
Single-Shot Multi-Frequency 3D Shape Measurement for Discontinuous Surface Object Based on Deep Learning

Abstract
:1. Introduction
2. Methods
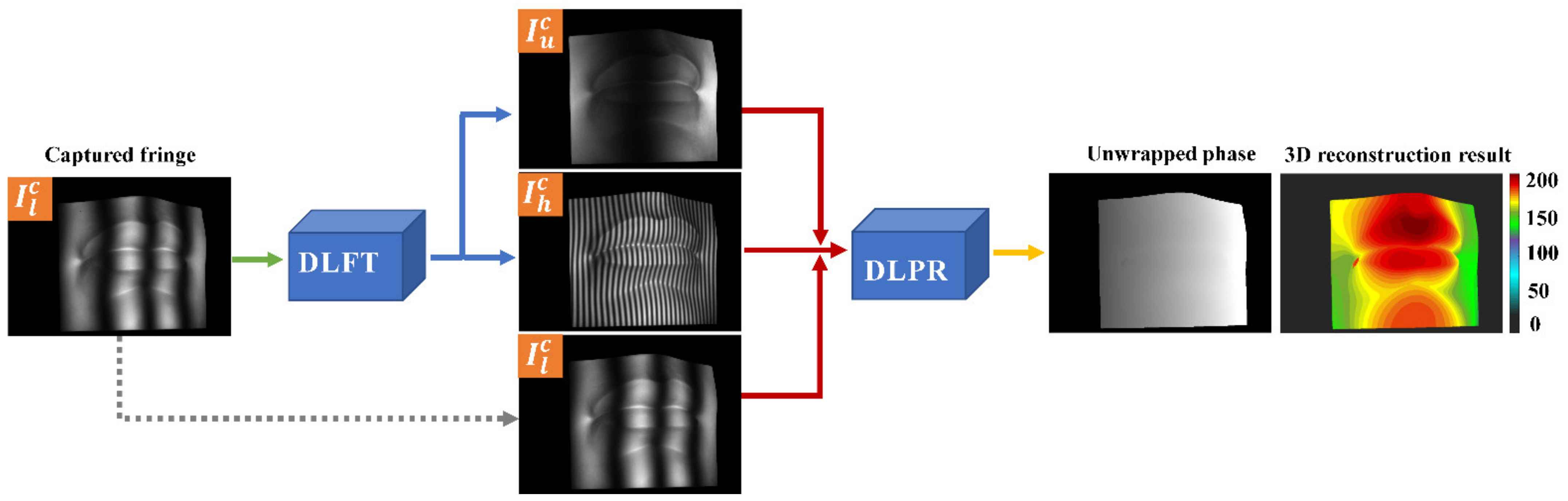
2.1. Principle of Single-Shot Multi-Frequency Absolute Phase Retrieval Method Based on Deep Learning
2.2. Training Data Set
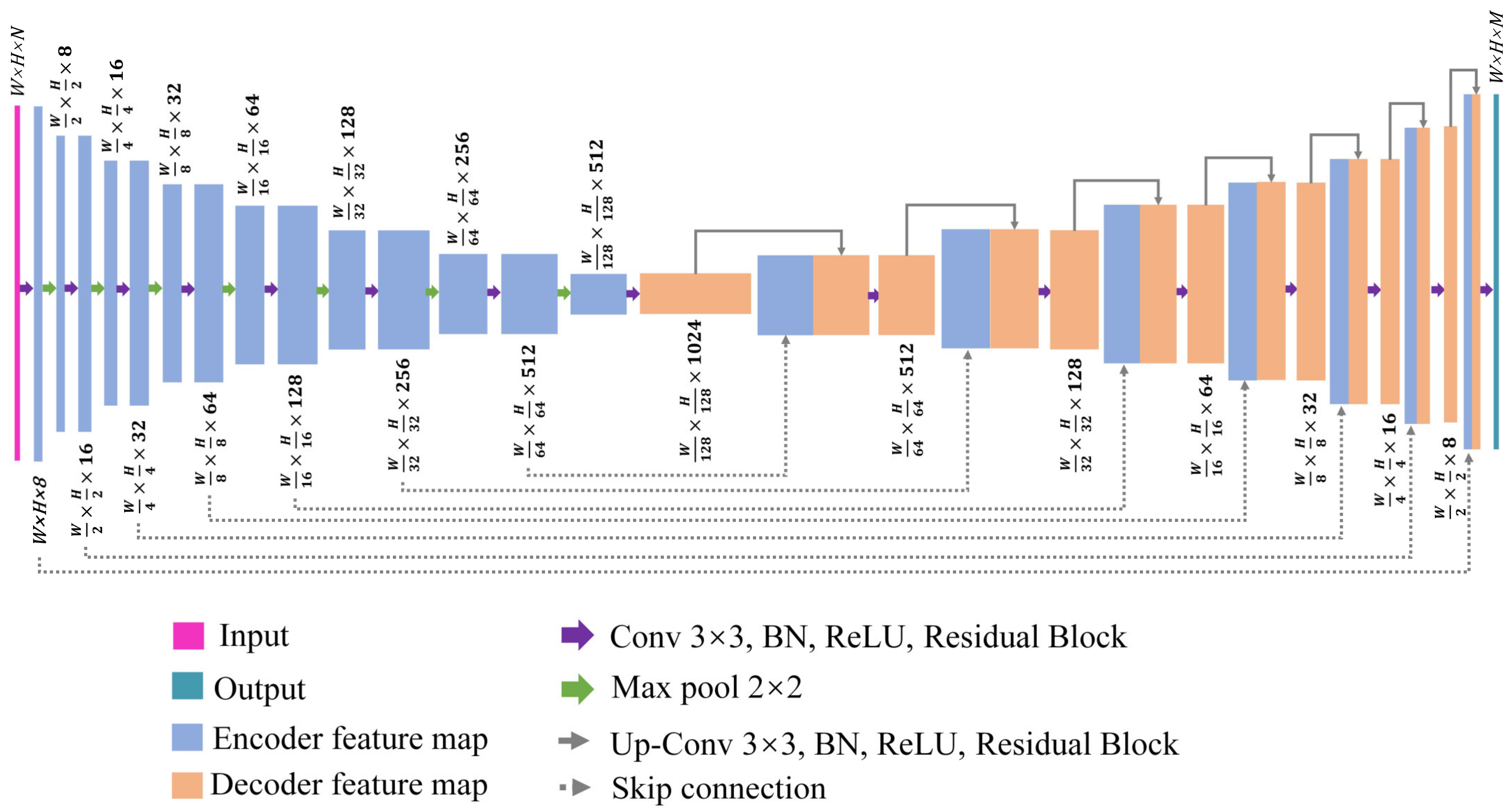
2.3. Network Architecture
2.4. Network Training
3. Experiments and Results
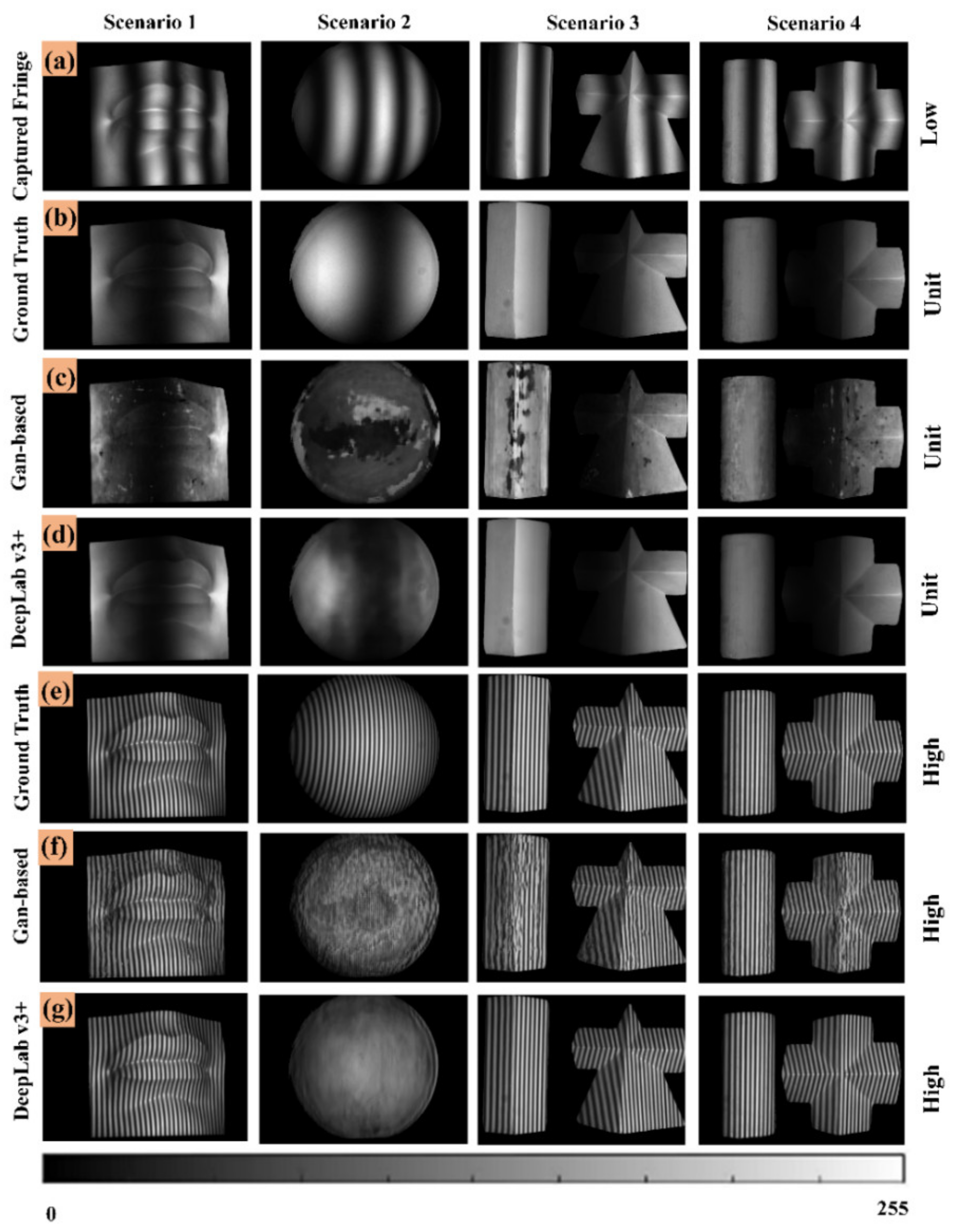
3.1. Generation of Fringe Images by DLFT Network
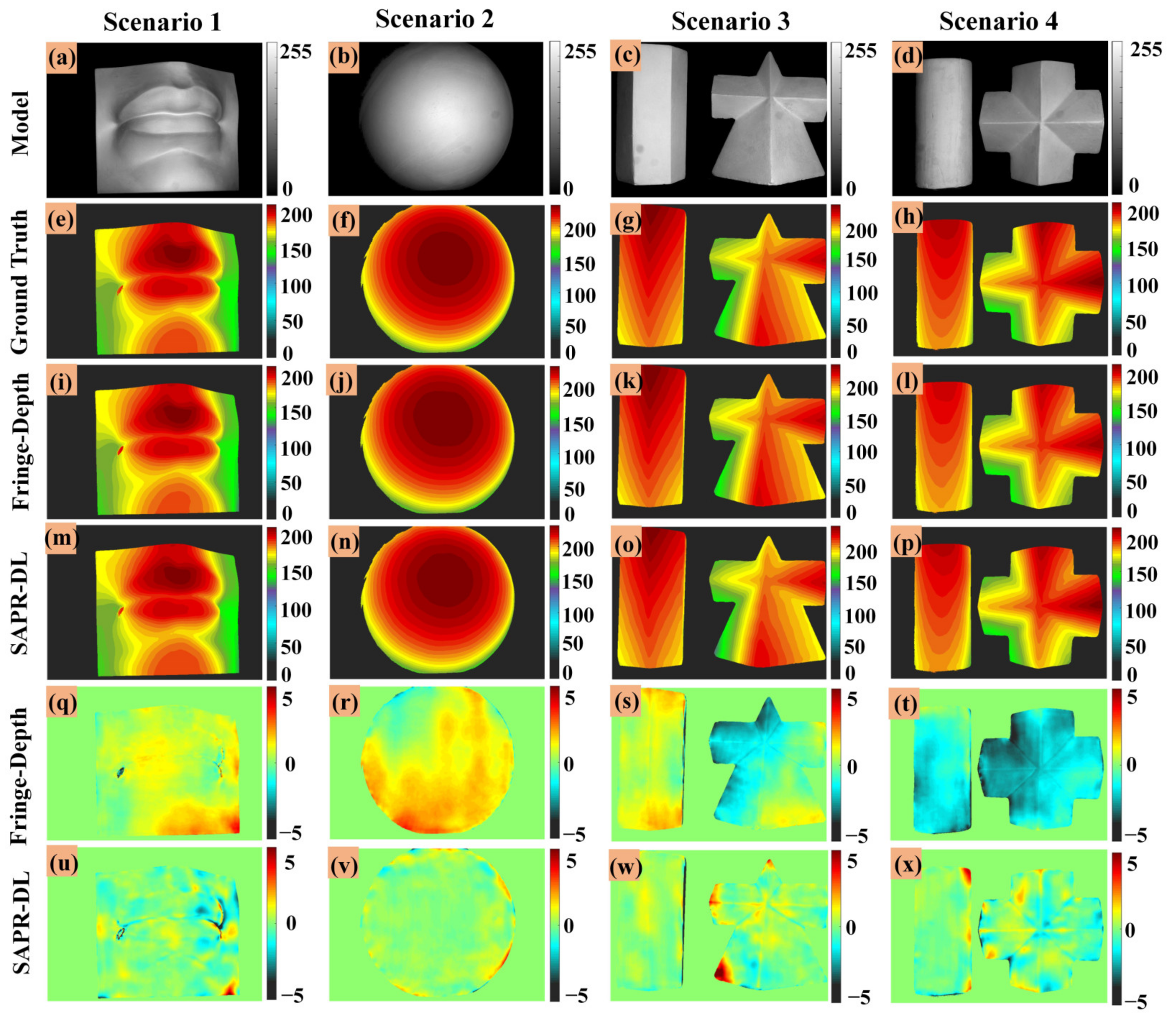
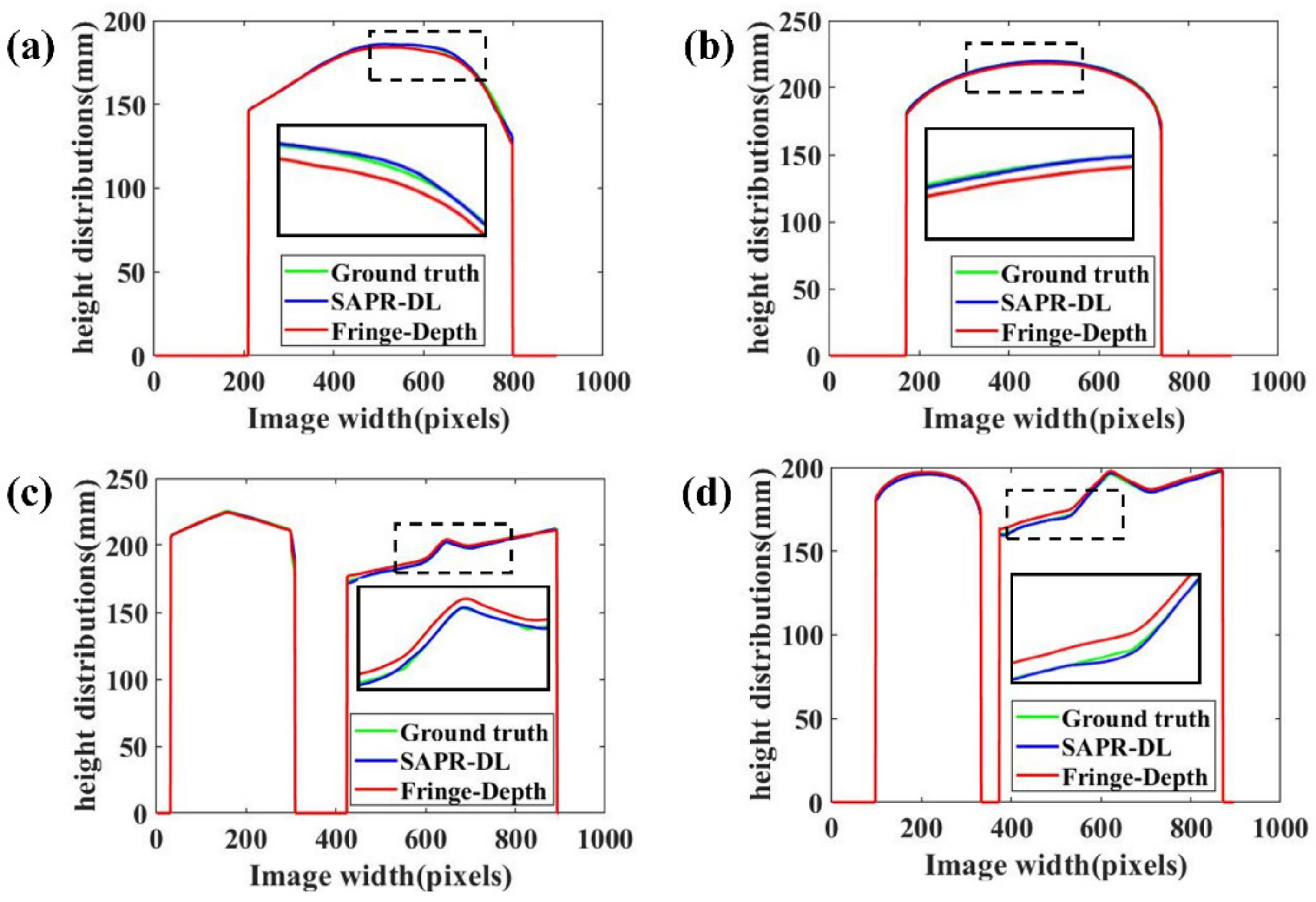
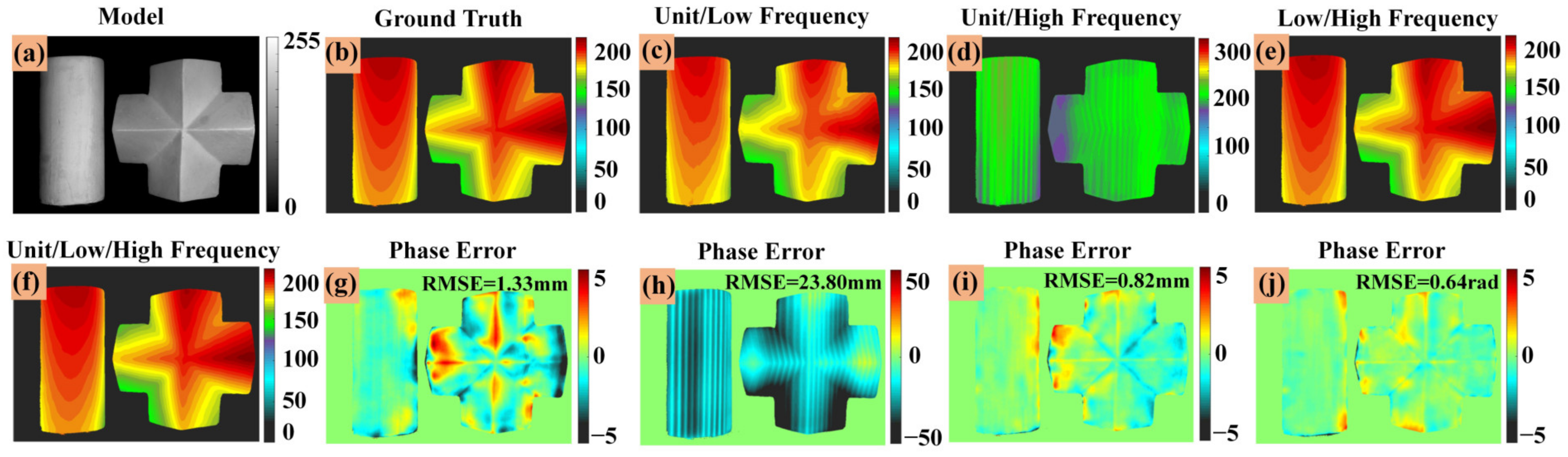
3.2. Extracting Absolute Phase by DLPR Network
4. Discussions
4.1. Acquisition of Training Data
4.2. Visualization of Feature Maps
4.3. The Influence of the Number of Fringe Images on the Measurement Results
4.4. Experimental Results Comparison of Different Network Architectures
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Furukawa, Y.; Hernández, C. Multi-view stereo: A tutorial. Found. Trends® Comput. Graph. Vis. 2015, 9, 1–148. [Google Scholar] [CrossRef] [Green Version]
