
Prediction of Prostate Cancer Disease Aggressiveness Using Bi-Parametric Mri Radiomics

 ,
,
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
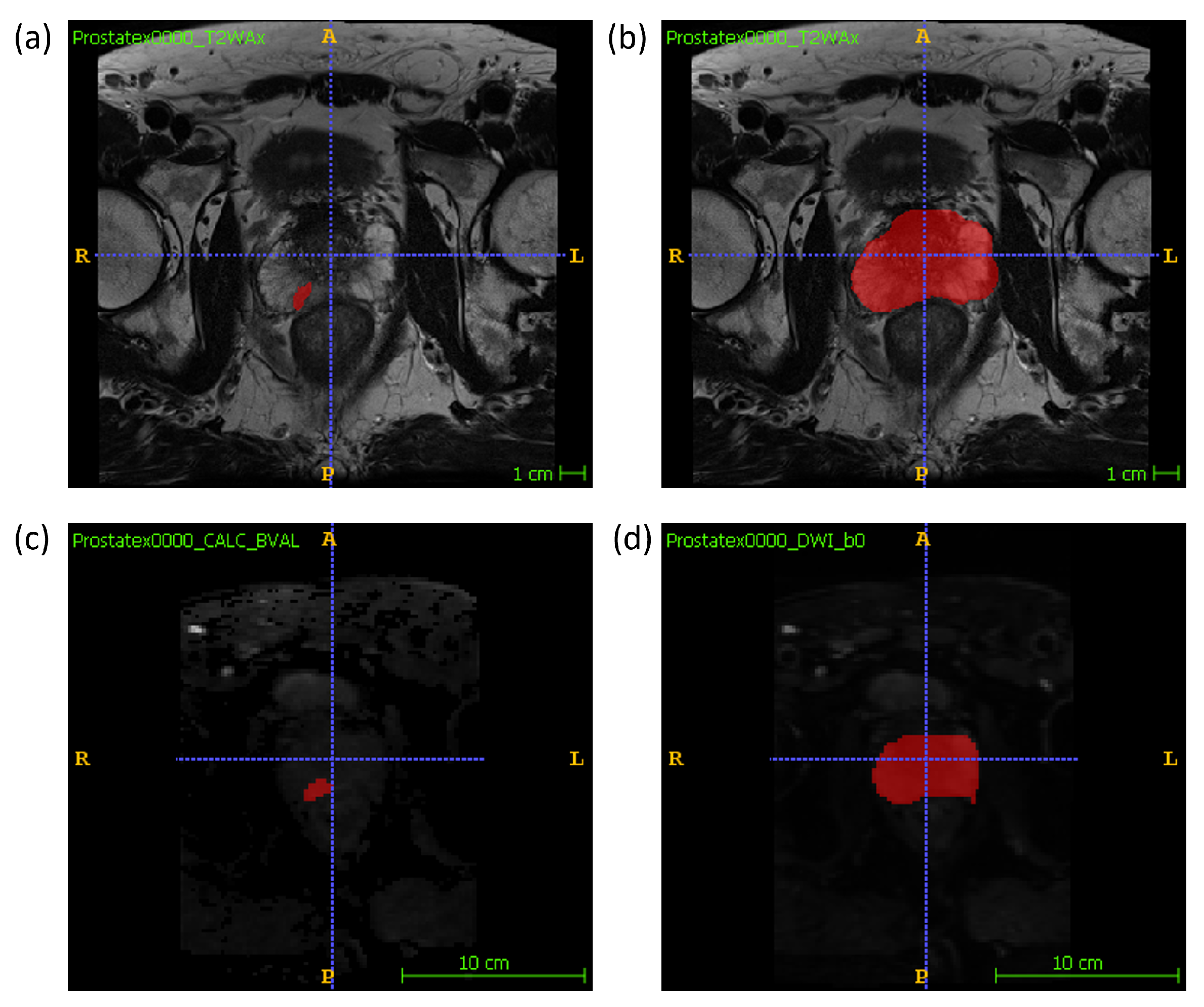
2.1. Data Description
2.2. Feature Extraction
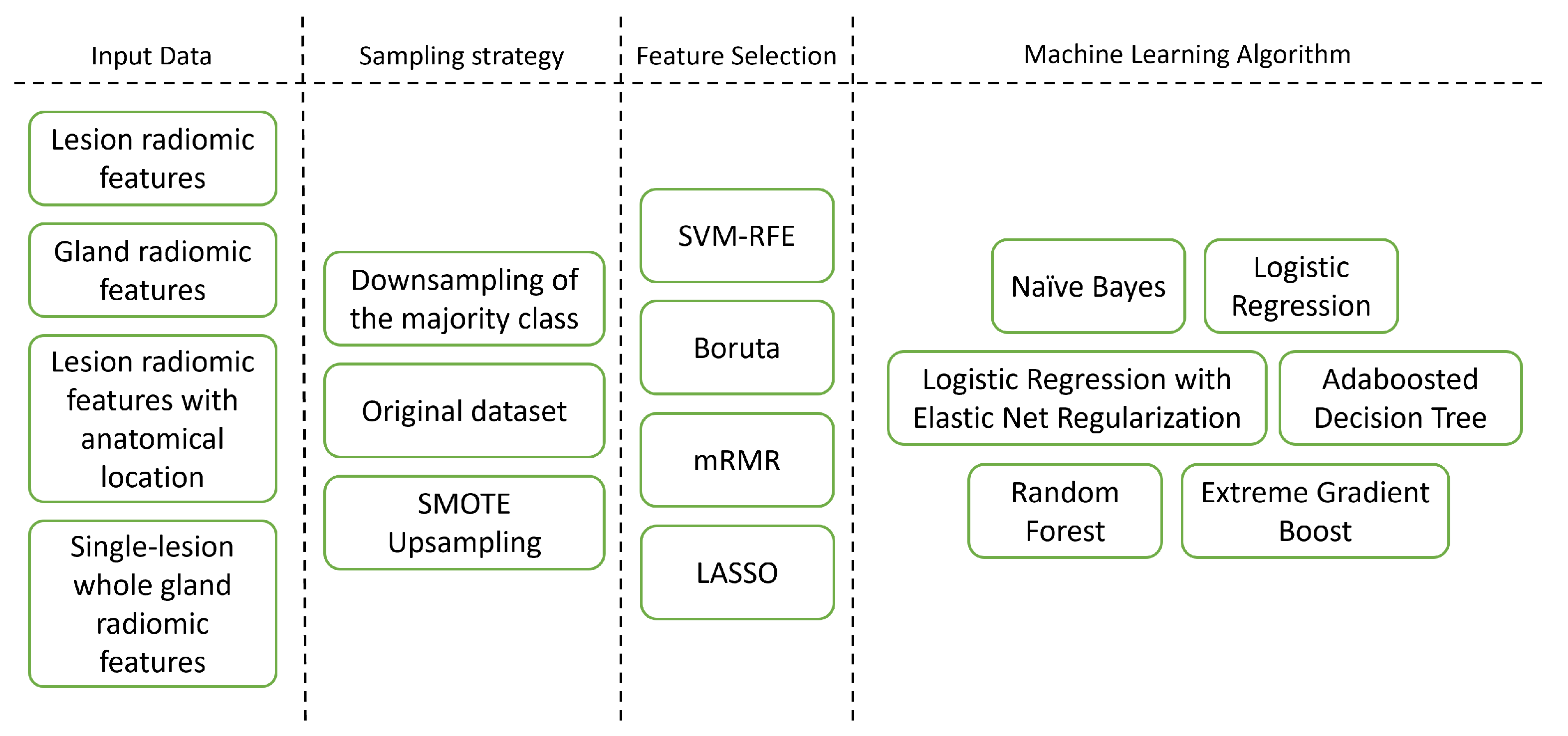
2.3. Dataset Construction
- Lesion Features with Anatomical Zone dataset—A dataset composed of lesion features plus features describing the anatomical location of the lesion.
