
YOLOv4-Tiny-Based Coal Gangue Image Recognition and FPGA Implementation

Abstract
:1. Introduction
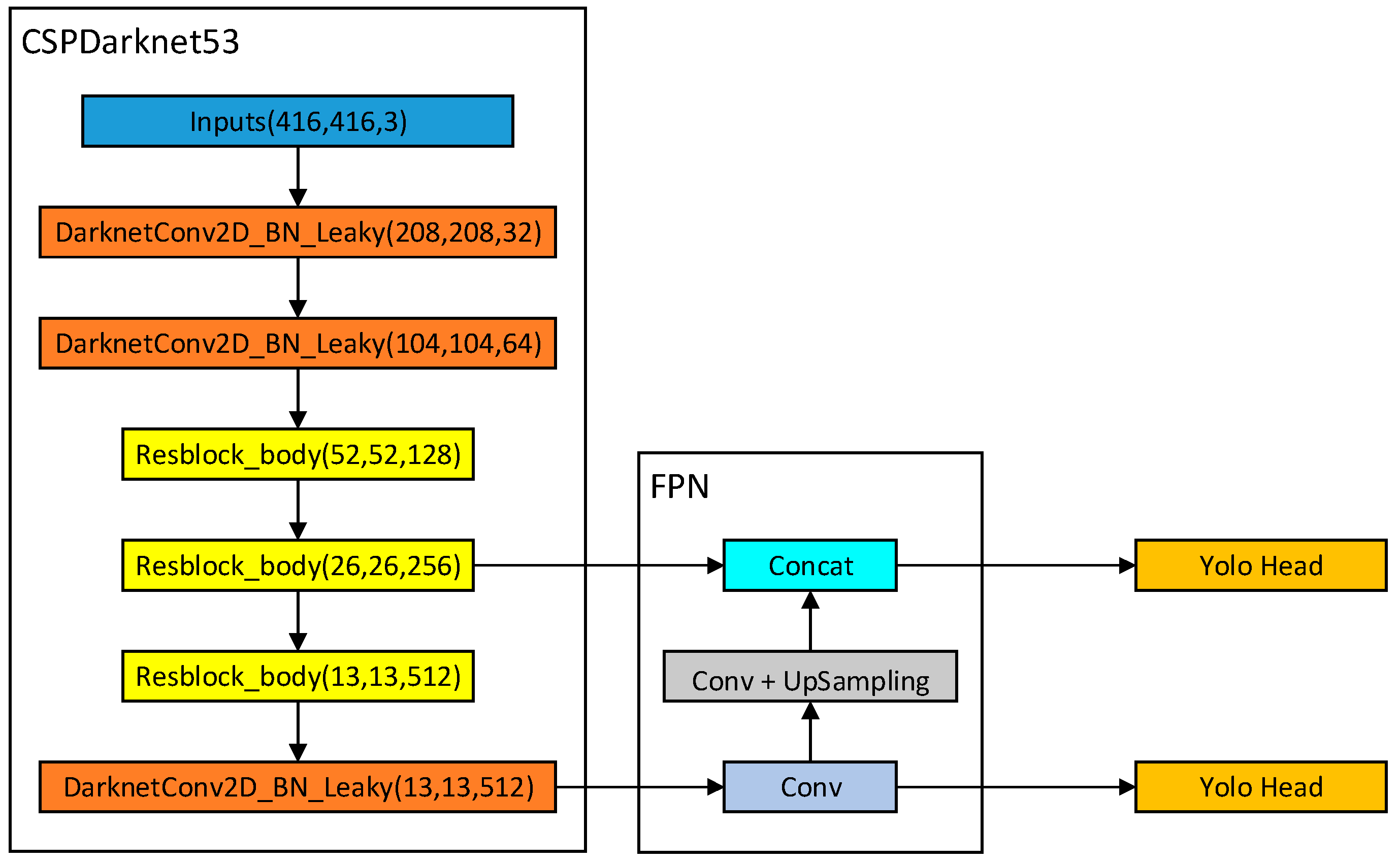
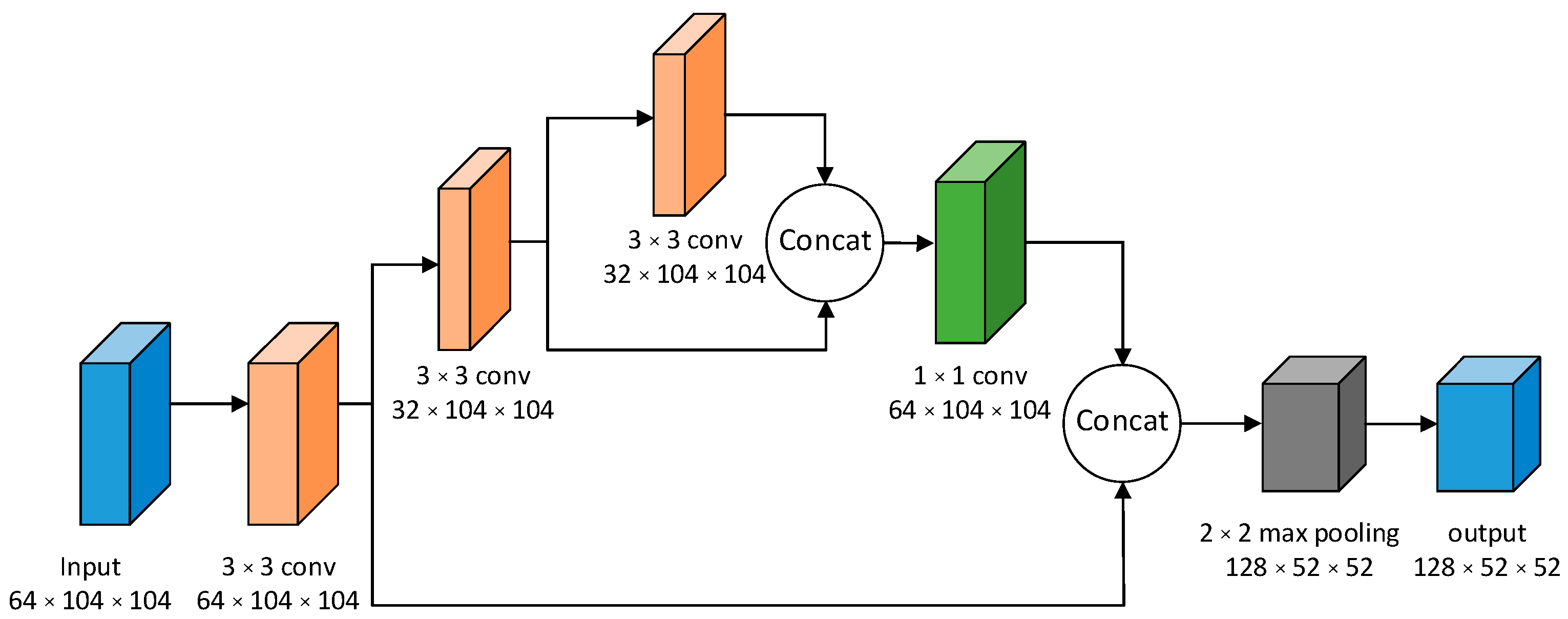
2. Principle of the YOLOv4-Tiny Algorithm
3. Optimization Method for Algorithm FPGA Implementation
3.1. Integration of the BN Layer and Convolution Layer
3.2. Sixteen-Bit Fixed-Point Quantization
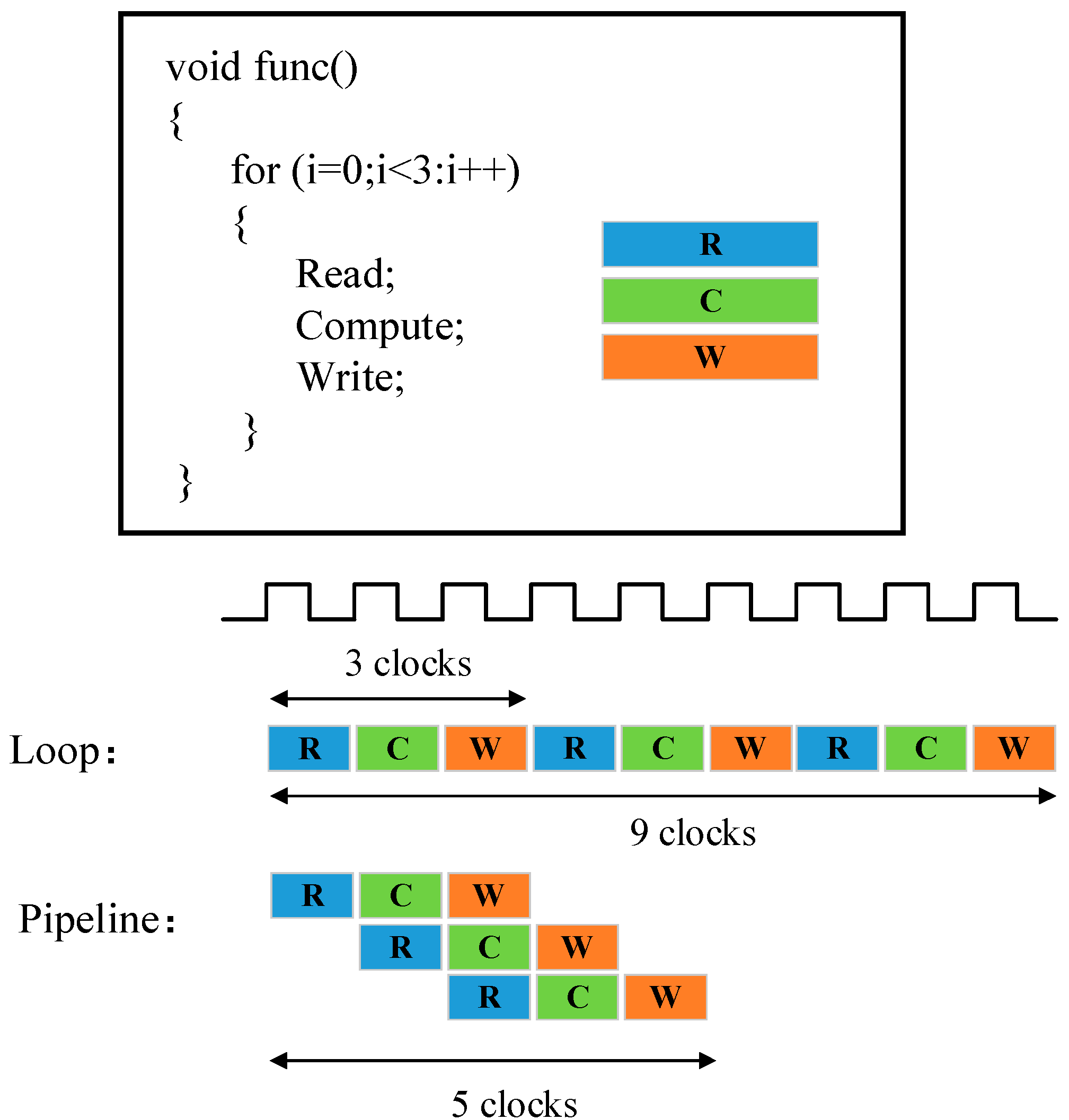
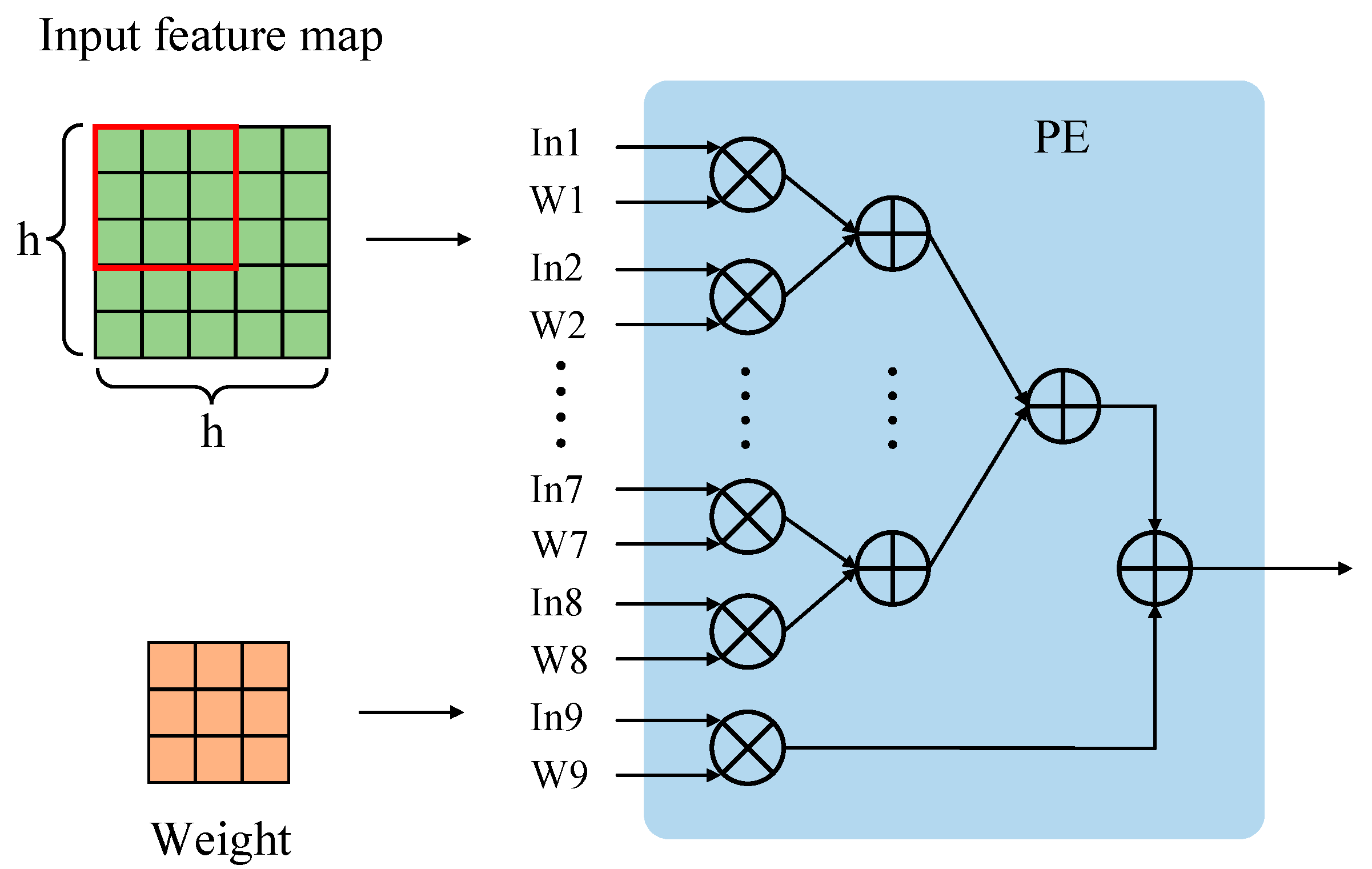
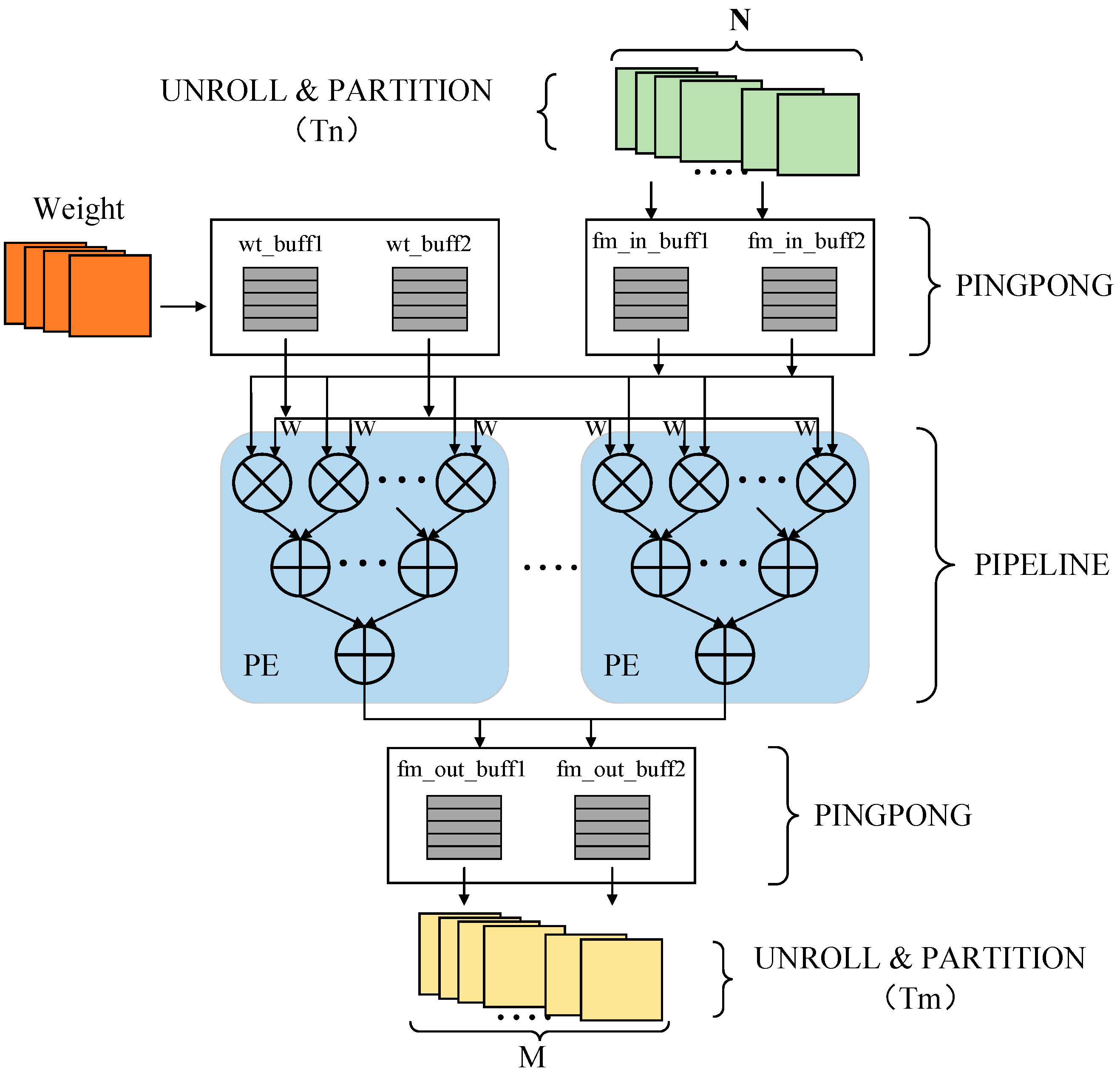
3.3. Pipeline Operation Optimization
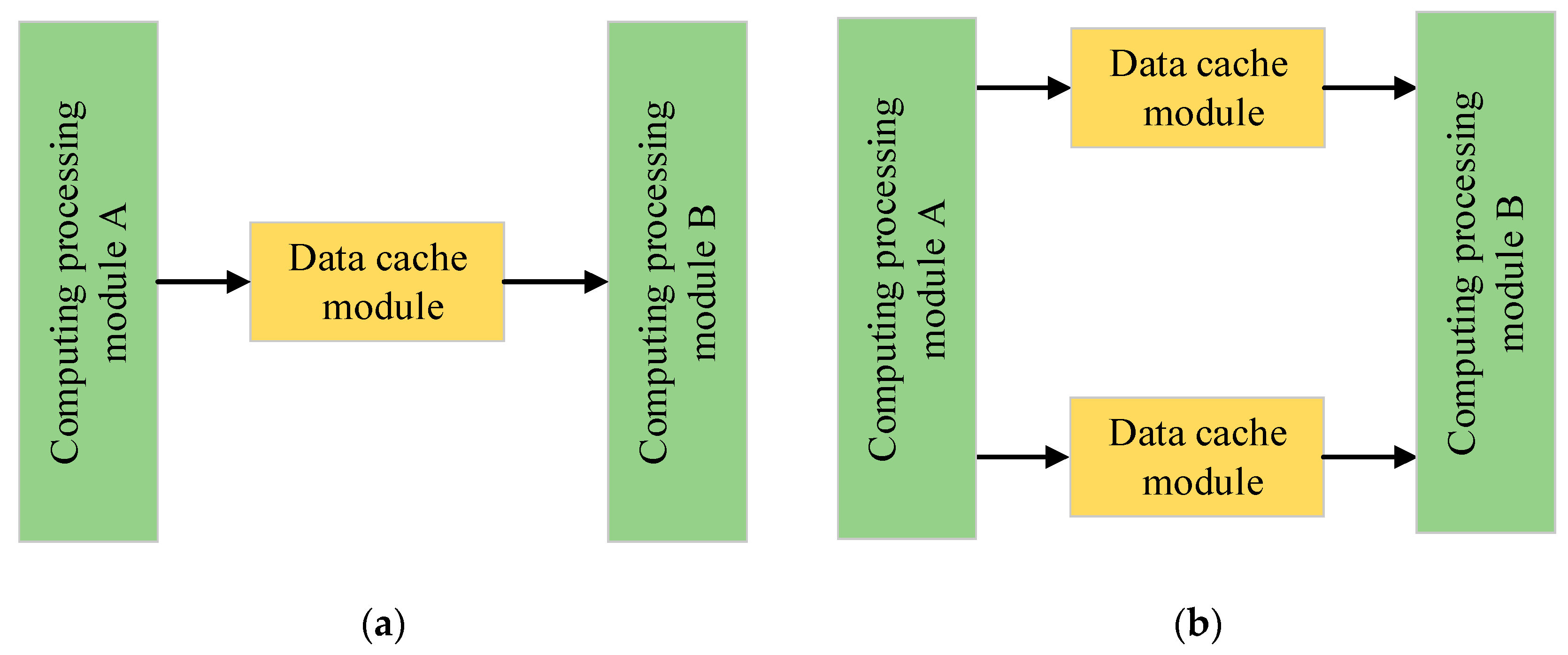
3.4. Ping-Pong Operation
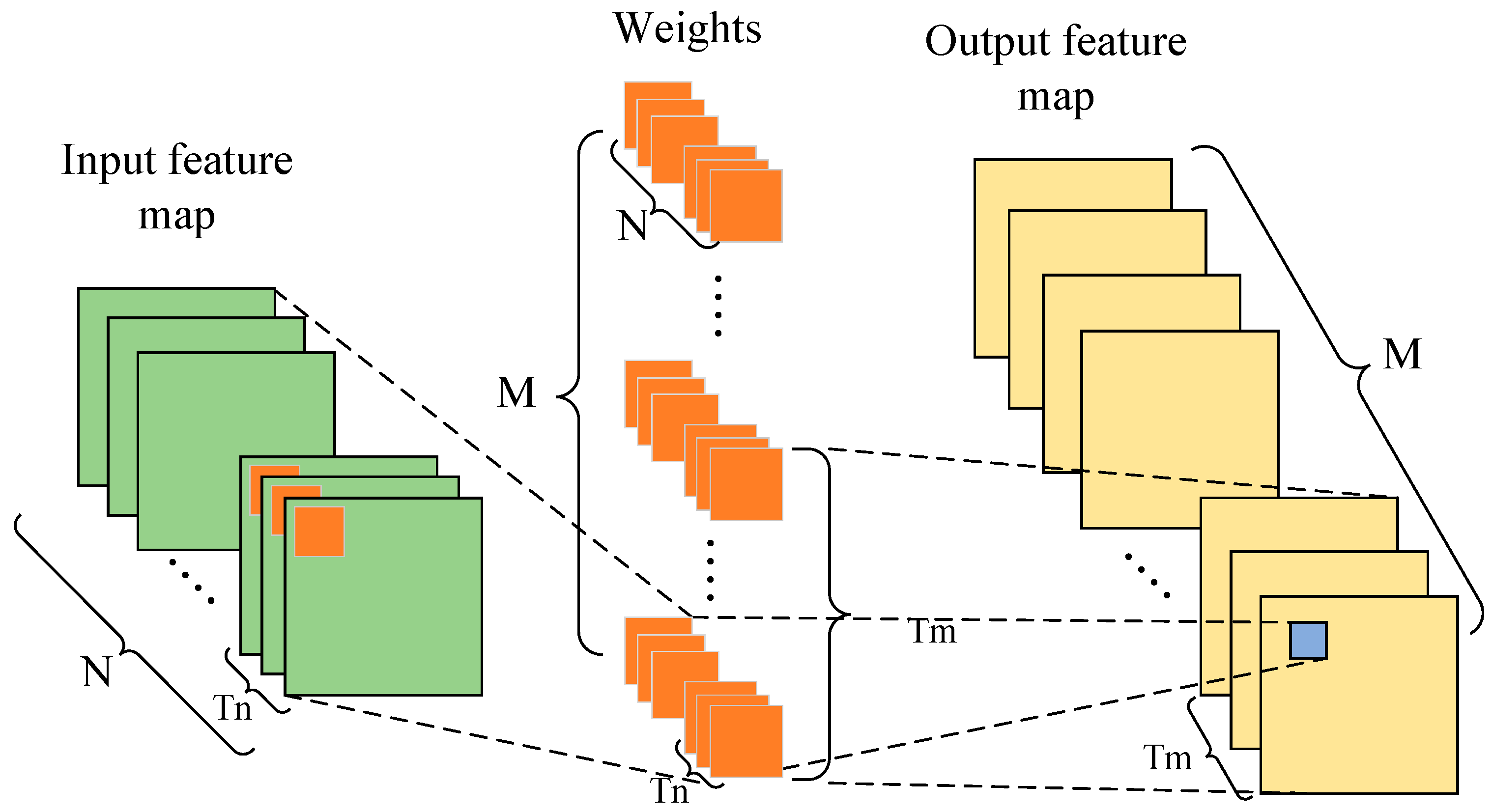
3.5. Parallelism of Input and Output Channels
4. FPGA Implementation of the YOLOv4-Tiny Algorithm
4.1. IP Kernel Design of the Algorithm Acceleration Module
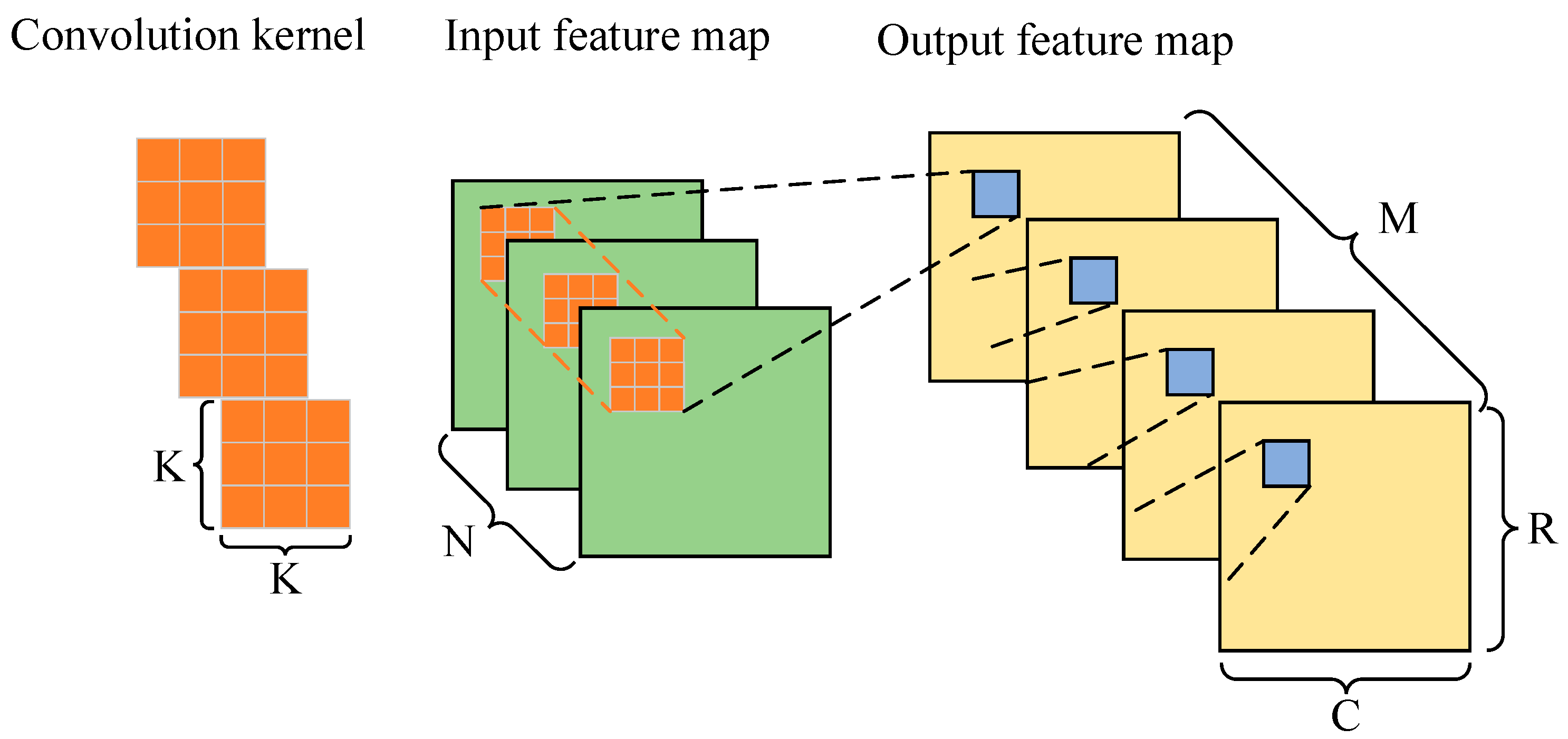
4.1.1. Design of Convolution IP kernel
| Algorithm 1. Computation of Convolution Layer |
| Input: fm_in_buff[n][S*r+kr][ S*c+kc] //Input feature map array |
| wt_buff[m][n][kr][kc] //Weight parameter array K, R, C, Tn, Tm //Size of convolution kernel; row and column of output feature map; unfolded input and output channel numbers Output: fm_out_buff[m][r][c] //Output feature map array Algorithm: #pragma HLS ARRAY_PARTITION variable=wt_buff complete dim=1 #pragma HLS ARRAY_PARTITION variable=wt_buff complete dim=2 #pragma HLS ARRAY_PARTITION variable=fm_out_buff complete dim=1 #pragma HLS ARRAY_PARTITION variable=fm_in_buff complete dim=1 for(kr=0; kr<K; kr++) //Periodically traverse the rows of convolution kernel for(kc=0; kc<K; kc++) //Periodically traverse