
A Portable Sign Language Collection and Translation Platform with Smart Watches Using a BLSTM-Based Multi-Feature Framework


Abstract
:1. Introduction
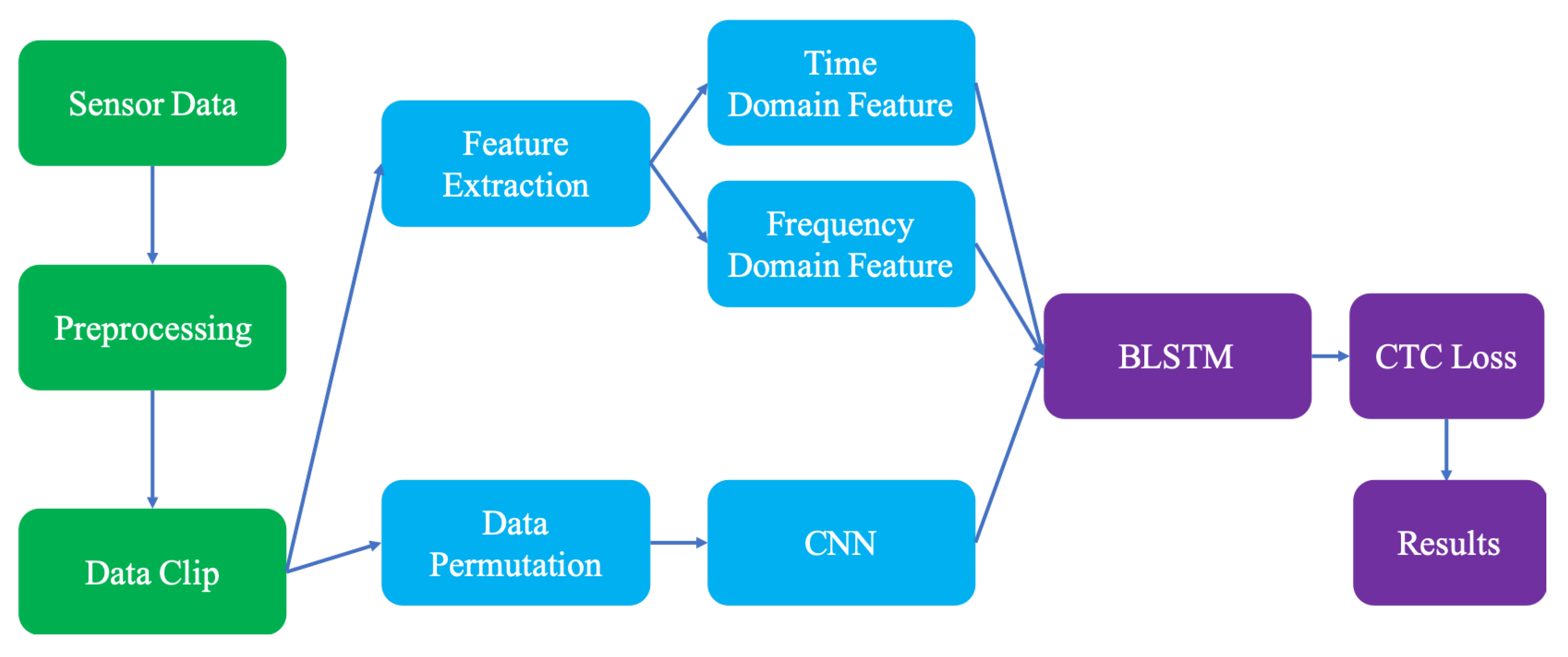
- A BLSTM-based multi-feature framework is proposed for conducting CSLR with smart watch data. In this framework, three types of features are extracted from the raw data and processed by the BLSTM layer to produce the results;
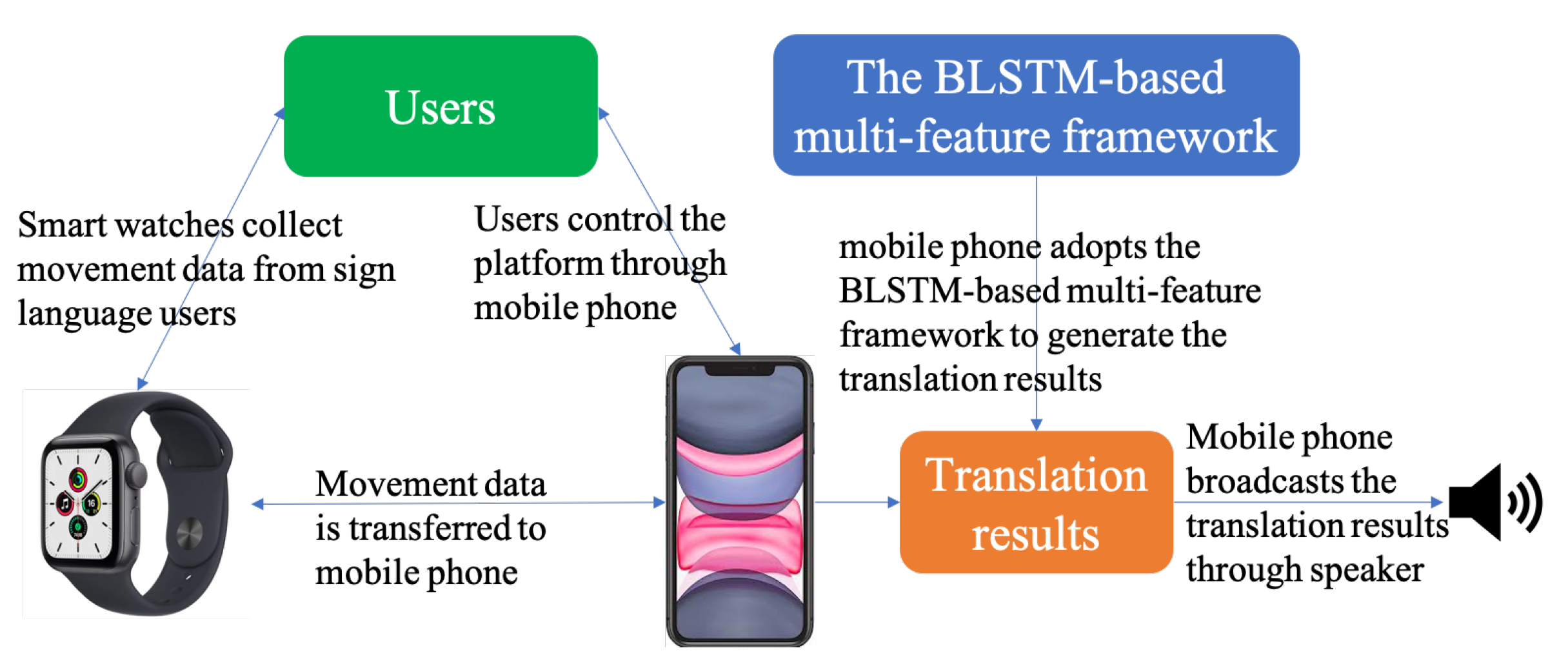
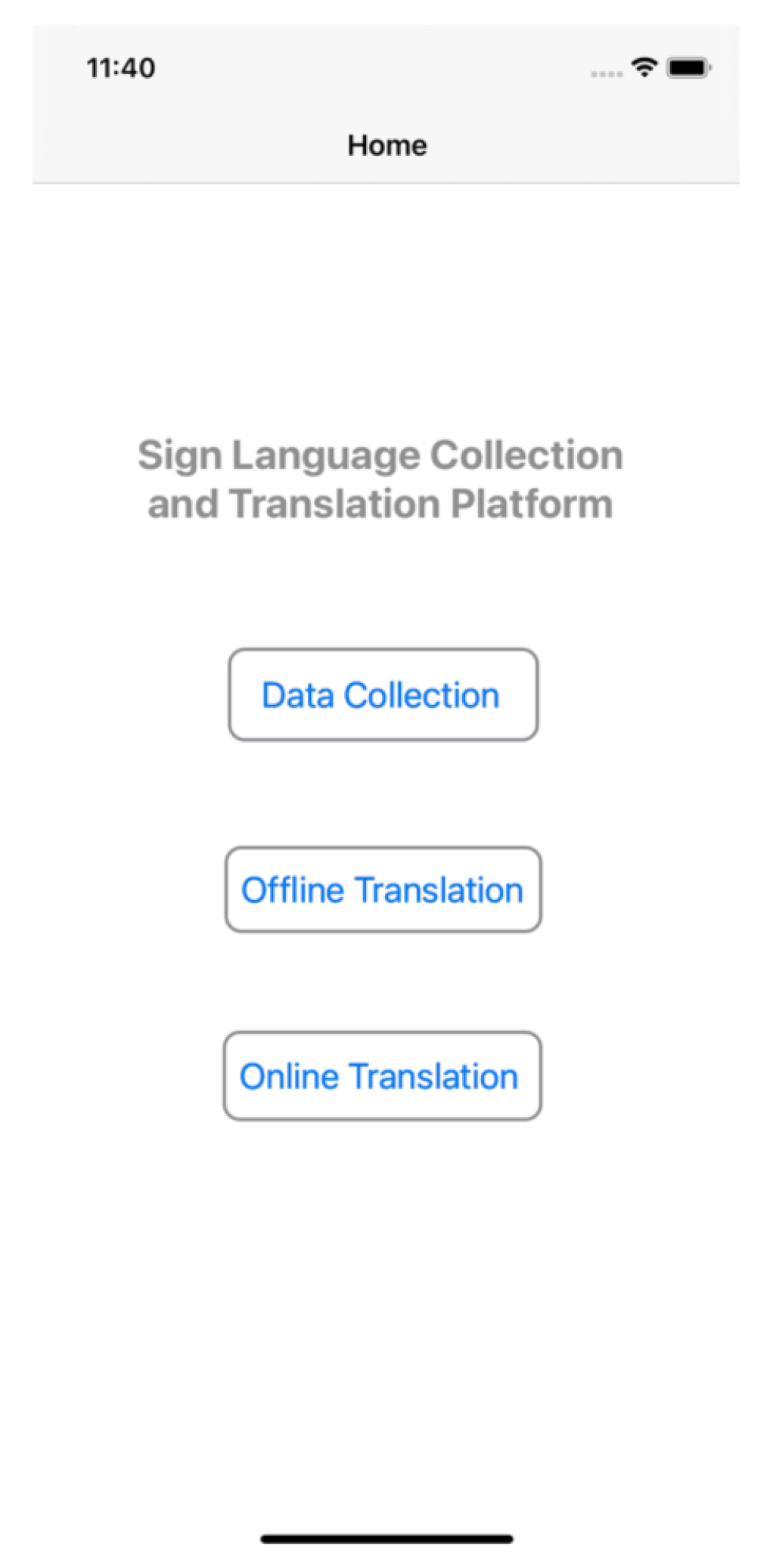
- A portable sign language collection and translation platform was developed. This platform not only simplifies the operation of collecting gesture-based sign language datasets, but also supports both offline and online sign language translation;
- A new gesture-based continuous HKSL dataset was collected, in which there are 50 sign language sentences performed by 6 signers with 8 repetitions. In this dataset, the accelerometer data and gyroscope data of the signers were recorded by smart watches with a sample rate of 50 Hz. This dataset will be available to the public to facilitate research into gesture-based CSLR;
- Intensive experiments were conducted to compare the performance of different machine learning and deep learning approaches with the BLSTM-based multi-feature framework in gesture-based CSLR.
2. Related Work
3. The BLSTM-Based and Multi-Feature Framework
3.1. Preprocessing the Raw Data
3.2. Extracting the Time Domain and Frequency Domain Features
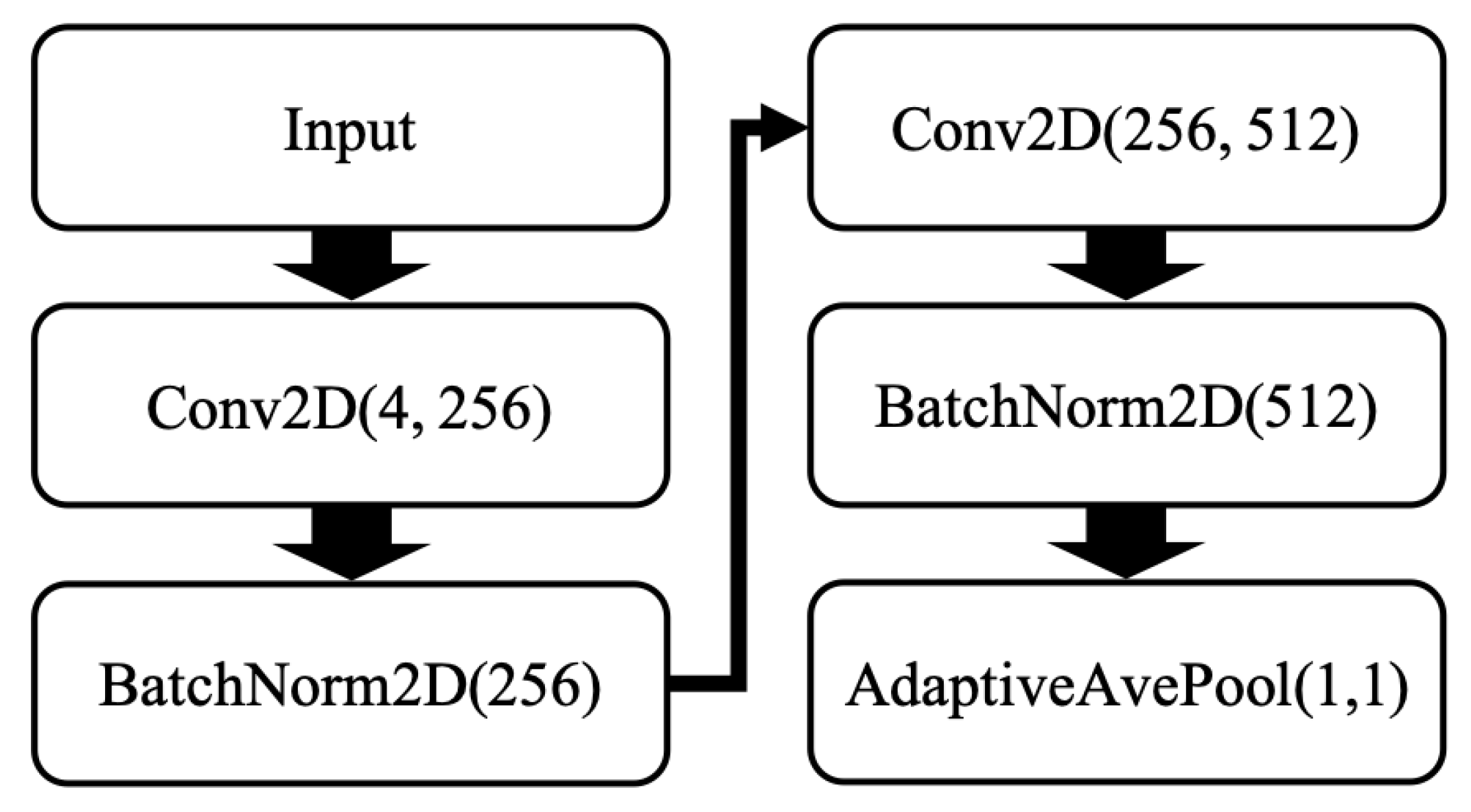
3.3. Extracting the CNN-Based Features
3.4. Sequential Learning with the BLSTM
3.5. Framework Formulation
3.6. Loss Function
4. Experimental Results of the Proposed Platform on the HKSL Dataset
4.1. Information on the Proposed Continuous Sign Language Dataset
4.2. Experimental Results
4.3. Comparison with Other Machine Learning Approaches
4.4. Comparison with Other Deep Learning Approaches
5. The Portable Sign Language Collection and Translation Platform
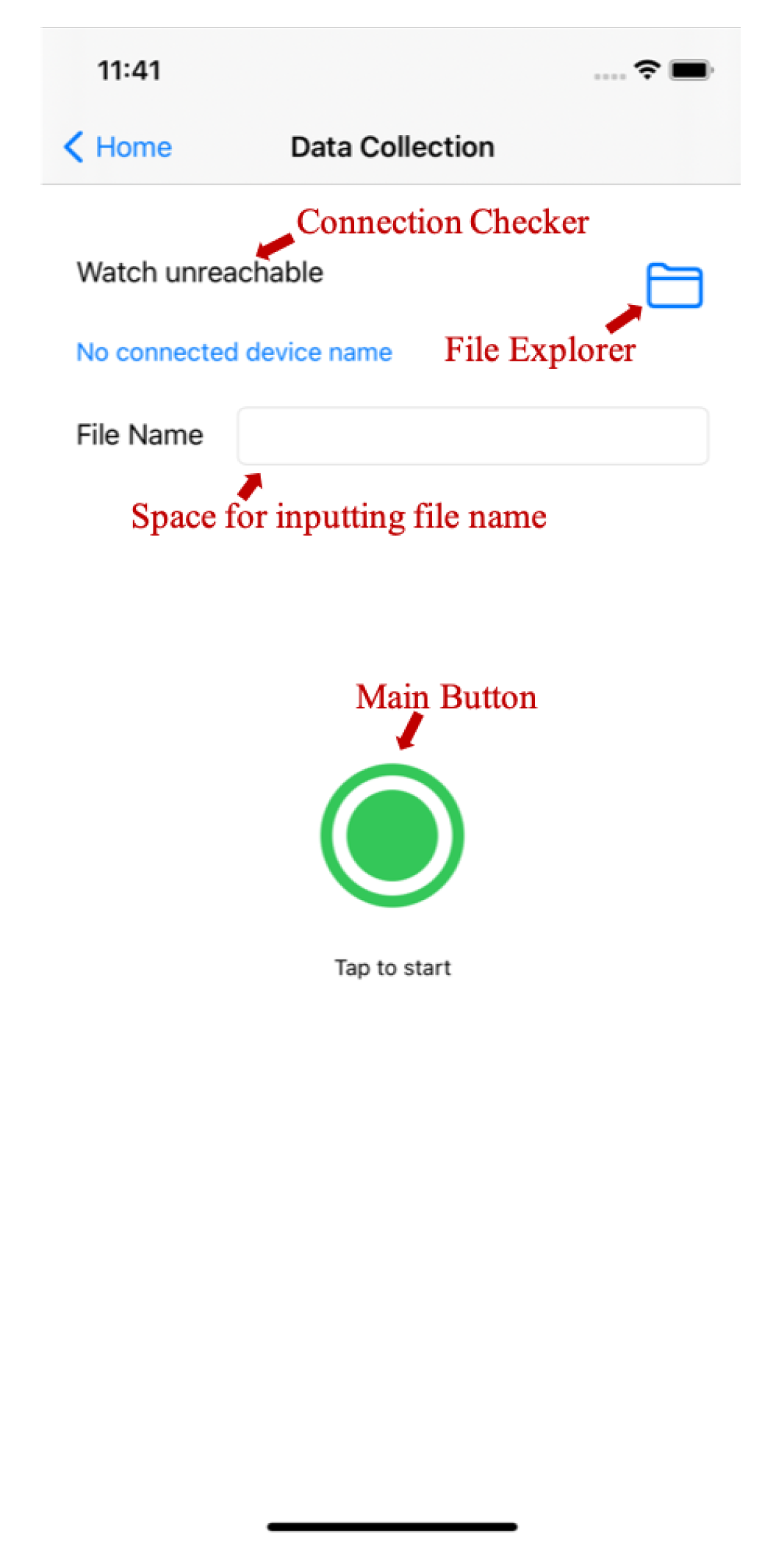
5.1. The Sign Language Dataset Collection System
5.2. The Offline Sign Language Translation System
