
Automatic Classification Framework of Tongue Feature Based on Convolutional Neural Networks

 ,
,
Abstract
:1. Introduction
2. Related Works
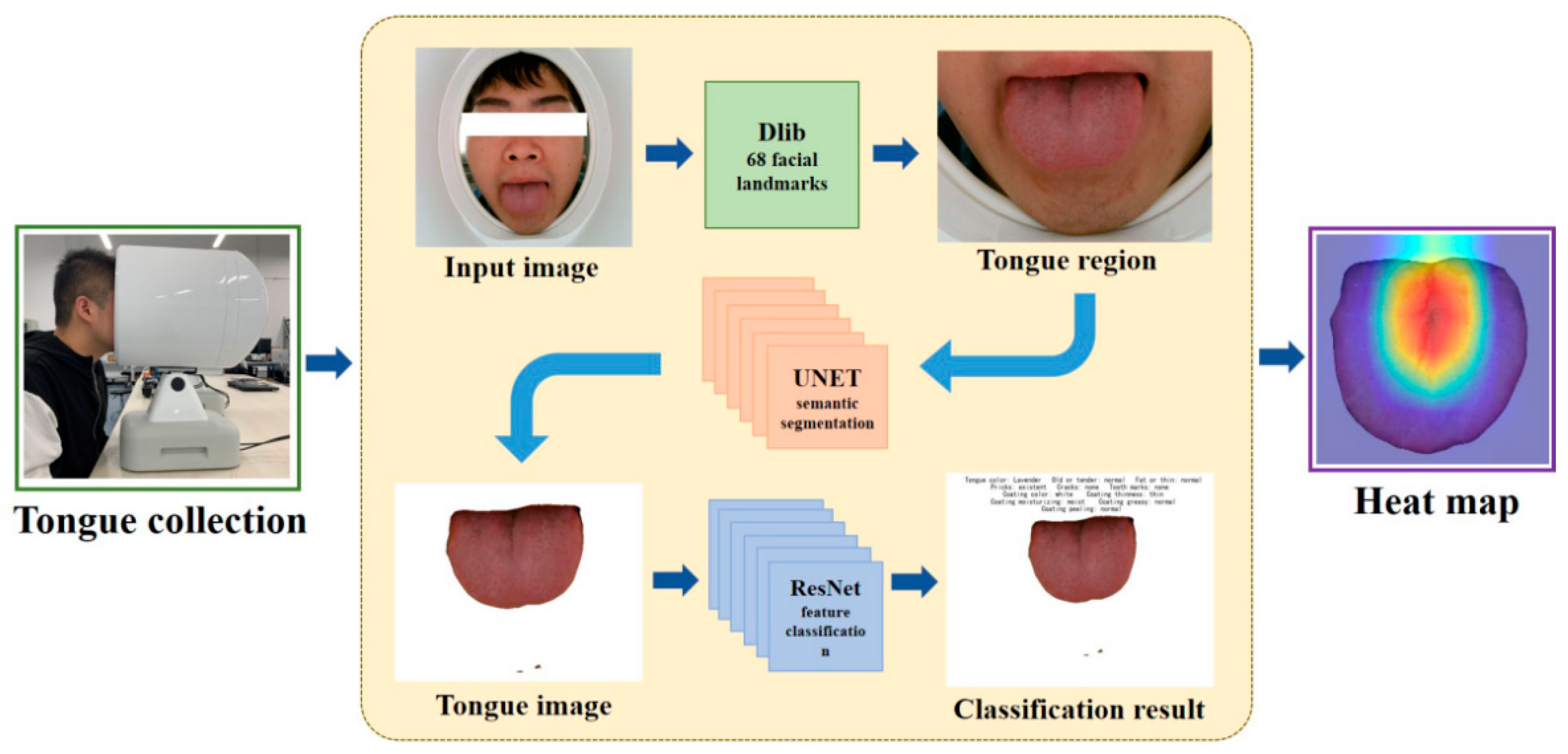
3. Methods
3.1. Data Sets
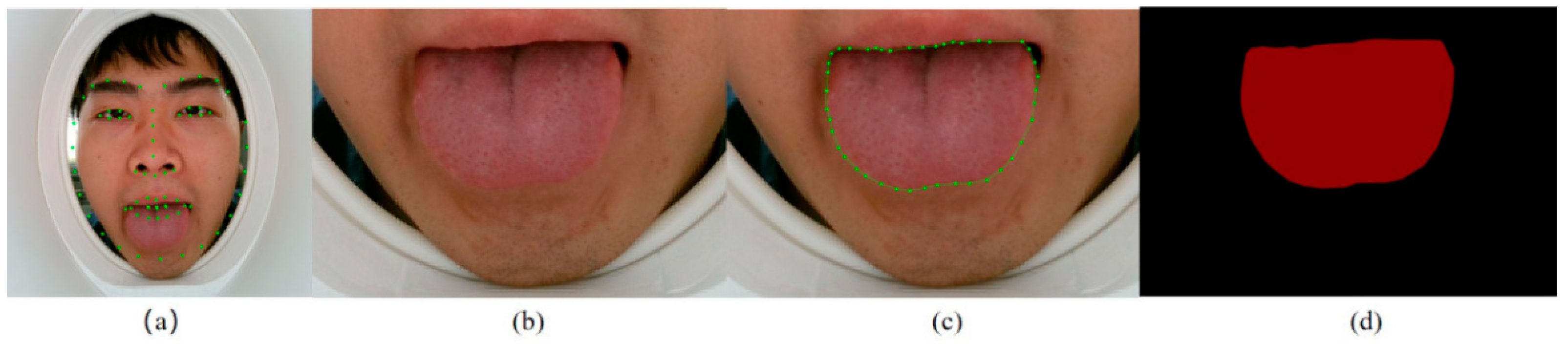
3.2. Extraction of the Tongue Region
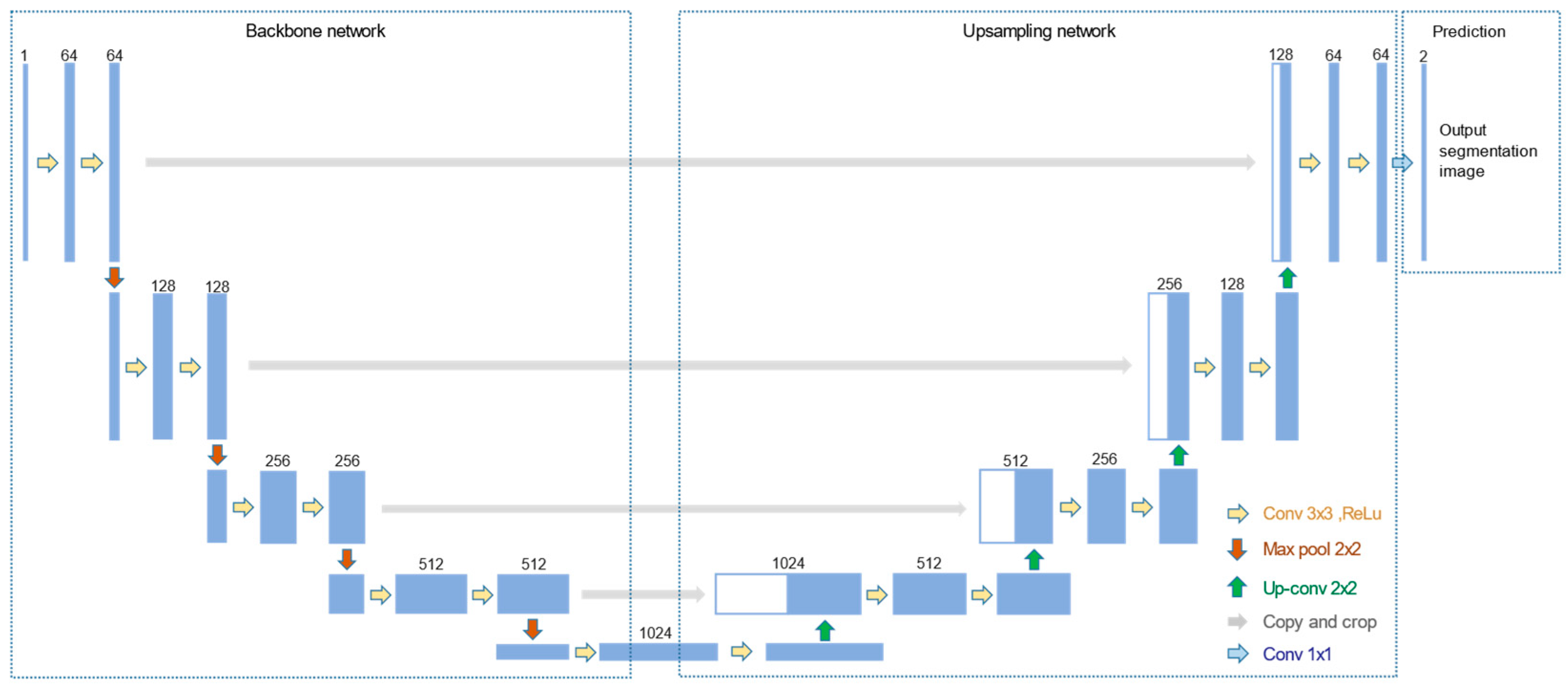
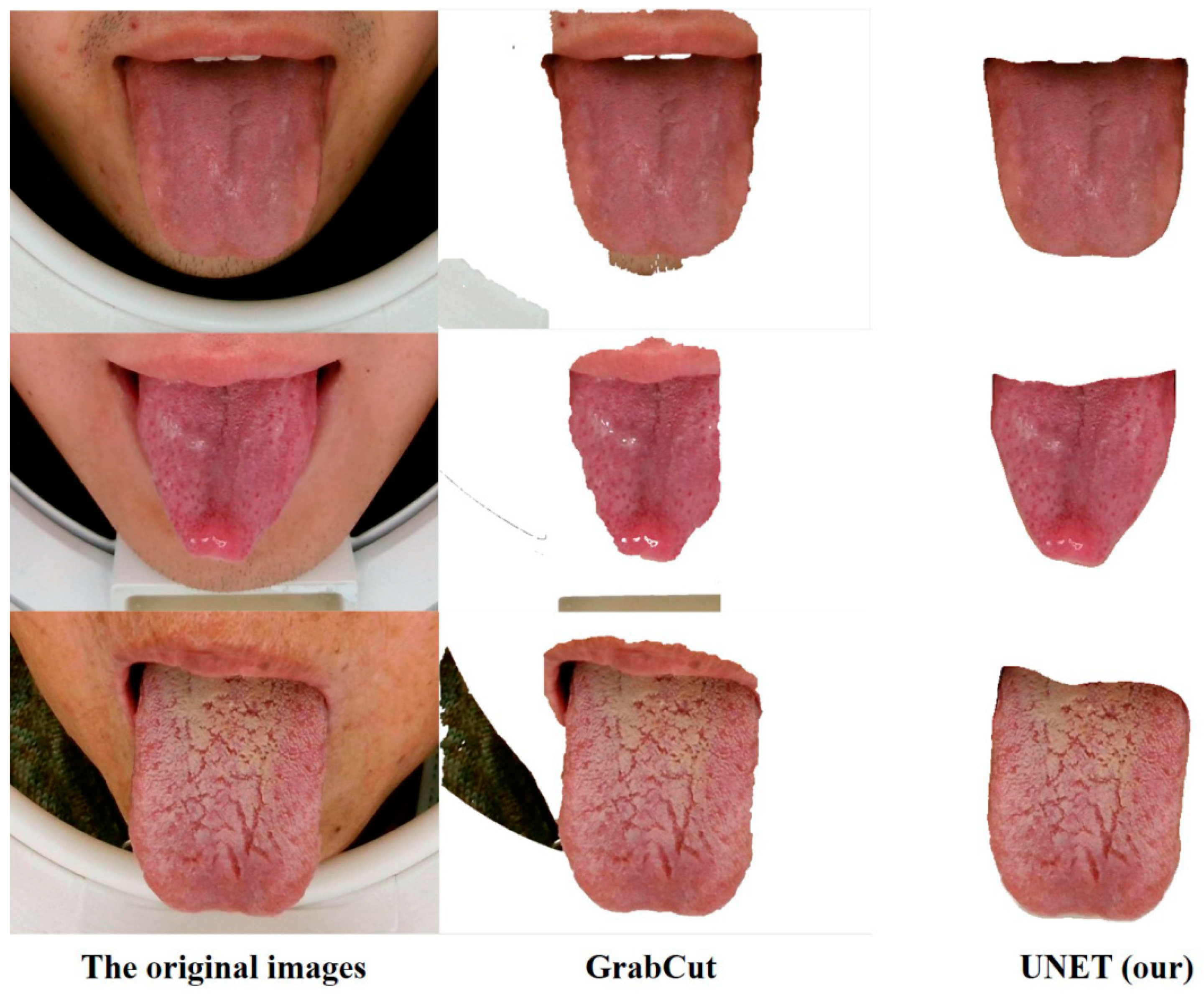
3.3. Segmentation of Tongue Images
- Structure: The structure of UNET can be divided into two parts (Figure 4). The first half of the UNET is the backbone feature extraction network. VGG16 [26] was chosen for feature extraction, which is a stack of convolution and maximum pooling operations. A feature layer with a new scale can be acquired after each pooling, resulting in five feature layers with distinct scales. The up-sampling part takes up the second half. The five feature layers were merged through the up-convolution method to produce an effective feature layer that contains all the features. The category of each pixel can be predicted according to the last obtained effective feature layer.
