
Dental Lesion Segmentation Using an Improved ICNet Network with Attention
 , ,
, ,
Abstract
:1. Introduction
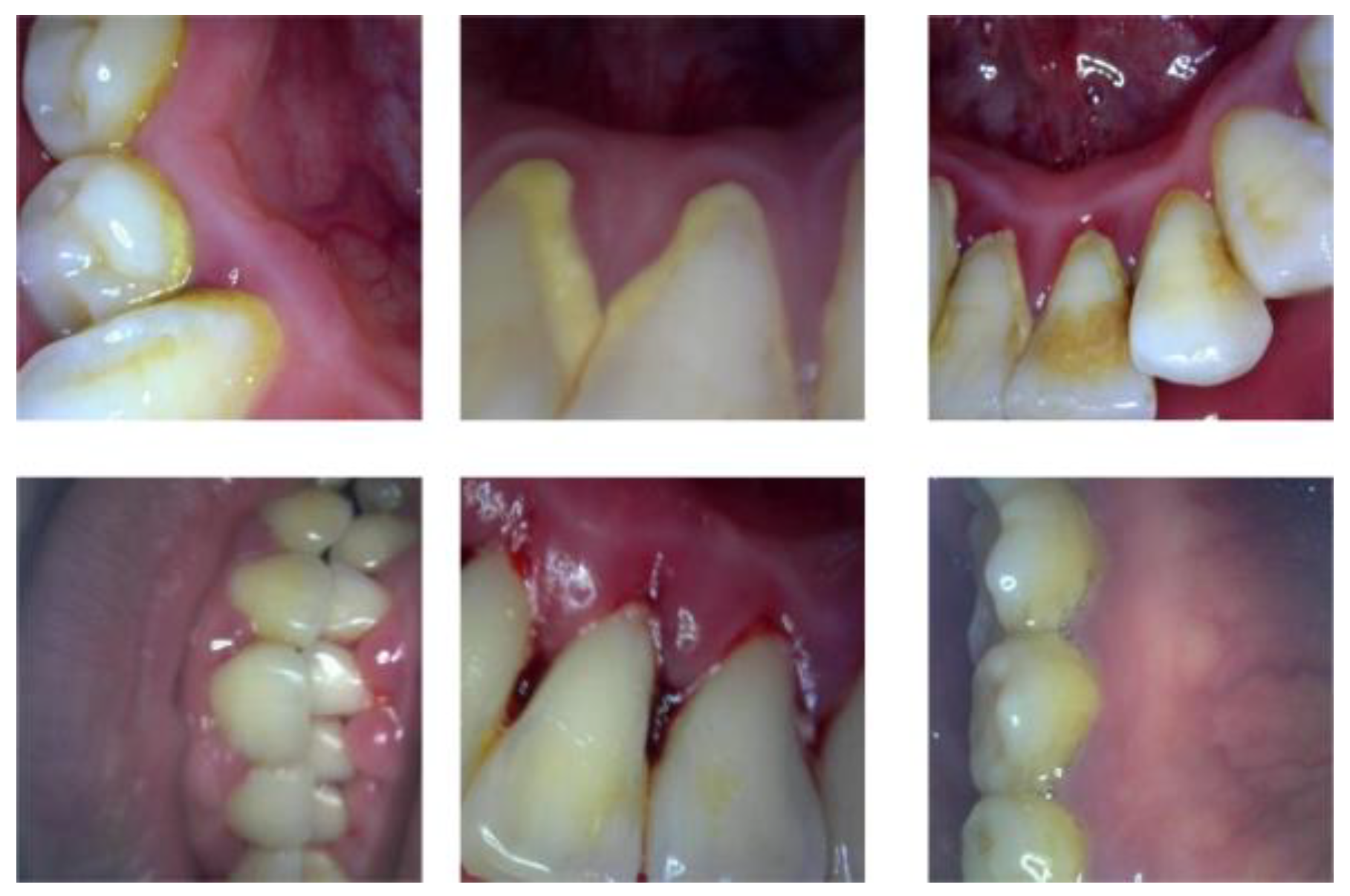
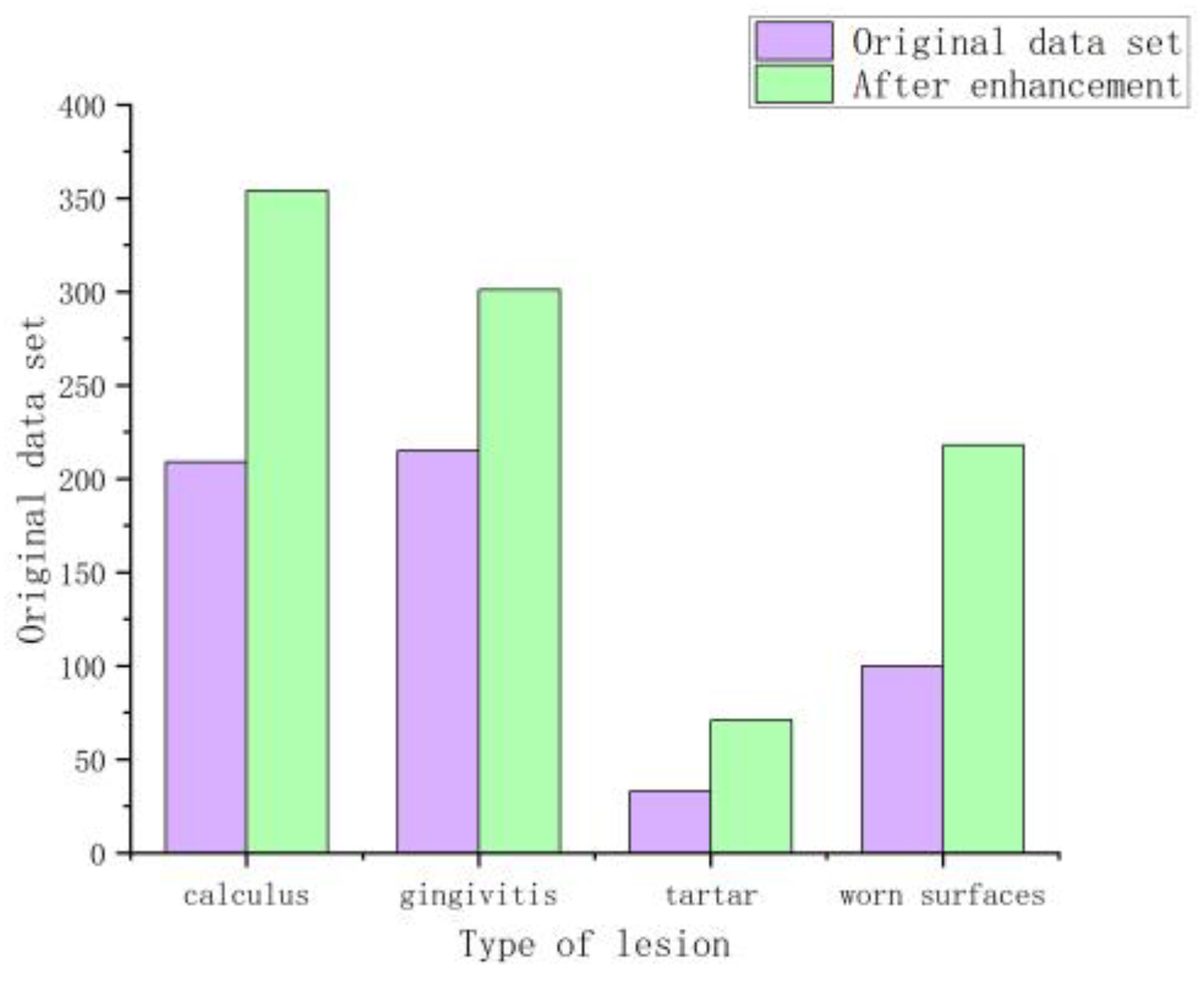
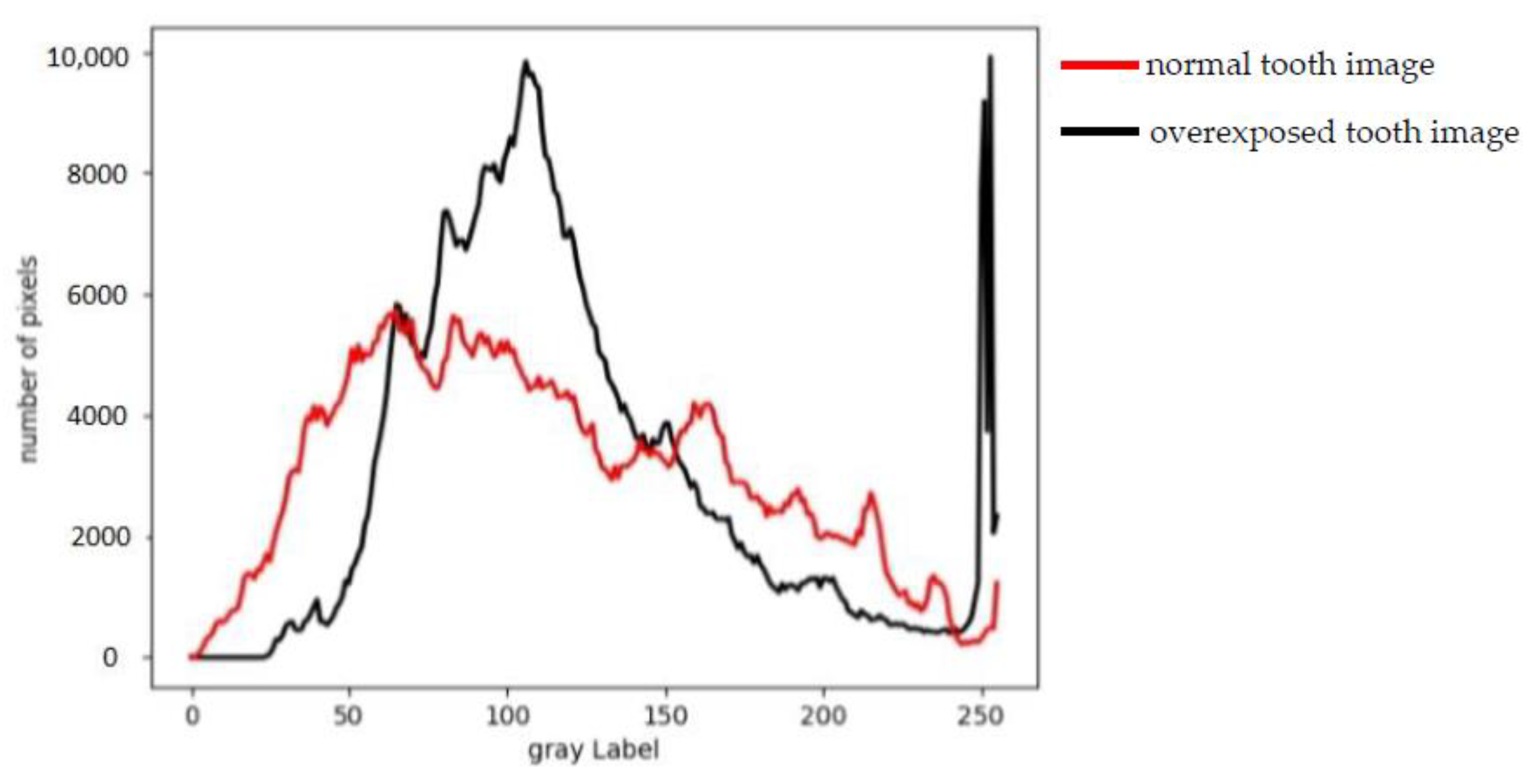
- The self-built dental lesion dataset included four types of lesions: calculus, gingivitis, tartar, and worn surfaces and was preprocessed with the ACE color equalization algorithm for overexposed images caused by light sources.
