
Blinded Independent Central Review (BICR) in New Therapeutic Lung Cancer Trials


Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Data Inclusion Criteria
2.2. Read Paradigm
2.3. Reader Variability Monitoring
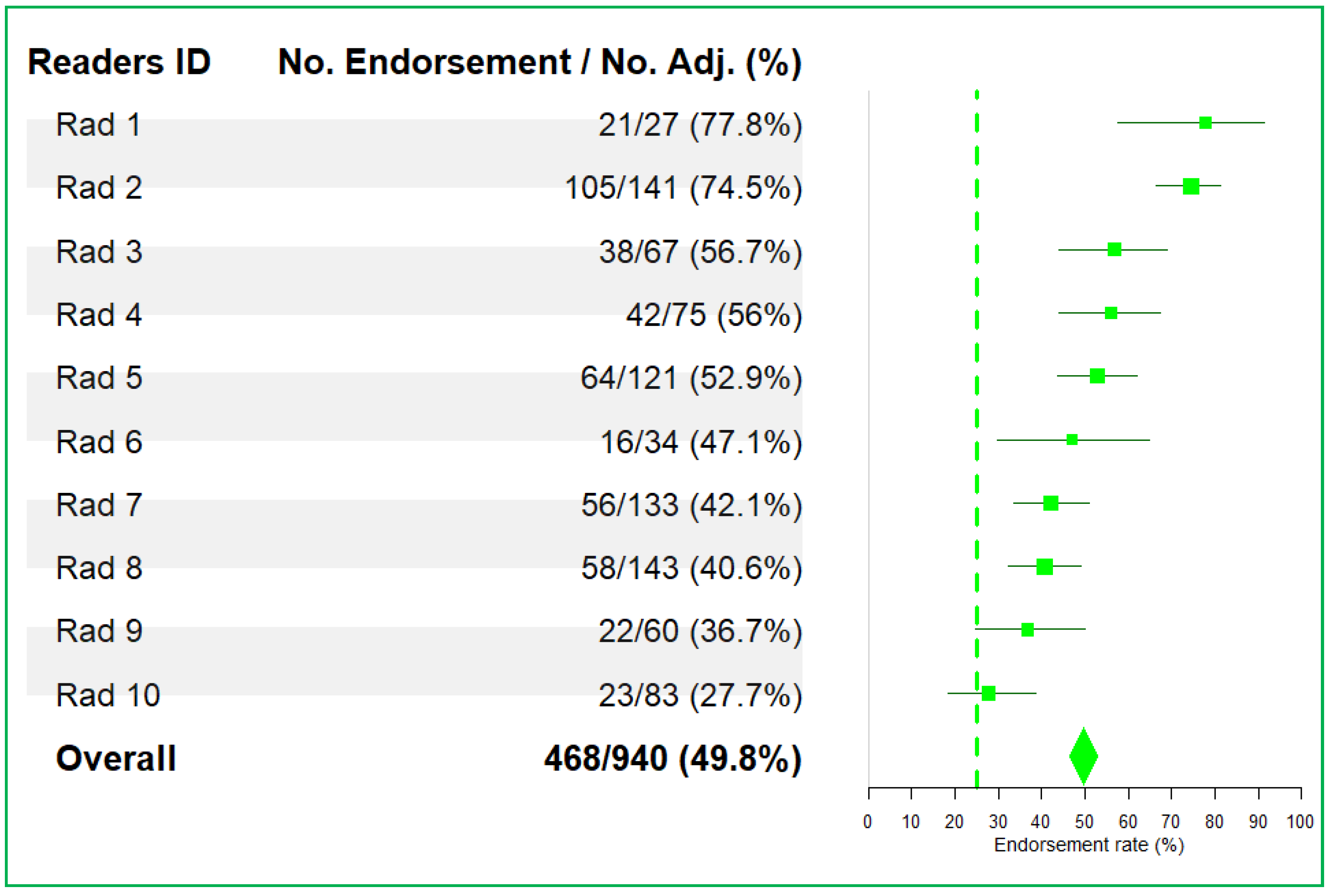
2.4. Analysis Plan and Statistics
- Considering discordances at any time point, independently of patient chronology. This KPI consists of the sum of all discrepant TPs out of the sum of all TPs for a given trial;
- Considering that at least one discordance occurred when reading the patient follow-up. This KPI is the same as the KPI described above but is taken at the patient level;
- Considering only discrepancies in the date of progression (DOP) and the adjudication rate based on this endpoint. This KPI allows meaningful comparison between trials.