- Seibert, V.; Wiesner, A.; Buschmann, T.; Meuer, J. Surface-enhanced laser desorption ionization timeof-flight mass spectrometry (seldi tof-ms) and proteinchip® technology in proteomics research. Pathol.-Res. Pract. 2004, 200, 83–94. [Google Scholar] [CrossRef] [PubMed]
- Gorthi, S.S.; Rastogi, P. Fringe projection techniques: Whither we are? Opt. Lasers Eng. 2010, 48, 133–140. [Google Scholar] [CrossRef] [Green Version]
- Woodham, R.J. Photometric method for determining surface orientation from multiple images. Opt. Eng. 1980, 19, 139–144. [Google Scholar] [CrossRef]
- Ju, Y.; Peng, Y.; Jian, M.; Gao, F.; Dong, J. Learning conditional photometric stereo with high-resolution features. Comput. Vis. Media 2022, 8, 105–118. [Google Scholar] [CrossRef]
- Liu, H.; Yan, Y.; Song, K.; Yu, H. Sps-net: Self-attention photometric stereo network. IEEE Trans. Instrum. Meas. 2020, 70, 5006213. [Google Scholar] [CrossRef]
- Takeda, M.; Mutoh, K. Fourier transform profilometry for the automatic measurement of 3-d object shapes. Appl. Opt. 1983, 22, 3977–3982. [Google Scholar] [PubMed]