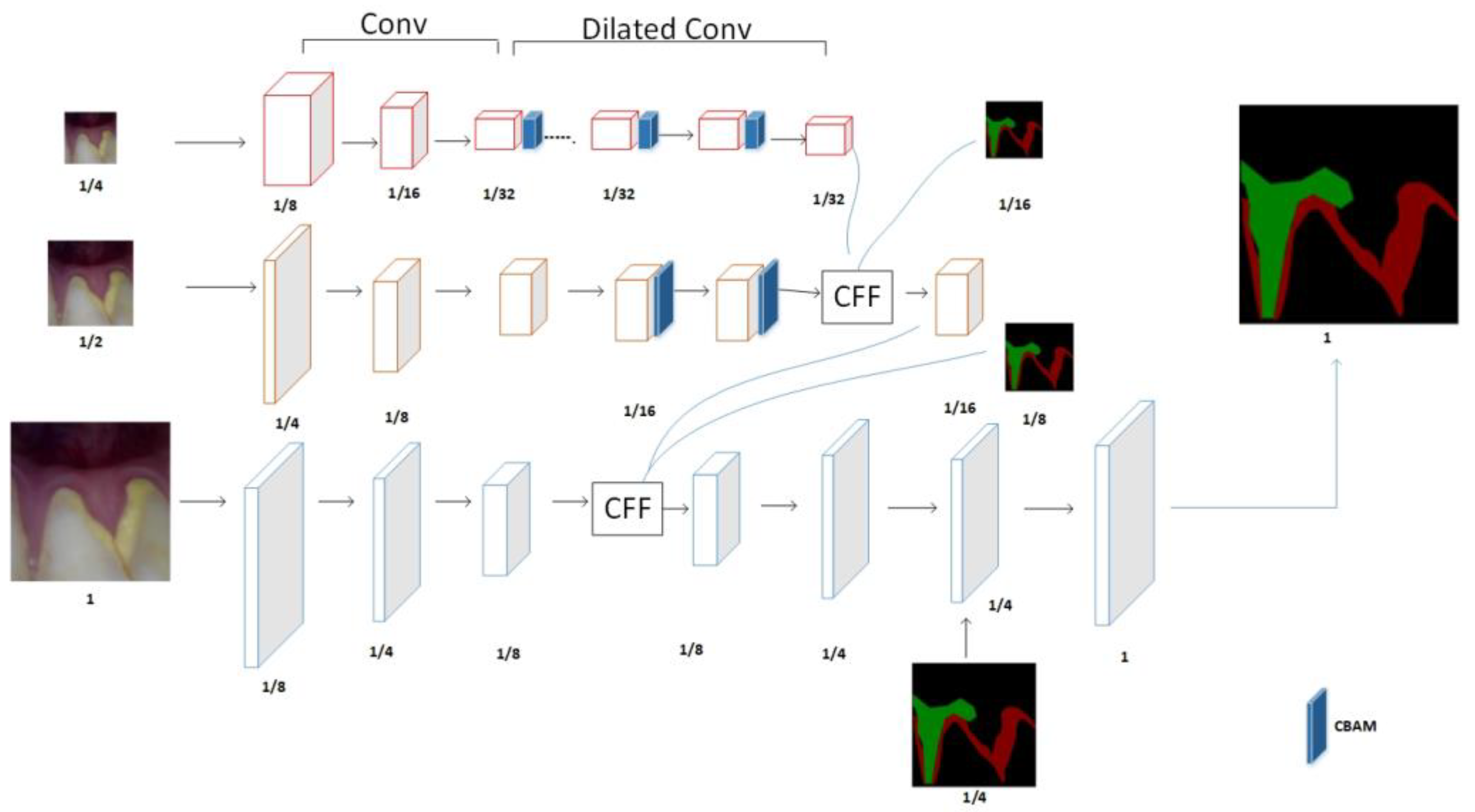
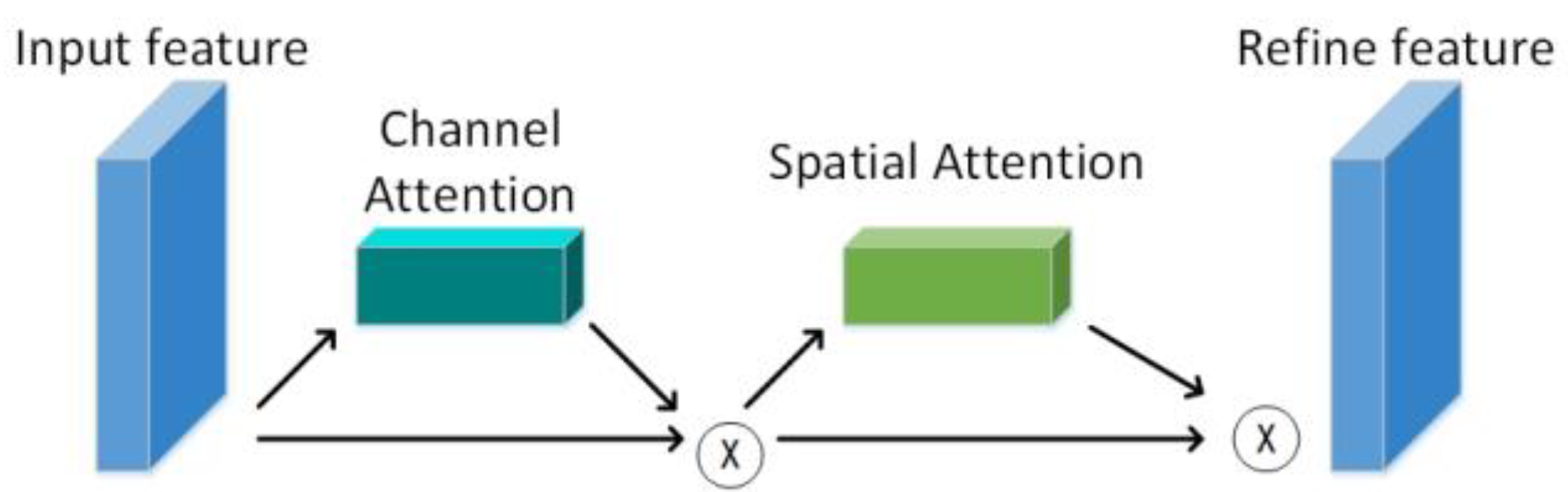
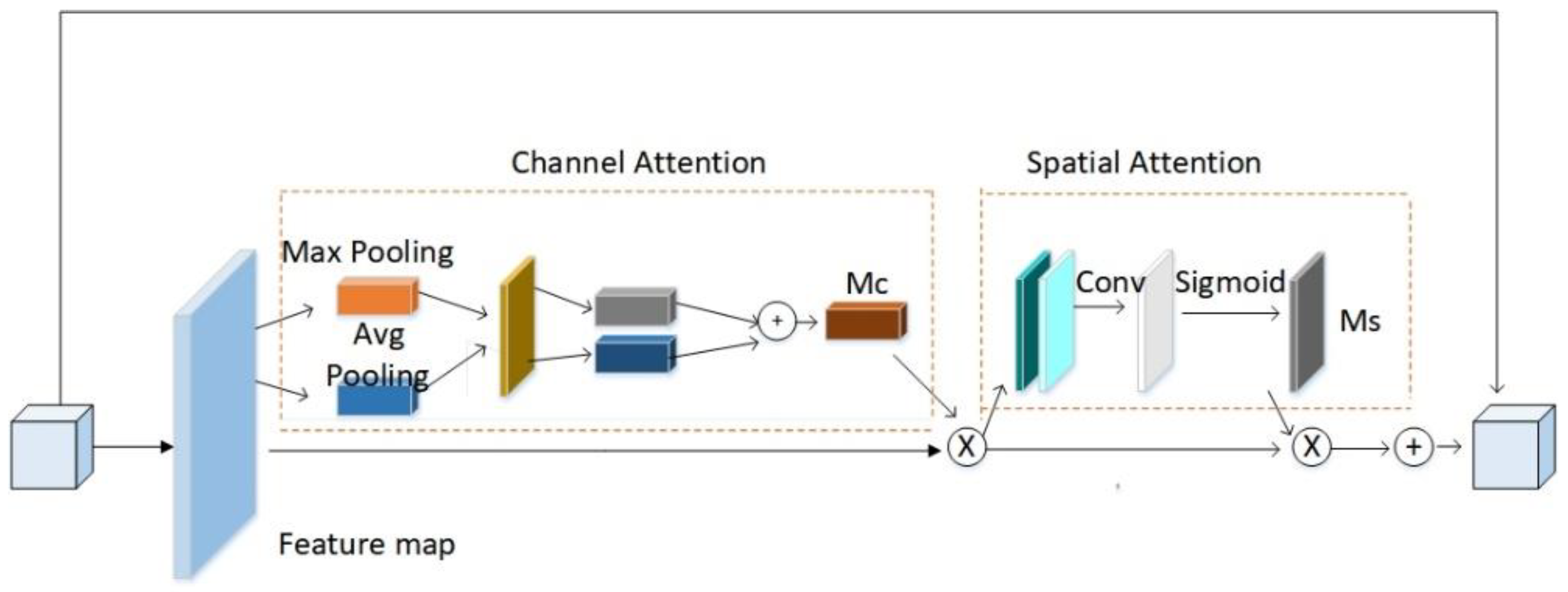
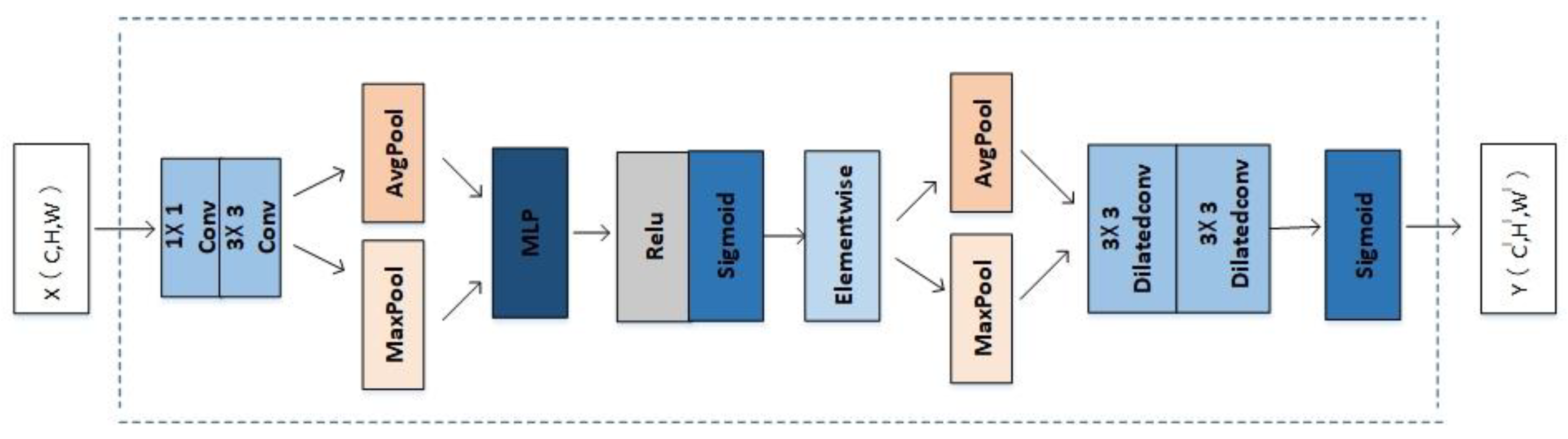
- The lightweight Convolutional Block Attention Module (CBAM) attention module is integrated into the low and middle branches of the image cascade network (ICNet) network so that the high-resolution branches can better guide the features of the low and middle branches, and the large-size convolution of spatial attention uses stacked hollow volumes for product replacement.
- The regular convolution in the low- and medium-resolution branches are replaced with asymmetric convolutions to reduce the computational effort.