5.3. The Online Sign Language Translation System
5.4. Experimental Results of the Proposed Platform
6. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Conflicts of Interest
References
- Bragg, D.; Koller, O.; Bellard, M.; Berke, L.; Boudrealt, P.; Braffort, A.; Caselli, N.; Huenerfauth, M.; Kacorri, H.; Verhoef, T.; et al. Sign Language Recognition, Generation, and Translation: An Interdisciplinary Perspective. In Proceedings of the The 21st International ACM SIGACCESS Conference on Computers and Accessibility, Pittsburgh, PA, USA, 28–30 October 2019; pp. 16–31. [Google Scholar]
- Starner, T.; Pentland, A. Real-Time American Sign Language Recognition from Video Using Hidden Markov Models. In Proceedings of the IEEE International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 1995; pp. 265–270. [Google Scholar] [CrossRef]
- Forster, J.; Oberdörfer, C.; Koller, O.; Ney, H. Modality Combination Techniques for Continuous Sign Language Recognition. In Pattern Recognition and Image Analysis; Sanches, J.M., Micó, L., Cardoso, J.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 89–99. [Google Scholar]
- Wang, H.; Chai, X.; Chen, X. A Novel Sign Language Recognition Framework Using Hierarchical Grassmann Covariance Matrix. IEEE Trans. Multimed. 2019, 21, 2806–2814. [Google Scholar] [CrossRef]
- Cheng, K.L.; Yang, Z.; Chen, Q.; Tai, Y.W. Fully Convolutional Networks for Continuous Sign Language Recognition. arXiv 2020, arXiv:2007.12402. [Google Scholar]
- Tubaiz, N.; Shanableh, T.; Assaleh, K. Glove-Based Continuous Arabic Sign Language Recognition in User-Dependent Mode. IEEE Trans. Hum. Mach. Syst. 2015, 45, 526–533. [Google Scholar] [CrossRef] [Green Version]
- Gaka, J.; Masior, M.; Zaborski, M.; Barczewska, K. Inertial Motion Sensing Glove for Sign Language Gesture Acquisition and Recognition. IEEE Sens. J. 2016, 16, 6310–6316. [Google Scholar] [CrossRef]
- Cui, R.; Liu, H.; Zhang, C. A Deep Neural Framework for Continuous Sign Language Recognition by Iterative Training. IEEE Trans. Multimed. 2019, 21, 1880–1891. [Google Scholar] [CrossRef]