- Su, X.; Chen, W. Fourier transform profilometry: A review. Opt. Lasers Eng. 2001, 35, 263–284. [Google Scholar] [CrossRef]
- Kemao, Q. Two-dimensional windowed fourier transform for fringe pattern analysis: Principles, applications and implementations. Opt. Lasers Eng. 2007, 45, 304–317. [Google Scholar] [CrossRef]
- Huang, L.; Kemao, Q.; Pan, B.; Asundi, A.K. Comparison of fourier transform, windowed fourier transform, and wavelet transform methods for phase extraction from a single fringe pattern in fringe projection profilometry. Opt. Lasers Eng. 2010, 48, 141–148. [Google Scholar] [CrossRef]
- Guan, C.; Hassebrook, L.; Lau, D. Composite structured light pattern for three-dimensional video. Opt. Express 2003, 11, 406–417. [Google Scholar] [CrossRef]
- García-Isáis, C.; Ochoa, N.A. One shot profilometry using a composite fringe pattern. Opt. Lasers Eng. 2014, 53, 25–30. [Google Scholar] [CrossRef]
- Takeda, M.; Gu, Q.; Kinoshita, M.; Takai, H.; Takahashi, Y. Frequency-multiplex fourier-transform profilometry: A single-shot three-dimensional shape measurement of objects with large height discontinuities and/or surface isolations. Appl. Opt. 1997, 36, 5347–5354. [Google Scholar] [CrossRef]