2. Related Work
2.1. Encoder–Decoder Network
2.2. Attention Mechanism
2.3. Multiple Forms of Convolution
3. Methods
3.1. Adding the CBAM Attention Module to Low- and Medium-Resolution Branches
3.2. Asymmetric Convolution Replaces Regular Convolution
4. Experiment
4.1. Datasets
4.1.1. Data Collection
4.1.2. Data Augmentation
4.2. Metrics
4.3. Loss Function
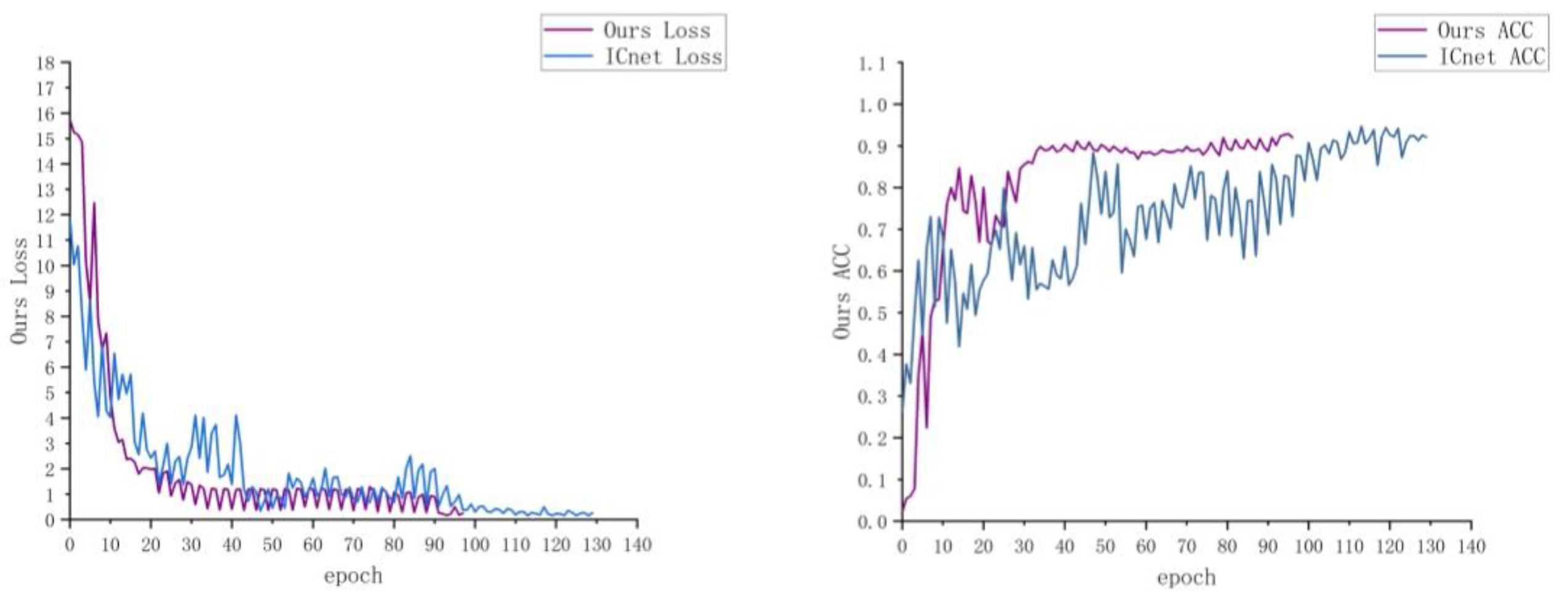
4.4. Experimental Details
5. Results
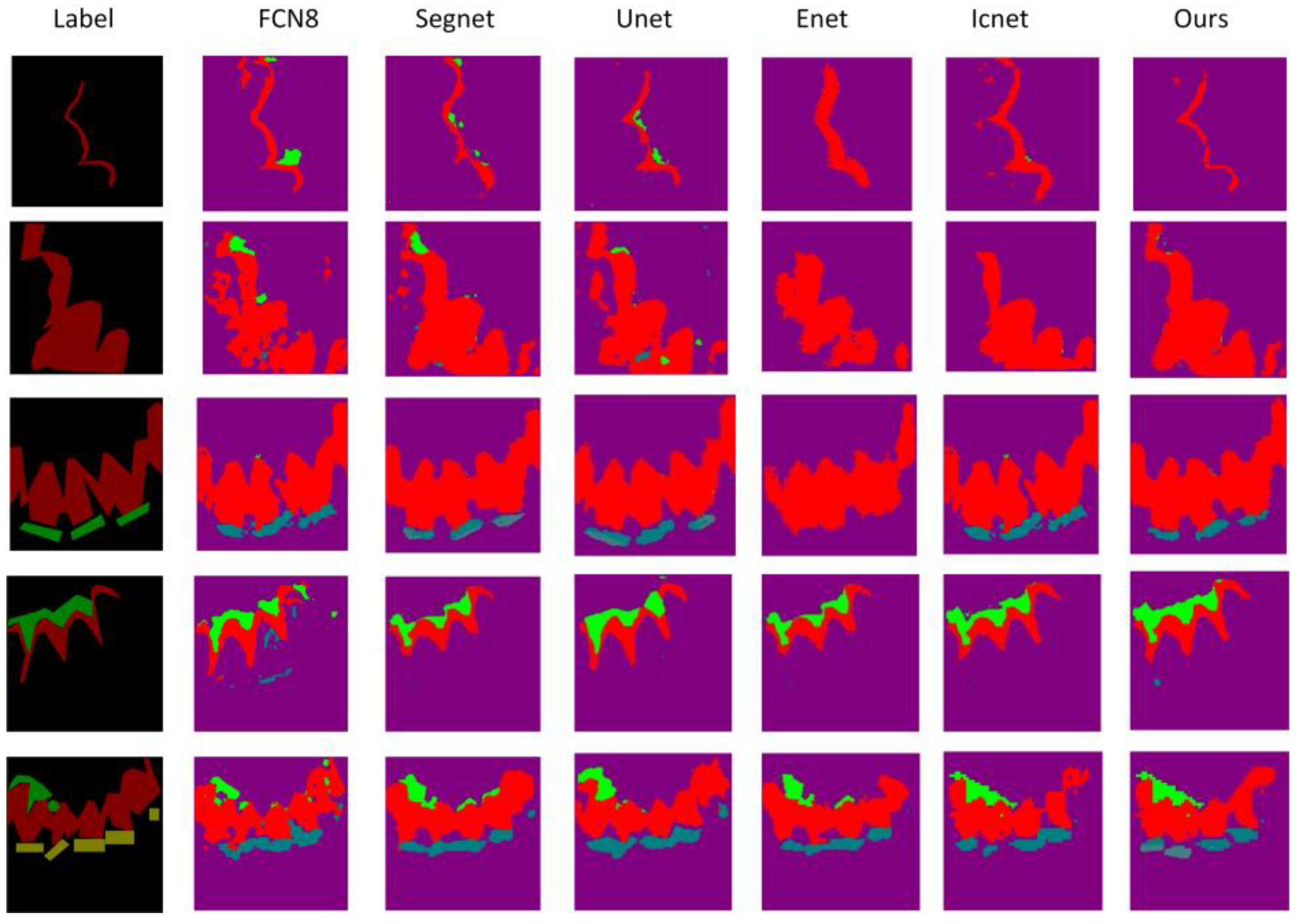
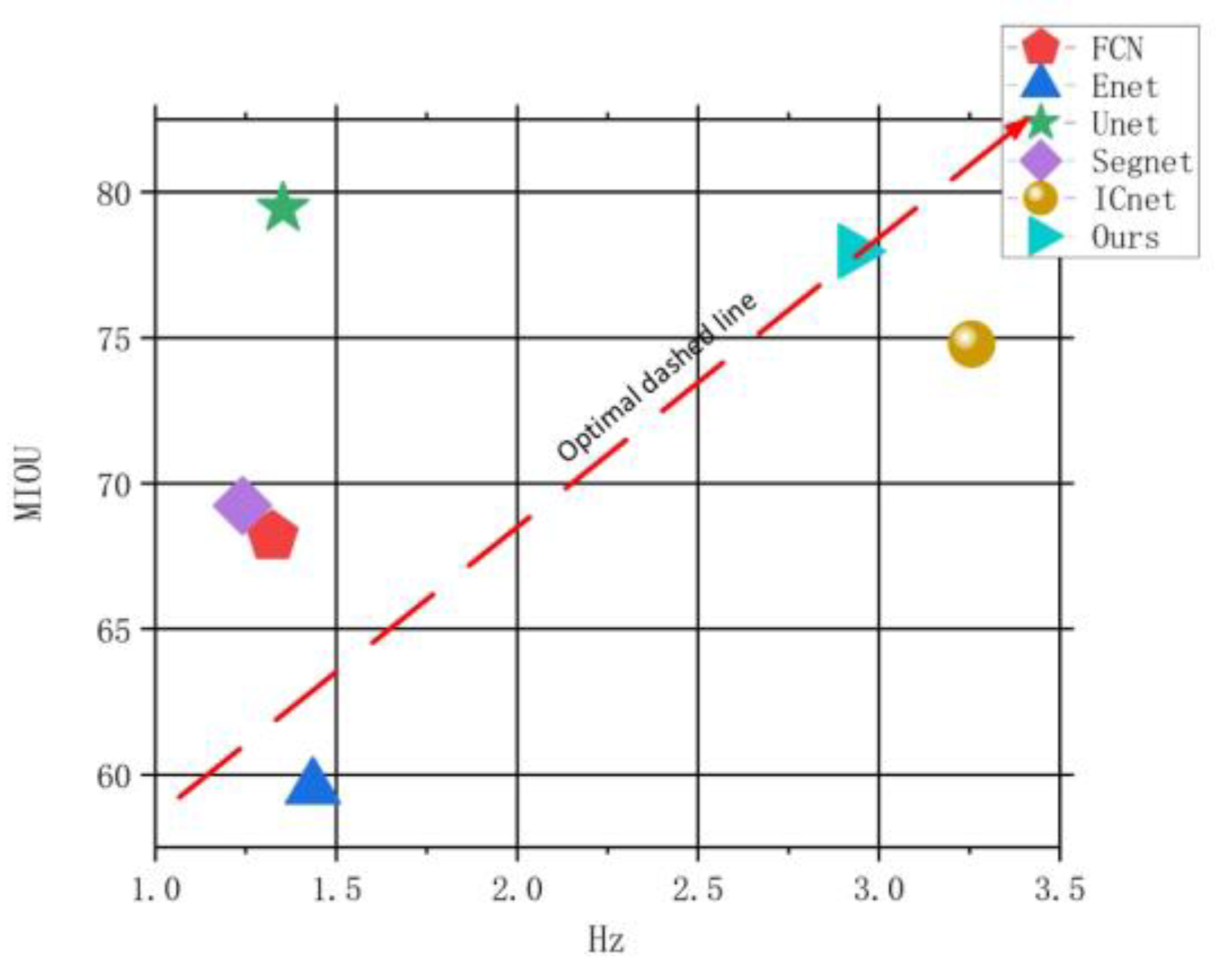
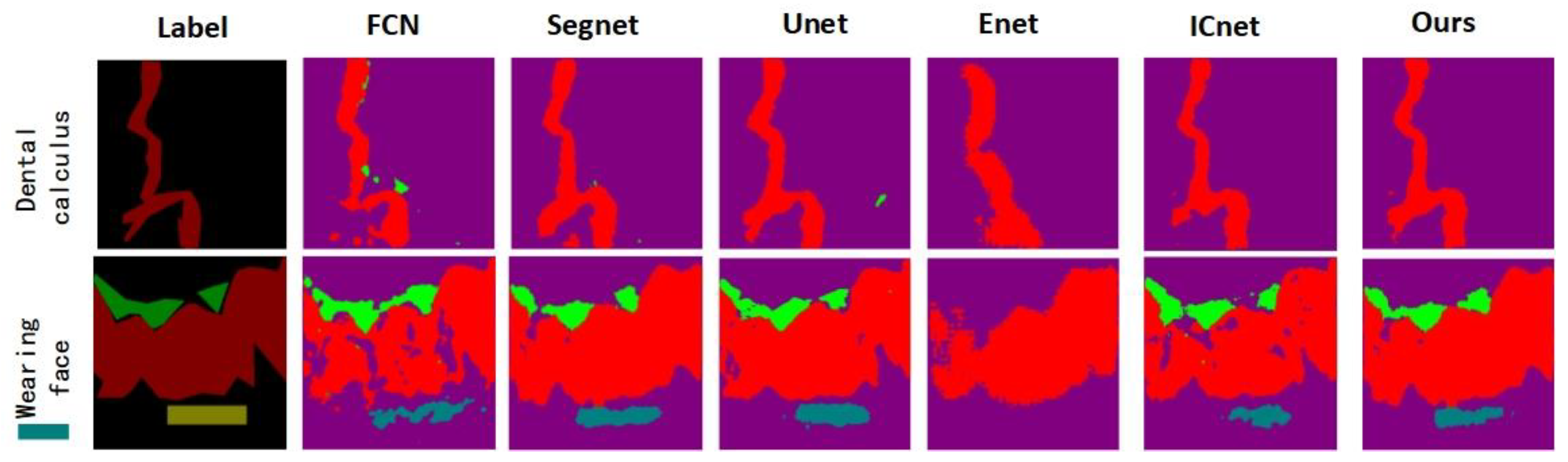
5.1. Contrast Test with Other Segmentation Algorithms
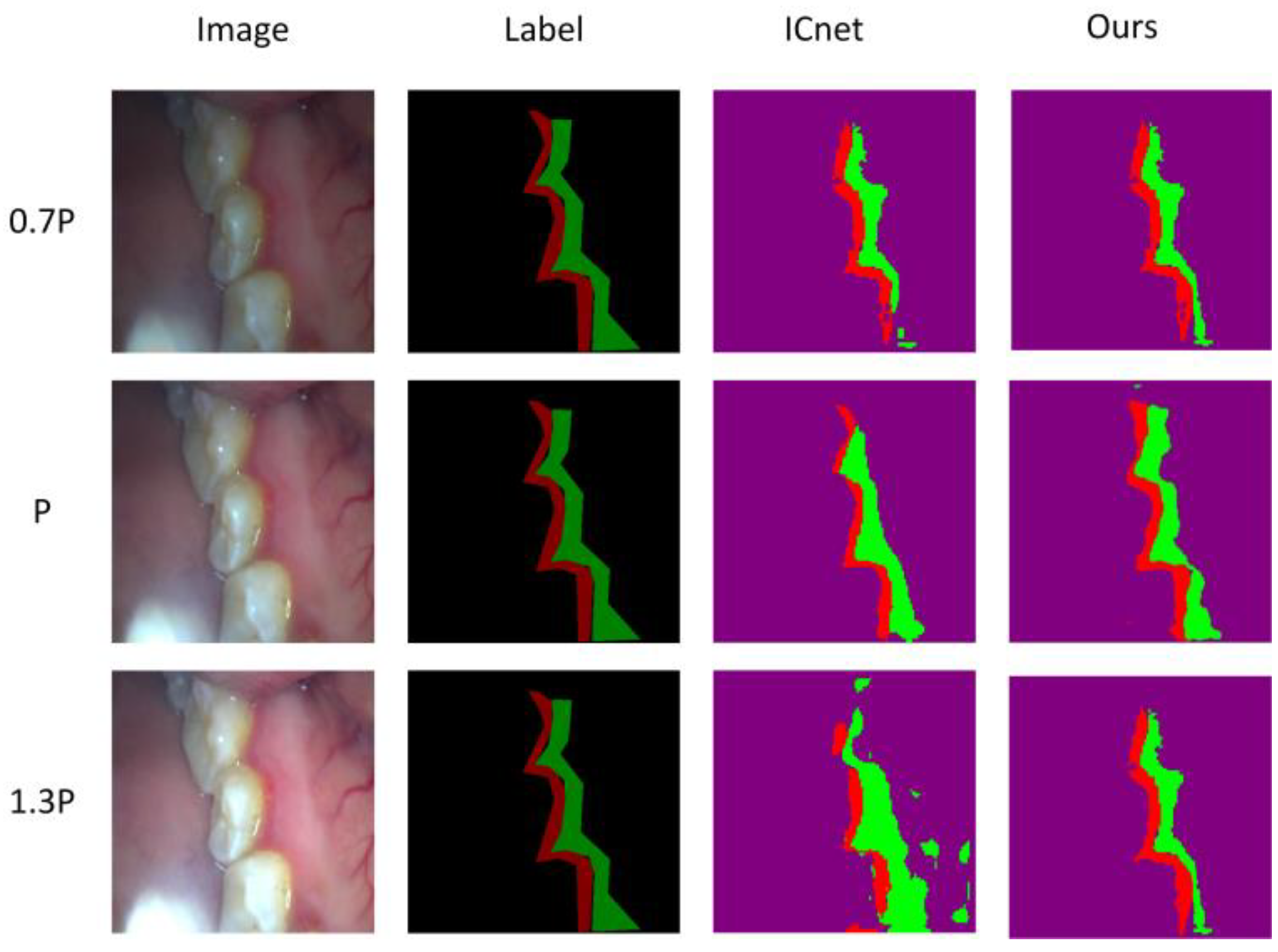
5.2. Segmentation under Different Brightness
5.3. Ablation Experiment of CBAM
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lee, C.Y.; Chuang, C.C.; Chen, G.J.; Huang, C.C.; Lee, S.Y.; Lin, Y.H. Automated segmentation of dental calculus in optical coherence tomography images. Sens. Mater. 2018, 30, 2517–2529. [Google Scholar] [CrossRef]
- Krois, J.; Ekert, T.; Meinhold, L.; Golla, T.; Kharbot, B.; Wittemeier, A.; Dörfer, C.; Schwendicke, F. Deep learning for the radio graphic detection of periodontal bone loss. Sci. Rep. 2019, 9, 84–95. [Google Scholar] [CrossRef] [Green Version]
- Casalegno, F.; Newton, T.; Daher, R.; Abdelaziz, M.; Lodi-Rizzini, A.; Schürmann, F.; Krejci, I.; Markram, H. Caries detection with near-infrared trans illumination using deep learning. J. Dent. Res. 2019, 98, 1227–1233. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.-H.; Kim, D.-H.; Jeong, S.-N.; Choi, S.-H. Diagnosis and prediction of periodontally compromised teeth using a deep learning-based convolutional neural network algorithm. J. Periodontal Implant Sci. 2018, 48, 114–123. [Google Scholar] [CrossRef] [Green Version]