the columns of convolution kernel for(r=0; r<R; r++) //Periodically traverse the rows of output feature map for(c=0; c<C; c++) //Periodically traverse the columns of output feature map #pragma HLS PIPELINE II=1 for(mm=0; m<Tm; m++) //Periodically traverse the rows of input feature map #pragma HLS UNROLL for(nn=0; n<Tn; n++) //Periodically traverse the columns of input feature map #pragma HLS UNROLL fm_out_buff[m][r][c]+=fm_in_buff[n][r*S+kr][c*S+kc]*wt_buff[m][n][kr][kc]; |
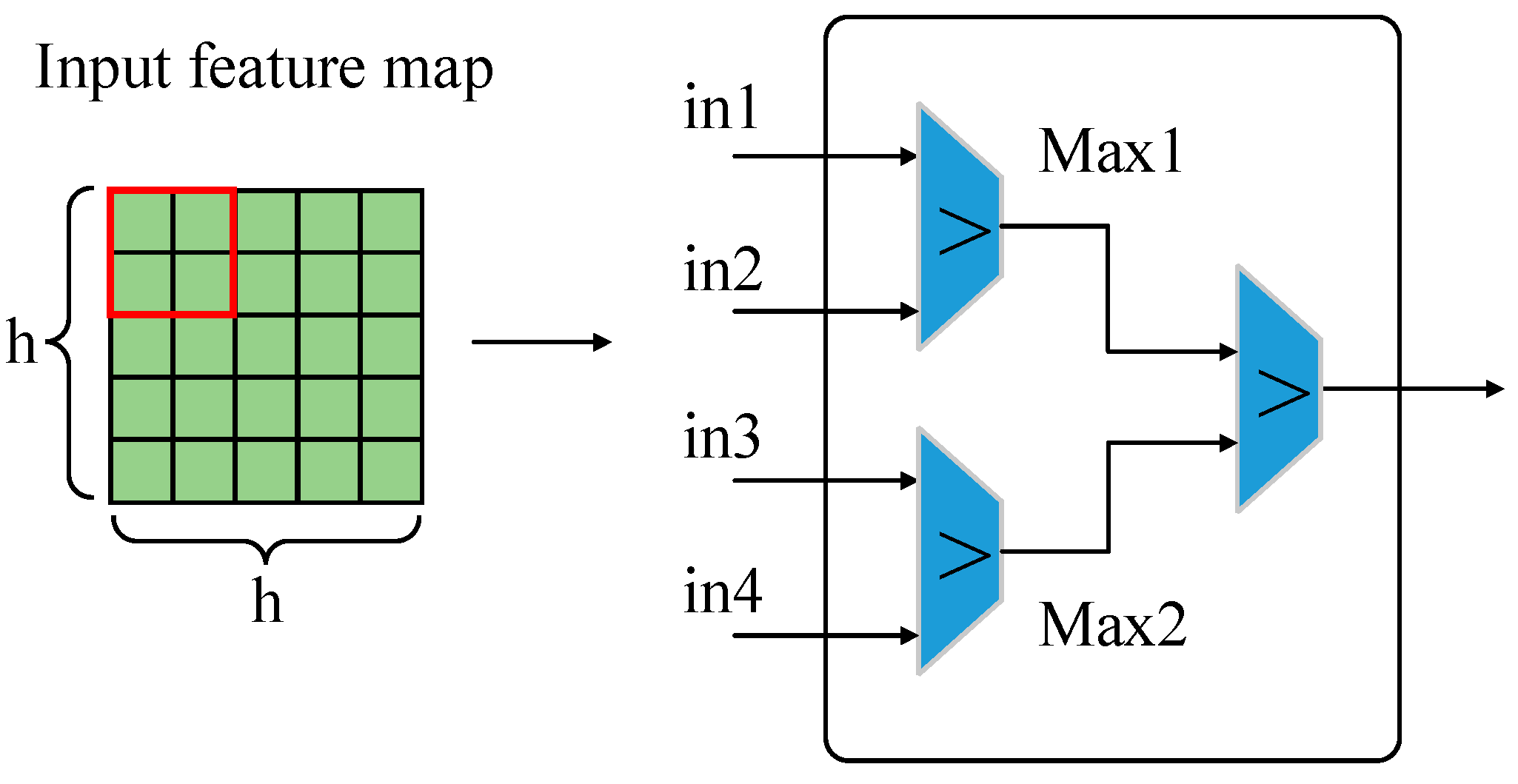
4.1.2. Design of Pooling IP kernel
| Algorithm 2. Pooling Layer Computation |
| Input: fm_in_buff[Tn][Tr*2][Tc*2] //Input feature map array Output: fm_out_buff[Tn][Tr][Tc] //Output feature map array Algorithm: for(unsigned short n=0;n<Tn;n++)//Periodically traverse channels of the input feature map for(unsigned short i=0;i<Tr;i++)// Periodically traverse rows of the input feature map for(unsigned short j=0;j<Tc;j++)// Periodically traverse columns of the input feature map #pragma HLS PIPELINE tmp1=fm_in_buff[n][i*2][j*2]; tmp2=fm_in_buff[n][i*2][j*2+1]; tmp3=fm_in_buff[n][i*2+1][j*2]; tmp4=fm_in_buff[n][i*2+1][j*2+1]; max1=(tmp1>tmp2)?tmp1:tmp2; max2=(tmp3>tmp4)?tmp3:tmp4; max=(max1>max2)?max1:max2; fm_out_buff[n][i][j]=max; |
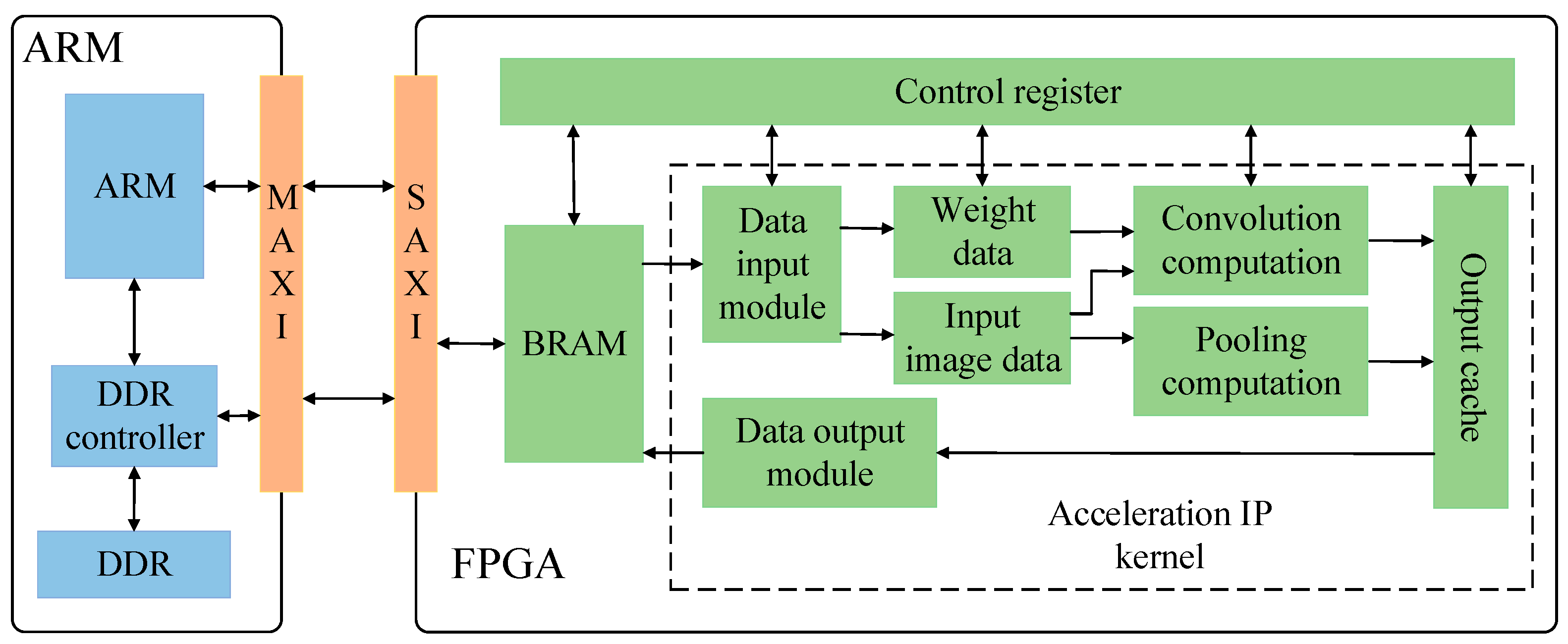
4.2. FPGA Hardware System Implementation of the YOLOv4-Tiny Algorithm
5. Experiments and Discussion
5.1. Experimental Environment
5.2. Computer Platform Experiment and Discussion
5.2.1. Coal Gangue Data Set
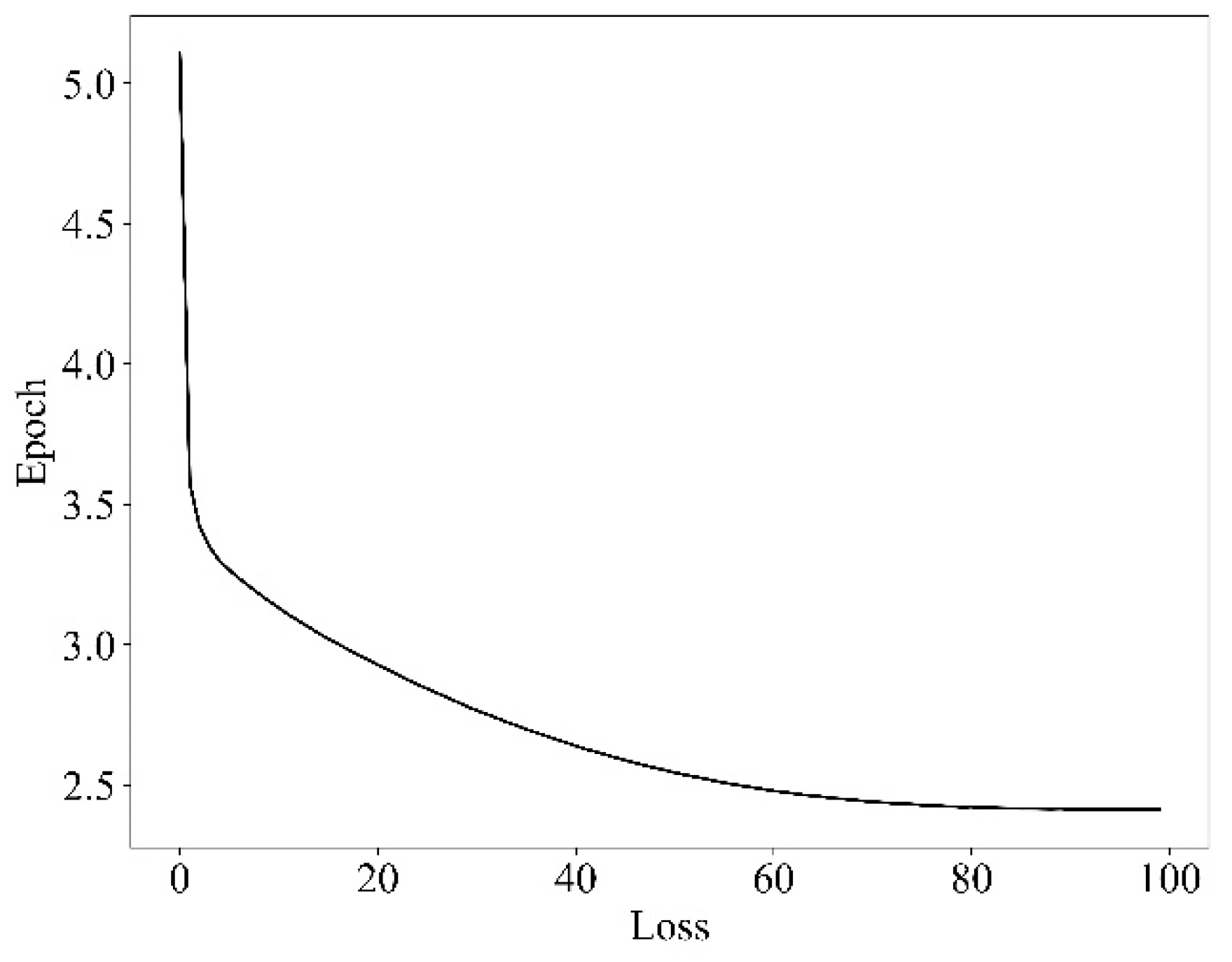
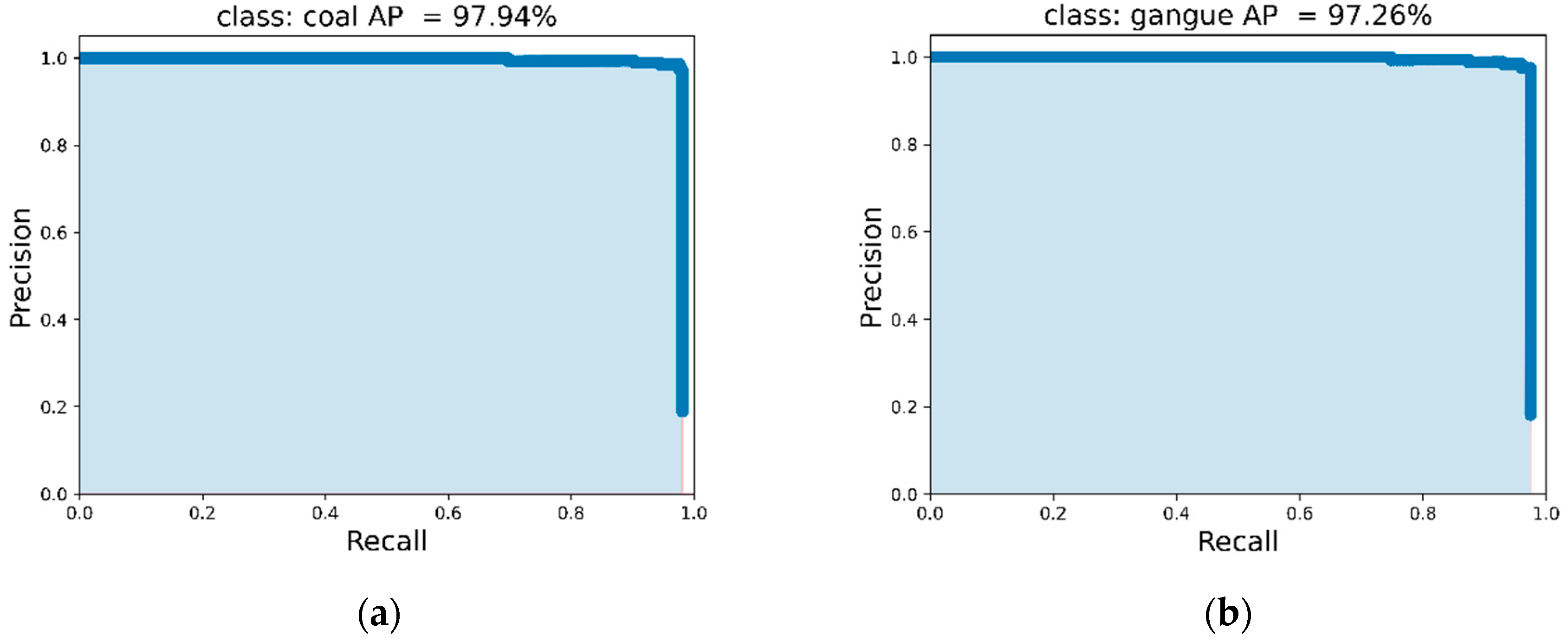
5.2.2. Algorithm Model Training and Results