- Reader endorsement rate;
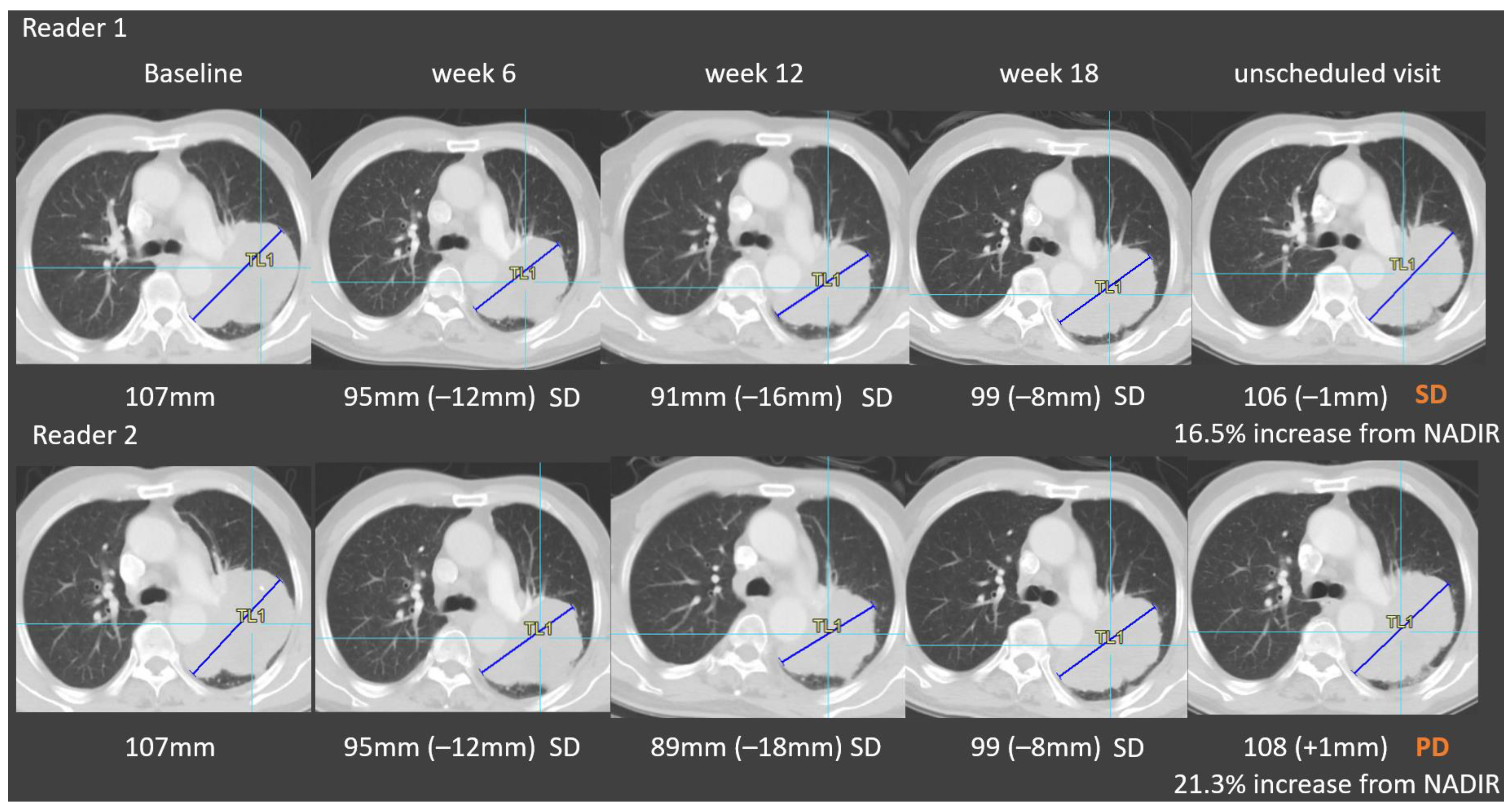
- Proportion of “errors” and “medically justifiable differences”;
3. Results
3.1. Trial Monitoring
3.2. Root Causes of Adjudicated Discrepancies
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviation
| BICR | Blinded independent central review |
| CAD | Computer-aided detection |
| CT | Computed tomography |
| DOP | Date of progression |
| KPI | Key performance indicator |
| LMS | Lesion management solution |
| NSCLC | Non-small cell lung cancer |
| ORR | Overall response rate |
| OS | Overall survival |
| PD | Progressive disease |
| PFS | Progression-free survival |
| RECIST | Response evaluation criteria in solid tumors |
| RTPR | Radiologic time-point response |
| SCLC | Small-cell lung cancer |
| SD | Stable disease |
References
- Toschi, L.; Rossi, S.; Finocchiaro, G.; Santoro, A. Non-small cell lung cancer treatment (r)evolution: Ten years of advances and more to come. Ecancermedicalscience 2017, 11, 787. [Google Scholar] [CrossRef] [PubMed]
- Chan, B.A.; Hughes, B.G.M. Targeted therapy for non-small cell lung cancer: Current standards and the promise of the future. Transl. Lung Cancer Res. 2015, 4, 36–54. [Google Scholar] [CrossRef] [PubMed]
- Yu, S.; Wang, R.; Tang, H.; Wang, L.; Zhang, Z.; Yang, S.; Jiao, S.; Wu, X.; Wang, S.; Wang, M.; et al. Evolution of Lung Cancer in the Context of Immunotherapy. Clin. Med. Insights Oncol. 2020, 14, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Pilz, L.R.; Manegold, C.; Schmid-Bindert, G. Statistical considerations and endpoints for clinical lung cancer studies: Can progression free survival (PFS) substitute overall survival (OS) as a valid endpoint in clinical trials for advanced nonsmall- cell lung cancer? Transl. Lung Cancer Res. 2012, 1, 26–35. [Google Scholar] [CrossRef] [PubMed]
- Eisenhauer, E.A.; Therasse, P.; Bogaerts, J.; Schwartz, L.H.; Sargent, D.; Ford, R.; Dancey, J.; Arbuck, S.; Gwyther, S.; Mooney, M.; et al. New response evaluation criteria in solid tumours: Revised RECIST guideline (version 1.1). Eur. J. Cancer 2009, 45, 228–247. [Google Scholar] [CrossRef] [PubMed]