- Training: The data set for tongue segmentation was divided into the training set, validation set, and test set according to 8:1:1. The data were enhanced prior to training by random rotation and horizontal flipping of the image, as well as normalization. The loss included cross-entropy loss and dice loss. Adam algorithm was applied for optimization. Then, we used the official weight of the UNET network in the ImageNet data set as the initial weight for transfer learning. A total of 160 rounds were used to train the network. The weights of the backbone network were frozen in the first 80 rounds for rough training, and the learning rate was 1 × 10−4. The global network was trained with a learning rate of 1 × 10−5 in the last 80 rounds for fine training.
- Image Processing: The segmented contour images were processed by grayscale. Through observation, the generated gray image had a single gray level, with black pixels in the outer circle. Therefore, the grayscale image could be used as a mask to perform AND operate on the original tongue region image to realize the separation of the tongue. Then, we appended corresponding labels to the segmented tongue images to create classification data sets, which were also divided into the training, validation, and test sets for the training of the classification models.
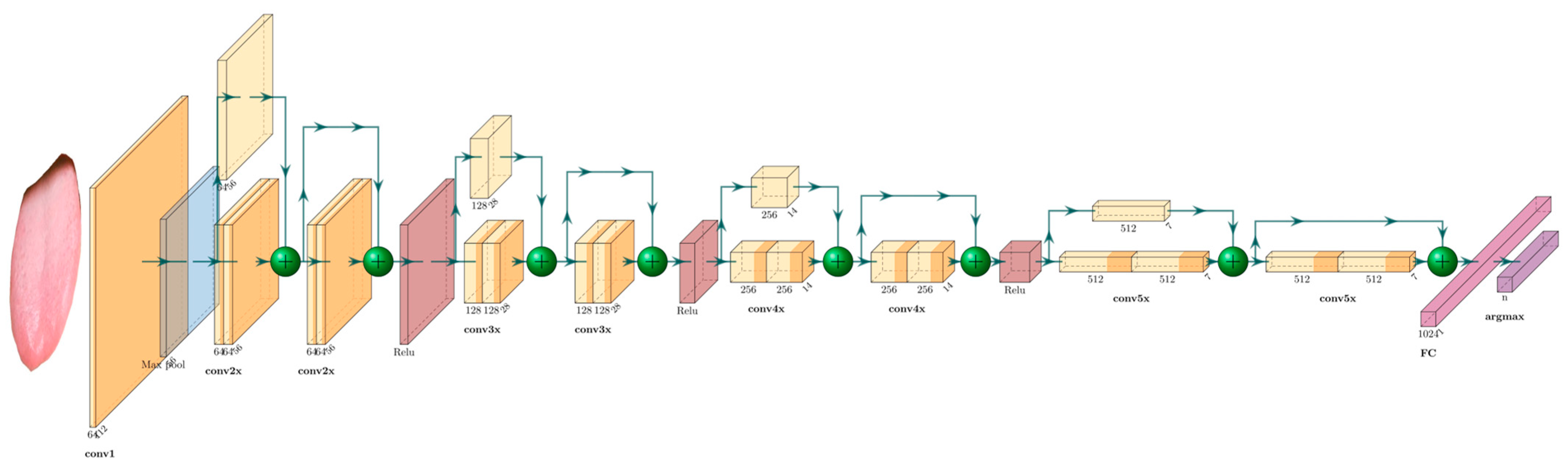
3.4. Classification
- Structure: Residual Network (ResNet-34) is a deep CNN with 34 layers, including 16 residual blocks, each with two layers (Figure 5). The last layer is an FC layer for tongue feature classification. The residual network increases the depth of the network through the connection of multiple residual blocks, while also avoiding the problem of gradient disappearance or gradient explosion.
- Training: The data sets for tongue feature classification are divided into the training set, validation set, and test set according to 6:2:2. The data are enhanced and normalized in the same way as the segmentation network preprocessing. The official model trained by ImageNet is used for initialization. The training is terminated after 160 rounds at a learning rate of 1 × 10−4. The models are trained separately for 11 different tongue feature data sets. At the end of the network, the output layer is adjusted accordingly to the number of internal categories of the different features, and the final classification judgment is made using the argmax function.