5.3. FPGA Platform Experiment and Discussion
5.3.1. FPGA Resource Utilization
5.3.2. Power Consumption and Performance Analysis
6. Conclusions
- (1)
- In this paper, the integration of the BN layer and convolution layer, and 16-bit fixed-point quantization were performed to initially reduce the computational load of the YOLOv4-tiny model.
- (2)
- In the design of convolution and pooling IP kernels, pipeline and ping-pong operations were adopted to improve the computing speed of the system. In addition, this paper adopted parallel computation of the input and output channels to make full use of the FPGA resources, which accelerated the computation speed.
- (3)
- In the computer platform experiments, the mean average precision (mAP) of coal and gangue was 97.60%. Due to fixed-point quantization, the mAP value on the FPGA platform was 1.25% lower than that on the computer platform, and the recognition time of each image on the FPGA platform was 0.376 s, between that of CPU and GPU. However, the FPGA power consumption was only 2.86 W, much lower than that of CPU and GPU. Although GOPS of FPGA was lower than that of CPU and GPU, FPGA still showed the highest energy efficiency ratio due to its low power consumption, which was 10.42 and 3.47 times higher than that of CPU and GPU, respectively.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dong, Z.C.; Xia, J.W.; Duan, X.M.; Cao, J.C. Based on curing age of calcined coal gangue fine aggregate mortar of X-ray diffraction and scanning electron microscopy analysis. Spectrosc. Spectr. Anal. 2016, 36, 842–847. [Google Scholar]