- Single-Lesion Whole Gland Features dataset—A truncated dataset composed of patients from the Gland dataset that had one only lesion.
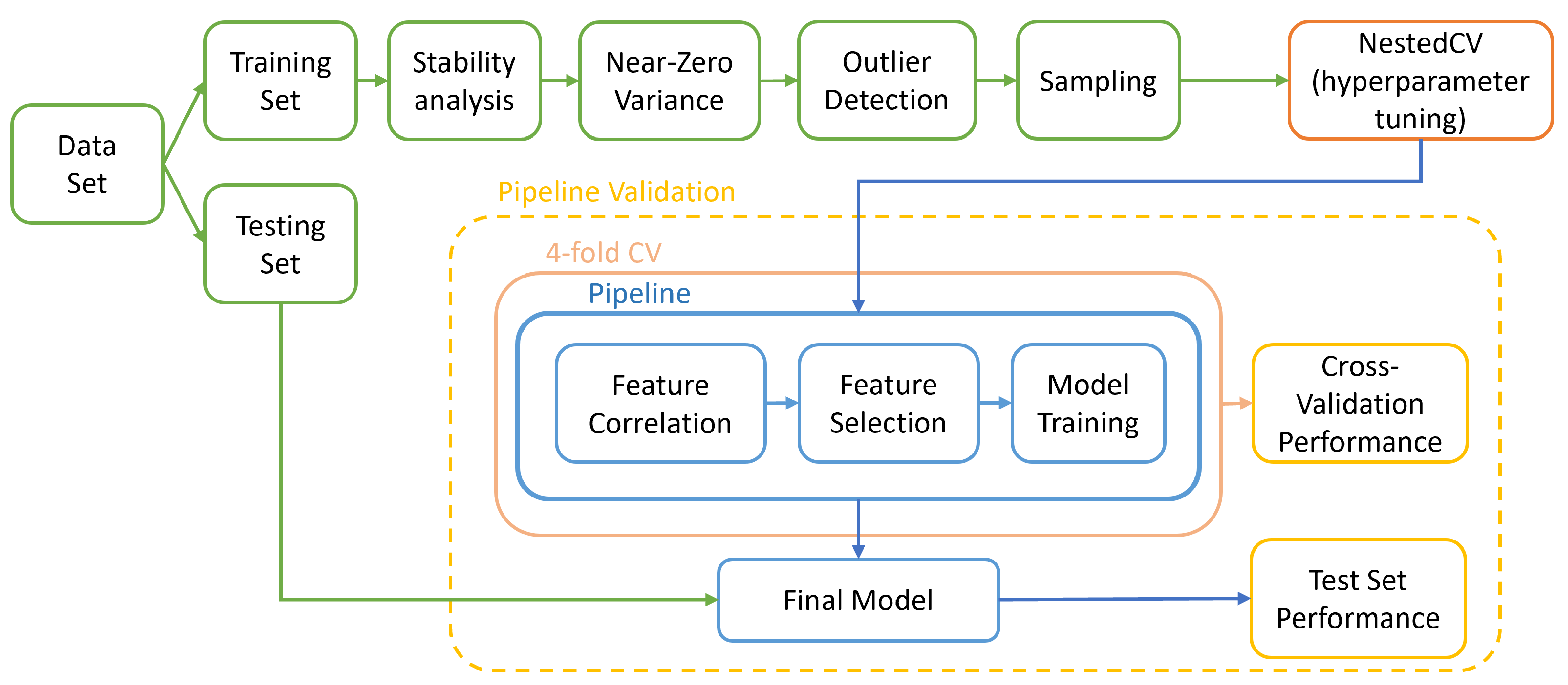
2.4. Feature Stability to Segmentation
2.5. Zero or Near-Zero Variance
2.6. Outlier Detection
2.7. Feature Correlation
2.8. Feature Selection
2.9. Model Development
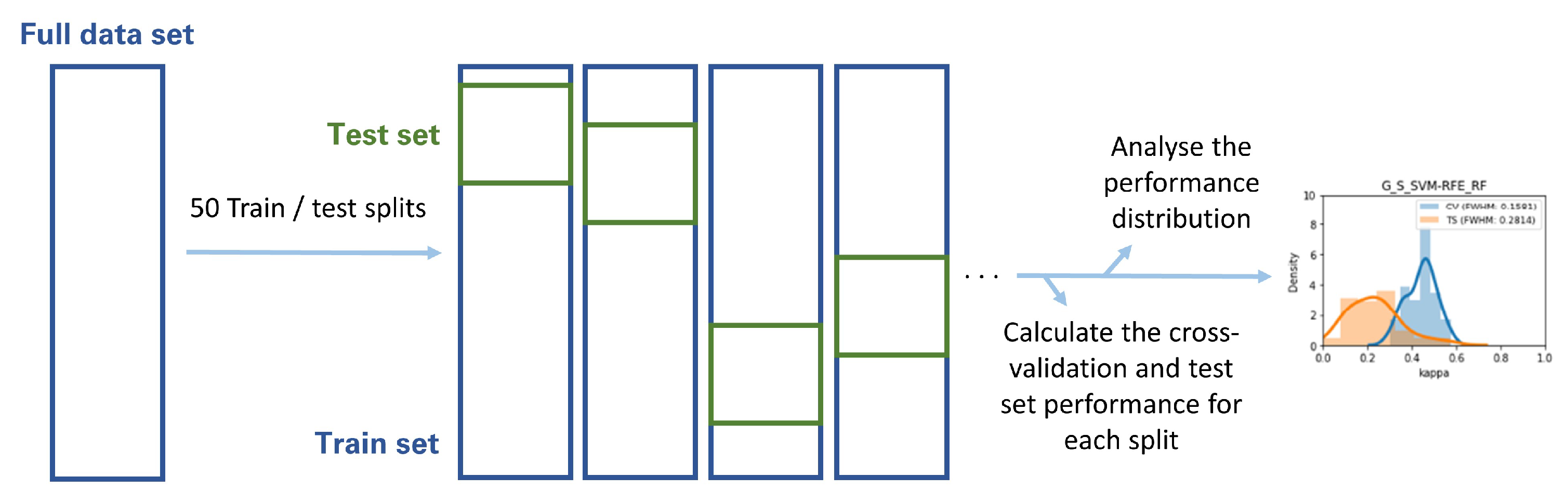
2.10. Metric Volatility Analysis
2.11. Distribution Comparison Tests
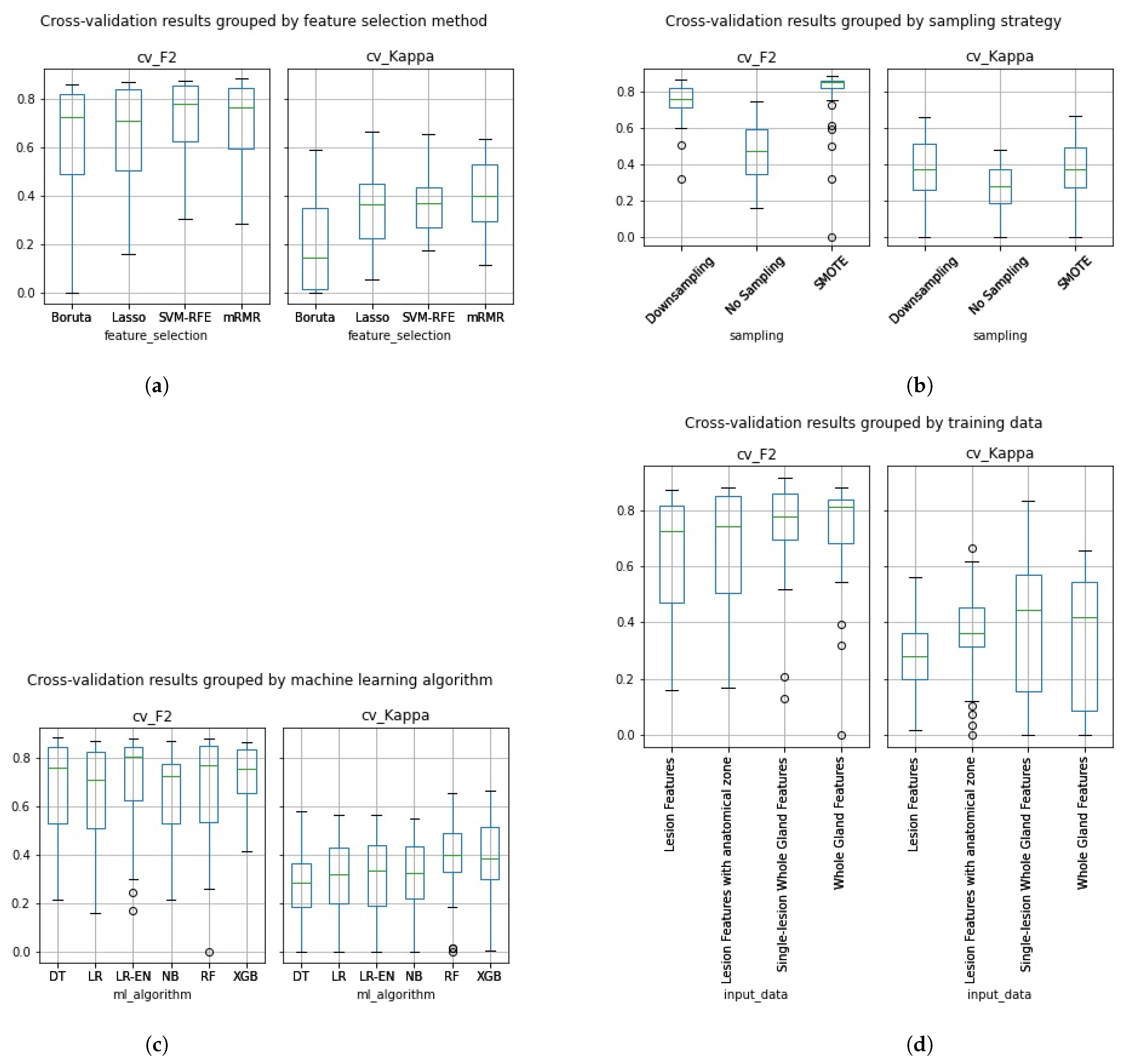
3. Results
3.1. Feature Stability to Segmentation
3.2. Zero or Near-Zero Variance
3.3. Classifier Development
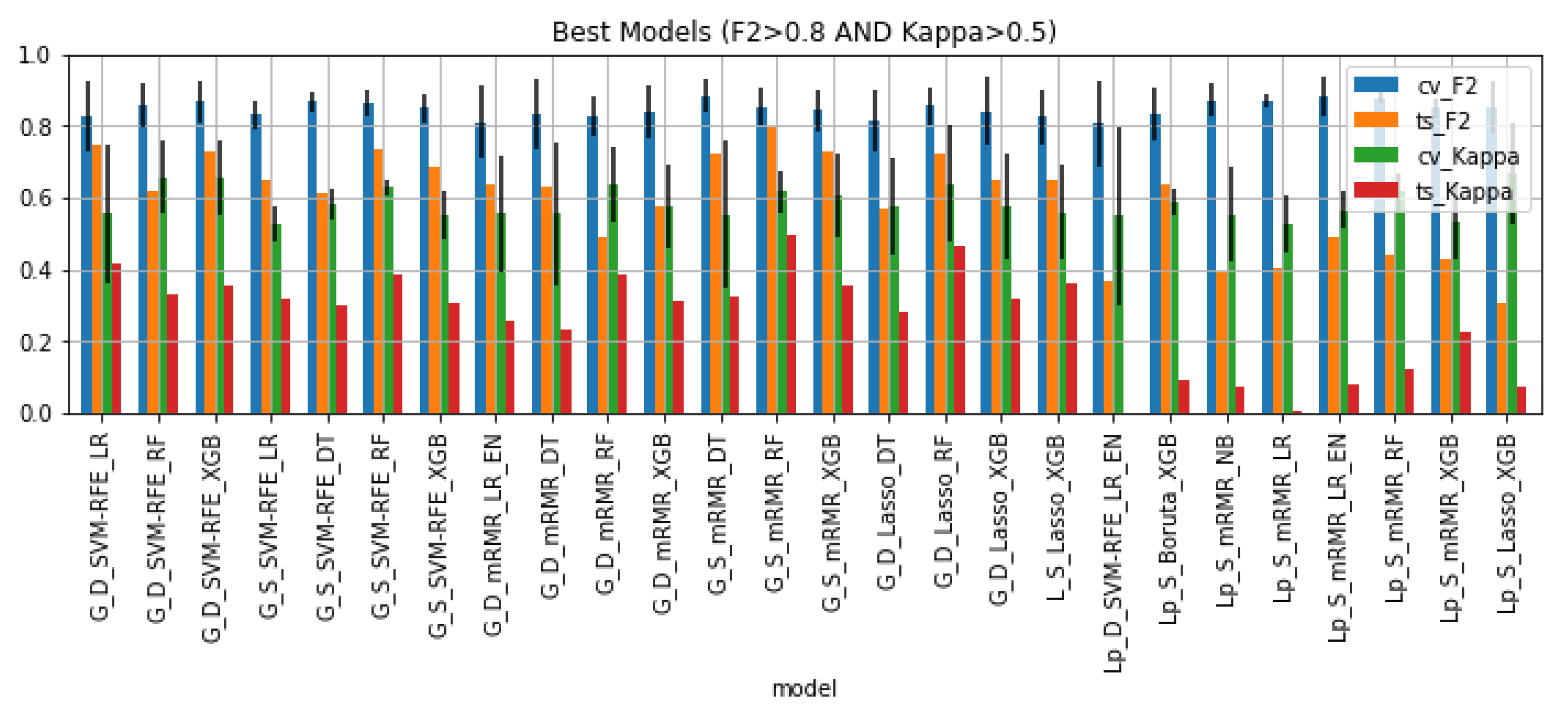
3.4. Best Classifiers Validation
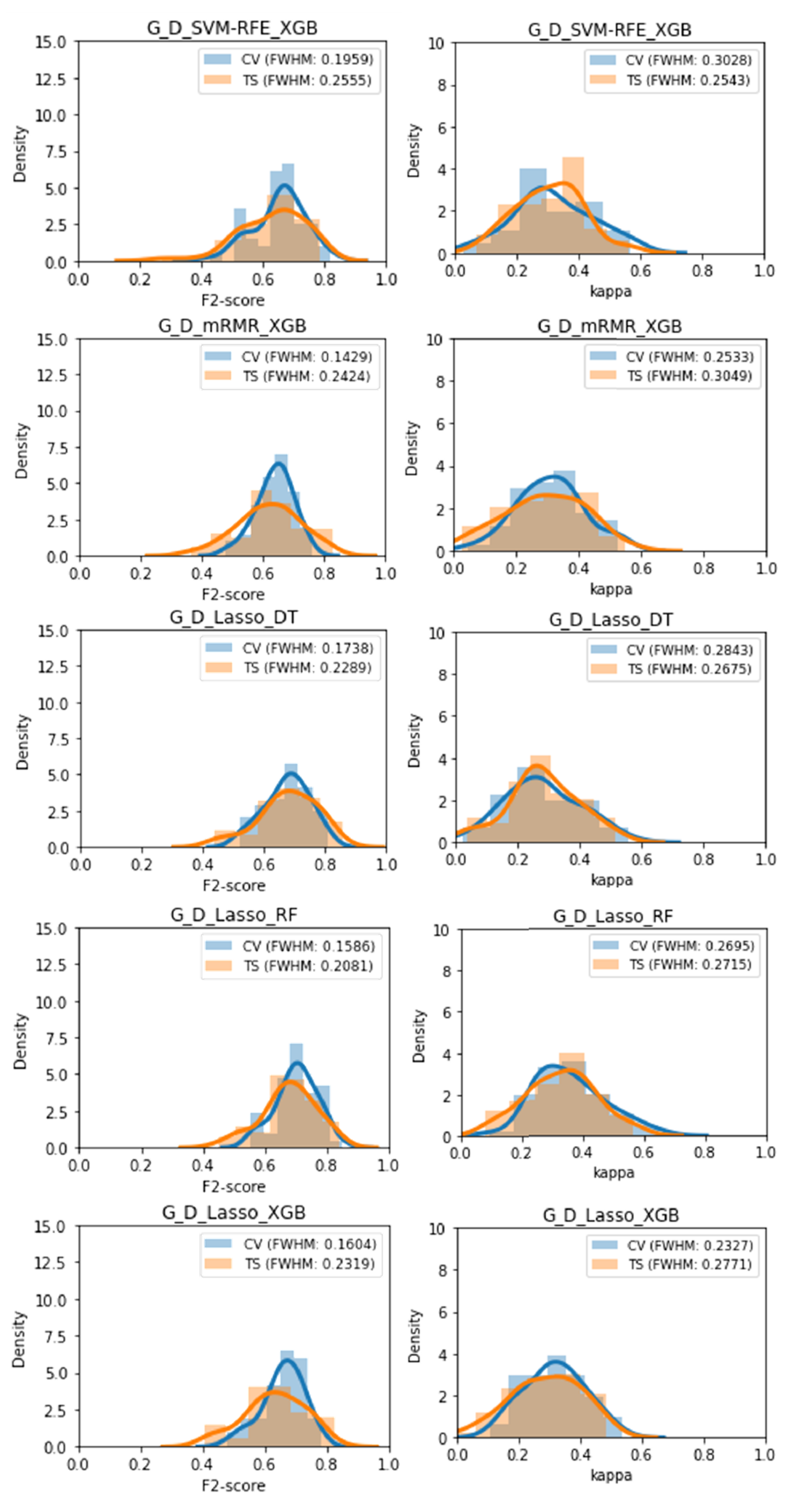
3.5. Metric Volatility Analysis
3.6. Distribution Comparison Tests
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PCa | Prostate cancer |
| GS | Gleason Score |
| DRE | Digital Rectal Examination |
| PSA | Prostate Specific Antigen |
| TRUS | Trans-rectal Ultrasound |
| mpMRI | Multiparametric MRI |
| T2W | T2-weighted imaging |
| DWI | Diffusion-weighted imaging |
| ADC | Apparent diffusion coefficient |
| VOI | Volume of interest |
| G | Model trained with gland data |
| L | Model trained with lesion data |
| Lp | Model trained with lesion data with anatomical location |
| D | Model trained with downsampled data |
| S | Model trained with synthetic SMOTE data |
| NB | Naive Bayes |
| LR | Logistic Regression |
| LR_EN | Logistic Regression with Elastic Net Regularization |
| DT | Decision Tree |
| RF | Random Forest |
| XGB | Extreme Gradient Boost |
| CV | Cross-validation performance |
| TS | Test-set performance |
| FWHM | Full width at half maximum |
References
- World Health Organization, International Agency for Research on Cancer, The Global Cancer Observatory. World Fact-Sheet. Available online: https://gco.iarc.fr/today/fact-sheets-cancers (accessed on 1 March 2021).
- Borkenhagen, J.F.; Eastwood, D.; Kilari, D.; See, W.A.; Van Wickle, J.D.; Lawton, C.A.; Hall, W.A. Digital rectal examination remains a key prognostic tool for prostate cancer: A national cancer database review. J. Natl. Compr. Cancer Netw. 2019, 17, 829–837. [Google Scholar] [CrossRef] [Green Version]