- Zhou, Z.; Lui, K.S.; Tam, V.W.; Lam, E.Y. Applying (3+2+1)D Residual Neural Network with Frame Selection for Hong Kong Sign Language Recognition. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4296–4302. [Google Scholar] [CrossRef]
- Pu, J.; Zhou, W.; Li, H. Iterative Alignment Network for Continuous Sign Language Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4160–4169. [Google Scholar] [CrossRef]
- Guo, D.; Zhou, W.; Li, A.; Li, H.; Wang, M. Hierarchical Recurrent Deep Fusion Using Adaptive Clip Summarization for Sign Language Translation. IEEE Trans. Image Process. 2020, 29, 1575–1590. [Google Scholar] [CrossRef]
- Guo, D.; Zhou, W.; Li, H.; Wang, M. Hierarchical LSTM for Sign Language Translation; AAAI: Menlo Park, CA, USA, 2018; pp. 6845–6852. [Google Scholar]
- Huang, J.; Zhou, W.; Li, H.; Li, W. Attention-Based 3D-CNNs for Large-Vocabulary Sign Language Recognition. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 2822–2832. [Google Scholar] [CrossRef]
- Maddalena, L.; Petrosino, A. A Self-Organizing Approach to Background Subtraction for Visual Surveillance Applications. IEEE Trans. Image Process. 2008, 17, 1168–1177. [Google Scholar] [CrossRef]
- Cuevas, C.; Martínez, R.; Berjón, D.; García, N. Detection of Stationary Foreground Objects Using Multiple Nonparametric Background-Foreground Models on a Finite State Machine. IEEE Trans. Image Process. 2017, 26, 1127–1142. [Google Scholar] [CrossRef] [Green Version]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar]
- Fels, S.; Hinton, G. Glove-Talk: A neural network interface between a data-glove and a speech synthesizer. IEEE Trans. Neural Netw. 1993, 4, 2–8. [Google Scholar] [CrossRef] [Green Version]
- Oz, C.; Leu, M.C. American Sign Language Word Recognition with a Sensory Glove Using Artificial Neural Networks. Eng. Appl. Artif. Intell. 2011, 24, 1204–1213. [Google Scholar] [CrossRef]
