

Research on Robot Grasping Based on Deep Learning for Real-Life Scenarios


Abstract
:1. Introduction
2. Materials and Methods
2.1. Performance Difference of CNN with Different Structures
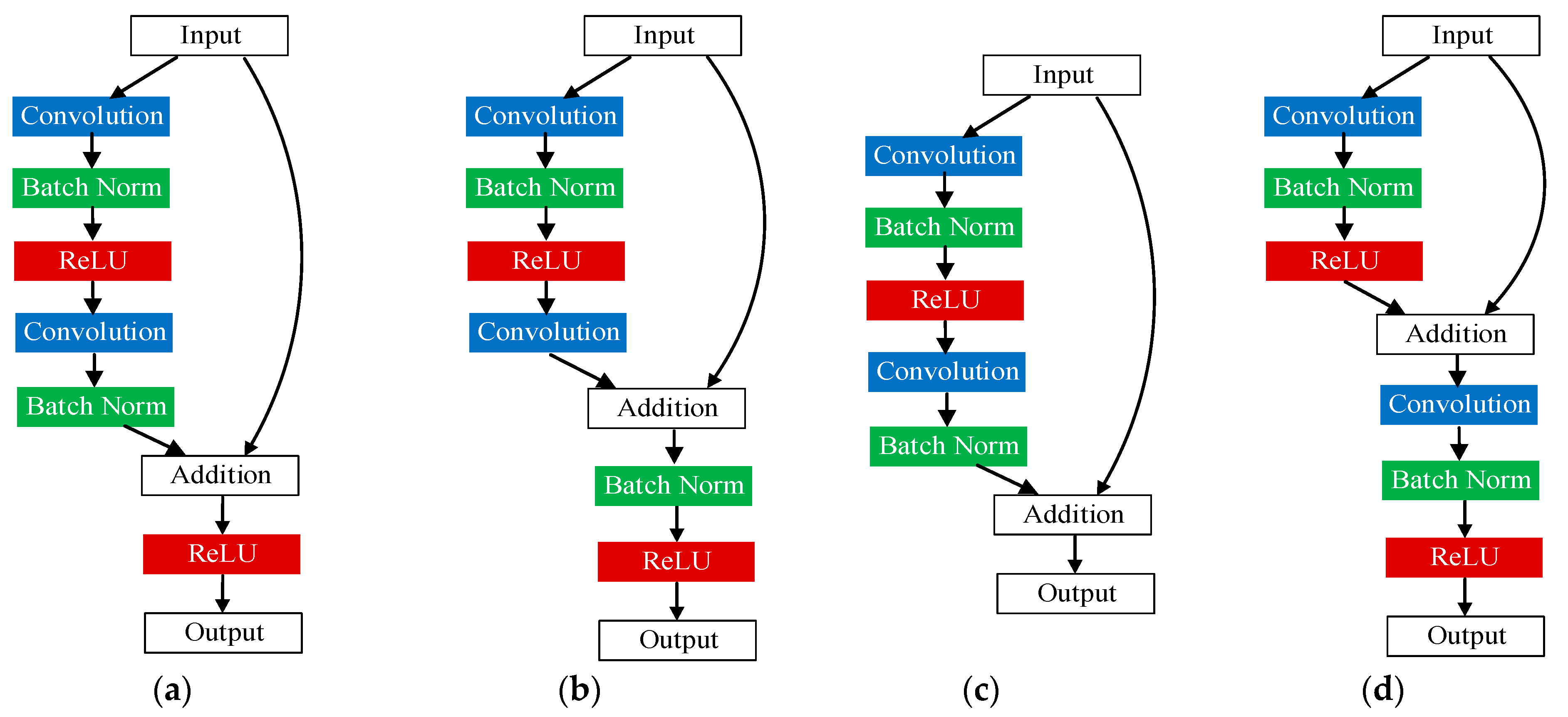
2.2. Theoretical Analysis of ResNet
- (1)
- In the complete training process of the model, the value of will not always be −1, which explains why the gradient in the residual networks does not disappear;
- (2)
- shows that the gradient of layer L in the model can be directly transferred to any shallow layer l without passing through the weight layer, while is transferred through the weight layer.