- Yue, H.-M.; Su, X.-Y.; Liu, Y.-Z. Fourier transform profilometry based on composite structured light pattern. Opt. Laser Technol. 2007, 39, 1170–1175. [Google Scholar] [CrossRef]
- Zhang, Z. Review of single-shot 3d shape measurement by phase calculation-based fringe projection techniques. Opt. Lasers Eng. 2012, 50, 1097–1106. [Google Scholar] [CrossRef]
- Feng, S.; Chen, Q.; Gu, G.; Tao, T.; Zhang, L.; Hu, Y.; Yin, W.; Zuo, C. Fringe pattern analysis using deep learning. Adv. Photonics 2019, 1, 025001. [Google Scholar] [CrossRef] [Green Version]
- Feng, S.; Zuo, C.; Yin, W.; Gu, G.; Chen, Q. Micro deep learning profilometry for high-speed 3d surface imaging. Opt. Lasers Eng. 2019, 121, 416–427. [Google Scholar] [CrossRef]
- Shi, J.; Zhu, X.; Wang, H.; Song, L.; Guo, Q. Label enhanced and patch based deep learning for phase retrieval from single frame fringe pattern in fringe projection 3d measurement. Opt. Express 2019, 27, 28929–28943. [Google Scholar] [CrossRef]
- Zuo, C.; Huang, L.; Zhang, M.; Chen, Q.; Asundi, A. Temporal phase unwrapping algorithms for fringe projection profilometry: A comparative review. Opt. Lasers Eng. 2016, 85, 84–103. [Google Scholar] [CrossRef]