- Tang, P.A.; Pond, G.R.; Chen, E.X. Influence of an independent review committee on assessment of response rate and progression-free survival in phase III clinical trials. Ann. Oncol. 2010, 21, 19–26. [Google Scholar] [CrossRef] [PubMed]
- Ford, R.; O’Neal, M.; Moskowitz, S.; Fraunberger, J. Adjudication Rates between Readers in Blinded Independent Central Review of Oncology Studies. J. Clin. Trials. 2016, 6, 289. [Google Scholar] [CrossRef] [Green Version]
- Ferrara, R.; Matos, I. Atypical patterns of response and progression in the era of immunotherapy combinations. Future Oncol. 2020, 16, 1707–1713. [Google Scholar] [CrossRef] [PubMed]
- Ferrara, R.; Caramella, C.; Besse, B.; Champiat, S. Pseudoprogression in Non–Small Cell Lung Cancer upon Immunotherapy: Few Drops in the Ocean? J. Thorac. Oncol. 2019, 14, 328–331. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marascuilo, L.A. Extensions of the significance test for one-parameter signal detection hypotheses. Psychometrika 1970, 35, 237–243. [Google Scholar] [CrossRef]
- Beaumont, H.; Evans, T.L.; Klifa, C.; Guermazi, A.; Hong, S.R.; Chadjaa, M.; Monostori, Z. Discrepancies of assessments in a RECIST 1.1 phase II clinical trial–association between adjudication rate and variability in images and tumors selection. Cancer Imaging 2018, 18, 50. [Google Scholar] [CrossRef] [PubMed]
- Carter, B.W.; Halpenny, D.F.; Ginsberg, M.S.; Papadimitrakopoulou, V.A.; de Groot, P.M. Immunotherapy in Non–Small Cell Lung Cancer Treatment. J. Thorac. Imaging 2017, 32, 300–312. [Google Scholar] [CrossRef] [PubMed]
- Schwartz, L.H.; Litière, S.; De Vries, E.; Ford, R.; Gwyther, S.; Mandrekar, S.; Shankar, L.; Bogaerts, J.; Chen, A.; Dancey, J.; et al. RECIST 1.1-Update and clarification: From the RECIST committee. Eur. J. Cancer 2016, 62, 132–137. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Coleman, R.E. Metastatic bone disease: Clinical features, pathophysiology and treatment strategies. Cancer Treat. Rev. 2001, 27, 165–176. [Google Scholar] [CrossRef] [PubMed]