- Robben, C.; De Korte, J.; Wotruba, H.; Robben, M. Experiences in Dry Coarse Coal Separation Using X-Ray-Transmission-Based Sorting. Int. J. Coal Prep. Util. 2014, 34, 210–219. [Google Scholar] [CrossRef]
- Yazdi, M.; Esmaeilnia, S. Dual-energy gamma-ray technique for quantitative measurement of coal ash in the Shahroud mine, Iran. Int. J. Coal Geol. 2003, 55, 151–156. [Google Scholar] [CrossRef]
- Yang, D.L.; Li, J.P.; Du, C.L.; Zheng, K.H.; Liu, S.Y. Particle size distribution of coal and gangue after impact-crush separation. J. Cent. South Univ. 2017, 24, 1252–1262. [Google Scholar] [CrossRef]
- Yang, D.; Li, J.; Zheng, K.; Du, C.; Liu, S. Impact-crush separation characteristics of coal and gangue. Int. J. Coal Prep. Util. 2018, 38, 127–134. [Google Scholar] [CrossRef]
- Zhou, J.; Liu, Y.; Du, C.; Wang, F. Experimental study on crushing characteristic of coal and gangue under impact load. Int. J. Coal Prep. Util. 2016, 36, 272–282. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, C. Separating coal and gangue using three-dimensional laser scanning. Int. J. Miner. Process. 2017, 169, 79–84. [Google Scholar] [CrossRef]
- Zhao, Y.D.; Hu, S.P. Research on coal and gangue identification method based on infrared thermal wave detection. In Applied Mechanics and Materials; Trans Tech Publications Ltd.: Stäfa, Switzerland, 2013; Volume 313, pp. 1285–1287. [Google Scholar]
- Sun, Z.; Lu, W.; Xuan, P.; Li, H.; Zhang, S.; Niu, S.; Jia, R. Separation of gangue from coal based on supplementary texture by morphology. Int. J. Coal Prep. Util. 2019, 42, 221–237. [Google Scholar] [CrossRef]
