
A Heterogeneity-Aware Replacement Policy for the Partitioned Cache on Asymmetric Multi-Core Architectures


Abstract
:1. Introduction
- We propose a heterogeneous-aware partitioned cache replacement policy, which reduces intercore interference and improves the efficiency of data usage in partitioned LLC in an asymmetric multi-core architecture.
- We design a reuse count table (RCT) for the historical reuse information of each cache block in LLC, and update the value inthe RCT according to the memory access characteristics of big cores and little cores, which can be further used in cache replacement decisions.
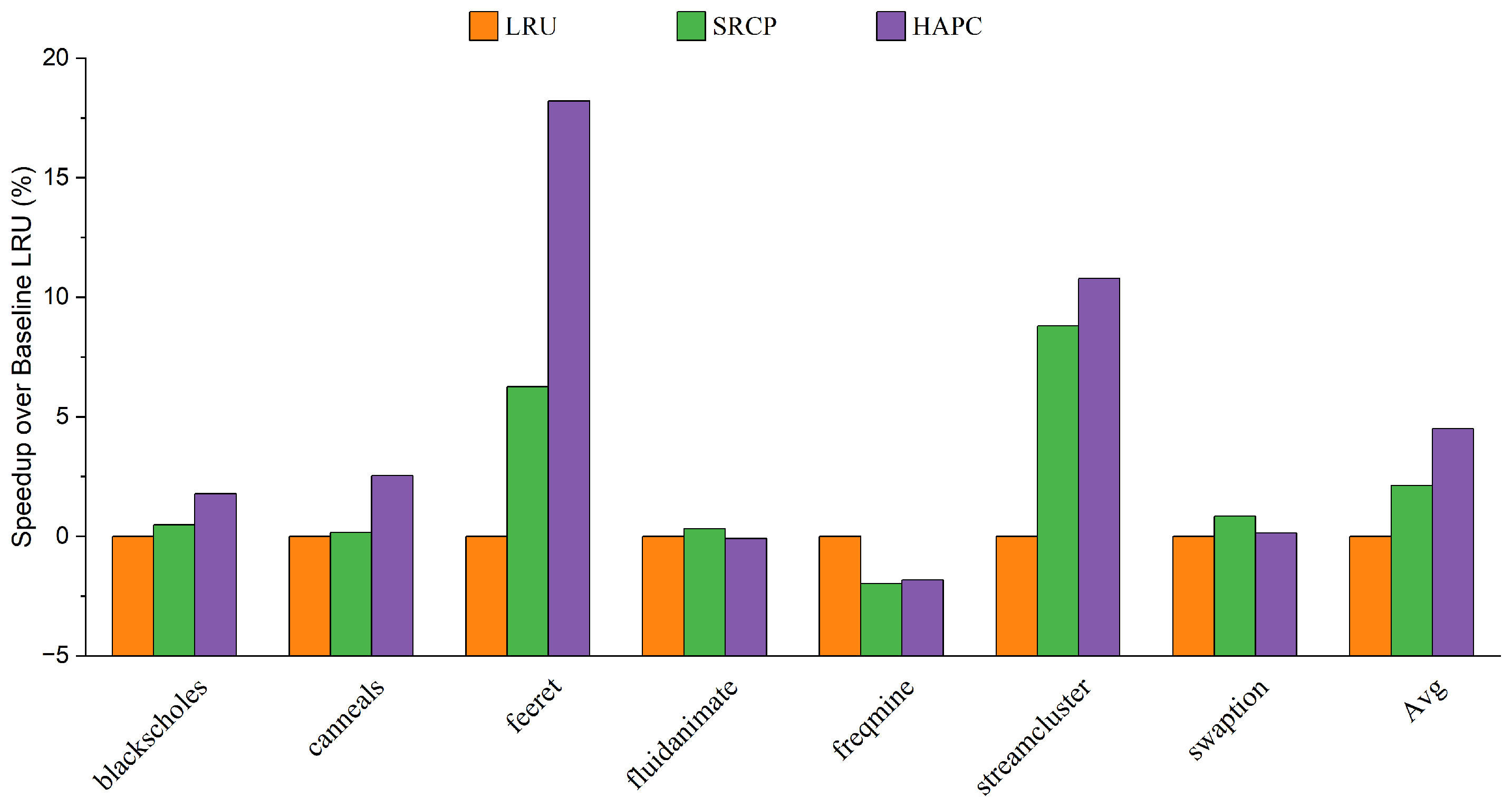
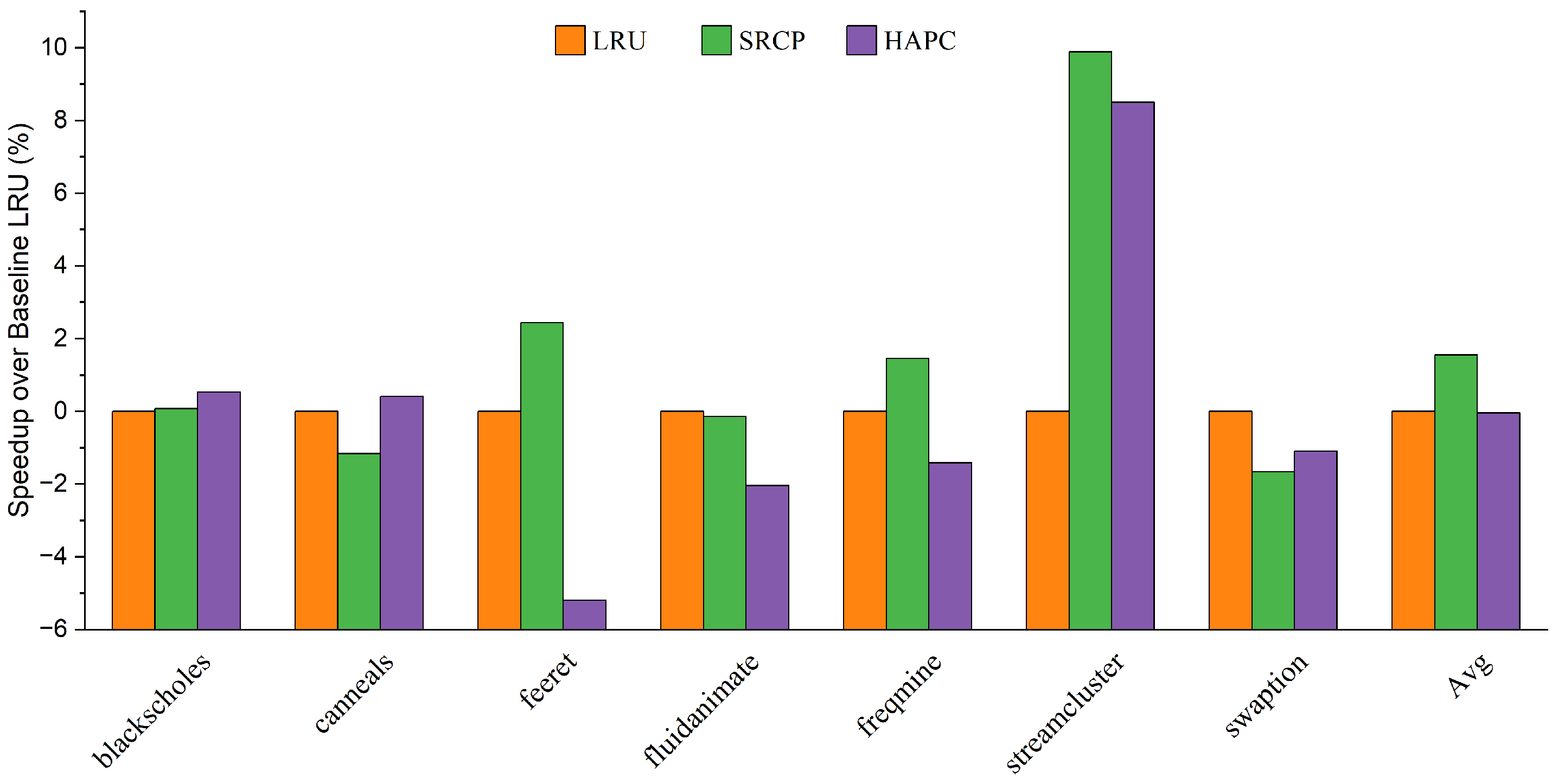
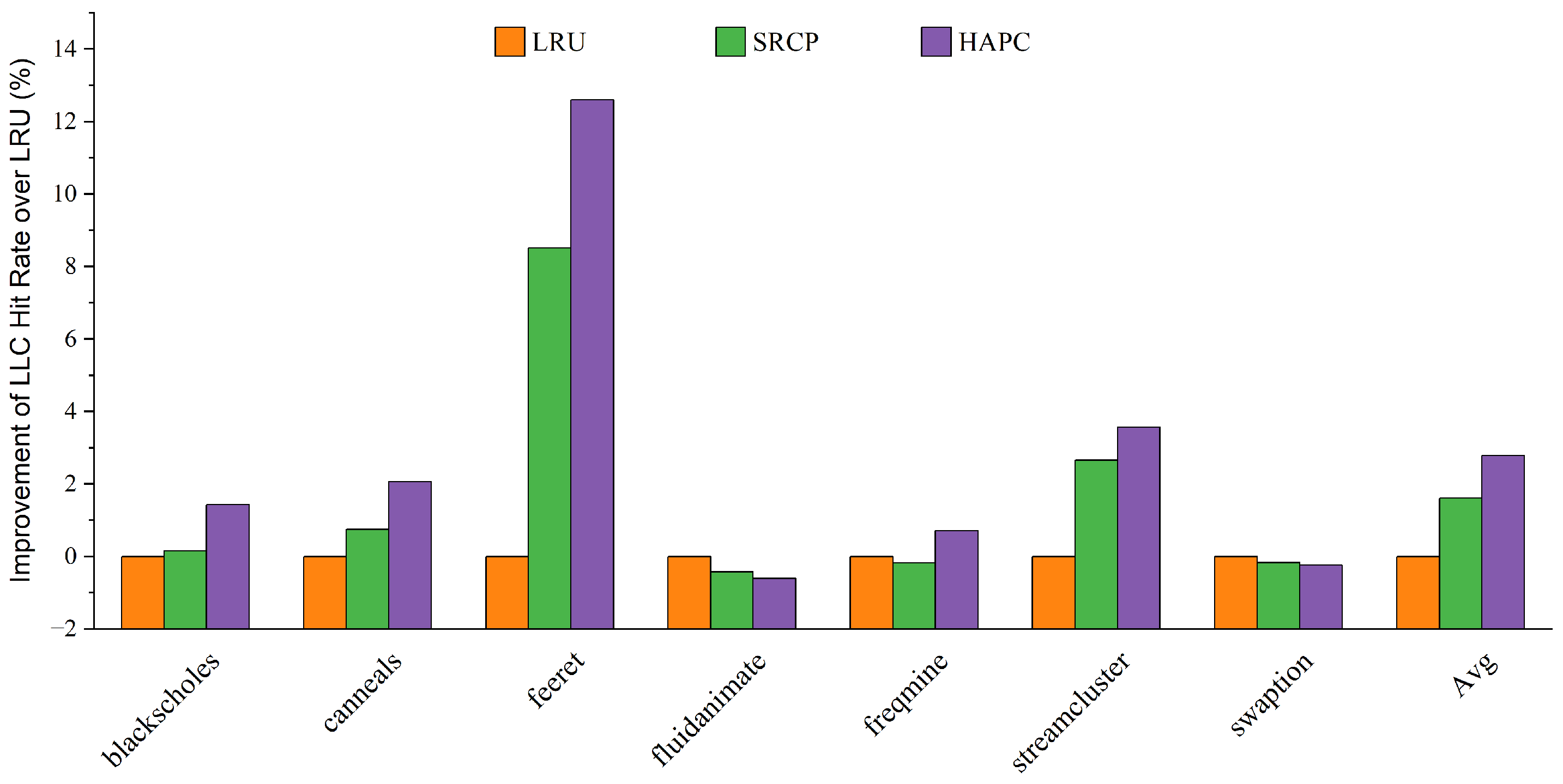
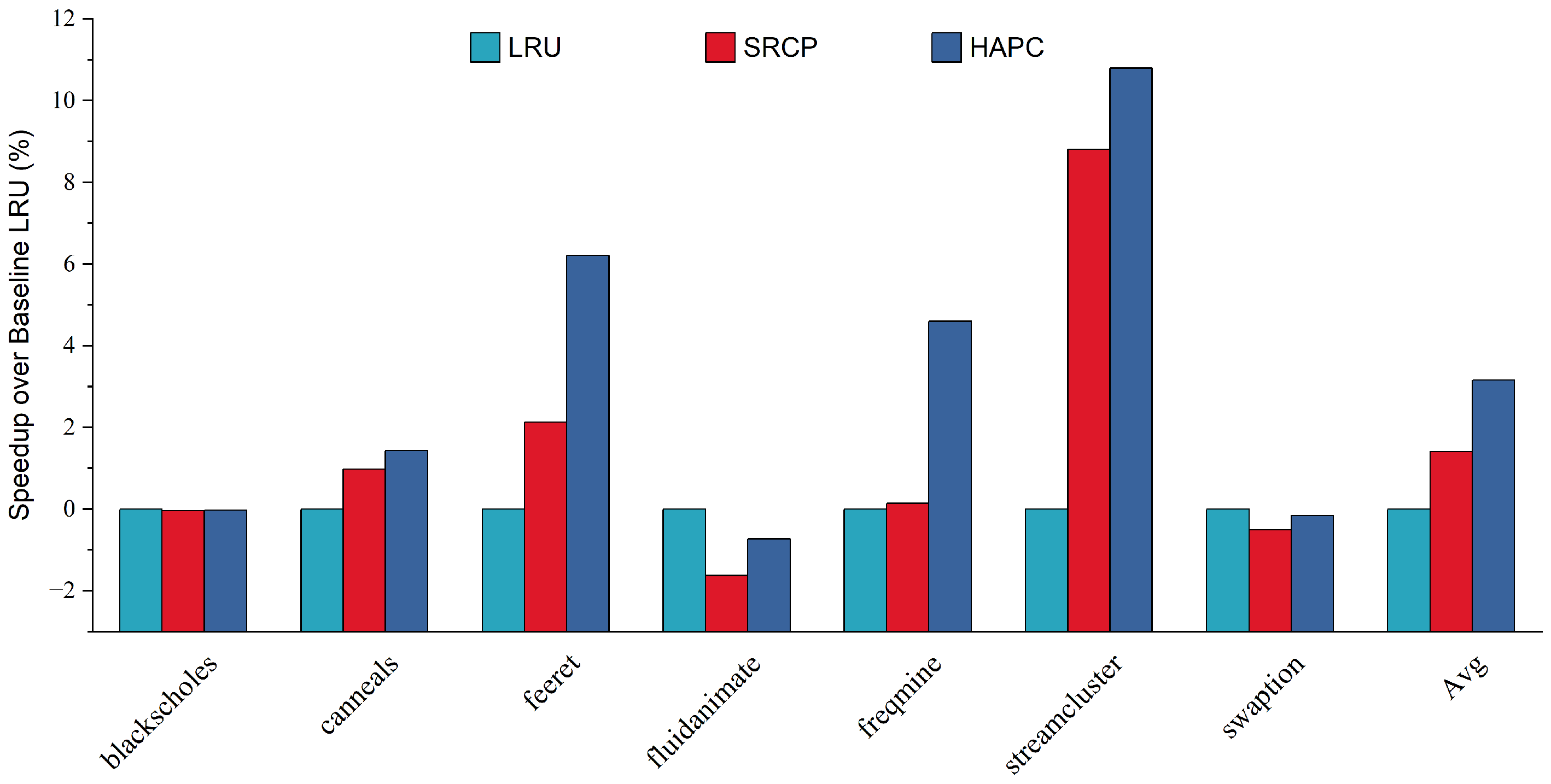
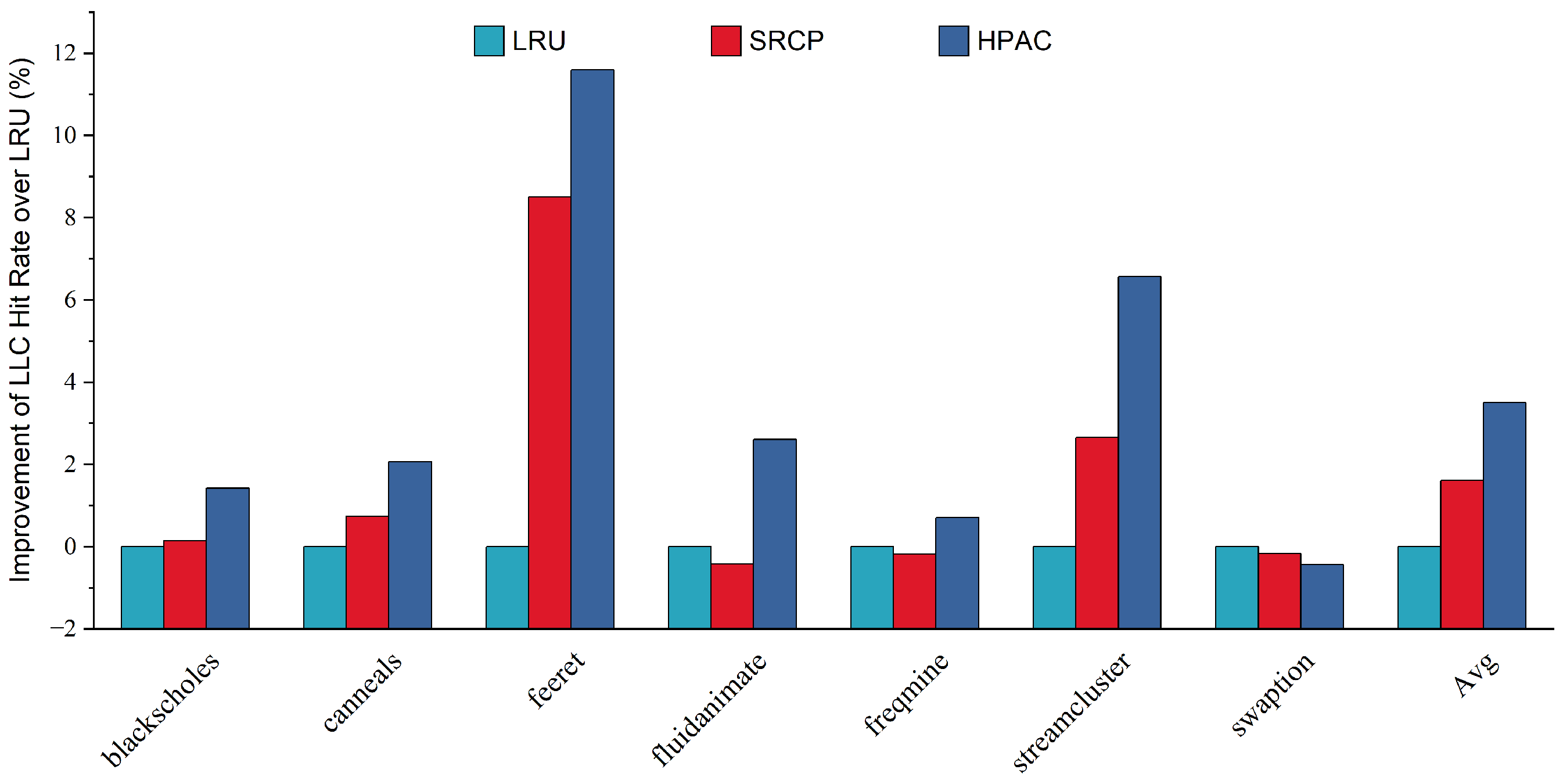
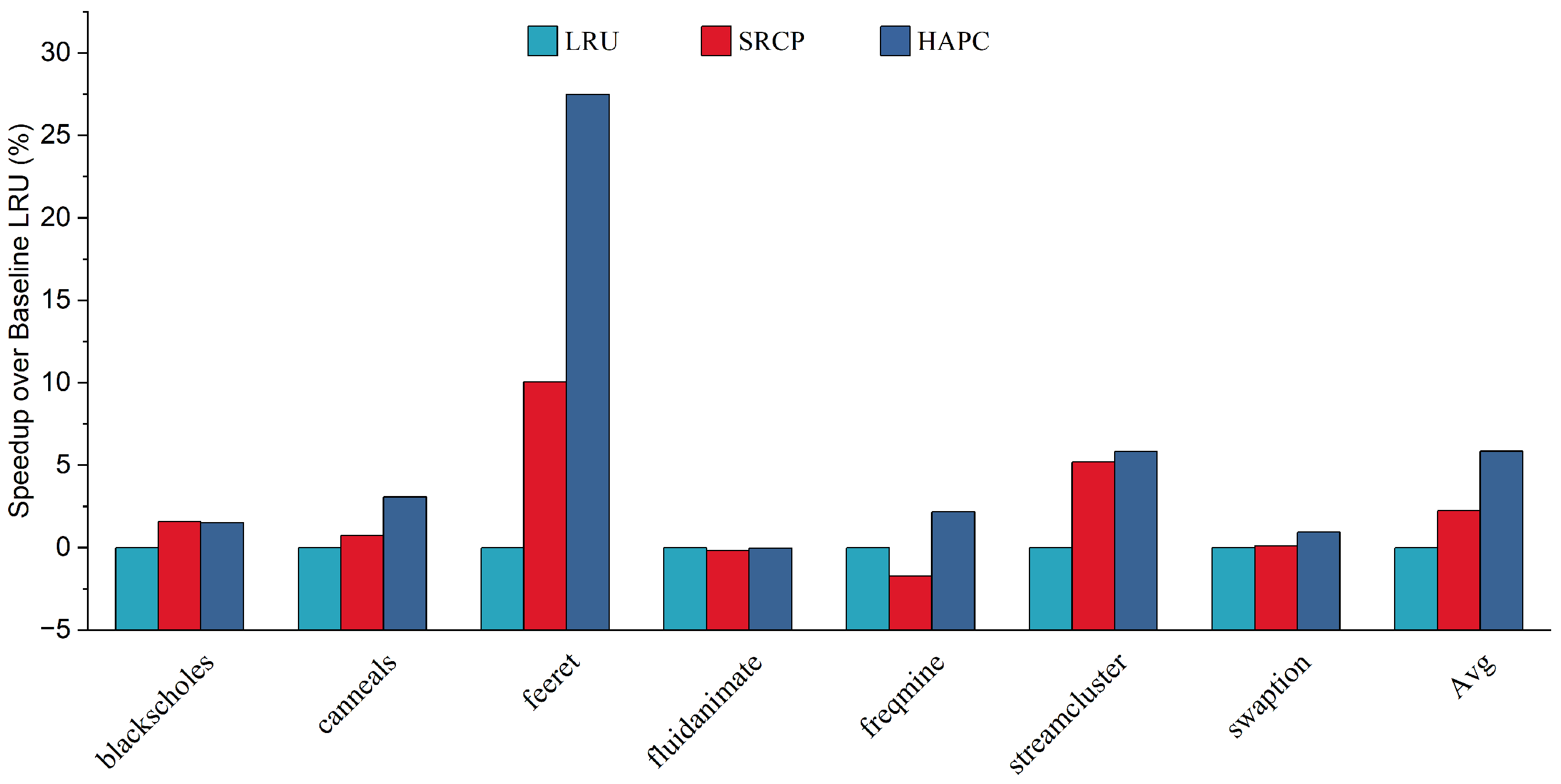
- Finally, we evaluate HAPC in detail with PARSEC 3.0 using the gem5 simulator. On average, HAPC improves the performance of big cores by 4.57% and 2.44% over LRU and SRCP, respectively. HPAC can provide effective performance improvement relative to the traditional replacement policies in various workloads and system configurations.
