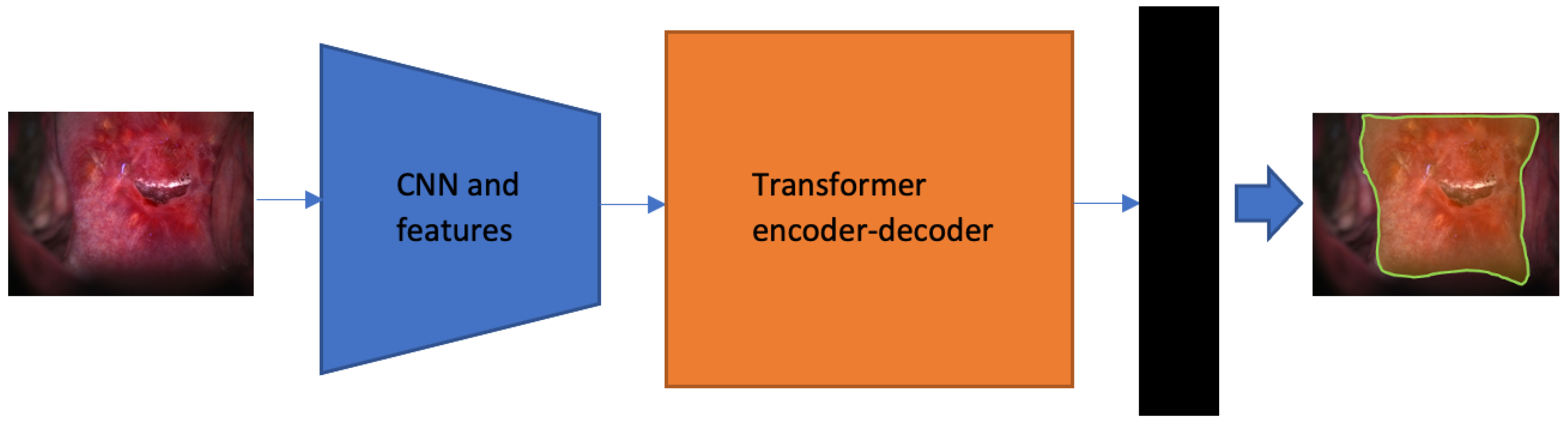
2.4. Segmentation Network
3. Results
3.1. Implementation Details
3.2. Experiment Results
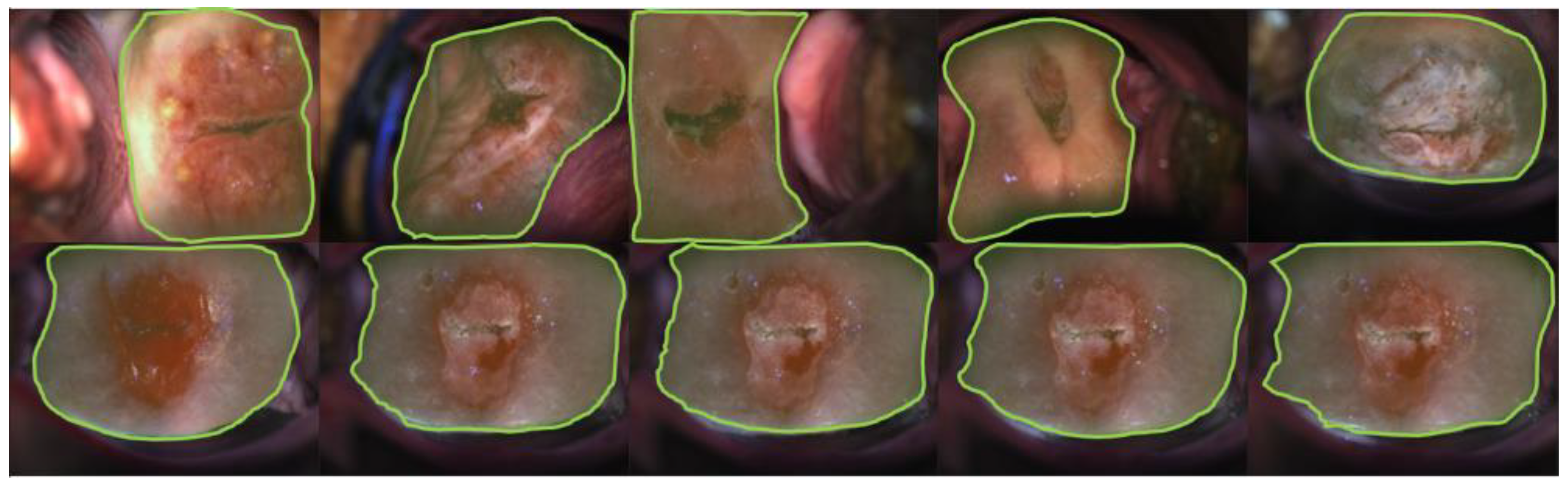