- Hobson, D.M.; Carter, R.M.; Yan, Y.; Lv, Z. Differentiation between Coal and Stone through Image Analysis of Texture Features. In Proceedings of the 2007 IEEE International Workshop on Imaging Systems and Techniques, Cracovia, Poland, 5 May 2007; pp. 1–4. [Google Scholar]
- Ma, X.-M. Coal Gangue Image Identification and Classification with Wavelet Transform. In Proceedings of the 2009 Second International Conference on Intelligent Computation Technology and Automation, Changsha, China, 10–11 October 2009; pp. 562–565. [Google Scholar] [CrossRef]
- Song, X.-R.; Wang, F.-J. Research on Coal Gangue On-Line Automatic Separation System Based on the Improved BP Algorithm and ARM. In Proceedings of the 2007 International Conference on Machine Learning and Cybernetics, Hong Kong, China, 19–22 August 2007; pp. 2897–2900. [Google Scholar] [CrossRef]
- Li, D.; Zhang, Z.; Xu, Z.; Xu Lili Meng, G.; Li Zhen Chen, S. An Image-Based Hierarchical Deep Learning Framework for Coal and Gangue Detection. IEEE Access 2019, 7, 184686–184699. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, H.-B. Coal Gangue Detection Method Based on Improved SSD Algorithm. In Proceedings of the 2021 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Xi’an, China, 27–28 March 2021; pp. 634–637. [Google Scholar] [CrossRef]
- Alfarzaeai, M.S.; Niu, Q.; Zhao, J.; Eshaq, R.M.A.; Hu, E. Coal/Gangue Recognition Using Convolutional Neural Networks and Thermal Images. IEEE Access 2020, 8, 76780–76789. [Google Scholar] [CrossRef]