- Yoon, S.H.; Kim, K.W.; Goo, J.M.; Kim, D.-W.; Hahn, S. Observer variability in RECIST-based tumour burden measurements: A meta-analysis. Eur. J. Cancer 2016, 53, 5–15. [Google Scholar] [CrossRef] [PubMed]
- Coche, E. Evaluation of lung tumor response to therapy: Current and emerging techniques. Diagn. Interv. Imaging 2016, 97, 1053–1065. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Fu, Y.; Xie, Q.; Zhu, B.; Wang, J.; Zhang, B. Anti-angiogenic Agents in Combination With Immune Checkpoint Inhibitors: A Promising Strategy for Cancer Treatment. Front. Immunol. 2020, 11, 1956. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trials ID | Indication | Phase | Expected Numbers of Patients | Therapy | Primary Study Endpoints |
|---|---|---|---|---|---|
| Trial 1 | NSCLC | III | 340 | Immune checkpoints + chemotherapy vs. chemotherapy + placebo | PFS |
| Trial 2 | NSCLC | III | 389 | Immune checkpoints + chemotherapy vs. chemotherapy + placebo | PFS |
| Trial 3 | SCLC | II | 100 | RNA-polymerase-II inhibitor | ORR |
| Trial 4 | NSCLC | III | 266 | Tyrosine kinases inhibitor | PFS |
| Trial 5 | NSCLC | II | 366 | Tyrosine kinases inhibitor | ORR |
| Trial 6 | NSCLC | III | 360 | Immune checkpoints + chemotherapy vs. chemotherapy + placebo | PFS |
| Trial ID | No. of TPs Reviewed | TP Level Discordance Rate (%) | No. of Patients | Patient Level (All Types) Discordance Rate (%) | Patient Level (DOP Only) Discordance Rate (%) | Average TP/Patient |
|---|---|---|---|---|---|---|
| Trial 1 | 1570 | 29.9 [26.9; 31.5] | 327 | 59.0 [53.4; 64.4] | 33.0 [27.9; 38.4] | 4.8 |
| Trial 2 | 1386 | 30.0 [27.6; 32.5] | 360 | 56.2 [50.8; 61.3] | 33.9 [29.0; 39.0] | 3.8 |
| Trial 3 | 290 | 15.8 [11.8; 20.6] | 107 | 32.7 [23.9; 42.4] | 25.2 [17.3; 34.5] | 2.7 |
| Trial 4 | 2610 | 34.9 [33.1; 36.8] | 278 | 61.8 [55.9; 67.6] | 39.9 [34.1; 45.9] | 9.4 |
| Trial 5 | 2706 | 43.4 [41.5; 45.3] | 357 | 69.5 [64.4; 74.2] | 30.5 [25.8; 35.6] | 7.6 |