3.2.1. Visual Impression—Segmentation
3.2.2. Quantitative Measurements—Segmentation
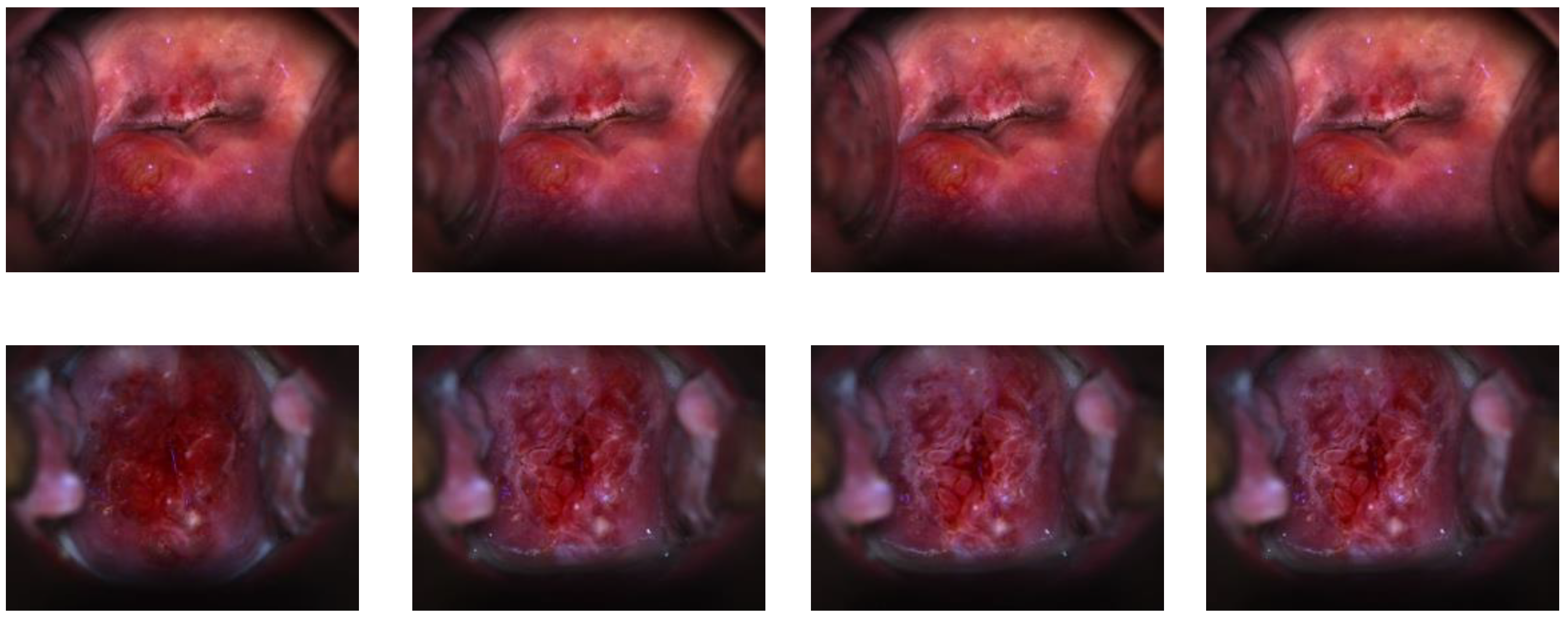
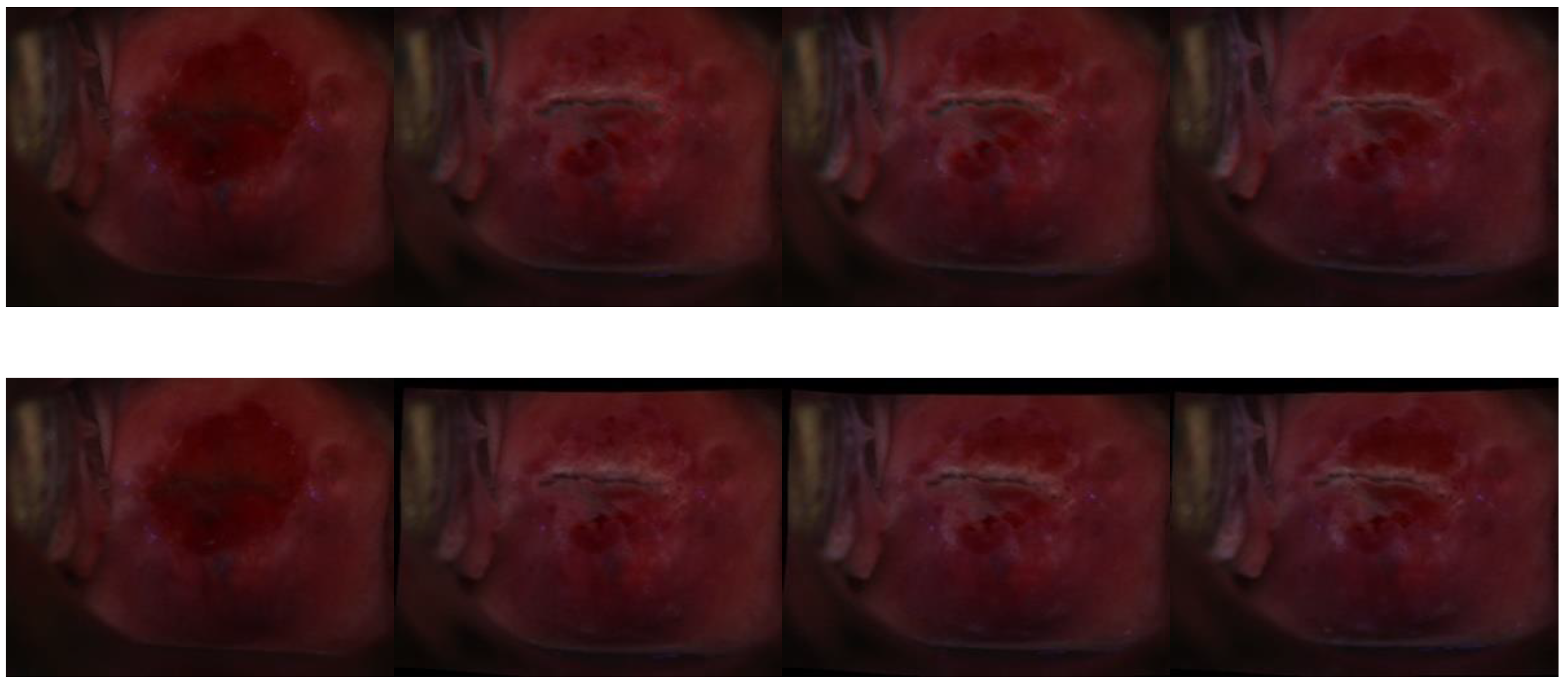
3.2.3. Visual Impression—Registration