- Eshaq, R.M.A.; Hu, E.; Qaid, H.A.A.M.; Zhang, Y.; Liu, T. Using Deep Convolutional Neural Networks and Infrared Thermography to Identify Coal Quality and Gangue. IEEE Access 2021, 9, 147315–147327. [Google Scholar] [CrossRef]
- Pan, H.; Shi, Y.; Lei, X.; Wang, Z.; Xin, F. Fast identification model for coal and gangue based on the improved tiny YOLOv3. J. Real-Time Image Process. 2022, 19, 687–701. [Google Scholar] [CrossRef]
- Gui, F.; Yu, S.; Zhang, H.; Zhu, H. Coal Gangue Recognition Algorithm Based on Improved YOLOv5. In Proceedings of the 2021 IEEE 2nd International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 17–19 December 2021; pp. 1136–1140. [Google Scholar] [CrossRef]
- Huang, H.; Liu, Z.; Chen, T.; Hu, X.; Zhang, Q.; Xiong, X. Design Space Exploration for YOLO Neural Network Accelerator. Electronics 2020, 9, 1921. [Google Scholar] [CrossRef]
- Kim, T.; Park, S.; Cho, Y. Study on the Implementation of a Simple and Effective Memory System for an AI Chip. Electronics 2021, 10, 1399. [Google Scholar] [CrossRef]
- Zhang, N.; Wei, X.; Chen, H.; Liu, W. FPGA Implementation for CNN-Based Optical Remote Sensing Object Detection. Electronics 2021, 10, 282. [Google Scholar] [CrossRef]
- Yu, Y.; Wu, C.; Zhao, T.; Wang, K.; He, L. OPU: An FPGA-Based Overlay Processor for Convolutional Neural Networks. In IEEE Transactions on Very Large Scale Integration (VLSI) Systems; IEEE: Piscataway, NJ, USA, 2020; Volume 28, pp. 35–47. [Google Scholar]
- Li, Z.; Wang, J. An improved algorithm for deep learning YOLO network based on Xilinx ZYNQ FPGA. In Proceedings of the 2020 International Conference on Culture-oriented Science & Technology (ICCST), Beijing, China, 28–31 October 2020; pp. 447–451. [Google Scholar] [CrossRef]