- Jani, A.B.; Kotak, N.A.; Roy, A.K. Sensor Based Hand Gesture Recognition System for English Alphabets Used in Sign Language of Deaf-Mute People. In Proceedings of the IEEE SENSORS, New Delhi, India, 28–31 October 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Sengupta, A.; Mallick, T.; Das, A. A Cost Effective Design and Implementation of Arduino Based Sign Language Interpreter. In Proceedings of the Devices for Integrated Circuit (DevIC), Kalyani, India, 23–24 March 2019; pp. 12–15. [Google Scholar] [CrossRef]
- Siddiqui, N.; Chan, R.H.M. A wearable hand gesture recognition device based on acoustic measurements at wrist. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2017, 4443–4446. [Google Scholar] [CrossRef]
- Suri, K.; Gupta, R. Convolutional Neural Network Array for Sign Language Recognition Using Wearable IMUs. In Proceedings of the 6th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 7–8 March 2019; pp. 483–488. [Google Scholar] [CrossRef]
- Wu, J.; Tian, Z.; Sun, L.; Estevez, L.; Jafari, R. Real-time American Sign Language Recognition using wrist-worn motion and surface EMG sensors. In Proceedings of the IEEE 12th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Cambridge, MA, USA, 9–12 June 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Grimes, G.J. Digital Data Entry Glove Interface Device. US Patent US4414537A, 8 November 1983. [Google Scholar]
- Ekiz, D.; Kaya, G.E.; Buğur, S.; Güler, S.; Buz, B.; Kosucu, B.; Arnrich, B. Sign sentence recognition with smart watches. In Proceedings of the 25th Signal Processing and Communications Applications Conference (SIU), Antalya, Turkey, 15–18 May 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Kishore, P.V.V.; Kumar, D.A.; Sastry, A.S.C.S.; Kumar, E.K. Motionlets Matching With Adaptive Kernels for 3-D Indian Sign Language Recognition. IEEE Sens. J. 2018, 18, 3327–3337. [Google Scholar] [CrossRef]
- Lee, B.G.; Lee, S.M. Smart Wearable Hand Device for Sign Language Interpretation System With Sensors Fusion. IEEE Sens. J. 2018, 18, 1224–1232. [Google Scholar] [CrossRef]
- Deriche, M.; Aliyu, S.O.; Mohandes, M. An Intelligent Arabic Sign Language Recognition System Using a Pair of LMCs With GMM Based Classification. IEEE Sens. J. 2019, 19, 8067–8078. [Google Scholar] [CrossRef]