- Catalona, W.J.; Richie, J.P.; Ahmann, F.R.; Hudson, M.A.; Scardino, P.T.; Flanigan, R.C.; Dekernion, J.B.; Ratliff, T.L.; Kavoussi, L.R.; Dalkin, B.L.; et al. Comparison of digital rectal examination and serum prostate specific antigen in the early detection of prostate cancer: Results of a multicenter clinical trial of 6630 men. J. Urol. 1994, 151, 1283–1290. [Google Scholar] [CrossRef]
- Halpern, J.A.; Oromendia, C.; Shoag, J.E.; Mittal, S.; Cosiano, M.F.; Ballman, K.V.; Vickers, A.J.; Hu, J.C. Use of digital rectal examination as an adjunct to prostate specific antigen in the detection of clinically significant prostate cancer. J. Urol. 2018, 199, 947–953. [Google Scholar] [CrossRef]
- Catalona, W.J.; Smith, D.S.; Ratliff, T.L.; Dodds, K.M.; Coplen, D.E.; Yuan, J.J.; Petros, J.A.; Andriole, G.L. Measurement of prostate-specific antigen in serum as a screening test for prostate cancer. N. Engl. J. Med. 1991, 324, 1156–1161. [Google Scholar] [CrossRef] [PubMed]
- Haythorn, M.R.; Ablin, R.J. Prostate-specific antigen testing across the spectrum of prostate cancer. Biomarkers Med. 2011, 5, 515–526. [Google Scholar] [CrossRef] [PubMed]
- Gleason, D.F. Histologic grading of prostate cancer: A perspective. Hum. Pathol. 1992, 23, 273–279. [Google Scholar] [CrossRef]
- George, A.K.; Turkbey, B.; Valayil, S.G.; Muthigi, A.; Mertan, F.; Kongnyuy, M.; Pinto, P.A. A urologist’s perspective on prostate cancer imaging: Past, present, and future. Abdom. Radiol. 2016, 41, 805–816. [Google Scholar] [CrossRef] [PubMed]
- Delongchamps, N.B.; Peyromaure, M.; Schull, A.; Beuvon, F.; Bouazza, N.; Flam, T.; Zerbib, M.; Muradyan, N.; Legman, P.; Cornud, F. Prebiopsy magnetic resonance imaging and prostate cancer detection: Comparison of random and targeted biopsies. J. Urol. 2013, 189, 493–499. [Google Scholar] [CrossRef] [PubMed]
- Haider, M.; Yao, X.; Loblaw, A.; Finelli, A. Multiparametric magnetic resonance imaging in the diagnosis of prostate cancer: A systematic review. Clin. Oncol. 2016, 28, 550–567. [Google Scholar] [CrossRef] [PubMed]