- Wei, G.; Hou, Y.; Cui, Q.; Deng, G.; Tao, X.; Yao, Y. YOLO Acceleration using FPGA Architecture. In Proceedings of the 2018 IEEE/CIC International Conference on Communications in China (ICCC), Beijing, China, 16–18 August 2018; pp. 734–735. [Google Scholar] [CrossRef]
- Yu, Z.; Bouganis, C.-S. A Parameterisable FPGA-Tailored Architecture for YOLOv3-Tiny. In International Symposium on Applied Reconfigurable Computing; Springer: Cham, Switzerland, 2020; pp. 330–344. [Google Scholar]
- Li, P.; Che, C. Mapping YOLOv4-Tiny on FPGA-Based DNN Accelerator by Using Dynamic Fixed-Point Method. In Proceedings of the 2021 12th International Symposium on Parallel Architectures, Algorithms and Programming (PAAP), Xi’an, China, 10–12 December 2021; pp. 125–129. [Google Scholar] [CrossRef]
- Chen, X.; An, Z.; Huang, L.; He, S.; Zhang, X.; Lin, S. Surface Defect Detection of Electric Power Equipment in Substation Based on Improved YOLOV4 Algorithm. In Proceedings of the 2020 10th International Conference on Power and Energy Systems (ICPES), Chengdu, China, 25–27 December 2020; pp. 256–261. [Google Scholar]
- Wang, L.; Zhou, K.; Chu, A.; Wang, G.; Wang, L. An Improved Light-Weight Traffic Sign Recognition Algorithm Based on YOLOv4-Tiny. IEEE Access 2021, 9, 124963–124971. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | Description |
|---|---|
| Windows10 | Operating system |
| Intel core i5-10200H | Processor CPU |
| NVIDIA GeForce RTX2060(6G) | Video card GPU |
| DDR4 16G | Memory |
| Python 3.7 | Python version |
| Tensorflow 2.4.0 | Deep learning frame |