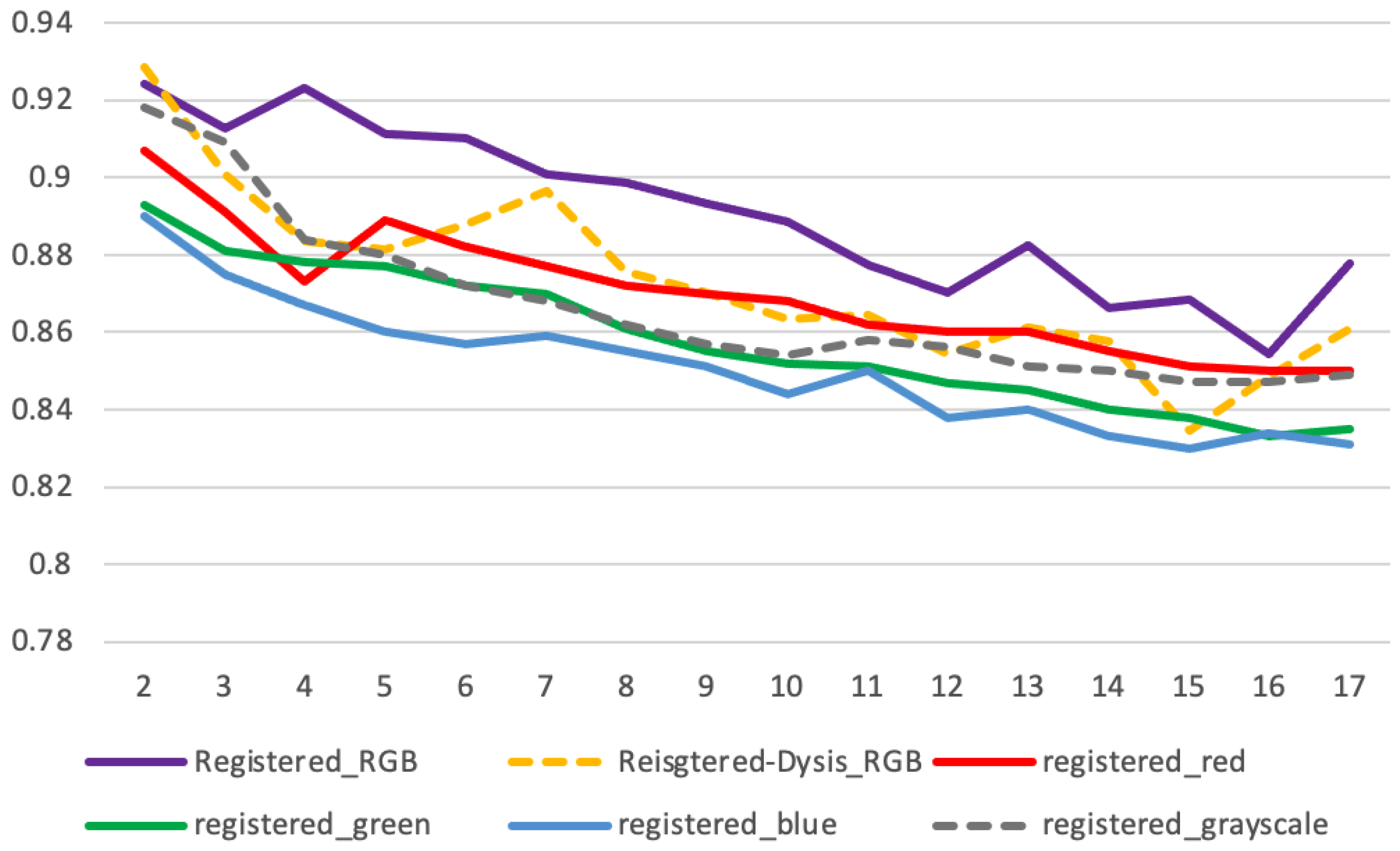
3.2.4. Quantitative Measurements—Registration
3.2.5. Limitations
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. Human Papillomavirus (HPV) and Cervical Cancer. World Health Organization. 24 January 2019. Available online: https://www.who.int/health-topics/cervical-cancer#tab=tab_1 (accessed on 10 February 2022).