- Boesen, L.; Nørgaard, N.; Løgager, V.; Balslev, I.; Bisbjerg, R.; Thestrup, K.C.; Winther, M.D.; Jakobsen, H.; Thomsen, H.S. Assessment of the diagnostic accuracy of biparametric magnetic resonance imaging for prostate cancer in biopsy-naive men: The Biparametric MRI for Detection of Prostate Cancer (BIDOC) study. JAMA Netw. Open 2018, 1, e180219. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Popiţa, C.; Popiţa, A.R.; Andrei, A.; Rusu, A.; Petruţ, B.; Kacso, G.; Bungărdean, C.; Bolog, N.; Coman, I. Local staging of prostate cancer with multiparametric-MRI: Accuracy and inter-reader agreement. Med. Pharm. Rep. 2020, 93, 150. [Google Scholar] [CrossRef]
- Stabile, A.; Giganti, F.; Rosenkrantz, A.B.; Taneja, S.S.; Villeirs, G.; Gill, I.S.; Allen, C.; Emberton, M.; Moore, C.M.; Kasivisvanathan, V. Multiparametric MRI for prostate cancer diagnosis: Current status and future directions. Nat. Rev. Urol. 2020, 17, 41–61. [Google Scholar] [CrossRef] [PubMed]
- Cutaia, G.; La Tona, G.; Comelli, A.; Vernuccio, F.; Agnello, F.; Gagliardo, C.; Salvaggio, L.; Quartuccio, N.; Sturiale, L.; Stefano, A.; et al. Radiomics and Prostate MRI: Current Role and Future Applications. J. Imaging 2021, 7, 34. [Google Scholar] [CrossRef]
- Stanzione, A.; Gambardella, M.; Cuocolo, R.; Ponsiglione, A.; Romeo, V.; Imbriaco, M. Prostate MRI radiomics: A systematic review and radiomic quality score assessment. Eur. J. Radiol. 2020, 129, 109095. [Google Scholar] [CrossRef] [PubMed]
- Gugliandolo, S.G.; Pepa, M.; Isaksson, L.J.; Marvaso, G.; Raimondi, S.; Botta, F.; Gandini, S.; Ciardo, D.; Volpe, S.; Riva, G.; et al. MRI-based radiomics signature for localized prostate cancer: A new clinical tool for cancer aggressiveness prediction? Sub-study of prospective phase II trial on ultra-hypofractionated radiotherapy (AIRC IG-13218). Eur. Radiol. 2021, 31, 716–728. [Google Scholar] [CrossRef] [PubMed]
- He, D.; Wang, X.; Fu, C.; Wei, X.; Bao, J.; Ji, X.; Bai, H.; Xia, W.; Gao, X.; Huang, Y.; et al. MRI-based radiomics models to assess prostate cancer, extracapsular extension and positive surgical margins. Cancer Imaging 2021, 21, 46. [Google Scholar] [CrossRef] [PubMed]