2. Related Work
2.1. Asymmetric Multi-Core Architecture
2.2. Shared Last-Level Cache Management Policies
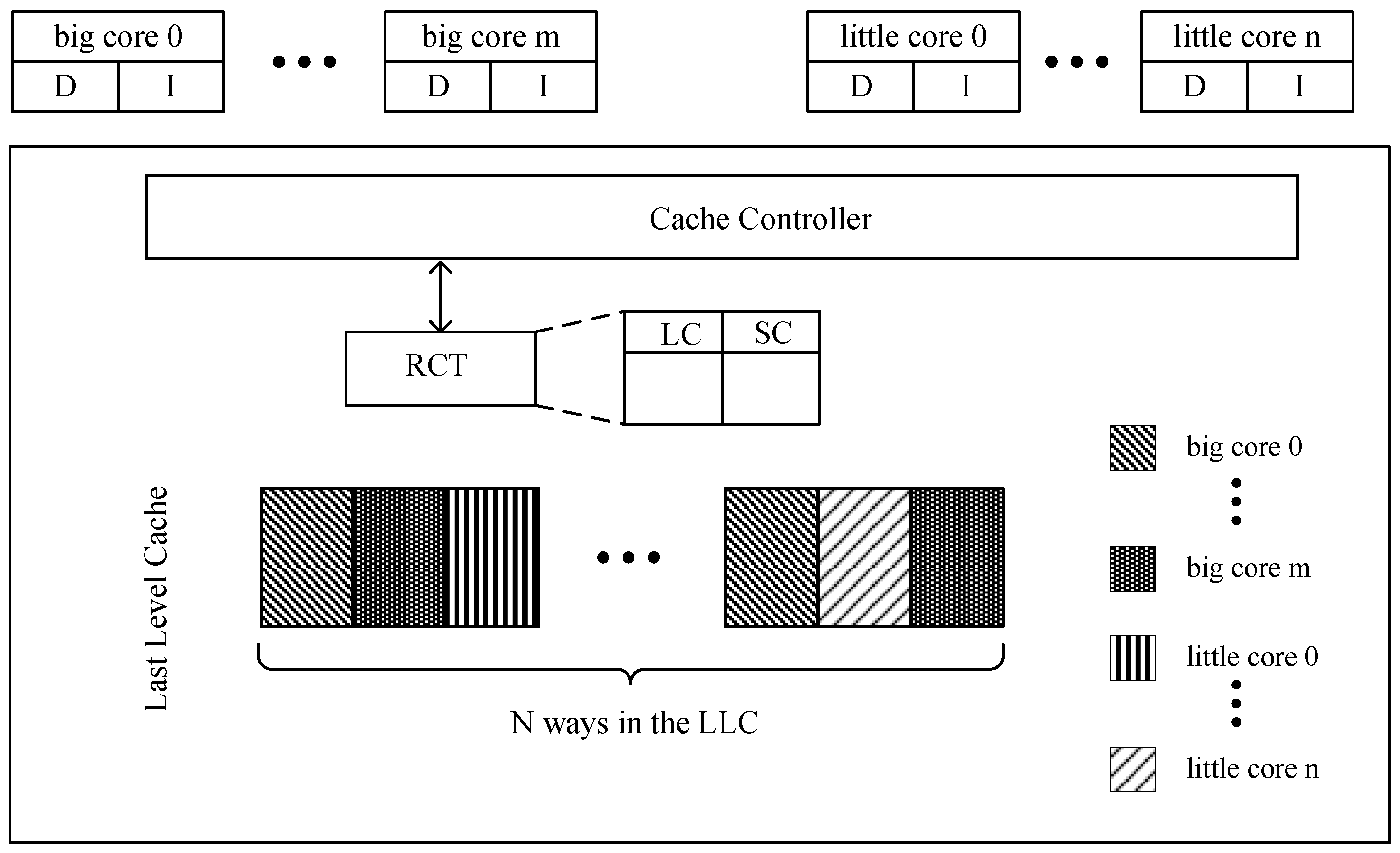
3. Heterogeneity-Aware Replacement Policy for the Partitioned Cache
3.1. Data Reuse for Multithreaded Programs
- LC (local count): LC is used to record the reuse count caused by the local core fetch request hitting the cache block.
- SC (share count): SC is used to record the reuse count caused by the shared core memory fetch request hitting the cache block.
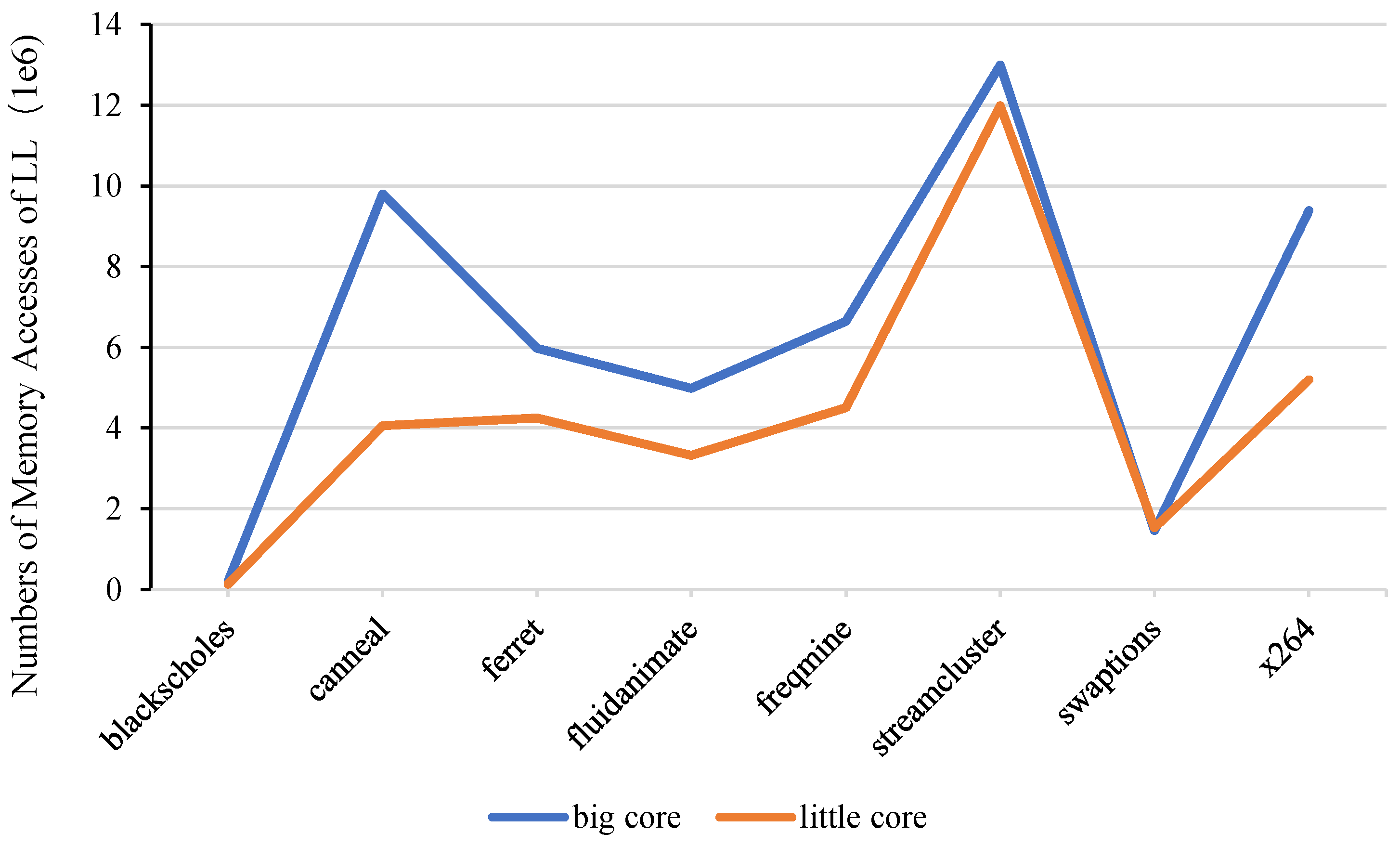
3.2. Memory Access Disturbance in Asymmetric Multi-Core Processor
3.3. Heterogeneous-Aware Partition Cache Replacement Policy
| Algorithm 1: RCT update. | |
| Input: The memory request issued by the core Req; Mapping of LLC ways and divided cores (Map[x] = c represents that the Xth way of LLC is divided to the core c); RCT table, representing reuse information for each cache line; Reuse weights for different cores (weight_big, weight_little). | |
| Output: Updated RCT table | |
| 1 | if Req hits cache line then |
| 2 | if core ∈ big cores then |
| 3 | LC = LC + weight_big; |
| 4 | SC = SC + weight_big; |
| 5 | end |
| 6 | if core ∈ big cores then |
| 7 | LC = LC + weight_little; |
| 8 | SC = SC + weight_little; |
| 9 | end |
| 10 | end |
| 11 | if Req cache misses then |
| /* Select the eviction block in the cache partition and execute | |
| the replacement policy */ | |
| 12 | for cache line ∈ core do |
| 13 | victim = LRU(min(LC) and min(SC)); |
| 14 | end |
| /* Insert new data into the cache line and update the | |
| corresponding RCT table */ | |
| 15 | for cache line ∈ core do |
| 16 | LC = average(LC ∈ core); |
| 17 | SC = 0; |
| 18 | end |
| /* Update other cache blocks in the cache partition */ | |
| 19 | for cache line ∈ core do |
| 20 | LC = LC − 1; |
| 21 | SC = SC − 1; |
| 22 | end |
| 23 | end |
- (1)
- Set weight_big and weight_little to 1.
- (2)
- Calculate the hit rate of the big cores in this interval, and increase the weight_big of the next interval by 1 until the weight_big increases to the threshold (the number of big cores).
- (3)
- Calculate the hit rate of the big core in the next interval and compare it with the hit rate of this interval. If the hit rate increases, go to (2); otherwise, go to (1).
4. Experiments
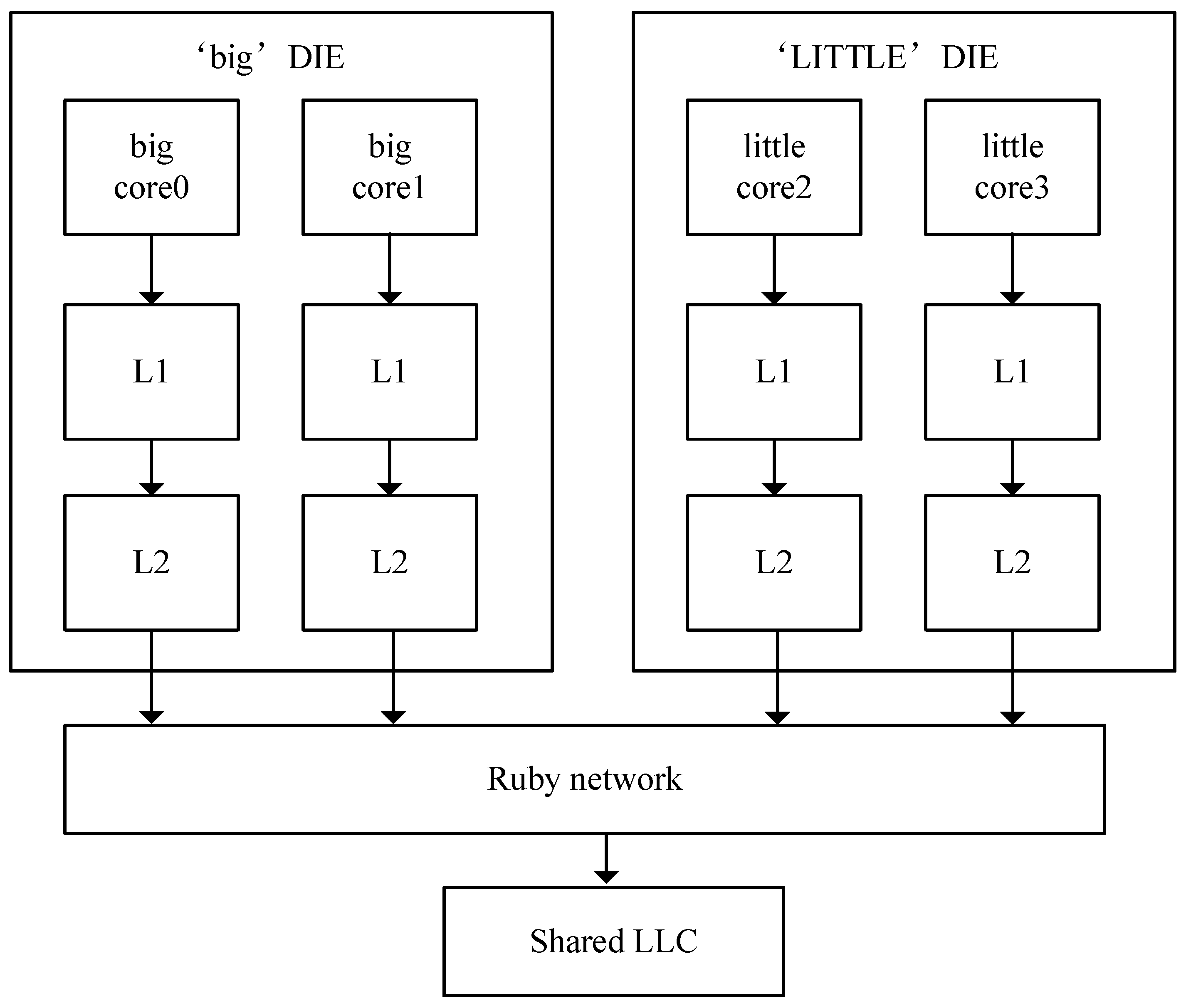
4.1. Experimental Setup
4.2. Results
5. Discussion
5.1. Effect of HAPC on the Parsec Sim_Medium Program
5.2. Overheads of HAPC
5.3. Varying Number of Cores
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Leiserson, C.E.; Thompson, N.C.; Emer, J.S.; Kuszmaul, B.C.; Lampson, B.W.; Sanchez, D.; Schardl, T.B. There’s plenty of room at the Top: What will drive computer performance after Moore’s law? Science 2020, 368, eaam9744. [Google Scholar] [CrossRef] [PubMed]