2.3. Overall Structure of Hybrid Model
3. Results
3.1. Experimental Environment
3.2. Combination of Large Convolution Kernel and Residual Networks
3.3. Combination of Small Convolution Kernel and Residual Networks
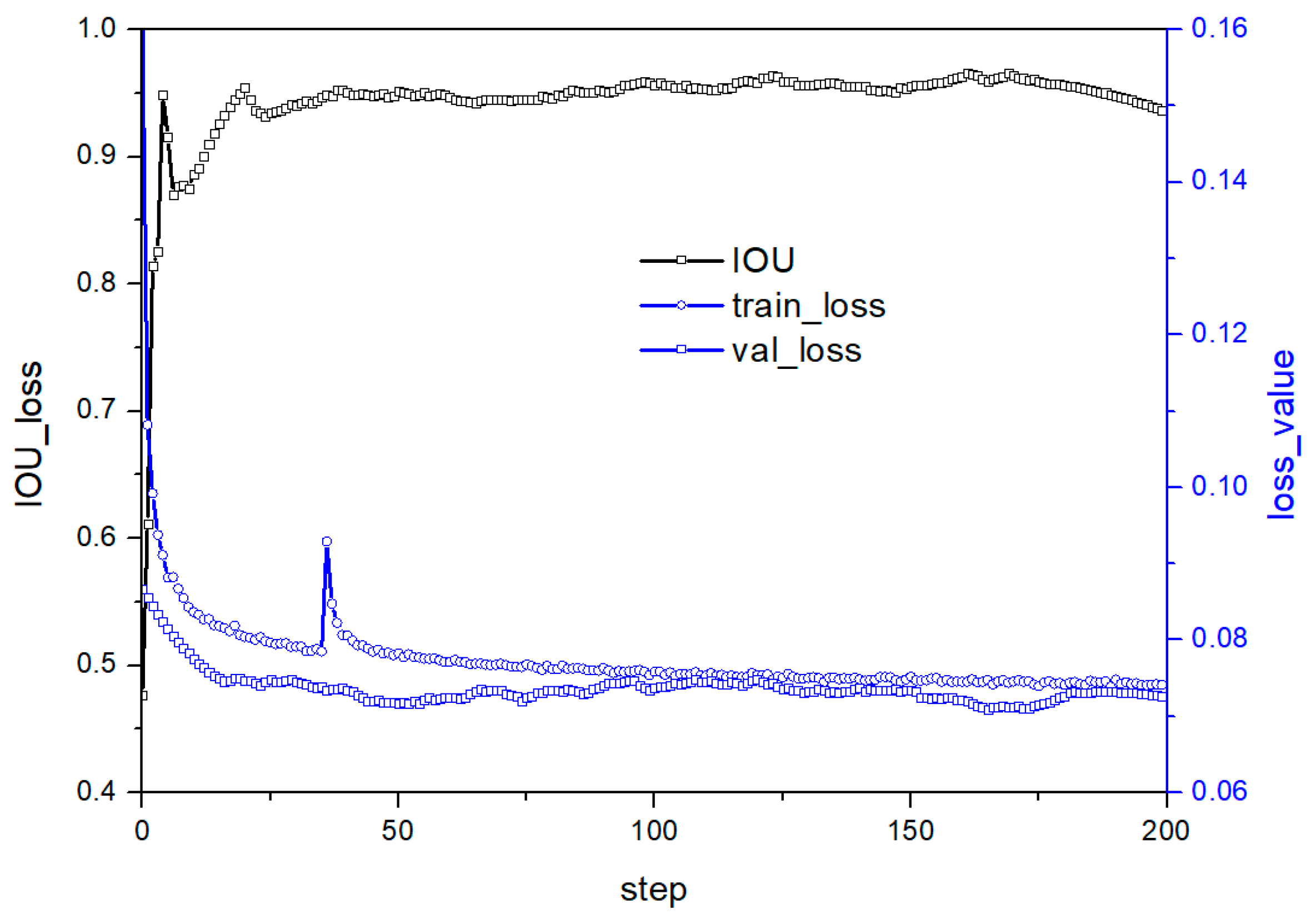
3.4. Further Optimization of Parameters
4. Discussion
4.1. Model Prediction Results
4.2. Application Validation
4.3. Result Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, Y.; Liu, Y.; Ma, Z.; Huang, P. A Novel Generative Convolutional Neural Network for Robot Grasp Detection on Gaussian Guidance. IEEE Trans. Instrum. Meas. 2022, 71, 1–10. [Google Scholar]
- Cheng, H.; Wang, Y.; Meng, M. A Vision-Based Robot Grasping System. IEEE Sens. J. 2022, 22, 9610–9620. [Google Scholar] [CrossRef]
- Xia, J.; Chi, J.; Wu, C.; Zhao, F. Robot Grasping Detection in Object Overlapping Scenes Based on Multi-Stage ROI Extraction. In Proceedings of the 34th Chinese Control and Decision Conference, Hefei, China, 15–17 August 2022; pp. 5066–5071. [Google Scholar]
- Zhang, H.; Liang, Z.; Li, C.; Zhong, H.; Liu, L.; Zhao, C.; Wang, Y.; Wu, Q.J. A Practical Robotic Grasping Method by Using 6-D Pose Estimation With Protective Correction. IEEE Trans. Ind. Electron. 2022, 69, 3876–3886. [Google Scholar] [CrossRef]
- Cai, J.; Cen, J.; Wang, H.; Wang, M.Y. Real-Time Collision-Free Grasp Pose Detection With Geometry-Aware Refinement Using High-Resolution Volume. IEEE Robot. Autom. Lett. 2022, 7, 1888–1895. [Google Scholar] [CrossRef]
- Lin, H.; Cong, M. Inference of 6-DOF Robot Grasps using Point Cloud Data. In Proceedings of the 19th International Conference on Control, Automation and Systems, ICC, Jeju, Republic of Korea, 15–18 October 2019; pp. 944–948. [Google Scholar]
- Yu, S.; Zhai, D.H.; Wu, H.; Yang, H.; Xia, Y. Object recognition and robot grasping technology based on RGB-D data. In Proceedings of the 39th Chinese Control Conference, Shenyang, China, 27–29 July 2020; pp. 3869–3874. [Google Scholar]
- Redmon, J.; Angelova, A. Real-Time Grasp Detection Using Convolutional Neural Networks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation, Washington, DC, USA, 26–30 May 2015; pp. 1316–1322. [Google Scholar]
- Kumra, S.; Kanan, C. Robotic Grasp Detection using Deep Convolutional Neural Networks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 769–776. [Google Scholar]
- Nandi, G.C.; Agarwal, P.; Gupta, P.; Singh, A. Deep Learning Based Intelligent Robot Grasping Strategy. In Proceedings of the 2018 IEEE 14th International Conference on Control and Automation (ICCA), Anchorage, AK, USA, 12–15 June 2018; pp. 1064–1069. [Google Scholar]