- Li, Y.; Qian, J.; Feng, S.; Chen, Q.; Zuo, C. Composite fringe projection deep learning profilometry for single-shot absolute 3d shape measurement. Opt. Express 2022, 30, 3424–3442. [Google Scholar] [CrossRef]
- Li, Y.; Qian, J.; Feng, S.; Chen, Q.; Zuo, C. Deep-learning-enabled dual-frequency composite fringe projection profilometry for single-shot absolute 3d shape measurement. Opto-Electron. Adv. 2022, 5, 210021. [Google Scholar]
- Qian, J.; Feng, S.; Tao, T.; Hu, Y.; Li, Y.; Chen, Q.; Zuo, C. Deep-learning-enabled geometric constraints and phase unwrapping for single-shot absolute 3d shape measurement. APL Photonics 2020, 5, 046105. [Google Scholar]
- Van der Jeught, S.; Dirckx, J.J. Deep neural networks for single shot structured light profilometry. Opt. Express 2019, 27, 17091–17101. [Google Scholar] [CrossRef]
- Nguyen, H.; Wang, Y.; Wang, Z. Single-shot 3d shape reconstruction using structured light and deep convolutional neural networks. Sensors 2020, 20, 3718. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, S.; Li, Q.; Li, B. Fringe projection profilometry by conducting deep learning from its digital twin. Opt. Express 2020, 28, 36568–36583. [Google Scholar]