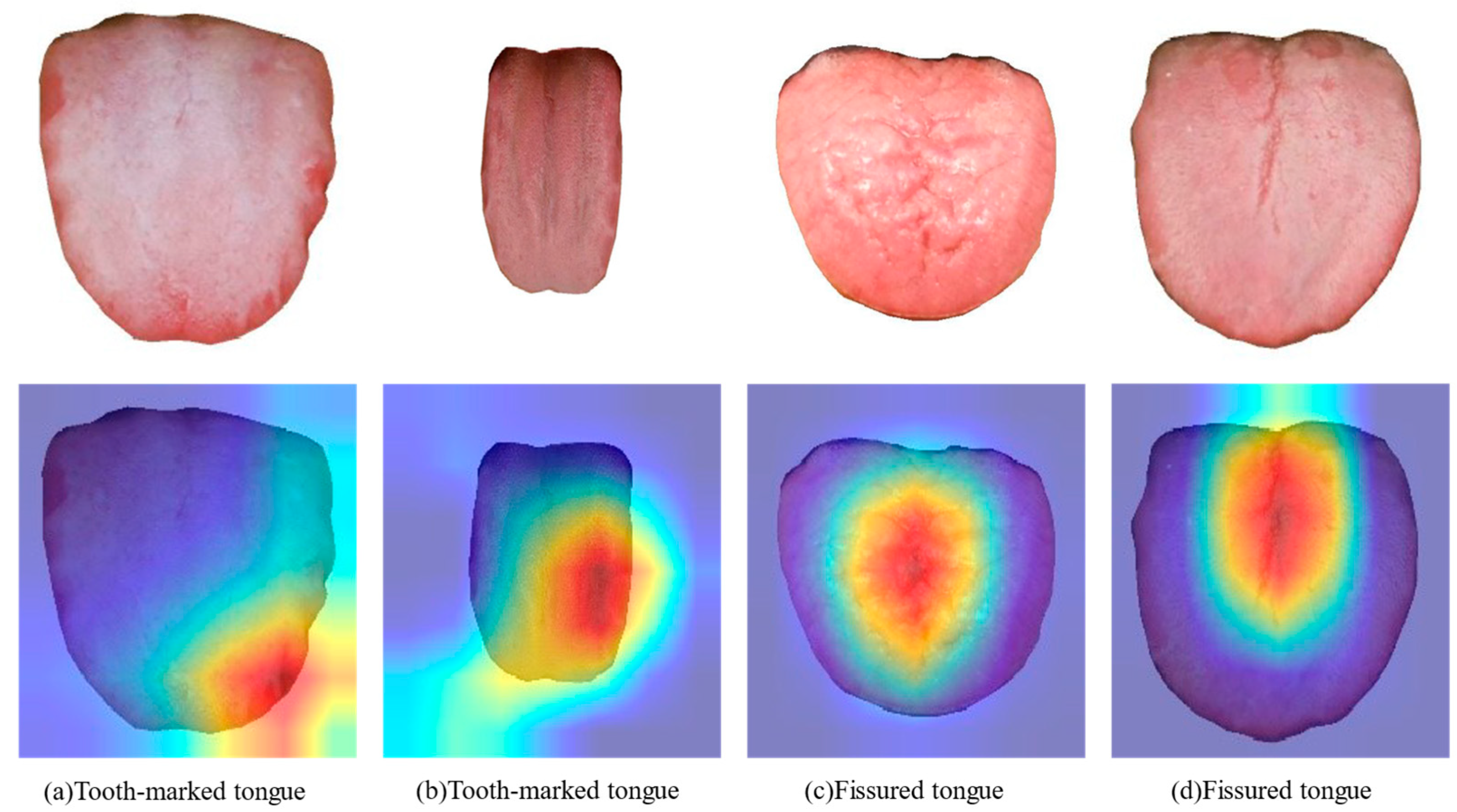
3.5. Feature Visualization
4. Results
4.1. Results of Tongue Image Segmentation
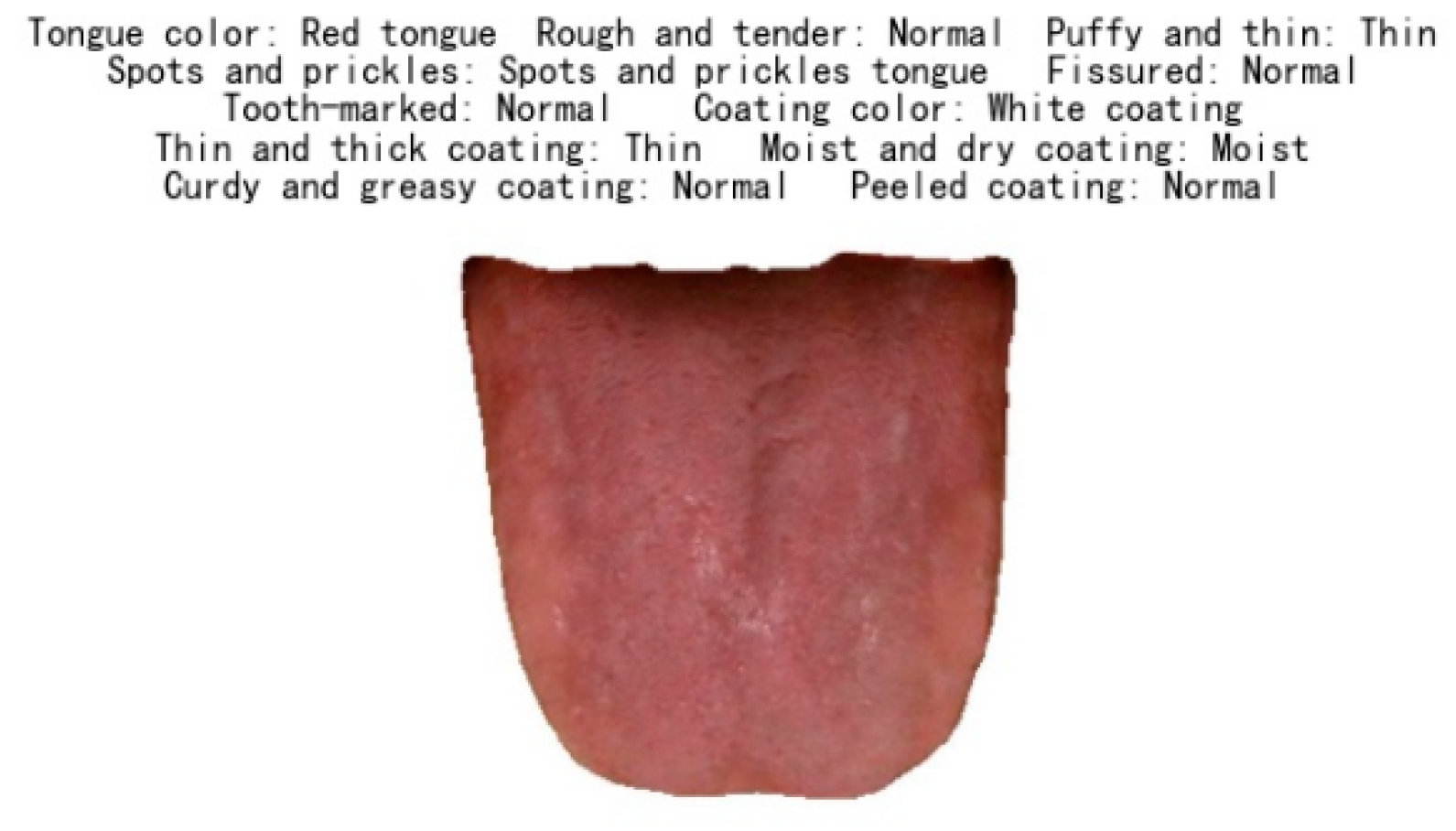
4.2. Results of Tongue Feature Classification
4.3. Visualization of the Indicator Regions of Tongue Feature Classification
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Ethical Statement
References
- Cyranoski, D. Why Chinese medicine is heading for clinics around the world. Nature 2018, 561, 448–450. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, Q.; Tang, W.; Teng, F.; Peng, W.; Zhang, Y.; Li, W.; Wen, C.; Guo, J. Intelligent Syndrome Differentiation of Traditional Chinese Medicine by ANN: A Case Study of Chronic Obstructive Pulmonary Disease. IEEE Access 2019, 7, 76167–76175. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Y.; Cui, Q.; Yi, X.; Zhang, Y. Tooth-Marked Tongue Recognition Using Multiple Instance Learning and CNN Features. IEEE Trans. Cybern. 2018, 49, 380–387. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Hu, G.; Zhang, X. Constitution Identification of Tongue Image Based on CNN. In Proceedings of the 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics, CISP-BMEI 2018, Beijing, China, 13–15 October 2018; IEEE: Beijing, China, 2019; pp. 1–5. [Google Scholar]
- Jiang, L.; Xu, W.; Chen, J. Digital imaging system for physiological analysis by tongue colour inspection. In Proceedings of the 2008 3rd IEEE Conference on Industrial Electronics and Applications, Singapore, 3–5 June 2008; IEEE: Singapore, 2008; pp. 1833–1836. [Google Scholar]
- Li, W.; Hu, S.; Wang, S.; Xu, S. Towards the objectification of tongue diagnosis: Automatic segmentation of tongue image. In Proceedings of the 2009 35th Annual Conference of IEEE Industrial Electronics, Porto, Portugal, 3–5 November 2009; IEEE: Porto, Portugal, 2010; pp. 2121–2124. [Google Scholar]
- Ning, J.; Zhang, D.; Wu, C.; Feng, Y. Automatic tongue image segmentation based on gradient vector flow and region merging. Neural Comput. Appl. 2012, 21, 1819–1826. [Google Scholar] [CrossRef]