- Van Timmeren, J.E.; Cester, D.; Tanadini-Lang, S.; Alkadhi, H.; Baessler, B. Radiomics in medical imaging—“How-to” guide and critical reflection. Insights Imaging 2020, 11, 91. [Google Scholar] [CrossRef] [PubMed]
- Cuocolo, R.; Cipullo, M.B.; Stanzione, A.; Romeo, V.; Green, R.; Cantoni, V.; Ponsiglione, A.; Ugga, L.; Imbriaco, M. Machine learning for the identification of clinically significant prostate cancer on MRI: A meta-analysis. Eur. Radiol. 2020, 30, 6877–6887. [Google Scholar] [CrossRef]
- Litjens, G.; Debats, O.; Barentsz, J.; Karssemeijer, N.; Huisman, H. ProstateX Challenge data. Cancer Imaging Arch. 2017. [Google Scholar] [CrossRef]
- Litjens, G.; Debats, O.; Barentsz, J.; Karssemeijer, N.; Huisman, H. Computer-Aided Detection of Prostate Cancer in MRI. IEEE Trans. Med Imaging 2014, 33, 1083–1092. [Google Scholar] [CrossRef] [PubMed]
- Clark, K.; Vendt, B.; Smith, K.; Freymann, J.; Kirby, J.; Koppel, P.; Moore, S.; Phillips, S.; Maffitt, D.; Pringle, M.; et al. The Cancer Imaging Archive (TCIA): Maintaining and operating a public information repository. J. Digit. Imaging 2013, 26, 1045–1057. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Griethuysen, J.J.; Fedorov, A.; Parmar, C.; Hosny, A.; Aucoin, N.; Narayan, V.; Beets-Tan, R.G.; Fillion-Robin, J.C.; Pieper, S.; Aerts, H.J. Computational radiomics system to decode the radiographic phenotype. Cancer Res. 2017, 77, e104–e107. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- McKinney, W. Data structures for statistical computing in python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; Volume 445, pp. 51–56. [Google Scholar]
- Koo, T.K.; Li, M.Y. A guideline of selecting and reporting intraclass correlation coefficients for reliability research. J. Chiropr. Med. 2016, 15, 155–163. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. Artic. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Rapidminer: The Best Data Science and Machine Learning Platform. Available online: https://rapidminer.com/ (accessed on 1 October 2021).