- Parque, V.; Miyashita, T. Estimation of Grasp States in Prosthetic Hands using Deep Learning. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020. [Google Scholar]
- Della Santina, C.; Arapi, V.; Averta, G.; Damiani, F.; Fiore, G.; Settimi, A.; Catalano, M.G.; Bacciu, D.; Bicchi, A.; Bianchi, M. Learning From Humans How to Grasp: A Data-Driven Architecture for Autonomous Grasping With Anthropomorphic Soft Hands. IEEE Robot. Autom. Lett. 2019, 4, 1533–1540. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Wang, C.; Wang, H.; Li, P.; Li, Y.; Wu, X. Object Detection for UAV Grasping: Solution and Analysis. In Proceeding of the IEEE International Conference on Information and Automation, Wuyishan, China, 11–13 August 2018; pp. 1078–1083. [Google Scholar]
- Goyal, P.; Shukla, P.; Nandi, G.C. Regression based robotic grasp detection using Deep learning and Autoencoders. In Proceedings of the 2020 IEEE 4th Conference on Information & Communication Technology (CICT), Chennai, India, 3–5 December 2020. [Google Scholar]
- Sebbata, W.; Kenk, M.; Brethe, J. An adaptive robotic grasping with a 2-finger gripper based on deep learning network. In Proceedings of the 2020 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vienna, Austria, 8–11 September 2020. [Google Scholar]
- Lundell, J.; Verdoja, F.; Kyrki, V. DDGC: Generative Deep Dexterous Grasping in Clutter. IEEE Robot. Autom. Lett. 2021, 6, 6899–6906. [Google Scholar] [CrossRef]
- Karunratanakul, K.; Yang, J.; Zhang, Y.; Black, M.J.; Muandet, K.; Tang, S. Grasping Field: Learning Implicit Representations for Human Grasps. In Proceedings of the 2020 International Conference on 3D Vision(3DV), London, UK, 25–28 November 2020; pp. 333–344. [Google Scholar]
- Wu, Y.; Fu, Y.; Wang, S. Real-Time Pixel-Wise Grasp Detection Based on RGB-D Feature Dense Fusion. In Proceedings of the 2021 IEEE International Conference on Mechatronics and Automation, Takamatsu, Japan, 8–11 August 2021; pp. 970–975. [Google Scholar]
- Morrison, D.; Corke, P.; Leitner, J. Learning robust, real-time, reactive robotic grasping. Int. J. Robot. Res. 2020, 39, 183–201. [Google Scholar] [CrossRef]
- Na, Y.; Jo, H.; Song, J. Learning to grasp objects based on ensemble learning combining simulation data and real data. In Proceedings of the 2017 17th International Conference on Control, Automation and Systems (ICCAS 2017), Jeju, Republic of Korea, 18–21 October 2017; pp. 1030–1034. [Google Scholar]
- Trottier, L.; Giguere, P.; Chaib-draa, B. Convolutional Residual Network for Grasp Localization. In Proceedings of the 14th Conference on Computer and Robot Vision, Edmonton, AB, Canada, 16–19 May 2017; pp. 168–175. [Google Scholar]