- Mittal, A.; Kumar, P.; Roy, P.; Balasubramanian, R.; Chaudhuri, B. A Modified LSTM Model for Continuous Sign Language Recognition Using Leap Motion. IEEE Sens. J. 2019, 19, 7056–7063. [Google Scholar] [CrossRef]
- Hou, J.; Li, X.Y.; Zhu, P.; Wang, Z.; Wang, Y.; Qian, J.; Yang, P. SignSpeaker: A Real-Time, High-Precision SmartWatch-Based Sign Language Translator. In Proceedings of the The 25th Annual International Conference on Mobile Computing and Networking, Los Cabos, Mexico, 21–25 October 2019; pp. 1–15. [Google Scholar] [CrossRef]
- Yu, Y.; Chen, X.; Cao, S.; Zhang, X.; Chen, X. Exploration of Chinese Sign Language Recognition Using Wearable Sensors Based on Deep Belief Net. IEEE J. Biomed. Health Informatics 2020, 24, 1310–1320. [Google Scholar] [CrossRef]
- Pan, J.; Luo, Y.; Li, Y.; Tham, C.K.; Heng, C.H.; Thean, A.V.Y. A Wireless Multi-Channel Capacitive Sensor System for Efficient Glove-Based Gesture Recognition With AI at the Edge. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 1624–1628. [Google Scholar] [CrossRef]
- Wong, W.K.; Juwono, F.H.; Khoo, B.T.T. Multi-Features Capacitive Hand Gesture Recognition Sensor: A Machine Learning Approach. IEEE Sens. J. 2021, 21, 8441–8450. [Google Scholar] [CrossRef]
- Ramalingame, R.; Barioul, R.; Li, X.; Sanseverino, G.; Krumm, D.; Odenwald, S.; Kanoun, O. Wearable Smart Band for American Sign Language Recognition With Polymer Carbon Nanocomposite-Based Pressure Sensors. IEEE Sens. Lett. 2021, 5, 1–4. [Google Scholar] [CrossRef]
- Zhao, T.; Liu, J.; Wang, Y.; Liu, H.; Chen, Y. Towards Low-Cost Sign Language Gesture Recognition Leveraging Wearables. IEEE Trans. Mob. Comput. 2021, 20, 1685–1701. [Google Scholar] [CrossRef]
- Gurbuz, S.Z.; Gurbuz, A.C.; Malaia, E.A.; Griffin, D.J.; Crawford, C.S.; Rahman, M.M.; Kurtoglu, E.; Aksu, R.; Macks, T.; Mdrafi, R. American Sign Language Recognition Using RF Sensing. IEEE Sens. J. 2021, 21, 3763–3775. [Google Scholar] [CrossRef]