- Yu, H.; Cho, S.; Kim, M.; Kim, W.; Kim, J.; Choi, J. Automated skeletal classification with lateral cephalometry based on artificial intelligence. J. Dent. Res. 2020, 99, 249–256. [Google Scholar] [CrossRef]
- Li, W.; Liang, Y.; Zhang, X.; Liu, C.; He, L.; Miao, L.; Sun, W. A deep learning approach to automatic gingivitis screening based on classification and localization in RGB photos. Sci. Rep. 2021, 11, 16831. [Google Scholar] [CrossRef]
- Karatas, O.H.; Toy, E. Three-dimensional imaging techniques: A literature review. Eur. J. Dent. 2014, 8, 132–140. [Google Scholar] [CrossRef]
- Graham, B.; Engelcke, M.; Van Der Maaten, L. 3D semantic segmentation with submanifold sparse convolutional networks. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 2018, 102, 9224–9232. [Google Scholar]
- Liu, T.; Cai, Y.; Zheng, J.; Thalmann, N.M. BEACon: A boundary embedded attentional convolution network for point cloud instance segmentation. Vis. Comput. 2022, 38, 2303–2313. [Google Scholar] [CrossRef]
- Ning, Z.; Zhong, S.; Feng, Q.; Chen, W.; Zhang, Y. SMU-Net: Saliency-Guided Morphology-Aware U-Net for Breast Lesion Segmentation in Ultrasound Image. IEEE Trans. Med. Imaging 2021, 41, 476–490. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar]