- Kim, C.; Huh, J. Fairness-Oriented OS Scheduling Support for Multi-core Systems. In Proceedings of the 2016 International Conference on Supercomputing, Istanbul, Turkey, 1–3 June 2016; Association for Computing Machinery: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Mittal, S. A Survey of Techniques for Architecting and Managing Asymmetric Multi-core Processors. ACM Comput. Surv. 2016, 48, 1–38. [Google Scholar] [CrossRef]
- Souza, J.D.; Becker, P.H.E.; Beck, A.C.S. Improving multitask performance and energy consumption with partial-ISA multi-cores. J. Parallel Distrib. Comput. 2021, 153, 1–14. [Google Scholar] [CrossRef]
- Karaoui, M.L.; Carno, A.; Lyerly, R.; Kim, S.H.; Olivier, P.; Min, C.; Ravindran, B. POSTER: Scheduling HPCWorkloads on Heterogeneous-ISA Architectures. In Proceedings of the 24th Symposium on Principles and Practice of Parallel Programming, New York, NY, USA, 16–20 February 2019. [Google Scholar] [CrossRef]
- Saez, J.C.; Pousa, A.; Giusti, A.D.; Prieto, M. On the Interplay Between Throughput, Fairness and Energy Efficiency on Asymmetric Multi-core Processors. Comput. J. 2018, 61, 74–94. [Google Scholar] [CrossRef]
- Saez, J.C.; Pousa, A.; Castro, F.; Chaver, D.; Prieto-Matias, M. Towards completely fair scheduling on asymmetric single-ISA multi-core processors. J. Parallel Distrib. Comput. 2017, 102, 115–131. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Saez, J.C.; Prieto-Matias, M. Contention-aware fair scheduling for asymmetric single-ISA multi-core systems. IEEE Trans. Comput. 2018, 67, 1703–1719. [Google Scholar] [CrossRef]
- Choudhury, A.M.; Nur, K. Qalitative Study of Contention-aware Scheduling Algorithm for Asymmetric Multi-core Processors. In Proceedings of the International Conference on Computing Advancements, Dhaka, Bangladesh, 10–12 January 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Del Sozzo, E.; Durelli, G.C.; Trainiti, E.; Miele, A.; Santambrogio, M.D.; Bolchini, C. Workload-aware power optimization strategy for asymmetric multiprocessors. In Proceedings of the 2016 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 531–534. [Google Scholar]
- Srinivasan, S.; Kurella, N.; Koren, I.; Kundu, S. Exploring heterogeneity within a core for improved power efficiency. IEEE Trans. Parallel Distrib. Syst. 2015, 27, 1057–1069. [Google Scholar] [CrossRef]
- Forbes, E.; Rotenberg, E. Fast register consolidation and migration for heterogeneous multi-core processors. In Proceedings of the 2016 IEEE 34th International Conference on Computer Design (ICCD), Scottsdale, AZ, USA, 2–5 October 2016; pp. 1–8. [Google Scholar]
- Padmanabha, S.; Lukefahr, A.; Das, R.; Mahlke, S.A. DynaMOS: Dynamic schedule migration for heterogeneous cores. In Proceedings of the 2015 48th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Waikiki, HI, USA, 5–9 December 2015; pp. 322–333. [Google Scholar]
- Selfa, V.; Sahuquillo, J.; Petit, S.; Gomez, M.E. A hardware approach to fairly balance the inter-thread interference in shared caches. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 3021–3032. [Google Scholar] [CrossRef] [Green Version]