- Meng, X.; Feng, L.; Yin, X.; Zhou, H.; Sheng, C.; Wang, C.; Du, A.; Xu, L. Sentence-Level Sign Language Recognition Using RF signals. In Proceedings of the 6th International Conference on Behavioral, Economic and Socio-Cultural Computing (BESC), Beijing, China, 28–30 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Breland, D.S.; Skriubakken, S.B.; Dayal, A.; Jha, A.; Yalavarthy, P.K.; Cenkeramaddi, L.R. Deep Learning-Based Sign Language Digits Recognition From Thermal Images With Edge Computing System. IEEE Sens. J. 2021, 21, 10445–10453. [Google Scholar] [CrossRef]
- Maharjan, P.; Bhatta, T.; Park, J.Y. Thermal Imprinted Self-Powered Triboelectric Flexible Sensor for Sign Language Translation. In Proceedings of the 20th International Conference on Solid-State Sensors, Actuators and Microsystems, Berlin, Germany, 23–27 June 2019; pp. 385–388. [Google Scholar] [CrossRef]
- Shin, H.C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Kim, M.; Cao, B.; Mau, T.; Wang, J. Speaker-Independent Silent Speech Recognition From Flesh-Point Articulatory Movements Using an LSTM Neural Network. IEEE ACM Trans. Audio Speech Lang. Process. 2017, 25, 2323–2336. [Google Scholar] [CrossRef]
- Li, W.; Chen, N.F.; Siniscalchi, S.M.; Lee, C.H. Improving Mispronunciation Detection of Mandarin Tones for Non-Native Learners With Soft-Target Tone Labels and BLSTM-Based Deep Tone Models. IEEE ACM Trans. Audio Speech Lang. Process. 2019, 27, 2012–2024. [Google Scholar] [CrossRef]
- Li, L.; Jiang, Y. Integrating Language Model and Reading Control Gate in BLSTM-CRF for Biomedical Named Entity Recognition. IEEE ACM Trans. Comput. Biol. Bioinform. 2020, 17, 841–846. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Bharti, P.; Panwar, A.; Gopalakrishna, G.; Chellappan, S. Watch-Dog: Detecting Self-Harming Activities From Wrist Worn Accelerometers. IEEE J. Biomed. Health Informatics 2018, 22, 686–696. [Google Scholar] [CrossRef]
- Iskanderov, J.; Guvensan, M.A. Breaking the Limits of Transportation Mode Detection: Applying Deep Learning Approach With Knowledge-Based Features. IEEE Sens. J. 2020, 20, 12871–12884. [Google Scholar] [CrossRef]
- Zhou, Z.; Lui, K.S.; Tam, V.W.; Lam, E.Y. SignBERT: A BERT-Based and Robust Deep Learning Framework for Continuous Sign Language Recognition. IEEE Access 2021, 9, 161669–161682, manuscript submitted for publication. [Google Scholar] [CrossRef]