| ZYNQ-7020 | FPGA platform |
| Resource | Utilization | Available | Utilization Rate % |
|---|---|---|---|
| LUT | 41,953 | 53,200 | 78.86 |
| LUTRAM | 7414 | 17,400 | 42.61 |
| FF | 47,652 | 106,400 | 44.79 |
| BRAM | 96 | 140 | 68.57 |
| DSP | 216 | 220 | 98.18 |
| BUFG | 1 | 32 | 3.13 |
| Experimental Platform | CPU | GPU | FPGA |
|---|---|---|---|
| Data precision | 32-bit | 32-bit | 16-bit |
| Computing time per image/s | 0.495 | 0.065 | 0.376 |
| Average precision mean (mAP) | 97.60% | 97.60% | 96.35% |
| GOPS | 14.04 | 106.92 | 9.24 |
| Power/w | 45 | 115 | 2.86 |
| Energy efficiency ratio (GOPs/w) | 0.31 | 0.93 | 3.23 |
| YOLO [24] | YOLOv3-Tiny [25] | YOLOv4-Tiny [26] | This Paper | |
|---|---|---|---|---|
| platform | ZYNQ Board | Zedboard | ZYNQ-7020 | ZYNQ-7020 |
| Latency/s | - | 0.532 | 18.025 | 0.376 |
| DSP/total | 409/900 | 160/220 | 149/220 | 216/220 |
| GOPS | - | 10.45 | - | 9.24 |
| Power/w | 7.518 | 3.36 | 2.384 | 2.86 |
| GOPs/w | - | 3.11 | - | 3.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, S.; Zhou, Y.; Huang, Y.; Han, T. YOLOv4-Tiny-Based Coal Gangue Image Recognition and FPGA Implementation. Micromachines 2022, 13, 1983. https://doi.org/10.3390/mi13111983
Xu S, Zhou Y, Huang Y, Han T. YOLOv4-Tiny-Based Coal Gangue Image Recognition and FPGA Implementation. Micromachines. 2022; 13(11):1983. https://doi.org/10.3390/mi13111983
Chicago/Turabian StyleXu, Shanyong, Yujie Zhou, Yourui Huang, and Tao Han. 2022. "YOLOv4-Tiny-Based Coal Gangue Image Recognition and FPGA Implementation" Micromachines 13, no. 11: 1983. https://doi.org/10.3390/mi13111983