- Dong, M.; Wei, S.; Yu, X.; Yin, J. MASK-GD segmentation based robotic grasp detection. Comput. Commun. 2021, 178, 124–130. [Google Scholar]
- Li, S.; Bai, Q.; Yang, J.; Yu, L. Research on grasping strategy based on residual network. J. Phys. Conf. Ser. 2022, 1, 012066. [Google Scholar] [CrossRef]
- Yun, J.; Jiang, D.; Sun, Y.; Huang, L.; Tao, B.; Jiang, G.; Kong, J.; Weng, Y.; Li, G.; Fang, Z. Grasping Pose Detection for Loose Stacked Object Based on Convolutional Neural Network with Multiple Self-Powered Sensors Information. IEEE Sens. J. 2022, 1. [Google Scholar] [CrossRef]
- Kumra, S.; Joshi, S.; Sahin, F. Antipodal Robotic Grasping using Generative Residual Convolutional Neural Network. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 9626–9633. [Google Scholar]
- Shan, M.; Zhang, J.; Zhu, H.; Li, C.; Tian, F. Grasp Detection Algorithm Based on CSP-ResNet. In Proceedings of the 2022 International Conference on Image Processing, Computer Vision and Machine Learning, Xi’an, China, 28–30 October 2022; pp. 501–506. [Google Scholar]
- Hu, Z.; Hou, R.; Niu, J.; Yu, X.; Ren, T.; Li, Q. Object Pose Estimation for Robotic Grasping based on Multi-view Keypoint Detection. In Proceedings of the 2021 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking, New York, NY, USA, 30 September 2021–3 October 2021. [Google Scholar]
- Yu, S.; Zhai, D.; Xia, Y. CGNet: Robotic Grasp Detection in Heavily Cluttered Scenes. IEEE/ASME Trans. Mechatron. 2023, 28, 884–894. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, B.; Liu, M.; Xin, M. Robust Object Detection in Aerial Imagery Based on Multi-Scale Detector and Soft Densely Connected. IEEE Access 2020, 8, 92791–92801. [Google Scholar] [CrossRef]
- Wang, Z.; Zou, C.; Cai, W. Small Sample Classification of Hyperspectral Remote Sensing Images Based on Sequential Joint Deeping Learning Model. IEEE Access 2020, 8, 71353–71363. [Google Scholar] [CrossRef]
- Brunner, G.; Wang, Y.; Wattenhofer, R.; Zhao, S. Symbolic Music Genre Transfer with CycleGAN. In Proceedings of the 2018 IEEE 30th International Conference on Tools with Artificial Intelligence, Singapore, 5–7 November 2018. [Google Scholar]
- Wu, L.; Zhang, H.; Chen, R.; Yi, J. Fruit Classification using Convolutional Neural Network via Adjust Parameter and Data Enhancement. In Proceedings of the 2020 12th International Conference on Advanced Computational Intelligence (ICACI), Xi’an, China, 14–16 August 2020; pp. 294–301. [Google Scholar]