- Kursa, M.B.; Rudnicki, W.R. Feature selection with the Boruta package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Erickson, B.J.; Korfiatis, P.; Akkus, Z.; Kline, T.L. Machine learning for medical imaging. Radiographics 2017, 37, 505–515. [Google Scholar] [CrossRef]
- Shaphiro, S.; Wilk, M. An analysis of variance test for normality. Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- D’agostino, R.B.; Belanger, A.; D’Agostino, R.B., Jr. A suggestion for using powerful and informative tests of normality. Am. Stat. 1990, 44, 316–321. [Google Scholar]
- Massey, F.J., Jr. The Kolmogorov-Smirnov test for goodness of fit. J. Am. Stat. Assoc. 1951, 46, 68–78. [Google Scholar] [CrossRef]
- Shi, Y.; Wahle, E.; Du, Q.; Krajewski, L.; Liang, X.; Zhou, S.; Zhang, C.; Baine, M.; Zheng, D. Associations between statin/omega3 usage and MRI-based radiomics signatures in prostate cancer. Diagnostics 2021, 11, 85. [Google Scholar] [CrossRef] [PubMed]
- Han, C.; Ma, S.; Liu, X.; Liu, Y.; Li, C.; Zhang, Y.; Zhang, X.; Wang, X. Radiomics Models Based on Apparent Diffusion Coefficient Maps for the Prediction of High-Grade Prostate Cancer at Radical Prostatectomy: Comparison With Preoperative Biopsy. J. Magn. Reson. Imaging 2021. [Google Scholar] [CrossRef]
- Armato, S.G.; Huisman, H.; Drukker, K.; Hadjiiski, L.; Kirby, J.S.; Petrick, N.; Redmond, G.; Giger, M.L.; Cha, K.; Mamonov, A.; et al. PROSTATEx Challenges for computerized classification of prostate lesions from multiparametric magnetic resonance images. J. Med Imaging 2018, 5, 044501. [Google Scholar] [CrossRef] [PubMed]
- Zamboglou, C.; Carles, M.; Fechter, T.; Kiefer, S.; Reichel, K.; Fassbender, T.F.; Bronsert, P.; Koeber, G.; Schilling, O.; Ruf, J.; et al. Radiomic features from PSMA PET for non-invasive intraprostatic tumor discrimination and characterization in patients with intermediate-and high-risk prostate cancer-a comparison study with histology reference. Theranostics 2019, 9, 2595. [Google Scholar] [CrossRef]
- Solari, E.L.; Gafita, A.; Schachoff, S.; Bogdanović, B.; Villagrán Asiares, A.; Amiel, T.; Hui, W.; Rauscher, I.; Visvikis, D.; Maurer, T.; et al. The added value of PSMA PET/MR radiomics for prostate cancer staging. Eur. J. Nucl. Med. Mol. Imaging 2021. [Google Scholar] [CrossRef]
- Cuocolo, R.; Stanzione, A.; Castaldo, A.; De Lucia, D.R.; Imbriaco, M. Quality control and whole-gland, zonal and lesion annotations for the PROSTATEx challenge public dataset. Eur. J. Radiol. 2021, 138, 109647. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Features | Number of Clinically Significant Cases | Number of Clinically Non-Significant Cases | Total |
|---|---|---|---|---|
| Lesion Dataset | 321 | 67 | 214 | 281 |
| Lesion Features with Anatomical Zone Dataset | 325 | 67 | 214 | 281 |
| Gland Dataset | 321 | 63 | 120 | 183 |
| Single-Lesion Whole Gland Features Dataset | 321 | 33 | 74 | 107 |
| Model | cv_F2 | ts_F2 | cv_Kappa | ts_Kappa | cv_AUC | ts_AUC | cv_AUPRC | ts_AUPRC | F2 | Kappa | AUC | AUPRC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| G_D_SVM-RFE_LR | 0.826 | 0.745 | 0.555 | 0.416 | 0.765 | 0.772 | 0.68 | 0.518 | 0.081 | 0.139 | −0.007 | 0.162 |
| G_D_SVM-RFE_RF | 0.859 | 0.618 | 0.657 | 0.333 | 0.857 | 0.843 | 0.787 | 0.734 | 0.241 | 0.324 | 0.014 | 0.053 |
| G_D_SVM-RFE_XGB | 0.868 | 0.729 | 0.655 | 0.354 | 0.859 | 0.753 | 0.792 | 0.545 | 0.139 | 0.301 | 0.106 | 0.247 |
| G_S_SVM-RFE_LR | 0.831 | 0.652 | 0.528 | 0.32 | 0.798 | 0.766 | 0.742 | 0.655 | 0.179 | 0.208 | 0.032 | 0.087 |
| G_S_SVM-RFE_DT | 0.868 | 0.611 | 0.584 | 0.301 | 0.806 | 0.746 | 0.545 | 0.449 | 0.257 | 0.283 | 0.06 | 0.096 |
| G_S_SVM-RFE_RF | 0.862 | 0.737 | 0.629 | 0.385 | 0.873 | 0.788 | 0.841 | 0.576 | 0.125 | 0.244 | 0.085 | 0.265 |
| G_S_SVM-RFE_XGB | 0.849 | 0.684 | 0.551 | 0.308 | 0.847 | 0.728 | 0.805 | 0.504 | 0.165 | 0.243 | 0.119 | 0.301 |
| G_D_mRMR_LR_EN | 0.812 | 0.638 | 0.557 | 0.26 | 0.789 | 0.755 | 0.724 | 0.53 | 0.174 | 0.297 | 0.034 | 0.194 |
| G_D_mRMR_DT | 0.836 | 0.632 | 0.556 | 0.231 | 0.767 | 0.634 | 0.636 | 0.404 | 0.204 | 0.325 | 0.133 | 0.232 |
| G_D_mRMR_RF | 0.827 | 0.488 | 0.636 | 0.385 | 0.789 | 0.757 | 0.683 | 0.737 | 0.339 | 0.251 | 0.032 | −0.054 |
| G_D_mRMR_XGB | 0.84 | 0.575 | 0.576 | 0.314 | 0.808 | 0.719 | 0.718 | 0.485 | 0.265 | 0.262 | 0.089 | 0.233 |
| G_S_mRMR_DT | 0.884 | 0.722 | 0.554 | 0.325 | 0.778 | 0.691 | 0.405 | 0.271 | 0.162 | 0.229 | 0.087 | 0.134 |
| G_S_mRMR_RF | 0.853 | 0.798 | 0.618 | 0.494 | 0.841 | 0.847 | 0.8 | 0.642 | 0.055 | 0.124 | −0.006 | 0.158 |