- Sun, G.; Shen, J.; Veidenbaum, A.V. Combining prefetch control and cache partitioning to improve multi-core performance. In Proceedings of the 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Rio de Janeiro, Brazil, 20–24 May 2019; pp. 953–962. [Google Scholar] [CrossRef]
- Yu, T.; Zhong, R.; Janjic, V.; Petoumenos, P.; Zhai, J.; Leather, H.; Thomson, J. Collaborative heterogeneity-aware OS scheduler for asymmetric multi-core processors. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1224–1237. [Google Scholar] [CrossRef]
- Zhao, S.; Hao, C.; Jian, Z.; Li, M. Energy-Efficient Phase-Aware Load Balancing on Asymmetric Multi-core Processors. In Proceedings of the 2018 IEEE 4th International Conference on Computer and Communications (ICCC), Chengdu, China, 7–10 December 2018; pp. 2575–2579. [Google Scholar] [CrossRef]
- Greenhalgh, P. Big. LITTLE Processing with ARM Cortex-A15 & Cortex-A7: Improving Energy Efficiency in High-Performance Mobile Platforms; White Paper; ARM Ltd.: Cambridge, UK, 2011. [Google Scholar]
- Lee, C.; Ro, W.W. Simultaneous and Speculative Thread Migration for Improving Energy Efficiency of Heterogeneous Core Architectures. IEEE Trans. Comput. 2018, 67, 498–512. [Google Scholar] [CrossRef]
- Boran, N.K.; Rathore, S.; Udeshi, M.; Singh, V. Fine-Grained Scheduling in Heterogeneous-ISA Architectures. IEEE Comput. Archit. Lett. 2021, 20, 9–12. [Google Scholar] [CrossRef]
- Cho, S.; Chen, H.; Madaminov, S.; Ferdman, M.; Milder, P. Flick: Fast and Lightweight ISA-Crossing Call for Heterogeneous-ISA Environments. In Proceedings of the 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 30 May–3 June 2020; pp. 187–198. [Google Scholar] [CrossRef]
- Liu, G.; Park, J.; Marculescu, D. Dynamic thread mapping for high-performance, power-efficient heterogeneous many-core systems. In Proceedings of the 2013 IEEE 31st International Conference on Computer Design (ICCD), Asheville, NC, USA, 6–9 October 2013; pp. 54–61. [Google Scholar] [CrossRef]
- Jia, G.; Han, G.; Jiang, J.; Sun, N.; Wang, K. Dynamic Resource Partitioning for Heterogeneous Multi-Core-Based Cloud Computing in Smart Cities. IEEE Access 2016, 4, 108–118. [Google Scholar] [CrossRef]
- Qureshi, M.K.; Patt, Y.N. Utility-based cache partitioning: A low-overhead, high-performance, runtime mechanism to partition shared caches. In Proceedings of the 2006 39th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO’06), Orlando, FL, USA, 9–13 December 2006; pp. 423–432. [Google Scholar]
- Huang, K.; Wang, K.; Zhang, X.; Yan, X. Curve fitting based shared cache partitioning scheme for energy saving. IEICE Electron. Express 2018, 15, 20180886. [Google Scholar] [CrossRef]
- Pons, L.; Sahuquillo, J.; Selfa, V.; Petit, S.; Pons, J. Phase-Aware Cache Partitioning to Target Both Turnaround Time and System Performance. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 2556–2568. [Google Scholar] [CrossRef]
- Marinakis, T.; Anagnostopoulos, I. Performance and Fairness Improvement on CMPs Considering Bandwidth and Cache Utilization. IEEE Comput. Archit. Lett. 2019, 18, 1–4. [Google Scholar] [CrossRef]