- Zhu, M.; Du, J. A Novel Approach for Color Tongue Image Extraction Based on Random Walk Algorithm. Appl. Mech. Mater. 2013, 462–463, 338–342. [Google Scholar] [CrossRef]
- Li, C.; Wang, D.; Liu, Y.; Gao, X.; Shang, H. A novel automatic tongue image segmentation algorithm: Color enhancement method based on L*a*b* color space. In Proceedings of the 2015 IEEE International Conference on Bioinformatics and Biomedicine, BIBM 2015, Washington, DC, USA, 9–12 November 2015; IEEE: Washington, DC, USA, 2015; pp. 990–993. [Google Scholar]
- Xu, W.; Kanawong, R.; Xu, D.; Li, S.; Ma, T.; Zhang, G.; Duan, Y. An automatic tongue detection and segmentation framework for computer-aided tongue image analysis. In Proceedings of the 2011 IEEE 13th International Conference on e-Health Networking, Applications and Services, Columbia, MO, USA, 13–15 June 2011; IEEE: Columbia, MO, USA, 2011; pp. 189–192. [Google Scholar]
- Wu, J.; Zhang, Y.; Bai, J. Tongue Area Extraction in Tongue Diagnosis of Traditional Chinese Medicine. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 17–18 January 2006; IEEE: Shanghai, China, 2006; pp. 4955–4957. [Google Scholar]
- Lin, B.; Xie, J.; Li, C.; Qu, Y. Deeptongue: Tongue Segmentation via Resnet. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2018, Calgary, AB, Canada, 15–20 April 2018; IEEE: Calgary, AB, Canada, 2018; pp. 1035–1039. [Google Scholar]
- Xue, Y.; Li, X.; Wu, P.; Li, J.; Wang, L.; Tong, W. Automated Tongue Segmentation in Chinese Medicine Based on Deep Learning. In Proceedings of the 25th International Conference on Neural Information Processing, ICONIP 2018, Siem Reap, Cambodia, 13–16 December 2018; Cheng, L., Leung, A., Ozawa, S., Eds.; Springer: Cham, Switzerland; Siem Reap, Cambodia, 2018; pp. 542–553. [Google Scholar]
- Zhang, B.; Zhang, H. Significant Geometry Features in Tongue Image Analysis. Evid.-Based Complement. Alternat. Med. 2015, 2015, 897580. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, B.; Wu, J.; Zhang, D.; Li, N. Tongue shape classification by geometric features. Inform. Sci. 2010, 180, 312–324. [Google Scholar] [CrossRef]