| G_S_mRMR_XGB | 0.844 | 0.729 | 0.607 | 0.354 | 0.814 | 0.783 | 0.766 | 0.576 | 0.115 | 0.253 | 0.031 | 0.19 |
| G_D_Lasso_DT | 0.815 | 0.568 | 0.574 | 0.282 | 0.808 | 0.71 | 0.696 | 0.346 | 0.247 | 0.292 | 0.098 | 0.35 |
| G_D_Lasso_RF | 0.855 | 0.722 | 0.638 | 0.466 | 0.826 | 0.824 | 0.754 | 0.659 | 0.133 | 0.172 | 0.002 | 0.095 |
| G_D_Lasso_XGB | 0.84 | 0.652 | 0.576 | 0.32 | 0.856 | 0.7 | 0.798 | 0.447 | 0.188 | 0.256 | 0.156 | 0.351 |
| L_S_Lasso_XGB | 0.826 | 0.652 | 0.56 | 0.363 | 0.855 | 0.755 | 0.844 | 0.54 | 0.174 | 0.197 | 0.1 | 0.304 |
| Lp_D_SVM-RFE_LR_EN | 0.806 | 0.368 | 0.55 | 0.001 | 0.786 | 0.581 | 0.706 | 0.812 | 0.438 | 0.549 | 0.205 | −0.106 |
| Lp_S_Boruta_XGB | 0.833 | 0.64 | 0.591 | 0.091 | 0.874 | 0.646 | 0.861 | 0.874 | 0.193 | 0.5 | 0.228 | −0.013 |
| Lp_S_mRMR_NB | 0.873 | 0.389 | 0.554 | 0.075 | 0.836 | 0.55 | 0.793 | 0.713 | 0.484 | 0.479 | 0.286 | 0.08 |
| Lp_S_mRMR_LR | 0.872 | 0.404 | 0.528 | 0.006 | 0.853 | 0.53 | 0.804 | 0.783 | 0.468 | 0.522 | 0.323 | 0.021 |
| Lp_S_mRMR_LR_EN | 0.882 | 0.49 | 0.566 | 0.078 | 0.849 | 0.667 | 0.783 | 0.862 | 0.392 | 0.488 | 0.182 | −0.079 |
| Lp_S_mRMR_RF | 0.879 | 0.44 | 0.617 | 0.124 | 0.881 | 0.58 | 0.868 | 0.805 | 0.439 | 0.493 | 0.301 | 0.063 |
| Lp_S_mRMR_XGB | 0.85 | 0.427 | 0.534 | 0.227 | 0.864 | 0.697 | 0.845 | 0.871 | 0.423 | 0.307 | 0.167 | −0.026 |
| Lp_S_Lasso_XGB | 0.852 | 0.305 | 0.667 | 0.073 | 0.904 | 0.634 | 0.907 | 0.846 | 0.547 | 0.594 | 0.27 | 0.061 |
| Models | F2 | Kappa | AUC | AUPRC | (CV - TS) | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CV | TS | CV | TS | CV | TS | CV | TS | |||||||||||||
| mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | mean | std | F2 | Kappa | AUC | AUPRC | |
| G_D_SVM-RFE_LR | 0.6447 | 0.0582 | 0.6060 | 0.0910 | 0.3103 | 0.1095 | 0.2754 | 0.1177 | 0.7041 | 0.0607 | 0.7130 | 0.0646 | 0.6308 | 0.0465 | 0.6281 | 0.1745 | 0.0388 | 0.0349 | −0.0089 | 0.0027 |
| G_D_SVM-RFE_RF | 0.6734 | 0.0651 | 0.6207 | 0.0957 | 0.3278 | 0.1174 | 0.2678 | 0.1199 | 0.7195 | 0.0782 | 0.7076 | 0.0688 | 0.6502 | 0.0584 | 0.6286 | 0.1638 | 0.0527 | 0.0601 | 0.0119 | 0.0215 |
| G_D_SVM-RFE_XGB | 0.6538 | 0.0832 | 0.6309 | 0.1085 | 0.3168 | 0.1286 | 0.3033 | 0.1080 | 0.7074 | 0.0722 | 0.7072 | 0.0640 | 0.6371 | 0.0565 | 0.6159 | 0.1838 | 0.0230 | 0.0135 | 0.0002 | 0.0212 |
| G_S_SVM-RFE_LR | 0.8011 | 0.0302 | 0.6944 | 0.0822 | 0.4376 | 0.0683 | 0.2762 | 0.1193 | 0.7721 | 0.0324 | 0.7102 | 0.0690 | 0.7156 | 0.0410 | 0.6245 | 0.1752 | 0.1067 | 0.1614 | 0.0619 | 0.0911 |
| G_S_SVM-RFE_DT | 0.7939 | 0.0312 | 0.6484 | 0.0990 | 0.3893 | 0.0827 | 0.1906 | 0.1280 | 0.7357 | 0.0487 | 0.6336 | 0.0824 | 0.5059 | 0.0912 | 0.4347 | 0.1954 | 0.1454 | 0.1987 | 0.1021 | 0.0712 |
| G_S_SVM-RFE_RF | 0.7967 | 0.0278 | 0.6318 | 0.0963 | 0.4422 | 0.0671 | 0.2311 | 0.1195 | 0.8122 | 0.0278 | 0.6838 | 0.0747 | 0.7662 | 0.0272 | 0.5959 | 0.1722 | 0.1649 | 0.2110 | 0.1284 | 0.1703 |
| G_S_SVM-RFE_XGB | 0.7509 | 0.0462 | 0.5627 | 0.1085 | 0.4599 | 0.0752 | 0.2364 | 0.1450 | 0.7986 | 0.0318 | 0.6718 | 0.0733 | 0.7469 | 0.0366 | 0.5786 | 0.1704 | 0.1881 | 0.2235 | 0.1268 | 0.1683 |
| G_D_mRMR_LR_EN | 0.6445 | 0.0546 | 0.6109 | 0.0731 | 0.3174 | 0.1084 | 0.2740 | 0.1015 | 0.7135 | 0.0699 | 0.7097 | 0.0624 | 0.6415 | 0.0585 | 0.6274 | 0.1777 | 0.0336 | 0.0434 | 0.0039 | 0.0141 |
| G_D_mRMR_DT | 0.6043 | 0.1085 | 0.6168 | 0.1652 | 0.2307 | 0.1250 | 0.2207 | 0.0960 | 0.6583 | 0.0834 | 0.6567 | 0.0606 | 0.5721 | 0.0812 | 0.5641 | 0.1742 | −0.0125 | 0.0100 | 0.0016 | 0.0080 |
| G_D_mRMR_RF | 0.6985 | 0.0635 | 0.6594 | 0.0778 | 0.3715 | 0.1103 | 0.3279 | 0.1120 | 0.7330 | 0.0621 | 0.7360 | 0.0648 | 0.6578 | 0.0527 | 0.6570 | 0.1593 | 0.0390 | 0.0436 | −0.0030 | 0.0007 |
| G_D_mRMR_XGB | 0.6381 | 0.0607 | 0.6188 | 0.1029 | 0.3091 | 0.1076 | 0.2907 | 0.1295 | 0.7058 | 0.0646 | 0.6976 | 0.0862 | 0.6343 | 0.0538 | 0.6175 | 0.1671 | 0.0193 | 0.0184 | 0.0082 | 0.0169 |
| G_S_mRMR_DT | 0.8257 | 0.0309 | 0.6744 | 0.0757 | 0.4070 | 0.0907 | 0.2260 | 0.0954 | 0.7191 | 0.0434 | 0.6411 | 0.0585 | 0.4480 | 0.0857 | 0.3913 | 0.1666 | 0.1513 | 0.1809 | 0.0780 | 0.0567 |
| G_S_mRMR_RF | 0.8204 | 0.0296 | 0.6669 | 0.0782 | 0.4850 | 0.0617 | 0.2757 | 0.1116 | 0.8318 | 0.0298 | 0.7283 | 0.0595 | 0.7810 | 0.0305 | 0.6645 | 0.1473 | 0.1535 | 0.2093 | 0.1035 | 0.1165 |
| G_S_mRMR_XGB | 0.7490 | 0.0487 | 0.5749 | 0.0967 | 0.4706 | 0.0825 | 0.2607 | 0.1193 | 0.8041 | 0.0357 | 0.6764 | 0.0699 | 0.7544 | 0.0377 | 0.5802 | 0.1835 | 0.1741 | 0.2099 | 0.1276 | 0.1741 |
| G_D_Lasso_DT | 0.6755 | 0.0738 | 0.6785 | 0.0972 | 0.2788 | 0.1207 | 0.2810 | 0.1136 | 0.6756 | 0.0688 | 0.6784 | 0.0638 | 0.5255 | 0.0748 | 0.4893 | 0.1560 | −0.0030 | −0.0021 | −0.0028 | 0.0362 |