- Xiong, W.; Katzenbeisser, S.; Szefer, J. Leaking Information Through Cache LRU States in Commercial Processors and Secure Caches. IEEE Trans. Comput. 2021, 70, 511–523. [Google Scholar] [CrossRef]
- Jain, A.; Lin, C. Back to the future: Leveraging Belady’s algorithm for improved cache replacement. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Republic of Korea, 18–22 June 2016; pp. 78–89. [Google Scholar] [CrossRef]
- Sanchez, D.; Kozyrakis, C. Scalable and efficient fine-grained cache partitioning with vantage. IEEE Micro 2012, 32, 26–37. [Google Scholar] [CrossRef]
- Ghosh, S.N.; Bhargava, L.; Sahula, V. SRCP: Sharing and reuse-aware replacement policy for the partitioned cache in multi-core systems. Des. Autom. Embed. Syst. 2021, 25, 193–211. [Google Scholar] [CrossRef]
- Kundan, S.; Anagnostopoulos, I. Priority-aware scheduling under shared-resource contention on chip multi-core processors. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Republic of Korea, 22–28 May 2021; pp. 1–5. [Google Scholar]
- Kundan, S.; Marinakis, T.; Anagnostopoulos, I.; Kagaris, D. A Pressure-Aware Policy for Contention Minimization on Multi-core Systems. ACM Trans. Archit. Code Optim. (TACO) 2022, 19, 1–26. [Google Scholar] [CrossRef]
- Jaleel, A.; Najaf-Abadi, H.H.; Subramaniam, S.; Steely, S.C.; Emer, J. Cruise: Cache replacement and utility-aware scheduling. In Proceedings of the Seventeenth International Conference on Architectural Support for Programming Languages and Operating Systems, London, UK, 3–7 March 2012; pp. 249–260. [Google Scholar]
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S.; et al. The gem5 simulator. ACM SIGARCH Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Zhan, X.; Bao, Y.; Bienia, C.; Li, K. PARSEC3.0: A multi-core benchmark suite with network stacks and SPLASH-2X. ACM SIGARCH Comput. Archit. News 2017, 44, 1–16. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Core | Big Core | Little Core |
|---|---|---|
| ISA | ARMv8 (64 bit) | ARMv8 (64 bit) |
| Frequency | 2.0 Hz | 1.4 Hz |
| Pipeline | Out-of-order | Out-of-order |
| Issue width | 6 | 4 |
| Fetch width | 16 | 4 |
| Pipeline stages | Big core | Little core |
| L1 cache (I & D) | 32 KB/2-way | 32 KB/2-way |
| L2 cache | 128 KB/2-way | 128 KB/2-way |
| LLC | 1 MB–8 MB/16-way | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, J.; Kong, H.; Yang, H.; Xu, Y.; Cai, M. A Heterogeneity-Aware Replacement Policy for the Partitioned Cache on Asymmetric Multi-Core Architectures. Micromachines 2022, 13, 2014. https://doi.org/10.3390/mi13112014
Fang J, Kong H, Yang H, Xu Y, Cai M. A Heterogeneity-Aware Replacement Policy for the Partitioned Cache on Asymmetric Multi-Core Architectures. Micromachines. 2022; 13(11):2014. https://doi.org/10.3390/mi13112014
Chicago/Turabian StyleFang, Juan, Han Kong, Huijing Yang, Yixiang Xu, and Min Cai. 2022. "A Heterogeneity-Aware Replacement Policy for the Partitioned Cache on Asymmetric Multi-Core Architectures" Micromachines 13, no. 11: 2014. https://doi.org/10.3390/mi13112014