- Srinivasan, V.; Liu, H.-C.; Halioua, M. Automated phase-measuring profilometry of 3-d diffuse objects. Appl. Opt. 1984, 23, 3105–3108. [Google Scholar]
- Huntley, J.M.; Saldner, H. Temporal phase-unwrapping algorithm for automated interferogram analysis. Appl. Opt. 1993, 32, 3047–3052. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceeding of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Munich, Germany, 5–9 October 2015, Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; PMLR. pp. 448–456. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; JMLR Workshop and Conference Proceedings. pp. 315–323. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv Prepr. 2014, arXiv:1412.6980. [Google Scholar]
- Xu, M.; Zhang, Y.; Wang, N.; Luo, L.; Peng, J. Single-shot 3d shape reconstruction for complex surface objects with colour texture based on deep learning. J. Mod. Opt. 2022, 69, 941–956. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; JMLR Workshop and Conference Proceedings. pp. 249–256. [Google Scholar]
- Chetlur, S.; Woolley, C.; Vandermersch, P.; Cohen, J.; Tran, J.; Catanzaro, B.; Shelhamer, E. cudnn: Efficient primitives for deep learning. arXiv Prepr. 2014, arXiv:1410.0759. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Feng, S.; Zuo, C.; Zhang, L.; Tao, T.; Hu, Y.; Yin, W.; Qian, J.; Chen, Q. Calibration of fringe projection profilometry: A comparative review. Opt. Lasers Eng. 2021, 143, 106622. [Google Scholar] [CrossRef]
- Zuo, C.; Qian, J.; Feng, S.; Yin, W.; Li, Y.; Fan, P.; Han, J.; Qian, K.; Chen, Q. Deep learning in optical metrology: A review. Light Sci. Appl. 2022, 11, 39. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SSIM | U (input) | L (Input) | H (Input) | |||
|---|---|---|---|---|---|---|
| L | H | U | H | U | L | |
| Scenario 1 | 0.984 | 0.970 | 0.979 | 0.982 | 0.979 | 0.985 |
| Scenario 2 | 0.987 | 0.974 | 0.952 | 0.989 | 0.950 | 0.988 |
| Scenario 3 | 0.976 | 0.932 | 0.972 | 0.973 | 0.971 | 0.975 |
| Scenario 4 | 0.972 | 0.970 | 0.984 | 0.984 | 0.983 | 0.972 |
| RMSE (mm) | Scenario 1 | Scenario 2 | Scenario 3 | Scenario 4 |