- Zhou, Z.; Neo, Y.; Lui, K.S.; Tam, V.W.; Lam, E.Y.; Wong, N. A Portable Hong Kong Sign Language Translation Platform with Deep Learning and Jetson Nano. In Proceedings of the The 22nd International ACM SIGACCESS Conference on Computers and Accessibility, Virtual Event, Greece, 26–28 October 2020; pp. 1–4. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Feature Number | |
|---|---|---|
| Time Domain | Mean | 12 |
| Magnitude of Mean | 4 | |
| Variance | 12 | |
| Correlation | 12 | |
| Covariance | 12 | |
| Frequency Domain | Intensities of the 12 columns at frequencies from 0 Hz to 25 Hz | 312 |
| Number | English Translation | Number | English Translation |
|---|---|---|---|
| 1 | I ate a French toast | 26 | My sister ate two rices with pork |
| 2 | You ate two French toasts | 27 | My sister ate three rices with mutton |
| 3 | He ate three French toasts | 28 | My elder brother wants a spoon |
| 4 | We like pineapple bread | 29 | My elder brother wants two bowls |
| 5 | You like pineapple bread | 30 | My elder brother wants three chopsticks |
| 6 | They like pineapple bread | 31 | My elder sister wants a bowl |
| 7 | I don’t like sandwich | 32 | My elder sister wants two chopsticks |
| 8 | You don’t like sandwich | 33 | My elder sister wants three spoons |
| 9 | He doesn’t like sandwich | 34 | My brother wants a chopstick |
| 10 | I want three rices with barbecued pork | 35 | My brother wants two spoons |
| 11 | You want one rice with roast goose | 36 | My brother wants three bowls |
| 12 | He wants two rices with pork chop | 37 | I want a cup |
| 13 | I like rice with roast goose | 38 | You want two saucers |
| 14 | You like rice with pork chop | 39 | He wants three forks |
| 15 | He likes rice with barbecued pork | 40 | We want a saucer |
| 16 | We don’t like rice with pork chop | 41 | You want two forks |
| 17 | You don’t like rice with barbecued pork | 42 | They want three cups |
| 18 | He doesn’t like rice with roast goose | 43 | My father wants one fork |