- Badrinarayanan Vijay and Kendall Alex and Cipolla Roberto. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. 2016. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for Real-Time Semantic Segmentation on High-Resolution Images; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Ye, H.; Jin, K.; Cheng, H. CT-UNet: Context-Transfer-UNet for Building Segmentation in Remote Sensing Images. Neural Process. Lett. 2021, 53, 4257–4277. [Google Scholar] [CrossRef]
- Tang, Q.; Liu, F.; Jiang, J.; Zhang, Y. EPRNet: Efficient Pyramid Representation Network for Real-Time Street Scene Segmentation. IEEE Trans. Intell. Transp. Syst. 2021, 23, 7008–7016. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017. [Google Scholar]
- Hu, S.; Ning, Q.; Chen, B.; Lei, Y.; Zhou, X.; Yan, H.; Zhao, C.; Tang, T.; Hu, R. Segmentation of aerial image with multi-scale feature and attention model. In Artificial Intelligence in China; Springer: Singapore, 2020; pp. 58–66. [Google Scholar]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic segmentation of urban buildings from VHR remote sensing imagery using a deep convolutional neural network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Jie, H.; Li, S.; Gang, S. Squeeze and Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 99. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammeria, N.Y.; Kainz, B.; et al. Attention U-Net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Guo, C.; Szemenyei, M.; Yi, Y.; Wang, W.; Chen, B.; Fan, C. SAUNet: Spatial Attention U-Net for Retinal Vessel Segmentation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 1236–1242. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depth wise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 2017, 2808, 3929–3938. [Google Scholar]