| G_D_Lasso_RF | 0.7027 | 0.0673 | 0.6779 | 0.0884 | 0.3570 | 0.1144 | 0.3266 | 0.1153 | 0.7213 | 0.0725 | 0.7376 | 0.0728 | 0.6489 | 0.0617 | 0.6530 | 0.1565 | 0.0249 | 0.0304 | −0.0163 | −0.0041 |
| G_D_Lasso_XGB | 0.6590 | 0.0681 | 0.6317 | 0.0985 | 0.3173 | 0.0988 | 0.2875 | 0.1177 | 0.7117 | 0.0703 | 0.7060 | 0.0712 | 0.6386 | 0.0598 | 0.6218 | 0.1838 | 0.0273 | 0.0298 | 0.0058 | 0.0168 |
| L_S_Lasso_XGB | 0.7987 | 0.0242 | 0.4141 | 0.0960 | 0.5295 | 0.0457 | 0.1490 | 0.0990 | 0.8500 | 0.0190 | 0.6176 | 0.0610 | 0.8208 | 0.0229 | 0.4277 | 0.1933 | 0.3846 | 0.3805 | 0.2324 | 0.3931 |
| Lp_D_SVM-RFE_LR_EN | 0.6065 | 0.0759 | 0.5396 | 0.1112 | 0.2910 | 0.0984 | 0.2417 | 0.1041 | 0.6913 | 0.0562 | 0.7028 | 0.0715 | 0.6280 | 0.0542 | 0.4944 | 0.1902 | 0.0668 | 0.0493 | −0.0115 | 0.1336 |
| Lp_S_Boruta_XGB | 0.7907 | 0.0277 | 0.2506 | 0.2442 | 0.5480 | 0.0520 | 0.0046 | 0.1402 | 0.8617 | 0.0205 | 0.4881 | 0.1042 | 0.8365 | 0.0230 | 0.2717 | 0.1541 | 0.5401 | 0.5434 | 0.3736 | 0.5648 |
| Lp_S_mRMR_NB | 0.7704 | 0.0453 | 0.5169 | 0.1168 | 0.4336 | 0.0780 | 0.2827 | 0.1331 | 0.7850 | 0.0309 | 0.7045 | 0.0638 | 0.7399 | 0.0313 | 0.4364 | 0.2120 | 0.2534 | 0.1510 | 0.0805 | 0.3035 |
| Lp_S_mRMR_LR | 0.8427 | 0.0178 | 0.5514 | 0.1006 | 0.3930 | 0.0662 | 0.2398 | 0.1102 | 0.7892 | 0.0264 | 0.6803 | 0.0676 | 0.7446 | 0.0374 | 0.4711 | 0.1940 | 0.2913 | 0.1532 | 0.1089 | 0.2735 |
| Lp_S_mRMR_LR_EN | 0.8397 | 0.0194 | 0.5388 | 0.1064 | 0.3781 | 0.0794 | 0.2328 | 0.1240 | 0.7814 | 0.0300 | 0.6840 | 0.0708 | 0.7360 | 0.0373 | 0.4729 | 0.1942 | 0.3009 | 0.1453 | 0.0973 | 0.2631 |
| Lp_S_mRMR_RF | 0.8454 | 0.0203 | 0.5705 | 0.0807 | 0.4940 | 0.0711 | 0.2463 | 0.0945 | 0.8556 | 0.0216 | 0.6925 | 0.0618 | 0.8274 | 0.0228 | 0.4832 | 0.1935 | 0.2749 | 0.2477 | 0.1631 | 0.3441 |
| Lp_S_mRMR_XGB | 0.8000 | 0.0319 | 0.5152 | 0.1058 | 0.5530 | 0.0528 | 0.1861 | 0.1203 | 0.8560 | 0.0236 | 0.6608 | 0.0732 | 0.8260 | 0.0248 | 0.4621 | 0.1957 | 0.2848 | 0.3669 | 0.1952 | 0.3639 |
| Lp_S_Lasso_XGB | 0.8012 | 0.0234 | 0.5124 | 0.0990 | 0.5588 | 0.0465 | 0.1614 | 0.0955 | 0.8642 | 0.0211 | 0.6505 | 0.0594 | 0.8364 | 0.0228 | 0.4513 | 0.1910 | 0.2888 | 0.3974 | 0.2137 | 0.3851 |
| Models | (CV - TS) | |||
|---|---|---|---|---|
| F2 | Kappa | AUC | AUPRC | |
| G_D_SVM-RFE_LR | 0.0388 | 0.0349 | −0.0089 | 0.0027 |
| G_D_SVM-RFE_RF | 0.0527 | 0.0601 | 0.0119 | 0.0215 |
| G_D_SVM-RFE_XGB | 0.0230 | 0.0135 | 0.0002 | 0.0212 |
| G_S_SVM-RFE_LR | 0.1067 | 0.1614 | 0.0619 | 0.0911 |
| G_S_SVM-RFE_DT | 0.1454 | 0.1987 | 0.1021 | 0.0712 |
| G_S_SVM-RFE_RF | 0.1649 | 0.2110 | 0.1284 | 0.1703 |
| G_S_SVM-RFE_XGB | 0.1881 | 0.2235 | 0.1268 | 0.1683 |
| G_D_mRMR_LR_EN | 0.0336 | 0.0434 | 0.0039 | 0.0141 |
| G_D_mRMR_DT | −0.0125 | 0.0100 | 0.0016 | 0.0080 |
| G_D_mRMR_RF | 0.0390 | 0.0436 | −0.0030 | 0.0007 |
| G_D_mRMR_XGB | 0.0193 | 0.0184 | 0.0082 | 0.0169 |
| G_S_mRMR_DT | 0.1513 | 0.1809 | 0.0780 | 0.0567 |
| G_S_mRMR_RF | 0.1535 | 0.2093 | 0.1035 | 0.1165 |
| G_S_mRMR_XGB | 0.1741 | 0.2099 | 0.1276 | 0.1741 |
| G_D_Lasso_DT | −0.0030 | −0.0021 | −0.0028 | 0.0362 |
| G_D_Lasso_RF | 0.0249 | 0.0304 | −0.0163 | −0.0041 |
| G_D_Lasso_XGB | 0.0273 | 0.0298 | 0.0058 | 0.0168 |
| L_S_Lasso_XGB | 0.3846 | 0.3805 | 0.2324 | 0.3931 |
| Lp_D_SVM-RFE_LR_EN | 0.0668 | 0.0493 | −0.0115 | 0.1336 |
| Lp_S_Boruta_XGB | 0.5401 | 0.5434 | 0.3736 | 0.5648 |
| Lp_S_mRMR_NB | 0.2534 | 0.1510 | 0.0805 | 0.3035 |
| Lp_S_mRMR_LR | 0.2913 | 0.1532 | 0.1089 | 0.2735 |
| Lp_S_mRMR_LR_EN | 0.3009 | 0.1453 | 0.0973 | 0.2631 |
| Lp_S_mRMR_RF | 0.2749 | 0.2477 | 0.1631 | 0.3441 |
| Lp_S_mRMR_XGB | 0.2848 | 0.3669 | 0.1952 | 0.3639 |
| Lp_S_Lasso_XGB | 0.2888 | 0.3974 | 0.2137 | 0.3851 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodrigues, A.; Santinha, J.; Galvão, B.; Matos, C.; Couto, F.M.; Papanikolaou, N. Prediction of Prostate Cancer Disease Aggressiveness Using Bi-Parametric Mri Radiomics. Cancers 2021, 13, 6065. https://doi.org/10.3390/cancers13236065
Rodrigues A, Santinha J, Galvão B, Matos C, Couto FM, Papanikolaou N. Prediction of Prostate Cancer Disease Aggressiveness Using Bi-Parametric Mri Radiomics. Cancers. 2021; 13(23):6065. https://doi.org/10.3390/cancers13236065
Chicago/Turabian StyleRodrigues, Ana, João Santinha, Bernardo Galvão, Celso Matos, Francisco M. Couto, and Nickolas Papanikolaou. 2021. "Prediction of Prostate Cancer Disease Aggressiveness Using Bi-Parametric Mri Radiomics" Cancers 13, no. 23: 6065. https://doi.org/10.3390/cancers13236065