- Mohsin, M.; Li, H.; Abdalla, H. Optimization Driven Adam-Cuckoo Search-Based Deep Belief Network Classifier for Data Classification. IEEE Access 2020, 8, 105542–105560. [Google Scholar] [CrossRef]
- Asif, S.; Yi, W.; Ain, Q.U.; Hou, J.; Yi, T.; Si, J. Improving Effectiveness of Different Deep Transfer Learning-Based Models for Detecting Brain Tumors From MR Images. IEEE Access 2022, 10, 34716–34730. [Google Scholar] [CrossRef]
- De Coninck, E.; Verbelen, T.; Van Molle, P.; Simoens, P.; Bart Dhoedt IDLab. Learning to Grasp Arbitrary Household Objects from a Single Demonstration. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 2372–2377. [Google Scholar]
- Ribeiro, E.G.; de Queiroz Mendes, R.; Grassi, V. Real-time deep learning approach to visual servo control and grasp detection for autonomous robotic manipulation. Robot. Auton. Syst. 2021, 139, 103757. [Google Scholar] [CrossRef]
- Lévesque, F.; Sauvet, B.; Cardou, P.; Gosselin, C. A model-based scooping grasp for the autonomous picking of unknown objects with a two-fingered gripper. Robot. Auton. Syst. 2018, 106, 14–25. [Google Scholar] [CrossRef]
- Shang, W.; Song, F.; Zhao, Z.; Gao, H.; Cong, S.; Li, Z. Deep Learning Method for Grasping Novel Objects Using Dexterous Hands. IEEE Trans. Cybern. 2022, 52, 2750–2762. [Google Scholar] [CrossRef]
- Liu, D.; Chen, Y.; Wu, Z. Digital Twin (DT)-CycleGAN: Enabling Zero-Shot Sim-to-Real Transfer of Visual Grasping Models. IEEE Robot. Autom. Lett. 2023, 8, 2421–2428. [Google Scholar] [CrossRef]
- Kasaei, H.; Kasaei, M. MVGrasp: Real-time multi-view 3D object grasping in highly cluttered environments. Robot. Auton. Syst. 2023, 160, 104313. [Google Scholar] [CrossRef]
- Zhao, Z.; Shang, W.; He, H.; Li, Z. Grasp Prediction Evaluation of Multi-Fingered Dexterous Hands Using Deep Learning. Robot. Auton. Syst. 2020, 2, 103550. [Google Scholar] [CrossRef]
- de Coninck, E.; Verbelen, T.; Van Molle, P.; Simoens, P.; Bart Dhoedt IDLab. Learning robots to grasp by demonstration. Robot. Auton. Syst. 2020, 127, 103474. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Author | Model | Model Accuracy (%) | Experimental Accuracy (%) |
|---|---|---|---|---|
| 2017 | Ludovic Trottier [21] | C-ResNet | 89.15 | - |
| 2021 | Mingshuai Dong [22] | MASK-GD | 96.8 | - |
| 2020 | Sulabh Kumra [25] | GRCNN | 95.4 | 93 |
| 2022 | Maomao Shan [26] | CSP-ResNet | 96.8 | 95.6 |
| 2022 | Juntong Yun [24] | ResNet | 90.67 | 87.33 |
| 2021 | Zheyuan Hu [27] | TC-ResNet | 96.5 | - |
| 2023 | Sheng Yu [28] | CGNet | 92.9 | 91.7 |
| 2022 | Li Shaobo [23] | C-ResNet | 94.5 | - |
| A | Conv 9 × 9 | Conv 4 × 4 | Conv 4 × 4 | |||
| BatchNorm | BatchNorm | BatchNorm | ResNet (a) | |||