| 19 | My mother wants a porridge with beef | 44 | My mother wants two cups |
| 20 | My mother wants two porridges with pork | 45 | My elder sister wants three saucers |
| 21 | My mother wants three porridges with mutton | 46 | My sister wants three cups of ice cola |
| 22 | My father doesn’t like soup with beef | 47 | My grandfather wants two cups of ice cola |
| 23 | My father doesn’t like soup with pork | 48 | My grandmother wants one cups of ice cola |
| 24 | My father doesn’t like soup with mutton | 49 | My grandfather doesn’t like ice water |
| 25 | My sister ate a rice with beef | 50 | My grandmother doesn’t like ice water |
| Method | WER |
|---|---|
| Time + Frequency + CNN + SVM | 0.227 |
| Time + Frequency + CNN + RF | 0.249 |
| Time + Frequency + CNN + KNN | 0.251 |
| Time + Frequency + CNN + LDA | 0.258 |
| Time + Frequency + CNN + GMM | 0.378 |
| The Proposed BLSTM-Based and Multi-Feature Framework | 0.088 |
| Method | WER |
|---|---|
| Time + BLSTM | 0.208 |
| Frequency + BLSTM | 0.232 |
| Time + Frequency + BLSTM | 0.167 |
| CNN + BLSTM | 0.103 |
| The Proposed BLSTM-Based and Multi-Feature Framework | 0.088 |
| Number of Data Samples | 50 | Mobile Phone Model | iPhone XR |
|---|---|---|---|
| Maximum Translation Delay | 1.5 s | Minimum Translation Delay | 0.8 s |
| Average Translation WER | 9.2% | Average Translation Delay | 1.1 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.; Tam, V.W.L.; Lam, E.Y. A Portable Sign Language Collection and Translation Platform with Smart Watches Using a BLSTM-Based Multi-Feature Framework. Micromachines 2022, 13, 333. https://doi.org/10.3390/mi13020333
Zhou Z, Tam VWL, Lam EY. A Portable Sign Language Collection and Translation Platform with Smart Watches Using a BLSTM-Based Multi-Feature Framework. Micromachines. 2022; 13(2):333. https://doi.org/10.3390/mi13020333
Chicago/Turabian StyleZhou, Zhenxing, Vincent W. L. Tam, and Edmund Y. Lam. 2022. "A Portable Sign Language Collection and Translation Platform with Smart Watches Using a BLSTM-Based Multi-Feature Framework" Micromachines 13, no. 2: 333. https://doi.org/10.3390/mi13020333