|---|---|---|---|---|
| SAPR-DL | 0.77 | 0.43 | 0.88 | 0.78 |
| Fringe-Depth | 1.47 | 1.02 | 0.95 | 1.42 |
| SSIM (L/H) | Scenario 1 | Scenario 2 | Scenario 3 | Scenario 4 |
|---|---|---|---|---|
| Gan-based | 0.923/0.907 | 0.706/0.525 | 0.850/0.782 | 0.911/0.878 |
| DeepLabv3+ | 0.973/0.970 | 0.881/0.551 | 0.962/0.951 | 0.978/0.970 |
| DLFT | 0.979/0.982 | 0.952/0.989 | 0.972/0.973 | 0.984/0.984 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, M.; Zhang, Y.; Wan, Y.; Luo, L.; Peng, J. Single-Shot Multi-Frequency 3D Shape Measurement for Discontinuous Surface Object Based on Deep Learning. Micromachines 2023, 14, 328. https://doi.org/10.3390/mi14020328
Xu M, Zhang Y, Wan Y, Luo L, Peng J. Single-Shot Multi-Frequency 3D Shape Measurement for Discontinuous Surface Object Based on Deep Learning. Micromachines. 2023; 14(2):328. https://doi.org/10.3390/mi14020328
Chicago/Turabian StyleXu, Min, Yu Zhang, Yingying Wan, Lin Luo, and Jianping Peng. 2023. "Single-Shot Multi-Frequency 3D Shape Measurement for Discontinuous Surface Object Based on Deep Learning" Micromachines 14, no. 2: 328. https://doi.org/10.3390/mi14020328