- Tao, L.; Amanguli, A.; Li, F.; Wang, Y.H.; Yang, L.; Mohemaiti, M.; Zhao, J.; Zou, X.G.; Saimaiti, A.; Abudu, M.; et al. Cervical Screening by Pap Test and Visual Inspection Enabling Same-Day Biopsy in LowResource. Obs. Gynecol. 2018, 132, 1421–1429. [Google Scholar] [CrossRef] [PubMed]
- Jeronimo, J.; Massad, L.S.; Castle, P.E.; Wacholder, S.; Schiffman, M. National Institutes of Health (NIH)-American Society for Colposcopy and Cervical Pathology (ASCCP) Research Group. Interobserver agreement in the evaluation of digitized cervical images Obstetrics and gynecology. Obs. Gynecol. 2007, 110, 833–840. [Google Scholar] [CrossRef] [PubMed]
- Hu, L.; Bell, D.; Antani, S.; Xue, Z.; Yu, K.; Horning, M.P.; Gachuhi, N.; Wilson, B.; Jaiswal, M.S.; Befano, B.; et al. An observational study of deep learning and automated evaluation of cervical images for cancer screening. J. Nat. Cancer Inst. 2019, 111, 923–932. [Google Scholar] [CrossRef] [PubMed]
- Xue, Z.; Novetsky, A.P.; Einstein, M.H.; Marcus, J.Z.; Befano, B.; Guo, P.; Demarco, M.; Wentzensen, N.; Long, L.R.; Schiffman, M.; et al. A demonstration of automated visual evaluation of cervical images taken with a smartphone camera. Int. J. Cancer 2020, 147, 2416–2423. [Google Scholar] [CrossRef] [PubMed]
- Guo, P.; Xue, Z.; Jeronimo, J.; Gage, J.C.; Desai, K.T.; Befano, B.; García, F.; Long, L.R.; Schiffman, M.; Antani, S. Network Visualization and Pyramidal Feature Comparison for Ablative Treatability Classification Using Digitized Cervix Images. J. Clin. Med. 2021, 10, 953. [Google Scholar] [CrossRef]
- Angara, S.; Guo, P.; Xue, Z.; Antani, S. Semi-Supervised Learning for Cervical Precancer Detection. In Proceedings of the 2021 IEEE 34th International Symposium on Computer-Based Medical Systems (CBMS), Aveiro, Portugal, 7–9 June 2021; pp. 202–206. [Google Scholar] [CrossRef]
- Guo, P.; Xue, Z.; Long, L.R.; Antani, S. Cross-Dataset Evaluation of Deep Learning Networks for Uterine Cervix Segmentation. Diagnostics 2020, 10, 44. [Google Scholar] [CrossRef] [Green Version]
- Guo, P.; Xue, Z.; Long, L.R.; Antani, S.K. Anatomical landmark segmentation in uterine cervix images using deep learning. In Proceedings of the SPIE 11318, Medical Imaging 2020: Imaging Informatics for Healthcare, Research, and Applications, Houston, TX, USA, 2 March 2020; p. 1131810. [Google Scholar] [CrossRef]
- Louwers, J.; Zaal, A.; Kocken, M.; Ter Harmsel, W.; Graziosi, G.; Spruijt, J.; Berkhof, J.; Balas, C.; Papagiannakis, E.; Snijders, P.; et al. Dynamic spectral imaging colposcopy: Higher sensitivity for detection of premalignant cervical lesions. BJOG 2011, 118, 309–318. [Google Scholar] [CrossRef]
- DeNardis, S.A.; Lavin, P.T.; Livingston, J.; Salter, W.R.; James-Patrick, N.; Papagiannakis, E.; Olson, C.G.; Weinberg, L. Increased detection of precancerous cervical lesions with adjunctive dynamic spectral imaging. Int. J. Women’s Health 2017, 9, 717–725. [Google Scholar] [CrossRef] [Green Version]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12346. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transform Network. Adv. Neural Inf. Processing Syst. 2015, 28, 2017–2025. [Google Scholar]
- Bajcsy, R.; Kovacic, S. Multiresolution elastic matching. Computer Vision. Graph. Image Processing 1989, 46, 1–21. [Google Scholar] [CrossRef]