- Xie, Z.; Huang, Y.; Zhu, Y.; Jin, L.; Liu, Y.; Xie, L. Aggregation Cross-Entropy for Sequence Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Calculus | Gingivitis | Tartar | Worn Surfaces |
|---|---|---|---|
| 209 | 215 | 33 | 100 |
| Model | Acc | mIoU | F1_Score | Times (ms) |
|---|---|---|---|---|
| FCN8 | 0.8215 | 68.17 | 0.8045 | 833 |
| ENet | 0.8160 | 62.30 | 0.7749 | 696 |
| U-Net | 0.8875 | 78.61 | 0.8838 | 739 |
| SegNet | 0.8284 | 69.24 | 0.8162 | 805 |
| ICNet | 0.8513 | 74.76 | 0.8493 | 307 |
| Ours | 0.8897 | 78.67 | 0.8890 | 395 |
| Model | FLOPs |
|---|---|
| ICNet | 13,524,726 |
| Ours | 15,608,042 |
| mIoU | |||
|---|---|---|---|
| Model | 0.7P | P | 0.8P |
| ICNet | 58.50 | 60.83 | 56.38 |
| Ours | 58.65 | 61.33 | 55.99 |
| Model | MIOU | Add Param |
|---|---|---|
| ICNet + CBAM3 × 3 | 76.84 | 0 |
| ICNet + CBAM7 × 7 | 77.42 | 240 |
| ICNet + CBAM2 × 3 × 3 | 77.97 | 180 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, T.; Zhou, X.; Yang, J.; Meng, B.; Qian, J.; Zhang, J.; Ge, G. Dental Lesion Segmentation Using an Improved ICNet Network with Attention. Micromachines 2022, 13, 1920. https://doi.org/10.3390/mi13111920
Ma T, Zhou X, Yang J, Meng B, Qian J, Zhang J, Ge G. Dental Lesion Segmentation Using an Improved ICNet Network with Attention. Micromachines. 2022; 13(11):1920. https://doi.org/10.3390/mi13111920
Chicago/Turabian StyleMa, Tian, Xinlei Zhou, Jiayi Yang, Boyang Meng, Jiali Qian, Jiehui Zhang, and Gang Ge. 2022. "Dental Lesion Segmentation Using an Improved ICNet Network with Attention" Micromachines 13, no. 11: 1920. https://doi.org/10.3390/mi13111920