| Trial 6 | 2122 | 30.7 [28.7; 32.7] | 404 | 58.2 [53.2; 63.0] | 31.2 [26.7; 35.9] | 5.2 |
| Total | 10,684 | 34.3 [33.4; 35.2] | 1833 | 59.2 [56.9; 61.4] | 32.9 [30.7; 35.1] | 5.8 |
| Trial ID | Lesion Selection | New Lesion Detection | Non-Target Lesion PD | Lesion Measurement | Missing Data | Image Quality | Sum |
|---|---|---|---|---|---|---|---|
| Trial 1 | 58 (30.8%) | 38 (20.2%) | 10 (5.3%) | 82 (43.6%) | 0 (0%) | 0 (0%) | 188 |
| Trial 2 | 11 (14.8%) | 38 (51.4%) | 8 (10.8%) | 17 (23.0%) | 0 (0%) | 0 (0%) | 74 |
| Trial 3 | 5 (14.7%) | 14 (41.2%) | 2 (5.9%) | 13 (38.2%) | 0 (0%) | 0 (0%) | 34 |
| Trial 4 | 46 (25.6%) | 80 (44.5%) | 12 (6.7%) | 40 (22.3%) | 1 (0.6%) | 1 (0.6%) | 180 |
| Trial 5 | 128 (51%) | 57 (22.7%) | 12 (4.8%) | 54 (21.5%) | 0 (0%) | 0 (0%) | 251 |
| Trial 6 | 34 (20.6%) | 30 (18.2%) | 14 (8.5%) | 86 (52.1%) | 0 (0%) | 1 (0.6%) | 165 |
| Sum (N) | 282 (31.6%) | 257 (28.8%) | 58 (6.6%) | 292 (32.7%) | 1 (0.1%) | 2 (0.2%) | 892 |
| Trial ID | Errors | Justifiable Differences | Sum |
|---|---|---|---|
| Trial 1 | 28 | 160 | 188 |
| Trial 2 | 8 | 66 | 74 |
| Trial 3 | 4 | 30 | 34 |
| Trial 4 | 60 | 120 | 180 |
| Trial 5 | 100 | 151 | 251 |
| Trial 6 | 30 | 135 | 165 |
| Sum (N) | 230 (25.8%) | 662 (74.2%) | 892 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Beaumont, H.; Iannessi, A.; Wang, Y.; Voyton, C.M.; Cillario, J.; Liu, Y. Blinded Independent Central Review (BICR) in New Therapeutic Lung Cancer Trials. Cancers 2021, 13, 4533. https://doi.org/10.3390/cancers13184533
Beaumont H, Iannessi A, Wang Y, Voyton CM, Cillario J, Liu Y. Blinded Independent Central Review (BICR) in New Therapeutic Lung Cancer Trials. Cancers. 2021; 13(18):4533. https://doi.org/10.3390/cancers13184533
Chicago/Turabian StyleBeaumont, Hubert, Antoine Iannessi, Yi Wang, Charles M. Voyton, Jennifer Cillario, and Yan Liu. 2021. "Blinded Independent Central Review (BICR) in New Therapeutic Lung Cancer Trials" Cancers 13, no. 18: 4533. https://doi.org/10.3390/cancers13184533