- Dalca, A.V.; Bobu, A.; Rost, N.S.; Golland, P. Patch-based discrete registration of clinical brain images. In International Workshop on Patch-Based Techniques in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2016; pp. 60–67. [Google Scholar]
- Glocker, B.; Komodakis, N.; Tziritas, G.; Navab, N.; Paragios, N. Dense image registration through mrfs and efficient linear programming. Med. Image Anal. 2008, 12, 731–741. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ashburner, J.; Friston, K. Voxel-based morphometry-the methods. Neuroimage 2000, 11, 805–821. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beg, M.F.; Miller, M.I.; Trouvé, A.; Younes, L. Computing large deformation metric mappings via geodesic flows of diffeomorphisms. Int. J. Comput. Vision 2005, 61, 139–157. [Google Scholar] [CrossRef]
- Rueckert, D.; Sonoda, L.I.; Hayes, C.; Hill, D.; Leach, M.O. Nonrigid registration using free-form deformation: Application to breast mr images. IEEE Trans. Med. Imaging 1999, 18, 712–721. [Google Scholar] [CrossRef]
- Krebs, J.; Mansi, T.; Delingette, H.; Li, Z.; Ghesu, F.C.; Miao, S.; Maier, A.K.; Ayache, N.; Liao, R.; Kamen, A. Robust non-rigid registration through agent based action learning. In International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI); Springer: Berlin/Heidelberg, Germany, 2017; pp. 344–352. [Google Scholar]
- Rohé, M.-M.; Datar, M.; Heimann, T.; Sermesant, M.; Pennec, X. Svf-net: Learning deformable image registration using shape matching. In International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI); Springer: Berlin/Heidelberg, Germany, 2017; pp. 266–274. [Google Scholar]
- Sokooti, H.; Vos, B.D.; Berendsen, F.; Lelieveldt, B.; Išgum, I.; Staring, M. Nonrigid image registration using multiscale 3d convolutional neural networks. In International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI); Springer: Berlin/Heidelberg, Germany, 2017; pp. 232–239. [Google Scholar]
- Yang, X.; Kwitt, R.; Styner, M.; Niethammer, M. Quicksilver: Fast predictive image registration—A deep learning approach. NeuroImage 2017, 158, 378–396. [Google Scholar] [CrossRef]
- Vos, B.; Berendsen, F.F.; Viergever, M.A.; Staring, M.; Igum, I. End-to-end unsupervised deformable image registration with a convolutional neural network. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2017; pp. 204–212. [Google Scholar]
- Li, H.; Fan, Y. Non-rigid image registration using fully convolutional networks with deep self-supervision. arXiv 2017, arXiv:1709.00799. [Google Scholar]
- Balakrishnan, G.; Zhao, A.; Sabuncu, M.R.; Guttag, J.; Dalca, A.V. VoxelMorph: A Learning Framework for Deformable Medical Image Registration. IEEE Trans. Med. Imaging 2019, 38, 1788–1800. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zhao, S.G. Cervical image classification based on image segmentation preprocessing and a CapsNet network model. Int. J. Imaging Syst. Technol. 2019, 29, 19–28. [Google Scholar] [CrossRef] [Green Version]
- Fernandes, K.; Cruz, R.; Cardoso, J.S. Deep Image Segmentation by Quality Inference. In Proceedings of the International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Gorantla, R.; Singh, R.K.; Pandey, R.; Jain, M. Cervical Cancer Diagnosis Using CervixNet-A Deep Learning Approach. In Proceedings of the IEEE Conference (BIBE), Athens, Greece, 28–30 October 2019. [Google Scholar]