| ReLU | ReLU | ReLU | ||||
| B | Conv 9 × 9 | Conv 4 × 4 | Conv 4 × 4 | |||
| BatchNorm | BatchNorm | BatchNorm | ResNet (b) | |||
| ReLU | ReLU | ReLU | ||||
| C | Conv 9 × 9 | Conv 4 × 4 | Conv 4 × 4 | |||
| BatchNorm | BatchNorm | BatchNorm | ResNet (c) | |||
| ReLU | ReLU | ReLU | ||||
| D | Conv 9 × 9 | Conv 4 × 4 | Conv 4 × 4 | |||
| BatchNorm | BatchNorm | BatchNorm | ResNet (d) | |||
| ReLU | ReLU | ReLU | ||||
| E | Conv 5 × 5 | Conv 3 × 3 | Conv 5 × 5 | Conv 3 × 3 | Conv 3 × 3 | |
| BatchNorm | BatchNorm | BatchNorm | BatchNorm | BatchNorm | ResNet (a) | |
| ReLU | ReLU | ReLU | ReLU | ReLU | ||
| F | Conv 5 × 5 | Conv 3 × 3 | Conv 5 × 5 | Conv 3 × 3 | Conv 3 × 3 | |
| BatchNorm | BatchNorm | BatchNorm | BatchNorm | BatchNorm | ResNet (b) | |
| ReLU | ReLU | ReLU | ReLU | ReLU | ||
| G | Conv 5 × 5 | Conv 3 × 3 | Conv 5 × 5 | Conv 3 × 3 | Conv 3 × 3 | |
| BatchNorm | BatchNorm | BatchNorm | BatchNorm | BatchNorm | ResNet (c) | |
| ReLU | ReLU | ReLU | ReLU | ReLU | ||
| H | Conv 5 × 5 | Conv 3 × 3 | Conv 5 × 5 | Conv 3 × 3 | Conv 3 × 3 | |
| BatchNorm | BatchNorm | BatchNorm | BatchNorm | BatchNorm | ResNet (d) | |
| ReLU | ReLU | ReLU | ReLU | ReLU |
| Method (%) | 944 + ResNet (a) | 944 + ResNet (c) | 944 + ResNet (d) | 53,333 + ResNet (a) | 53,333 + ResNet (c) | 53,333 + ResNet (d) | Adam—SGD, Epoch: 32–64 | |
|---|---|---|---|---|---|---|---|---|
| Epoch | ||||||||
| 10 | 89.89 | 88.70 | 80.41 | 88.54 | 89.59 | 88.64 | 79.78 | |
| 20 | 89.89 | 90.87 | 86.67 | 91.60 | 93.45 | 95.42 | 83.15 | |
| 30 | 91.01 | 89.11 | 85.34 | 93.24 | 91.96 | 94.06 | 86.64 | |
| 40 | 86.52 | 91.92 | 84.97 | 92.05 | 91.95 | 95.11 | 88.76 | |
| 50 | 94.38 | 92.00 | 85.41 | 92.37 | 91.72 | 95.15 | 91.01 | |
| 60 | 83.15 | 90.60 | 85.09 | 91.84 | 92.39 | 94.67 | 92.13 | |
| 70 | 93.26 | 92.80 | 85.73 | 91.52 | 92.69 | 94.46 | 94.36 | |
| 80 | 94.38 | 91.50 | 87.02 | 92.35 | 92.28 | 94.61 | 95.03 | |
| 90 | 95.51 | 90.52 | 87.09 | 92.37 | 92.26 | 95.18 | 95.45 | |
| 100 | 88.76 | 90.76 | 87.63 | 92.27 | 91.63 | 95.67 | 95.68 | |
| 110 | 92.13 | 91.08 | 87.95 | 91.00 | 92.06 | 95.32 | 95.47 | |
| 120 | 92.13 | 90.69 | 88.20 | 90.48 | 93.02 | 95.81 | 95.5 | |
| 130 | 93.26 | 91.80 | 88.64 | 91.37 | 92.99 | 95.64 | 95.5 | |
| 140 | 89.89 | 93.97 | 89.30 | 92.61 | 91.92 | 95.51 | 96.52 | |
| 150 | 88.76 | 91.67 | 88.12 | 92.81 | 92.34 | 95.55 | 96.63 | |
| 160 | 92.13 | 91.57 | 87.14 | 92.59 | 92.55 | 96.28 | 97.43 | |
| 170 | 88.76 | 92.29 | 87.12 | 92.07 | 93.36 | 96.44 | 97.75 | |
| 180 | 95.51 | 91.22 | 87.63 | 92.08 | 92.20 | 95.65 | 98 | |