- Tang, Y.; Sun, Y.; Chiang, J.; Li, X. Research on Multiple-Instance Learning for Tongue Coating Classification. IEEE Access 2021, 9, 66361–66370. [Google Scholar] [CrossRef]
- Xu, Q.; Zeng, Y.; Tang, W.; Peng, W.; Xia, T.; Li, Z.; Teng, F.; Li, W.; Guo, J. Multi-Task Joint Learning Model for Segmenting and Classifying Tongue Images Using a Deep Neural Network. IEEE J. Biomed. Health 2020, 24, 2481–2489. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Liu, J.; Wu, C.; Liu, J.; Li, Q.; Chen, Y.; Wang, X.; Chen, X.; Pang, X.; Chang, B.; et al. Artificial intelligence in tongue diagnosis: Using deep convolutional neural network for recognizing unhealthy tongue with tooth-mark. Comput. Struct. Biotechnol. J. 2020, 18, 973–980. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Yu, Z.; Liu, W.; Zhang, Z. Tongue Image Segmentation via Color Decomposition and Thresholding. In Proceedings of the 2017 4th International Conference on Information Science and Control Engineering, ICISCE 2017, Changsha, China, 21–23 July 2017; IEEE: Changsha, China, 2017; pp. 752–755. [Google Scholar]
- Shi, M.; Li, G.; Li, F. C2G2FSnake: Automatic tongue image segmentation utilizing prior knowledge. Sci. China Inf. Sci. 2013, 56, 1–14. [Google Scholar] [CrossRef]
- Qu, P.; Zhang, H.; Zhuo, L.; Zhang, J.; Chen, G. Automatic Tongue Image Segmentation for Traditional Chinese Medicine Using Deep Neural Network. In Proceedings of the Intelligent Computing Theories and Application, ICIC 2017, Liverpool, UK, 20 July 2017; Springer: Cham, Switzerland; Liverpool, UK, 2017; pp. 247–259. [Google Scholar]
- Zhou, C.; Fan, H.; Li, C. TongueNet: Accurate Localization and Segmentation for Tongue Images using Deep Neural Networks. IEEE Access 2019, 7, 1. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef] [Green Version]
- Karen, S.; Andrew, Z. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Rother, C.; Kolmogorov, V.; Blake, A. GrabCut: Interactive foreground extraction using iterated graph cut. ACM Trans. Graphic. 2004, 23, 309–314. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Inner-Class |
|---|---|