- Herrero, R.; Hildesheim, A.; Rodríguez, A.C.; Wacholder, S.; Bratti, C.; Solomon, D.; González, P.; Porras, C.; Jiménez, S.; Guillen, D.; et al. Rationale and design of a community-based double-blind randomized clinical trial of an HPV 16 and 18 vaccine in Guanacaste, Costa Rica. Vaccine 2008, 26, 4795–4808. [Google Scholar] [CrossRef] [Green Version]
- Herrero, R.; Wacholder, S.; Rodríguez, A.C.; Solomon, D.; González, P.; Kreimer, A.R.; Porras, C.; Schussler, J.; Jiménez, S.; Sherman, M.E.; et al. Prevention of persistent Human Papillomavirus Infection by an HPV16/18 vaccine: A community-based randomized clinical trial in Guanacaste, Costa Rica. Cancer Discov. 2011, 1, 408–419. [Google Scholar] [CrossRef] [Green Version]
- The Atypical Squamous Cells of Undetermined Significance/Low-Grade Squamous Intraepithelial Lesions Triage Study (ALTS) Group. Human Papillomavirus Testing for Triage of Women with Cytologic Evidence of Low-Grade Squamous Intraepithelial Lesions: Baseline Data from a Randomized Trial. J. Nat. Cancer Inst. 2000, 92, 397–402. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Intel & MobileODT Cervical Cancer Screening Competition. March 2017. Available online: https://www.kaggle.com/c/intel-mobileodt-cervical-cancer-screening (accessed on 8 December 2021).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929v1. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. arXiv 2017, arXiv:abs/1706.03762. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Label | Image Size | Number of Images | ||
|---|---|---|---|---|
| Training | Validation | Test | ||
| A | 1200 × 800 | 2447 | 350 | 601 |
| B | 1200 × 800 | 939 | 0 | 0 |
| C | 900 × 1200 | 1268 | 180 | 502 |
| D | 1024 × 768 | 210 × 17 | 30 × 17 | 60 × 17 |
| Tested Dataset | Testing Measurements (Dice/IoU) | |
|---|---|---|
| This Study | Prior Work [8] | |
| A | 0.938/0.885 | 0.945/0.897 |
| C | 0.917/0.870 | 0.916/0.863 |
| Unregistered | Registered (RGB/Red/Green/Blue/Grayscale) | ||||||
|---|---|---|---|---|---|---|---|
| 2nd | 0.908 | 10th | 0.782 | 2nd | 0.924/0.907/0.893/0.890/0.918 | 10th | 0.889/0.868/0.852/0.844/0.854 |
| 3rd | 0.878 | 11th | 0.773 | 3rd | 0.913/0.891/0.881/0.875/0.909 | 11th | 0.878/0.862/0.851/0.850/0.858 |
| 4th | 0.852 | 12th | 0.770 | 4th | 0.923/0.873/0.878/0.867/0.884 | 12th | 0.870/0.860/0.847/0.838/0.856 |
| 5th | 0.840 | 13th | 0.748 | 5th | 0.911/0.889/0.877/0.860/0.880 | 13th | 0.883/0.860/0.845/0.840/0.851 |
| 6th | 0.802 | 14th | 0.733 | 6th | 0.910/0.882/0.872/0.857/0.872 | 14th | 0.866/0.855/0.840/0.833/0.850 |
| 7th | 0.803 | 15th | 0.740 | 7th | 0.901/0.877/0.870/0.859/0.868 | 15th | 0.869/0.851/0.838/0.830/0.847 |
| 8th | 0.801 | 16th | 0.739 | 8th | 0.899/0.872/0.861/0.855/0.862 | 16th | 0.854/0.850/0.833/0.834/0.847 |
| 9th | 0.767 | 17th | 0.741 | 9th | 0.893/0.870/0.855/0.851/0.857 | 17th | 0.878/0.850/0.835/0.831/0.849 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, P.; Xue, Z.; Angara, S.; Antani, S.K. Unsupervised Deep Learning Registration of Uterine Cervix Sequence Images. Cancers 2022, 14, 2401. https://doi.org/10.3390/cancers14102401
Guo P, Xue Z, Angara S, Antani SK. Unsupervised Deep Learning Registration of Uterine Cervix Sequence Images. Cancers. 2022; 14(10):2401. https://doi.org/10.3390/cancers14102401
Chicago/Turabian StyleGuo, Peng, Zhiyun Xue, Sandeep Angara, and Sameer K. Antani. 2022. "Unsupervised Deep Learning Registration of Uterine Cervix Sequence Images" Cancers 14, no. 10: 2401. https://doi.org/10.3390/cancers14102401