| 190 | 94.38 | 90.39 | 87.36 | 92.45 | 91.41 | 94.82 | 98.32 | |
| 200 | 89.89 | 91.82 | 86.81 | 93.09 | 93.25 | 93.67 | 98.5 | |
| Author | Year | Representation | Algorithm | Accuracy (%) | Speed (ms) | |
|---|---|---|---|---|---|---|
| Model | Experiment | |||||
| Elias De Coninck [35] | 2020 | rectangle | — | 99 | 90 | |
| Mingshuai Dong [22] | 2021 | rectangle | MASK-GD | 96.5 | — | 9.43 |
| Eduardo Godinho Ribeiro [36] | 2021 | rectangle | single-stage regression | 90.9 | 85.7 | 8.51 |
| François Lévesque [37] | 2018 | rectangle | — | — | 84 | — |
| Weiwei Shang [38] | 2020 | rectangle | CNN + MDN | — | 95 | — |
| David Liu [39] | 2023 | rectangle | Digital Twin (DT)-CycleGAN | 90 | 85 | — |
| Hamidreza Kasaei [40] | 2023 | rectangle | DL | 92.6 | 90 | — |
| Ours | 2023 | rectangle | C-ResNet | 98.5 | — | 8.78 |
| Joint | Maximum Speed (Radian/s) | Bending Stiffness | Peak Moment |
|---|---|---|---|
| S0 | 2.0 | 843 Nm/rad | 50 Nm |
| S1 | 2.0 | 843 Nm/rad | 50 Nm |
| E0 | 2.0 | 843 Nm/rad | 50 Nm |
| E1 | 2.0 | 843 Nm/rad | 50 Nm |
| W0 | 4.0 | 250 Nm/rad | 15 Nm |
| W1 | 4.0 | 250 Nm/rad | 15 Nm |
| W2 | 4.0 | 250 Nm/rad | 15 Nm |
| Total weight (kg) | 135.2 | Maximum power (W) | 720 |
| Maximum grasp force (N) | 35 | Maximum load (including gripper) (kg) | 2.2 |
| Position accuracy (mm) | ±5 mm | DOF | 7 × 2 |
| Operate system | ROS | ||
| Method | Common Object Accuracy (%) | Uncommon Object Accuracy (%) | Overall Accuracy (%) | Number of Fingers |
|---|---|---|---|---|
| Model-based object grasp [37] | - | - | 84.1 (673/800) | Rectangle (Two) |
| Mixed density grasp prediction network [41] | - | - | 95 (57/60) | Rectangle (Four) |
| Demo-based object grasp [42] | - | - | 91.34 | Rectangle (Two) |
| Autonomous grasp [36] | - | - | 85.7 | Rectangle (Two) |
| David Liu [39] | - | - | 85 | Rectangle (Two) |
| Hamidreza Kasaei [40] | - | - | 90 | Rectangle (Two) |
| Ours_rectangle_no_sponge | 89 (89/100) | 78 (39/50) | 85.3 | Rectangle (Two) |
| Ours_rectangle_with_sponge | 93 (93/100) | 84 (42/50) | 90 | Rectangle (Two) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, J.; Li, Q.; Bai, Q. Research on Robot Grasping Based on Deep Learning for Real-Life Scenarios. Micromachines 2023, 14, 1392. https://doi.org/10.3390/mi14071392
Hu J, Li Q, Bai Q. Research on Robot Grasping Based on Deep Learning for Real-Life Scenarios. Micromachines. 2023; 14(7):1392. https://doi.org/10.3390/mi14071392
Chicago/Turabian StyleHu, Jie, Qin Li, and Qiang Bai. 2023. "Research on Robot Grasping Based on Deep Learning for Real-Life Scenarios" Micromachines 14, no. 7: 1392. https://doi.org/10.3390/mi14071392