| Tongue color | Pale tongue, Light red tongue, Light cyanosed tongue, Red tongue, Deep red tongue, Cyanosed tongue, Ashen tongue, Red tongue borders and tip |
| Rough and tender tongue | Normal, Rough tongue, Tender tongue |
| Puffy and thin tongue | Normal, Puffy tongue, Swollen tongue, Thin tongue |
| Spots and prickles tongue | Normal, Spots and prickles tongue |
| Fissured tongue | Normal, Fissured tongue |
| Tooth-marked tongue | Normal, Tooth-marked tongue |
| Tongue coating color | White coating, Yellow coating, Grayish black coating |
| Thin and thick coating | Thin coating, Thick coating |
| Moist and dry coating | Moist coating, Slippery coating, Dry coating |
| Curdy and greasy coating | Normal, Greasy coating, Curdy coating |
| Peeled coating | Normal, Peeled coating |
| Method | PA | MIoU |
|---|---|---|
| GrabCut | 79.96% | 66.26% |
| UNET | 98.54% | 97.14% |
| Feature | Acc | F1-Score |
|---|---|---|
| Tongue color | 62.4% | 55.2% |
| Rough and tender tongue | 91.6% | 83.6% |
| Puffy and thin tongue | 86.3% | 74.4% |
| Spots and prickles tongue | 83.3% | 76.5% |
| Fissured tongue | 87.5% | 82.9% |
| Tooth-marked tongue | 86.7% | 84.0% |
| Tongue coating color | 87.5% | 86.5% |
| Thin and thick coating | 89.5% | 89.2% |
| Moist and dry coating | 87.4% | 67.0% |
| Curdy and greasy coating | 86.3% | 87.2% |
| Peeled coating | 98.9% | 94.2% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhang, Z.; Zhu, X.; Zhao, Y.; Ma, Y.; Zang, J.; Li, B.; Cao, X.; Xue, C. Automatic Classification Framework of Tongue Feature Based on Convolutional Neural Networks. Micromachines 2022, 13, 501. https://doi.org/10.3390/mi13040501
Li J, Zhang Z, Zhu X, Zhao Y, Ma Y, Zang J, Li B, Cao X, Xue C. Automatic Classification Framework of Tongue Feature Based on Convolutional Neural Networks. Micromachines. 2022; 13(4):501. https://doi.org/10.3390/mi13040501
Chicago/Turabian StyleLi, Jiawei, Zhidong Zhang, Xiaolong Zhu, Yunlong Zhao, Yuhang Ma, Junbin Zang, Bo Li, Xiyuan Cao, and Chenyang Xue. 2022. "Automatic Classification Framework of Tongue Feature Based on Convolutional Neural Networks" Micromachines 13, no. 4: 501. https://doi.org/10.3390/mi13040501